1. Introduction
With the advent of the 21st century, autonomous robots have become an integral part of intelligent machines for performing various tasks including inspection, manufacturing, warehouse handling, and maintenance (cleaning, dusting and painting etc.). Among them, autonomous cleaning robots play a vital role in many day to day activities and also in industrial automation applications [
1,
2]. These robots have become the need of the day due to the large demand in household works, hospitals and industries. There are many commercially available autonomous cleaning robots in the market. However, these robots are designed for single floor operations and their mechanism cannot support staircase navigation to reach the next floor. They are also not capable of cleaning the steps of the staircases [
3]. Various staircase climbing robotic architectures have been proposed for different applications. These include staircase climbing wheelchairs [
4,
5,
6], rescue operations in disasters [
7,
8] and security applications [
9]. While there are many such applications, very few works have been reported on the design of cleaning robots with staircase climbing capabilities. Takahisa et al. [
10,
11] proposed an autonomous cleaning robot suitable for both flat surfaces and staircases. in this work, an L-shaped leg was designed to climb down the staircase. A vertical climbing mechanism based staircase cleaning robot is reported by Rajesh et al. [
12]. In [
3,
13], the authors propose a modular re-configurable robot sTetro for staircase cleaning where the robot is equipped with a vertical conveyor mechanism for climbing the staircase. Generally, these robots use an array of sensors such as 2D LiDAR and 1D laser sensors [
3,
13] and Position Sensitive Detectors (PSDs) [
10,
11] to recognize their environment. However, these sensors only provide limited information about the environment due to their limited capability when it comes to recognizing the object type. In addition, they are not capable of detecting obstacles or debris, which is crucial for safe operation and efficient cleaning.
Computer vision based environmental perception has been widely deployed for various autonomous robotic platforms [
14,
15,
16,
17]. These methods are cost effective and are capable of operating in a wide range of scenarios. Instead of traditional computer vision based techniques, learning based environmental perception (e.g., Deep Learning) is a new paradigm. The deep learning neural network layers can learn features to distinguish and determine objects at high accuracy and can be used in various vision tasks such as outdoor environmental perception for autonomous vehicles [
18,
19,
20], cleaning and maintenance robot vision pipeline [
2,
21,
22,
23,
24], mobile robot place recognition and mapping tasks [
25,
26,
27,
28]. While these state-of-the-art deep learning algorithms have achieved impressive results for environment perception design, there are some shortcomings such as false detection, which can be due to objects with similar features. This can lead to inconsistencies during real-time robotic applications. One approach to solve this issue is by using additional data, such as depth information.
Recently, many works have been reported with depth based fusion to overcome the false detection of objects and improve the model’s classification accuracy [
29,
30,
31,
32,
33]. In [
31,
32] authors propose a RGB-D based object detection technique and describe how to utilize the depth information to effectively enhance the detection quality. In these implementations, the first one adds the fourth channel for depth directly, and then equally convolutes all channels in one network [
31]. The other separately processes the depth and color (RGB) using two independent networks [
32]. Tanguy et al. [
33] fused the depth information and RGB data to increase the detection performance of the YOLOv2 object detection framework. Here, the author introduced a fusion layer architecture for combining the depth and RGB detection networks. Even though many works have explored the advantages of using deep learning techniques for detection applications, none of these works are targeted towards environmental perception for staircase cleaning robots.
This work proposes an operation framework empowered by the deep learning based environmental perception system for our modular re-configurable staircase cleaning robot sTetro [
3,
13]. The environmental perception system assists the robot in makings decisions, such as recognizing the staircases for autonomous stair climbing operation, static and dynamic obstacle detection for safe navigation and debris detection for efficient cleaning.
The flow of the paper is organized as follows: The architecture of the sTetro platform is detailed in
Section 2 and
Section 3, which describe the proposed EPS and autonomous staircase climbing scheme. This is followed by the experimental setup and results in
Section 4. Finally,
Section 5 describes the conclusions and future work.
2. Brief Overview of sTetro
sTetro is a modular re-configurable cleaning and maintenance robot developed by our ROAR lab. The general view and exploded view of sTetro are shown in
Figure 1a,b. Its body is comprised of three cuboids. The slider mechanism mounted on both the front and the back of the central (second) cuboid interconnects with the first and third cuboids. Each cuboid is a vertical block with hollow space which contains the control circuits, debris collection chamber, suction fan, and sweeping mechanism. The vertical conveyor belt mechanism enables the robot to climb the staircase as shown in
Figure 2. The limitation of being able to clean only a single floor is overcome by modular design with a re-configurable mechanism.
Hardware and Software Description
sTetro hardware architecture is comprised of Jetson Nano hardware module with RGB-D camera, Arduino with DC motor control unit and sensor unit as shown in
Figure 3.
Here, the Jetson Nano module acts as a Central Control Unit (CCU) which controls the entire operation of the robot. The module is comprised of ARM A57 CPU and 128 Core maxwell GPU with 4GB memory for real-time deep learning inference and running on Ubuntu 18. The processing unit utilizes Rosserial communication interface to enable the communication between ROS nodes, and other modules include environmental perception unit and Arduino control blocks. This bridge is used to communicate the sensor data and trajectory information between Arduino Mega microcontroller and Jetson Nano unit.
Arduino mega microcontroller performs the locomotion control and onboard sensor interface. It collects the data from the various sensor modules and sends it CCU. The control signal to the DC motor unit based on the received trajectory information is generated using inbuilt PWM module.
Various sensors are integrated to perform the self-reconfiguration and locomotion tasks (
Figure 4a). Bump sensors were used to detect the inner string of the staircase, and six bump sensors were assembled on both the left and right sides of the robot. For staircase riser detection, we provide two Time Of Flight distance sensors (TOF) mounted on the front face of the first block, and two mechanical limit switches assembled in front of the second and third blocks. Furthermore, at the bottom of all three blocks, we provide Time Of Flight distance sensors (TOF) to detect the staircase runner on each step while climbing. The detail of motor and all sensor detail and its communication protocol is given in
Table 1.
Figure 4b shows the locomotion unit assembly. Adafruit servo shields are used to drive the four high torque servo motors. Of these four servos, two of them lift the three blocks through the vertical conveyor belt mechanism. The remaining two servo motors are used to drive the direction control mono-wheels fitted in the first and third blocks. In addition, the driving unit also drives six DC motors: Four worm gear DC motors and two Pololu motors. These motors are used to drive the Omni-direction wheels, which were used to navigate the robot in planar directions. These motors are operated at 12 volts and consume an average of 800 mA current from the power source.
Four side sweepers are used to accomplish the cleaning task and are mounted on Modules 1 and 3 and propelled by 12v DC with a 100 RPM Metal gear motor. Side sweepers spin inwards to grab the dust particle and push towards the suction mouth; then the suction unit collects to the collection chamber.
3. Proposed Framework
The previous work suggests the design principles behind the sTetro platform along with a basic sensor based climbing mechanism [
3,
13]. This work enhances the sTetro performance by incorporating the deep learning based environmental perception system, which is utilized to deploy the autonomous staircase climbing framework.
Figure 5 Shows the functional block diagram of the proposed scheme. It comprises the environmental perception system and the autonomous stair climbing framework. A detailed description of the two is given below.
3.1. Environmental Perception System (EPS)
Environmental Perception System plays a crucial role to enable autonomous control systems in the robot. This system is tasked to recognize the objects in the environment. The EPS system is comprised of the RGB-D vision sensor, SSD MobileNet based object detection module and depth based error correction unit. The EPS addresses the key challenges of staircase cleaning robot including detection of staircases, debris (e.g., liquid spillages), static and dynamic obstacles present on the stairs (e.g., flower pots, human) which may obstruct the path of the robot during climbing. In the current study, the vision sensor data was used to identify the human and plant pot on the staircase through a deep learning algorithm. According to obstacle position the robot navigation direction will be controlled by CCU.
3.1.1. Object Detection
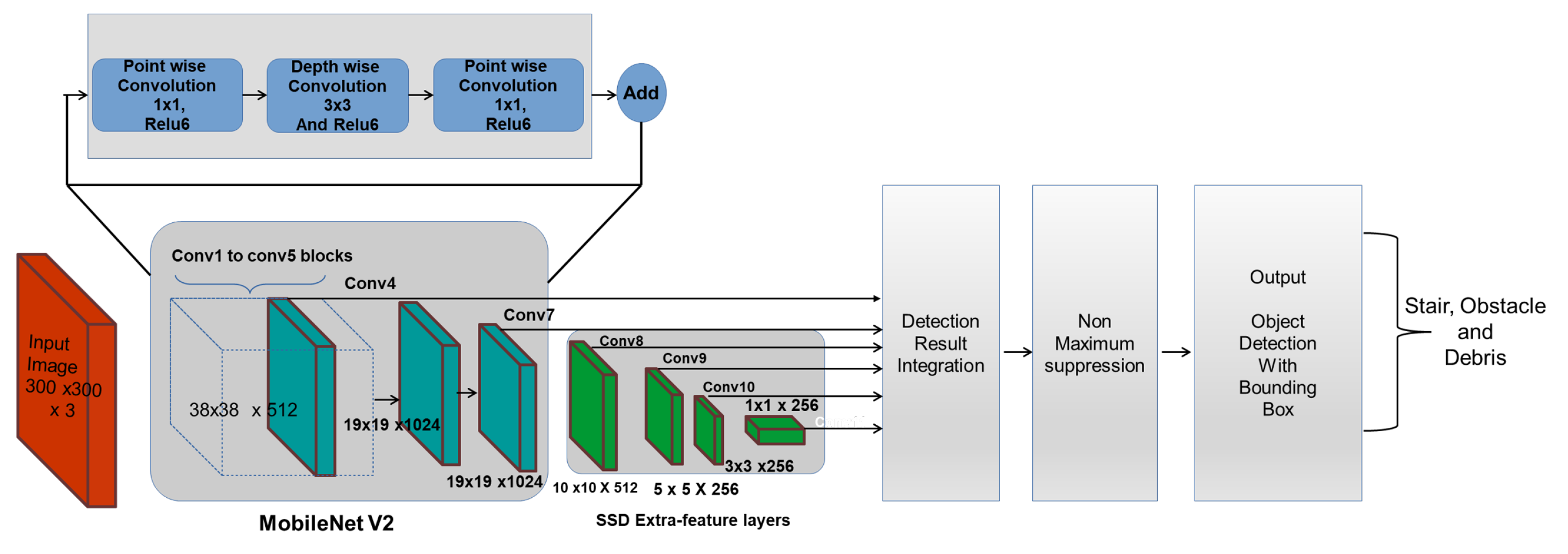
The SSD-MobileNet v2 object detection framework [
34,
35] is used to enable real-time object detection. Here, Mobilenet V2 is the base network called the feature extractor and SSD is the object localizer.
Figure 6 shows the schematic representation SSD-MobileNetv2 object detection framework. The MobileNet feature extractor extracts the high-level features from the captured image stream and generates a feature map, which describes the important features needed for classification or detection tasks. The detection model, SSD uses the feature map and detects the class of an object and its location using a bounding box. The framework is trained to identify staircases, debris and obstacles on the staircase such as humans and flower/plant pots.
Mobilenet v2 is a lightweight feature extractor, suitable for use in real-time object detection application and low power applications of embedded devices. Its architecture is comprised of multiple residual bottleneck layers. These layers use depthwise convolution layers, which are more efficient compared to standard convolution layers. They also employ convolutions instead. The architecture also uses ReLU6 layers, which are ReLU layers with an upper limit of 6. The upper limit prevents the outputs from scaling to a very large value, thereby also reducing the computation cost. Moreover, the model gives better accuracy for the architecture due to the residual connection over the non-residual architectures.
SSD is an object localizer which runs on top of the MobileNet v2 feature extractor. The network utilizes output from the last few layers (feature map) from the feature extractor to predict the location and class of objects. In the SSD architecture, the input is passed through different convolution layers of different sizes. These layers decrease in size progressively through the network. The purpose of these layers is to enable the network to detect objects of different shapes and sizes. A fixed set of predictions is taken from each one of these convolution layers and merged at the end. Furthermore, the computational cost of the model is reduced by choosing the fixed set of shapes. The model outputs locations and confidence of various objects in the image.
The loss for each prediction is computed as the combination of confidence loss
and location loss
(Equation (
1)). The error in the prediction of class and confidence is termed as confidence loss and location loss is calculated as squared distance between the coordinates of prediction. The parameter
balances both the losses and reduced the influence on overall loss. Root Mean Squared gradient descent algorithm [
36] is used to optimize the loss. This algorithm computes the weights
at any time
t using the gradient of loss
L,
and gradient of the gradient
(Equations (
2)–(
4)). The Hyperparameters
are used to balance the momentum and gradient estimation and
is a minimum value close to zero for preventing divide-by-zero errors.
3.1.2. Depth Based False Detection Correction
The detection of the staircase through the use of SSD MobileNet model using RGB data leads to false detection of objects with features similar to staircases. This may include objects similar to staircase such as patterned walls, railings, benches, etc. However, the depth data can be used in tandem to correct the classification decision of the SSD MobileNet. The depth information is fed through the MobileNet network architecture which classifies whether a given object is a staircase or not. However, the depth information may be noisy which may also lead to false detection. Hence, the two outcomes are fused using a support vector machine (SVM) to identify staircases with higher accuracy.
Figure 7 shows the model used to identify staircases.
SVM determines a hyperplane which separates the different classes present in the dataset [
37]. The position of a point relative to this hyperplane determines its class. In this work, a soft margin SVM is used, whose hyperplane boundary is computed by minimizing the function
as computed in Equation (
5).
where
is a hyper parameter which dictates the size of the soft margin. Due to the linear inseparability of the data, an RBF kernel is used to reduce the dataset into a linear space. The kernel uses the kernel function
K on
and
using a free parameter
as shown in Equation (
6).
3.2. Autonomous Staircase Climbing Methodology for sTetro
For autonomous staircase climbing, three crucial environmental features are considered. First, the system should detect staircases, which is used to plan the locomotion to reach the staircase. Next, the robot must detect any obstacles present on the steps which can prevent its operation in that specific region. This includes static and dynamic obstacle like flower/pot plants or humans (a possible obstacle in staircase), with which the robot should not collide. Finally, the robot must move slowly in the slippage region (here we consider liquid spillage debris) and also avoid the slippage region to perform the climbing operation.
3.2.1. First Step Identification and Align with Staircase
A combination of the RGB and depth information is used to determine the location of the first step of the staircase and the angle at which the robot is facing the staircase. This information is crucial to guide the robot towards the staircase. A point closer to the center of the step is chosen to allow room for the robot to align itself and start climbing. Common techniques for detection of steps involve the use of edge detection techniques such as Canny [
38] or Sobel [
39]. This is followed by line detection using Hough Transform [
40]. However, steps can be straight or curved, which limits the accuracy of the Hough transform technique. Furthermore, Hough Transform is highly influenced by noise. One option to alleviate the issue of curved steps is to use contour detection algorithms. These form arbitrary lines by joining points through a Square sweep, Moore sweep or Radial sweep. These check nearby squares and their neighbors in a particular manner. However, for the case of step detection, the change of gradient between one edge point and the next is very small. Hence, search for the next point can prioritize the direction of the gradient over other directions. Furthermore, staircases often have very small gradients, which can narrow the search region at each point.
This work proposes a contour detection algorithm specifically for the case of first step recognition (Algorithm 1). The algorithm gives a higher preference to points along the gradient. This prevents the contour detected from being highly influenced by noise. Moreover, the algorithm checks for points which have deviated from the gradient. Due to this, the contour detected by this technique can be curved or straight, thereby allowing efficient use in all types of staircases.
| Algorithm 1: Contour detection algorithm |
![Sensors 21 06279 i001]() |
The algorithm generates the contour representing the first step from the edge map . The algorithm is run at each edge point from the bottom to top, left to right in the edge map. The function add added a point to the start of an array. In the algorithm, the gradient of the five most recent detected points in the contour is computed through function grad. This function computes the gradient by using regression to fit a line through the given points. If the gradient is too large, the function limits the gradient to , since steps tend to have small gradients. In each iteration, a new point along a gradient is explored, whose coordinates are and . The previously checked points, which are present in the array A, are also checked but for larger deviation from the gradient as compared to previous iterations (), until the deviation gradient limit is reached. This is repeated until a search threshold is reached. This defines the maximum distance that can exist between two edge points. The whole process is repeated until no new edge points are found () or the end of the image is reached. Finally, contours of width lesser than half of the image are ignored and the algorithm is re-run in this case.
After determining the contour, the midpoint of the first step is determined. First, a line is fitted through the points close to the horizontal midpoint of the bounding box by regression. The misalignment angle is determined through the slope of this line. Further, the intersection of this line and the horizontal midline is the midpoint of the first step. The distance to travel to reach the staircase is determined through the depth information of this location in the depth map.
3.2.2. Obstacle and Debris Detection and Localization
Obstacle and debris detection task is accomplished through SSD MobileNet object detection framework. Obstacles can cause collisions or slippages when climbing the staircase. Similarly, the debris detection result assists the robot to perform efficient cleaning. Here, stains and liquid spillage are considered as debris which is commonly found debris in the staircase environment. Furthermore, it is crucial to determine the step in which the obstacle/debris is present in order to plan the appropriate cleaning trajectory. The depth information corresponding to the detected object is used to determine this. The depth data is grouped into clusters through the use of k-means clustering, which is used to determine which step an obstacle/debris is in. In most of the staircases, four steps are clearly visible from the robot perspective; that is why four centers are chosen for the algorithm.
3.2.3. Trajectory Planning
While climbing, the robot generates a zig-zag trajectory (
Figure 8a) completely covering the staircase. The algorithm avoids obstacles (
Figure 8b) while climbing. Further, the robot must move slowly in the slippage region (
Figure 8c) and also avoid the slippage region while performing the climbing operation. The robot performs the climbing operation next to recognizing the slippage area (
Figure 8c) and also stops the cleaning task (
Figure 8b) on human detection. Algorithm 2 defines the trajectory planning scheme. Function
detect updates the staircase data
S representing the position of obstacles and debris. Static obstacles (pots) such as debris are retained in the step data through iterations (represented by ′
O′, ′
D′) and dynamic obstacles (humans) are maintained temporarily (represented by ′
H′).
represents that the position is empty. Function climb performs the step climbing action, as shown in
Figure 2 in
Section 2. Function move (
M) moves the robot in direction
M. Sleep (
t) pauses the robot operation for
t seconds.
| Algorithm 2: Trajectory planning |
![Sensors 21 06279 i002]() |
5. Conclusions
This work proposed the cascaded machine learning based operational framework for the staircase maintenance robot, sTetro. The SSD MobileNet object detection framework was utilized in the EPS to recognize the staircase, obstacles and debris. The feasibility of the proposed method was verified in real time with Jetson Nano, which is a lightweight and low power hardware. The framework detected the objects in real time and took an average of 200 ms to execute the staircase detection, first step localization and 112 ms for obstacle and debris detection. The statistical analysis shows that the depth based fusion scheme reduces the false detection rate and enhances the classification accuracy of the detection system. Further, the first step detection results ensure that the contour detection algorithm is able to determine the first step of the staircase with varying shapes and structures. Through the depth based clustering scheme, obstacles and debris position are effectively localized in the staircase. In the future, we plan to reduce the detection time of the framework by optimizing the CNN layers and also increase the number of obstacle and debris class for safe navigation and efficient cleaning on staircases.

 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}