
Stereo Visual Odometry Pose Correction through Unsupervised Deep Learning

Abstract
:1. Introduction
- (1)
- An unsupervised stereo visual odometry pose correction network is used, which can be trained without labeled data.
- (2)
- During training, the spatial and temporal properties of the stereo image sequence are used to model the camera ego-motion, and a modified version of the U-Net encoder–decoder [18] is designed.
- (3)
- An unsupervised stereo visual odometry pose correction network is used that can output camera pose correction, left–right depth map, and left–right explainability mask simultaneously.
- (4)
- Experiments show the stereo visual odometry pose correction network can significantly improve the positioning accuracy of the classical stereo VO system, and the improved stereo VO system has almost reached the state of the art.
2. Related Work
2.1. Classical VO
2.2. Supervised Deep Learning VO
2.3. Unsupervised Deep Learning VO
2.4. Hybrid VO
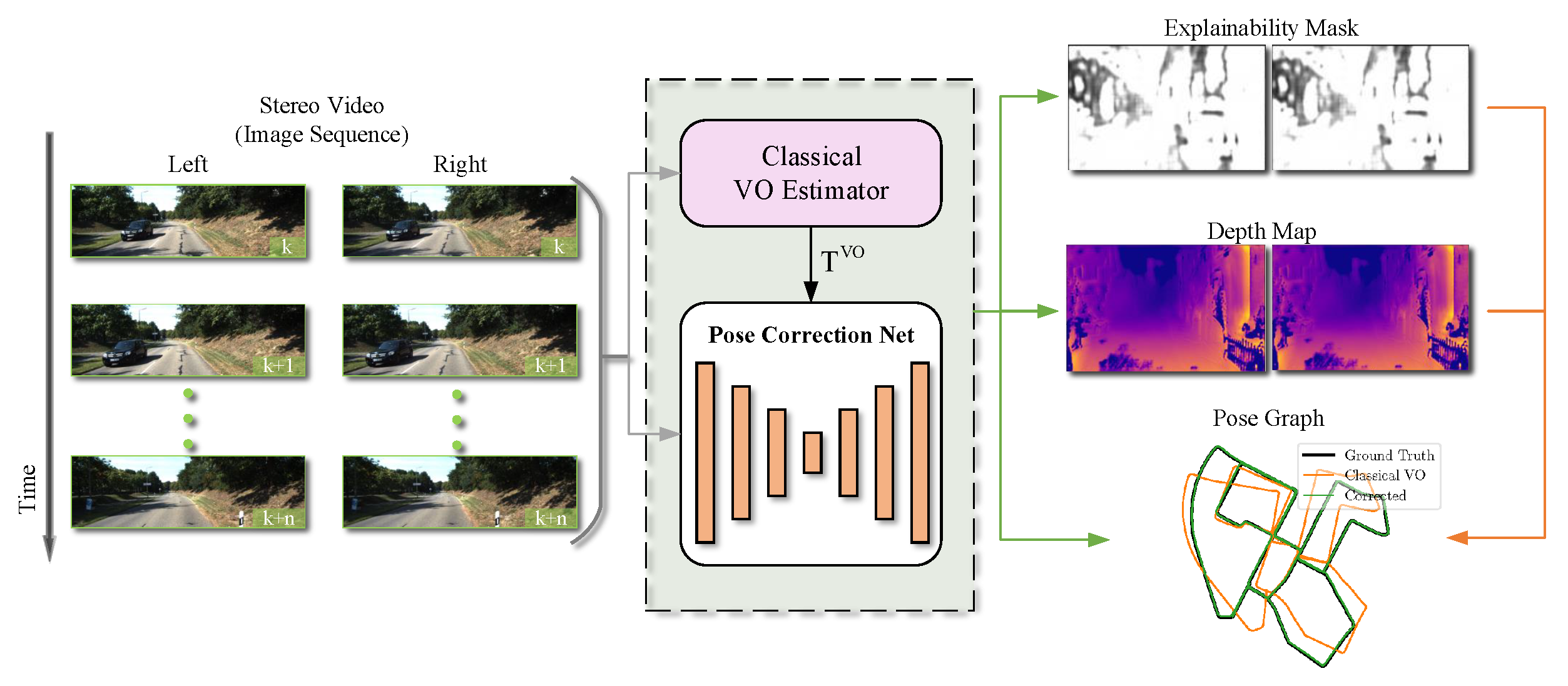
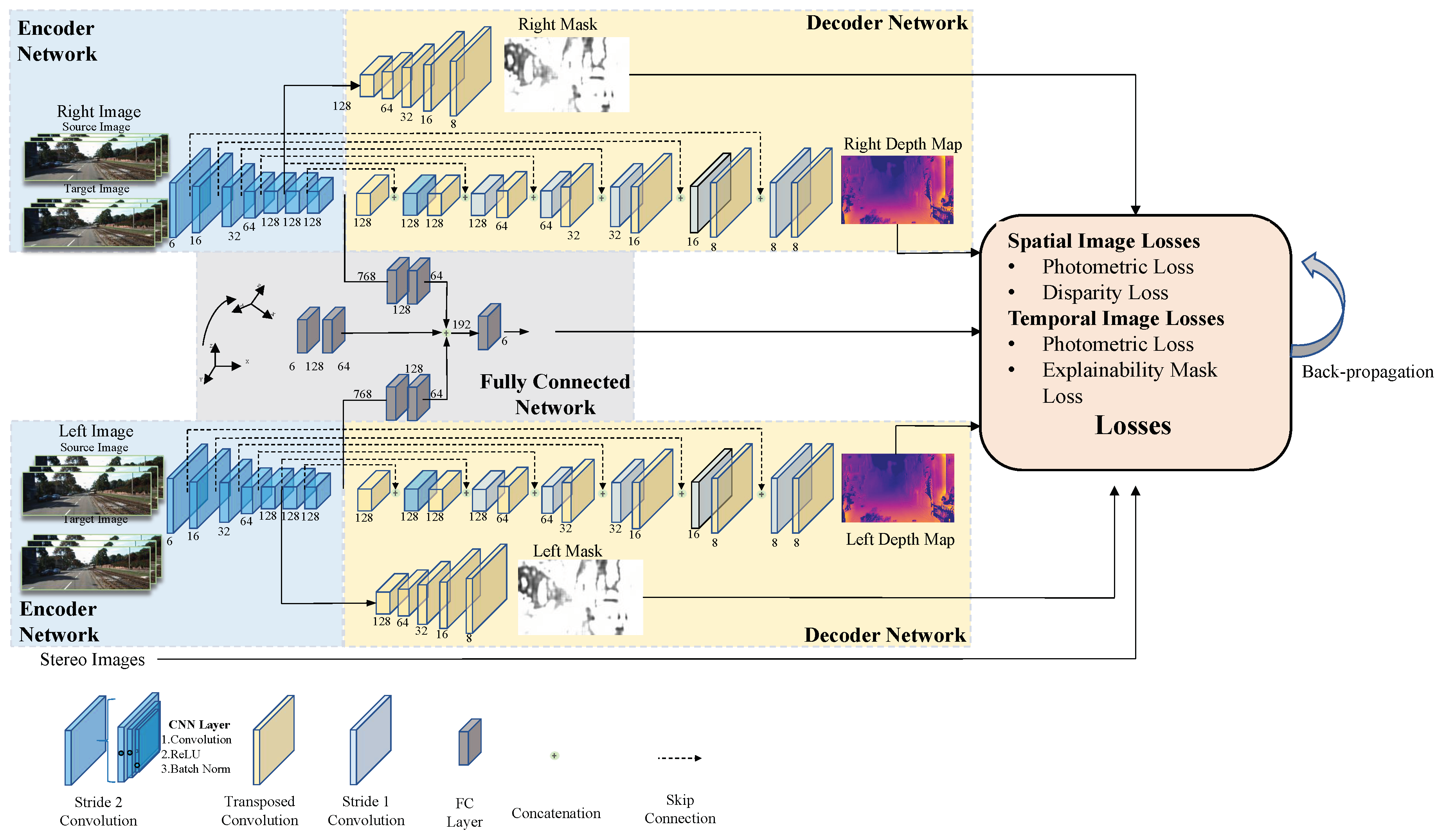
3. System Overview
 Lie algebra, to parameterize the correction. When the network outputs the final correction, we use the exponential map to generate an correction as follows:
Lie algebra, to parameterize the correction. When the network outputs the final correction, we use the exponential map to generate an correction as follows:4. Loss Function
4.1. Spatial Image Loss of Left–Right Image Pairs
4.1.1. Photometric Consistency Loss
4.1.2. Disparity Consistency Loss
4.2. Temporal Image Loss of a Sequence of Monocular Imagery
4.2.1. Photometric Consistency Loss
4.2.2. Explainability Mask Loss
5. Experimental Evaluation
5.1. Implementation Details
5.2. Visual Odometry Evaluation
5.2.1. Evaluation Metrics
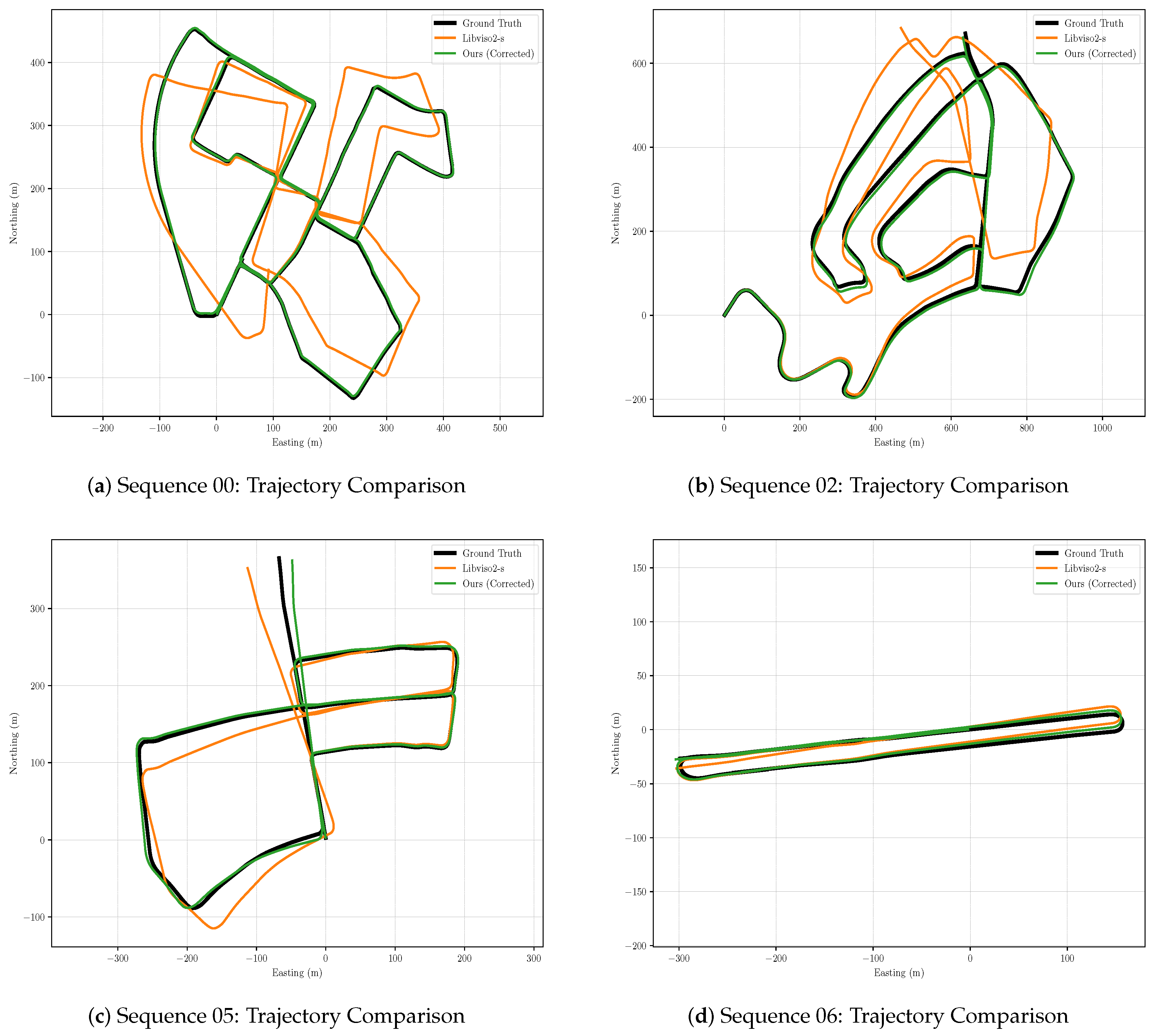
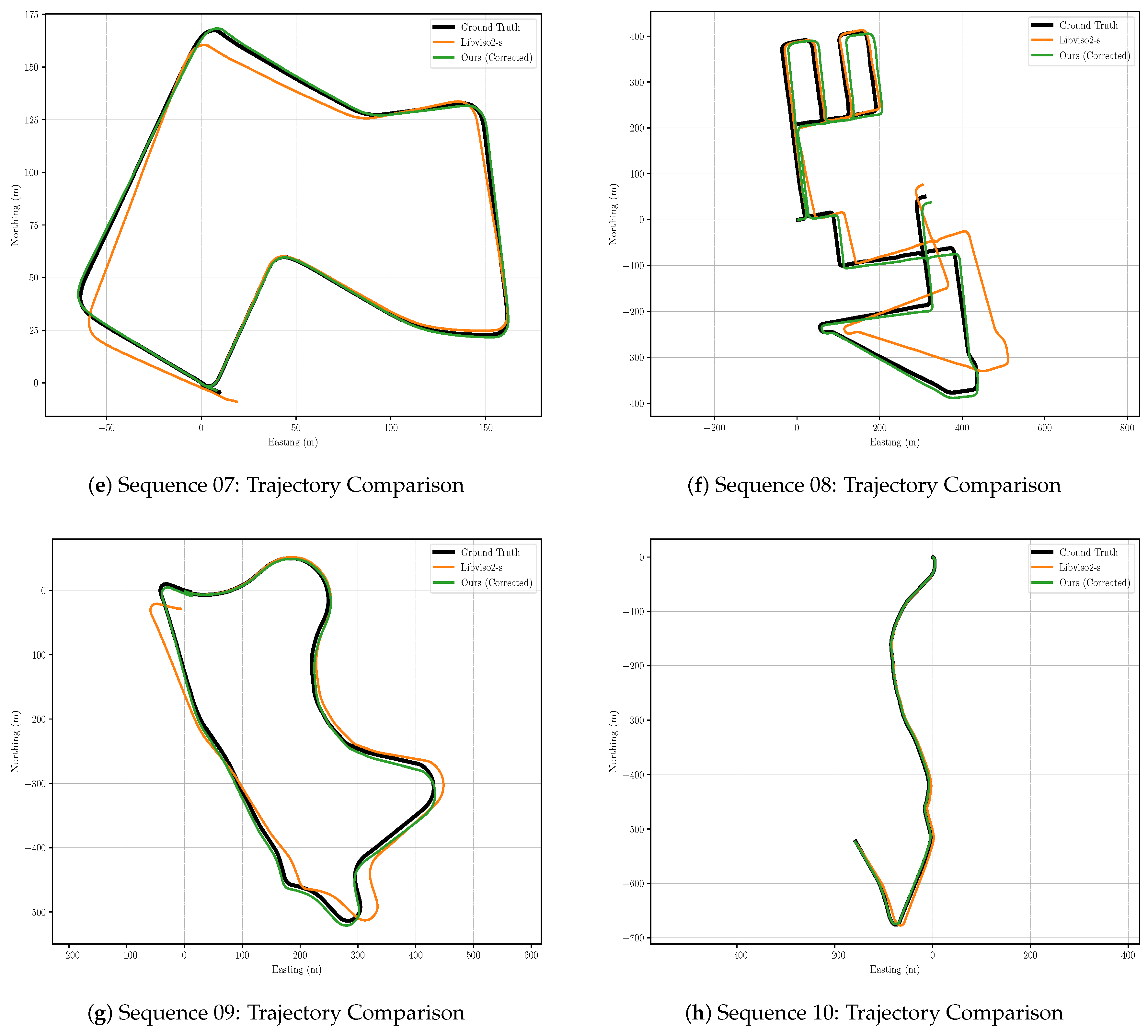
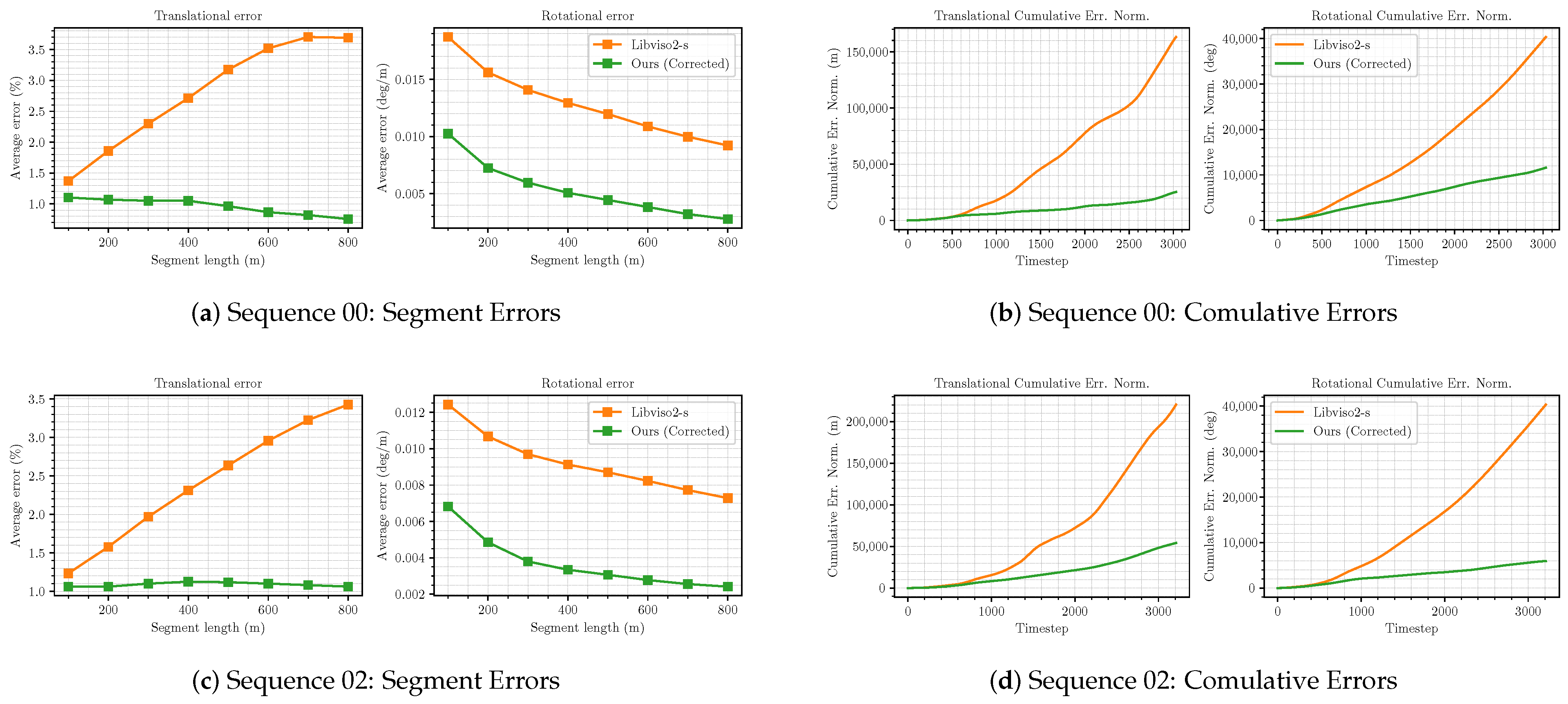
5.2.2. Improvement Degree of Classical Stereo VO System
5.2.3. Corrected Classical Stereo VO System Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the Eight IEEE and ACM International Symposium on Mixed and Augmented Reality, Orlando, FL, USA, 19–22 October 2009; pp. 225–234. [Google Scholar]
- Lin, M.; Yang, C.; Li, D. An improved transformed unscented Fast-SLAM with adaptive genetic resampling. IEEE Trans. Ind. Electron. 2019, 66, 3583–3594. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Zhan, H.; Garg, R.; Weerasekera, C.S.; Li, K.; Agarwal, H.; Reid, I. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 340–349. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Bian, J.-W.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.-M.; Reid, I. Unsupervised scale-consistent depth and ego-motion learning from monocular video. In Proceedings of the Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-DoF camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Brachmann, E.; Krull, A.; Nowozin, S.; Shotton, J.; Michel, F.; Gumhold, S.; Rother, C. Dsac-differentiable ransac for camera localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6684–6692. [Google Scholar]
- Brachmann, E.; Rother, C. Learning less is more-6d camera localization via 3d surface regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4654–4662. [Google Scholar]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6565–6574. [Google Scholar]
- Tang, J.; Ericson, L.; Folkesson, J.; Jensfelt, P. GCNv2: Efficient correspondence prediction for real-time SLAM. IEEE Robot. Autom. Lett. 2019, 4, 3505–3512. [Google Scholar] [CrossRef] [Green Version]
- Memon, A.R.; Wang, H.; Hussain, A. Loop closure detection using supervised and unsupervised deep neural networks for monocular SLAM systems. Robot. Auton. Syst. 2020, 126, 103470. [Google Scholar] [CrossRef]
- Li, R.; Wang, S. DeepSLAM: A robust monocular SLAM system with unsupervised deep learning. IEEE Trans. Ind. Electron. 2021, 68, 3577–3587. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–341. [Google Scholar]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An open-source SLAM system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Ziegler, J.; Stiller, C. Stereoscan: Dense 3d reconstruction in real-time. In Proceedings of the Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Konda, K.; Memisevic, R. Learning visual odometry with a convolutional network. In Proceedings of the International Conference on Computer Vision Theory and Applications, Berlin, Germany, 11–14 March 2015; pp. 486–490. [Google Scholar]
- Li, R.; Liu, Q.; Gui, J.; Gu, D.; Hu, H. Indoor relocalization in challenging environments with dual-stream convolutional neural networks. IEEE Trans. Autom. Sci. Eng. 2018, 15, 651–662. [Google Scholar] [CrossRef]
- Walch, F.; Hazirbas, C.; Leal-Taixé, L.; Sattler, T.; Hilsenbeck, S.; Cremers, D. Image-based localization using LSTMs for structured feature correlation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 627–637. [Google Scholar]
- Kendall, A.; Cipolla, R. Modelling uncertainty in deep learning for camera relocalization. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4762–4769. [Google Scholar]
- Clark, R.; Wang, S.; Markham, A.; Trigoni, N.; Wen, H. VidLoc:6-DoF video-clip relocalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6856–6864. [Google Scholar]
- Saputra, M.R.U.; de Gusmao, P.P.; Wang, S.; Markham, A.; Trigoni, N. Learning monocular visual odometry through geometry-aware curriculum learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3549–3555. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2043–2050. [Google Scholar]
- Barnes, D.; Maddern, W.; Pascoe, G.; Posner, I. Driven to distraction: Self-supervised distractor learning for robust monocular visual odometry in urban environments. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1894–1900. [Google Scholar]
- Zhao, C.; Sun, L.; Purkait, P.; Duckett, T.; Stolkin, R. Learning monocular visual odometry with dense 3D mapping from dense 3D flow. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6864–6871. [Google Scholar]
- Zhang, H.; Weerasekera, C.S.; Bian, J.-B.; Reid, I. Visual odometry revisited: What should be learnt? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Liu, Q.; Zhang, H.; Xu, Y.; Wang, L. Unsupervised Deep Learning-Based RGB-D Visual Odometry. Appl. Sci. 2020, 10, 5426. [Google Scholar] [CrossRef]
- Valente, M.; Joly, C.; de La Fortelle, A. Deep sensor fusion for real-time odometry estimation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Yang, N.; Stumberg, L.V.; Wang, R.; Cremers, D. D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry. arXiv 2020, arXiv:2003.01060. [Google Scholar]
- Sarlin, P.-E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperGlue: Learning feature matching with graph neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Ji, X.; Ye, X.; Xu, H.; Li, H. Dense reconstruction from monocular SLAM with fusion of sparse map-points and CNN-inferred depth. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Dumoulin, V.; Visin, F. A guide to convolution arithmetic for deep learning. arXiv 2016, arXiv:1603.07285. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. arXiv 2016, arXiv:1506.02025. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. (IJRR) 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differen-tiation in PyTorch. In Proceedings of the NIPS Autodiff Workshop, Long Beach, CA, USA, 3–9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wagstaff, B.; Peretroukhin, V.; Kelly, J. Self-Supervised Deep Pose Corrections for Robust Visual Odometry. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–4 June 2020; pp. 2331–2337. [Google Scholar]
- Wang, S.; Clark, R.; Wen, H.; Trigoni, N. End-to-end, sequence-to-sequence probabilistic visual odometry through deep neural networks. Int. J. Robot. Res. 2018, 37, 513–542. [Google Scholar] [CrossRef]
- Loo, S.Y.; Amiri, A.J.; Mashohor, S.; Tang, S.H.; Zhang, H. CNN-SVO: Improving the mapping in semi-direct visual odometry using single-image depth prediction. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Method | 00 | 02 | 05 | 06 | 07 | 08 | 09 | 10 | Avg. Err. |
|---|---|---|---|---|---|---|---|---|---|---|
| SfM-Learner (from [31]) | 21.32 | 24.10 | 12.99 | 15.55 | 12.61 | 10.66 | 11.32 | 15.25 | 15.48 | |
| Depth-VO-Feat (from [31]) | 6.23 | 6.59 | 4.94 | 5.80 | 6.49 | 5.45 | 11.89 | 12.82 | 7.53 | |
| SC-SfM-Learner (from [31]) | 11.01 | 6.74 | 6.70 | 5.36 | 8.29 | 8.11 | 7.64 | 10.74 | 8.07 | |
| ss-DPC-Net | 2.49 | 0.93 | 1.25 | 1.06 | 1.16 | 1.52 | 2.11 | 3.20 | 1.72 | |
| ESP-VO (from [17]) | - | - | 3.35 | 7.24 | 3.52 | - | - | 9.77 | 5.97 | |
| libviso2-s | 2.79 | 2.42 | 2.31 | 1.12 | 3.14 | 2.44 | 2.43 | 1.40 | 2.26 | |
| ORB-SLAM2 (from [31]) | 11.43 | 10.34 | 9.04 | 14.56 | 9.77 | 11.46 | 9.30 | 2.57 | 9.81 | |
| Ours | 0.95 | 1.08 | 1.06 | 0.73 | 0.84 | 1.42 | 1.70 | 0.89 | 1.08 | |
| SfM-Learner (from [31]) | 6.19 | 4.18 | 4.66 | 5.58 | 6.31 | 3.75 | 4.07 | 4.06 | 4.85 | |
| Depth-VO-Feat (from [31]) | 2.44 | 2.26 | 2.34 | 2.06 | 3.56 | 2.39 | 3.60 | 3.41 | 2.76 | |
| SC-SfM-Learner (from [31]) | 3.39 | 1.96 | 2.38 | 1.65 | 4.53 | 2.61 | 2.19 | 4.58 | 2.91 | |
| ss-DPC-Net | 1.41 | 0.42 | 0.45 | 0.54 | 0.95 | 0.80 | 0.80 | 1.19 | 0.82 | |
| ESP-VO (from [17]) | - | - | 4.93 | 7.29 | 5.02 | - | - | 10.2 | 6.86 | |
| libviso2-s | 1.29 | 0.92 | 1.13 | 0.79 | 1.68 | 1.39 | 1.19 | 1.06 | 1.18 | |
| ORB-SLAM2 (from [31]) | 0.58 | 0.26 | 0.26 | 0.26 | 0.36 | 0.28 | 0.26 | 0.32 | 0.28 | |
| Ours | 0.53 | 0.37 | 0.44 | 0.41 | 0.88 | 0.75 | 0.58 | 0.43 | 0.54 | |
| ATE | SfM-Learner (from [31]) | 104.87 | 185.43 | 60.89 | 52.19 | 20.12 | 30.97 | 26.93 | 24.09 | 63.19 |
| Depth-VO-Feat (from [31]) | 64.45 | 85.13 | 22.15 | 14.31 | 15.35 | 29.53 | 52.12 | 24.70 | 38.47 | |
| SC-SfM-Learner (from [31]) | 93.04 | 70.37 | 40.56 | 12.56 | 21.01 | 56.15 | 15.02 | 20.19 | 41.11 | |
| ss-DPC-Net | 15.16 | 36.87 | 8.20 | 6.96 | 5.88 | 42.32 | 28.91 | 30.75 | 21.88 | |
| libviso2-s | 64.42 | 84.61 | 25.02 | 7.71 | 14.47 | 65.68 | 48.88 | 9.46 | 40.03 | |
| DSO (from [46]) | 113.18 | 116.81 | 47.46 | 55.62 | 16.72 | 111.08 | 52.23 | 11.09 | 65.52 | |
| ORB-SLAM2 (from [31]) | 40.65 | 47.82 | 29.95 | 40.82 | 16.04 | 43.09 | 38.77 | 5.42 | 32.82 | |
| CNN-SVO (from [46]) | 17.53 | 50.52 | 8.15 | 11.51 | 6.51 | 10.98 | 10.69 | 4.84 | 15.09 | |
| Ours | 10.47 | 19.38 | 7.00 | 4.40 | 3.28 | 37.48 | 24.90 | 3.28 | 13.77 | |
| RPE(M) | SfM-Learner (from [31]) | 0.282 | 0.365 | 0.158 | 0.151 | 0.081 | 0.122 | 0.103 | 0.118 | 0.173 |
| Depth-VO-Feat (from [31]) | 0.084 | 0.087 | 0.077 | 0.079 | 0.081 | 0.084 | 0.164 | 0.159 | 0.102 | |
| SC-SfM-Learner (from [31]) | 0.139 | 0.092 | 0.070 | 0.069 | 0.075 | 0.085 | 0.095 | 0.105 | 0.091 | |
| ss-DPC-Net | 0.050 | 0.063 | 0.037 | 0.047 | 0.037 | 0.051 | 0.054 | 0.042 | 0.048 | |
| libviso2-s | 0.062 | 0.078 | 0.051 | 0.063 | 0.052 | 0.068 | 0.069 | 0.059 | 0.062 | |
| ORB-SLAM2 (from [31]) | 0.169 | 0.172 | 0.140 | 0.237 | 0.105 | 0.192 | 0.128 | 0.045 | 0.315 | |
| Ours | 0.041 | 0.053 | 0.031 | 0.042 | 0.031 | 0.047 | 0.049 | 0.038 | 0.041 | |
| RPE | SfM-Learner (from [31]) | 0.227 | 0.172 | 0.153 | 0.119 | 0.181 | 0.152 | 0.159 | 0.171 | 0.167 |
| Depth-VO-Feat (from [31]) | 0.202 | 0.177 | 0.156 | 0.131 | 0.176 | 0.180 | 0.233 | 0.246 | 0.188 | |
| SC-SfM-Learner (from [31]) | 0.129 | 0.087 | 0.069 | 0.066 | 0.074 | 0.074 | 0.102 | 0.107 | 0.089 | |
| ss-DPC-Net | 0.095 | 0.082 | 0.076 | 0.073 | 0.084 | 0.083 | 0.067 | 0.077 | 0.080 | |
| libviso2-s | 0.117 | 0.095 | 0.091 | 0.093 | 0.077 | 0.095 | 0.086 | 0.093 | 0.092 | |
| ORB-SLAM2 (from [31]) | 0.079 | 0.074 | 0.058 | 0.055 | 0.047 | 0.061 | 0.061 | 0.065 | 0.062 | |
| Ours | 0.093 | 0.072 | 0.066 | 0.063 | 0.054 | 0.071 | 0.063 | 0.071 | 0.069 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Lu, S.; He, R.; Bao, Z. Stereo Visual Odometry Pose Correction through Unsupervised Deep Learning. Sensors 2021, 21, 4735. https://doi.org/10.3390/s21144735
Zhang S, Lu S, He R, Bao Z. Stereo Visual Odometry Pose Correction through Unsupervised Deep Learning. Sensors. 2021; 21(14):4735. https://doi.org/10.3390/s21144735
Chicago/Turabian StyleZhang, Sumin, Shouyi Lu, Rui He, and Zhipeng Bao. 2021. "Stereo Visual Odometry Pose Correction through Unsupervised Deep Learning" Sensors 21, no. 14: 4735. https://doi.org/10.3390/s21144735
APA StyleZhang, S., Lu, S., He, R., & Bao, Z. (2021). Stereo Visual Odometry Pose Correction through Unsupervised Deep Learning. Sensors, 21(14), 4735. https://doi.org/10.3390/s21144735