1. Introduction
Construction sites usually consist of various elements such as personnel, machinery, materials, method, and environment. At the same time, construction sites are also characterized by multiple work types, simultaneous operation of various large-scale pieces of machinery and complex construction environments. Any problem in any links mentioned above may lead to hidden construction quality problems and threaten structural safety and personal safety. Therefore, it is necessary to comprehensively supervise construction sites’ condition in real-time [
1]. Work productivity is an essential factor in engineering construction, which directly affects each process’ completion time and quality. However, limited by human resources and time costs, most construction parties only control the project’s progress at a macro level. They do not supervise and record the work productivity of each process in detail.
In the field of engineering construction, most traditional monitoring methods are based on manual monitoring. However, manual supervision often fails to cover every aspect, preventing complete and timely notification of hazardous conditions, irresponsible and irregular worker behavior, sub-standard work quality, and inefficient task execution at construction sites. Therefore, more supervisors are needed, which increases management costs. As a result, many advanced technologies have been introduced into engineering construction, such as the application of acceleration sensors for structural health monitoring [
2,
3,
4] and workers’ activity recognition [
5,
6,
7,
8]. However, contact sensors may cause some inconvenience to construction when performing practical applications in engineering. Therefore, an efficient way is to use a non-contact monitoring sensor with high accuracy using video and image signals. In recent years, artificial intelligence and computer vision have accelerated, showing new features such as deep learning, cross-border integration, human–machine collaboration, the openness of group intelligence, and autonomous control [
9]. Related deep learning-based monitoring methods have been applied to medical diagnosis [
10,
11,
12], food inspection [
13,
14,
15], vehicle identification [
16,
17,
18], and structural health monitoring [
19,
20,
21,
22], providing the possibility to solve problems related to engineering construction.
The convolutional neural network (CNN) is the most common deep learning network, which originated from the handwritten numbers recognition problem proposed by Lecun in the 1990s [
23]. By optimizing the configuration of convolution and pooling layers, many CNNs have been developed, including AlexNet [
24], ZFNet [
25], VGGNet [
26], GoogleNet [
27], and ResNet [
28]. An effective way to improve CNNs is to increase the number of layers. In this way, the approximate structure of the objective function can be obtained using the increased nonlinearity, and better features can be obtained.
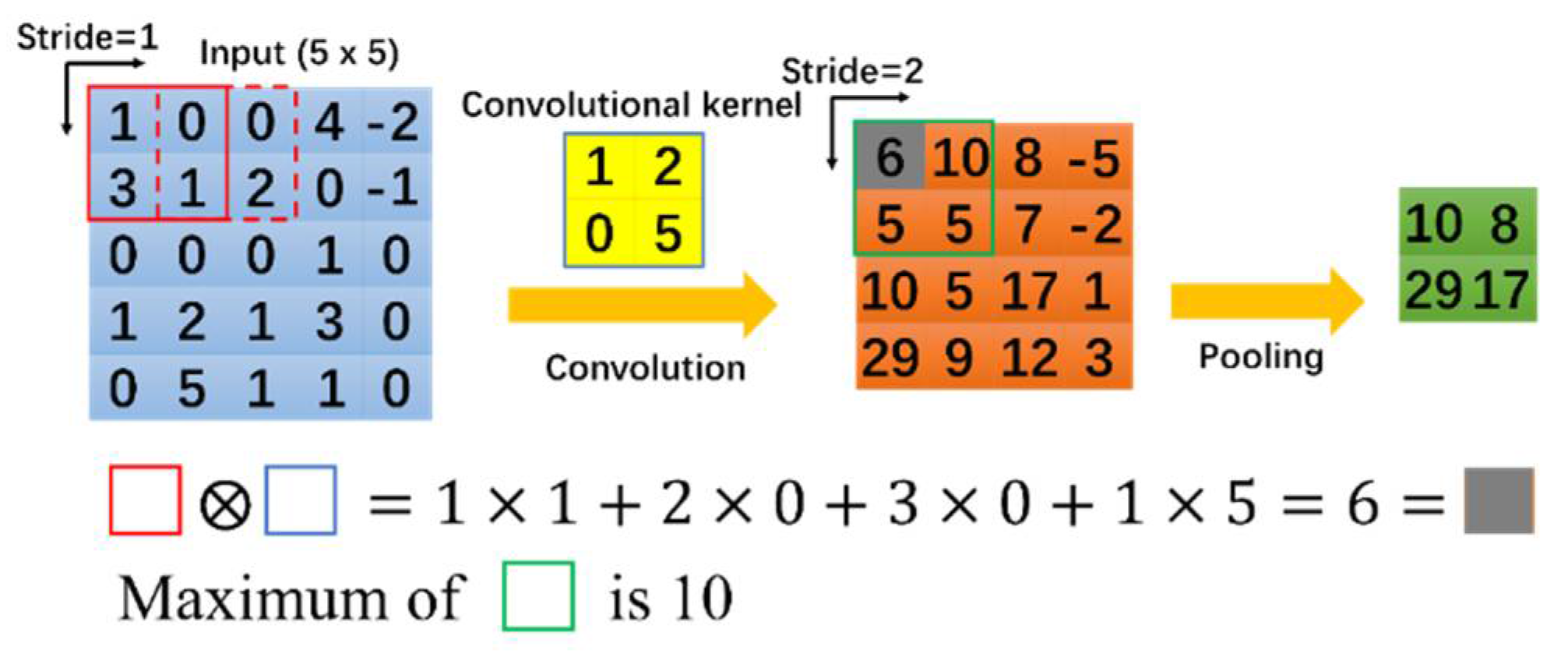
Figure 1 illustrates the operation principle of convolution and pooling layers in a CNN. Several object detection methods based on CNNs that can be applied to different scenes have been developed. Currently, there are various object detection algorithms, including CenterNet [
29] and Faster R-CNN [
30], such as Mask R-CNN [
31] and FCN [
32] for object segmentation, and YOLO [
33,
34,
35,
36], SSD [
37] and MobileNet [
38,
39] for fast detection of mobile devices.
The urgent need to solve practical problems in engineering construction and the growing maturity of deep learning technology have contributed to the rapid development of computer vision technology in engineering construction in recent years. A large amount of literature has focused on this issue.
The first is construction individual-related issues, which receive more attention by recognizing workers’ activities and usage of personal protective equipment (PPE). In activities recognition: Luo and Li et al. [
40,
41,
42] used various computer vision algorithms for construction worker activity recognition; Cai et al. [
43] and Liu et al. [
44] also carried out computer vision-based approaches for construction activities’ recognition. Cai used a two-step LSTM (long short-term memory network), while Liu combined computer vision and natural language processing methods; Han et al. [
45], Yu et al. [
46] and Yang et al. [
47] extracted workers’ joint coordinate to recognize the activity and judge the safety status. In the aspect of PPE’s usage: Park et al. [
48], Fang et al. [
49], and Wu et al. [
50] introduced different computer vision-based methods for hardhat detection; Fang et al. [
51] and Tang et al. [
52] achieved PPE usage detection not limited to hardhats.
The second is material-related issues, Zhang and Zhao et al. [
53,
54] presented a bolt looseness detection method based on MobileNet. Cha et al. [
55,
56,
57,
58] used deep learning technology based on convolutional neural networks to complete the identification and location of surface cracks in concrete structures, the volume measurement of surface corrosion on steel structures, and the volume measurement of concrete spalling damage. Concrete surface defect identification is also an issue that has been studied frequently in recent years, and representative ones are Xu et al. [
59], G Li et al. [
60], S Li et al. [
61], Miao et al. [
62] and others. However, most objects covered in the literature mentioned above are materials of existing built structures, which are not strictly speaking construction materials. These studies are more focused on damage detection of building structures. In the aspect of construction materials, Li et al. [
63] proposed a YOLOv3-based method for counting rebars. He et al. [
64] introduced an object detection framework called Classification Priority Network for defect detection of hot-rolled steels. Zhou et al. [
65] described an approach to analyze concrete pore structure based on deep learning.
The third is machinery-related issues, Kim et al. [
66] used unmanned aerial vehicles and monitored mobile machinery devices on a construction site remotely based on the YOLOv3 algorithm. Roberts et al. [
67] combined unmanned aerial vehicles and image recognition technology to track a crane on a construction site and estimated the three-dimensional posture. Slaton et al. [
68] introduced a method to recognize activities of roller compactor and activator by using a convolutional recurrent network. Yang et al. [
69] proposed a video monitoring method to evaluate the working state of a tower crane. Yang et al. [
70] successfully identified the safe distance between the hook and the worker using a monitoring camera installed on a tower crane.
These studies have contributed to taking a significant step forward in introducing computer vision technologies to construction engineering. However, there are still some limitations:
In the case of individuals and machinery, most extant computer vision-based approaches focus only on safety monitoring and activity recognition. No literature has been found to use computer vision to analyze their work productivity in some dynamic processes.
In terms of material, no studies have focused on the changes in materials during dynamic construction, and no studies have connected them to individual work and work productivity.
Although we have not found studies addressing work productivity evaluation, the large number of successful applications of deep learning and computer vision in engineering construction illustrate their potential to assist in filling this research gap in work productivity evaluation.
When evaluating work productivity, it is necessary to know the time consumed and the number of workers involved in the task, and it will take much time to use manual methods to make statistics. To address the above issues, the authors select construction processes of assembling column reinforcement (ACR) and assembling beam reinforcement (ABR) as research cases and propose a new computer vision-based method for work productivity evaluation. Firstly, we train a detector that can accurately distinguish various assembling reinforcement-related entities using the video images collected from on-site surveillance cameras. An anchor-free center point estimation network (CenterNet) is adopted, which can have a good detection speed without loss of accuracy. Secondly, we determine the number of workers who participated in the ACR\ABR task in every moment according to the position relationship between the detected work object and the detected workers to establish a connection between the workers and construction materials. Finally, we record the change of coordinates of the work object in the video and evaluate the work productivity by combining the time consumed and the number of participants. In this article, computer vision technology is used to realize construction activity recognition of ACR\ABR work, and the number of workers participating in the task can be judged. Additionally, using the results output by CenterNet, the productivity evaluation of the ACR\ABR process is realized. Final inspection documents, tables, and work productivity images can be used for project managers to view the work details of this process more intuitively and quickly. The rest of this paper is organized as follows.
Section 2 describes the proposed method in detail.
Section 3 describes the establishment of the CenterNet model.
Section 4 reports the evaluation tests based on construction video clips.
Section 5 is the comparison.
Section 6 and
Section 7 outline the discussion of the results and conclusions, respectively.
6. Discussion
In the field of engineering construction, construction productivity has not received much attention for a long time. Generally, as long as the tasks that should be carried out are completed by the specified deadline, most construction companies do not add the cost of monitoring each process’ speed. Noting the potential of computer vision technology for applications in engineering construction, the authors propose a computer vision-based approach for the productivity evaluation of assembling reinforcement processes. This paper contributes to engineering construction in the following aspects:
Firstly, advanced deep learning technology is employed to detect the frequency observed five classes of objects in ABR\ACR images. To achieve this plan, the authors collect and annotate the dataset to train the CenterNet model and evaluate the performance through the test set. It is found that the CenterNet-based model presents satisfactory mAP and detection speed.
Secondly, based on the detected ABR\ACR-related objects, a connection between the worker and construction object is established. The ABR\ACR task can be recognized through the position relationship between the worker and the construction object, so as to obtain the number of workers who participate in the process (N). The time (T) to perform the task can also be obtained through the recognized materials changing.
Thirdly, with N and T, productivity can be evaluated. The results of this paper validate the feasibility of computer vision-based methods in evaluating work productivity. With this paper’s results, managers can check the work productivity in detail, determine which workers are performing inefficient work, and then allocate labor resources more reasonably to promote and improve the complete quality of the whole project, forming a virtuous cycle. With the refinement of the proposed method and the expansion of its application, the computer vision-based approach will make it possible to perform rapid productivity evaluation for each process in construction.
The study in this paper contains some limitations that need to be further improved in future work. First of all, error analysis: the results of this paper have some errors, and most of these errors are caused by workers or construction objects being obscured. It is a common problem faced by most current computer vision-based methods. When a worker is not completely obscured, it is still possible for him/her to be recognized, for example, at some moments when the worker only shows half of his/her upper body, but it can still be detected. However, if the worker is completely obscured, it will lead to an error in the judgment of
N. When the work object is obscured, it will affect the results of
L and
H, and thus fluctuate in the curve shown in
Figure 13. In the future, we can consider adding several cameras in a process scene to expand the dataset, to try to reduce errors from multi-view monitoring. Second is the applicability issue: the results of this paper can be extended to other processes of civil engineering construction. Processes such as earthwork, concrete pouring projects, masonry structure projects can apply the ideas of this paper for productivity evaluation, which is the direction in which future work needs to be improved.
7. Conclusions
This paper introduces a new method to evaluate the productivity of assembling reinforcement through the position relationship of objects detected by CenterNet. Firstly, a dataset of 1051 images with five categories is created based on entities related to assembling reinforcement. Eighty percent of the dataset is used to train and evaluate the CenterNet model, and the remaining twenty is used to test the detector’s performance. The results showed that the mAP reached 0.9682. Compared with the other three object detection models, the detector trained in this paper is comparable. Then, by inputting the videos into the model, the coordinate of the detected boxes at each moment can be obtained, and the number of workers engaged in the task can be judged through the boxes’ position relationship. Finally, evaluation of work productivity is realized by the change of coordinates of the work object in the video, the time consumed to perform the task, and the number of workers involved in the process.
The work productivity evaluation value obtained matches the construction site’s actual condition and satisfies the objective law, indicating that the application of computer vision to evaluate engineering work productivity is a feasible approach. Applying the dataset proposed in this paper, the trend of construction material changes can be accurately reflected. With this method, project managers can quickly visualize the productivity of assembling reinforcement without a significant cost increase. The information obtained can be used to allocate human resources to construction sites more rationally. As the method is improved, it will potentially to be used for productivity evaluation of various processes in engineering construction.



 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}