1. Introduction
Deep learning revolutionized machine learning by improving the accuracy by dozens of percents for fundamental tasks in natural language processing (NLP), speech/image recognition, etc. One of the disadvantages of deep learning is that in many cases, the classifier is extremely large compared to classical machine learning models. A large network usually requires expensive and stronger resources due to: (1) slower classification time, which may be a serious limitation, especially in real-time systems such as autonomous cars or real-time text/speech translations; (2) a large memory requirement, which makes it infeasible to store the network on RAM or on a device such as IoT/smartphones; and (3) high energy consumption which is related to the CPU/GPU time of each classification and requires larger batteries with shorter lifespan.
Pipeline of network compression. Given training data P, a common pipeline to obtain a compressed network consists of the following stages:
- (i)
Train a network N based on the training set P, starting from an initial random network.
- (ii)
Compress the network N to a small network . The input P may be not involved in this stage.
- (iii)
Fine-tune the weights of by training it on P. This step aims to improve the accuracy of the network but does not change its size.
In this paper, our goal is to improve the compression step (ii) in order to avoid the fine-tuning step (iii) via suggesting a better and more robust compressing scheme. We suggest a novel low rank factorization technique for compressing an embedding layer of a given NLP model. This is motivated by the fact that in many networks, the embedding layer accounts for 20–40% of the network size. Indeed, the results are easily extended to fully connected layers.
1.1. Embedding Matrix
One of the most common approaches for compressing neural networks is to treat a layer in the network as a matrix operation and then to approximate this matrix by its compressed version. This is especially relevant in a fully connected layer. Specifically, in word embedding, this layer is called the embedding layer, which is defined by the following matrix.
The input of the embedding layer consists of d input neurons, and the output has n neurons. The edges between these layers define a matrix . Here, the entry in the ith row and jth column of A is equal to the weight of the edge between the jth input neuron to the ith output neuron. Suppose that a test sample (vector) is received as an input. The corresponding output n-dimensional vector is thus . To simply, a column from A during training is read, and a standard vector x (a column of the identity matrix) is used and is called a one-hot vector.
k-rank approximation. One of the natural and common matrix approximations, including in the context of network compression, is the
k-rank approximation (see, e.g., [
1,
2] and references therein). This is the matrix which minimizes the Frobenius norm, i.e., the sum of squared distances
between the
ith row
in
A and its corresponding row
in
, over every rank
k matrix
. It can be easily computed via the singular value decomposition (SVD) in
time. Although
has the same size as
A, due to its low rank, it can be factorized as
, where
and
. We can then replace the original embedding layer that corresponds to
A by a pair of layers that correspond to
U and
W, which can be stored using
memory, compared to the
entries in
A. Moreover, the computation of the output
takes
time, compared to the
time that it takes to compute
.
Handling other linear layers. The rank approximation technique can be also applied to a fully connected layer, where an activation function is applied on the output or each of its coordinates (as Relu) to obtain . By approximating A, in a sense, is also approximated by . Then, is replaced by two smaller layers , as explained above. Furthermore, it is known that convolutional layers (tensors) can be viewed as fully connected layers (matrix multiplication) applied to reshaped volumes of the input. Then, one can approximate the convolutional weights by approximating its corresponding weight matrix. Hence, the rank approximation technique can be also applied to a convolutional layer.
1.2. Motivation
In what follows, we explain the main motivation of this paper, which in sum, aims to eliminate the need for the fine-tuning step due to the reasons explained in
Section 1.2.1. We also discuss the weaknesses of the known SVD factorization in
Section 1.2.2, which in turn, give rise to the motivation behind our approach discussed in
Section 1.2.3.
1.2.1. Fine-Tuning
The layers that correspond to the matrices U and W above are usually used only as initial seeds for a training process that is called fine-tuning, where the aim is to improve the initial results. Here, the training data are fed into the network, and as opposed to the error, the error is measured with respect to the final classification, i.e., in the fine-tuning step, the compressed network is trained using the input P, similar to Step (i). The goal of this step is to improve the accuracy of the compressed network without increasing its size. Hence, the structure of the data remains the same, but the edges are updated in each iteration.
To be or not to be fine-tuned? Fine-tuning is a necessary step to recover the generalization ability damaged by the model compression. Despite its widespread use, fine-tuning is vaguely understood, e.g., what fraction of the pre-trained weights are actually changing and why? [
3].
In many cases, the fine-tuning cannot be applied:
Hence, some have attempted to prune each layer independently, by which a fine-tuning process can be done with a small number of epochs to avoid the excessive computational power required by the fine-tuning process [
5]. Finally, it is worth mentioning that the fine-tuned parameters are not constrained to share any components with the pre-trained weights and thus are equally expensive to store and to compute per iteration [
13].
In this paper, we replace the go-to method for compression models using matrix factorization by a more robust low rank approximation scheme, where the emphasis here is that the learning capability of the model after the compression is less affected.
1.2.2. Should We Use SVD?
Training the network and compressing it are natural steps. However, it is not clear that the last fine-tuning step, which may be a serious time consumer, is necessary. The goal of this work is to remove this step by improving the previous (compression) step via more involved algorithms that provably approximate the more robust rank approximation. We begin with geometric intuition.
The geometry behind SVD. Geometrically, each row of A corresponds to a d-dimensional vector (point) in , and the corresponding row in is its projection on a k-dimensional subspace of . This subspace (which is the column space of U) minimizes the sum of squared distances to the rows of A over every k-subspace in .
Statistically, if these
n points were generated by adding a Gaussian noise to a set of
n points on a
k-dimensional subspace, then it is easy to prove that most likely (in the sense of maximum-likelihood) this subspace is
U. The disadvantage of
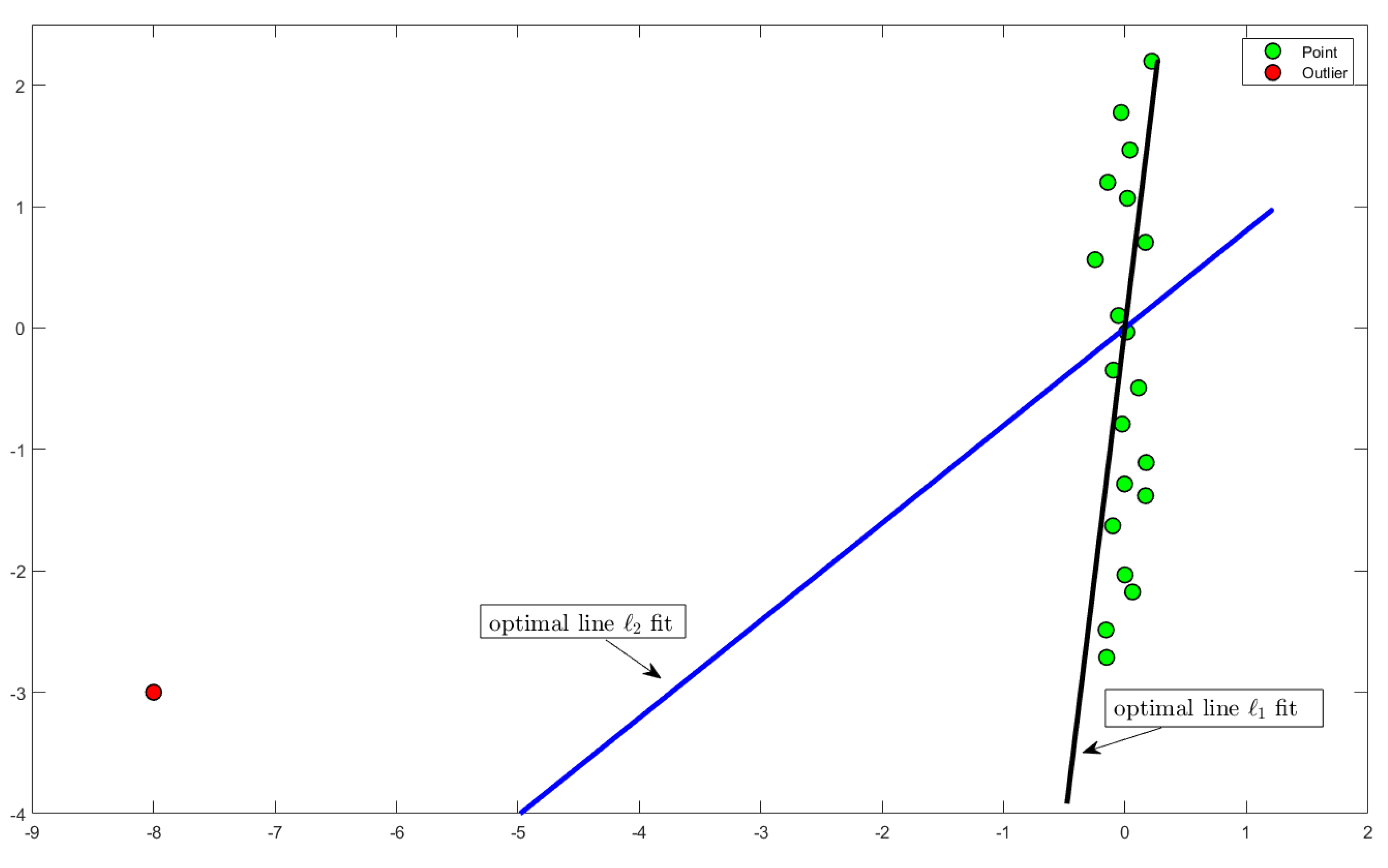
k-rank approximation is that it is optimal under the above statistical assumption, which rarely seems to be the case for most applications. In particular, minimizing the sum of squared distances is heavily sensitive to outliers [
14] (see
Figure 1). As explained in [
15], this is the result of squaring each term, which effectively weights large errors more heavily than small ones.
This undesirable property, in many applications, has led researchers to use alternatives such as the mean absolute error (MAD), which minimizes the
(sum of distances) of the error vector. For example, compressed sensing [
16] uses
approximation as its main tool to clean corrupted data [
17] as well as to obtain sparsified embeddings with provable guarantees as explained, e.g., in [
18].
In machine learning, the
-approximation replaces or is combined with the
approximation. Examples in scikit-learn include lasso regression, elastic-nets, or MAD error in decision trees [
19].
1.2.3. Novel Approach and Its Challenges
Novel approach: deep learning meets subspace approximation. We suggest generalizing the above approximation to k-rank approximation, or even approximation for more general . Geometrically, we wish to compute the k-subspace that minimizes the sum of pth power of the distances to the given set of n points. This should result in more accurate compressed networks that are more robust to outliers and classification mistakes.
Unlike the case
, which was solved more than a century ago [
20] via SVD and its variants, the
low rank approximation was recently proved to be NP-hard even to approximate up to a factor of
(recall that
d is the number of columns of
A above) for
[
21] and even for general (including constant) values of
p (see
Section 2). In the most recent decade, there was great progress in this area; however, the algorithms were either based on ad hoc heuristics with no provable bounds or impractical, i.e., their running time is exponential in
k [
21,
22], and their efficiency in practice is not clear. Indeed, we could not find implementations of such provable algorithms.
This motivates the questions that are answered affirmably in this paper: (i) Can we efficiently compute the corresponding k-rank approximation matrix , similar to SVD? (ii) Can we remove the fine-tuning step by using the low rank approximation, while scarifying only a small decrease in the accuracy of the compressed network? (iii) Can we obtain smaller networks with higher accuracy (without fine-tuning) by minimizing the sum of non-squared errors, or any other power of distances, instead of the k-rank approximation via SVD?
1.3. Our Contribution
We answer these questions by suggesting the following contributions:
A new approach for compressing networks based on k-rank approximation instead of , for . The main motivation is the robustness to outliers and noise, which is supported by many theoretical justifications.
Provable algorithms for computing this low rank approximation of every matrix A. The deterministic version takes time , and the randomized version takes . The approximation factor depends polynomially on d, is independent of n for the deterministic version, and is only poly-logarithmic in n for the randomized version.
Experimental results confirming that our approach significantly improves existing results when the fine-tuning step is removed from the pipeline upon using SVD (see
Section 5).
Full open source code is provided [
23].
Our results are based on a novel combination of modern techniques in computational geometry and applied deep learning. We expect that future papers will extend this approach (see
Section 7).
To obtain efficient implementations with provable guarantees, we suggest a leeway by allowing the approximation factor to be larger than k, instead of aiming for (-approximation (PTAS). In practice, this worst-case bound seems to be too pessimistic, and the empirical approximation error in our experiments is much smaller. This phenomenon is common in approximation algorithms, especially in deep learning, when the dataset has a lot of structure and is very different from synthetic worse-case artificial examples. The main mathematical tool that we use is the Löwner ellipsoid, which generalizes the SVD case to general cases, inspired by many papers in the related work below.
To be part and not apart. Our technique can be combined with previous known works to obtain better compression. For example, DistilBERT [
24] is based on knowledge distillation, and it reduces the size of the BERT [
12] model by
, while maintaining
of its language understanding capabilities and being
faster. However, this result does not use low rank factorization to compress the embedding layer. We further compressed DistilBERT and achieved better accuracy than SVD.
2. Related Work
In the context of training giant models, some interesting approaches were suggested to reduce the memory requirement, e.g., [
25,
26]. However, those methods reduced the memory requirement at the cost of speed/performance. Later, [
27] proposed a way to train large models based on parallelization. Here, the model size and evaluation speed are also still an obstacle. Hence, many papers were dedicated to the purpose of compressing neural networks in the field of NLP. These papers are based on different approaches such as pruning [
28,
29,
30,
31,
32], quantization [
33,
34], knowledge distillation [
24,
35,
36,
37,
38,
39,
40,
41], weight sharing [
42], and low rank factorization [
42,
43,
44] (see the example table in [
45] for compressing the BERT model). There is no convention for which approach from the above should be used. However, recent works, e.g., [
42], showed that combining such approaches yields good results.
Subspace approximation. The
k-rank approximation can be solved easily in
time, while a
approximation can be computed deterministically in
time [
46] for every
, and a randomized version takes
time, where nnz(
A) is the number of non-zero entries in
A [
47,
48,
49]. These and many of the following results are summarized in the seminal work of [
21]. However, for
, even computing a multiplicative
-approximation is NP-hard when
k is part of the input [
21]. Nevertheless, it is an active research area, where techniques from computational geometry are frequently used. The case
was introduced in the theory community by [
50], and earlier, the case
was introduced in the machine learning community by [
51]. In [
50], a randomized algorithm for any
that runs in time
was suggested. The state of the art for
in [
21] takes
time.
Approximation algorithms for the
low rank approximation were suggested in [
52] for any
, which we also handle. Although the obtained approximation, in some cases, is smaller than the approximation achieved in this paper, the running time in most cases (depending on k) is much larger than that of ours.
Regardless of the approximation, [
52] suggests a polynomial time algorithm (one of many) as long as
. Similar to the discussion in [
52], our
low rank approximation allows us to recover an approximating matrix of any chosen rank, while the robust PCA [
53] returns some matrix of unknown rank. Although variants of robust PCA have been proposed to force the output rank to be a given value [
54,
55], these variants make assumptions about the input matrix, whereas our results do not. The time complexity for
was improved in [
56] to
, and later, for general
p to
[
22]. The latter work, together with [
57], also gives a
coreset for subspace approximation, i.e., a way of reducing the number of rows of
A so as to obtain a matrix
such that the cost of fitting the rows of
to any
k-dimensional subspace
F is within a
factor of the cost of fitting the rows of
A to
F; for
, such coresets were known [
47,
58,
59,
60] and can be computed exactly
[
61,
62].
Efficient approximations. The exponential dependency on k and hardness results may explain why we could not find (even inefficient) open or closed code implementations on the web. To our knowledge, it is an open problem to compute larger factor approximations () in a time polynomial in k, even in theory. The goal of this paper is to provide such a provable approximation in time that is near-linear in n with practical implementation and to demonstrate our usefulness in compressed networks.
3. Method
Notations. For a pair of integers , we denote by the set of all real matrices, by the identity matrix, and . For a vector , a matrix , and a real number , the pth norm of x is defined as , and the entry-wise norm of A is defined as , where is a vector whose ith entry is 1 and 0 elsewhere. We say that the columns of a matrix (where ) are orthogonal if . In addition, a matrix is called positive definite matrix if F is a symmetric matrix, and for every such that , we have . Furthermore, we say that a set is centrally symmetric if for every , it holds that . Finally, a set is called a convex set if for every and , .
3.1. -SVD Factorization and the Löwner Ellipsoid
In what follows, we intuitively and formally describe the tools that will be used in our approach. Definition 1 is based on Definition 4 in [
63]. While the latter defines a generic factorization for a wide family of functions, Definition 1 focuses on our case, i.e., the function we wish to factorize is
for any
, where
is the input matrix, and
x is any vector in
.
Definition 1 (Variant of Definition 4 [
63]).
Let be a matrix of rank d, and let be a real number. Suppose that there is a diagonal matrix of rank d, and an orthogonal matrix , such that for every ,Define . Then, is called the -SVD of A.
Why -SVD? The idea behind using the -SVD factorization of an input matrix A is that we obtain a way to approximate the span of the column space of . This allows us to approximate the dot product for any , which implies an approximation for the optimal solution of the low rank approximation problem.
For example, in the case of
, the
-SVD of a matrix
is equivalent to the known SVD factorization
. This holds due to the fact that the columns of the matrix
U are orthogonal, and for every
, we have
As for the general case of any
, [
63] showed that the
-SVD factorization always exists, and can be obtained using the
Löwner ellipsoid.
Theorem 2 (Variant of Theorem III [
64]).
Let be a diagonal matrix of full rank and an orthogonal matrix , and let E be an ellipsoid defined as Let L be a centrally symmetric compact convex set. Then, there exists a unique ellipsoid E called theLöwner ellipsoidof L such that , where .
Computing -SVD via Löwner ellipsoid. Intuitively speaking, for an input matrix , the -SVD aims to bound from above and below the cost function for any by the term . Since is a convex continuous function (for every ), the level set is also convex. Having a convex set enables us to use the Löwner ellipsoid, which, in short, is the minimum volume enclosing ellipsoid of L. In addition, contracting the Löwner ellipsoid by yields an inscribed ellipsoid in L. It turns out that of the -SVD represents the Löwner ellipsoid of L as follows: D is a diagonal matrix such that its diagonal entries contain the reciprocal values of the ellipsoid axis lengths, and V is an orthogonal matrix which is the basis of the same ellipsoid. Using the enclosing and inscribed ellipsoids (the Löwner ellipsoid and its contracted form) enables us to bound using the mahalonobis distance. Although in traditional k-low rank factorization with respect to an input matrix , the optimal result is equal to the sum of the smallest singular values, we generalize this concept to -low rank factorization. Specifically, the singular values of D (the reciprocal values of the ellipsoid axis lengths) serve as a bound on the “” singular values of A.
3.2. Additive Approximation for the -Low Rank Factorization
In what follows, we show how to compute an approximated solution for the -low rank factorization for any (see Algorithm 1). This is based on the -SVD factorization (see Definition 1).
From -SVD to -low rank factorization. For any and any matrix of rank d, the -low rank factorization problem aims to minimize over every matrix whose columns are orthogonal. As a byproduct of the orthogonality of X, the problem above is equivalent to minimizing over every matrix whose columns are orthogonal such that . By exploiting the definition of the entry-wise norm of , we can use -SVD to bound this term from above and below using the mahalonobis distance. Furthermore, we will show that by using the -SVD, we can compute a matrix of rank k such that depends on the ellipsoid axis lengths (see Algorithm 1 and Theorem 5).
Overview of Algorithm 1. Algorithm 1 receives as input a matrix
of rank
d, a positive integer
, and a positive number
and outputs a matrix
of rank
k, which satisfies Theorem 5. At Line 1, we compute a pair of matrices
such that the ellipsoid
is the Löwner ellipsoid of
, where
D is a diagonal matrix of rank
d, and
V is an orthogonal matrix; we refer the reader to the
Appendix A for computing the Löwner ellipsoid. At Line 2, we compute the matrix
U from the
-SVD of
A (see Definition 1). At Lines 3–4, we set
to be the diagonal matrix of
entries where the first
k diagonal entries are identical to the first
k diagonal entries of
D, while the rest of the matrix is set to 0 (see
Figure 2 for an illustrative description of our algorithm).
| Algorithm 1:ℓρ-LOW-RANK (A, k, p)
|
- Input :
A matrix of rank d, , a positive integer , and a positive real number . - Output :
A matrix , a diagonal matrix , an orthogonal matrix where are from the -SVD of A, and a set of d positive real numbers .
//computing U from the -SVD of A with respect to the -regression problem the diagonal entries of D //A diagonal matrix in return
|
4. Analysis
Some of the proofs in this section were moved into the Supplementary Material due to space limitations.
4.1. Deterministic Result
In what follows, we present our deterministic solution for the -low rank factorization problem.
Claim 3. Letbe a diagonal matrix of rankd, and letbe the lowest singular value ofD. Then, for every unit vector,
Proof. Let
be a unit vector, and for every
, let
denote the
ith diagonal entry of
D, and
denotes the
ith entry of
x. Observe that
where the first equality follows from the definition of norm, the inequality holds by definition of
, and the last equality holds since
x is a unit vector. □
Lemma 4 (Special case of Lemma 15 [
63]
Let be a matrix of full rank, . Then, there exist a diagonal matrix of full rank and an orthogonal matrix such that for every , Proof. First, let , and put . Observe that (i) since , the term is a convex function for every which follows from properties of norm function. This means that the level set L is a convex set. In addition, (ii) by definition of L, it holds that for every , also , which makes L a centrally symmetric set by definition. Note that (iii) since A is of full rank, then L spans .
Since properties (i)–(iii) hold, we obtain by Theorem 1 that there exists a diagonal matrix
of full rank and an orthogonal matrix
such that the set
satisfies
Proving the right hand side of Equation (1). Let
, and observe that
where the equality follows from the definition of
y, and the inequality holds since
follows from Equation (
2).
Proving the left hand side of Equation (1). Since
L spans
, there then exists
such that
. By Equation (
2),
, which results in
. Thus,
Since Equation (
3) and Equation (
4) hold for every
, Lemma 4 follows. □
Theorem 5. Let be real matrix, ; be an integer; and () be the output of a call to ℓρ-Low-rank(). Let . Then, Proof. First, we assume that ; otherwise, the factorization is the SVD factorization, and we obtain the optimal solution for the low rank approximation problem. For every , let be a vector of zeros, except for its ith entry, where it is set to 1. Observe that , where the first equality holds by definition of , and the second equality follows from the definition of (see Lines 3–4 of Algorithm 1).
Plugging
,
,
,
into Lemma 4 yields that for every
,
Observe that for every
,
where the first inequality holds by properties of the
matrix induced norm, and the second inequality holds since
V is an orthogonal matrix.
Since
is a unit vector,
where the inequality holds by plugging
and
into Claim 3.
In addition, we have that
where both the inequality and equality hold since
is the lowest eigenvalue of
D,
D being a diagonal matrix.
By combining Equations (
5)–(
8), we obtain that for every
,
Theorem 5 follows by summing Equation (
9) over every
. □
Note that the set denotes the reciprocal values of the ellipsoid E axis’s lengths, where E is the Löwner ellipsoid of . As discussed in the previous section, these values serve to bound the “ singular values of A”.
4.2. Randomized Result
In addition to our deterministic result, we also show how to support a randomized version that computes an approximation in a faster time, which relies on the following result of [
65].
Theorem 6 (Variant of Theorem 10 [
65]).
For any of rank d and , one can compute an invertible matrix and a matrix such that holds with a probability of at least , where R can be computed in time . Theorem 7. Let be real matrix, , and be an integer. There exists a randomized algorithm which, when given a matrix , , in time , returns , such that holds with a probability of at least , where .
Proof. The algorithm is described throughout the following proof. Let
be as defined in Theorem 6 when plugging
into Theorem 6. Let
be the
SVD of
R;
be a diagonal matrix where its first
k diagonal entries are identical to those of
D, while the rest of the entries in
are set to 0; and
be the set of singular values of
D. Note that since for every
, by Theorem 6 it holds that
From here, similar to the proof of Theorem 5, we obtain that
□
Remark 8. Note that in our context of embedding layer compression, the corresponding embedding matrix A has more columns than rows. Regardless, our norm of any such that enables us to have Hence, substituting and yieldsfor our deterministic results, and similarly, we can obtain this for our randomized result. 5. Experimental Results
The compressed networks. We compress several frequently used NLP networks:
- (i)
BERT [
12]: BERT is a bidirectional transformer pre-trained using a combination of masked language modeling objective and next sentence prediction on a large corpus comprising the Toronto Book Corpus and Wikipedia.
- (ii)
DistilBERT [
24]: the DistilBERT model is smaller, faster, cheaper, and lighter than BERT. This model is a distilled version of BERT. It has
less parameters than bert-base-uncased and runs
faster, while preserving over
of BERT’s performances as measured on the GLUE language understanding benchmark [
24].
- (iii)
XLNet [
66]: XLnet is an extension of the Transformer-XL model [
67] pre-trained using an autoregressive method to learn bidirectional contexts by maximizing the expected likelihood over all permutations of the input sequence factorization order.
- (iv)
RoBERTa [
68]: RoBERTa modifies the key hyperparameters in BERT, including removing BERT’s next-sentence pre-training objective, and training with much larger mini-batches and learning rates. This allows RoBERTa to improve on the masked language modeling objective compared with BERT and leads to better downstream task performance.
See full details on the sizes of each network and their embedding layer before compression in
Table 1.
Implementation, Software, and Hardware. All the experiments were conducted on an AWS p2.xlargs machine with 1 GPU NVIDIA K80, 4 vCPUs, and 61 RAM [GiB]. We implemented our suggested compression algorithm (Algorithm 1) in Python
using the Numpy library [
69]. To build and train networks (i)–(iv), we used the suggested implementation in the Transformers
https://github.com/huggingface/transformers (accessed on 15 July 2021) library from HuggingFace [
70] (Transformers version
and PyTorch version
[
71]). Before the compression, all the networks were fine-tuned on all the tasks from the GLUE benchmark to obtain almost the same accuracy results as reported in the original papers. Since we did not succeed in obtaining close accuracy on the tasks QQP and WNLI (with most of the network), we did not include results from them.
Our compression. We compress each embedding layer (matrix) of the reported networks by factorizing it into two smaller layers (matrices) as follows. For an embedding layer that is defined by a matrix , we compute the matrices by a call to ℓρ-Low-rank (see Algorithm 1), where k is the low rank projection we wish to have. Observe, that the matrix is a diagonal matrix, and its last columns are zero columns. We then compute a non-square diagonal matrix that is the result of removing all the zero columns of . Now, the k-rank approximation of A can be factorized as . Hence, we save the two matrices (layers): (i) of size , and (ii) of size . This yields two layers of a total size of instead of a single embedding layer of a total size of .
Reported results. We report the test accuracy drop (relative error) on all the tasks from the GLUE benchmark [
72] after compression for several compression rates:
In
Figure 3, the
x-axis is the compression rate of the embedding layer, and the
y-axis is the accuracy drop (relative error) with respect to the original accuracy of the network. Each figure reports the results for a specific task from the GLUE benchmark on all the networks we compress. Here, all reported results are compared to the known
-factorization using SVD. In addition, in all the experiments, we do not fine-tune the model after compressing; this is to show the robustness and efficiency of our technique.
Table 2 suggests the best compressed networks in terms of accuracy vs size. For every network from (i)–(iv), we suggest a compressed version of it with a very small drop in the accuracy and sometimes with an improved accuracy. Given a network “X”, we call our compressed version of “X” “RE-X”, e.g., RE-BERT and RE-XLNet. The “RE” here stands for “Robust Embedding”.
Table 3 reports a comparison between our approach and different compressionmethods that do not require fine-tuning or any usage of the training data after compression:
- (i)
SVD.
- (ii)
- (iii)
- (iv)
Random pruning.
- (v)
6. Discussion
It can be seen by
Figure 3 that our approach is more robust than the traditional SVD. In most of the experiments, our suggested compression achieves better accuracy for the same compression rate compared to the traditional SVD. Mainly, we observed that our compression schemes shine when either vocabulary is rich (the number of subword units is large) or the model itself is small (excluding the embedding layer). Specifically speaking, in RoBERTa, our method achieves better results due to the fact that RoBERTa’s vocabulary is rich (i.e., 50 K subword units compared to the 30 K in BERT). This large vocabulary increases the probability of having outliers in it, which is the main justification for our approach. In DistilBERT, the network is highly efficient. This can lead to a sensitive snowball effect, i.e., the classification is highly affected by even the smallest errors caused by the compression of the embedding layer. Since SVD is sensitive to outliers and due to the fact that the network is highly sensitive to small errors, the existence of outliers highly affects the results. This phenomenon is illustrated throughout
Figure 3. Here, our compression scheme outperforms the SVD due to its robustness against outliers, which, in turn, achieves smaller errors. As for XLNet, the model encodes the relative positional embedding, which, in short, represents an embedding of the relative positional distance between words. In our context, this means that having outliers highly affects the relative positional embedding, which, in turn, affects the classification accuracy. Hence, this explains why we outperform SVD. Since none of the above phenomena hold for BERT, this may explain why SVD sometimes achieves better results. However, across most tasks, our compression scheme is favorable upon SVD.
Finally, for some tasks at low compression rates, the accuracy has been improved (e.g., see task SST-2 at
Figure 3 when compressing BERT). This may be due to the fact that at low compression rates, we remove the least necessary (redundant) dimensions. Thus, if these dimensions are actually unnecessary, by removing them, we obtain a generalized model which is capable of classifying better.
7. Conclusion and Future Work
We provided an algorithm that computes an approximation for
k-rank approximation, where
. We then suggested a new approach for compressing networks based on
k-rank
-approximation, where
instead of
. The experimental results in
Section 5 showed that our suggested algorithm overcomes the traditional
k-rank approximation and achieves higher accuracy for the same compression rate when there is no fine-tuning involved.
Future work includes: (1) Extending our approach to other factorization models, such as non-negative matrix approximation or dictionary learning; (2) experimental results on other benchmarks and other models; (3) suggesting algorithms for the k-rank approximation for any , while checking the practical contribution in compressing deep networks for this case; and (4) combining this result with other compression techniques to obtain a smaller network with higher accuracy.
Author Contributions
Conceptualization, M.T., A.M., M.W., and D.F.; methodology, M.T. and A.M.; software, M.T. and M.W.; validation, M.T. and M.W.; formal analysis, M.T. and D.F. ; investigation, M.T. and A.M.; resources, M.W. and D.F.; data curation, M.T. and M.W.; writing—original draft preparation, M.T. and A.M.; writing—review and editing, M.T., A.M., M.W., and D.F.; visualization, M.T.; supervision, D.F.; project administration, M.T.; funding acquisition, M.W. and D.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Computing the Löwner Ellipsoid
Figure A1.
Computing the Löwener ellipsoid. Step I:We start with an ellipsoid that contains our level set (the blue body). From here, the basic ellipsoid method is invoked, i.e., while the center is not contained inside the level set (blue body), a separating hyperplane between the center of the ellipsoid and the level set is computed, and the ellipsoid is stretched in a way such that the center moves closer in distance to the level set. The basic ellipsoid method halts when the center is contained in the level set (see (a–c) for illustration of the ellipsoid method). Step III:We compute a contracted version of the current ellipsoid and check if all of its vertices are contained in the level set. If there exists one ellipsoid’s vertex which is not contained in the level set, we find the farthest vertex of the contracted ellipsoid from the level set and compute a separating hyperplane between it and the level set. Then, the ellipsoid is stretched such that this vertex becomes closer to the level set presented in (d,e). We then loop StepsII–III until the contracted ellipsoid’s vertices are contained in the level set (see (f)).
Figure A1.
Computing the Löwener ellipsoid. Step I:We start with an ellipsoid that contains our level set (the blue body). From here, the basic ellipsoid method is invoked, i.e., while the center is not contained inside the level set (blue body), a separating hyperplane between the center of the ellipsoid and the level set is computed, and the ellipsoid is stretched in a way such that the center moves closer in distance to the level set. The basic ellipsoid method halts when the center is contained in the level set (see (a–c) for illustration of the ellipsoid method). Step III:We compute a contracted version of the current ellipsoid and check if all of its vertices are contained in the level set. If there exists one ellipsoid’s vertex which is not contained in the level set, we find the farthest vertex of the contracted ellipsoid from the level set and compute a separating hyperplane between it and the level set. Then, the ellipsoid is stretched such that this vertex becomes closer to the level set presented in (d,e). We then loop StepsII–III until the contracted ellipsoid’s vertices are contained in the level set (see (f)).
![Sensors 21 05599 g0a1]()
For an input matrix of rank d and a number , we now show how to compute the Löwner ellipsoid for the set . This is a crucial step towards computing the -SVD (see Definition 1) for the matrix A in the context of the -low rank approximation problem, which will allow us to suggest an approximated solution (See Theorem 5).
Overview of Algorithm A1 (computing the Löwner ellipsoid).Algorithm A1 receives as input a matrix
of rank
d and a number
. It outputs a Löwner ellipsoid for the set
L (see Line 1 of
Algorithm A1). First, at Line 1, we initialize
L to be set of all the points
x in
such that
. At Lines 2–5, we find a ball
E in
of radius
r, which contains the set
L, and its center is set to be the origin
. Then, we build a diagonal matrix
F, where we set its diagonal entries to
r.
Lines 8–12 represent the pseudo-code of the basic ellipsoid method which is described in detail in [
76], where we set
H to the separating hyperplane between
c (the center of the ellipsoid
E) and
L;
b is set to be the multiplication between
F and the normalized subgradient of
at
, where
b is used to set the next candidate ellipsoid.
In Lines 13–17, we compute the next candidate ellipsoid E, and based on it, we set to be the set containing the vertices of the inscribed ellipsoid in L. Now, if , then we halt the algorithm; otherwise, we find the farthest vertex point v in from L with respect to , and finally, we set H to be the separating hyperplane between v and L.
Lines 19–25 present the pseudo code of applying a shallow cut update to the ellipsoid
E; this is described in detail in [
76]. Finally, at Line 27, we set
G to be the Cholesky decomposition of
(see [
77] for more details). For formal details, see Theorem 2.
| Algorithm A1: Löwner (A, p)
|
![Sensors 21 05599 i001]() |
References
- Yu, X.; Liu, T.; Wang, X.; Tao, D. On compressing deep models by low rank and sparse decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7370–7379. [Google Scholar]
- Acharya, A.; Goel, R.; Metallinou, A.; Dhillon, I. Online embedding compression for text classification using low rank matrix factorization. In Proceedings of the AAAI Conference on Artificial Intelligence, Hawaiian Village, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6196–6203. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Growing a brain: Fine-tuning by increasing model capacity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2471–2480. [Google Scholar]
- He, Y.; Lin, J.; Liu, Z.; Wang, H.; Li, L.J.; Han, S. Amc: Automl for model compression and acceleration on mobile devices. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–800. [Google Scholar]
- Luo, J.H.; Wu, J.; Lin, W. Thinet: A filter level pruning method for deep neural network compression. In Proceedings of the IEEE International Conference On Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5058–5066. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 2, 3111–3119. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the PInternational Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Dai, A.M.; Le, Q.V. Semi-supervised sequence learning. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 7–10 December 2015; pp. 3079–3087. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 7 September 2020).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MI, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Radiya-Dixit, E.; Wang, X. How fine can fine-tuning be? Learning efficient language models. In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, Sicily, Italy, 3–5 June 2020; pp. 2435–2443. [Google Scholar]
- Bermejo, S.; Cabestany, J. Oriented principal component analysis for large margin classifiers. Neural Netw. 2001, 14, 1447–1461. [Google Scholar] [CrossRef]
- Wikipedia. Mean Squared Error—Wikipedia, The Free Encyclopedia. 2020. Available online: http://en.wikipedia.org/w/index.php?title=Mean%20squared%20error&oldid=977071088 (accessed on 7 September 2020).
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Huang, X.; Liu, Y.; Shi, L.; Van Huffel, S.; Suykens, J.A.K. Two-level ℓ1 minimization for compressed sensing. Signal Process. 2015, 108, 459–475. [Google Scholar] [CrossRef]
- Donoho, D.L.; Elad, M. Optimally sparse representation in general (nonorthogonal) dictionaries via ℓ1 minimization. Proc. Natl. Acad. Sci. USA 2003, 100, 2197–2202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Eckart, C.; Young, G. The approximation of one matrix by another of lower rank. Psychometrika 1936, 1, 211–218. [Google Scholar] [CrossRef]
- Clarkson, K.L.; Woodruff, D.P. Input sparsity and hardness for robust subspace approximation. In Proceedings of the 2015 IEEE 56th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 17–20 October 2015; pp. 310–329. [Google Scholar]
- Feldman, D.; Langberg, M. A unified framework for approximating and clustering data. In Proceedings of the Forty-Third Annual ACM Symposium on Theory of Computing, San Jose, CA, USA, 6–8 June 2011; pp. 569–578. [Google Scholar]
- Code. Open Source Code for All the Algorithms Presented in this Paper. 2021. Available online: https://github.com/muradtuk/LzModelCompression (accessed on 7 September 2020).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Chen, T.; Xu, B.; Zhang, C.; Guestrin, C. Training deep nets with sublinear memory cost. arXiv 2016, arXiv:1604.06174. [Google Scholar]
- Gomez, A.N.; Ren, M.; Urtasun, R.; Grosse, R.B. The reversible residual network: Backpropagation without storing activations. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; pp. 2214–2224. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- McCarley, J.S. Pruning a bert-based question answering model. arXiv 2019, arXiv:1910.06360. [Google Scholar]
- Michel, P.; Levy, O.; Neubig, G. Are sixteen heads really better than one? In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 14014–14024. [Google Scholar]
- Fan, A.; Grave, E.; Joulin, A. Reducing transformer depth on demand with structured dropout. arXiv 2019, arXiv:1909.11556. [Google Scholar]
- Guo, F.M.; Liu, S.; Mungall, F.S.; Lin, X.; Wang, Y. Reweighted proximal pruning for large-scale language representation. arXiv 2019, arXiv:1909.12486. [Google Scholar]
- Gordon, M.A.; Duh, K.; Andrews, N. Compressing BERT: Studying the effects of weight pruning on transfer learning. arXiv 2020, arXiv:2002.08307. [Google Scholar]
- Zafrir, O.; Boudoukh, G.; Izsak, P.; Wasserblat, M. Q8bert: Quantized 8bit bert. arXiv 2019, arXiv:1910.06188. [Google Scholar]
- Shen, S.; Dong, Z.; Ye, J.; Ma, L.; Yao, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT. AAAI 2020, 34, 8815–8821. [Google Scholar] [CrossRef]
- Zhao, S.; Gupta, R.; Song, Y.; Zhou, D. Extreme language model compression with optimal subwords and shared projections. arXiv 2019, arXiv:1909.11687. [Google Scholar]
- Tang, R.; Lu, Y.; Liu, L.; Mou, L.; Vechtomova, O.; Lin, J. Distilling task-specific knowledge from bert into simple neural networks. arXiv 2019, arXiv:1903.12136. [Google Scholar]
- Mukherjee, S.; Awadallah, A.H. Distilling transformers into simple neural networks with unlabeled transfer data. arXiv 2019, arXiv:1910.01769. [Google Scholar]
- Liu, L.; Wang, H.; Lin, J.; Socher, R.; Xiong, C. Attentive student meets multi-task teacher: Improved knowledge distillation for pretrained models. arXiv 2019, arXiv:1911.03588. [Google Scholar]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient knowledge distillation for bert model compression. arXiv 2019, arXiv:1908.09355. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. Tinybert: Distilling bert for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. Mobilebert: A compact task-agnostic bert for resource-limited devices. arXiv 2020, arXiv:2004.02984. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Wang, Z.; Wohlwend, J.; Lei, T. Structured pruning of large language models. arXiv 2019, arXiv:1910.04732. [Google Scholar]
- Maalouf, A.; Lang, H.; Rus, D.; Feldman, D. Deep Learning Meets Projective Clustering. arXiv 2020, arXiv:2010.04290. [Google Scholar]
- Gordon, M.A. All The Ways You Can Compress BERT. Available online: http://mitchgordon.me/machine/learning/2019/11/18/all-the-ways-to-compress-BERT.html (accessed on 15 July 2021).
- Cohen, M.B.; Nelson, J.; Woodruff, D.P. Optimal approximate matrix product in terms of stable rank. arXiv 2015, arXiv:1507.02268. [Google Scholar]
- Clarkson, K.L.; Woodruff, D.P. Low-rank approximation and regression in input sparsity time. J. ACM 2017, 63, 1–45. [Google Scholar] [CrossRef]
- Meng, X.; Mahoney, M.W. Low-distortion subspace embeddings in input-sparsity time and applications to robust linear regression. In Proceedings of the Forty-Fifth Annual ACM Symposium on Theory of Computing, New York, NY, USA, 1–4 June 2013; pp. 91–100. [Google Scholar]
- Nelson, J.; Nguyên, H.L. OSNAP: Faster numerical linear algebra algorithms via sparser subspace embeddings. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 26–29 October 2013; pp. 117–126. [Google Scholar]
- Shyamalkumar, N.D.; Varadarajan, K. Efficient subspace approximation algorithms. SODA 2007, 7, 532–540. [Google Scholar] [CrossRef] [Green Version]
- Ding, C.; Zhou, D.; He, X.; Zha, H. R 1-PCA: Rotational invariant L 1-norm principal component analysis for robust subspace factorization. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 281–288. [Google Scholar]
- Chierichetti, F.; Gollapudi, S.; Kumar, R.; Lattanzi, S.; Panigrahy, R.; Woodruff, D.P. Algorithms for ℓp Low-Rank Approximation. Int. Conf. Mach. Learn. 2017, 34, 806–814. [Google Scholar]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM (JACM) 2011, 58, 1–37. [Google Scholar] [CrossRef]
- Netrapalli, P.; UN, N.; Sanghavi, S.; Anandkumar, A.; Jain, P. Non-convex robust PCA. Adv. Neural Inf. Process. Syst. 2014, 27, 1107–1115. [Google Scholar]
- Yi, X.; Park, D.; Chen, Y.; Caramanis, C. Fast algorithms for robust PCA via gradient descent. Adv. Neural Inf. Process. Syst. 2016, 30, 4152–4160. [Google Scholar]
- Feldman, D.; Monemizadeh, M.; Sohler, C.; Woodruff, D.P. Coresets and sketches for high dimensional subspace approximation problems. In Proceedings of the Twenty-First Annual ACM-SIAM Symposium on Discrete Algorithms, Austin, TX, USA, 17–19 January 2010; pp. 630–649. [Google Scholar]
- Varadarajan, K.; Xiao, X. On the Sensitivity of Shape Fitting Problems. In Proceedings of the 32nd International Conference on Foundations of Software Technology and Theoretical Computer Science, Hyderabad, India, 15–17 December 2012; p. 486. [Google Scholar]
- Feldman, D.; Volkov, M.; Rus, D. Dimensionality reduction of massive sparse datasets using coresets. Adv. Neural Inf. Process. Syst. 2016, 29, 2766–2774. [Google Scholar]
- Maalouf, A.; Statman, A.; Feldman, D. Tight sensitivity bounds for smaller coresets. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Goa, India, 14–18 December 2020; pp. 2051–2061. [Google Scholar]
- Maalouf, A.; Jubran, I.; Tukan, M.; Feldman, D. Faster PAC Learning and Smaller Coresets via Smoothed Analysis. arXiv 2020, arXiv:2006.05441. [Google Scholar]
- Maalouf, A.; Jubran, I.; Feldman, D. Fast and accurate least-mean-squares solvers. Adv. Neural Inf. Process. Syst. 2019, 33, 8307–8318. [Google Scholar]
- Jubran, I.; Maalouf, A.; Feldman, D. Introduction to coresets: Accurate coresets. arXiv 2019, arXiv:1910.08707. [Google Scholar]
- Tukan, M.; Maalouf, A.; Feldman, D. Coresets for near-convex functions. Adv. Neural Inf. Process. Syst. 2020, 33, 4. [Google Scholar]
- John, F. Extremum problems with inequalities as subsidiary conditions. In Traces and Emergence of Nonlinear Programming; Springer: Berlin/Heidelberg, Germany, 2014; pp. 197–215. [Google Scholar]
- Clarkson, K.L.; Drineas, P.; Magdon-Ismail, M.; Mahoney, M.W.; Meng, X.; Woodruff, D.P. The fast cauchy transform and faster robust linear regression. SIAM J. Comput. 2016, 45, 763–810. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 1, 5753–5763. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.G.; Le, Q.; Salakhutdinov, R. Transformer-XL: Attentive Language Models beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Van Der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22. [Google Scholar] [CrossRef] [Green Version]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:1910.03771v5. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. NIPS-W. 2017. Available online: https://openreview.net/pdf?id=BJJsrmfCZ (accessed on 15 July 2021).
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 353–355. [Google Scholar]
- Markopoulos, P.P.; Karystinos, G.N.; Pados, D.A. Optimal algorithms for L_{1}-subspace signal processing. IEEE Trans. Signal Process. 2014, 62, 5046–5058. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Tanaka, H.; Kunin, D.; Yamins, D.L.; Ganguli, S. Pruning neural networks without any data by iteratively conserving synaptic flow. Adv. Neural Inf. Process. Syst. 2020, 33, 13. [Google Scholar]
- Grötschel, M.; Lovász, L.; Schrijver, A. The Ellipsoid Method. In Geometric Algorithms and Combinatorial Optimization; Springer: Berlin/Heidelberg, Germany, 1993; pp. 64–101. [Google Scholar]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; JHU Press: Baltimore, MD, USA, 2012; Volume 3. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}