
Printed Circuit Board Defect Detection Using Deep Learning via A Skip-Connected Convolutional Autoencoder

Abstract
:1. Introduction
2. Materials and Methods
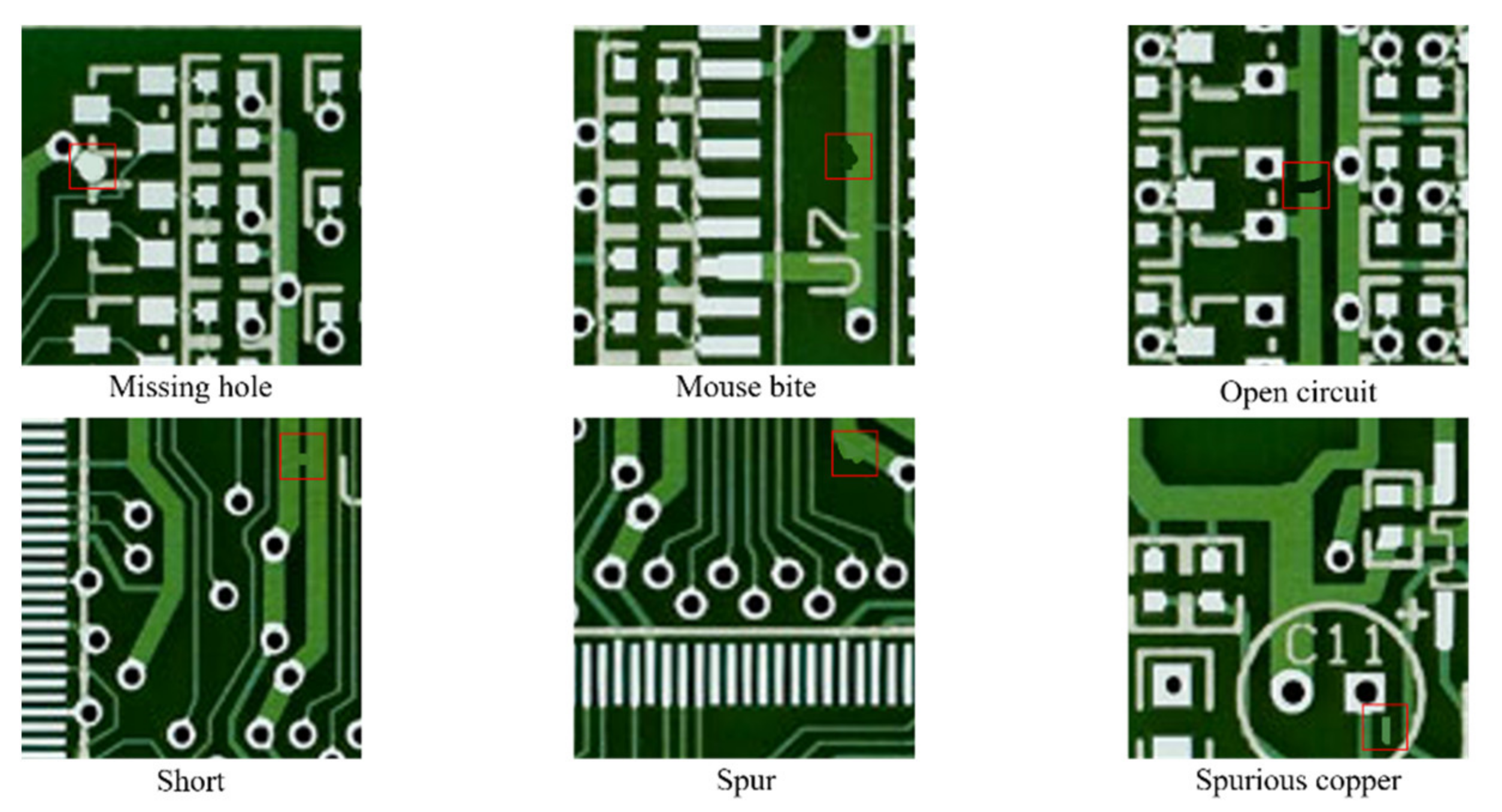
2.1. Data
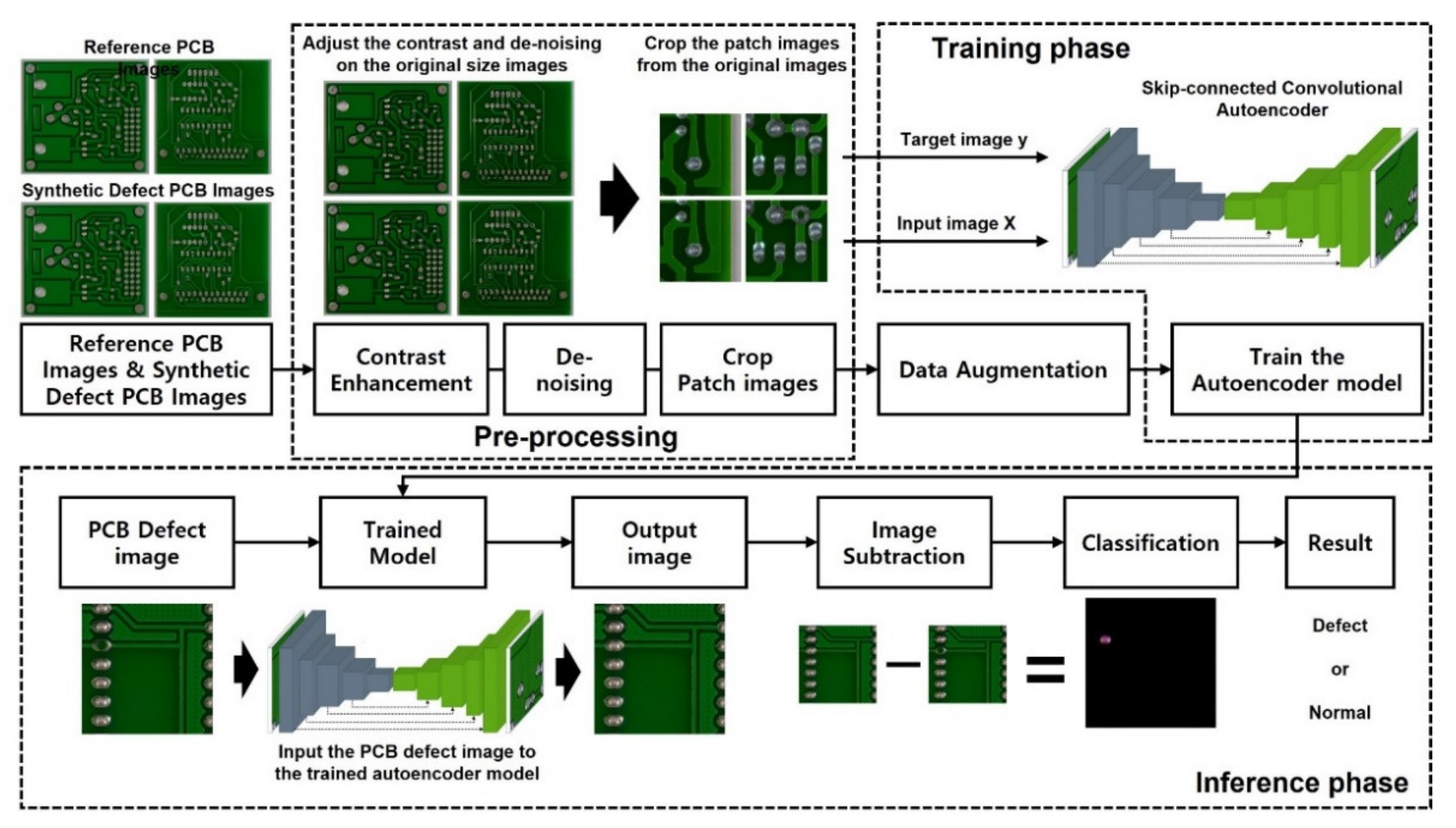
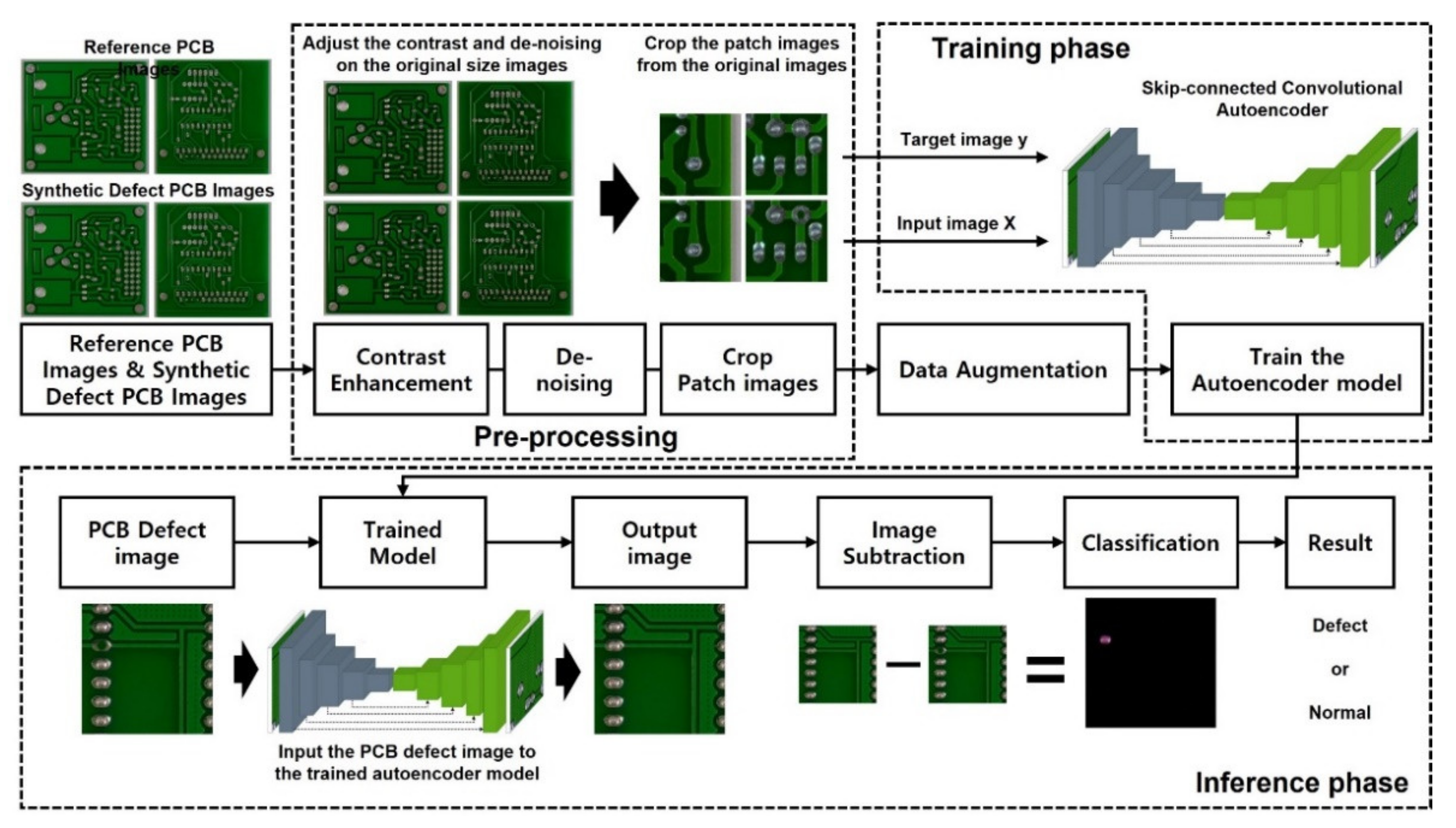
2.2. Overall System Configuration
2.3. Preprocessing
2.4. Data Augmentation
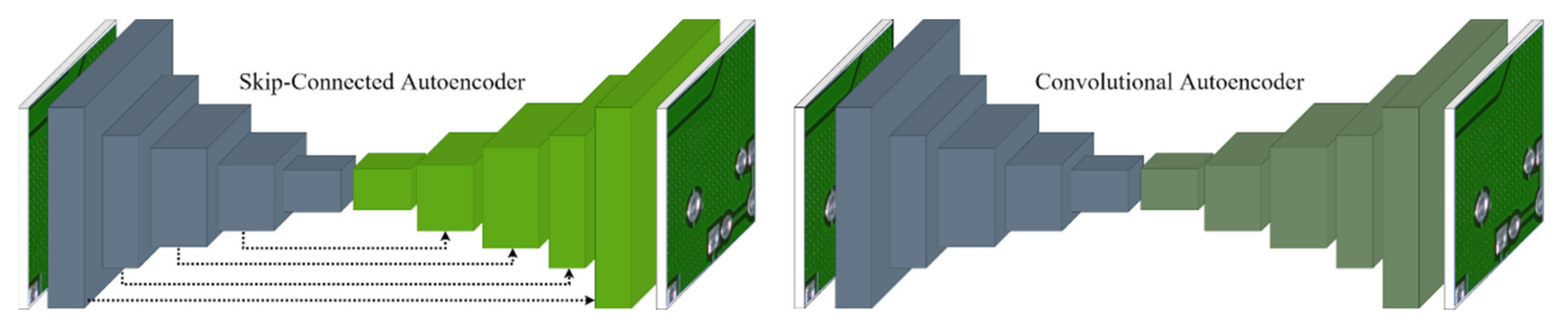
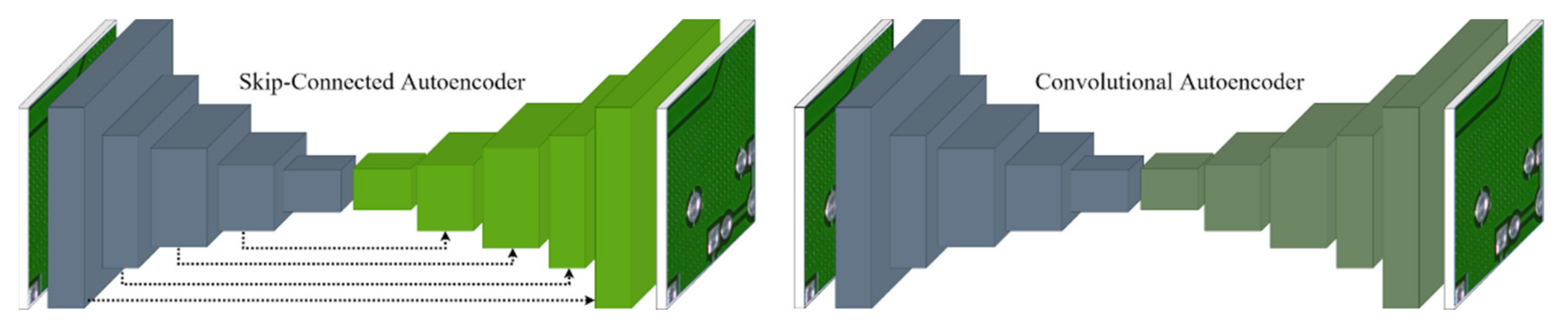
2.5. Skip-Connected Convolutional Autoencoder
2.6. Performance Evaluation
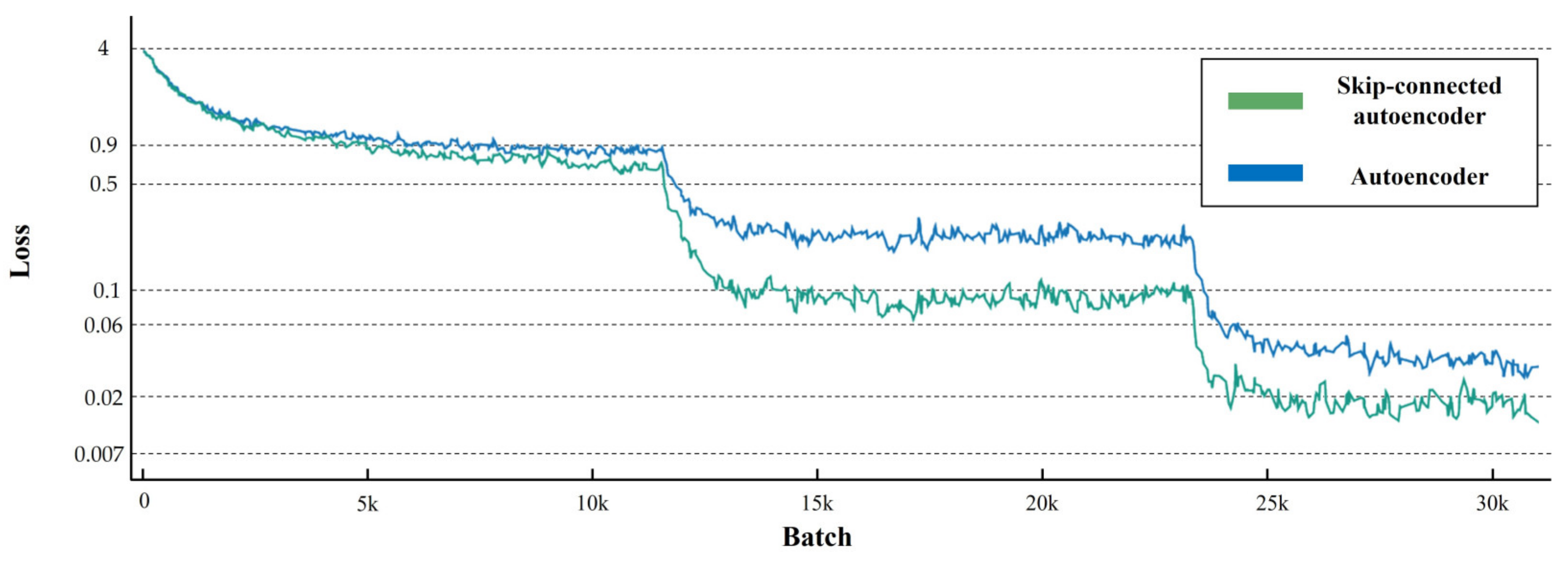
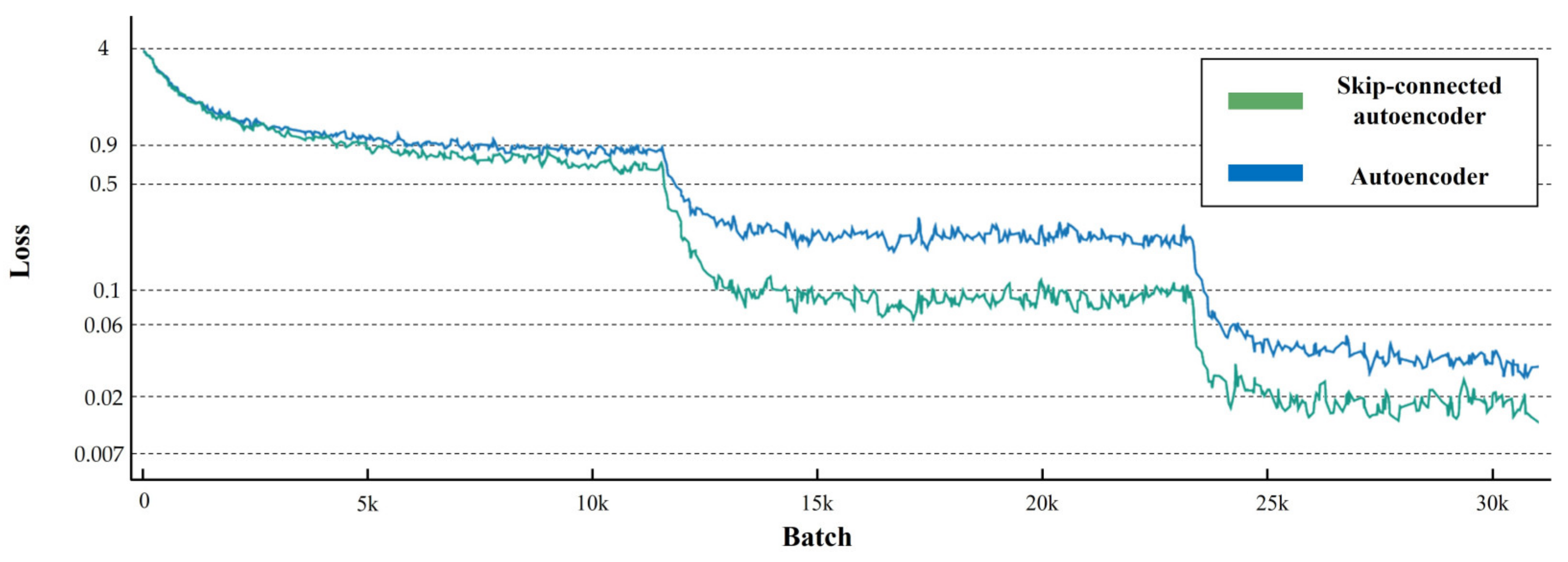
3. Experiment Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PCB | Printed Circuit Boards |
| AOI | Automated Optical Inspection |
| CCD | Charge Coupled Device |
| CMOS | Complementary Metal Oxide Semiconductor |
| CNN | Convolutional Neural Network |
| Conv | Convolutional Layers |
| ReLU | Rectified Linear Unit |
| BFLOPs | Billion Floating-point Operations |
| FPS | Frames Per Second |
| MSE | Mean Square Error |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index Measurement |
| TPR | True Positive Rate |
| TNR | True Negative Rate |
| BCR | Balanced Classification Rate |
References
- Radiant Vision System. Available online: https://www.radiantvisionsystems.com/products (accessed on 19 July 2021).
- Guo, F.; Guan, S.-A. Research of the Machine Vision Based PCB Defect Inspection System. In Proceedings of the International Conference on Intelligence Science and Information Engineering, Washington, DC, USA, 20–21 August 2011; pp. 472–475. [Google Scholar]
- Koch, J.; Gritsch, A.; Reinhart, G. Process design for the management of changes in manufacturing: Toward a Manufacturing Change Management process. CIRP J. Manuf. Sci. Technol. 2016, 14, 10–19. [Google Scholar] [CrossRef]
- Anoop, K.P.; Kumar, S. A Review of PCB Defect Detection Using Image Processing. Intern. J. Eng. Innov. Technol. 2015, 4, 188–192. [Google Scholar]
- Park, J.-K.; Kwon, B.-K.; Park, J.-H.; Kang, D.-J. Machine learning-based imaging system for surface defect inspection. Int. J. Precis. Eng. Manuf. Technol. 2016, 3, 303–310. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections. Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates: Red Hook, NY, USA, 2016. [Google Scholar]
- Baldi, P. Autoencoders, Unsupervised Learning, and Deep Architectures; Guyon, I., Dror, G., Lemaire, V., Taylor, G., Silver, D., Eds.; PMLR: Bellevue, WA, USA, 2012; pp. 37–49. [Google Scholar]
- Srimani, P.K.; Prathiba, V. Adaptive Data Mining Approach for PCB Defect Detection and Classification. Indian J. Sci. Technol. 2016, 9. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Wei, P. A PCB Dataset for Defects Detection and Classification. arXiv 2019, arXiv:1901.08204. [Google Scholar]
- Kivinen, J.; Mannila, H. The power of sampling in knowledge discovery. In Proceedings of the Thirteenth ACM SIGACT-SIGMODSIGART Symposium on Principles of Database Systems, Minneapolis, MN, USA, 24–27 May 1994; Association for Computing Machinery: New York, NY, USA, 1994; pp. 77–85. [Google Scholar]
- Maragatham, G.; Roomi, S.M. A Review of Image Contrast Enhancement Methods and Techniques. Res. J. Appl. Sci. Eng. Technol. 2015, 9, 309–326. [Google Scholar] [CrossRef]
- Hambal, A.M.; Pei, Z. Image Noise Reduction and Filtering Techniques. Int. J. Sci. Res. 2017, 6, 2033–2038. [Google Scholar]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Editorial: Special Issue on Learning from Imbalanced Data Sets. SIGKDD Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Manning Publications: Shelter Island, NY, USA, 2017. [Google Scholar]
- Turchenko, V.; Chalmers, E.; Luczak, A. A Deep convolutional auto-encoder with pooling—Unpooling layers in caffe. Int. J. Comput. 2019, 8–31. [Google Scholar] [CrossRef]
- Theis, L.; Shi, W.; Cunningham, A.; Huszár, F. Lossy Image Compression with Compressive Autoencoders. arXiv 2017, arXiv:1703.00395. [Google Scholar]
- Choi, Y.; El-Khamy, M.; Lee, J. Variable Rate Deep Image Compression with a Conditional Autoencoder. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Ashfahani, A.; Pratama, M.; Lughofer, E.; Ong, Y.-S. DEVDAN: Deep evolving denoising autoencoder. Neurocomputing 2020, 390, 297–314. [Google Scholar] [CrossRef] [Green Version]
- Sun, M.; Wang, H.; Liu, P.; Huang, S.; Fan, P. A sparse stacked denoising autoencoder with optimized transfer learning applied to the fault diagnosis of rolling bearings. Measurement 2019, 146, 305–314. [Google Scholar] [CrossRef]
- Sakurada, M.; Yairi, T. Anomaly Detection Using Autoencoders with Nonlinear Dimensionality Reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, Australia, 2 December 2014. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep Autoencoding Gaussian Mixture Model for Unsupervised Anomaly Detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.V.D. Memorizing Normality to Detect Anomaly: Memory-Augmented Deep Autoencoder for Unsupervised Anomaly Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zavrak, S.; Iskefiyeli, M. Anomaly-Based Intrusion Detection from Network Flow Features Using Variational Autoencoder. IEEE Access 2020, 8, 108346–108358. [Google Scholar] [CrossRef]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011. [Google Scholar]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; pp. 92–101. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition; Springer: Thessaloniki, Greece, 2016; pp. 770–778. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Wu, W.-Y.; Wang, M.-J.J.; Liu, C.-M. Automated inspection of printed circuit boards through machine vision. Comput. Ind. 1996, 28, 103–111. [Google Scholar] [CrossRef]
- Shultz, T.R.; Fahlman, S.E.; Craw, S.; Andritsos, P.; Tsaparas, P.; Silva, R.; Drummond, C.; Lanzi, P.L.; Gama, J.; Wiegand, R.P.; et al. Confusion Matrix. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar]
- Devries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference PCB Name | Adjusted Size | Defect Type | |||||
|---|---|---|---|---|---|---|---|
| Missing Hole | Mouse Bite | Open Circuit | Short | Spur | Spurious Copper | ||
| 1 | 3034 × 1586 | 20 | 20 | 20 | 20 | 20 | 20 |
| 4 | 3056 × 2464 | 20 | 20 | 20 | 20 | 20 | 20 |
| 5 | 2544 × 2156 | 10 | 10 | 10 | 10 | 10 | 10 |
| 6 | 2868 × 2316 | 10 | 10 | 10 | 10 | 10 | 10 |
| 7 | 2904 × 1921 | 10 | 10 | 10 | 10 | 10 | 10 |
| 8 | 2759 × 2154 | 10 | 10 | 10 | 10 | 10 | 10 |
| 9 | 2775 × 2159 | 10 | 10 | 10 | 10 | 10 | 10 |
| 10 | 2240 × 2016 | 10 | 10 | 10 | 10 | 10 | 10 |
| 11 | 2282 × 2248 | 10 | 10 | 10 | 10 | 10 | 10 |
| 12 | 2529 × 2530 | 10 | 10 | 10 | 10 | 10 | 10 |
| Total image (total number of defects) | 115 (497) | 115 (492) | 116 (482) | 116 (491) | 115 (488) | 116 (503) | |
| 693 (2593) | |||||||
| Layer | Kernel | Output |
|---|---|---|
| Input | – | (400, 400, 3) |
| Conv1 | 64, (5,5) | (400, 400, 64) |
| MaxPooling1 | (2,2) | (200, 200, 64) |
| Conv2 | 64, (5,5) | (200, 200, 64) |
| MaxPooling2 | (2,2) | (100, 100, 64) |
| Conv3 | 128, (3,3) | (100, 100, 128) |
| MaxPooling3 | (2,2) | (50, 50, 64) |
| Conv4 | 128, (3,3) | (50, 50, 64) |
| MaxPooling4 | (2,2) | (25, 25, 128) |
| Conv5 | 128, (3,3) | (25, 25, 128) |
| UpSampling1 | (2,2) | (50, 50, 128) |
| Conv6 | 128, (3,3) | (50, 50, 128) |
| UpSampling2 | (2,2) | (100, 100, 128) |
| SkipConnection1 | – | UpSampling2 + Conv3 |
| Conv7 | 64, (5,5) | (100, 100, 64) |
| UpSampling3 | (2,2) | (200, 200, 64) |
| SkipConnection2 | – | UpSampling3 + Conv2 |
| Conv8 | 64, (5,5) | (200, 200, 64) |
| UpSampling4 | (2,2) | (400, 400, 64) |
| SkipConnection3 | – | UpSampling4 + Conv1 |
| Conv9 | 3, (3,3) | (400, 400, 3) |
| Actual Class | |||
|---|---|---|---|
| NG | OK | ||
| Predicted Class | NG | True Positive (TP) | False Positive (FP) |
| OK | False Negative (FN) | True Negative (TN) | |
| Hyperparameter | Value | ||||
|---|---|---|---|---|---|
| Total number of epochs | 300 | ||||
| Batch size | 128 | ||||
| Optimizer | Weight decay: 5 × 10−4 | ||||
| Momentum: 0.9 | |||||
| Learning rate (lr) | Epoch | 60 | 120 | 160 | 300 |
| Lr | 0.1 | 0.02 | 0.004 | 0.0008 | |
| Dataset Configuration | ||
|---|---|---|
| Total number of training data | 98,730 pairs of defect and non-defect images | |
| Total number of test data | 3900 | |
| 1900 normal images | 2000 defect images | |
| Models | Accuracy | TPR | TNR | Precision | F1 | BCR | SSIM |
|---|---|---|---|---|---|---|---|
| Convolutional autoencoder | 0.9508 | 0.9131 | 0.9865 | 0.9847 | 0.9475 | 0.9491 | 0.9510 |
| Skip-connected convolutional autoencoder | 0.9808 | 0.9773 | 0.9840 | 0.9830 | 0.9801 | 0.9806 | 0.9749 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Ko, J.; Choi, H.; Kim, H. Printed Circuit Board Defect Detection Using Deep Learning via A Skip-Connected Convolutional Autoencoder. Sensors 2021, 21, 4968. https://doi.org/10.3390/s21154968
Kim J, Ko J, Choi H, Kim H. Printed Circuit Board Defect Detection Using Deep Learning via A Skip-Connected Convolutional Autoencoder. Sensors. 2021; 21(15):4968. https://doi.org/10.3390/s21154968
Chicago/Turabian StyleKim, Jungsuk, Jungbeom Ko, Hojong Choi, and Hyunchul Kim. 2021. "Printed Circuit Board Defect Detection Using Deep Learning via A Skip-Connected Convolutional Autoencoder" Sensors 21, no. 15: 4968. https://doi.org/10.3390/s21154968
APA StyleKim, J., Ko, J., Choi, H., & Kim, H. (2021). Printed Circuit Board Defect Detection Using Deep Learning via A Skip-Connected Convolutional Autoencoder. Sensors, 21(15), 4968. https://doi.org/10.3390/s21154968