1. Introduction
With the development of modern machinery and equipment, the structure of equipment has become more complex. The failure of parts in machinery and equipment may cause the entire equipment to fail to operate, and the failure of key parts may cause serious casualties and economic losses. The mechanical fault diagnosis technology has matured, and its results have been widely used in industrial production. However, with the emergence and widespread application of advanced technologies such as sensors, big data, and the Internet of Things, the development trend of mechanical fault diagnosis technology is bound to be combined with contemporary cutting-edge technologies. These factors promote the transformation of the monitoring and diagnosis of industrial equipment faults to the direction of intelligence; the future development direction of this technology combines with artificial intelligence.
Rolling bearing fault diagnosis is the process of determining the damage state through detection, isolation, and identification through data collected by the health monitoring of the rolling bearing. The early fault diagnosis method of rolling bearing was relatively simple, mainly through some statistical parameters (average value, root mean square value, kurtosis, etc.) to judge the fault condition of rolling bearing. However, these statistical values cannot determine the noise and interference caused by shaft speed changes, gears, and other vibration sources. Cempel [
1] constructed a set of discriminants for the crest factor, pulse factor, harmonic factor, frequency modulation factor, and other parameters of the random vibration process. Sturm et al. [
2] designed a zero-mean normalization parameter and found that the parameter normalized to zero-mean condition is more suitable for fault diagnosis than the absolute value of the time-domain parameter. Martin et al. [
3] used standardized skewness and standardized kurtosis to determine early failures of rolling bearings. Pand et al.’s [
4] research extended the field even further and proposed the use of statistical moments to detect the health status of rolling bearings. Following this, the industry explored parameterized signal processing methods. For example, Mechefske et al. [
5] found that the effect of parameterized spectral index fault classification is better than that of traditional fast Fourier transform. Logan and Mathew [
6] have proposed a correlation integration algorithm to measure the results of the correlation di-mension on the rolling bearing test rig. Vapnik et al. [
7] proposed a learning theory based on statistics. It showed superiority in the identification of small samples and non-linear processing, which was later introduced into the field of fault diagnosis and achieved wide applications. Li et al. [
8] proposed a bearing vibration feature extraction method based on multi-scale permutation entropy and binary tree based on an improved support vector machine. Lin [
9] analyzed the impact of different Gaussian kernel functions, such as fine, medium, and coarse, on the performance of the SVM algorithm in the classification results of related motor data sets obtained by motor fault detection and diagnosis. The most critical part of bearing fault diagnosis is to effectively process the collected vibration signals to obtain features that can express bearing state information, that is, feature extraction, which lays a good foundation for subsequent fault pattern recognition. Vibration signal processing methods generally include three types of analysis: time domain analysis, frequency domain analysis, and time-frequency domain analysis [
10]. Empirical mode decomposition can adaptively decompose non-stationary signals based on the time scale. It is a signal processing method that is widely used in the field of mechanical fault diagnosis [
11,
12]. Han et al. [
13] proposed a new power-based IMF selection algorithm and used an improved fully integrated EMD with adaptive noise and a multilayer perceptron neural network to verify the performance of the proposed fault diagnosis system. Lee and Hung [
14] proposed a feature ranking and differential evolution method for feature selection in brushless DC motor BLDC fault diagnosis. This research uses Hilbert–Huang transform (HHT) to extract the hall signal characteristics of four different types of brushless DC motors. Wang [
15] proposed to use short-time Fourier transform (STFT) to preprocess the original signal to obtain the corresponding time-frequency diagram. Then, a convolutional neural network (CNN) began to be used to adaptively extract the features of the time-frequency image. Li [
16] proposed pseudo-Wigner–Ville distribution and relative cross information methods for intelligent fault diagnosis methods for motor roller bearings running at unsteady speed and load. Gu et al. [
17] developed a new type of long short-term memory (LSTM) model with discrete wavelet transform (DWT) for multi-sensor fault diagnosis. Nguyen’s [
18] research applies the wavelet vibration imaging method (WVI) to the denoised vibration signal. The obtained scale map is used as the input of the deep convolutional neural network architecture (DCNA), which is used to extract the discriminative features in the gearbox and the multiple degree tooth failure (MDTF) classification under variable speed conditions. Dragomiretskiy et al. [
19] proposed variational mode decomposition, which is a new non-recursive, variational adaptive signal processing method. The decomposition process is the process of solving the variational problem. Specifically, it first constructs the variational problem for the input signal. Then, by solving the variational problem, the signal is decomposed into a specified number of eigenmode functions. In addition, variational mode decomposition has gained attention and application in bearing fault diagnosis [
20]. Lin’s research proposed an automatic fault diagnosis system combining VMD and ResNet101 for bearing fault diagnosis. Recent efforts have also been made in the field of deep learning to promote the miniaturization of neural networks. While ensuring the accuracy of the model, it is smaller and faster and will become a popular method in the future. These models make it possible for mobile terminals and embedded devices to run neural network models. Online and timely diagnosis can be achieved in intelligent fault diagnosis. This research proposes a comparison of advanced lightweight network models such as ShuffleNet, MobileNet, and DenseNet as traditional deep learning networks are large, slow, and complicated. Lin’s research, for example, uses the Federal University of Rio de Janeiro database, a traditional fixed speed database. The database of this research is special the speed of each data is different from the traditional fixed speed, yet the database is more challenging. Traditional machine learning methods such as artificial neural networks, sparse representation, fuzzy inference, SVM have been widely applied in bearing fault diagnosis [
21,
22,
23]. Recent years have seen the advancement of training deep network technology and a substantial increase in hardware computing capabilities. Deep learning and machine learning technologies have more powerful feature extraction and processing capabilities, as well as wide applicability and model migration capabilities; this superior performance makes them widely used in various industries. Methods based on deep learning have gradually become the focus of attention, and related fault diagnosis research is shown in the literature [
24,
25,
26,
27,
28]. In a paper published by Google, the MobileNet lightweight network was proposed. The MobileNet deep convolutional neural network is mainly developed for mobile terminals or embedded devices [
29]. Compared with traditional convolution, MobileNet uses depth separable convolution to divide the convolution operation into two parts, Depthwise and Pointwise. The calculation amount of depth separable convolution can be eight to nine times less than that of traditional convolution. The design goal of ShuffleNet also includes how to use limited computing resources to achieve the best model accuracy, which requires a good balance between speed and accuracy [
30]. The core of ShuffleNet uses two operations: pointwise group convolution and channel shuffle, which greatly reduces the amount of model calculations while maintaining accuracy. After ResNet, Huang [
31] proposed the DenseNet network, which inherited the idea of residual network and improved the connection method. The DenseNet network takes image features as the starting point, and achieves better results, and reduces a large number of parameters through the reuse of image features.
Traditional machine learning or deep learning classification prediction requires the selection of features. The features to be used and the number of features are determined and selected according to the intended use; there is no fixed standard operating procedure. The spectrogram analyzed by VMD can fully present the characteristics of bearing diagnostic signals. Through image classification and prediction in deep learning, ResNet is a good method of classification and prediction. Compared with convolutional neural networks and general deep learning methods, ResNet can solve the problems, to an extent, of gradient descent and gradient disappearance. It produces it as the number of layers increases, and each layer has a corresponding weight, and the number of parameters will increase accordingly. In order to achieve real-time bearing monitoring and diagnosis, it is necessary to reduce the amount of network calculations. In recent years, DenseNet has been proposed. DenseNet is also an improved neural network framework based on convolutional neural networks, which is mainly composed of dense blocks, transition layers, and bottleneck layers. In order to further improve the efficiency of information flow between the various layers, DenseNet proposes a different connection method, that is, the direct connection from which layer to all subsequent layers is introduced. It enhances the propagation of features to promote the repetition and effective use of features, reduces the number of parameters, and simultaneously reduces the calculation. Therefore, VMD spectrogram plus DenseNet is suitable for bearing fault diagnosis.
The research contribution aims to use VMD to analyze the Hilbert spectrum, convert the one-dimensional bearing signal into a two-dimensional time-frequency graph, and combine it with the deep neural network DenseNet to realize intelligent fault classification prediction and diagnosis. Generally, neural networks require high-intensity calculations, but for small and medium-sized embedded systems, computing resources are limited. In order to deploy the network model in a small embedded system, it mainly compresses the large-scale classical classification network model and reduces the number of parameters of the model operation so that it can run in the case of insufficient CPU, memory, or other hardware resources.
4. Results and Discussion
The process of VMD involves three very important theories: Wiener filtering, Hilbert transform, and frequency mixing. The basic principle of VMD uses Wiener filtering and Hilbert transform to construct multiple constraint problems from an input signal and to solve the constraint problem by continuously updating the bandwidth and center frequency of each constraint problem. Finally, the adaptive decomposition of the vibration signal is realized because the VMD method uses a non-recursive, variational adaptive decomposition mode. Therefore, it can effectively solve the problems of mode aliasing and end effect in other commonly used mechanical fault vibration signal processing methods. In addition, the VMD method has the advantages of fast running speed and stable decomposition results.
The VMD parameter setting uses Max Iterations, one of the optimizations’ stopping criteria; the optimization of Max Iterations is stopped when the number of iterations is greater than 600, the maximum number of optimization iterations of 600. Num IMF (the number of extracted IMFs) is 5 IMF, Initial IMFs (initial IMF) is a zero matrix, and Penalty Factor (penalty factor) is 1500. This parameter determines the fidelity of reconstruction. Using a smaller penalty factor value can obtain tighter data fidelity. LMU update Rate (the update rate of the Lagrangian multiplier) is 0.01, which is the update rate of the Lagrangian multiplier in each iteration. A higher rate will lead to faster convergence, but it will increase the optimization process into a local, best opportunity. The initialize method is peaked, and peaks initialize the center frequency to the peak position of the signal in the frequency domain.
This result discusses the application of the VMD method to the actual bearing vibration signal, and for the healthy state of the rolling bearing as well as the different positions of the inner ring, outer ring, and rolling element mixing (acceleration, deceleration, acceleration and deceleration, and deceleration and acceleration). The four speed-increasing modes are tested experimentally using the VMD method.
Figure 3 and
Figure 4 show the VMD analysis of the healthy bearing state. The motor speed is increased from 846 RPM to 1428 RPM.
Figure 3 is the time-domain waveform diagram of the vibration signal,
Figure 3 and
Figure 4 show the VMD analysis of the healthy bearing state. The motor speed is increased from 846 RPM to 1428 RPM.
Figure 3 is the time-domain waveform diagram of the vibration signal VMD.
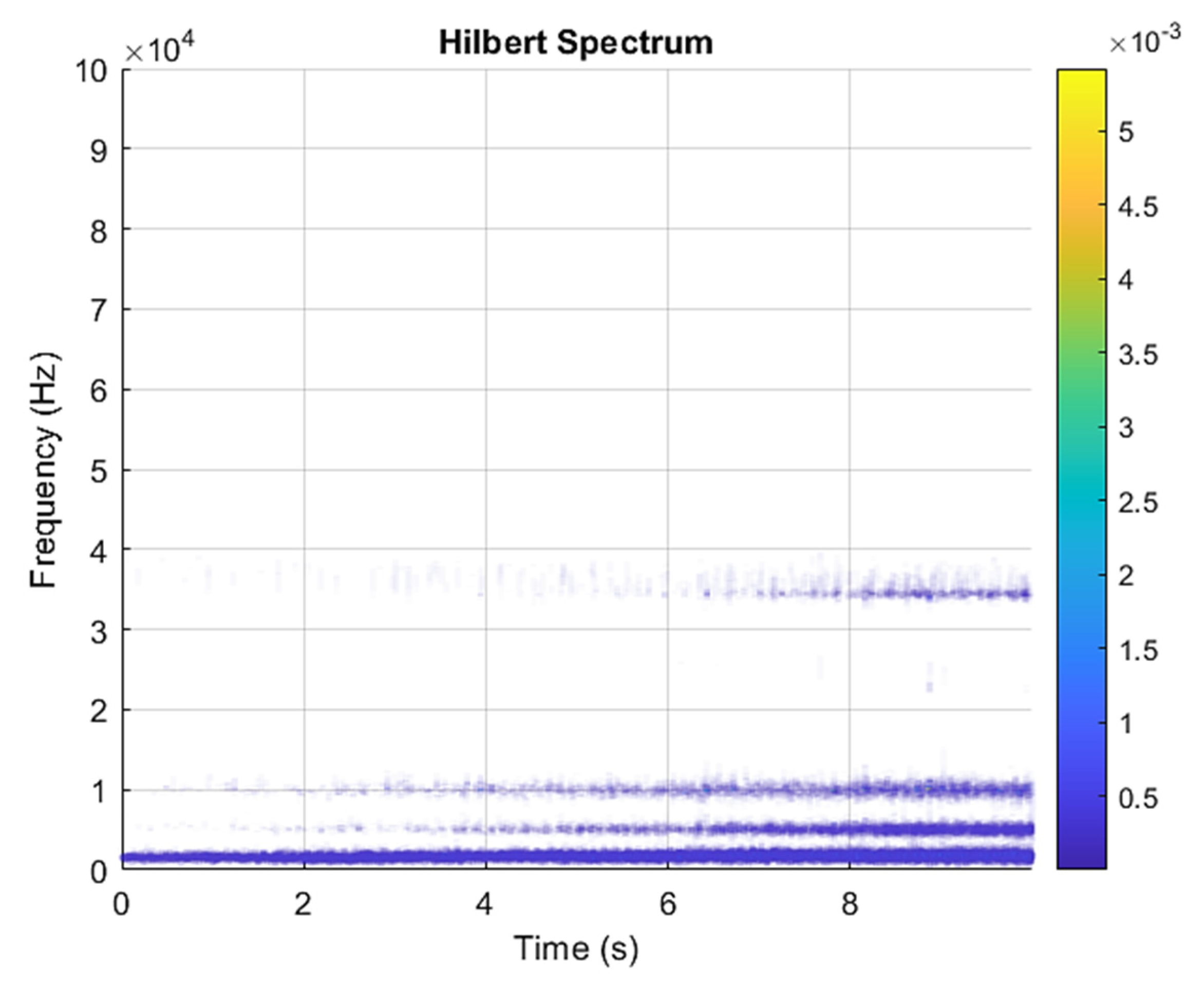
Figure 4 is a component spectrum diagram; each state vibration signal is decomposed into five mode components. The results show that the IMF Hilbert marginal spectrum of the vibration data processed by VMD has a higher frequency resolution. There are five frequencies in healthy bearings, the most obvious being 57 k Hz, 35 k Hz, 15 k Hz, 5 k Hz, 1.6 k Hz. The healthy bearing has not changed due to the increase in speed. The healthy bearing has four transmission modes: increase, deceleration, increase and then decelerate, and deceleration and increase again. Each mode contains data with three measurements, and the speed is measured each time. There are a total of 12 different test data; these data are all converted into images of Hilbert’s marginal spectrum.
Figure 5 and
Figure 6 are the VMD analysis results of the inner race fault bearing state, and
Figure 4 is the time-domain waveform diagram of the VMD of the vibration signal.
Figure 6 is a component spectrum diagram; each state vibration signal is decomposed into five mode components. The results show that the IMF Hilbert marginal spectrum of the vibration data processed by VMD has a higher frequency resolution. There are five frequencies in healthy bearings, the most obvious are 35 k Hz, 23 k Hz, 9 k Hz, 5.4 k Hz, 1.9 k Hz. The higher the speed of the faulty bearing, the greater the vibration. The inner race fault bearing also has four transmission modes: increase, decrease, increase and decrease, and decrease and increase. Each mode has three measurements. The rotation speed is different during each measurement, and there is a total of 12 test data; these data are all converted into images of Hilbert’s marginal spectrum.
Figure 7 and
Figure 8 show the VMD analysis results of the outer race fault-bearing state. Among them,
Figure 6 is the time-domain waveform of the vibration signal variational mode decomposition.
Figure 8 is the component spectrogram. Each state vibration signal is decomposed into five mode components. The results show that the IMF Hilbert marginal spectrum of the vibration data processed by VMD has a higher frequency resolution. There are five frequencies in healthy bearings, the most obvious being 65 k Hz, 37 k Hz, 10 k Hz, 5 k Hz, 750 Hz. The higher the speed of the faulty bearing, the greater the vibration. The outer race fault bearing also has four speed modes: increase, decrease, increase and decrease, and decrease and increase. There are three measurements for each mode, and the rotation speed is different during each measurement. There are 12 test data in total; these data are all converted into images of Hilbert’s marginal spectrum.
Figure 9 and
Figure 10 are the VMD analysis results of the ball fault-bearing state.
Figure 9 is the time-domain waveform of the vibration signal’s VMD.
Figure 10 is the component frequency spectrum. The results show that the IMF Hilbert marginal spectrum of the vibration data processed by VMD has a higher frequency resolution. There are five frequencies in healthy bearings, the most obvious being 33 k Hz, 22 k Hz, 10 k Hz, 5 k Hz, 1.9 k Hz. The higher the speed of the faulty bearing, the greater the vibration. The ball fault bearing also has four speed modes: increase, decrease, increase and decrease, and decrease and increase. There are three measurements for each mode, and the rotation speed is different during each measurement. There are 12 test data in total; these data are all converted into images of Hilbert’s marginal spectrum.
Figure 11 and
Figure 12 are the VMD analysis results of the combined fault-bearing state, and
Figure 11 is the time-domain waveform of the vibration signal’s VMD.
Figure 12 is a component spectrum diagram; each state vibration signal is decomposed into four mode components. The results show that the IMF Hilbert marginal spectrum of the vibration data processed by VMD has a higher frequency resolution. There are four frequencies in healthy bearings, the most obvious being 9 k Hz, 7 k Hz, 5 k Hz, 1.5 k Hz. The higher the speed, the greater the vibration of the faulty bearing. The combined fault bearing has four speed modes: increase, decrease, increase and decrease, and decrease and increase. There are three measurements for each mode, and the rotation speed is different during each measurement. There are 12 test data in total. These data are all converted into images of Hilbert’s marginal spectrum.
In this study, all five categories of data, which included healthy, inner race fault, outer race fault, ball fault, and combined fault, were analyzed by VMD and converted into the Hilbert spectrum. Each category contained 12 test data; a total of 60 test data and 60 Hilbert spectrograms of VMD were obtained.
VMD time-domain waveform diagrams and component spectrograms of faults in different parts of the bearing are also different. This part is mainly to carry out the VMD of the fault vibration signals of different parts of the rolling bearing. In this way, the feature extraction of different parts of the bearing is realized, and finally, the diagnosis of the bearing fault is realized by comparing and analyzing the characteristic information of the healthy state and the fault state of different parts. From the analysis of the time-domain waveform diagram, it can be found that in the four failure states of the bearing, the vibration signal has a certain impact, and the frequency of each mode component is also different. It can be seen from the spectrogram of the four state components of the bearing that the vibration signal is processed by the VMD method. The bearing signals of different parts are effectively decomposed according to a certain bandwidth, and there is almost no mode aliasing between the mode components. By comparing and analyzing the component spectrograms under the four failure states, it is possible to simply analyze several failure states of the rolling bearing from the frequency distribution range, the energy level of the corresponding component spectrum, and the vibration intensity.
The IMF components obtained by VMD decomposition of the above healthy and four types of motor faults are subjected to Hilbert transformation, although the obtained Hilbert marginal spectra are different. However, because there are four different speed modes and the frequencies are close, engineers without professional training cannot understand the fault situation at first glance. In order to evaluate the method proposed in the text more comprehensively, it is compared with the current mainstream methods on the same test set, from both qualitative and quantitative aspects.
Efforts are also being made in the field of deep learning to promote the development of the miniaturization of neural networks. While ensuring the accuracy of the model, it is smaller and faster. This study has proposed a comparison of lightweight network models that make it possible for mobile terminals and embedded devices to run neural network models.
This research uses three deep learning image classification models/methods for identification: MobileNet, ShuffleNet, and DenseNet, to find the method with the highest recognition rate. Each category has only 12 images; in order to retain more images for verification testing, 60% of each category of images are trained, and 40% are verified. Therefore, there are seven images of each category for training and five images for verification testing. The size of the image in the training process is 224 × 224 × 3, and the pixels of the image will affect the training accuracy. The higher the pixel of the image, the higher the accuracy can be obtained, but the calculation time will increase.
By plotting various indicators during training, researchers can understand the training progress. For example, the figure can determine whether the accuracy of the network has improved and the speed at which it has improved, as well as whether the network has begun to overfit the training data.
Figure 13 shows the results of DenseNet training and verification network monitoring. The figure demonstrates the following:
Training accuracy—the classification accuracy of each mini-batch.
Smooth training accuracy—Smooth training accuracy is obtained by applying a smoothing algorithm to training accuracy. It is less noisy than unsmoothed precision, and it is easier to spot trends.
Validation accuracy—The classification accuracy of the entire validation set.
Training loss, smooth training loss, and validation loss—the loss of each mini-batch, its smoothed version, and the loss of the validation set, respectively. If the last layer of the network is the classification layer, for example, then the loss function is the cross-entropy loss.
Once the training is complete, results are checked, which shows the final verification accuracy and reason for the end of the training. The final verification index is marked as Final in the drawing. After the training is over, the results are checked, which shows the final verification accuracy and the reason for the end of the training. The final verification index is marked as Final in the drawing. The figure on the right shows information about training time and settings.
In order to test the three methods with the same parameter settings, the specified algorithm, the Stochastic Gradient Descent (SGDM) optimizer with momentum, is used. The parameters can be explained as follows.
Verbose is 0. Verbose is an indicator that displays training progress information. Verbose consists of 1 (true) and 0 (false).
Verbose Frequency is 50. Frequency of verbose printing, which is the number of iterations between printing to the command window.
Max epochs is 10. Max epochs is the maximum number of epochs. It is used for the maximum number of epochs of training. Iteration is a step in the gradient descent algorithm that uses small batch processing to minimize the loss function. An epoch is a full traversal of the training algorithm on the entire training set.
Mini batch size is 4. Mini-batch size, the size of the mini-batch used for each training iteration. Mini-batch processing is a subset of the training set used to evaluate the gradient of the loss function and update the weights.
Validation frequency is 3. Validation frequency is the frequency of network validation.
Validation patience is 5. Validation patience is the patience of validation stopping.
Initial learn rate is 0.0001. The initial learning rate is 0.01, but if the network training does not converge, you may wish to choose a smaller value. Learn rate schedule is none. Learn rate schedule is an option for dropping the learning rate during training.
Learn rate drop period is 10. Learn rate drop period is number of epochs for dropping the learning rate.
Learn rate drop factor is 0.1. Learn rate drop factor is the factor for dropping the learning rate.
L2 Regularization is 0.0001. L2 Regularization is a factor for L2 regularization.
Momentum is 0.9. Momentum is the contribution of the previous step.
Gradient threshold is Inf. The gradient threshold can be Inf or a positive value. Gradient threshold method is L2 norm.
Sequence length is longest. Sequence length fills the sequence in each mini-batch to make it the same length as the longest sequence. This option will not discard any data, but padding may cause noise to the network.
Sequence padding value is 0. Sequence padding value is the value to pad input sequences.
Execution environment is GPU. GPU is the hardware resource for training the network. Due to the popularity of deep learning, convolutional neural network models in the field of computer vision, such as MobileNet, are emerging in an endless stream, and the application of deep learning network models in image processing is improving. Neural networks are expanding, their structures are becoming more complex, and the hardware resources required for prediction and training are gradually increasing. Often, deep learning neural network models can only be run on servers with high computing power, and on mobile devices are difficult to run complex deep learning network models due to the limitations of hardware resources and computing power.
The classification results of MobileNet are shown in
Figure 14. The classification accuracy rate of the predicted five categories is as follows: 100% for ball fault bearing, inner race fault bearing, and outer race fault bearing; 71.4% for combination fault bearing; 83% for healthy bearing; and the total classification accuracy rate of 88%.
The authors’ proposal is to use the ShuffleNet network and Point group convolution to improve the computational efficiency of convolution. The proposed channel shuffle operation can realize information exchange between different channels, which helps to encode more information. Compared with many other advanced network models, ShuffleNet greatly reduces the calculation cost and achieves excellent performance while ensuring calculation accuracy. In fact, grouped convolution was used in the AlexNet network model at the earliest, and some efficient neural network models such as Xception and MobileNet proposed later introduced deep separable convolution on the basis of grouped convolution. Although the ability of the model and the amount of calculation can be coordinated, the calculation amount of point-by-point convolution in the model occupies a large part. Therefore, the pixel-level group convolution is introduced in the ShuffleNet structure to reduce the computational complexity caused by the convolution operation. The ShuffleNet classification results are shown in
Figure 15. The classification accuracy rate in the predicted three categories shows a classification accuracy rate of 100% for ball fault bearing, combination fault bearing, and inner race fault bearing; 71.4% for healthy bearing; 80% for outer race fault bearing; and a total classification accuracy rate of 88%.
Huang [
31] proposed the use of DenseNet network following ResNet [
32], which inherited the idea of residual network and improved the connection method. The DenseNet network takes image features as the starting point, and achieves better results, and reduces a large number of parameters through the reuse of image features. Instead of learning redundant features multiple times, feature reuse is a better feature extraction method. The advantages of DenseNet network compared to other deep networks are as follows:
(1) Compared with other deep network structures, it has fewer parameters.
(2) Based on the idea of residual network, the idea of feature reuse is added to the bypass.
(3) For network training, it prevents over-fitting, is easy to train, and has a certain regularization effect.
(4) The problem of vanishing gradient is alleviated.
There are many Dense block modules in the DenseNet network structure. In the Dense block module, the feature maps of different layers need to be connected. Therefore, the size of the feature maps in the Dense block must be kept the same.
The DenseNet classification results are shown in
Figure 16. The classification accuracy rate of the predicted 100% in the five categories is 71.4% for combination fault bearing, healthy bearing, inner race fault bearing, outer race fault bearing, and ball fault bearing. The total classification accuracy rate is 92%.
In order to verify the computing time, this study compares the typical networks Alexnet, GooleNet, and ResNet with the three models of this study under the same standard, and shows the results in
Table 2. The table compares the computing time and accuracy of the six models. All models have good classification prediction performance, but the DenseNet computing time is 146 s and the accuracy of 92% is the best in this study.
Based on the above research results, these three predictive classification methods have excellent performance, but the accuracy rate of DenseNet can reach 92%, which is the highest. The advantages of DenseNet are compared with other convolutional neural networks. DenseNet has excellent performance, mainly in the number of parameters, less calculation, and strong anti-fitting ability. DenseNet also has a strong anti-overfitting ability, which is suitable for network training when data is relatively scarce. Because the information flow and gradient flow in the entire network are improved, it is easy to train; the directly connected dense block structure itself has a regularization effect. It allows each layer to receive in-depth supervision and obtain gradient information from the loss function and input signal, which is more helpful for training deep network structures and is suitable for bearing fault diagnosis.
This study has some limitations. First, there must be sufficient data length. In this study, a total of 2,000,000 points were recorded for 10 s. If the data length is too small, VMD cannot present a complete Hilbert spectrogram, and deep learning cannot correctly classify it. Second, obtaining data must not be interfered with by noise. When the original signal is submerged in noise, it cannot be analyzed or is analyzed incorrectly. Third, the original limitation of VMD still exists, and will have mode mixing and end effect. Finally, the disadvantage of DenseNet is that training takes up a substantial amount of memory. Each splicing operation will open up a new memory to store the spliced features. This results in an n-layer network, which consumes the memory equivalent to n(n + 1)/2-layer network (the output of the i-th layer is stored in memory (n − i + 1)).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}