
Survey and Performance Analysis of Deep Learning Based Object Detection in Challenging Environments

 ,
,  ,
, 
 ,
,
Abstract
:1. Introduction
- 1.
- 2.
- 3.
Contributions
- 1.
- We present a unified framework that explains object detection in a challenging environment;
- 2.
- We give an overview of all the publicly available datasets that have been published to detect objects in challenging scenarios;
- 3.
- We summarize the advantages and limitations of the discussed methods in order to improve object detection in a challenging environment;
- 4.
- We benchmark current state-of-the-art generic object detection algorithms on the three well-known challenging datasets.
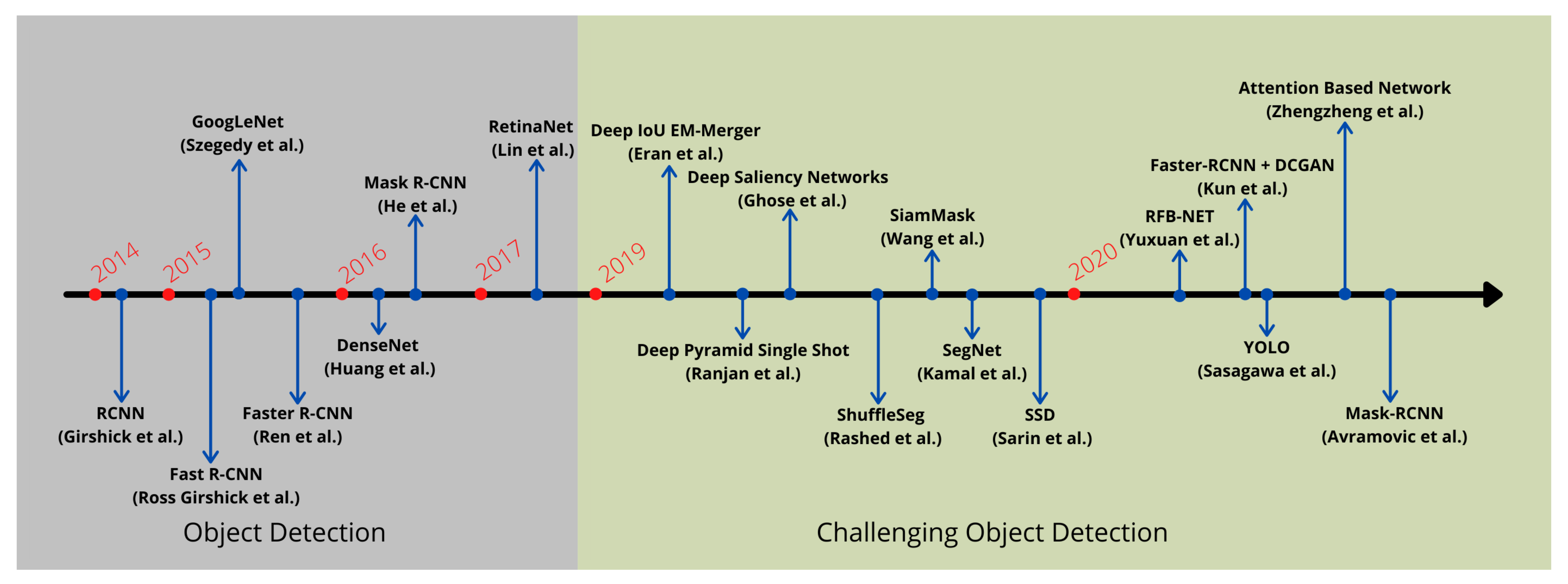
2. Related Surveys on Object Detection
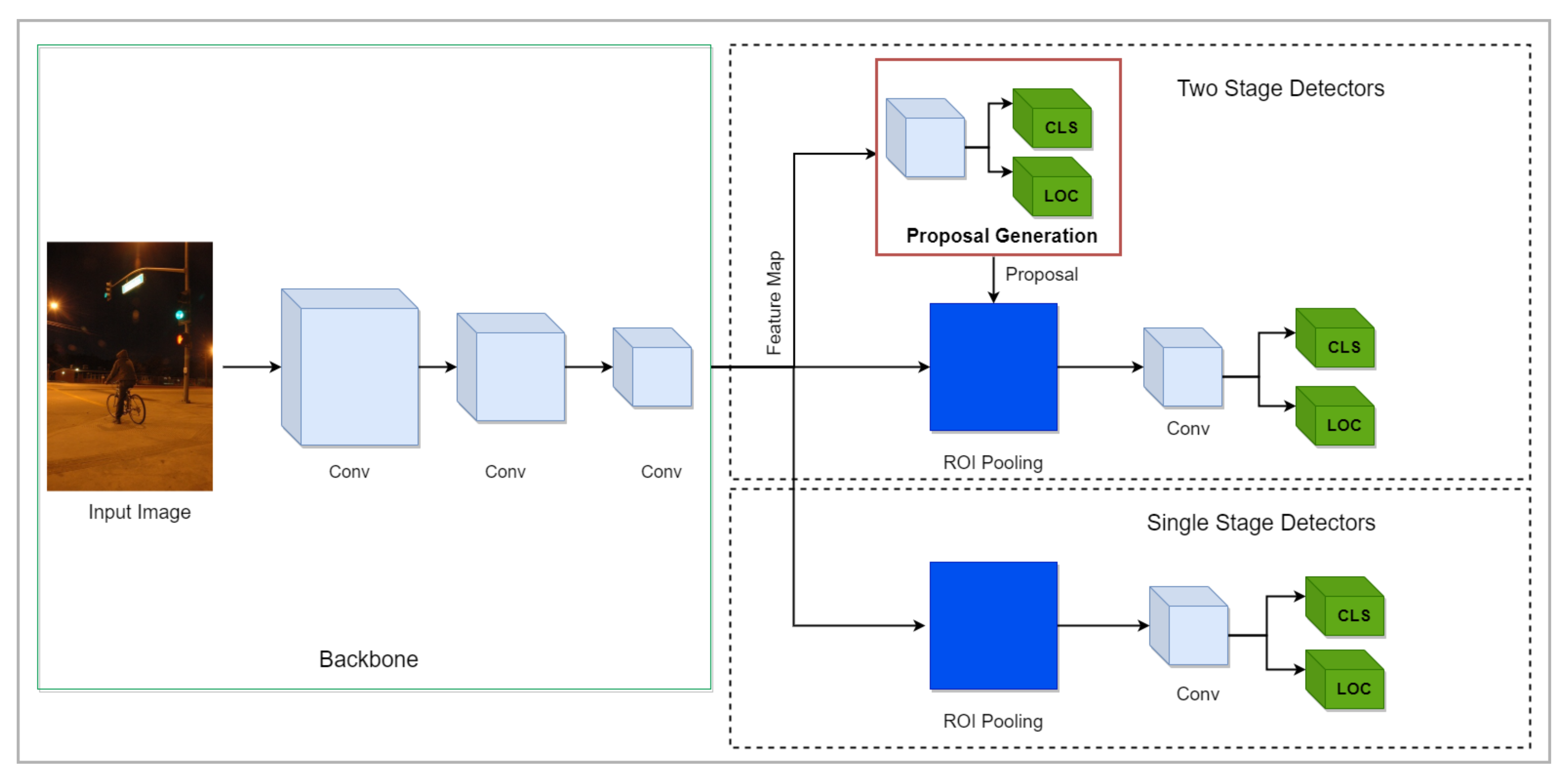
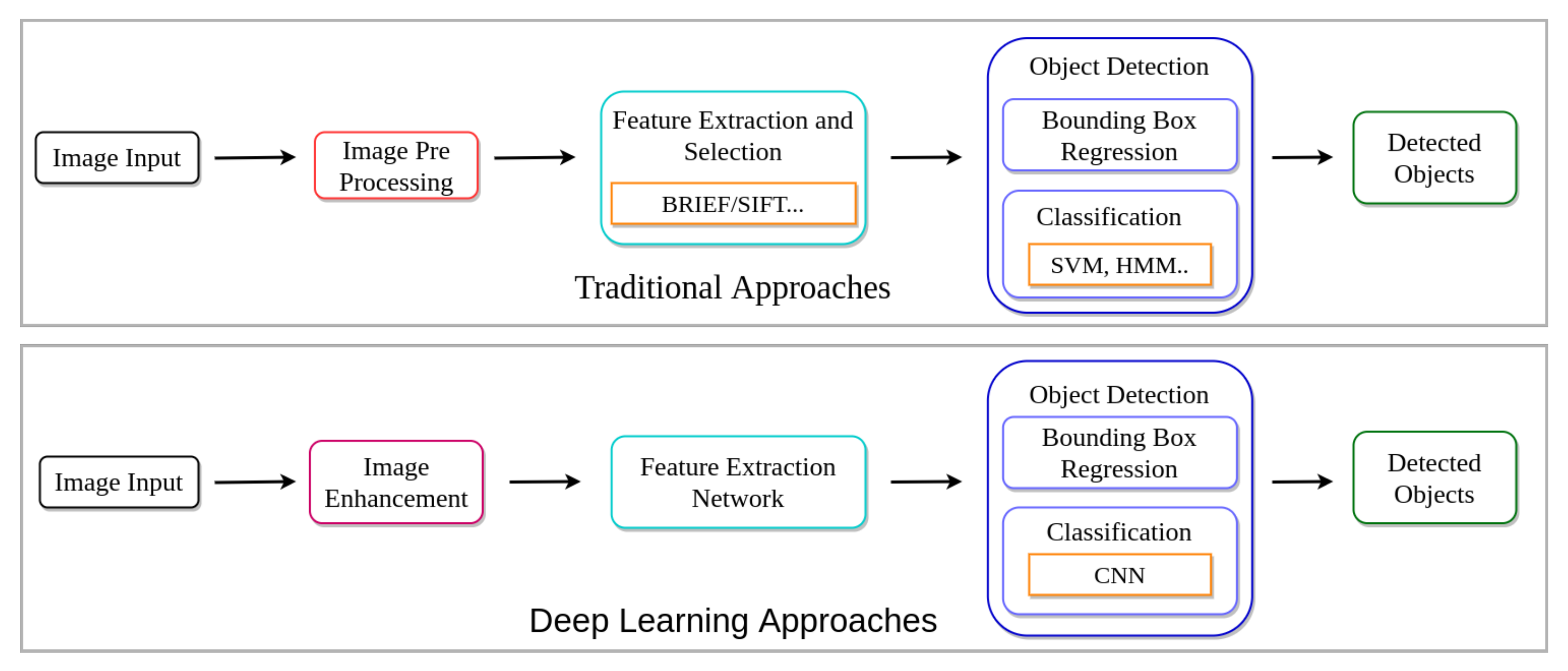
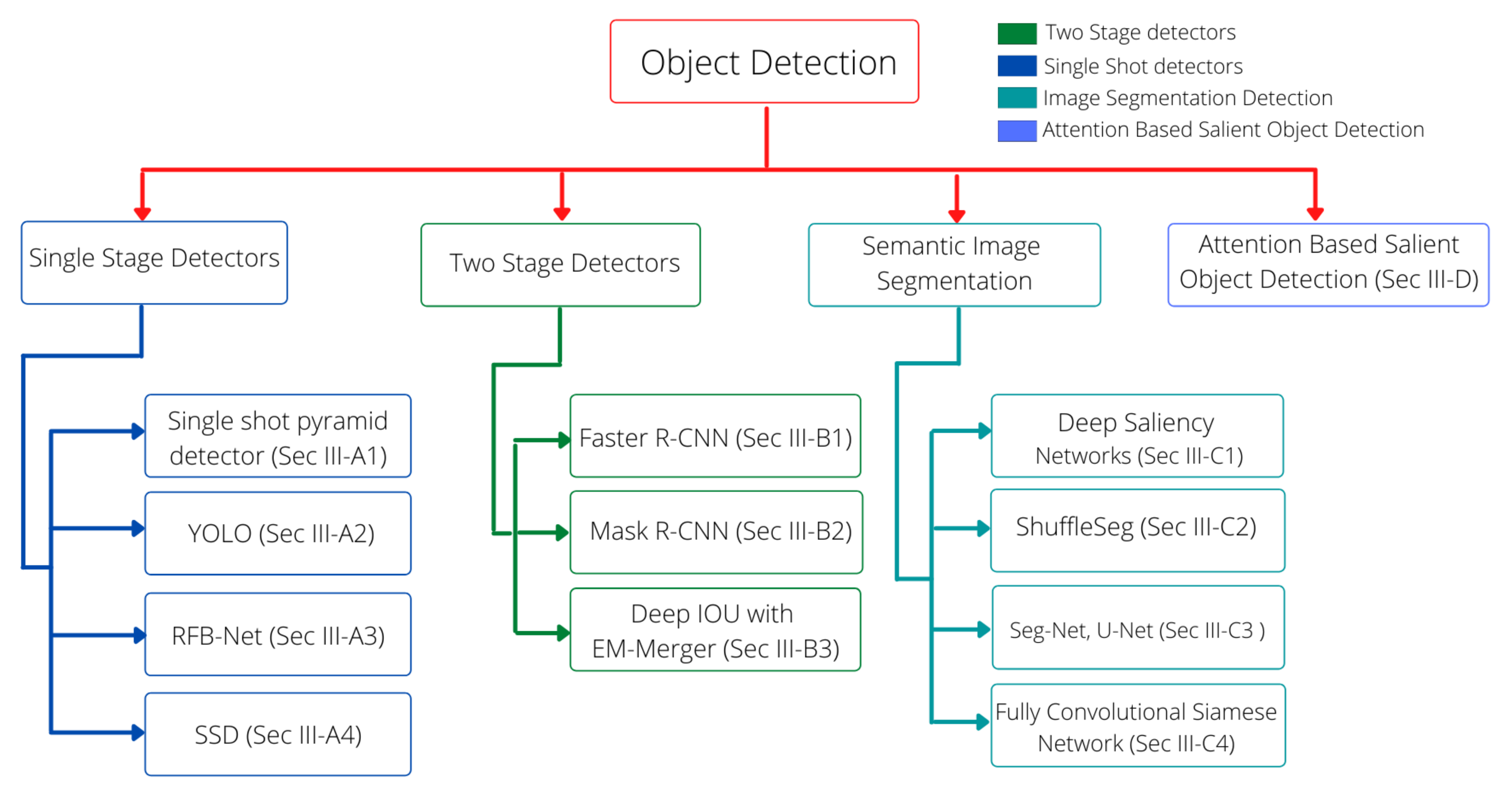
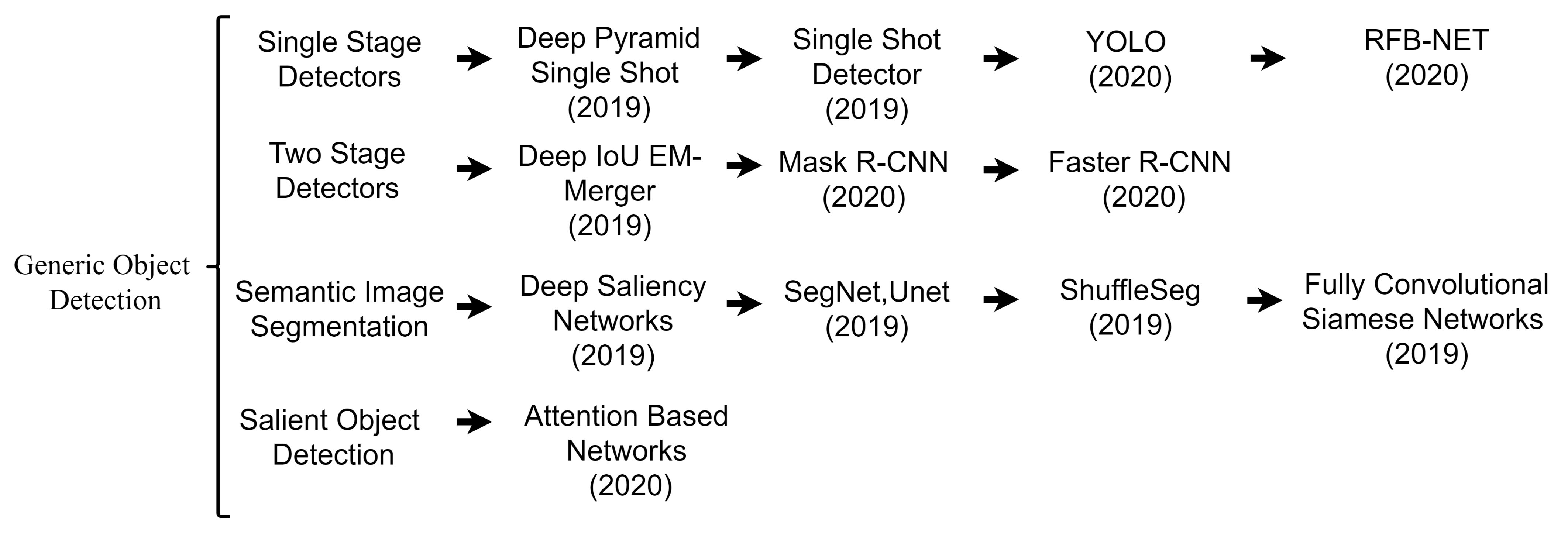
3. Methodologies
- 1.
- Find regions as object/no-object;
- 2.
- Classify the detected regions where objects exist.
3.1. One-Stage Detectors
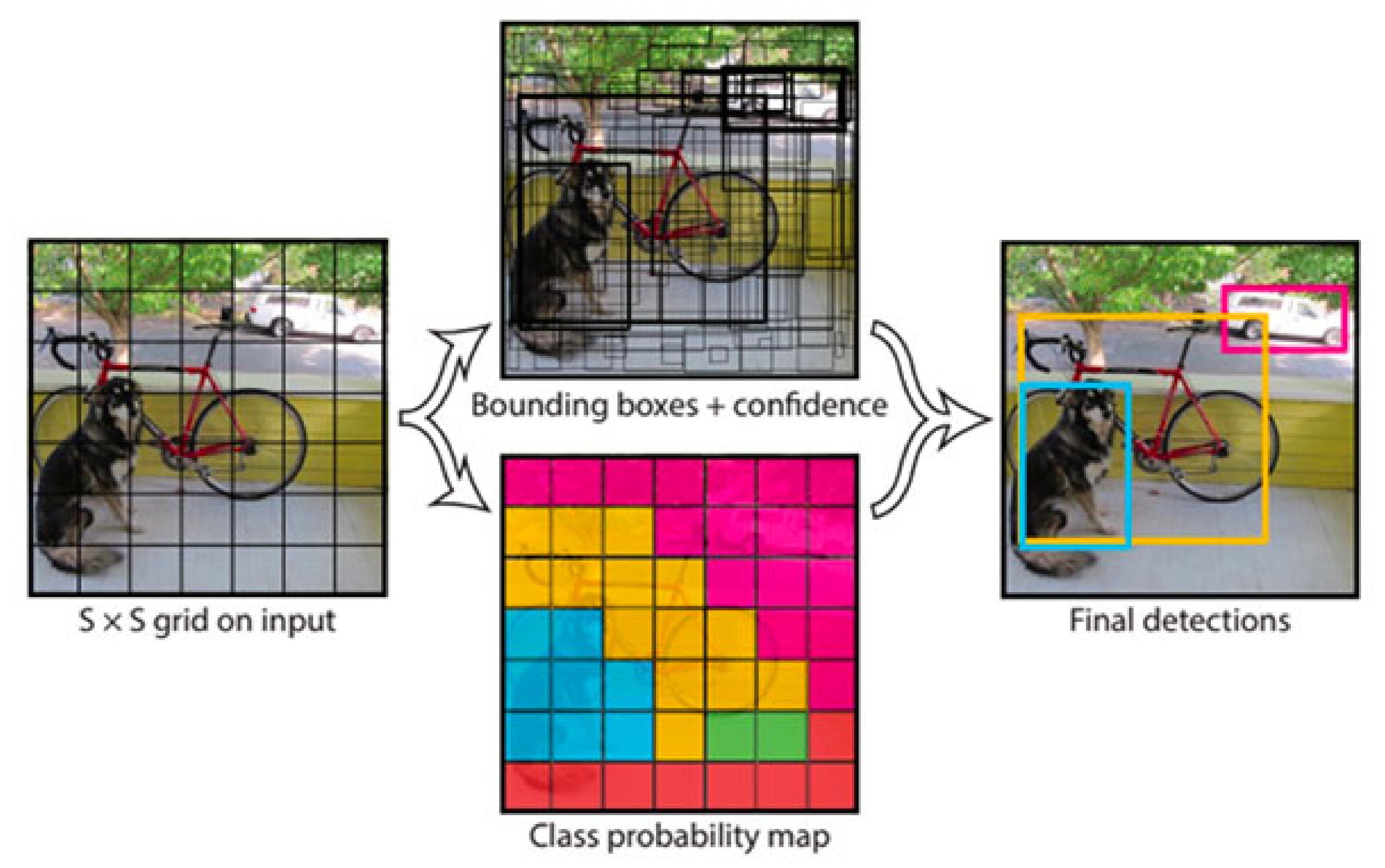
3.1.1. YOLO
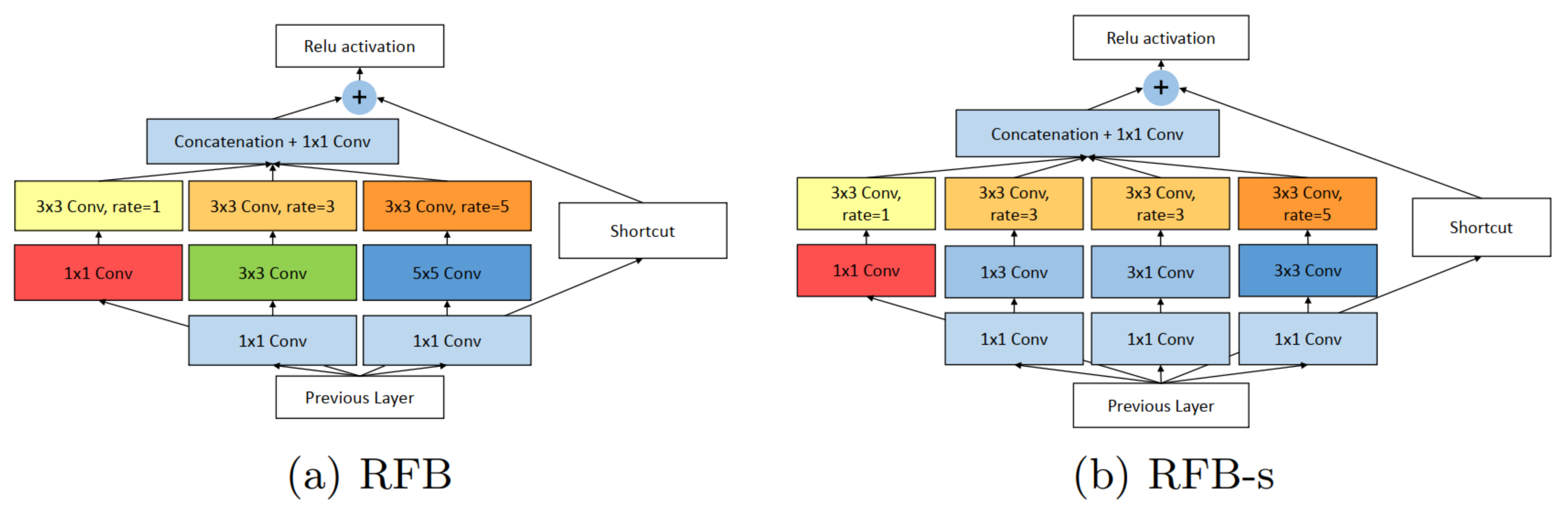
3.1.2. RFB-Net
3.1.3. SSD
Deep Pyramid Single Shot Face Detector
3.2. Two-Stage Detectors
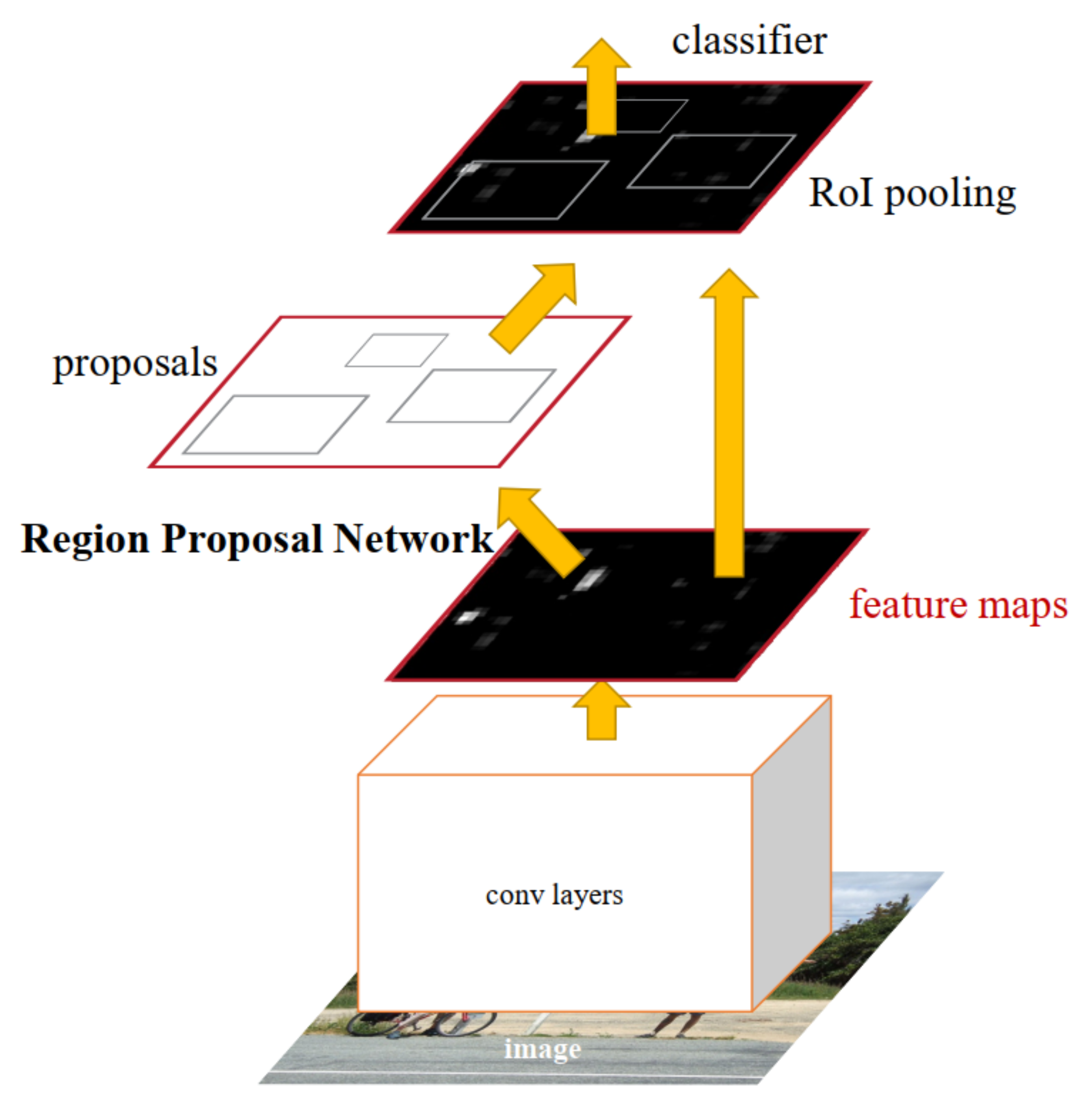
3.2.1. Faster R-CNN
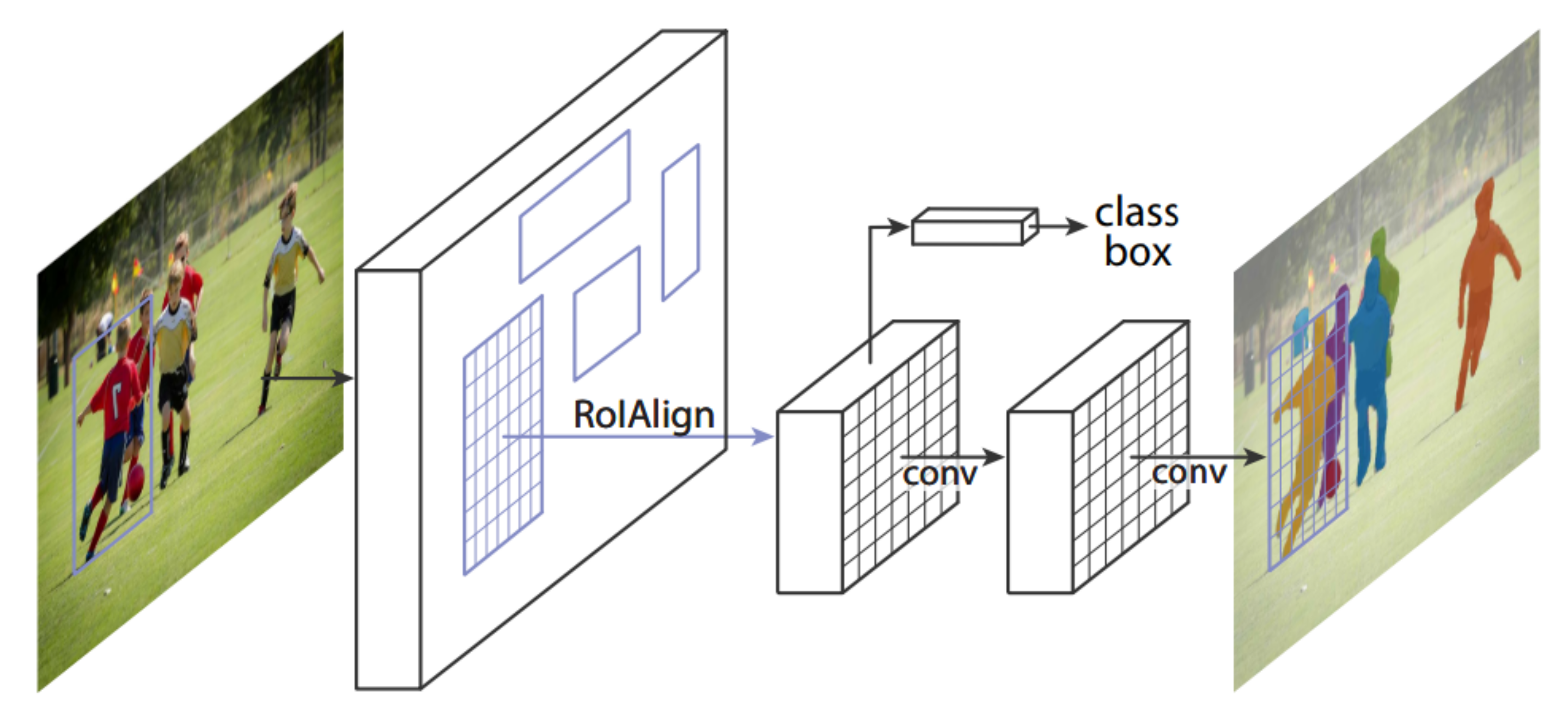
3.2.2. Mask R-CNN
3.2.3. Deep IOU with EM-Merger
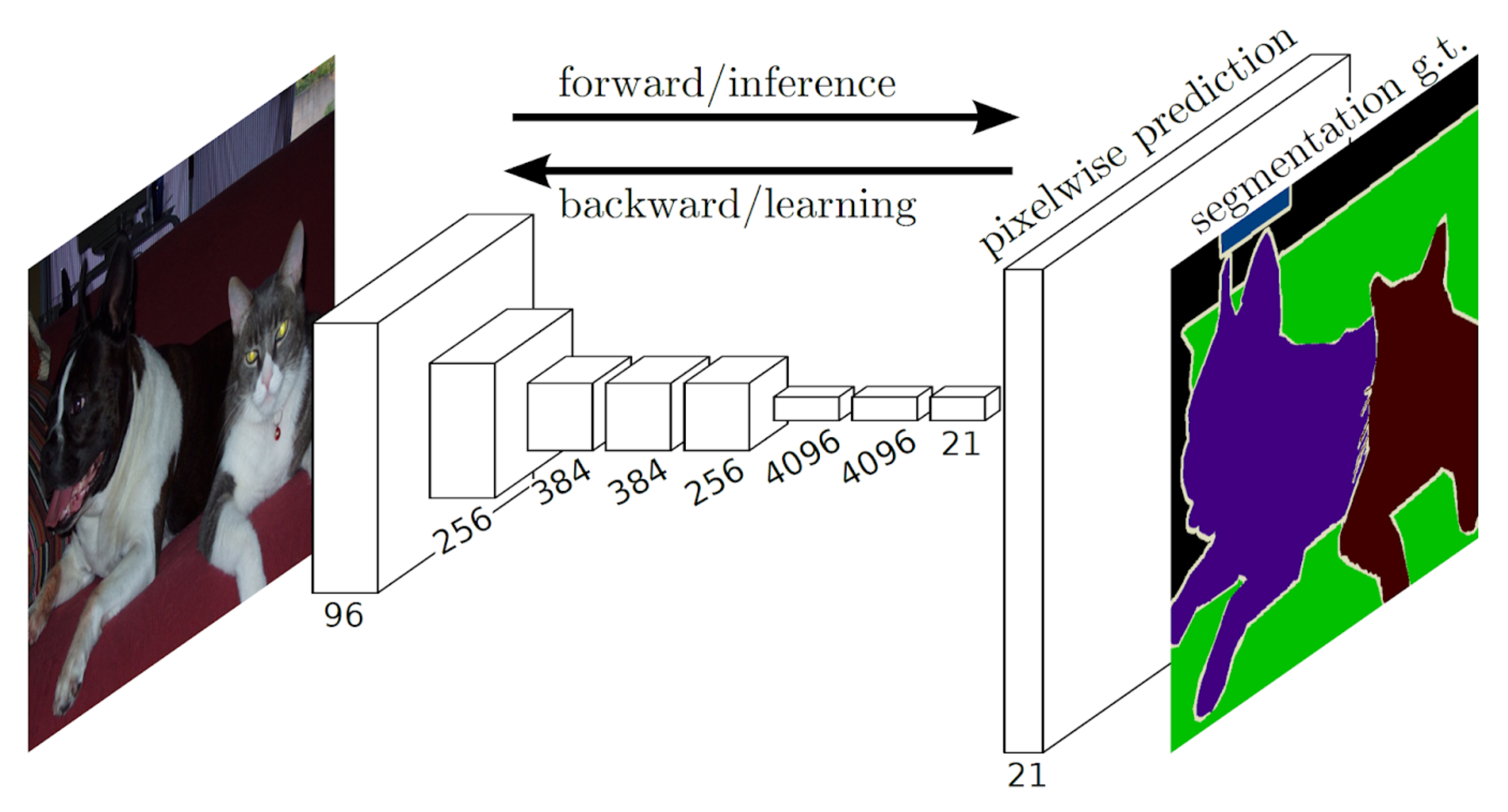
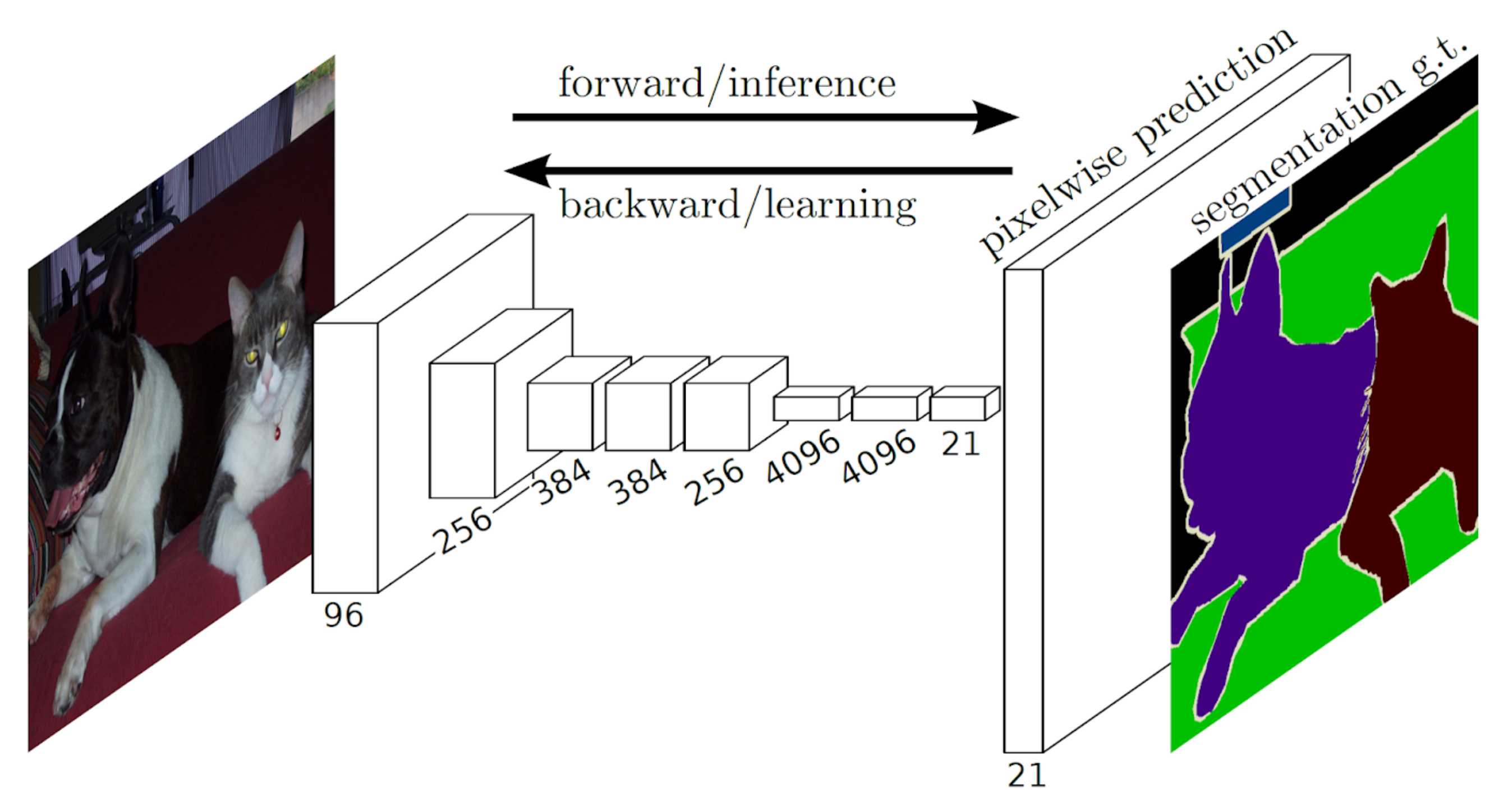
3.3. Semantic Image Segmentation
3.3.1. Deep Saliency Networks
3.3.2. ShuffleSeg
3.3.3. SegNet, U-Net
3.3.4. Fully Convolutional Siamese Networks
3.4. Attention-Based Salient Object Detection
4. Datasets
4.1. ExDARK
4.2. CURE-TSD
4.3. RESIDE
4.4. SKU-110K
4.5. UNIRI-TID
4.6. KAIST Multispectral Pedestrian Detection
4.7. DFG Traffic Sign Dataset
4.8. VT5000 Dataset
4.9. Wider Face
4.10. UFDD
4.11. See in the Dark
4.12. MS-COCO
4.13. VOT-2018
4.14. Kitti
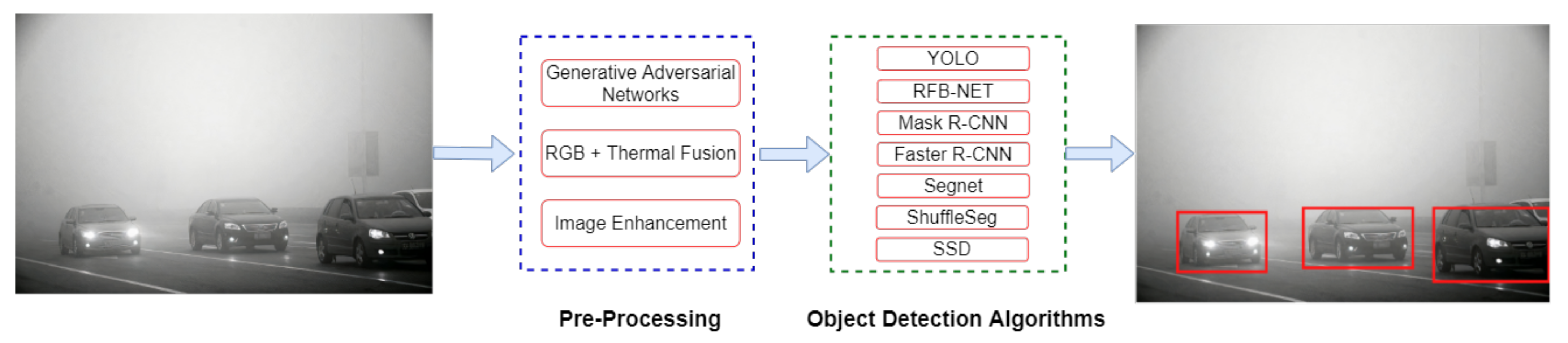
5. Experiments
6. Evaluation
6.1. Evaluation Criteria
6.1.1. Precision
6.1.2. Recall
6.1.3. F-Measure
6.1.4. Intersection Over Union
6.1.5. Average Precision (AP)
6.1.6. Mean Absolute Error (MAE)
6.1.7. Mean Average Precision
6.2. Evaluations for Object Detection in a Challenging Environment
6.3. Evaluation of Our Experiments
7. Open Challenges and Future Directions
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1July 2016; pp. 3150–3158. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 297–312. [Google Scholar]
- Alberti, C.; Ling, J.; Collins, M.; Reitter, D. Fusion of detected objects in text for visual question answering. arXiv 2019, arXiv:1908.05054. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; 2015; pp. 2048–2057, PMLR 37:2048-2057. [Google Scholar]
- Wu, Q.; Shen, C.; Wang, P.; Dick, A.; Van Den Hengel, A. Image captioning and visual question answering based on attributes and external knowledge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1367–1381. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, K.; Li, H.; Yan, J.; Zeng, X.; Yang, B.; Xiao, T.; Zhang, C.; Wang, Z.; Wang, R.; Wang, X.; et al. T-cnn: Tubelets with convolutional neural networks for object detection from videos. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2896–2907. [Google Scholar] [CrossRef] [Green Version]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-guided neural networks for efficient skeleton-based human action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 1112–1121. [Google Scholar]
- Vaswani, N.; Chowdhury, A.R.; Chellappa, R. Activity recognition using the dynamics of the configuration of interacting objects. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 2, p. II-633. [Google Scholar]
- Motwani, T.S.; Mooney, R.J. Improving Video Activity Recognition using Object Recognition and Text Mining; ECAI; Citeseer: Forest Grove, OR, USA, 2012; Volume 1, p. 2. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollar, P. Microsoft COCO: Common objects in context (2014). arXiv 2019, arXiv:1405.0312. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D. Cascade object detection with deformable part models. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2241–2248. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 17–19 June 2014; pp. 580–587. [Google Scholar]
- Alexe, B.; Deselaers, T.; Ferrari, V. Measuring the objectness of image windows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2189–2202. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Sminchisescu, C. CPMC: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1312–1328. [Google Scholar] [CrossRef]
- Rahtu, E.; Kannala, J.; Blaschko, M. Learning a category independent object detection cascade. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1052–1059. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 391–405. [Google Scholar]
- Kuo, W.; Hariharan, B.; Malik, J. Deepbox: Learning objectness with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 2479–2487. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. Available online: http://gitlinux.net/assets/SSD-Single-Shot-MultiBox-Detector.pdf (accessed on 21 July 2021).
- Liu, T.; Yuan, Z.; Sun, J.; Wang, J.; Zheng, N.; Tang, X.; Shum, H.Y. Learning to detect a salient object. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 353–367. [Google Scholar]
- Cheng, M.M.; Mitra, N.J.; Huang, X.; Torr, P.H.; Hu, S.M. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 569–582. [Google Scholar] [CrossRef] [Green Version]
- Ouyang, W.; Wang, X.; Zeng, X.; Qiu, S.; Luo, P.; Tian, Y.; Li, H.; Yang, S.; Wang, Z.; Loy, C.C.; et al. Deepid-net: Deformable deep convolutional neural networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2403–2412. [Google Scholar]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced deep-learning techniques for salient and category-specific object detection: A survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Lienhart, R.; Maydt, J. An extended set of haar-like features for rapid object detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 1, p. I-I. [Google Scholar]
- Agarwal, S.; Terrail, J.O.D.; Jurie, F. Recent advances in object detection in the age of deep convolutional neural networks. arXiv 2018, arXiv:1809.03193. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- Grauman, K.; Leibe, B. Visual object recognition. Synth. Lect. Artif. Intell. Mach. Learn. 2011, 5, 1–181. [Google Scholar] [CrossRef] [Green Version]
- Andreopoulos, A.; Tsotsos, J.K. 50 years of object recognition: Directions forward. Comput. Vis. Image Underst. 2013, 117, 827–891. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3d object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef] [Green Version]
- Bharati, P.; Pramanik, A. Deep Learning Techniques—R-CNN to Mask R-CNN: A Survey. In Computational Intelligence in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2020; pp. 657–668. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Lan, W.; Dang, J.; Wang, Y.; Wang, S. Pedestrian detection based on YOLO network model. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 1547–1551. [Google Scholar]
- Sasagawa, Y.; Nagahara, H. Yolo in the dark-domain adaptation method for merging multiple models. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 345–359. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; pp. 448–456, PMLR 37:448-456. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3291–3300. [Google Scholar]
- Krišto, M.; Ivasic-Kos, M.; Pobar, M. Thermal Object Detection in Difficult Weather Conditions Using YOLO. IEEE Access 2020, 8, 125459–125476. [Google Scholar] [CrossRef]
- Krišto, M.; Ivašić-Kos, M. Thermal imaging dataset for person detection. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 1126–1131. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Xiao, Y.; Jiang, A.; Ye, J.; Wang, M.W. Making of night vision: Object detection under low-illumination. IEEE Access 2020, 8, 123075–123086. [Google Scholar] [CrossRef]
- Sarin, M.; Chandrakar, S.; Patel, R. Face and Human Detection in Low Light for Surveillance Purposes. In Proceedings of the 2019 International Conference on Computational Intelligence and Knowledge Economy (ICCIKE), Dubai, UAE, 11–12 December 2019; pp. 614–620. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Nada, H.; Sindagi, V.A.; Zhang, H.; Patel, V.M. Pushing the limits of unconstrained face detection: A challenge dataset and baseline results. In Proceedings of the 2018 IEEE 9th International Conference on Bio metrics Theory, Applications and Systems (BTAS), Redondo Beach, CA, USA, 22–25 October 2018; pp. 1–10. [Google Scholar]
- Ranjan, R.; Bansal, A.; Zheng, J.; Xu, H.; Gleason, J.; Lu, B.; Nanduri, A.; Chen, J.C.; Castillo, C.D.; Chellappa, R. A fast and accurate system for face detection, identification, and verification. IEEE Trans. Biom. Behav. Identity Sci. 2019, 1, 82–96. [Google Scholar] [CrossRef] [Green Version]
- Avramović, A.; Sluga, D.; Tabernik, D.; Skočaj, D.; Stojnić, V.; Ilc, N. Neural-Network-Based Traffic Sign Detection and Recognition in High-Definition Images Using Region Focusing and Parallelization. IEEE Access 2020, 8, 189855–189868. [Google Scholar] [CrossRef]
- Goldman, E.; Herzig, R.; Eisenschtat, A.; Goldberger, J.; Hassner, T. Precise detection in densely packed scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5227–5236. [Google Scholar]
- Wang, K.; Liu, M.Z. Object Recognition at Night Scene Based on DCGAN and Faster R-CNN. IEEE Access 2020, 8, 193168–193182. [Google Scholar] [CrossRef]
- Ghose, D.; Desai, S.M.; Bhattacharya, S.; Chakraborty, D.; Fiterau, M.; Rahman, T. Pedestrian detection in thermal images using saliency maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Rashed, H.; Ramzy, M.; Vaquero, V.; El Sallab, A.; Sistu, G.; Yogamani, S. Fusemodnet: Real-time camera and lidar based moving object detection for robust low-light autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27 OctobeR–2 November 2019. [Google Scholar]
- Kamal, U.; Tonmoy, T.I.; Das, S.; Hasan, M.K. Automatic traffic sign detection and recognition using SegU-net and a modified tversky loss function with L1-constraint. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1467–1479. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H. Fast online object tracking and segmentation: A unifying approach. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1328–1338. [Google Scholar]
- Tu, Z.; Ma, Y.; Li, Z.; Li, C.; Xu, J.; Liu, Y. RGBT salient object detection: A large-scale dataset and benchmark. arXiv 2020, arXiv:2007.03262. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Reed, S.; Erhan, D.; Anguelov, D.; Ioffe, S. Scalable, high-quality object detection. arXiv 2014, arXiv:1412.1441. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5525–5533. [Google Scholar]
- Klare, B.F.; Klein, B.; Taborsky, E.; Blanton, A.; Cheney, J.; Allen, K.; Grother, P.; Mah, A.; Jain, A.K. Pushing the frontiers of unconstrained face detection and recognition: Iarpa janus benchmark a. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1931–1939. [Google Scholar]
- Whitelam, C.; Taborsky, E.; Blanton, A.; Maze, B.; Adams, J.; Miller, T.; Kalka, N.; Jain, A.K.; Duncan, J.A.; Allen, K.; et al. Iarpa janus benchmark-b face dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 90–98. [Google Scholar]
- Maze, B.; Adams, J.; Duncan, J.A.; Kalka, N.; Miller, T.; Otto, C.; Jain, A.K.; Niggel, W.T.; Anderson, J.; Cheney, J.; et al. Iarpa janus benchmark-c: Face dataset and protocol. In Proceedings of the 2018 International Conference on Biometrics (ICB), Queensland, Australia, 20–23 February 2018; pp. 158–165. [Google Scholar]
- Fan, Q.; Brown, L.; Smith, J. A closer look at Faster R-CNN for vehicle detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenberg, Sweden, 19–22 June 2016; pp. 124–129. [Google Scholar]
- He, Z.; Zhang, L. Multi-adversarial faster-rcnn for unrestricted object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6668–6677. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Kopelowitz, E.; Engelhard, G. Lung Nodules Detection and Segmentation Using 3D Mask-RCNN. arXiv 2019, arXiv:1907.07676. [Google Scholar]
- Zhang, Q.; Chang, X.; Bian, S.B. Vehicle-damage-detection segmentation algorithm based on improved mask RCNN. IEEE Access 2020, 8, 6997–7004. [Google Scholar] [CrossRef]
- Tabernik, D.; Skočaj, D. Deep learning for large-scale traffic-sign detection and recognition. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1427–1440. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liu, N.; Han, J.; Yang, M.H. Picanet: Learning pixel-wise contextual attention for saliency detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3089–3098. [Google Scholar]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; AAAI Press: Menlo Park, CA, USA, 2018; pp. 684–690. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 18–20 June 2012; pp. 3354–3361, PMLR 116:171-183. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Salehi, S.S.M.; Erdogmus, D.; Gholipour, A. Tversky loss function for image segmentation using 3D fully convolutional deep networks. In International Workshop on Machine Learning in Medical Imaging; Springer: Berlin/Heidelberg, Germany, 2017; pp. 379–387. [Google Scholar]
- Temel, D.; Chen, M.H.; AlRegib, G. Traffic sign detection under challenging conditions: A deeper look into performance variations and spectral characteristics. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3663–3673. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Čehovin Zajc, L.; Vojir, T.; Bhat, G.; Lukezic, A.; Eldesokey, A.; et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the exclusively dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jaeger, P.F.; Kohl, S.A.; Bickelhaupt, S.; Isensee, F.; Kuder, T.A.; Schlemmer, H.P.; Maier-Hein, K.H. Retina U-Net: Embarrassingly simple exploitation of segmentation supervision for medical object detection. In Proceedings of the Machine Learning for Health NeurIPS Workshop, Durham, NC, USA, 7–8 August 2020; pp. 171–183. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Zhang, Z. Improved adam optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Blaschko, M.B.; Lampert, C.H. Learning to localize objects with structured output regression. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 2–15. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Nidadavolu, P.S.; Villalba, J.; Dehak, N. Cycle-gans for domain adaptation of acoustic features for speaker recognition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6206–6210. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Methods | Advantages | Limitations |
|---|---|---|---|
| Yuxan et al. [57] | Images are transformed and then fed into the RFB-Net (Section 3.1.2). | Context information fusion allows detection of object in low-light. | Relies on prior information about type of object, shape etc for detecting them in night-time. |
| Mate et al. [54] | Thermal images incorporated with YOLO (Section 3.1.1). | Thermal images give better information then RGB images in difficult conditions. | Fails at capturing from bird’s-eye view. Further, thermal images are not useful in environments where background and object temperature is same. |
| Ranjan et al. [61] | Single shot deep pyramid face detector (DPSSD). | Extract rich contextual information and multiscale features with help of pooling layers. | Requires a fixed input size. |
| Sasagawa et al. [48] | Fusion of pre-trained models using Glue layer and information distillation (Section 3.1.1). | Domain joining with help of glue layer reduces in computation and provides more information for models to learn from different domains. | Relies on prior domain knowledge. |
| Sarin et al. [58] | Single shot human and face detector (Section 3.1.3). | Simple and effective approach. | Fails in low light and gets fooled by human look alike pictures. |
| Avramovic et al. [62] | Region of interest(ROI) integration with Mask-RCNN and YOLO (Section 3.2.2). | Only choose regions of interest where objects of interest can occur instead of applying object detection to whole image. | Relies on prior knowledge of where objects can show. |
| Eran et al. [63] | Modification of CNN with Soft-IOU layer and custom EM-Merger layer. | Reduces overlapping detections (Section 3.2.3). | Treats overlapping predictions as clustering problem. Not very real run time. |
| Kun et al. [64] | Generative adversarial network with Faster R-CNN (Section 3.2.1). | Networks learns both day and night-time features. | Relies on prior information of converting night-time images to day time. |
| Ghose et al. [65] | Fusion of thermal images and their saliency maps using deep saliency networks (Section 3.3.1). | Provides rich contextual and depth information. | Relying on thermal images causes poor performance in day time or similar conditions. |
| Rashed et al. [66] | Fusion of RGB images with LiDAR sensors information with encoder–decoder architecture (Section 3.3.2). | Fusion of RGB, rgbFLow and lidarFlow provides greater information. | LiDAR sensors data and rgbFlow data need to be merged. There are multiple methods of fusion. |
| Kamal et al. [67] | Combination of SegNet and U-Net to detect traffic signs (Section 3.3.3). | Less computation cost as four corners of image are cropped and merged together before passing through network | Relies on prior information regarding where objects are most likely to occur. Fails when object location changes. |
| Wang et al. [68] | Fully convolutional Siamese networks with modified binary segmentation task (Section 3.3.4). | Pre-frame binary segmentation mask is used for low-level object representation instead of relying on feature extractor backbone. | Relies on prior information while generating binary segmentation mask. Fails when faced with motion blur and non-object pattern. |
| Zhengzheng et al. [69] | Two Stream convolutional neural network with attention mechanism (Section 3.4). | Fusion of rgb and thermal image to generate features and noise reduction with convolutional block attention module. A new dataset for benchmarking. | Thermal images are not efficient for every environment use. |
| Literature | Year | Dataset | IOU | mAP | AP | F-Measure | Highlights | FPS |
|---|---|---|---|---|---|---|---|---|
| Eran et al. [63] | 2019 | SKU-110K | 0.50:0.95 | - | 0.49 | - | Deep IoU with EM-Merger (Section 3.2.3) | 0.5 |
| Yuxuan et al. [57] | 2020 | ExDark | 0.50:0.95 | - | 0.34 | - | RFB-Net (Section 3.1.2) | - |
| Zhengzheng et al. [69] | 2020 | VT5000 | - | - | - | 0.81 | Attention-based SOD (Section 3.4) | - |
| Mate et al. [54] | 2020 | KAIST | 0.50:0.95 | 0.35 | - | 0.36 | YOLO (Section 3.1.1) | - |
| Ghose et al. [65] | 2019 | KAIST | 0.50:0.95 | 0.68 | - | - | Deep Saliency Networks (Section 3.3.1 ) | - |
| Avramovic et al. [62] | 2020 | DFG | 0.50 | 0.94 | - | - | Mask R-CNN (Section 3.2.2) | 2 |
| Sasagawa et al. [48] | 2020 | SID | - | 0.55 | - | - | YOLO (Section 3.1.1) | - |
| Rashed et al. [66] | 2019 | KITTI | 0.75 | - | - | - | ShuffleSeg Segmentation Network (Section 3.3.2) | 25 |
| Wang et al. [68] | 2019 | VOT-2018 | 0.50 | 0.90 | - | - | FC Siamese Networks (Section 3.3.4) | 55 |
| Kun et al. [64] | 2019 | Night-Dataset | - | 0.82 | - | - | GAN + Faster R-CNN (Section 3.2.1) | 3.22 |
| Kamal et al. [67] | 2019 | CURE-TSD | 0.50:0.95 | - | 0.94 | - | SegNet + U-Net (Section 3.3.3) | - |
| Literature | Year | Dataset | Evaluation Metric | Score | Highlights | FPS |
|---|---|---|---|---|---|---|
| Ranjan et al. [61] | 2019 | WIDER Face | True Accept Rate [61] | 91.4% | Single Shot deep pyramid Face Detector | - |
| Sarin et al. [58] | 2019 | KAIST | True Positive Rate [58] | 92.80% | Single Shot Human and Face Detector (Section 3.1.3) | - |
| Our Models | ExDark | CURE-TSD | RESIDE | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | AP50 | APs | APm | APl | FPS | AP | AP50 | APs | APm | APl | FPS | AP | AP50 | APs | APm | APl | FPS | |
| MR-CNN | 0.54 | 0.84 | 0.22 | 0.46 | 0.59 | 8 | 0.20 | 0.35 | 0.2 | 0.17 | 0.37 | 5 | 0.51 | 0.79 | 0.4 | 0.11 | 0.57 | 8 |
| FR-CNN | 0.53 | 0.82 | 0.22 | 0.46 | 0.58 | 13 | 0.25 | 0.43 | 0.03 | 0.14 | 0.41 | 13 | 0.49 | 0.78 | 0.07 | 0.70 | 0.56 | 12 |
| Yolo V3 | 0.67 | 0.93 | 0.5 | 0.61 | 0.71 | 51 | 0.16 | 0.32 | 0.05 | 0.03 | 0.26 | 50 | 0.37 | 0.78 | 0.07 | 0.87 | 0.56 | 50 |
| Retina-Net | 0.36 | 0.67 | 0.12 | 0.30 | 0.52 | 11 | 0.14 | 0.25 | 0.12 | 0.19 | 0.35 | 12 | 0.48 | 0.75 | 0.1 | 0.07 | 0.55 | 11 |
| CMR-CNN | 0.49 | 0.78 | 0.27 | 0.37 | 0.55 | 10 | 0.28 | 0.38 | 0.06 | 0.23 | 0.34 | 11 | 0.50 | 0.76 | 0.06 | 0.12 | 0.56 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, M.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Survey and Performance Analysis of Deep Learning Based Object Detection in Challenging Environments. Sensors 2021, 21, 5116. https://doi.org/10.3390/s21155116
Ahmed M, Hashmi KA, Pagani A, Liwicki M, Stricker D, Afzal MZ. Survey and Performance Analysis of Deep Learning Based Object Detection in Challenging Environments. Sensors. 2021; 21(15):5116. https://doi.org/10.3390/s21155116
Chicago/Turabian StyleAhmed, Muhammad, Khurram Azeem Hashmi, Alain Pagani, Marcus Liwicki, Didier Stricker, and Muhammad Zeshan Afzal. 2021. "Survey and Performance Analysis of Deep Learning Based Object Detection in Challenging Environments" Sensors 21, no. 15: 5116. https://doi.org/10.3390/s21155116