Abstract
In Opportunistic Networks (OppNets), mobility of and contact between nodes are explored to create communication opportunities and exchange messages and information. A basic premise for a better performance of these networks is a collaboration of the nodes during communication. However, due to energy restriction factors, nodes may eventually fail to collaborate with message exchanges. In this work, we propose a routing mechanism called eGPDMI to improve message probability of delivery while optimizing nodes’ energy consumption. Unlike other algorithms proposed in OppNets literature, eGPDMI groups nodes by energy level and nodes interests using clustering techniques. Our major assumption is that retaining messages in nodes with the highest energy levels can improve network performance, thus overcoming the problem of nodes’ disconnection due to unwillingness to cooperate due to low energy values. Through questionnaire application and factorial design experiments, we characterize the impacts of energy levels in OppNets. Further, we apply performance evaluation of the eGPDMI mechanism in terms of effectiveness using mobility from real-world scenarios. The results show that our mechanism effectively reduces the degradation of the probability of delivery when the minimum energy level used for nodes to cooperate with communication increases.
1. Introduction
Recent advances in wireless networks have boosted promising paradigms such as communication between people directly from their own devices without using network infrastructure. The global Internet traffic reaches higher values year after year, mainly because of (i) the increasing number of personal devices, such as smartphones, tablets, or wearable devices; (ii) the diffusion of content-oriented services, such as chats, streaming, and content shared among users. It has become a considerable challenge for Internet providers to meet this constantly higher traffic.
Some paradigms of infrastructure-less communications emerged to address these situations, such as the Opportunistic Networks (OppNets). OppNets are a particular case of delay-tolerant networks (DTN), where messages exchange occurs during contact opportunities when mobile nodes are in the same coverage area.
Because mobile devices use resources to share data, OppNets can overcharge resources such as device energy or device buffer. Buffer management for mobile devices still draws the attention of researchers [1]. However, we found a lack of in-depth studies related to energy level or consumption and their impact on OppNets [2,3].
Therefore, one should consider energy consumption as a relevant metric for performance evaluation [4]. In [5], the authors claim that the communication process is mainly responsible for the energy consumption of devices in wireless communications. Energy usage can have different effects on OppNets’ performance evaluation. While mobile devices with a fully discharged battery cannot take part in data transmission, those with low battery levels may not be encouraged to cooperate on opportunistic communications [6,7]. It is well known that data transfer and the discovery of nearby devices consume energy. In addition, after turning a device off, it is not possible to predict when it will be available again, affecting the routing success.
The battery usage pattern depends on the user’s behavior. The work of Bulut and Dhungana [8] examines the problem of energy balance in OppNets from the social structure of the network, considering energy balance with social awareness as an important strategy. We conceived, designed, and implemented a routing protocol that groups nodes according to their battery usage pattern, classifying them by high and low power levels, with forwarding decisions based on devices with similar power levels, considering the high levels.
The proposed mechanism (eGPDMI) extends the GPDMI opportunistic routing protocol by Neves et al. [9], taking advantage of its essential characteristics of clustering the nodes around their interests and social-based mobility. That assumption relies on the fact that, in OppNets, nodes tend to cooperate in communication if message content is in their interest [10].
From the OppNets perspective, these network characteristics are attractive to share interests using mobile devices contacts. This article assumes that the message dissemination considers the interests of the users carrying the mobile devices. Therefore, the proposed mechanism intends to apply a forwarding decision based on the nodes’ energy consumption, combining the nodes’ social interests over the nodes.
The idealized routing mechanism creates groups of nodes according to both the energy levels and the similarity of social interests. This combination avoids trying to forward messages through nodes that are considered selfish because of the limited available energy. We present the motivation for this investigation and compare its performance against other routing mechanisms in the literature.
This paper is organized as follows. Section 2 presents some related works. Section 3 shows our study on energy effects over opportunistic networks. Section 4 describes the architecture overview of the proposed mechanism. Section 5 describes the deployed methodology. Section 6 depicts the performance evaluation results. Finally, Section 7 presents our conclusions and future works.
2. Related Works
Recent forwarding strategies adopt social aspects at the core of their decisions. OppNet users carry mobile devices; thus, it is reasonable to claim that social network models are suitable for designing routing protocols [11]. Most of them emphasize the role of social aspects in the design phase, such as tie strength, popularity, or centrality metrics [12,13].
Recently, Ying et al. [14] researched opportunistic routing algorithms that use social features to stimulate the performance of message forwarding. The authors conducted comparative research on these algorithms, analyzing three social characteristics, namely centrality, similarity, and tie strength, in addition to simulation experiments, demonstrating the impact of these algorithms on the network. They reinforced the idea that, although much work has already been performed on opportunistic routing algorithms, they still need to explore social features more effectively in designing new routing algorithms.
Despite the significance of social aspects, resource constraints also play an essential role in nodes deciding to cooperate in network transactions. Whereas opportunistic contacts are the primary reason to yield communication, the node’s unwillingness to cooperate affects the network performance and may be harmful [15]. In a questionnaire applied by Souza et al. [16], 10% of the mobile users at the Federal University of Amazonas (UFAM) claimed they would share data with other devices, even though they had a low battery level, and 55% of the users would prefer to recharge their battery fully. Gupta et al. [17] showed that network performance degrades to about 62% when the proportion of non-cooperating nodes goes from 0% to 50%.
In OppNets, nearby devices may cooperate by sharing data. However, the interaction and data transfer among nodes can consume different energy levels depending on the operation, since mobile nodes are battery operated. Therefore, even discovering if a neighbor device is near may consume an extensive amount of energy. In [17], the authors define the following modes as energy-consuming: scanning, transmission, reception, and inactive mode.
A study by Loudari and Benamar [18] on the evaluation and comparison of energy consumption in OppNets takes into account mobility models relating them to energy consumption and selfish nodes, concluding that routing protocols in opportunistic networks focus on decreasing the average delay and the overhead and increasing the message delivery rate. For this, they increase the number of copies of packets on the network. Therefore, more energy is consumed by the nodes, making the environment more hostile, as the energy consumption plays a crucial role in modifying the behavior of nodes in the network because nodes with low battery power can become selfish and uncooperative.
The authors Yu et al. [19] emphasized the formation of communities based on social characteristics, proposing an opportunistic network routing strategy based on individual communities of nodes. The algorithm builds social relationships through the probabilistic encounter between them; individual communities are formed based on the centrality of nodes.
Another approach in [20] is to form user clusters through the probability of meeting between the nodes. This reflects the degree of connection between them, which can be used for forwarding future messages. The idea is that users with a high probability of finding each other must be in the same cluster.
The work of Hui et al. [12] demonstrates that social communities positively affect data transmission. However, in [2], the authors conclude that using social characteristics might be unfair and may cause node overload. Their results showed that only 10% of nodes handle 63% of all data traffic. Junior and Campos [3] proposed a modified version of Bubble Rap [12] by randomly choosing some nodes among the most central (a popularity metric) nodes to reduce their load.
An approach used in [21] proposes a protocol based on energy-efficient inactive nodes detection. It is a method to detect nodes in a dead or inactive state in the network and provide an efficient buffer management policy to avoid network congestion. In summary, there is a focus on controlling the transmission of messages destined for dead nodes, eliminating messages destined for them and thus avoiding the consumption of nodes resources.
In line with the authors mentioned above, Neves et al. [9] demonstrated clustering methods to improve delivery rates in scenarios with social aspects and message interest profiles. They applied the clustering algorithms EM [22] and k-means [23] to build groups with common interests. They compared the performance of their proposed method (GPDMI) with Bubble Rap [12], which also uses clustering techniques to create social communities.
Their results showed that, by introducing interest profiles and social aspects in the OppNet context, clustering nodes by interest profiles is the most suitable choice to improve the dissemination of messages.
Since there are more interactions among the nodes with over one common interest topic, message forwarding from the source to the cluster of the topic of interest occurs over the nodes’ path with an indirect interest in the message. Although GPDMI performs better than Bubble Rap, we realized a gap in performance evaluation when considering energy constraints. It is essential to emphasize that, though our approach is similar to GPDMI, we added a new clustering layer above to group the nodes with the highest battery level.
Our mechanism considers the relationship of users’ mobile device usage with battery consumption. The idea is to group them by energy levels, assuming that there is a user behavior correlation to the daily use of their mobile device so that this history can be exploited to optimize the energy resources of the nodes when forwarding messages on the network.
Amah et al. [24] investigated the burden and fairness of forwarding strategies in OppNets. Using mobility traces, they found it difficult to estimate the node’s burden determinant factors. The authors claim that resource usage depends on variables unrelated to nodes’ contribution in forwarding messages, such as TTL, number of contacts, queuing policy, and routing protocol.
3. Energy Impact
The battery level is the remaining energy in the user’s device used by the user’s applications and communication among nearby devices. However, when this resource is low, we assume the nodes will not cooperate in opportunistic communication. Network metrics can degrade if a node leaves the network operations, as fewer nodes store the messages. To test this hypothesis, we carried out a questionnaire to evaluate two issues:
- (i).
- the behavior of real users when taking part in OppNet at a critical energy level,
- (ii).
- from which level of energy users consider taking part in the network only favoring themselves (not accepting messages from other users).
We conducted this experiment on the UFAM campus Manaus with 351 participants of several courses to answer these questions. The research questions and alternatives can be seen in Table 1.

Table 1.
Questionnaire about user behavior in usage of their battery of mobile devices in OppNets.
The questionnaire result showed that 77.16% of the users would not accept the request to take part or wait for their batteries to recharge. This result corroborates the null hypothesis that nodes may leave network operations of storing data to forward later. One can analyze the cooperation behavior by using the second question as a guide.
We found that 68.10% of the users would no longer cooperate in communication if the battery was lower than 30%. Only 19.65% of the users agreed to cooperate with the network operation if their energy level was above 50%.
This result reinforces the hypothesis that low energy nodes would not cooperate with the network forwarding mechanism.
We applied another experiment that highlights the impact of cooperation based on the energy level. This analysis can allow us to choose an appropriate design of experiments; it also defines an adequate set of investigation factors.
Factorial Design
A performance evaluation must comprise two key components, the design of experiments, which refers to planning the experiments to collect the data feasibly for statistical analysis, and the actual statistical analysis of the data [25]. We applied a 2k factorial design, a technique comprising two or more factors as input, representing some of the network parameters that significantly influence the performance metrics.
Factorial design helps sort out the factors according to their impact and points out how their interactions can impact performance metrics. The basic approach for factorial design is to select a set of k factors with two levels (represented as −1 and 1). We simulated all combinations of k factors with 2k experiments. Since we were interested in the impact of energy level, we defined the factors in Table 2. Our response variable y is the probability of delivery of the messages. The coded variables were used in a regression non-linear model built to represent the effects of the factors and all their possible interactions on the variable, given by Equation (1). It is important to highlight that we carry out the factorial design without replication.
y = q0 + qAxA + qBxB +qCxC + qDxD+ qABxAxB + qACxAxC +…+ qBCxBxC +…+ qABCDxAxBxCxD
Table 2.
Factors of experiments.
In order to find out the effect of each factor (explained in Table 3) on the response of interest y, one can assign minimum and maximum levels to the selected factors (see Jain’s book [26] for more details) and record the result of the probability of delivery of the message obtained by simulation.
Table 3.
Variation of Xi vs. result of variable y.
We determined the density of the scenario as a factor to analyze how scenarios can affect the simulation results. We defined two battery ranges, so the values represent which battery level node keeps cooperating in the network and carrying messages from other nodes. In the experiment’s execution, we used an epidemic routing algorithm. In the minimum value (between 75% and 100%), nodes cooperate only if their battery levels are in this range (low cooperation). In the maximum value of (0% the 100%), nodes carry messages from other nodes regardless of their remaining energy level (high cooperation).
Since the scenario needs to be similar to the real-world ones, we chose a sparse (Reality) and a dense (Infocom), extracting information from real experiments. In Section 5.1, we present further details for the selected scenarios.
Table 3 presents the investigation of the effect of the node’s battery charge level on the message’s probability of delivery and the levels attributed to each factor in the simulation. The minimum and maximum levels are assigned to variables of set X = {x1, x2, x3, x4}, which alternate their levels according to Table 3. For example, x2 = −1 is assigned to battery range = [75, 100] and x2 = 1 is assigned to battery range = [0, 100].
The next step is to calculate the percentage of message delivery variance attributed to each of the four factors and each interaction between them. The percentage of variation captures the importance of each factor in the response variable.
Table 4 describes the percentage of variation pointed out by the factorial design. The battery range factor has a more significant impact on the message’s probability of delivery (76.96%). The scenario and the joining factor composed of both battery range and scenario explain 18% and 3% of the variation. Thus, the remaining node energy necessary to cooperate is the most significant factor that deserves further analysis.
Table 4.
Factor evaluation.
Although the impact of cooperation has been studied previously [17], to the best of our knowledge, this is the first study that applied factorial design to evaluate the impact of energy level on the messages delivery probability compared to other OppNets parameters.
Further, we highlight scenarios that also have a relevant effect on the performance metric evaluated.
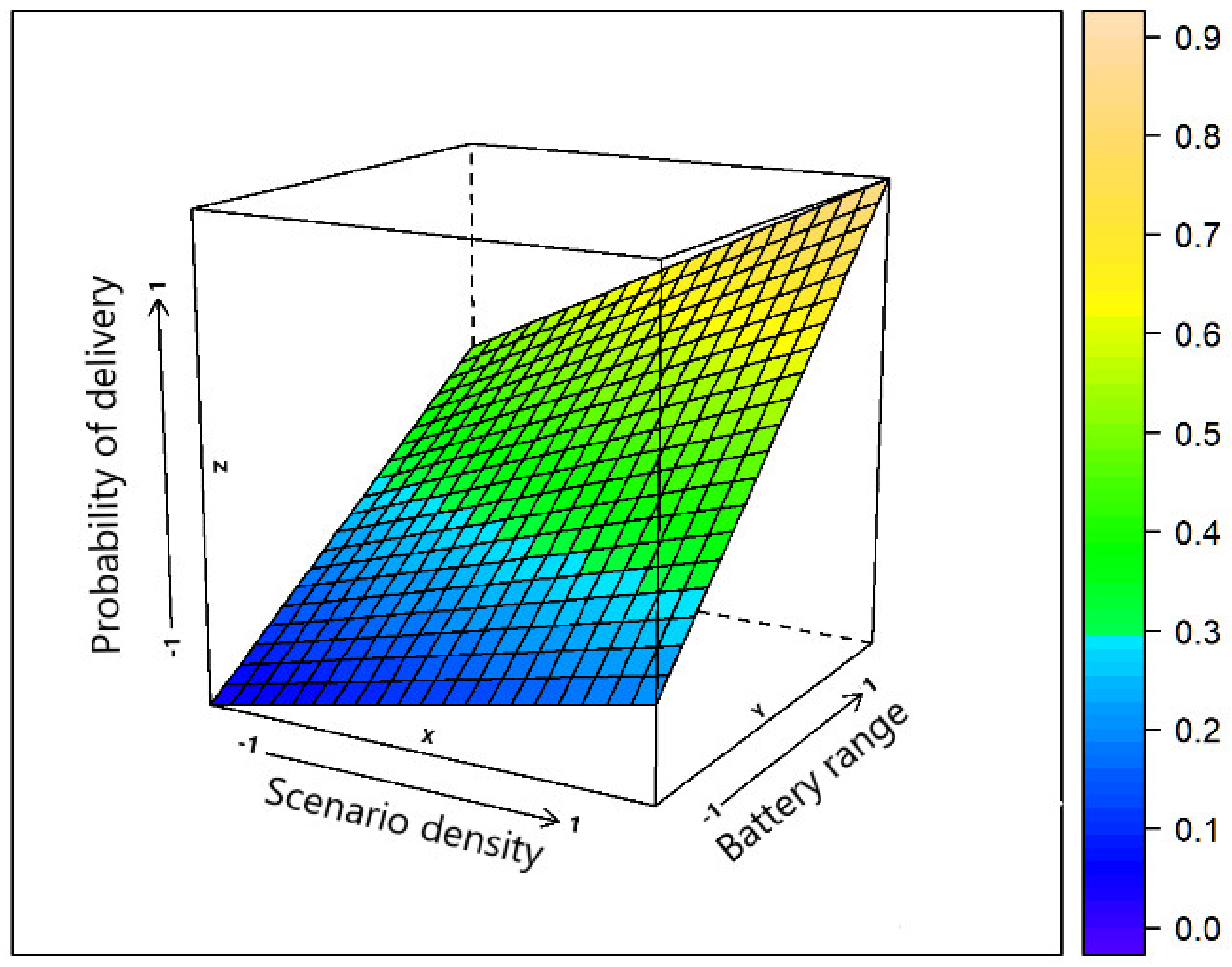
Figure 1 presents the correlation between the battery range and the density of the scenario, both related to the result of the message delivery probability metric.
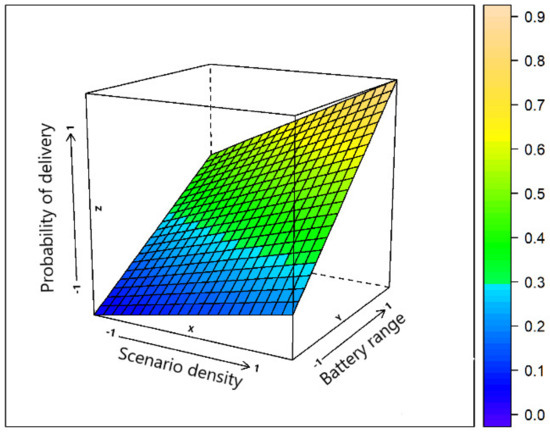
Figure 1.
Impact of the scenario density and battery range on the delivery probability of messages.
When the density of the scenario is higher (more contacts) and the battery level is in the range E = [0, 100], which means full cooperation of the nodes in the network, message delivery probability is higher than in the sparse scenario or if the range battery is out of range E = [75, 100].
4. Architecture Overview
In this section, we describe the assumptions used in the simulations and the proposed mechanism.
4.1. Network Model
An opportunistic network can be modeled as a graph G (N, E), comprising a set of N vertices representing the nodes and a set of E edges representing the contacts between the nodes. Initially, each node has an initial random energy value. The energy level decreases when one of the following operations occurs: neighbor scanning, message transmission, or reception.
We assumed the nodes did not recharge their batteries during the simulation. After the full discharge of the node battery, they did not take part in the network operations. The mobility relied on human interactions by using contact traces extracted from real experiments.
4.2. Interest Profiles
Message interest is represented by a finite set M of distinct parts (A.K.A. “topics”). At the start, each node has a subset M of messages of interest. Two nodes (i, j) do not have common interests if Mi ∩ Mj = Ø. So, we assumed that nodes interests are static and do not change during the simulation run. Each message assigned to node “i” is initialized with one interest, randomly chosen from Mi.
4.3. Detailed Design
Our mechanism comprises nodes with the highest energy level values to forward messages and avoid network resource loss. Additionally, eGPDMI focused on situations of gathering nodes by similar interests. We applied two clustering phases to enable decision-making:
- (i).
- the first phase clusters the nodes by energy level;
- (ii).
- the second phase clusters the nodes according to the interest profile.
For building clusters, we analyzed two well-known clustering methods:
- EM (expect-maximization) is a clustering technique based on a statistics model called “finite mixtures”. A finite mixture is a set of k distribution probabilities representing k clusters and the values that define each cluster. EM is a method to find the maximum likelihood for a group of parameters:
- 1.
- Step 1 (expect step): It calculates the likelihood of the dataset by associating each object xi to the cluster Ck by applying Equation (2).
- 2.
- Step 2 (maximization step): Applying the maximization of Equation (1), recalculating the unknown values.
EM repeats the steps above, and the algorithm ends when the maximum likelihood criteria are satisfied.
- K-means: Unlike hierarchical clustering, where the clusters merge or partition at each iteration, k-means partitions the clustering into precise k groups. The aim is to find clusters as homogeneous as possible. Hence, k-means can be written as follows.
- Each cluster Ck is randomly built by applying a random centroid αkk for each cluster;
- For each input y, assign it to the cluster Ck, which centroid αk is the closest for each input;
- Update their centroids by using all inputs assigned for each class;
- Calculate the error function by applying Equation (4):
- 5.
- Repeat steps 2, 3, and 4 until there is no change in any clusters.
EM allows a more stable control over the characteristics of the clusters. Both yield a sub-optimal solution since there is a lack of global knowledge of the network status. Further, this solution is suitable for routing through groups in OppNets, where there is no central network infrastructure.
- Cluster-based forwarding: The primary goal of our mechanism is to mitigate the unnecessary use of device resources, particularly energy level, prioritizing the message transmission from nodes with a low level of energy. We assume these nodes have a stronger trend to become selfish due to a lack of resources.
Our mechanism has three main steps, (i) apply clusterization techniques to arrange neighbor nodes according to their energy levels; (ii) apply clusterization techniques to group neighbor nodes with common interests; (iii) validate the threshold of the neighbor’s energy during each contact.
The energy level threshold is defined as E = [Energylower, Energyupper], E ⊂ [0, 100]. For example, if E = [50, 100], our mechanism builds a cluster with nodes with an energy level between 50% and 100%.
Depending on this condition, each node taking part in a contact forwards or does not forward a message towards a node not belonging to this cluster.
Our complete message forwarding mechanism is written as follows:
- Message creation: Each created message is classified according to the topics of interest of the source node.
- Classification of interests: Each node is classified according to its topics of interest.
- Classification of energy: Each node is classified according to its energy level.
- Clustering: The clusters of interests are built by applying the same mechanism presented in GPDMI. Then, we carry out a new clusterization run based on the energy level. We deploy the EM technique to gather nodes by energy.
- Decision-making: The forwarding process verifies whether the node on the receiving side is in the cluster with the highest energy level and the topic of interest.
This work extends GPDMI by adding steps 3, 4, and 5. We used training data to define low energy or high energy to train the clusters by energy level, defined by E = [Energylower, Energyupper]. The interests are globally represented, and every node knows the interests of all the other nodes. The node interest did not change during the simulation.
5. Methodology
We compared the performance of eGPDMI to the performance of two other strategies based on social interactions and message replications, namely PRoPHET and GPDMI. The following subsections detail the settings of this quantitative experiment.
5.1. Mobility Datasets
We designed a set of experiments based on stochastic simulation using the tool ONE (Opportunistic Network Environment) [27]. We selected the scenarios Reality Mining [28] and Haggle-Infocom5 [29] once they resulted from real experiments. Table 5 presents the simulation parameters.
Table 5.
Mobility dataset parameters.
5.2. Simulation Parameters
We initialized each node with a random energy level between 0 and 100%. We defined four ranges to battery capacity to use as a decision criterion during message forwarding in the mechanism presented.
We considered that, in the defined ranges, the nodes continue to cooperate with the network, forwarding the messages.
The battery capacity ranges were extended for PRoPHET and GPDMI strategies. The decision-making processes of those routings also considered the energy level. Table 6 presents detailed parameters. We repeated each simulation ten times in each set of parameters defined, and for each metric used, we computed the average values of all executions.
Table 6.
Simulation parameters.
5.3. Modeling of Groups
To define the groups of nodes within the range battery capacity, we applied the intervals specified in Table 6. These values were used to build both groups of energy, the low energy level nodes and the high energy level nodes. In addition, interest groups were formed from topics obtained using the Haggle-Infocom5 mobility data set [28].
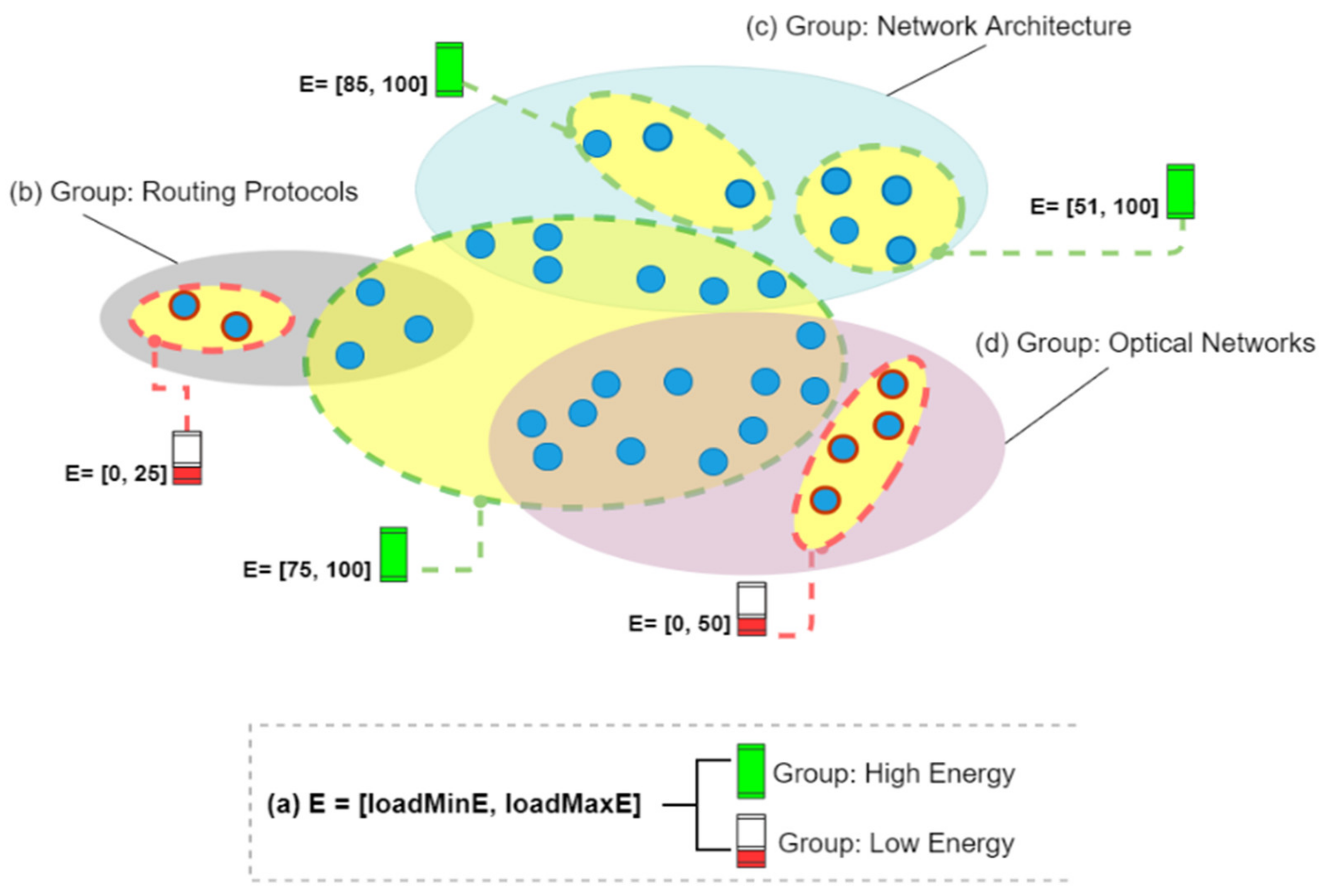
Table 7 describes how the groups were created. We used a set of 30 different topics of interest. Then, we set k = 30 in the clustering technique k-means. Figure 2 is an example of group formation, where (b), (c), and (d) represent the nodes grouped according to their interests, and (a) demonstrates the use of established energy level ranges (E ⊂ [0, 100]) to generate the energy groups. This can be seen in the image, where we have groups of nodes with low and high battery levels. Figure 2 illustrates how clusters intersect in this strategy.
Table 7.
Classification used for the formation of energy and interest groups.
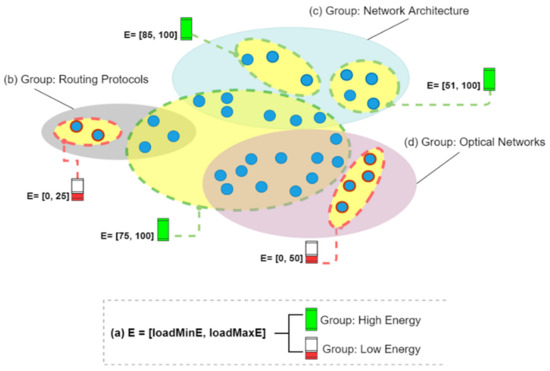
Figure 2.
Formation of groups by energy levels and common interests.
6. Performance Evaluation
Each simulation sequence performed the data collection to guarantee a 95% confidence interval for the estimated parameters. For each simulation run, the metric of interest was the message delivery probability, average delay, and overhead.
We applied statistical tests to estimate the efficiency of our mechanism regarding the related proposals. We divided the analysis into two subsections for each compared scenario.
6.1. Statistical Tests
In this paper, we applied the test “analysis of variance” (ANOVA), a statistical technique to verify potential significant difference among means and if these factors can influence the outcome variable.
ANOVA allows the comparison of several groups using continuous variables, and the means of outcome variables are computed within an acceptable margin of error. This error is referred to as α probability, and we selected the following values, 1%, 5%, or 10%.
In our performance evaluation, we used a significance level of 5%, α = 0.05, so we could verify the hypothesis H0: µ1 = µ2 = … = µc and H1, where the means are statistically different. So, the hypotheses applied in this paper were:
H0—Null Hypothesis, where the means do not differ.
H1—Alternative Hypothesis, where the means differ, i.e., at least one mean value is different from others. To evaluate the variance of an object, we applied Equation (5).
Furthermore, the sum of the squares of the residuals is obtained from the difference:
where SQRes, the variance within groups, is a function of differences between the same treatment repetitions. The SQTrt, variation between groups is the variance between different treatments. The mean squares are calculated as follows:
SQRes = SQTotal − SQTrt
When applied to more than two treatments, we cannot designate the best treatment for the variable outcome in case of a significant difference among samples. We also applied a statistical test to complement the results found with ANOVA.
Tukey test is based on minimum significant difference (HSD), defined by Equation (8):
where q is the total studentized amplitude given by the division of amplitude and standard deviation s for k means (number of treatments), and gl is the degree of freedom at the level α of the residue’s significance.
QMRes is the mean square of the residue, and r is the number of repetitions. If the contrast is greater than (hsd), the means differ at the significance level or < α.
6.2. Scenario Infocom
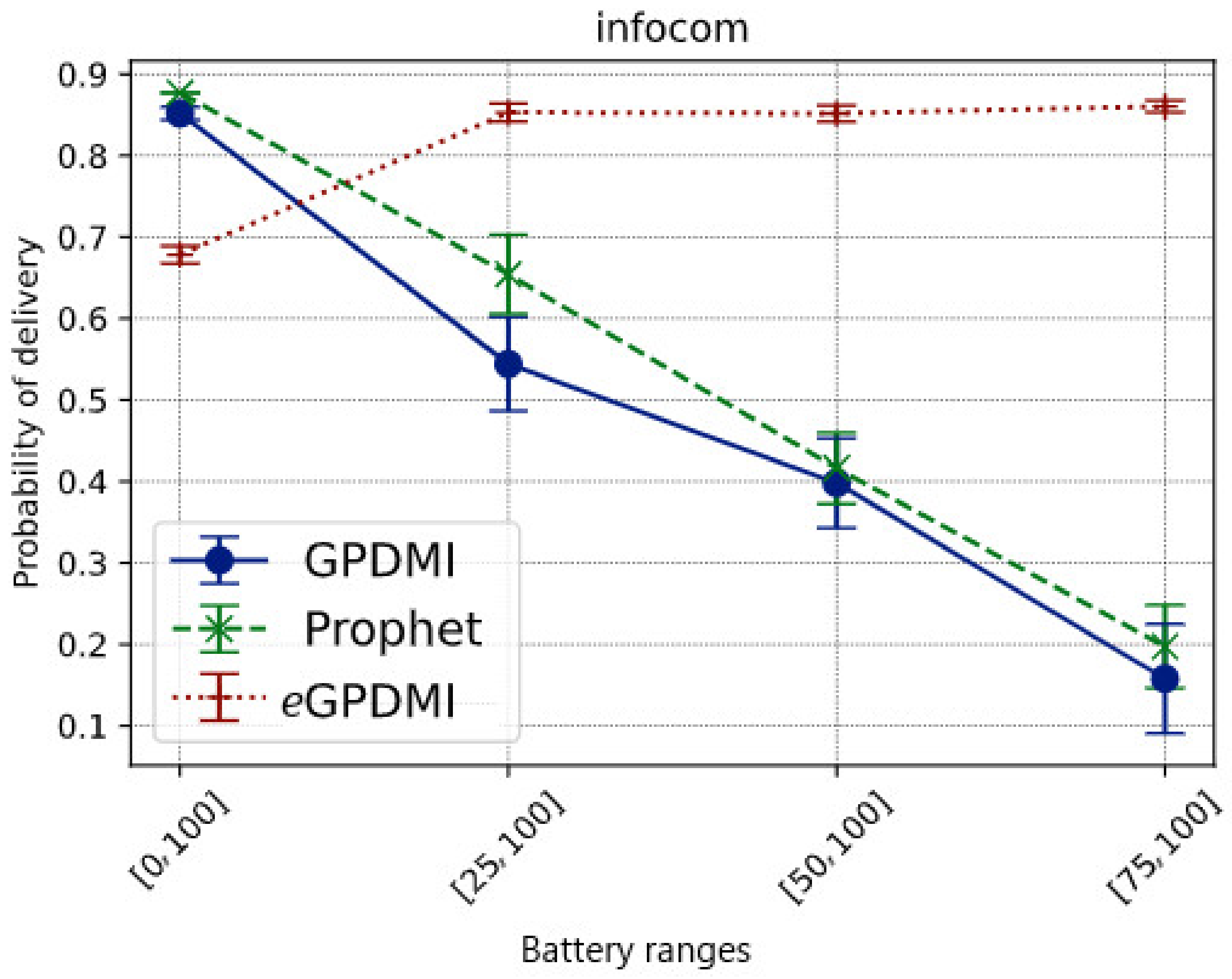
Figure 3 shows the message delivery probability in each battery range for each tested routing algorithm. When applying the clustering layer for energy level over the other decision-making factors of the routing algorithms, we intended to keep messages alive, carried by nodes with the highest level, thus, mitigating the delivery rate degradation. The results confirm this intuition, since eGPDMI achieved the best message delivery probability when nodes became less cooperative to save energy.
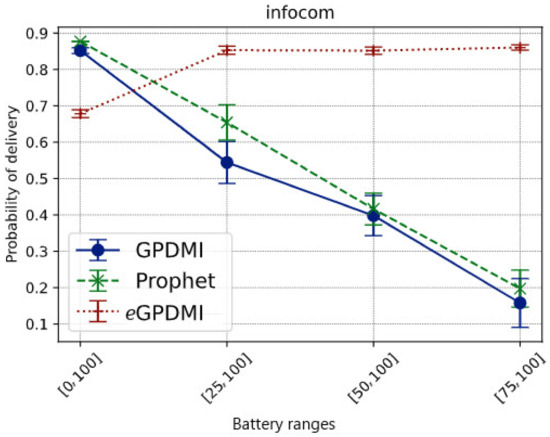
Figure 3.
Impact of battery ranges on the delivery probability of messages in the Infocom mobility scenario.
While in the base case E = [0, 100], where all nodes cooperate regardless of the battery level, our approach had a message delivery rate of approximately 70%. The other routing algorithms had about an 85% delivery rate. Regarding the probability of delivery of the message of eGPDMI, a reasonable justification for this result relates to the fact that eGPDMI groups the nodes in two groups, energy levels and interests. As there was no restriction on energy level, only interests were taken into consideration. Thus, for PRoPHET and GPDMI, the flooding was higher since there was no restriction on energy. Hence, the number of replicated messages on the network was higher when compared to eGPDMI, as can be seen in Figure 5. Even with a smaller number of replicated messages (142.85% lower), eGPDMI achieved a probability of delivery only 19.35% lower than the other two protocols.
When nodes with less than 75% battery level did not cooperate (E = [75, 100]), eGPDMI had about an 80% message delivery rate, while the other routing algorithms had a delivery rate below 25%. The reasoning is that these algorithms decide to forward for nodes most likely to have new contacts, not necessarily the nodes with the highest battery levels.
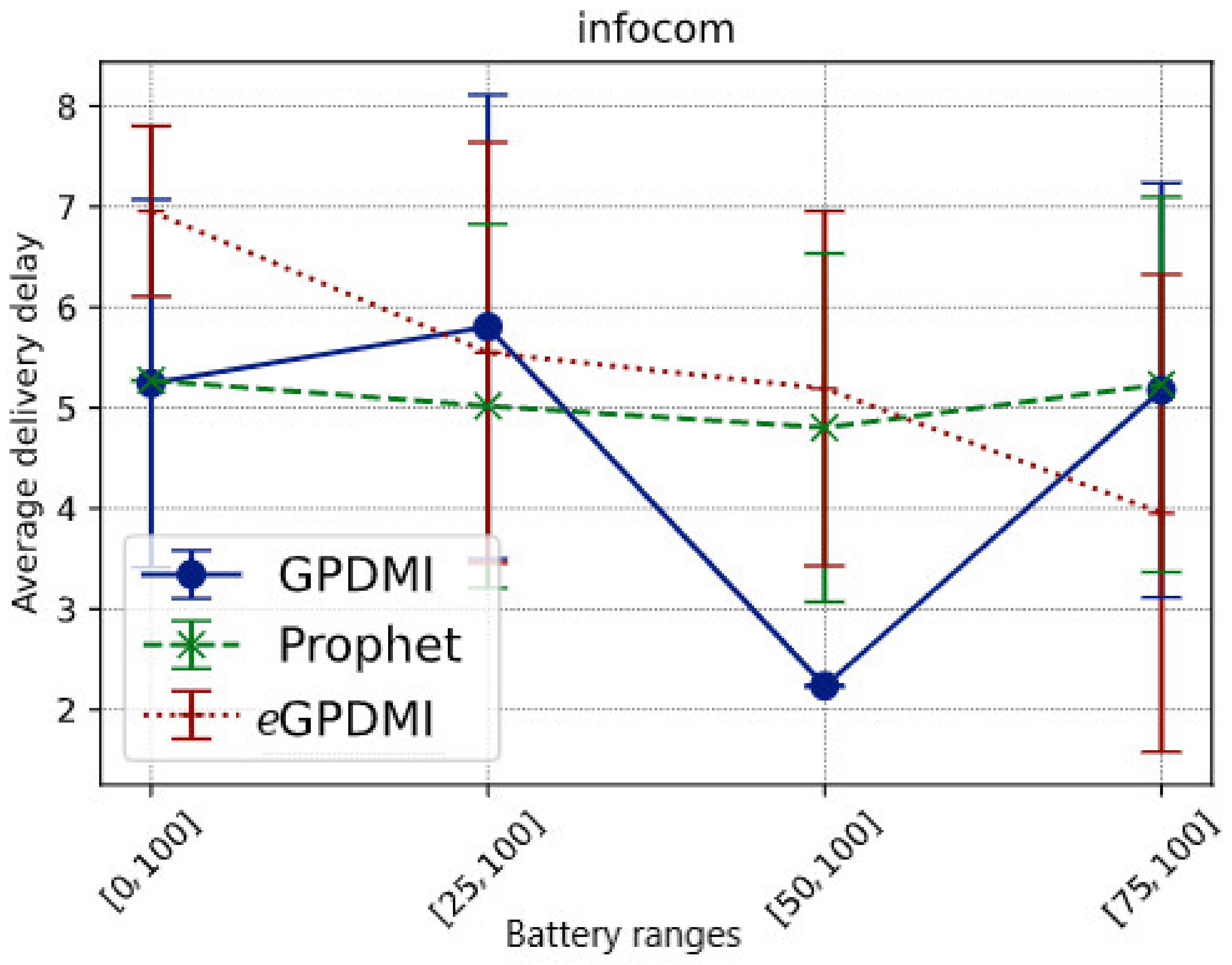
It is important to highlight that eGPDMI had a better performance (approx. 104.76%) in message delivery probability when compared to GPDMI and PRoPHET. In the result of the average delay (Figure 4), eGPDMI performed better in case E = [75, 100]. Therefore, to verify if there was a significant difference between the means, we applied the t-test, whose result demonstrates that both eGPDMI and GPDMI did not present a statistically significant difference (p-value = 0.3904). Similarly, the results comparing eGPDMI and PRoPHET (p-value = 0.3505) did not reach sufficient conditions to reject the null hypothesis. In summary, as shown in Figure 3, the probability of delivery was higher for the case E = [75, 100] without substantially increasing the average delivery delay of eGPDMI with regard to the other routing protocols, as can be seen in Figure 4.
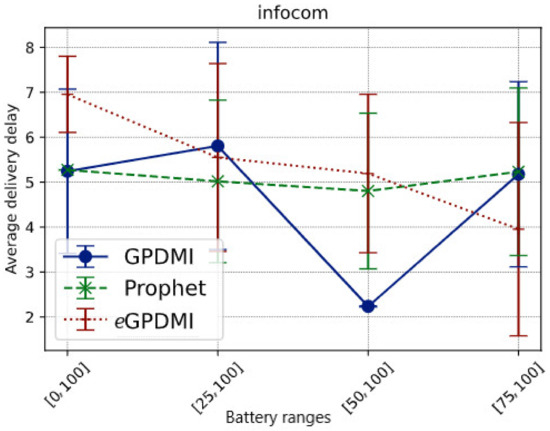
Figure 4.
Average delivery delay vs. battery ranges in scenario Infocom.
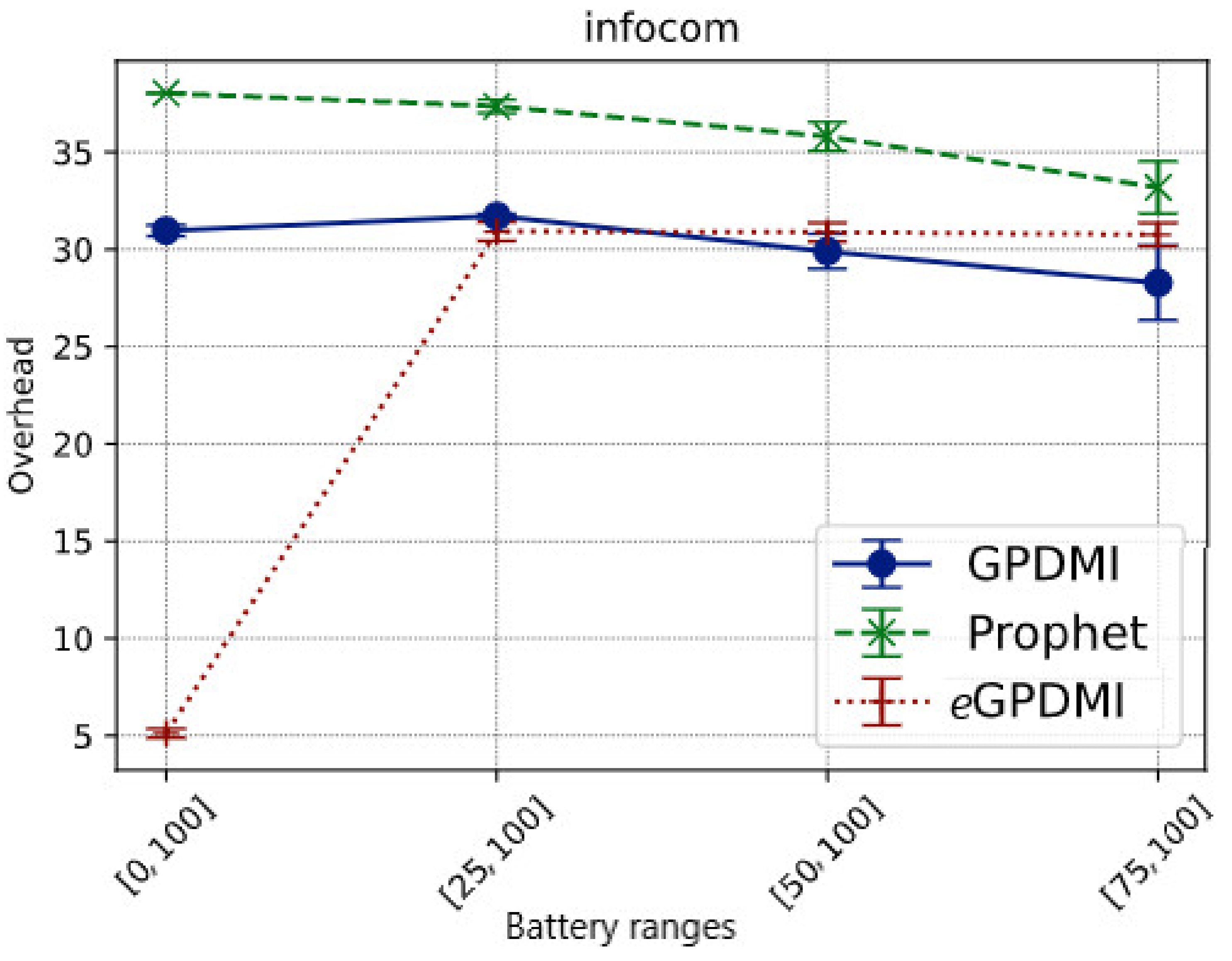
In order to measure overhead, we defined overhead as follows:
As shown in Figure 5, the overhead of our proposal (eGPDMI) is significantly lower in case E = [0, 100]. The results show that messages were relayed mostly to the nodes with the highest energy level, even if the nodes cooperated with a low battery level. Further, in this scenario, eGPDMI forwarded fewer messages than the other algorithms.
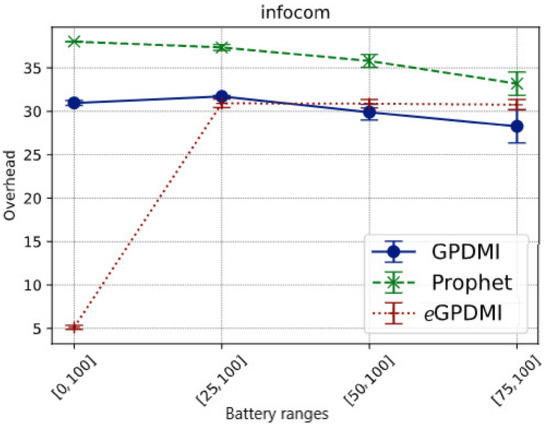
Figure 5.
Network overhead vs. battery ranges in Infocom scenario.
On the other hand, when the battery load limit to forward increased, we noticed that eGPDMI relayed more messages than GPDMI and PRoPHET. These results imply that eGPDMI can keep messages alive longer than GPDMI and PRoPHET.
6.3. ANOVA—Delivery Probability of Messages—Infocom Scenario
When applying the ANOVA statistical test in the messages delivery probability, our results show a significant difference in the battery ranges used, as shown in Table 8. Analyzing the results of the ANOVA, it is observed by the F test using 5% significance that F > Fcritical, that is, there was at least one routing algorithm with a different message delivery performance between the battery range studied.
Table 8.
Analysis of variance vs. delivery rate in scenario Infocom.
So, there is a variance in means captured by each algorithm and battery range (F = 409.58 and F = 295.17). This result supports the performance difference in delivery rates between the routing algorithms previously described in Figure 3 (delivery probability graph).
Thus, the null hypothesis H0 is rejected, where all averages are equal. To specifically address where this variation is occurring, we applied the Tukey test.
6.4. Tukey Test—Infocom Scenario
Equation (8) previously described in the subsection performance evaluation was applied to use the Tukey test in the Infocom scenario. By applying the equation to the values found in the ANOVA calculation and the other variables, we have the following result HSD = 0.058.
The HSD (minimum significant difference) is used to identify, through statistical tests, which algorithms are the same or different in the delivery performances according to the tested energy ranges. When the absolute difference of the averages (average module) calculated is greater than the value of the HSD, we say that the averages of the delivery rates of the algorithms are statistically different.
We can conclude from the results that there are relevant differences in the average performance of the delivery rates between all routing algorithms for the case where the battery range is E = [25, 100].
eGPDMI maintained the highest results with an approximately 80% delivery rate, compared with PRoPHET and GPDMI. We found no significant difference in average performance between the PRoPHET and GPDMI routing algorithms for the remaining battery ranges.
In E = [50, 100] and E = [75, 100] energy ranges, there are significant differences between the performance of the eGPDMI and the GPDMI and PRoPHET algorithms, with rates of approximately 80% and 85% delivery for the proposed algorithm, while GPDMI and PRoPHET were in the 25% range for energy cooperation in the E = [75, 100] range and 40% in delivery performance when E = [50, 100].
Finally, the Tukey test also showed differences in the performance of delivery rates between all the algorithms in the E = [0, 100] range. PRoPHET and GPDMI delivered approximately 85% of the messages on the network, and eGPDMI did not exceed 70%.
The exact values for the Tukey test are described in Table 9. These results support the previous ones in the message delivery probability, where our proposal (eGPDMI) achieved statistically different performance for all the battery load limits. Statistically, it is possible to compare the differences between the means.
Table 9.
Tukey test applied to the ANOVA results obtained in Table 8.
6.5. Reality Scenario
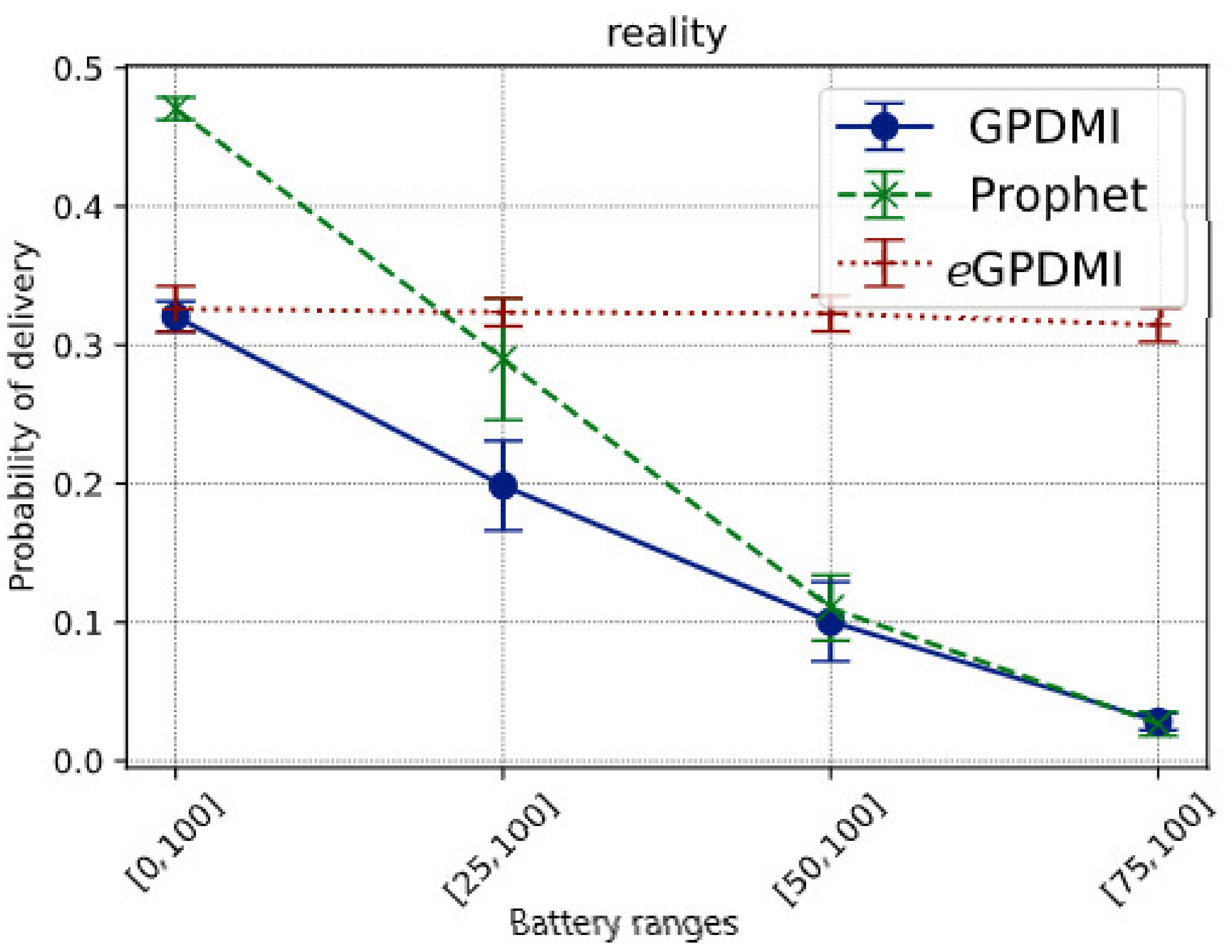
Reality is a sparser scenario. We simulated only a few days of the entire trace, as mentioned in Table 6. Hence, it is expected that the message delivery probability would be lower. Figure 6 presents the value of the delivery probability of messages for all the tested routing algorithms.
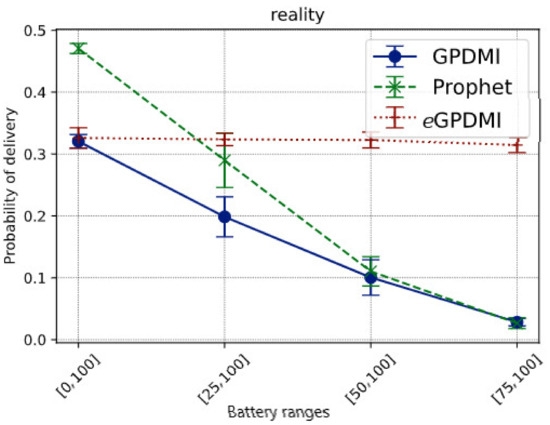
Figure 6.
Impact of battery ranges on the delivery probability of messages in the Reality scenario.
The results show that eGPDMI can stay stable even when the battery range decreases. Additionally, as the battery range decreases, the delivery rate by GPDMI decreases from 32% to below 5%. PRoPHET protocol goes from 48% to less than 5%; meanwhile, eGPDMI goes from 32% to 30%.
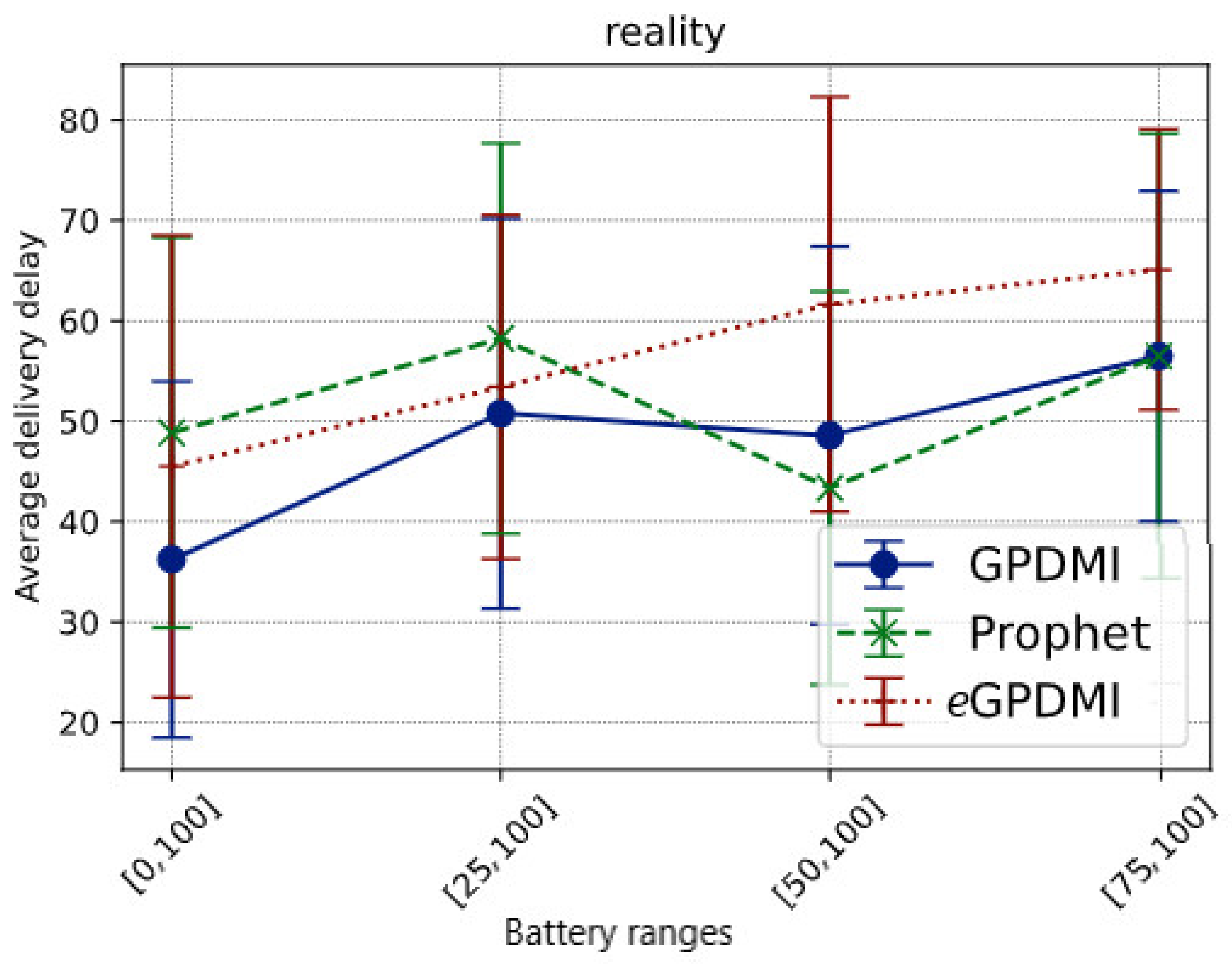
Comparing the data in Figure 6, we see that eGPDMI had a performance of approximately 142.85% better in the delivery probability regarding GPDMI and PRoPHET. Moreover, we remarked that eGPDMI had a worse performance of average delivery delay, around 13% difference (Figure 7). However, analyzing the results of the average delivery delay between eGPDMI and GPDMI, the standard deviation was 18.53 and 21.82, respectively. These values indicated that there was not a significant difference between the results. Thus, an unpaired t-test was applied to find the value of p = 0.3533, keeping the null hypothesis H0 prevailed, mean of eGPDMI = mean of GPDMI. It is essential to highlight that the same test was applied to eGPDMI and PRoPHETto obtain a p-value > 0.05.
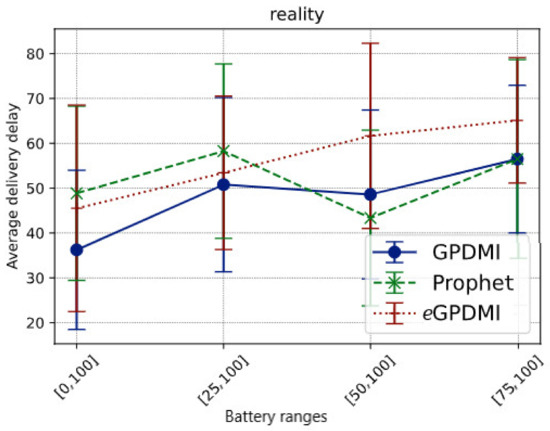
Figure 7.
Average delivery delay vs. battery ranges in Reality scenario.
It is important to emphasize that the performance of average delivery delay is statistically similar for GPDMI and PRoPHET. Furthermore, the average delivery delay was close between eGPDMI and the other routing algorithms in all battery ranges cases.
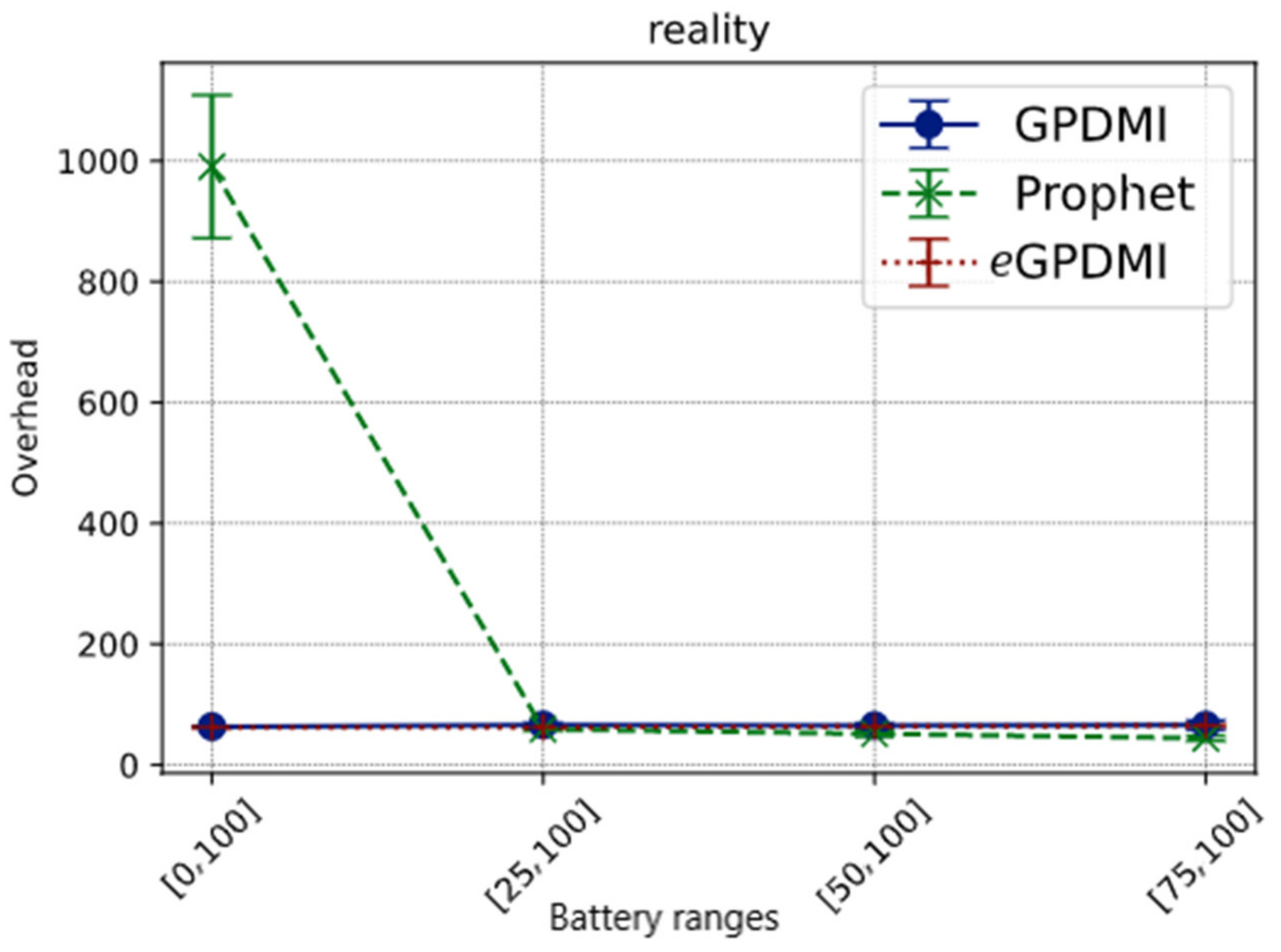
In Figure 8, in the cases where the minimum battery load limit for nodes to cooperate is greater than 25%, the overhead is less than 100 for all routing algorithms. On the other hand, when E = [0, 100], we found the overhead for the PRoPHET routing protocol to be about ten times higher than GPDMI and eGPDMI. The hypothesis for this result is that in PRoPHET, the forwarding probabilities take longer to adjust since Reality is a sparse scenario.
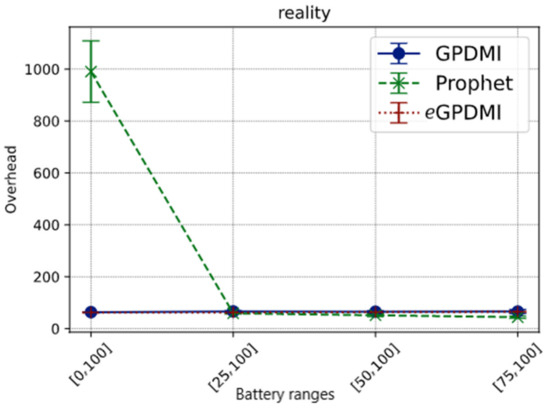
Figure 8.
Network overhead vs. battery ranges in Reality scenario.
These results further demonstrate that eGPDMI mitigates network overhead, while stabilizing the message delivery probability in both scenarios.
6.6. ANOVA—Delivery Probability of Messages—Reality Scenario
The results for ANOVA in the Reality scenario are described in Table 10.
Table 10.
Analysis of variance vs. delivery rate in Reality scenario.
There is at least one routing algorithm with relevant performance differences in message delivery probability for the variation in the battery ranges. By doing the F test, using 5% of significance, we have F > Fcritical, being F = 414.05 for the battery range and F = 299.04 for the routing algorithms, values respectively higher than the Fcritical of each one.
Hence, it is reasonable to state the impact of each battery range on the delivery probability of messages. These results also support the authors’ findings in [14], which evaluated the impact of low cooperation on network performance.
Thus, such as the analysis made in the Infocom scenario, the null hypothesis H0 is rejected where all averages are equal. We then applied the Tukey test and statistically calculated the variations.
6.7. Tukey Test—Reality Scenario
Using the Tukey test, we calculated HSD = 0.032. After analyzing the impact between the message delivery probability results of the routing algorithms, we concluded that there were significant differences in the performance averages between all routing algorithms in the battery range E = [25, 100].
In the battery range E = [0, 100], there was no difference between the performance of the proposed algorithm concerning the GPDMI algorithm. However, there was a slight difference between the eGPDMI algorithm with 32% and the PRoPHET algorithm with 48% delivery rates.
The relationship between the PRoPHET algorithm with 48% concerning GPDMI and 32% shows that the last two comparisons maintained an average of similar deliveries.
The calculation of the absolute difference of the averages (module of the averages) supports the delivery rates in Figure 6, where E = [25, 100], the GPDMI algorithm had 20%, PRoPHET 30%, and eGPDMI 32% of the message delivery probability. In the limits of E = [50, 100] and E = [75, 100], no significant differences were found between the comparison of the PRoPHET and GPDMI algorithms.
Some differences were found in other algorithms when comparing both limits. eGPDMI maintained the best results compared with GPDMI and PRoPHET. The proposal (eGPDMI) had about 32% and 30% of the delivery performance over 10% against less than 5% of the other algorithms. In summary, eGPDMI obtained a statistically different performance in almost all battery ranges, except compared to GPDMI in the E = [0, 100] range. The exact values for the Tukey test are described in Table 11.
Table 11.
Tukey test applied to the ANOVA result obtained in Table 10.
7. Conclusions and Future Works
In this paper, we presented a new routing mechanism that groups nodes inside two clusters, the cluster of highest energy level nodes and the clusters based on the profile interest of each node. We performed a questionnaire and factorial design to confirm that the energy range used for nodes to cooperate on communication has a significant negative impact on the probability of delivery of the messages.
The results showed that eGPDMI can mitigate the degradation of messages delivery probability when nodes are unwilling to cooperate due to their energy level. It is reasonable to assume that this happened due to the formation of groups composed of nodes with similar energy levels within a battery range considered by the nodes as high for cooperation in the network. eGPDMI had a general performance that was better than PRoPHET and GPDMI in higher energy level restriction scenarios, especially when the battery range for nodes cooperation was E = [75, 100] (only nodes with high energy level cooperated). In addition, by applying the t-test, no evidence of a significant difference was found among eGPDMI, GPDMI, and PRoPHET in the average delivery delay metric, even with a better performance of eGPDMI in message deliveries.
The current work has a wide range of uses in OppNets. Since there is a lack of studies that consider battery a critical parameter for routing strategy implementations, it is relevant to design protocols and other algorithms to balance energy usage, the nodes cooperation, and the messages delivery probability.
As for future work, we intend to collect accurate data on human mobility with a history of energy consumption and battery percentages of users’ mobile devices to evaluate the eGPDMI assessment experiments, applying machine learning techniques to learn about current energy levels of nearby devices. Besides, additional factors must be considered, such as time for recharging the battery, TTL of messages, and contacts duration.
Author Contributions
G.S., D.S., E.M. conceived the idea; G.S., D.S., E.M. designed and implemented the protocol optimization; G.S., D.S. and E.M. performed the experiments; G.S., D.S., E.M. analyzed the data. G.S., D.S., C.C. and E.M. wrote the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research, according to Article 48 of Decree nº 6.008/2006, was partially funded by Samsung Electronics of Amazonia Ltda, under the terms of Federal Law nº 8.387/1991, through agreement nº 003/2019, signed with ICOMP/UFAM.
Acknowledgments
This study was financed in part by the Coordination for the Improvement of Higher Education Personnel—Brazil (CAPES)—Finance Code 001.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Silva, A.P.; Burleigh, S.; Hirata, C.M.; Obraczka, K. A survey on congestion control for delay and disruption tolerant networks. Ad. Hoc. Netw. 2015, 25, 480–494. [Google Scholar] [CrossRef]
- Xu, K.; Li, V.O.; Chung, J. Exploring centrality for message forwarding in opportunistic networks. In Proceedings of the 2010 IEEE Wireless Communication and Networking Conference, Sydney, Australia, 18–21 April 2010; pp. 1–6. [Google Scholar]
- Junior, N.M.; Campos, C.A.V. Socleer: A social-based energy-efficient forwarding protocol for opportunistic networks. In Proceedings of the 2015 International Wireless Communications and Mobile Computing Conference (IWCMC), Dubrovnik, Croatia, 24–28 August 2015; pp. 757–762. [Google Scholar]
- Silva, D.R.; Costa, A.; Macedo, J. Energy Impact Analysis on Dtn Routing Protocols. In Proceedings of the ACM ExtremeCom, Zurich, Switzerland, 10–14 March 2012. [Google Scholar]
- Wang, W.; Srinivasan, V.; Motani, M. Adaptive contact probing mechanisms for delay-tolerant applications. In Proceedings of the 13th Annual ACM International Conference on Mobile Computing and Networking, Montréal, QC, Canada, 9–14 September 2007; pp. 230–241. [Google Scholar]
- Jedari, B.; Xia, F.; Chen, H.; Das, S.K.; Tolba, A.; Zafer, A.-M. A social-based watchdog system to detect selfish nodes in opportunistic mobile networks. Future Gener. Comput. Syst. 2019, 92, 777–788. [Google Scholar] [CrossRef]
- Soares, D.; Mota, E.; Souza, C.; Manzoni, P.; Cano, J.C.; Calafate, C. A statistical learning reputation system for opportunistic networks. In Proceedings of the 2014 IFIP Wireless Days (WD), Rio de Janeiro, Brazil, 12–14 November 2014; pp. 1–6. [Google Scholar]
- Bulut, E.; Dhungana, A. Social-Aware Energy Balancing in Mobile Opportunistic Networks. In Proceedings of the 2020 16th International Conference on Distributed Computing in Sensor Systems (DCOSS), Marina del Rey, CA, USA, 25–27 May 2020. [Google Scholar]
- Das Neves, E.V.; Martins, R.N.; Carvalho, C.B.; Mota, E. Disseminac¸ão de mensagens dtn com base em grupos de interesses. In Anais da IV Escola Regional de Informa´tica: Regional Norte 1-Amazonas e Roraima; ERIN: Manaus, Brazil, 2017. [Google Scholar]
- Xia, F.; Yang, Q.; Li, J.; Cao, J.; Liu, L.; Ahmed, A.M. Data dissemination using interest-tree in socially aware networking. Comput. Netw. 2015, 91, 495–507. [Google Scholar] [CrossRef]
- Zhu, Y.; Xu, B.; Shi, X.; Wang, Y. A survey of social-based routing in delay tolerant networks: Positive and negative social effects. IEEE Commun. Surv. Tutor. 2013, 15, 387–401. [Google Scholar] [CrossRef]
- Hui, P.; Crowcroft, J.; Yoneki, E. Bubble rap: Social-based forwarding in delay-tolerant networks. IEEE Trans. Mob. Comput. 2010, 10, 1576–1589. [Google Scholar] [CrossRef] [Green Version]
- Li, F.; Jiang, H.; Li, H.; Cheng, Y.; Wang, Y. Sebar: Social- energy-based routing for mobile social delay-tolerant networks. IEEE Trans. Veh. Technol. 2017, 66, 7195–7206. [Google Scholar] [CrossRef]
- Cai, Y.; Zhang, H.; Fan, Y.; Xia, H. A survey on Routing Algorithms for Opportunistic Mobile Social Networks. China Commun. 2021, 18, 86–109. [Google Scholar] [CrossRef]
- Souza, C.; Mota, E.; Galvão, L.; Manzoni, P.; Cano, J.C.; Calafate, C.T. FSF: Friendship and selfishness forwarding for delay tolerant networks. In Proceedings of the 2016 IEEE Symposium on Computers and Communication (ISCC), Messina, Italy, 27–30 June 2016; pp. 1200–1207. [Google Scholar]
- Souza, C.B.; Mota, E.; Galvão, L.; Soares, D. Gerenciamento de buffer baseado em egoísmo para redes tolerantes a atrasos e desconexões. In Anais Principais do XXXV Simpo’sio Brasileiro de Redes de Computadores e Sistemas Distribuídos; SBC: Manaus, Brazil, 2017. [Google Scholar]
- Gupta, S.; Nagpal, C.; Singla, C. Impact of selfish node concentration in manets. Int. J. Wirel. Mob. Netw. 2011, 3, 29–37. [Google Scholar] [CrossRef]
- Loudari, S.E.; Benamar, N. Effects of Selfishness on the Energy Consumption in Opportunistic Networks: A Performance Assessment. In Proceedings of the 2019 International Conference on Wireless Technologies, Embedded and Intelligent Systems (WITS), Fez, Morocco, 3–4 April 2019. [Google Scholar]
- Yu, L.; Xu, G.; Zhang, N.; Wei, F. Opportunistic Network Routing Strategy Based on Node Individual Community. In Proceedings of the 2021 IEEE International Conference on Communications Workshops (ICC Workshops), Montreal, QC, Canada, 14–23 June 2021. [Google Scholar]
- Xiong, W.; Zhou, X.; Wu, J. Effective Data Transmission Based on Cluster User Communications in Opportunistic Complexity Social Networks. IEEE Access 2020, 8, 1. [Google Scholar] [CrossRef]
- Ayub, Q.; Rashid, S. Energy Efficient Inactive Node Detection Based Routing Protocol for Delay Tolerant Network. Wirel. Pers. Commun. 2020, 116, 227–248. [Google Scholar] [CrossRef]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C 1979, 28, 100. [Google Scholar] [CrossRef]
- Amah, T.; Kamat, M.; Bakar, K.A.; Moreira, W.; Oliveira, A., Jr.; Batista, M. Measuring burden and routing fairness in pocket switched networks. In Proceedings of the 2017 XXXV Brazilian Symposium on Computer Networks and Distributed Systems, Belém, Brazil, 15–19 May 2017. [Google Scholar]
- Totaro, M.W.; Perkins, D.D. Using statistical design of experiments for analyzing mobile ad hoc networks. In Proceedings of the 8th ACM International Symposium on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Montréal, QC, Canada, 10–13 October 2005; pp. 159–168. [Google Scholar]
- Jain, R. The Art of Computer Systems Performance Analysis; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Keränen, A.; Ott, J.; Kärkkäinen, T. The one simulator for dtn protocol evaluation. In Proceedings of the 2nd International Conference on Simulation Tools and Techniques (SIMUtools), Rome, Italy, 2–6 March 2009. [Google Scholar]
- Eagle, N.; Pentland, A.S. Reality mining: Sensing complex social systems. Pers. Ubiquitous Comput. 2005, 10, 255–268. [Google Scholar] [CrossRef]
- Chaintreau, A.; Hui, P.; Crowcroft, J.; Diot, C.; Gass, R.; Scott, J. Impact of human mobility on opportunistic forwarding algorithms. IEEE Trans. Mob. Comput. 2007, 6, 606–620. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).