1. Introduction
Collecting operation data from production systems in the factory floor has been a critical task to maintain the system operation and productivity. Most existing data collection systems are intended to monitor faults that are occurring from various machines in the system. Some are automated to raise alarms in ab-normalcy [
1], and others rely on manual data collection and feed them to tools such as statistical process control [
2]. Recently, thanks to the rapid advances of the Internet of Everything (IoE) technology, automated data collections are receiving a great deal of attention in the era of smart factory and Industry 4.0 with visions of using them beyond the fault detection and isolation: for preventive maintenance, job scheduling, productivity improvement, and various optimization [
3,
4]. Indeed, ref. [
5] proposes to use an IoT-based architecture that collects information regarding key performance indicators to improve productivity, refs. [
6,
7,
8] propose to build a digital twin for the production systems for multi-purpose optimization, ref. [
9] suggests a smart factory framework, which has a cloud-assisted and self-organized structure to produce customized products in a real-time manner, and [
10] suggests an IoT-based supply chain management system that tracks locations of goods to help managers check the status of a supply chain and its dependencies.
An important issue that can be addressed using the infrastructure of IoE enabled smart factory is the continuous improvement of a production line [
11]. The continuous improvement is a major tool for production systems management, where projects are designed to improve productivity of the production systems. Specifically, continuous improvement projects involve bottleneck identification and elimination by allocating additional resources in order to achieve higher productivity in an efficient manner. In addition, analysis for the continuous improvement requires the capability of quantifying the improvement if characteristics of the bottleneck are changed. Existing studies [
12] for methods of bottleneck identification and analysis for continuous improvement projects are based on measurement data, such as cycle-time (average time for a machine to finish a task), uptime (average time for a machine to be up, i.e., operational), downtime (average time for a machine to be down, i.e., not operational), and buffer capacity.
We point out that hardly any manufacturing facilities has dedicated IoE devices for direct measurement of cycle-time, uptime, and downtime for the continuous improvement while many facilities have basic fault monitoring systems. Unfortunately, cycle-time, uptime, and downtime are not directly available from fault monitoring systems. For example, the fault monitoring system in [
13] represents machine states as ‘processing’, ‘inspection’, and ‘manual operation’ and that of a microfluidic device manufacturing line [
14] categorizes machine states as ‘no operation’, ‘idling’, and ‘operating’. A monitoring system in an automotive part production line that is used for a case study in this work categorizes machine states as ‘working’, ‘idling’, ‘complete’, and ‘alarm’. Clearly, extracting cycle-time, uptime, and downtime of each machine from the mentioned fault monitoring data are not at all straightforward. Although many manufacturing facilities are installing IoE devices for data collection under the initiative of smart factory and Industry 4.0, the new devices are still installed with the main purpose of monitoring faults [
15].
A method of using the data from the existing fault monitoring IoE systems for the purpose of the continuous improvement would save time and resource for the manufacturing facilities: new installation is not necessary which may avoid stopping the production for the installation. Thus, in this paper, we present a case study where the continuous improvement of an automotive parts production system is addressed using the data from a fault monitoring system. As mentioned earlier, the dataset necessary for the continuous improvement (i.e., uptime, downtime, and cycle-time) are not directly available from the fault monitoring systems. Therefore, we study the problem of how to derive the dataset of uptime, downtime, and cycle-time for the continuous improvement from the existing fault monitoring data.
In order to model and analyze production systems, many approaches and frameworks are available as reviewed in [
16]. In this work, as a main tool for productivity analysis, we use the theory of production systems engineering (PSE) [
11] due to three distinct advantages: evaluation of various performance metrics is possible for production systems; convergence of the numerical algorithm in PSE is analytically proven; and it has been applied to various actual manufacturing systems.
The theory of PSE models a production line with machines and buffers, where machines are characterized by uptime, downtime, and cycle-time. The aggregation algorithm approximates the model of the serial production line as one virtual machine by aggregating the consecutive two machines and one buffer, recursively. Using this aggregation algorithm, the theory of PSE provides the foundation of modeling production systems and predicting performance characteristics, such as throughput, transient [
17,
18], lean buffering [
19], lead time [
20], bottleneck machine, and bottleneck buffer [
12].
The aggregation algorithm is analytically proven to converge [
11]. This is a significant advantage compared to other methods. For instance, the convergence of the ADDX algorithm used in the decomposition approach [
21] is not analytically guaranteed.
Various productivity analysis cases based on the theory of PSE have been reported (an automotive paint shop line [
22], a lighting equipment assembly line [
23], a ham shaving and packaging line [
24], and a gear assembly line in a motorcycle powertrain manufacturing plant [
25]).
Finally, several major manufacturing companies appear to have in-house tools and methods, but these are not publicly available. Discrete event simulations could be an alternative approach, but are computationally much heavier than the methods PSE provide, especially, when number of machines and capacity of buffers are large.
Our case study pertains to an automotive part production line. The line has a fault monitoring system that observes the status of all the machines in the production system. We present a method of extracting uptime, downtime, cycle-time from the fault monitoring data. Then, based on PSE, we model the production line with appropriate parameters. In turn, we use this model to address continuous improvement projects under various scenarios.
The main contributions of this paper are as follows:
We propose a concept of using existing fault monitoring data for the purpose of continuous improvement of production systems;
We present a case study using an automotive parts production line;
We develop a mathematical model of the line that predicts key performance characteristics, such as throughput, lead time, bottleneck machine, and bottleneck buffer;
Based on the model, we develop a continuous improvement scenario that leads to up to 10% of productivity improvement.
The outline of the rest of the paper is as follows.
Section 2 describes the production line we consider. Additionally, description of the fault monitoring data are given. In
Section 3, we discuss the challenges why fault monitoring data are not directly transferable to uptime, downtime, and cycle-time. Then, we introduce a method of conversion for this particular production line considered. Based on the estimated parameters, we create a model and analyze the production line with the theory of PSE in
Section 4.
Section 5 shows the continuous improvement results in a few scenarios. Finally, conclusions are presented in
Section 6.
2. Automotive Parts Production Line and Fault Monitoring Data
2.1. Production Line
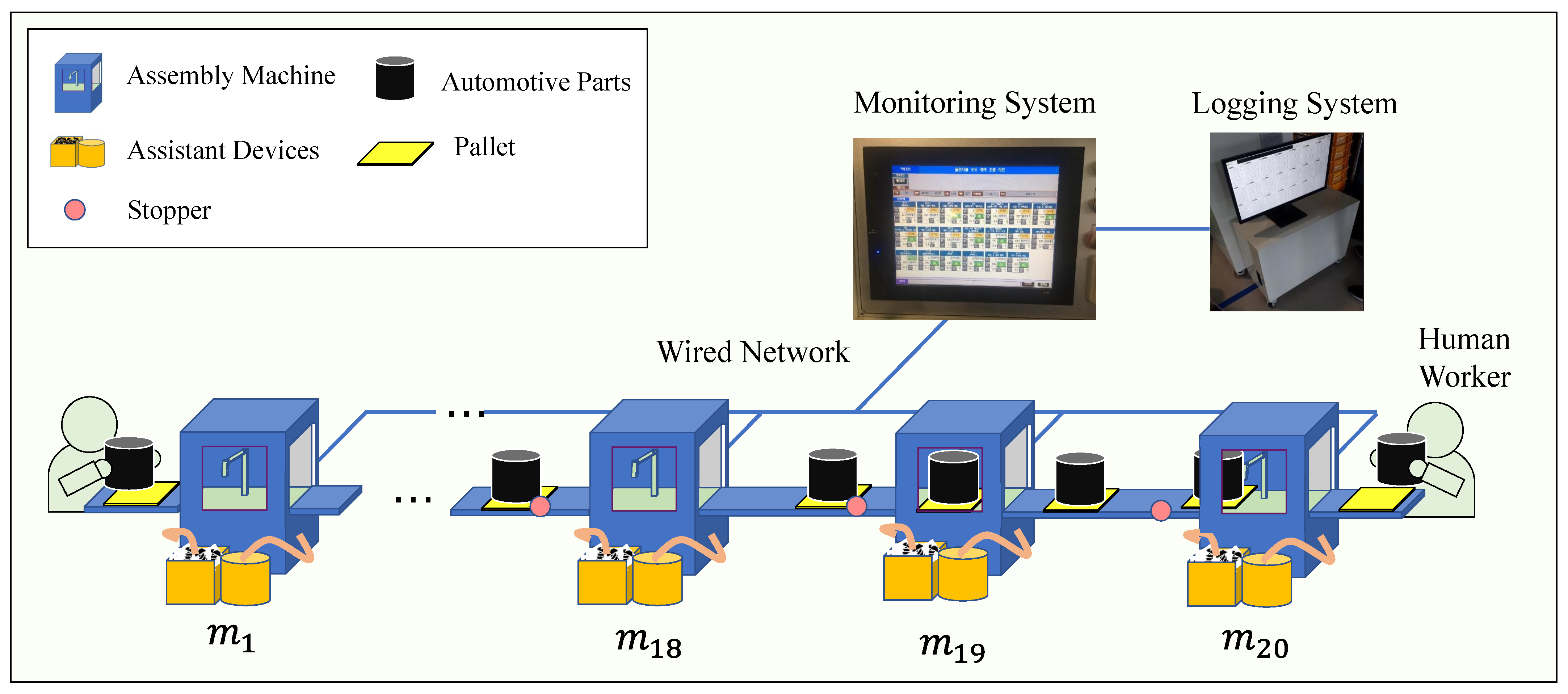
The plant covered in this paper is an automotive parts assembly line from a tier-1 vendor for a world top-5 motor company. We consider an automotive parts production line whose simplified illustration is shown in
Figure 1. The line comprises 20 assembly machines connected serially. We refer to each machine by
,
in the order of the part flow in the production system. The machines
and
are semi-automatic, i.e., operated by human workers and the rest are automatic. Machines assemble sub parts and inspect defectiveness of products. Sub parts and assembled parts are moving on pallets in the production line. Each pallet is identified by an RFID, the reader of which is installed on all machines in the line. There are various assisting devices to some machines that provide necessary materials (screw, lubricants, etc.). Semi-assembled products are placed on a pallet and moved to the next machine.
All machines are connected by the pallet conveyor system. The pallet conveyor system transfers pallets from
to
. After passing
, pallets return to the first machine. The total number of pallets is 40. The pallet conveyor system has stoppers to block the pallet from getting into the machine. The stopper is in front of the entrance of the machine as shown in
Figure 1. All pallets stop at the stopper once. If the machine is full, a pallet waits at the stopper until the machine is empty. If not, then the pallet goes into the machine.
Among 20 machines, , are identical, and , are also identical to each other. This is because the task by and are taking about twice as much time as the other tasks. Hence, two identical machines are allocated for the job in order to speed up the process. Their operations are as follows. If operate only on the parts delivered by even numbered (pallet RFID) pallets. It passes the odd numbered pallets to . The other pair and are operated in a similar manner.
The machines
,
,
operate with block before service (BBS) and the other machines operate with block after service (BAS), where BAS and BBS are rules for interacting between machines and buffers. When the downstream buffer of a machine is full, the machine should stop producing. In this situation, the machine with the BAS rule produces one product and keeps it inside the machine. On the other hand, the machine with the BBS rule does not produce and leaves its inside space empty [
11].
The line produces a total of 52 types of products. The machines need to change their settings whenever the types of products change. It takes time to change the settings, therefore the company operates the line with a batch production rule to reduce the process change time where the batch refers to a group of products of the same type. As the machines are differently operated by the product type, the throughput of the line may also be different product types.
Figure 1 also shows a fault monitoring system. Every machine transfers its operation data to the fault monitoring system at every second. The monitoring system represents all machine’s states right after receiving the operation data from each machine. The fault monitoring system in this manufacturing facility
does not record data perhaps because it is designed only for raising alarm at faults. We develop the logging system which takes all data from the monitoring system and write the data to a file by the hour.
The machines rarely produce defective products. Nevertheless, the line has the capability built in to deal with the defective parts. The defective products are not removed from the production line immediately. If a machine generates a defective product, then the machine informs to the monitoring system. After that, the monitoring system transmits the serial number of the defective product to the downstream machines so that the downstream machines just pass the defective product until or , which are inspection machines. The inspection machines eliminate defective parts into their basket.
The production line operates for 24 h with several break times.
2.2. Fault Monitoring Data
Using the logging system described in the previous subsection, we obtained fault monitoring data for five months in 2019. The fault monitoring data contain machine state, product state, processing time, serial number, and logging time. An example of the data is shown in
Table 1, where ‘Time’, ‘Type’, ‘M State’, ‘P State’, ‘SN’, and ‘PT’ refer to ‘Logging Time’, ‘Product Type’, ‘Machine State’, ‘Product State’, ‘Serial Number’, and ‘Processing Time’, respectively.
The item ‘Machine State’ in the operation data indicates the operate state of the machine at a specific time. The machine reports its state by ‘Idling’, ‘Working’, ‘Complete’, or ‘Alarm’. The detailed description of ‘Machine State’ are as follows:
A machine reports ‘Idling’ when the inside of the machine is empty;
A machine reports ‘Working’ when the machine does assembling, inspecting, or other actions for producing products;
A machine reports ‘Complete’ after finishing production processes, and sustains ‘Complete’ until its inside becomes empty;
A machine reports ‘Alarm’ if the machine is in a breakdown.
The item ‘Product State’ represents the inspection results of the defectiveness of the assembled product. The machine informs the state of the product as ‘Stand by’, ‘OK’, and ‘NO’.
A machine represents ‘Product State’ as ‘Stand by’ after the machine takes a product;
After finishing the inspection, the machine reports ‘Product State’ as ‘OK’ if there is no problem with the product;
If the machine identifies defective parts, then the machine reports ‘Product State’ as ‘NO’.
The rest of the data include ‘Serial Number’, ‘Processing Time’, ‘Time’, and ‘Type’. The item ‘Serial Number’ refers to the sequence of products during a day. The monitoring system initiates ‘Serial Number’ to 1 at midnight. The monitoring system sequentially assigns ‘Serial Number’ to pallets by reading RFID at the first machine, and removes it at . The item ‘Processing Time’ indicates how long the pallet stays inside the machine for producing. The item ‘Time’ indicates when the log is recorded, and ‘Type’ represents a product type in the first machine.
3. Obtaining Uptime, Downtime, Cycle-Time from the Fault Monitoring Data
Obviously, the data shown in
Table 1 are not in a form from which the uptime, downtime, and cycle-time of each machine are obtained in a straightforward manner. As we pointed out in the introduction, this is due to that the fault monitoring data collection are not intended for continuous productivity improvement. This difficulty of mismatch is dealt with in detail in
Section 3.2.
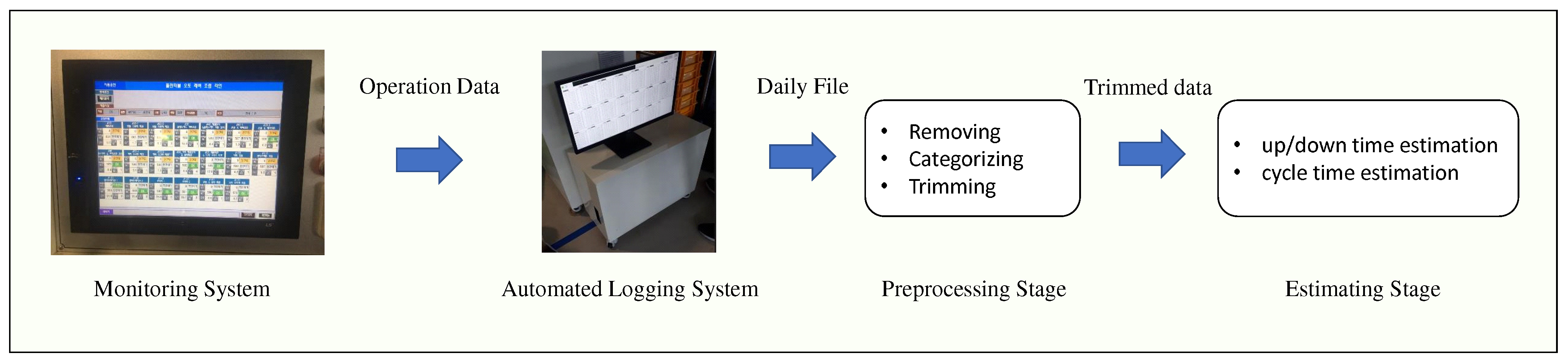
Additionally, as alluded to in
Section 2.2, uptime, downtime, and cycle-time may be different by the types of the product. Hence, the first step is to isolate the time segment where a given product type is produced. Therefore, we propose a parameter estimation method consisting of two stages, a preprocessing stage and an estimating stage. The preprocessing stage is trimming the fault monitoring data: removing the break time from the log, classifying the product types, and removing the logs that corresponds to initial transient state. The parameters, uptime, downtime, and cycle-time, are estimated by the second stage based on the trimmed data. The entire procedure for estimating the parameters are simplified in
Figure 2.
3.1. Preprocessing Stage
Figure 3 shows typical daily operation of the production line for a week in the Month 4 of 2019. This snapshot of the operation data is obtained as follows. First, break time had to be determined from the logs. For this purpose, we use the ‘SN’ of
: if ‘SN’ of
does not change for more than 10 min, we determine that the production line is not operational (break time for the workers). The color of the bar represents different product types. This is determined by the ‘Type’ data in
from the fault monitoring dataset. We point out that
Figure 3 is the result of preprocessing that identifies in automatic manner the break time and the types.
From
Figure 3, one may use all the data segment with the same color to extract the cycle-time of each machine. However, for uptime, another aspect must be taken into account. When the machine is in transient state, total operation time may not be accurate, which affects the calculation of uptime (uptime is computed by subtracting downtime from the total operation time). Hence, we additionally remove the first portion of the data until the last machine completes five products. Therefore, we cut the data related to the first five products off in the fault monitoring data in order to generate trimmed data.
3.2. Estimating Stage
The purpose of this stage is to extract uptime, downtime, and cycle-time of individual machine (from
tot
) for a given product type. Trimmed segments for a given product (same color in
Figure 3) are used.
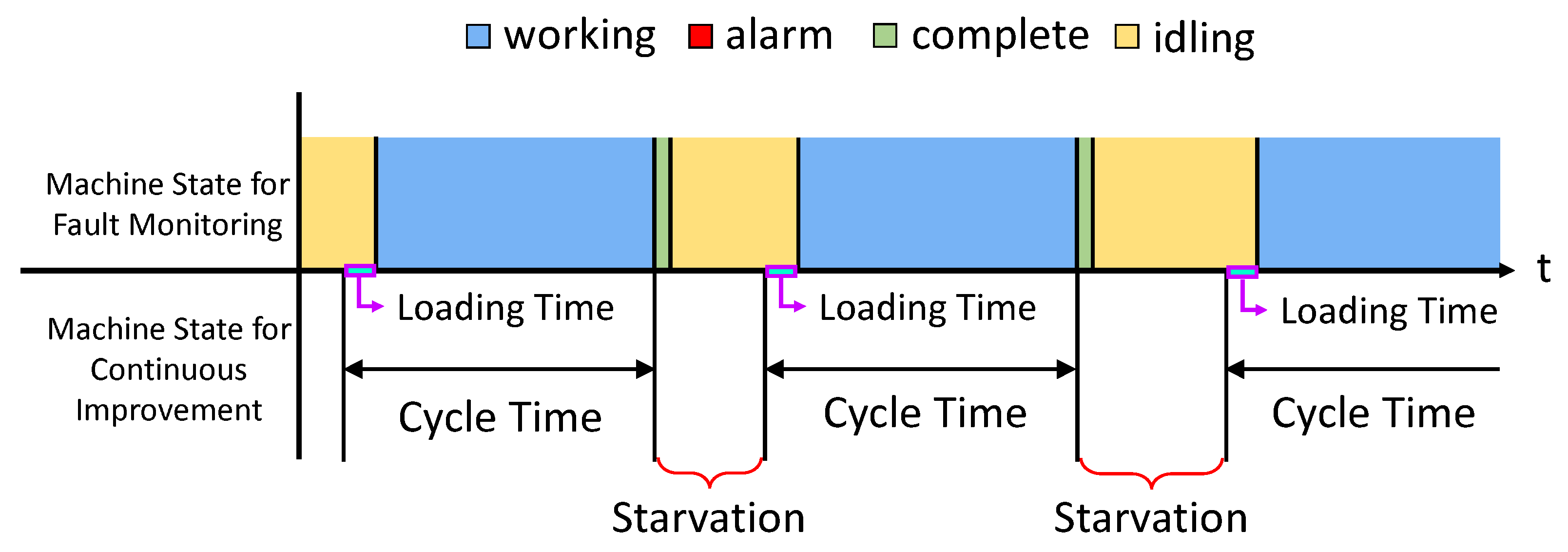
We first discuss how to obtain a cycle-time for each machine. The cycle-time is identified by searching ‘Idle’-‘Working’-‘Complete’ states sequence in the fault log. This is illustrated in
Figure 4. It may appear that after find the sequence, use ‘Working’ state as one instantiation of the cycle-time may suffice. However, after observing the operation on the factory floor for an extended period of time, we realize that computing cycle-time in this manner may not be accurate: there is time, referred to as
loading time, for a machine to load the product from the pallet. This portion must be included in the cycle-time, but it is included in the ‘Idle’ state according to the fault log. As shown in
Figure 4, we extract the sequence in the log, then identify the duration of ‘Working’ and add to it the loading time to obtain a realization of the cycle-time.
For this procedure to work, the loading time for each machine needs to be determined. As it turns out, we can identify the loading time from the log in a specific situation called blockage. Blockage means that a machine completes the task, but cannot move the part to the down stream buffer because the buffer is full. In order to identify the loading time of
, the blockage of
has to be searched. The condition for this is to look for a prolonged ‘Complete’ state of
(because
cannot push the product out). When
is in blockage, the upstream buffer for
is full. Thus,
takes the part right after it finishes the task on the previous part. This means the duration of the ‘Idle’ state in
is equal to the loading time of the next machine. An illustration is given in
Figure 5.
A code is written to identify for each machine the above described conditions. It results more than thousand cases for loading time, the average of which is used as ‘loading time’ for the machine.
Next, we attend to the up and down time. From a continuous improvement analysis point of view (e.g., PSE analysis framework) each machine state is either up or down. Up state means that a machine is operational, and down state means that the machine is not operational. The time that a machine is waiting for a product to arrive (starvation), although the machine is not producing, is counting up towards a certain state that the machine is capable of producing. The time that a machine cannot produce due to the shortage of assembly parts (e.g., shortage of screws) although the machine is not out of order is counted toward down state. Obviously, this classification of up and down state does not match with machine state recorded in fault monitoring data. We illustrate this by
Figure 6.
The first down state shown in
Figure 6 matches with the ‘Alarm’ state (i.e., the machine is out of order). However, the second down state does not show at all in the log. This was due to the lack of assembly supplies. Uptime does not exactly align with ‘Working’ state either.
In the theory of PSE, downtime is the average amount of time a machine cannot produce, even if it is capable of producing. We observed two situations for this production system that corresponded to downtime of the machines. First is the breakdown of the machines. This is indicated by ‘Alarm’. The second is running out of additional assembly parts and materials (screws, lubricants, etc.) that are necessary for the assembly. The second case does not correspond to any state in fault monitoring data. We identify this by looking at abnormally long ‘Working’ state. Since we computed cycle-time earlier, the abnormally long means that it is longer than 1.5 times the cycle-time. The long working duration minus the cycle-time is counted toward down time. Again, a code is written to identify all such cases for each machine to determine down time.
Once the down time is obtained, uptime is computed by subtracting down time from a total operation time. The total operation time is computed from the trimmed data.
It must be pointed out that, although we discuss in detail the fault monitoring data of the production system considered in the case study, no generalization is given how to obtain cycle-time, uptime, and downtime from general fault monitoring data. For instance, the fault monitoring data of [
13,
14] would require algorithms different from those used in this work.
6. Conclusions
Continuous improvement of the production line is one of the important issues of the manufacturing industry. Thanks to the advance of IoT technology, infrastructures to collect data are rapidly being developed. However, many data collection systems (especially, in middle-size companies) still focus on fault monitoring systems. The data of the fault monitoring system are not directly matched to the data required for continuous improvement project for productivity. Developing a new IoE enabled system dedicated for a continuous improvement project is time-consuming and incurs additional cost.
In this work, we propose a data processing method to use the conventional fault monitoring data for continuous improvement project. For an automotive part production line, a case study is presented where the dataset required for continuous improvement are derived from the dataset recorded for conventional fault monitoring system. Several conditions for this data conversion have been explained and illustrated. Then, using the converted dataset, the line is modeled with high accuracy based on the theory of productions systems engineering. Two improvement scenarios are considered using the model to quantify throughput improvement. In one of the scenarios, more than 9% productivity improvement is possible if the cycle-times are decreased for two machines out of 20 machines.
This study showcases a method of obtaining the information necessary for continuous improvement project from a legacy system. Extending the work to general fault monitoring systems, beyond the case study, would be a future work. We expect the results will be useful for manufacturing companies (especially middle-size) that are either building new IoE devices or seek additional benefits from the existing data collection systems.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}