
A Novel Approach to Automated 3D Spalling Defects Inspection in Railway Tunnel Linings Using Laser Intensity and Depth Information



Abstract
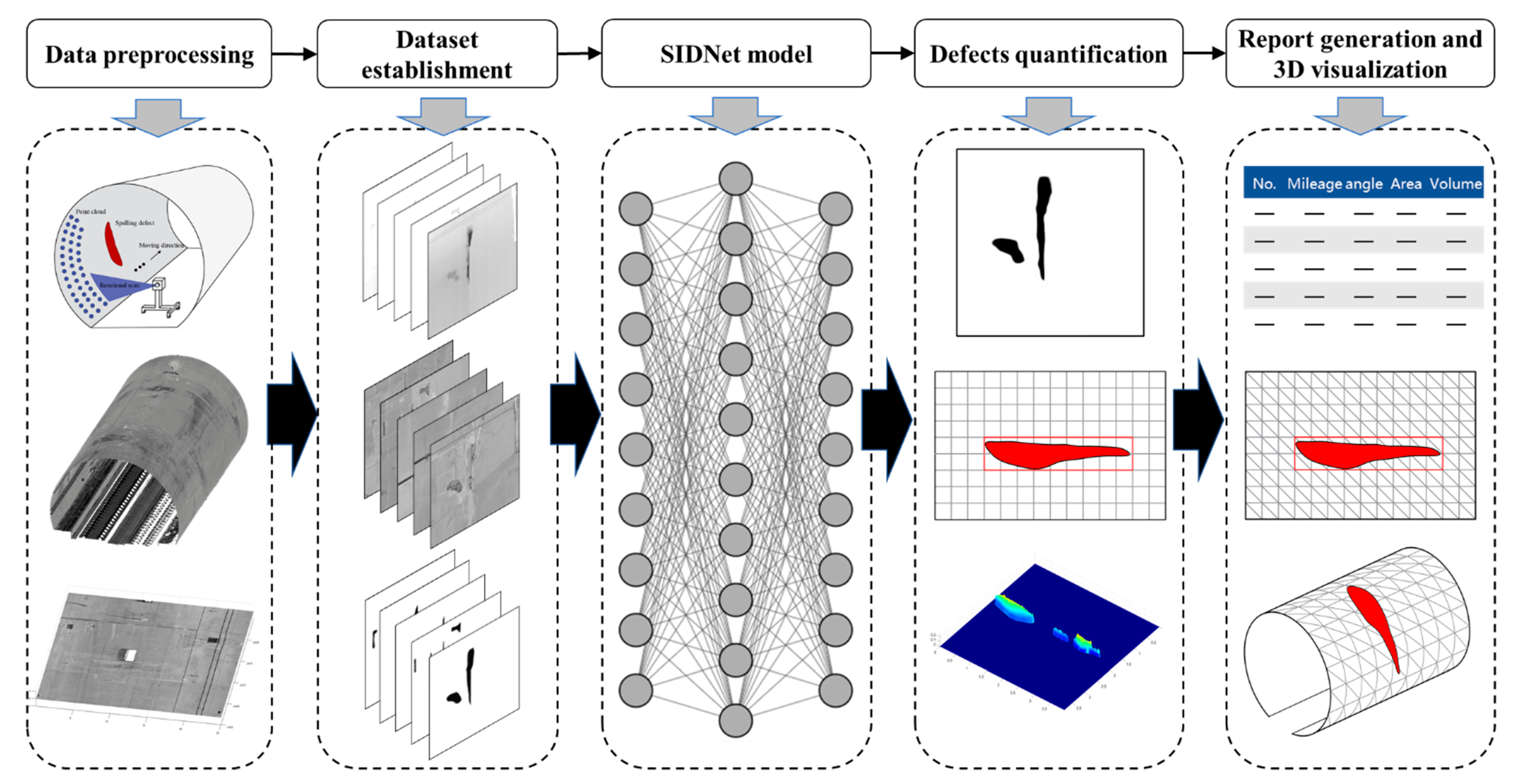
:1. Introduction
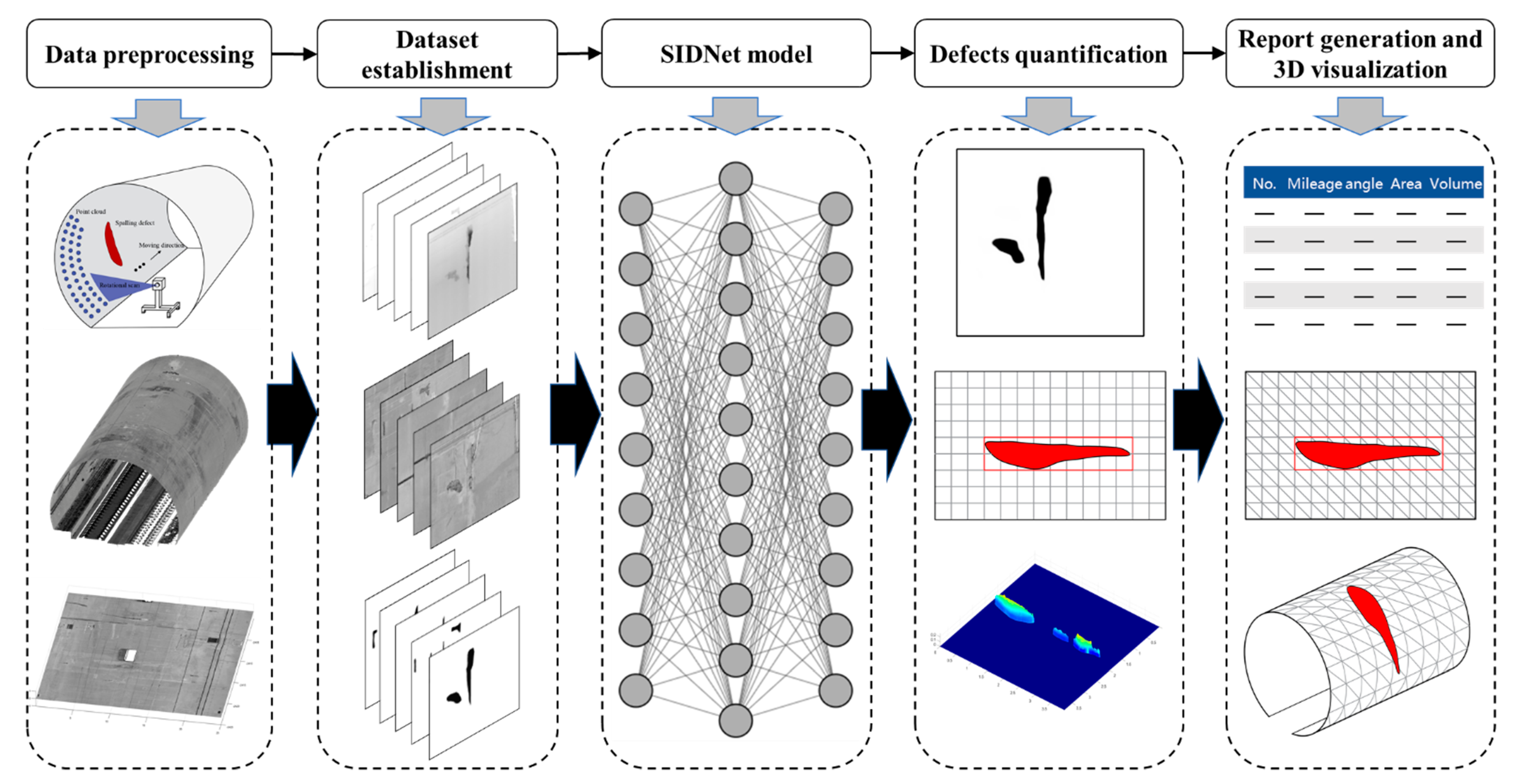
2. Data Acquisition and Dataset Establishment
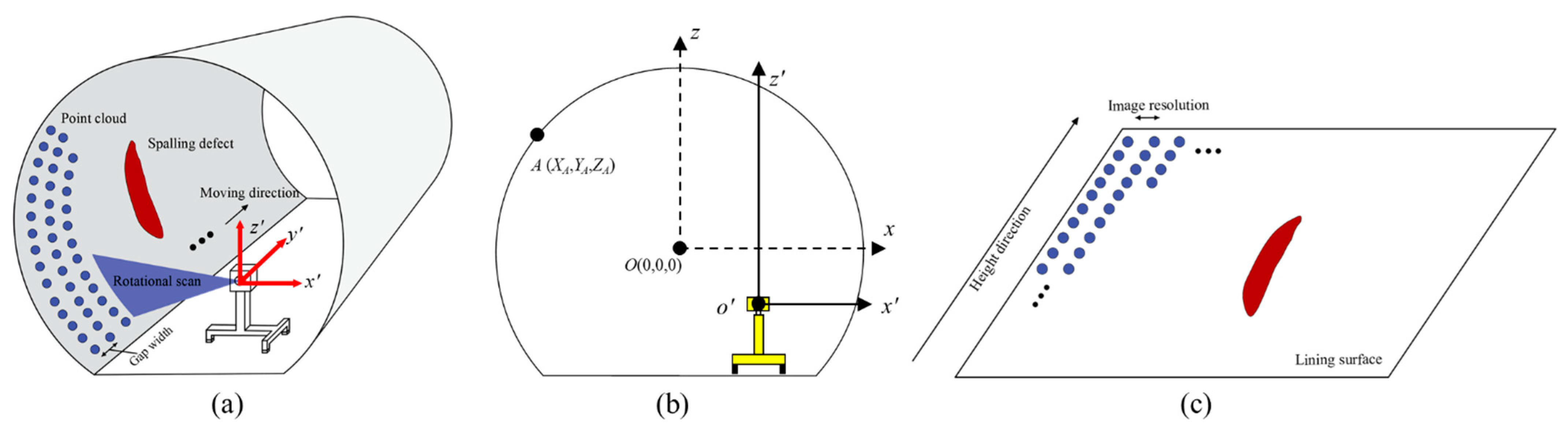
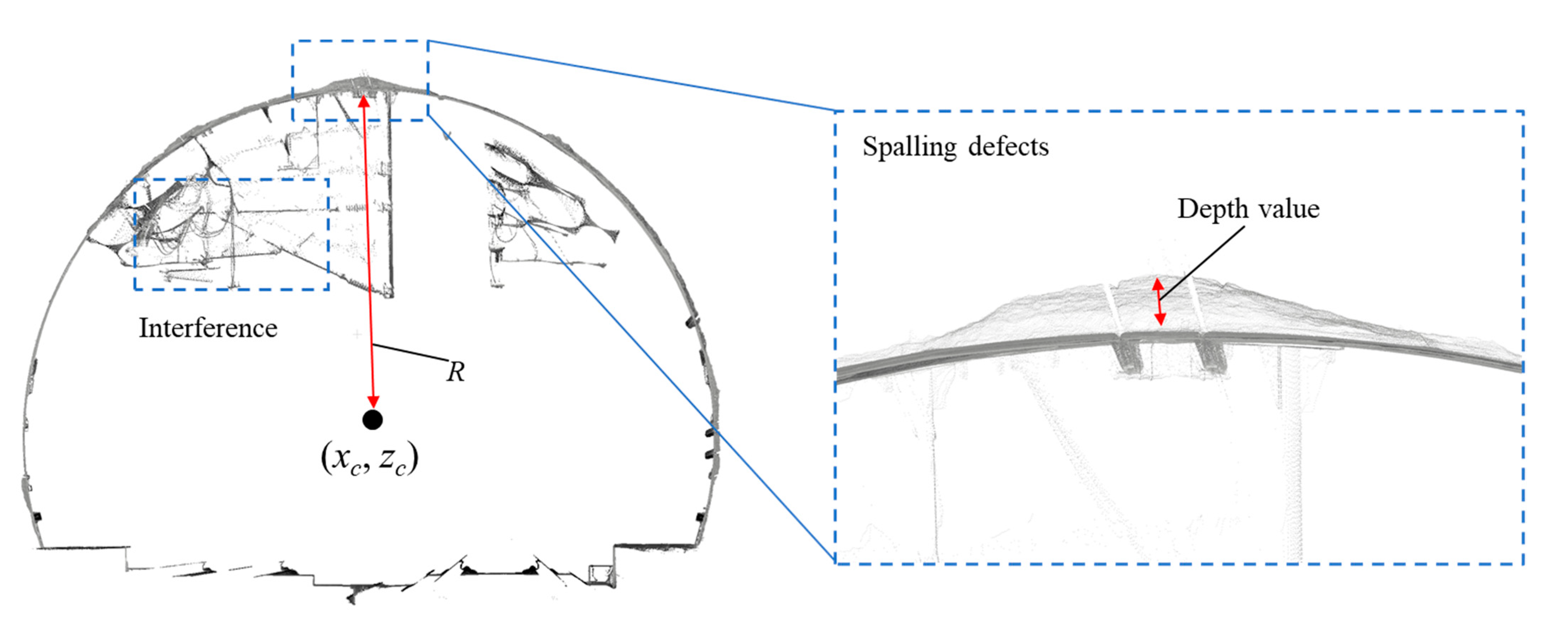
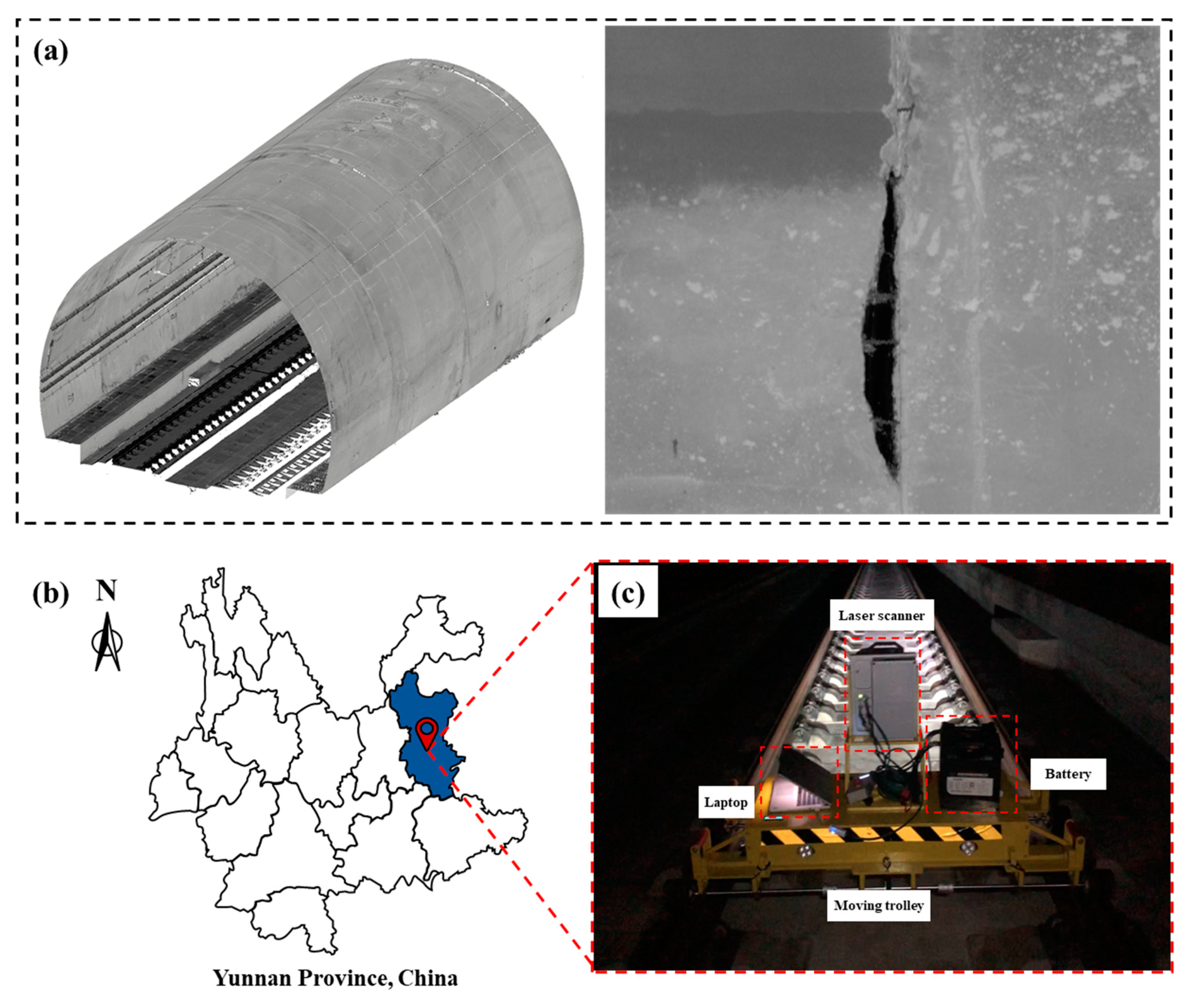
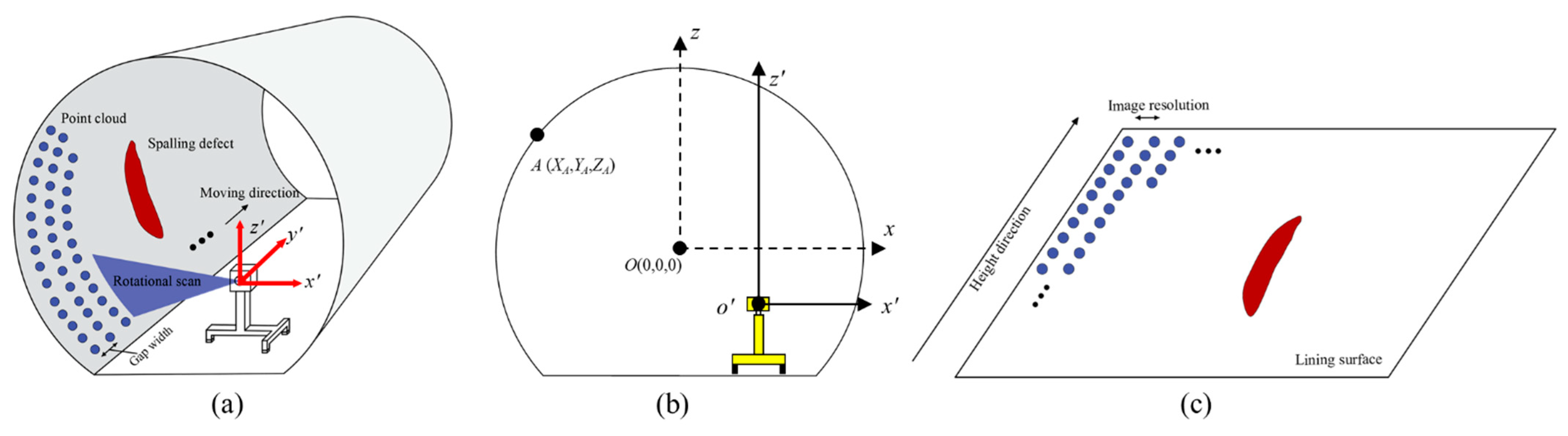
2.1. Point Cloud Data Acquisition
2.2. Intensity and Depth Images Conversion
2.3. Intensity and Depth Dataset for Spalling Detection
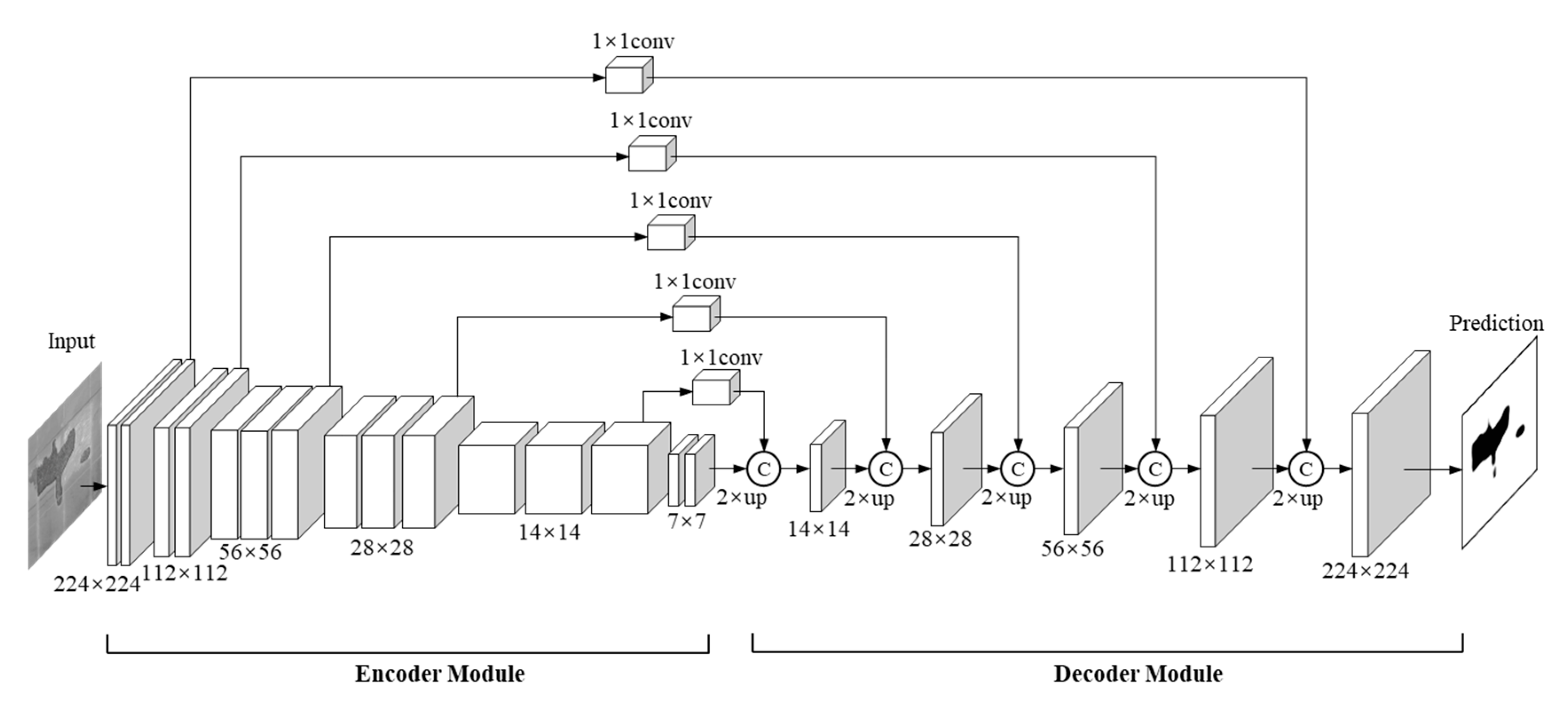
3. SIDNet for Spalling Inspection
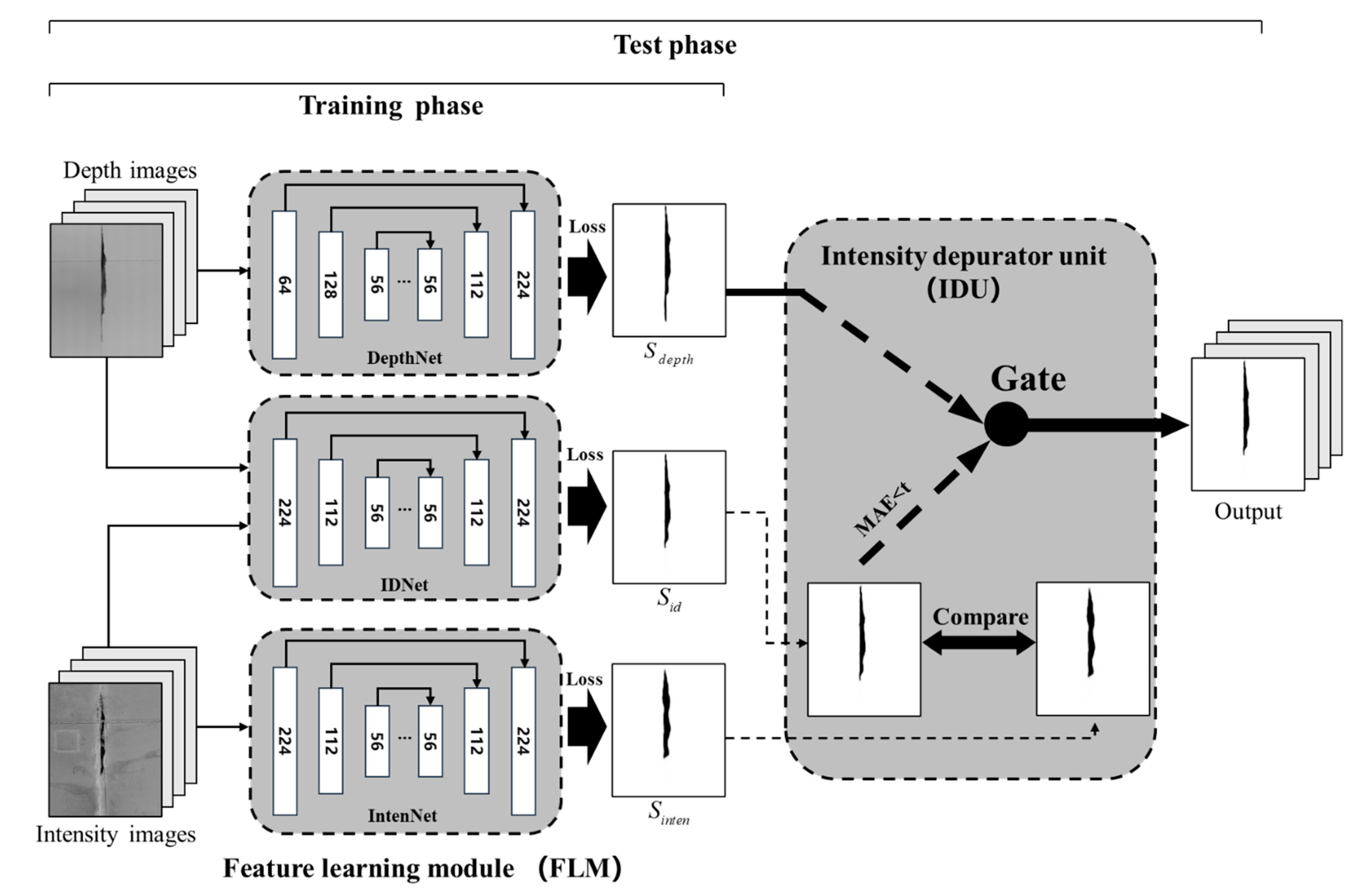
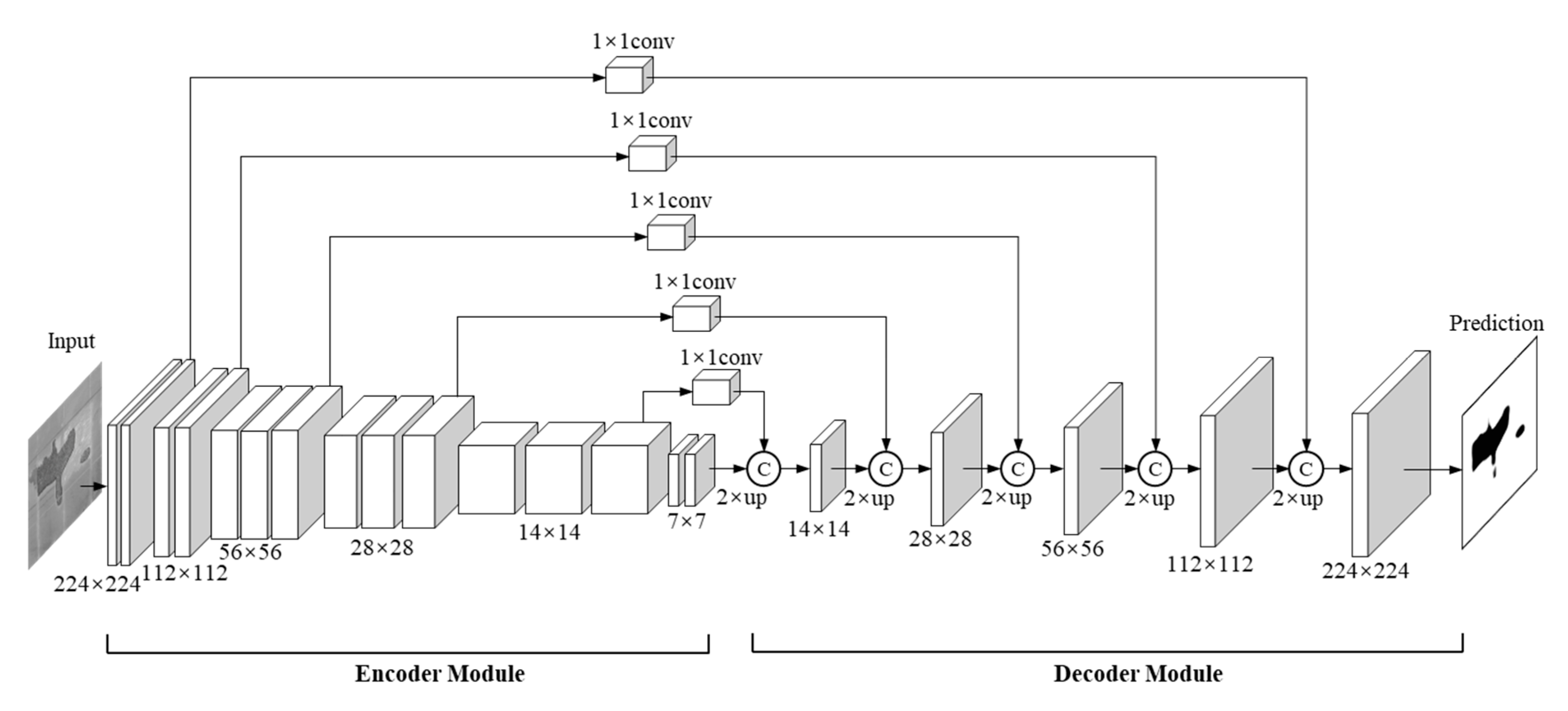
3.1. Three-Stream Feature Learning Module
3.2. Intensity Depurator Unit
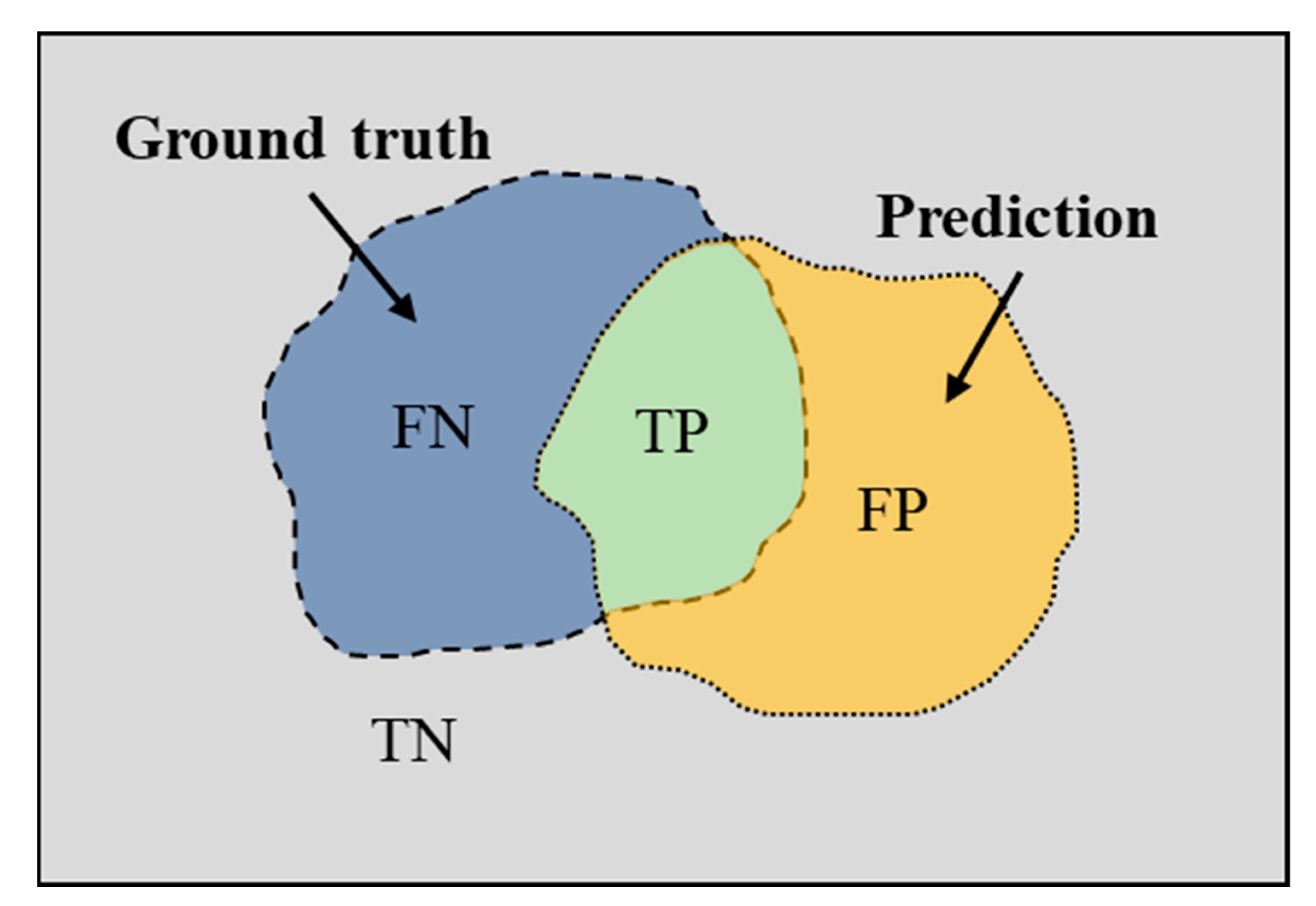
3.3. Network Evaluation Metric
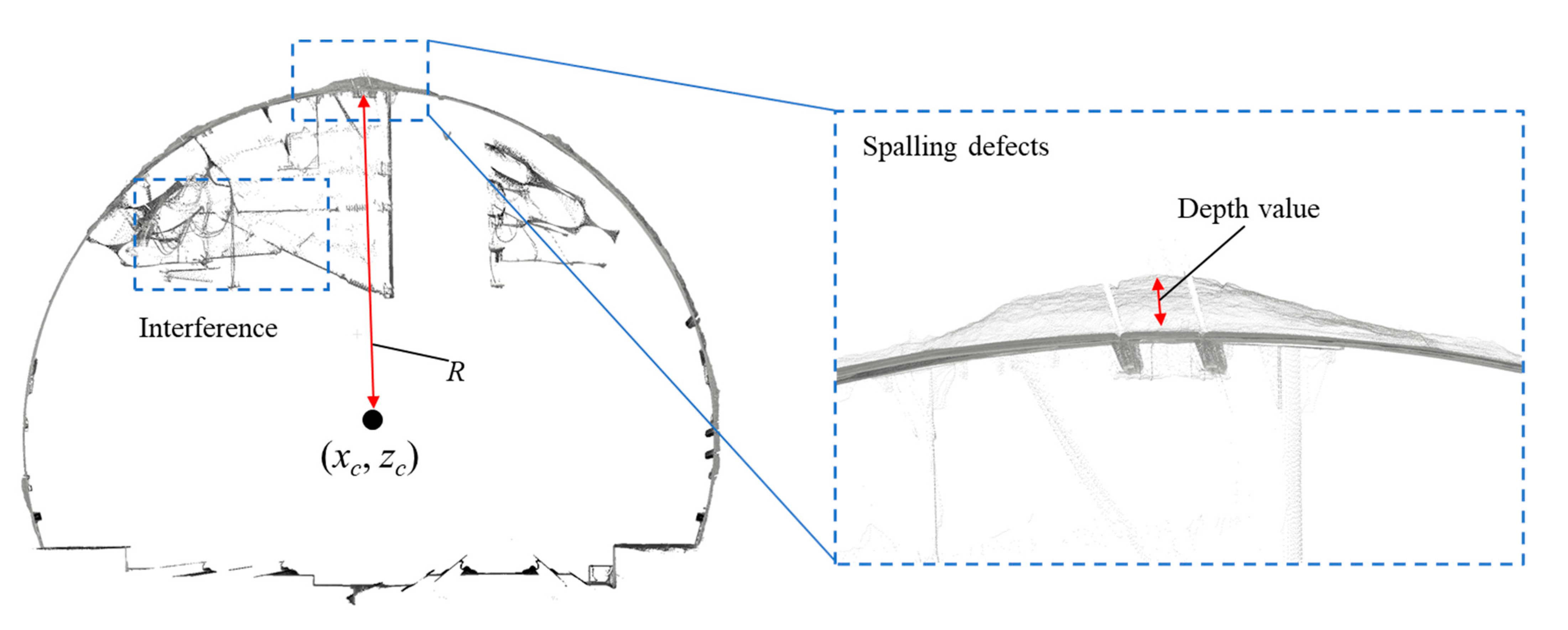
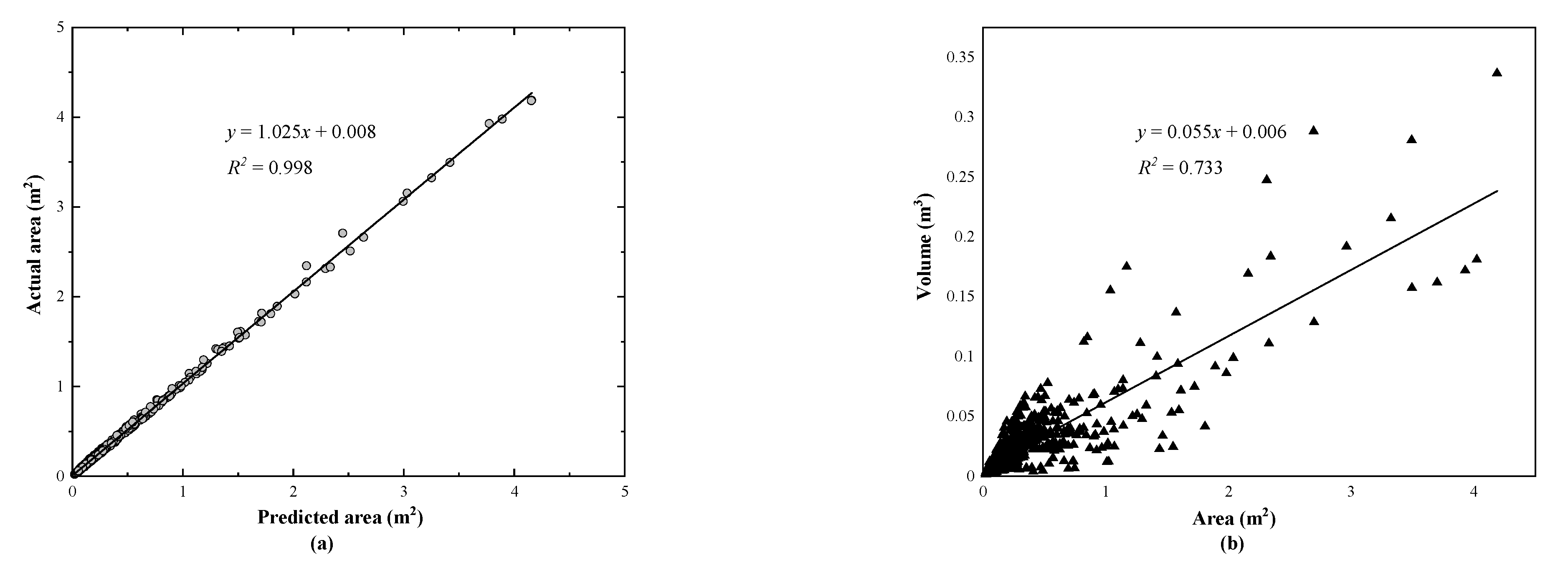
3.4. Quantitative Evaluation of Spalling Defects
4. Experiment and Results
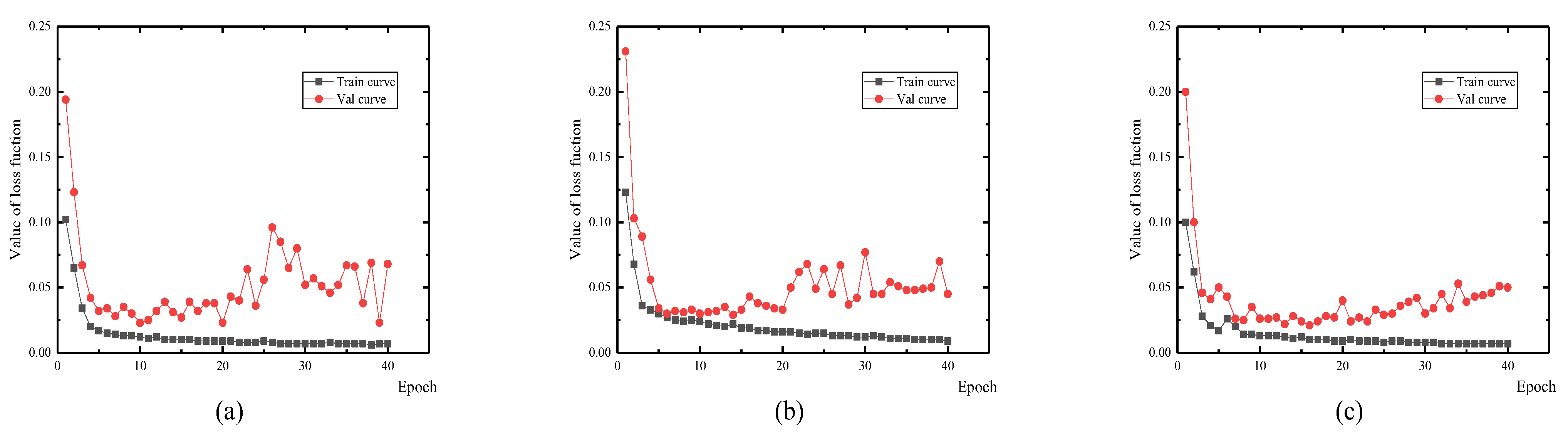
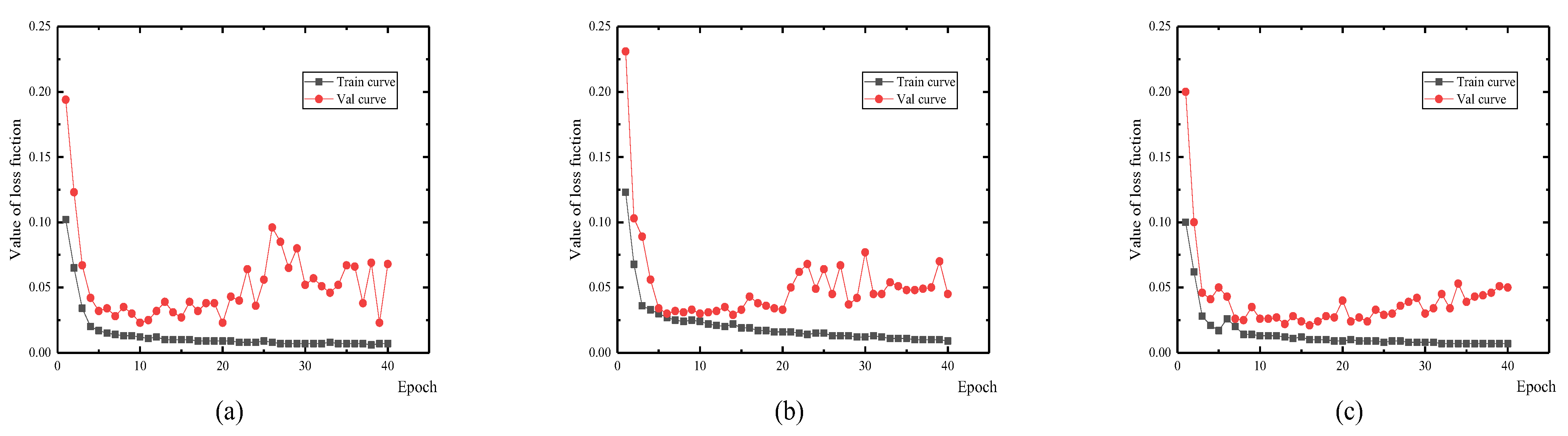
4.1. Training and Test Results
4.2. Segmentation Performance of the SIDNet
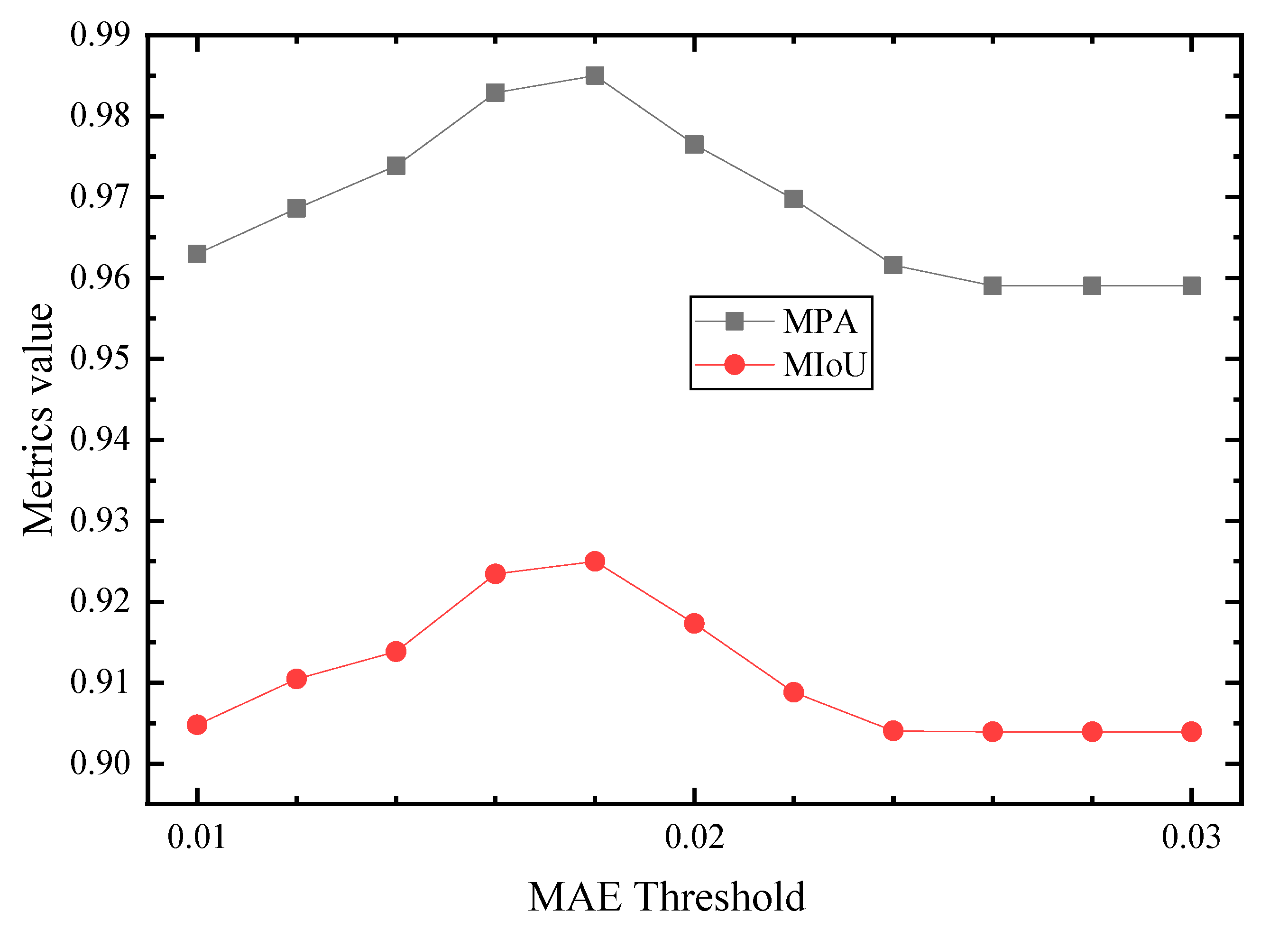
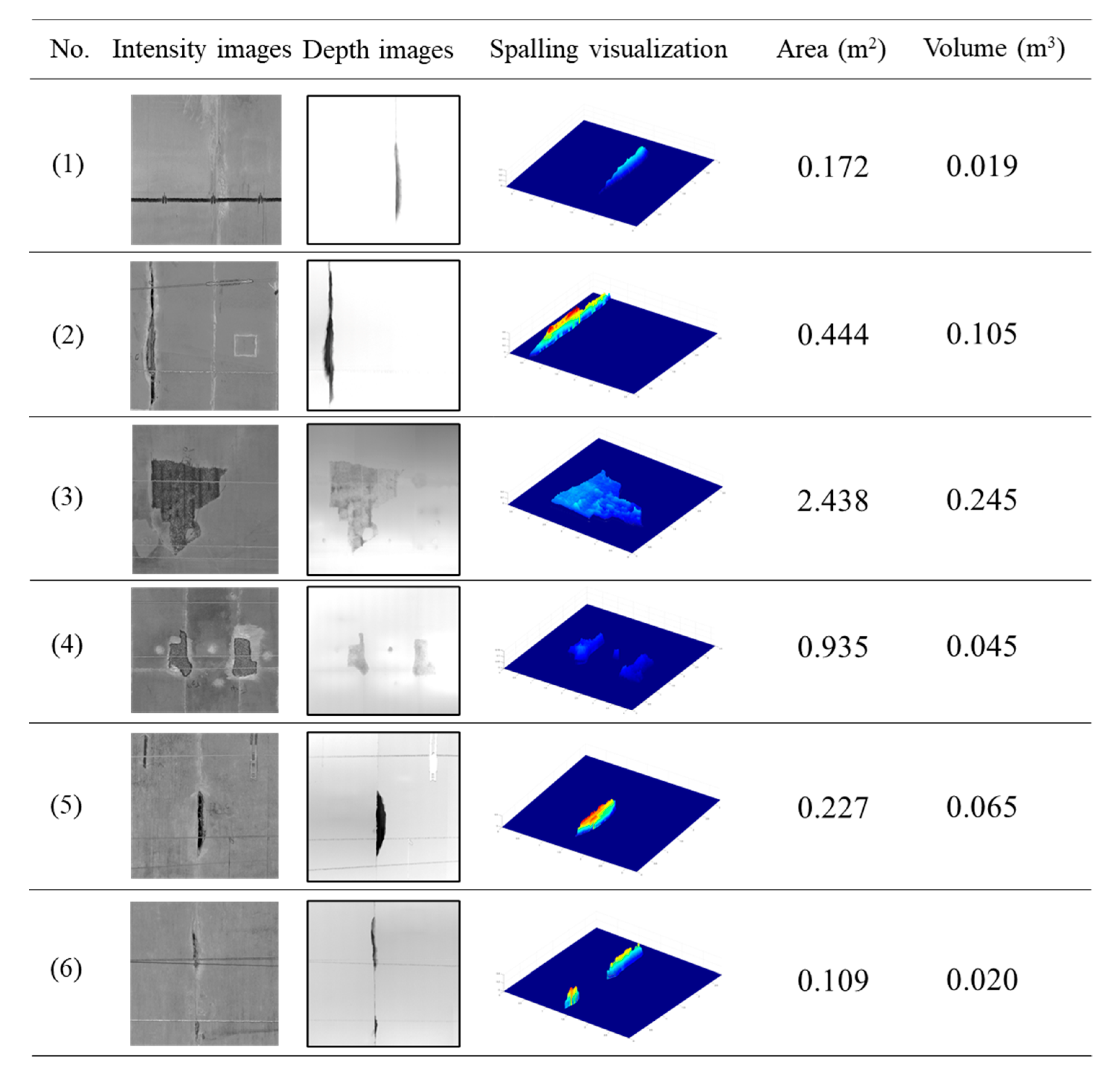
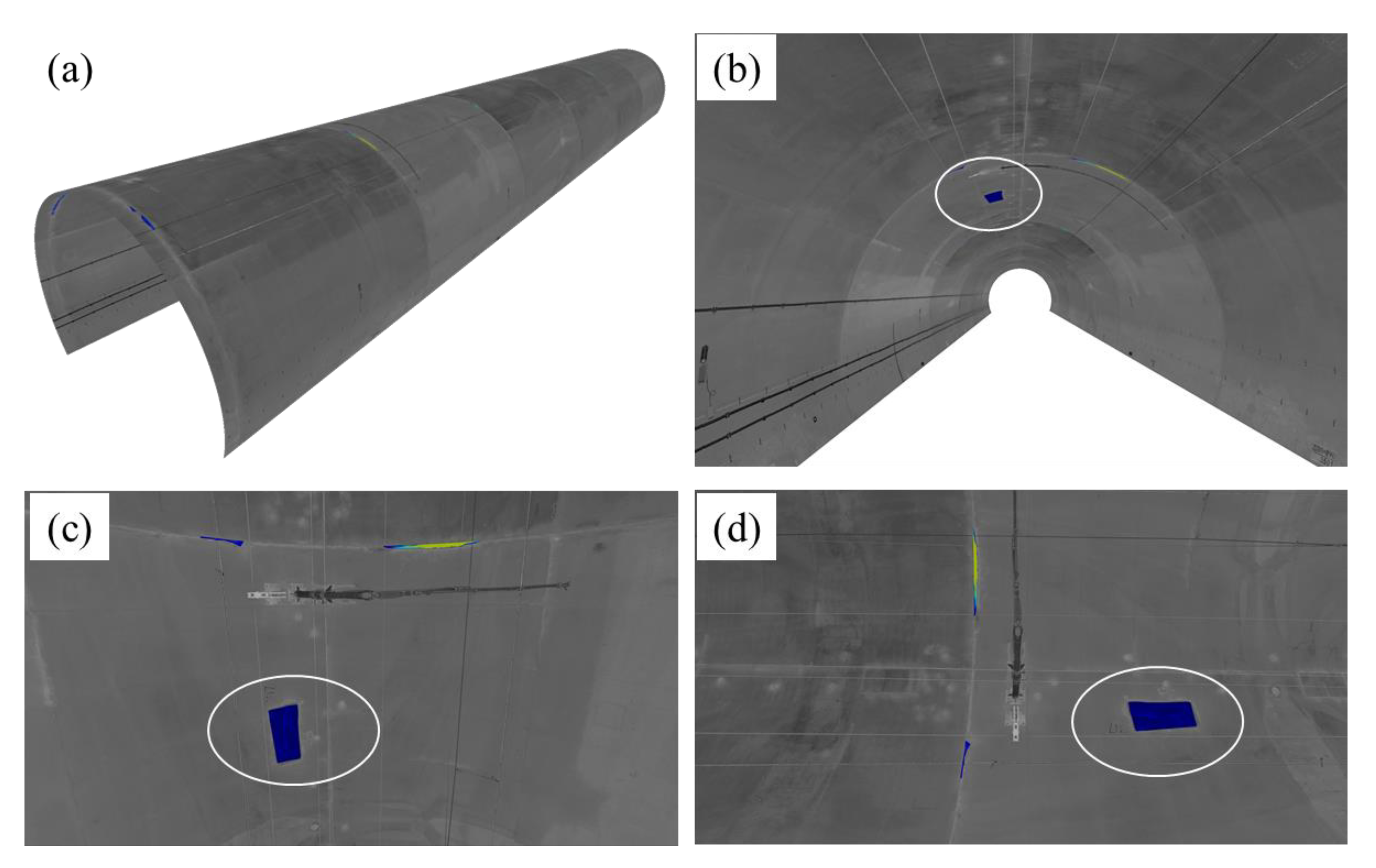
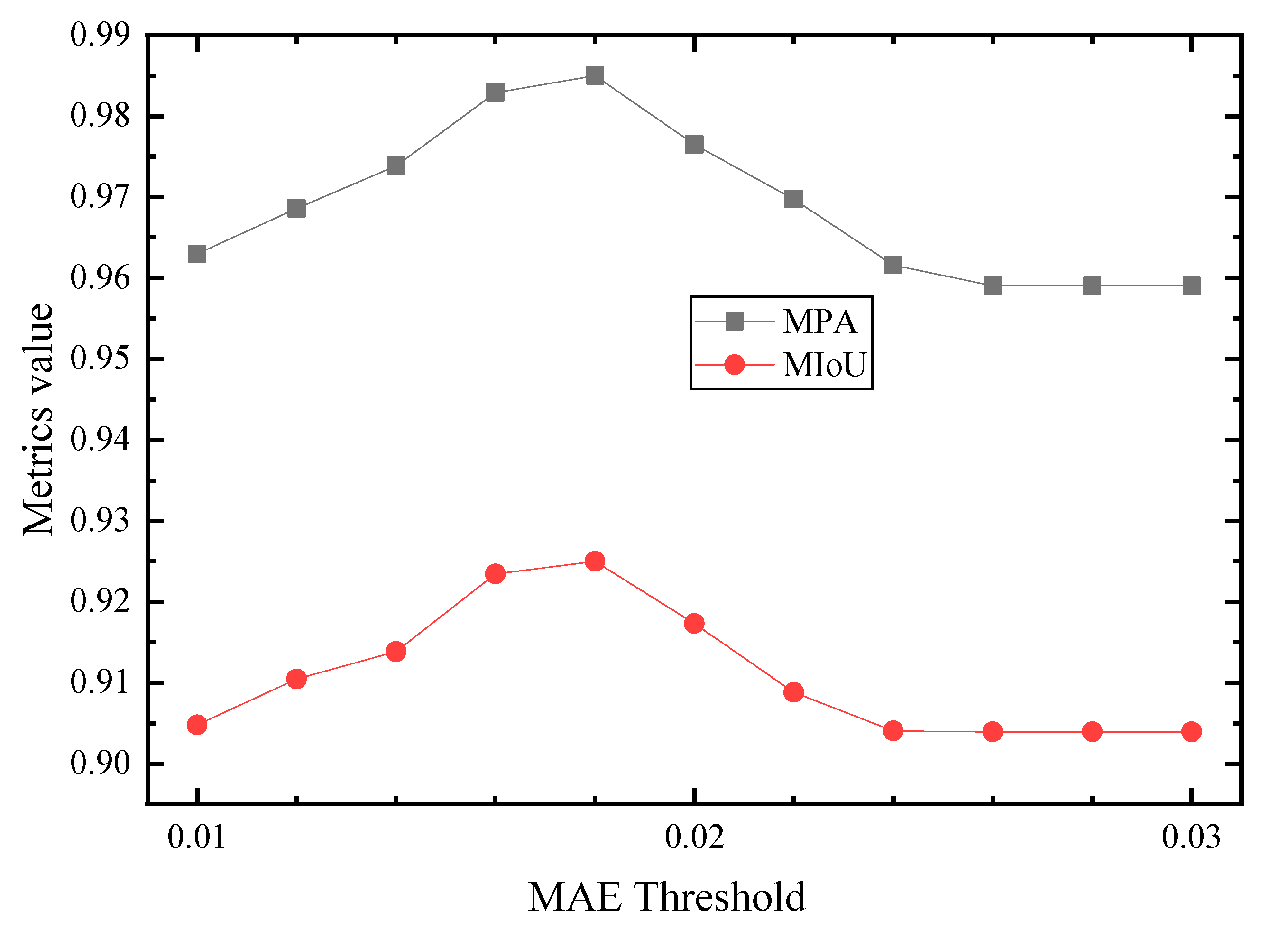
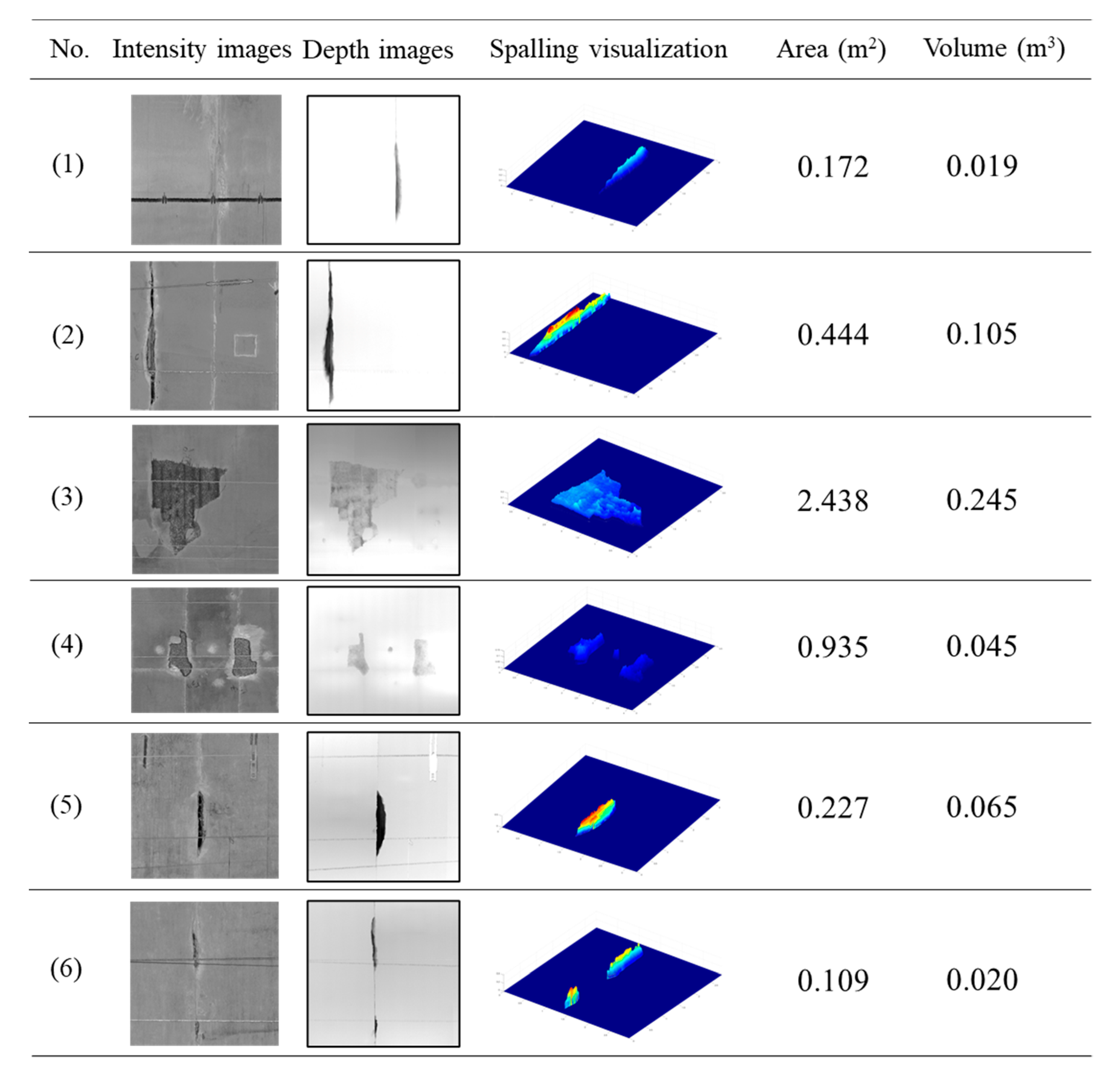
4.3. Evaluation of the Detected Spalling
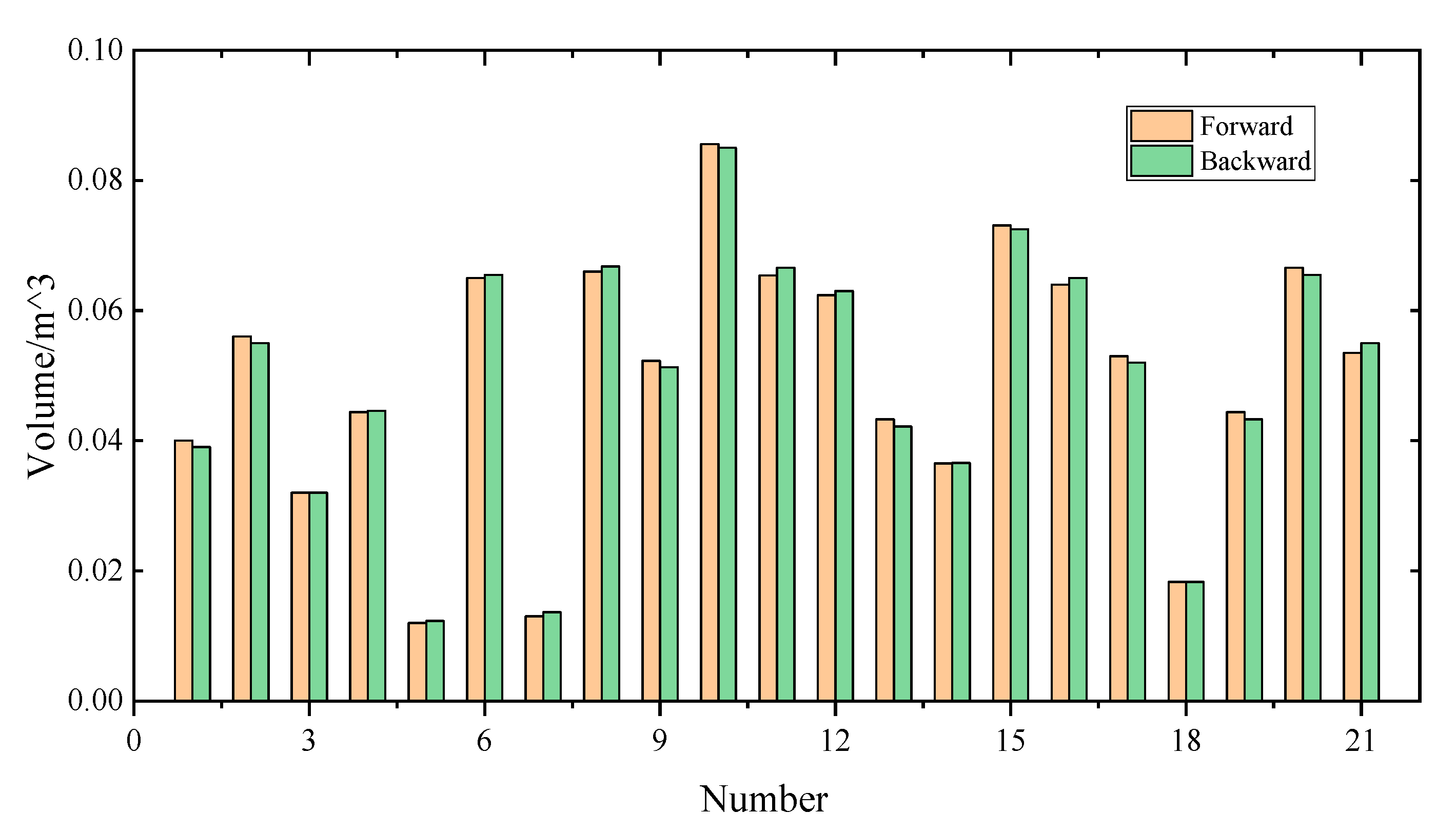
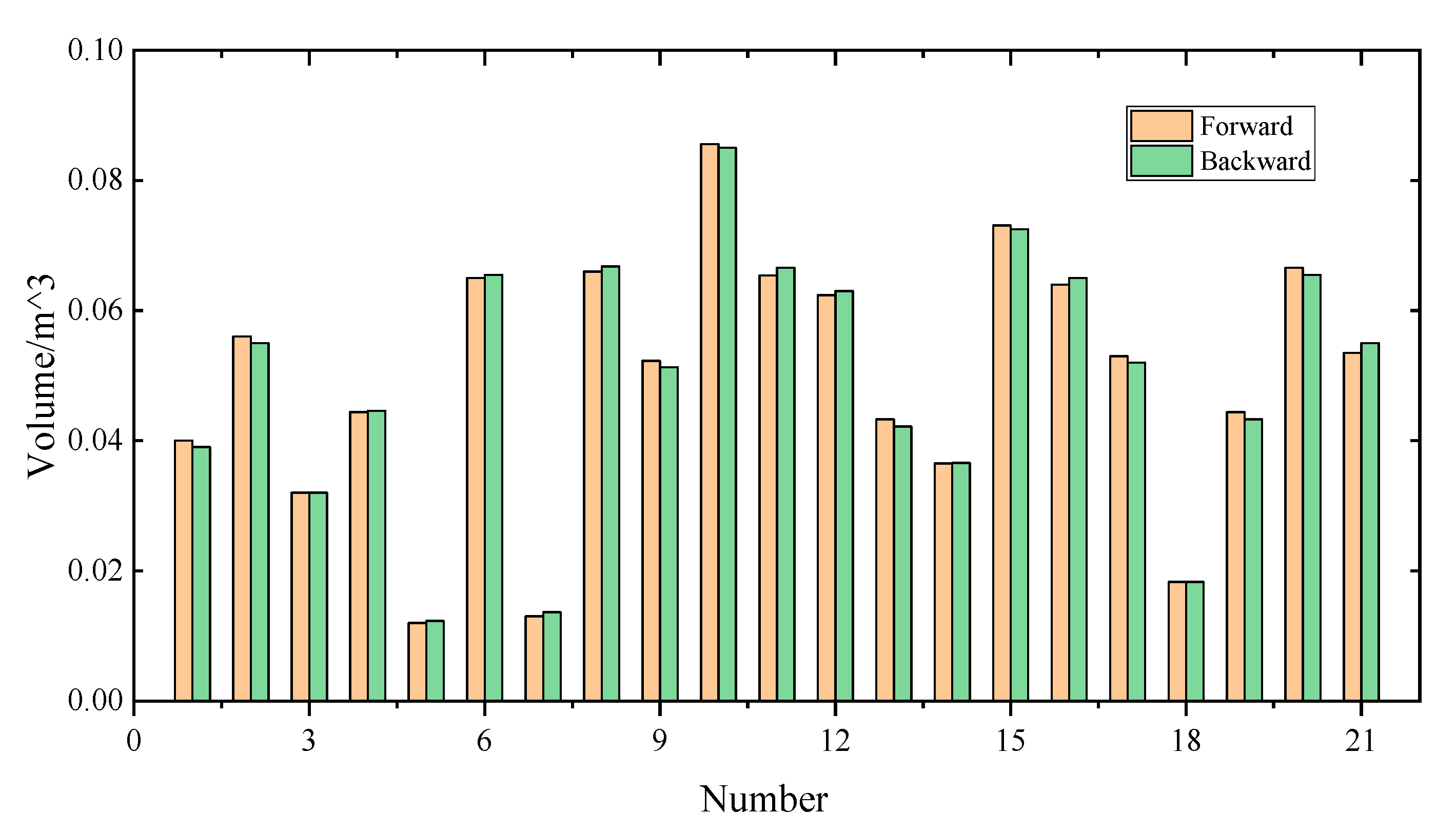
4.4. Robustness Test on the Proposed Approach
5. 3D Visualization and Inspection Report
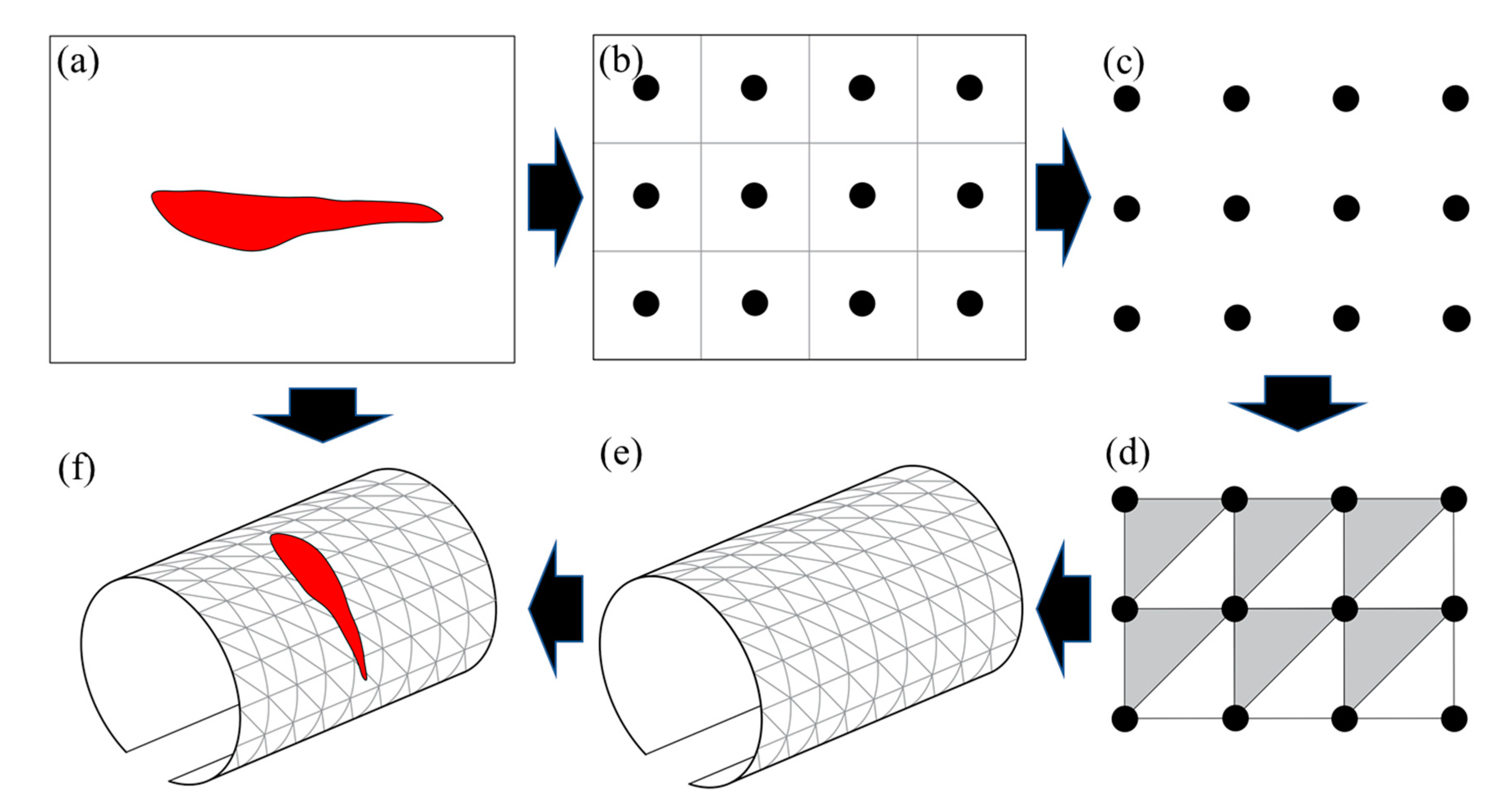
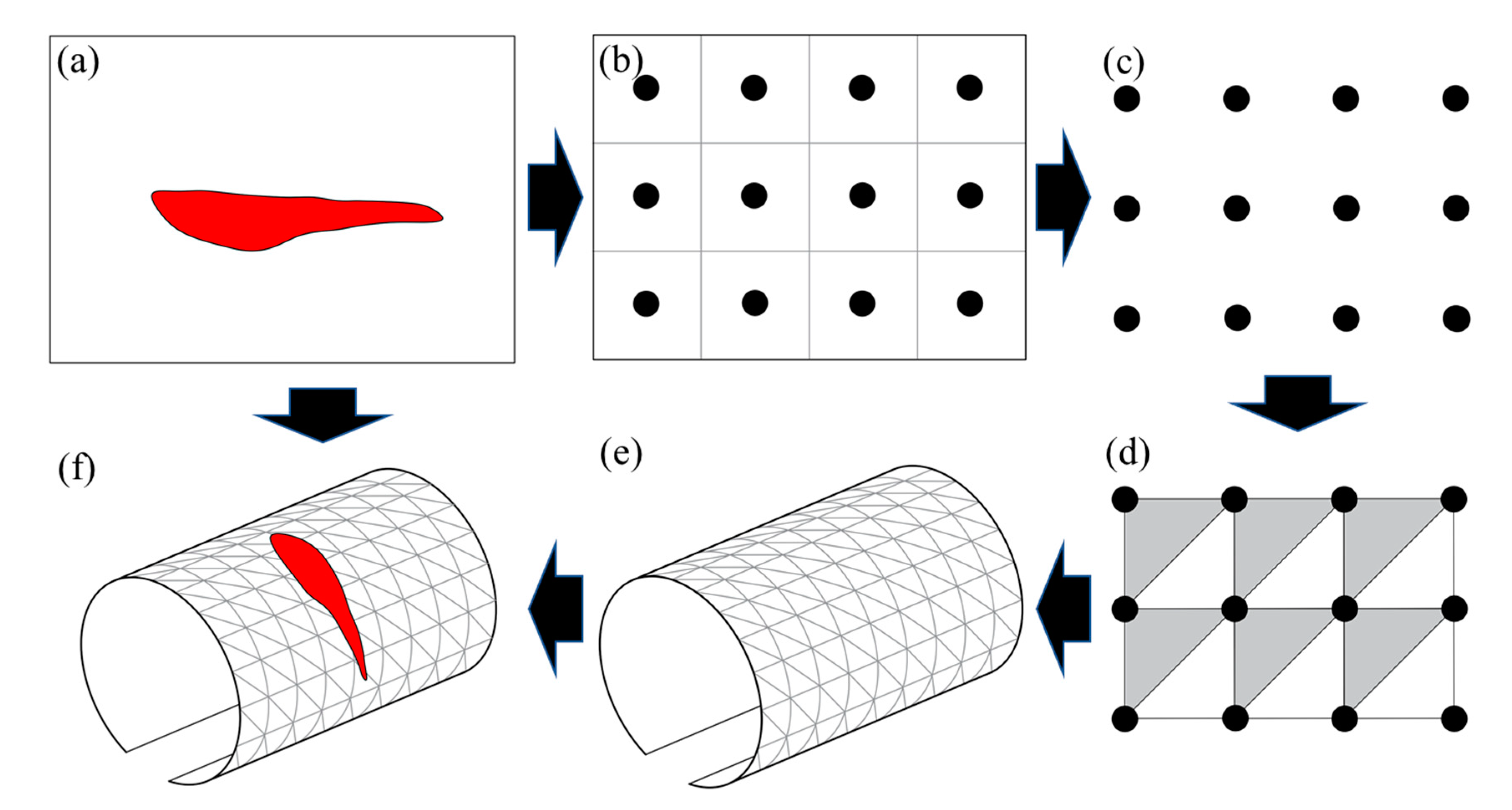
5.1. 3D Tunnel Model Reconstruction Method
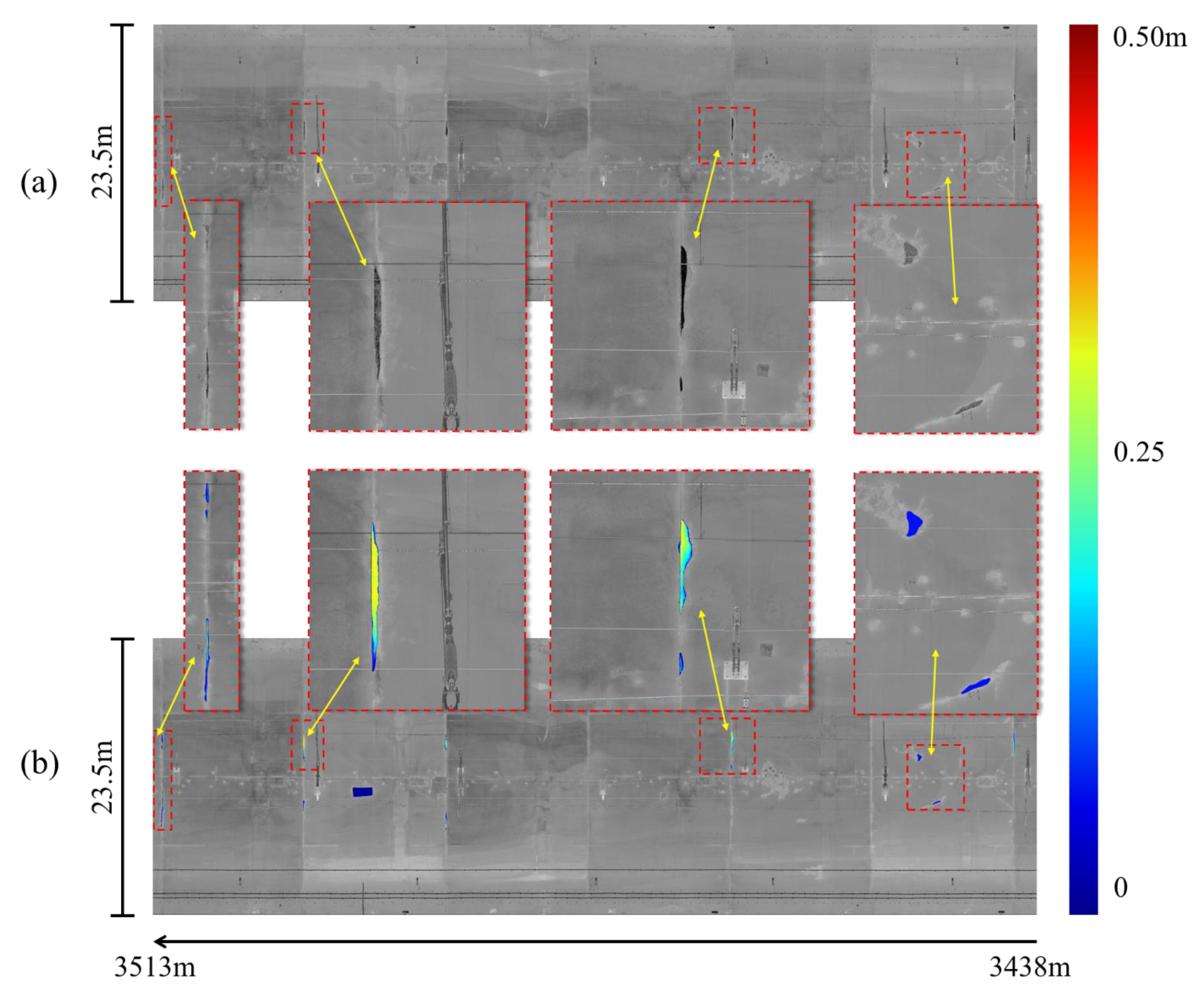
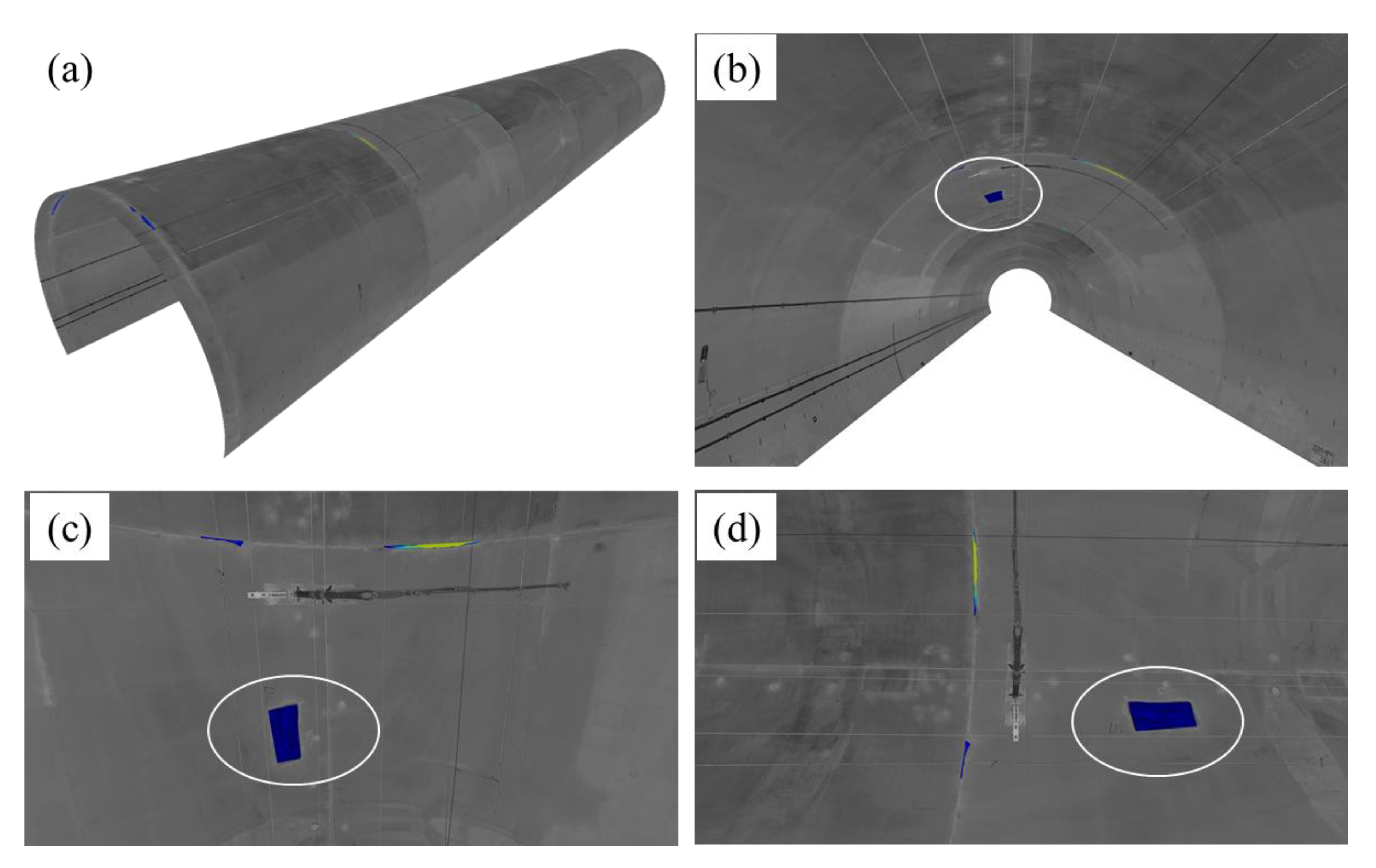
5.2. 3D Inspection Results of a Testing Tunnel Section
6. Discussion
6.1. The Advantages of the Proposed Approach
6.2. Possible Applications of the Proposed Approach
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dawood, T.; Zhu, Z.; Zayed, T. Machine vision-based model for spalling detection and quantification in subway networks. Autom. Constr. 2017, 81, 149–160. [Google Scholar] [CrossRef]
- Liu, D.; Wang, F.; Hu, Q.; Huang, H.; Zuo, J.; Tian, C.; Zhang, D. Structural responses and treatments of shield tunnel due to leakage: A case study. Tunn. Undergr. Space Technol. 2020, 103, 103471. [Google Scholar] [CrossRef]
- Zhao, S.; Shadabfar, M.; Zhang, D.; Chen, J.; Huang, H. Deep learning-based classification and instance segmentation of leakage-area and scaling images of shield tunnel linings. Struct. Control. Health Monit. 2021, 28, e2732. [Google Scholar] [CrossRef]
- Yuan, Y.; Jiang, X.; Liu, X. Predictive maintenance of shield tunnels. Tunn. Undergr. Space Technol. 2013, 38, 69–86. [Google Scholar] [CrossRef]
- Cui, H.; Ren, X.; Mao, Q.; Hu, Q.; Wang, W. Shield subway tunnel deformation detection based on mobile laser scanning. Autom. Constr. 2019, 106, 102889. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, S.; Mei, X.; Yin, W.; Lin, C.; Hu, Q.; Mao, Q. Railway tunnel clearance inspection method based on 3D point cloud from mobile laser scanning. Sensors 2017, 17, 2055. [Google Scholar] [CrossRef]
- Huang, H.; Sun, Y.; Xue, Y.; Wang, F. Inspection equipment study for subway tunnel defects by grey-scale image processing. Adv. Eng. Inf. 2017, 32, 188–201. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civil Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Tsai, Y.-C.; Kaul, V.; Mersereau, R.M. Critical assessment of pavement distress segmentation methods. J. Transp. Eng. 2010, 136, 11–19. [Google Scholar] [CrossRef]
- Sun, H.; Xu, Z.; Yao, L.; Zhong, R.; Du, L.; Wu, H. Tunnel monitoring and measuring system using mobile laser scanning: Design and deployment. Remote Sens. 2020, 12, 730. [Google Scholar] [CrossRef] [Green Version]
- Sánchez-Rodríguez, A.; Soilán, M.; Cabaleiro, M.; Arias, P. Automated inspection of railway tunnels’ power line using LiDAR point clouds. Remote Sens. 2019, 11, 2567. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Sha, H.; Ling, C.; Li, J. Intelligent Detection for Tunnel Shotcrete Spray Using Deep Learning and LiDAR. IEEE Access 2019, 8, 1755–1766. [Google Scholar]
- Wu, H.; Ao, X.; Chen, Z.; Liu, C.; Xu, Z.; Yu, P. Concrete Spalling Detection for Metro Tunnel from Point Cloud Based on Roughness Descriptor. J. Sens. 2019, 2019, 1–12. [Google Scholar] [CrossRef]
- Kim, M.-K.; Sohn, H.; Chang, C.-C. Localization and quantification of concrete spalling defects using terrestrial laser scanning. J. Comput. Civil Eng. 2015, 29, 04014086. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Zhao, S.; Zhang, D.; Chen, J. Deep learning-based instance segmentation of cracks from shield tunnel lining images. Struct. Infrastruct. Eng. 2020, 1–14. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, S.; Zhao, X.; Zhou, G. Automatic pixel-level multiple damage detection of concrete structure using fully convolutional network. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 616–634. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Mazzia, V.; Daneshgaran, F.; Mondin, M. Use of Deep Learning for Automatic Detection of Cracks in Tunnels. In Progresses in Artificial Intelligence and Neural Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 91–101. [Google Scholar]
- Xue, Y.; Li, Y. A fast detection method via region-based fully convolutional neural networks for shield tunnel lining defects. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 638–654. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, D.M.; Huang, H.W. Deep learning–based image instance segmentation for moisture marks of shield tunnel lining. Tunn. Undergr. Space Technol. 2020, 95, 103156. [Google Scholar] [CrossRef]
- Huang, H.; Li, Q.; Zhang, D. Deep learning based image recognition for crack and leakage defects of metro shield tunnel. Tunn. Undergr. Space Technol. 2018, 77, 166–176. [Google Scholar] [CrossRef]
- Xu, Y.; Li, D.; Xie, Q.; Wu, Q.; Wang, J. Automatic defect detection and segmentation of tunnel surface using modified Mask R-CNN. Measurement 2021, 178, 109316. [Google Scholar] [CrossRef]
- Chen, J.; Yang, T.; Zhang, D.; Huang, H.; Tian, Y. Deep learning based classification of rock structure of tunnel face. Geosci. Front. 2021, 12, 395–404. [Google Scholar] [CrossRef]
- Chen, J.; Zhou, M.; Zhang, D.; Huang, H.; Zhang, F. Quantification of water inflow in rock tunnel faces via convolutional neural network approach. Autom. Constr. 2021, 123, 103526. [Google Scholar] [CrossRef]
- Chen, J.; Zhou, M.; Huang, H.; Zhang, D.; Peng, Z. Automated extraction and evaluation of fracture trace maps from rock tunnel face images via deep learning. Int. J. Rock Mech. Min. Sci. 2021, 142, 104745. [Google Scholar] [CrossRef]
- Mostafa, K.; Hegazy, T. Review of image-based analysis and applications in construction. Autom. Constr. 2021, 122, 103516. [Google Scholar] [CrossRef]
- Zhou, T.; Fan, D.; Cheng, M.; Shen, J.; Shao, L. RGB-D salient object detection: A survey. Comput. Vis. Media 2021, 7, 37–69. [Google Scholar] [CrossRef] [PubMed]
- Lang, C.; Nguyen, T.V.; Katti, H.; Yadati, K.; Kankanhalli, M.; Yan, S. Depth matters: Influence of depth cues on visual saliency. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Han, J.; Chen, H.; Liu, N.; Yan, C.; Li, X. CNNs-based RGB-D saliency detection via cross-view transfer and multiview fusion. IEEE Trans. Cybern. 2017, 48, 3171–3183. [Google Scholar] [CrossRef]
- Qu, L.; He, S.; Zhang, J.; Tian, J.; Tang, Y.; Yang, Q. RGBD salient object detection via deep fusion. IEEE Trans. Image Process. 2017, 26, 2274–2285. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Li, Y.; Su, D. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognit. 2019, 86, 376–385. [Google Scholar] [CrossRef]
- Chen, H.; Li, Y. Three-stream attention-aware network for RGB-D salient object detection. IEEE Trans. Image Process. 2019, 28, 2825–2835. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Cao, Y.; Fan, D.; Cheng, M.; Li, X.; Zhang, L. Contrast prior and fluid pyramid integration for RGBD salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Fu, K.; Fan, D.; Ji, G.; Zhao, Q. JL-DCF: Joint learning and densely-cooperative fusion framework for rgb-d salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Fan, D.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M. Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2075–2089. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Fan, D.; Dai, Y.; Anwar, S.; Saleh, F.; Aliakbarian, S.; Barnes, N. Uncertainty inspired RGB-D saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Attard, L.; Debono, C.J.; Valentino, G.; Di Castro, M. Vision-based change detection for inspection of tunnel liners. Autom. Constr. 2018, 91, 142–154. [Google Scholar] [CrossRef]
- Lee, C.-H.; Chiu, Y.-C.; Wang, T.-T.; Huang, T.-H. Application and validation of simple image-mosaic technology for interpreting cracks on tunnel lining. Tunn. Undergr. Space Technol. 2013, 34, 61–72. [Google Scholar] [CrossRef]
- Chaiyasarn, K.; Kim, T.-K.; Viola, F.; Cipolla, R.; Soga, K. Distortion-free image mosaicing for tunnel inspection based on robust cylindrical surface estimation through structure from motion. J. Comput. Civil Eng. 2016, 30, 04015045. [Google Scholar] [CrossRef]
- Xue, Y.; Zhang, S.; Zhou, M.; Zhu, H. Novel SfM-DLT method for metro tunnel 3D reconstruction and Visualization. Undergr. Space 2021, 6, 134–141. [Google Scholar] [CrossRef]
- Stent, S.; Gherardi, R.; Stenger, B.; Soga, K.; Cipolla, R. Visual change detection on tunnel linings. Mach. Vis. Appl. 2016, 27, 319–330. [Google Scholar] [CrossRef]
- Torok, M.M.; Golparvar-Fard, M.; Kochersberger, K.B. Image-based automated 3D crack detection for post-disaster building assessment. J. Comput. Civil Eng. 2014, 28, A4014004. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, R.; Chen, W.; Sun, H.; Ren, Y.; Lei, N.J.I.G.; Letters, R.S. Study of Tunnel Surface Parameterization of 3-D Laser Point Cloud Based on Harmonic Map. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1623–1627. [Google Scholar] [CrossRef]
- Ao, X.; Wu, H.; Xu, Z.; Gao, Z. Damage Extraction of Metro Tunnel Surface from Roughness Map Generated by Point Cloud. In Proceedings of the 2018 26th International Conference on Geoinformatics, Kunming, China, 28–30 June 2018. [Google Scholar]
- Huang, H.; Cheng, W.; Zhou, M.; Chen, J.; Zhao, S. Towards Automated 3D Inspection of Water Leakages in Shield Tunnel Linings Using Mobile Laser Scanning Data. Sensors 2020, 20, 6669. [Google Scholar] [CrossRef]
- Sun, H.; Liu, S.; Zhong, R.; Du, L. Cross-section deformation analysis and visualization of shield tunnel based on mobile tunnel monitoring system. Sensors 2020, 20, 1006. [Google Scholar] [CrossRef] [Green Version]
- Yue, Z.; Sun, H.; Zhong, R.; Du, L. Method for Tunnel Displacements Calculation Based on Mobile Tunnel Monitoring System. Sensors 2021, 21, 4407. [Google Scholar] [CrossRef]
- Yi, C.; Lu, D.; Xie, Q.; Liu, S.; Li, H.; Wei, M.; Wang, J. Hierarchical tunnel modeling from 3D raw LiDAR point cloud. Comput.-Aided Des. 2019, 114, 143–154. [Google Scholar] [CrossRef]
- Fitzgibbon, A.; Pilu, M.; Fisher, R.B. Direct least square fitting of ellipses. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 476–480. [Google Scholar] [CrossRef] [Green Version]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Ai, Q.; Yuan, Y.; Bi, X. Acquiring sectional profile of metro tunnels using charge-coupled device cameras. Struct. Infrastruct. Eng. 2016, 12, 1065–1075. [Google Scholar] [CrossRef]
- Tsai, C.-M. Adaptive local power-law transformation for color image enhancement. Appl. Math. Inform. Sci. 2013, 7, 2019. [Google Scholar] [CrossRef]
- Wada, K. Labelme: Image Polygonal Annotation with Python. GitHub Repository. 2016. Available online: https://github.com/wkentaro/labelme (accessed on 20 August 2021).
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Zurich, Switzerland, 5–12 September 2014. [Google Scholar]
- Xue, Y.; Cai, X.; Shadabfar, M.; Shao, H.; Zhang, S. Deep learning-based automatic recognition of water leakage area in shield tunnel lining. Tunn. Undergr. Space Technol. 2020, 104, 103524. [Google Scholar] [CrossRef]
- Yu, A.; Mei, W.; Han, M. Deep learning based method of longitudinal dislocation detection for metro shield tunnel segment. Tunn. Undergr. Space Technol. 2021, 113, 103949. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Training | Validation | Testing | Total Number |
|---|---|---|---|---|
| Intensity | 5664 | 1619 | 809 | 8092 |
| Depth | 5664 | 1619 | 809 | 8092 |
| GT | 5664 | 1619 | 809 | 8092 |
| IntenNet | DepthNet | IDNet | SIDNet | D3Net | UC-Net | DeeplabV3+ | OTSU | |
|---|---|---|---|---|---|---|---|---|
| MPA | 0.904 | 0.957 | 0.970 | 0.985 | 0.935 | 0.971 | 0.881 | 0.519 |
| MIoU | 0.838 | 0.905 | 0.911 | 0.925 | 0.874 | 0.907 | 0.792 | 0.409 |
| Spalling No. | Mileage (m) | Start Angle (°) | End Angle (°) | Area (m2) | Volume (m3) |
|---|---|---|---|---|---|
| #1 | 3438 | 132 | 134 | 0.031 | 0.017 |
| #2 | 3438 | 101 | 120 | 0.187 | 0.028 |
| #3 | 3446 | 96 | 103 | 0.086 | 0.004 |
| #4 | 3445 | 79 | 82 | 0.103 | 0.004 |
| #5 | 3463 | 103 | 122 | 0.254 | 0.053 |
| #6 | 3463 | 92 | 94 | 0.037 | 0.003 |
| #7 | 3488 | 115 | 121 | 0.107 | 0.017 |
| #8 | 3488 | 64 | 73 | 0.089 | 0.012 |
| #9 | 3495 | 80 | 85 | 1.253 | 0.075 |
| #10 | 3501 | 100 | 121 | 0.356 | 0.068 |
| #11 | 3501 | 76 | 80 | 0.121 | 0.010 |
| #12 | 3513 | 117 | 119 | 0.118 | 0.009 |
| #13 | 3513 | 115 | 116 | 0.065 | 0.004 |
| #14 | 3513 | 63 | 85 | 0.347 | 0.031 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, M.; Cheng, W.; Huang, H.; Chen, J. A Novel Approach to Automated 3D Spalling Defects Inspection in Railway Tunnel Linings Using Laser Intensity and Depth Information. Sensors 2021, 21, 5725. https://doi.org/10.3390/s21175725
Zhou M, Cheng W, Huang H, Chen J. A Novel Approach to Automated 3D Spalling Defects Inspection in Railway Tunnel Linings Using Laser Intensity and Depth Information. Sensors. 2021; 21(17):5725. https://doi.org/10.3390/s21175725
Chicago/Turabian StyleZhou, Mingliang, Wen Cheng, Hongwei Huang, and Jiayao Chen. 2021. "A Novel Approach to Automated 3D Spalling Defects Inspection in Railway Tunnel Linings Using Laser Intensity and Depth Information" Sensors 21, no. 17: 5725. https://doi.org/10.3390/s21175725
APA StyleZhou, M., Cheng, W., Huang, H., & Chen, J. (2021). A Novel Approach to Automated 3D Spalling Defects Inspection in Railway Tunnel Linings Using Laser Intensity and Depth Information. Sensors, 21(17), 5725. https://doi.org/10.3390/s21175725