Abstract
An improved spectral reflectance estimation method was developed to transform captured RGB images to spectral reflectance. The novelty of our method is an iteratively reweighted regulated model that combines polynomial expansion signals, which was developed for spectral reflectance estimation, and a cross-polarized imaging system, which is used to eliminate glare and specular highlights. Two RGB images are captured under two illumination conditions. The method was tested using ColorChecker charts. The results demonstrate that the proposed method could make a significant improvement of the accuracy in both spectral and colorimetric: it can achieve 23.8% improved accuracy in mean CIEDE2000 color difference, while it achieves 24.6% improved accuracy in RMS error compared with classic regularized least squares (RLS) method. The proposed method is sufficiently accurate in predicting the spectral properties and their performance within an acceptable range, i.e., typical customer tolerance of less than 3 DE units in the graphic arts industry.
1. Introduction
One of the ultimate goals of spectral estimation from a camera image is to predict the spectral reflectance data that represent the physical properties of a device-dependent camera signal. Spectral reflectance is a major area of interest in many fields, including biometric identification [1,2], art archiving [3], cosmetics [4,5], agriculture [6], and high-fidelity color reproduction [7]. Thus, the technique of spectral estimation from camera images has gained importance.
Generally, it is acknowledged that spectral reflectance estimation from a three-channel RGB camera has a relatively lower estimation accuracy compared with a multispectral imaging system that contains more signal channels with different filtration mechanisms. Conventionally, a multispectral imaging system is constructed using a camera with bandpass filtration systems, such as narrowband filters, liquid crystal tunable filters (LCTF) [7,8,9,10,11], programmable illumination imaging system [12,13,14,15,16,17], or broadband filters with trichromatic cameras [18,19,20,21,22,23]. It is worth mentioning that, with dramatically developing technology for both digital cameras and LED lighting, a multispectral imaging system with consumer-grade cameras and broadband lighting can be developed with much lower cost and easier operation processing, although the spectral reflectance estimation algorithm needs to be developed and verified.
The current literature on spectral reflectance estimation is extensive and focuses particularly on accurate algorithms. These algorithms can be classified into three groups: model-based methods, interpolation methods, and learning-based methods [20]. Recently, learning-based reconstruction has developed dramatically. It can use low-cost but high-resolution cameras, and it is convenient in practical applications because it is not necessary to characterize the spectral sensitivity function of the imaging system, which has a low requirement in wavelength resolution similar to a spectrophotometer. The performance, however, is greatly affected by the choice of the training set used as part of the characterization process. In recent years, there has been an increased amount of literature on learning-based algorithms, for example, the pseudoinverse method, Wiener estimation [23,24], principal component analysis [25,26,27], and polynomial-based regression models [18,28,29]. For example, Berns et al. proposed an image-based spectral reflectance estimation method using matrix R based on the Wyszecki hypothesis by combining a trichromatic camera and absorption filters [18,19]. Hardeberg et al. proposed a method using a principal eigenvector technique and pointed out that any spectral reflectance can be expressed as a linear combination of basic functions and a scalar vector and evaluated illuminant estimation models from color to multispectral imaging [7,10]. Li and Cao proposed two reconstruction methods, based on local linear regression, which achieve reasonable reconstruction accuracy [30,31]. Shen et al. reported that the partial least squares regression (PLS) method could also be adopted in constructing a regression model based on the correlation between response value and spectral reflectance [32]. All these studies claimed to have achieved good results using different metrics.
Overall, most studies use a mathematical algorithm for spectral estimation. However, the impact of overfitting, which would lead to poor accuracy performance, has not been sufficiently investigated. Overfitting is usually caused by the polynomial degree of camera signal expansion. When using higher degree polynomials, the irrelevant detail and noise in the training dataset are picked up and learned as concepts, and the error for the test set starts to rise as the model’s ability to generalize decreases, i.e., when a model works well for the training set data but performs badly on the test set. Several approaches could be used to reduce this problem, such as approaches based on reducing the feature numbers or imposing penalties by putting weights on the features, such as the regularization method [33,34,35,36,37,38,39,40]. For example, Shen et al. proposed a nonlinear regression method based on a polynomial model for spectral estimation, with consideration being given to the potential overfitting problem in the polynomial-based regression model [14,33]. Graham et al. demonstrated that the root-polynomial regression model could provide leading performance in both spectral recovery and color reproduction. Harifi et al. initially applied the principal component analysis embedded regression method to recover the spectral reflectance, and a third-order polynomial system was found to be best for the calculation of the transformation matrix [28]. Therefore, a method that reduces the problem of overfitting as well as characterizes the nonlinearity of the spectral reflectance estimation of multispectral imaging systems should be promising.
The main aim of this study is to develop a multispectral imaging system using an RGB camera and two commonly used illuminants. We specifically focused on the development of a more accurate spectral estimation method from raw camera responses using the iteratively reweighted regularization regression model proposed in this study. To solve the overfitting problem, we develop a feature selection process that uses neighborhood component analysis. The superior performance of this proposed method is evaluated and compared with existing methods by using both a semiglossy ColorChecker SG (CCSG140) chart and a matte ColorChecker DC chart (CCDC240). The overall performance of both the proposed and the traditional methods is compared in terms of both spectral and colorimetric accuracy.
2. Multispectral Imaging Model
In this section, we show the details of the proposed method. Two raw images are captured under two different color temperature lighting conditions to recover the spectral reflectance of a scene.
2.1. Regularization Model
The camera response is proportional to the intensity of the captured light; thus, the camera response can be expressed as a linear combination of the camera sensitivity functions, the illumination spectral power distribution, and the spectral reflectance of the objects. As has been shown in previous work [5,6,7,8,9,10], the camera sensor response vector c can be formulated as spectral reflectance:
where S is a 31 × 3 matrix that represents the spectral sensitivities of the sensors (assuming we have 31 bands from 400 nm to 700 nm at 10 nm intervals); L is a 31 × 31 diagonal matrix that represents the spectral power distribution of the illuminant; r is a 1 × 31 discrete spectral vector of the object uniformly sampled over the visible wavelength range, typically from 400 nm to 700 nm at 10 nm intervals; ε is a 1 × 3 vector of the additive system errors; and c is a 1 × 3 vector that represents the camera sensor response.
The spectral reflectance can be estimated using prior knowledge of a training set of measured color patches and camera responses. When the error can be ignored, the above equation can be transformed as a scalar product in matrix notation as:
where R is an n × 31 matrix of the spectral dataset in which each row represents the spectral reflectance of n samples. C is an n × 3 matrix that represents the camera response, and each row consists of one or two sets (two three-channel images taken under two different lighting conditions) of camera responses for a sample. Q is a 3 × 31 matrix that represents the transform between the camera response and the spectral reflectance.
As described in the literature, most spectral estimation processes perform spectral estimation based on regression models, including linear, second-, third-, and fourth-order polynomial expansion models. In general, the accuracy of the spectral estimation depends not only on the training set but also on the number of signal features: the greater the number of features, the better the linearity of the imaging system. To improve the spectral estimation accuracy, a polynomial transform was used to extend the response values instead of increasing the number of imaging channels. Taking a third-order polynomial model as an example, the six-channel camera response (a row of C) can be expanded to 84 terms:
Using D to denote the matrix expanded from C, models can be built to map the polynomial camera response features to the spectral reflectance as:
where Θ is the 84 × 31 transform matrix searched for by the least-squares method. This could address some of the problems by imposing a penalty on the size of the coefficients. The L2-norm of vector κ can be added to the loss expression to give the preferred solutions with smaller norms. The objective functions are as follows:
here, κ is a regularization parameter to be empirically selected. The purpose of this regularization setting is to stabilize the regression output, which prevents a large change in the result when small perturbations in the input camera response occur. The gradient of the objective functions in the least-square sense becomes:
Let the gradient manually be zero, that is,
where I is the identity matrix. Small, positive values of κ reduce the variance of the estimates. While biased, the reduced variance of ridge estimates often results in a smaller mean squared error when compared to the ordinary least-squares estimates, and is the smallest positive singular value. Referring to the singular value decomposition of the expanded camera signal response matrix, , , the above equation can be transformed:
2.2. Iteratively Reweighted Regularization Model
The conventional method is optimum when the noise is ignored; however, it provides a poor estimation and is unreliable when outliers are present in the training data. Residual analysis is required to address these problems and downweight the influence of outliers. Here, we proposed a method by assigning a weight to each training sample to downweight the influence of outliers iteratively. In the first iteration, each training sample is assigned an equal weight, and the model coefficients are estimated using the regularization model from Equation (8). At subsequent iterations, weights are recomputed so that the points farther from the model predictions in the previous iteration are given lower weight until the values of the coefficient estimates converge within a specified tolerance. The modified objective function minimized by the M-estimator is as follows:
where ω is a function of weighted residuals called fair estimators defined as follows. The M-estimator needs to be found; it is a way of mitigating the influence of outliers in an otherwise normally distributed data set.
The value u in the weight functions is
where resid is the vector of residuals from the previous iteration, the tune is the tuning constant with 1.4 as the default, and s is an estimate of the standard deviation of the error term given by
where h is the vector of the leverage values from a least-squares fit, which is calculated from a QR decomposition, and . Assuming the signal matrix is of full rank and the test sample errors are independent and identically distributed with variance, the gradient for the weighted residual in the least-square sense becomes
Let the gradient of the above equation be zero. The schemes for finding the solution are as follows:
Solving this estimation equation is equivalent to a weighted least-squares problem: the weight depends upon the residuals, and the residual depends upon the estimated coefficient, so an iterative solution is therefore required.
(a) The initial estimates of spectral reflectance R0 are calculated in Equation (8).
(b) At each iteration t, residuals resid(t−1) and associated weights wi(t−1) are calculated from the previous iteration.
(c) The new weighted least-squares estimates are solved with Equation (10)
(d) Steps (b) and (c) are repeated until the estimated coefficients converge.
2.3. Feature Selection
It should be noted that when the number of polynomial expansion signals is large, its components are correlated, and the columns of the signal matrix have an approximately linear dependence. The estimation is extremely sensitive to random noise in the camera response, producing a large variance, and the situation of multicollinearity is an issue. This will degrade the prediction performance and the stability of spectral estimation precision [29]. The objective of a feature selection search for a subset of extended polynomial camera responses is to optimally model the camera responses and the spectral reflectance. The subset is subject to constraints such as the required or excluded features and the size of the subset. The performance of the spectral estimation transform matrix can be improved using the neighborhood component analysis feature selection [38,39,40,41,42]. Consider a spectral estimation training set S containing n color patches:
where ci is the polynomial expansion of the camera signals from the ith patch, and ri is the corresponding spectral reflectance. A randomized regression model can be built as follows:
(a) A patch Ref(c) is randomly selected from S as the ‘reference point’ for camera response.
(b) The response value at c is set equal to the response value of reference point Ref(C).
The probability, P(Ref (x) = cj|S), that point cj is picked from S as the reference for c is
where dw is the distance function, and ν is the kernel function that assumes large values when dw is small. Now consider the leave-one-out application of this randomized regression model, that is, predicting the response for using the data in , and the training set S excluding the point . The probability that point cj is picked as the reference point for is given by:
Let be the response value the randomized regression model predicts and ri be the actual spectral response for ci. Let l be a loss function that measures the disagreement between ri and . Then, the average value of the loss function l(ri, ) is given by:
After adding the regularization term λ, the weight vector wf can be expressed as the following minimization regression error:
where wr is weight vector for rth feature item, n is the number of observations, and p is the number of predictor variables.
3. Experiment and Result
In this section, the proposed method is implemented and compared with the currently existing methods; meanwhile, the feature selection that will influence the estimation accuracy of the proposed method is also investigated and discussed.
3.1. Camera Setup
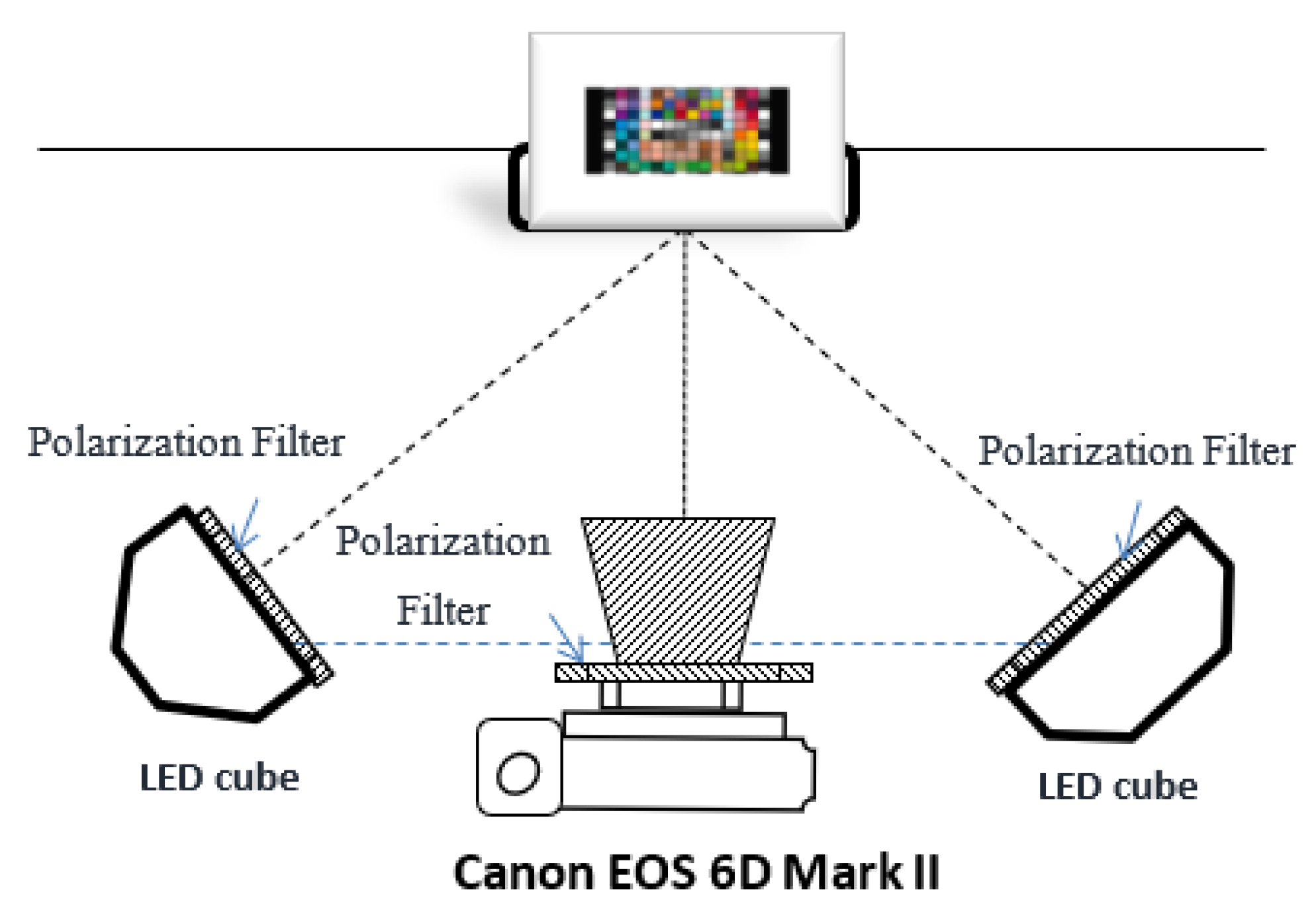
To verify the proposed approach, comparative experiments were conducted. The multispectral imaging system we developed includes a commercial trichromatic camera (Canon EOS 6D Mark II) with 16-bit digitization and two spectrally tunable THOUSLITE LED Cubes mounted with translucent diffuse reflectors. To illuminate glare and specular highlights, a linear polarizer was placed in the illumination plane of each LED Cube with the polarizing axes orientated in the same direction, and another linear polarizing filter was placed on the lens of the camera. As shown in Figure 1, the imaging plane of the digital camera was set to be approximately parallel to the sample placement plane, and the two LED Cubes were placed at an angle of approximately 45° to the color samples.
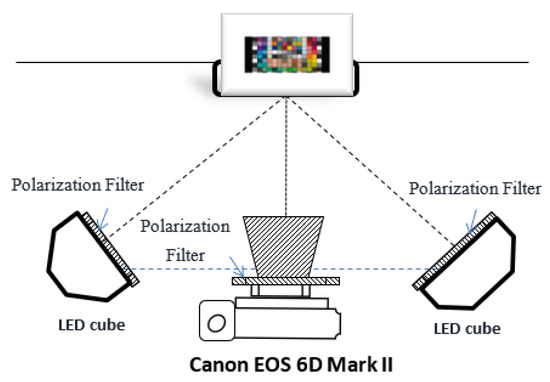
Figure 1.
The system setting of the image acquisition.
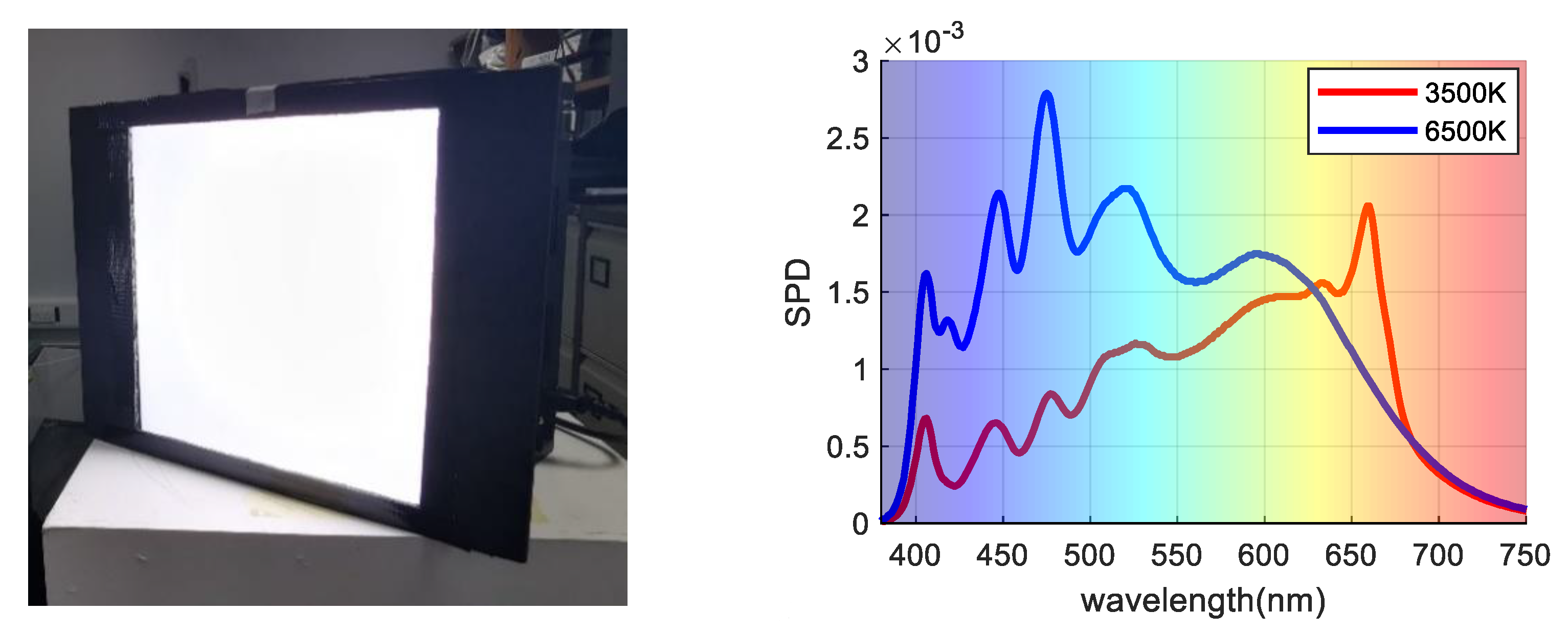
During image capture, each cube is used to simulate D65 (CCT approximately 6500 K) and incandescent light (CCT approximately 3500 K), These two illuminations are most commonly used, and the shape of SPD curves are quite different and weak in correlation. The spatial nonuniformity of the light field was corrected using exposure to a white card. The relative spectral power distribution of the two light sources was measured using a diffused white sample and is illustrated in Figure 2. Note that the SPD curves are similar in some wavelength bands because these lights are fitted from 15 narrow channels over the visible wavelength range.
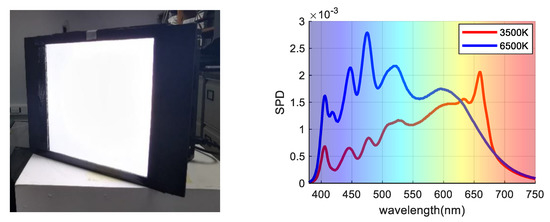
Figure 2.
(Left) LED Cube; (Right) Two SPD curves under 3500 K and 6500 K illumination conditions.
The parameter settings for the camera were fixed during the image capture, with the aperture size set to f5.6, the shutter speed at 1/8 s, and the ISO speed set to 640. Canon EOS Utility software was used to control the camera for the image capture. The original raw responses were recorded by the camera and used to predict spectral reflectance. The dark current noise was recorded with the camera lens cap closed and was subsequently subtracted from the captured digital images.
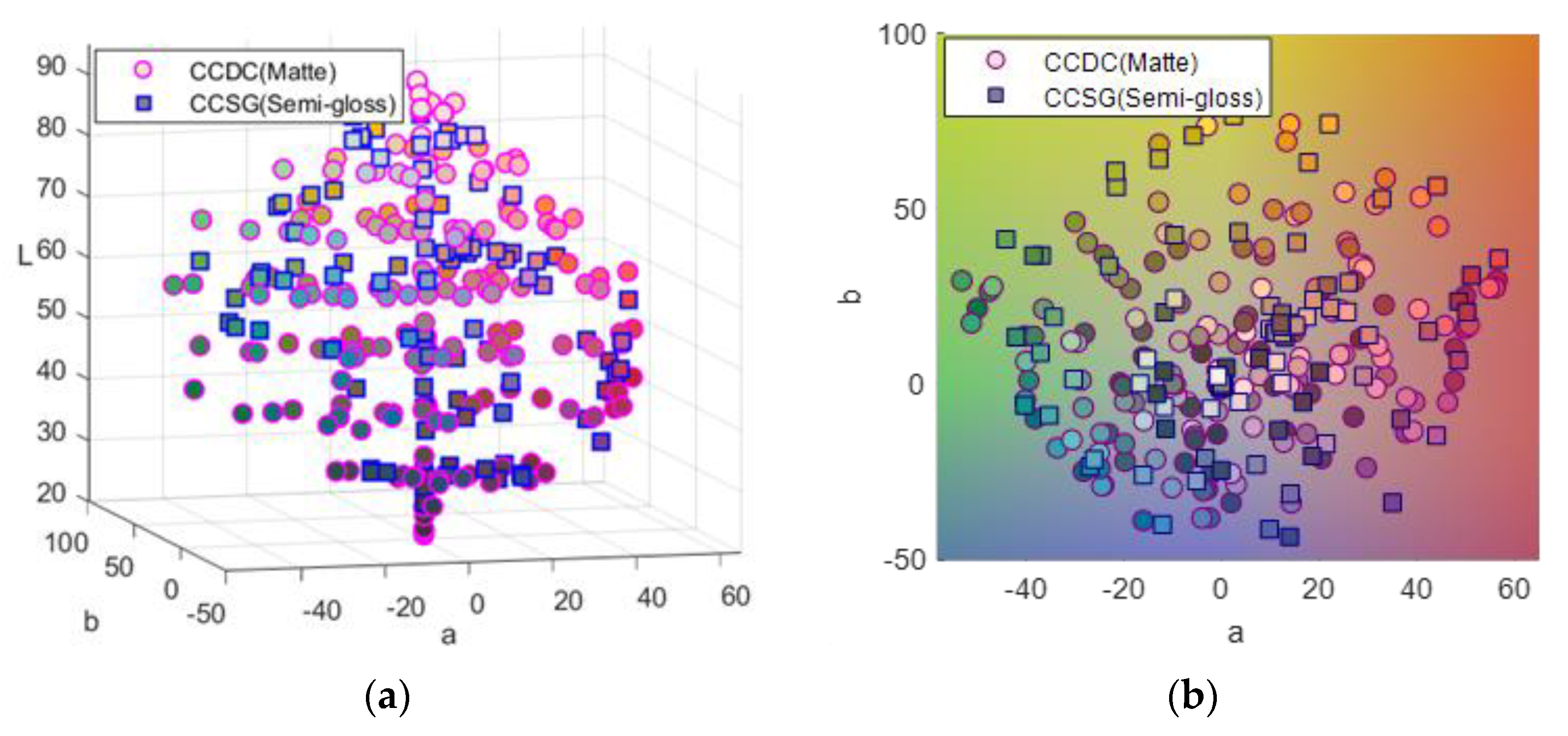
An X-Rite ColorChecker semigloss chart (CCSG, 140 patches) and a Gretag–Macbeth ColorChecker DC matte chart (CCDC, 240 patches including 232 mattes, and 8 glossy patches) were used as color targets and captured by the proposed multispectral imaging system. The spectral reflectance of all the patches was measured by a Konica Minolta CM2600D portable sphere Spectrophotometer from 400 nm to 700 nm (under SCI measurement based on diffuse: 8 geometry) at intervals of 10 nm over the wavelength range. Measuring Specular Component Included (SCI) would capture true color data from the sample and negate the effect of surface appearance to measure only color. It makes little or no difference if the patches are mirror-like or matte in appearance. Figure 3 shows the color distribution of both charts plotted in the CIELAB color space. The CIELAB values were calculated using the CIE 1931 standard observer and illuminant D65.
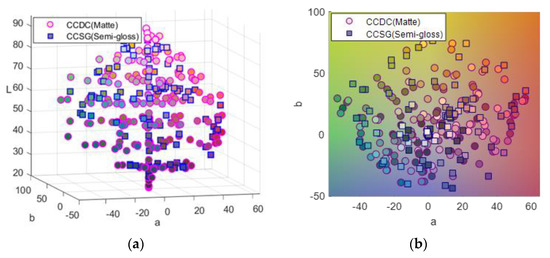
Figure 3.
The color distribution of matte charts (circle marker) and semigloss charts (square maker). (a) Comparison of color distribution in the CIELAB color space. (b) The chromaticity coordinates of samples in a* − b* plane.
The raw camera RGB of each patch in the color chart was obtained, and 50 × 50 pixels from the raw Bayer-patterned response of the central color patches of the image without postprocessing were extracted and demosaiced by the DcRaw program. Then, the transform matrix between the camera response and spectral reflectance was calculated from the training set and evaluated on the test set. To test the model more robustly and fairly, a ten-fold cross-validation approach was used ten times to evaluate the proposed method. All the patches were divided into ten groups randomly, and for each group, 9/10 of the patches were assigned as the training set, and 1/10 of the patches were assigned as the test set. Both spectral differences and color differences between the model-predicted results from the camera and the measurement results from the spectrophotometer were calculated to represent the performance of the predictive accuracy for the spectral reflectance estimation. That is, root-means-square error (RMS) was used as spectral metrics [15], with CIEDE2000 (color difference) under the D65 CIE standard illuminant as the colorimetric metric. The RMS and CIEDE2000 are positive values, with 0 corresponding to a perfect estimation. These metrics are given by the following equations:
where denotes the reconstructed spectral reflectance of ith patches, denotes the measured reference of ith patches, and n denotes the number of full samples. n denotes the wavelength sampling number of the spectral reflectance over the visible spectrum.
3.2. The Influence of Feature Selection
Another common problem that was raised in the introduction section concerns the feature number of the expanded polynomial. For all the existing methods, the performance is calculated by the first-order, second-order, and third-order, rather than by the most important selected features. As noted in Section 2.3, the feature number of the camera response is crucial for spectral estimation.
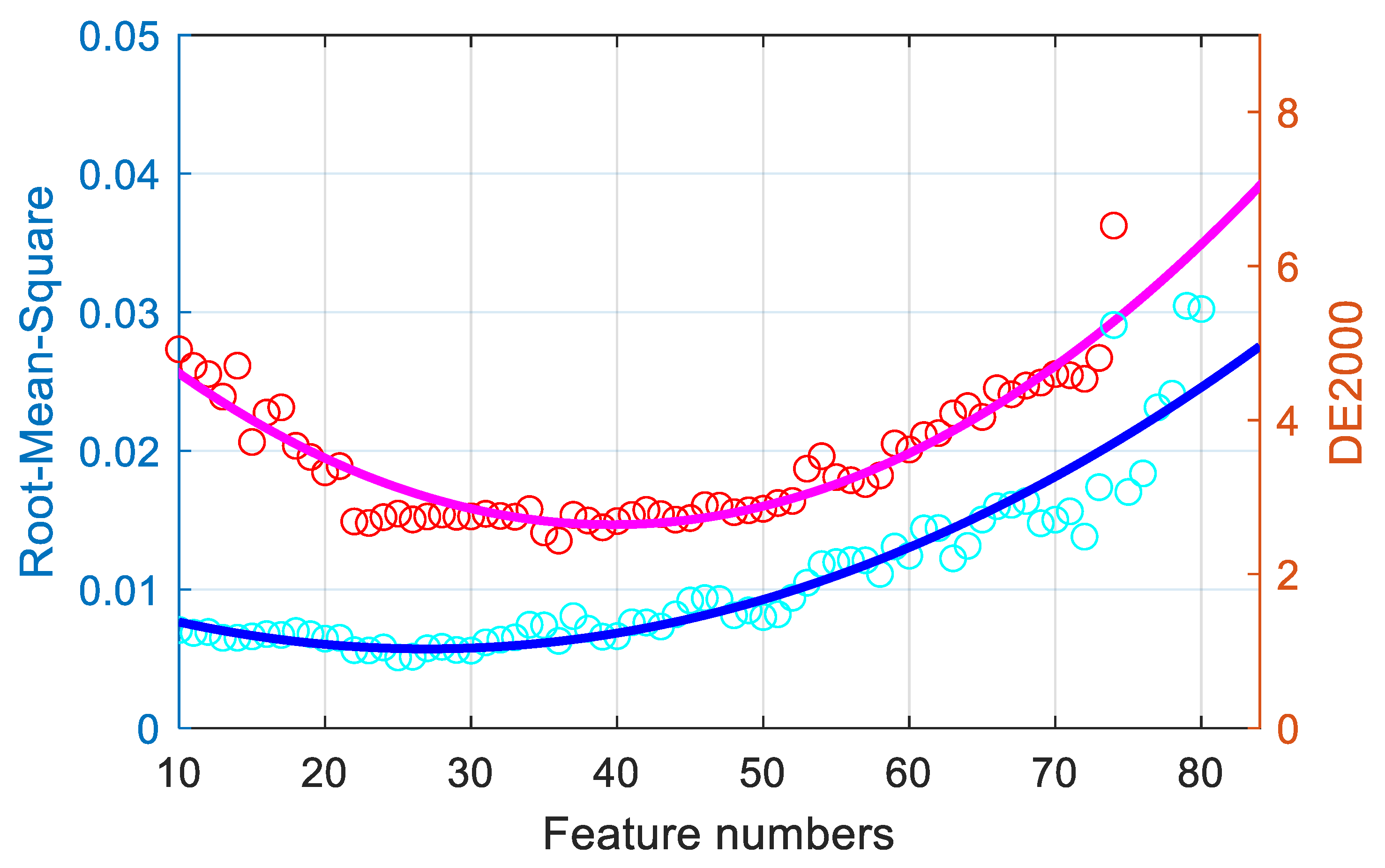
Neighborhood component analysis feature selection is performed to optimize the feature selection for the proposed imaging system. Here, the MATLAB function fsrnca, in the Machine Learning Toolbox, was used. However, as explained by Urban et al., too many items can cause overfitting problems [22]. By selecting weighted features, the colorimetric and spectral metric precision will be determined as the feature number is changed. In this study, using 380 color samples from the SG140 chart and DC240 chart, a regularization model with third-order polynomial expansion was used to calculate the different selected features in terms of both the spectral reflectance RMS and the mean CIEDE2000 color difference. Figure 4 reveals the relationship between the mean spectral reflectance RMS, the mean CIEDE2000 color difference, and the feature numbers within the expanded polynomial feature range. The performance of colorimetric and spectral metrics initially decreased with an increase in the feature number, and then their performance increased after an optimal value of approximately 30 features was reached. Thus, it should be more meaningful to understand the importance of the features and train a model using the only the selected features.
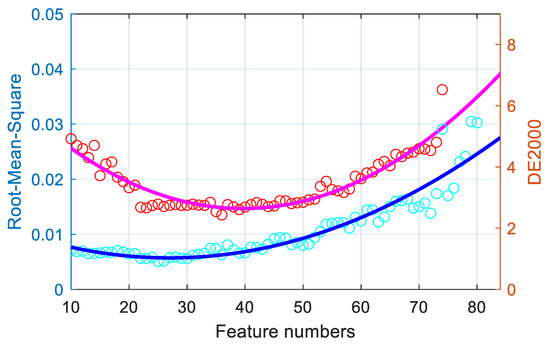
Figure 4.
Relationship of the feature numbers with the spectral and color performance.
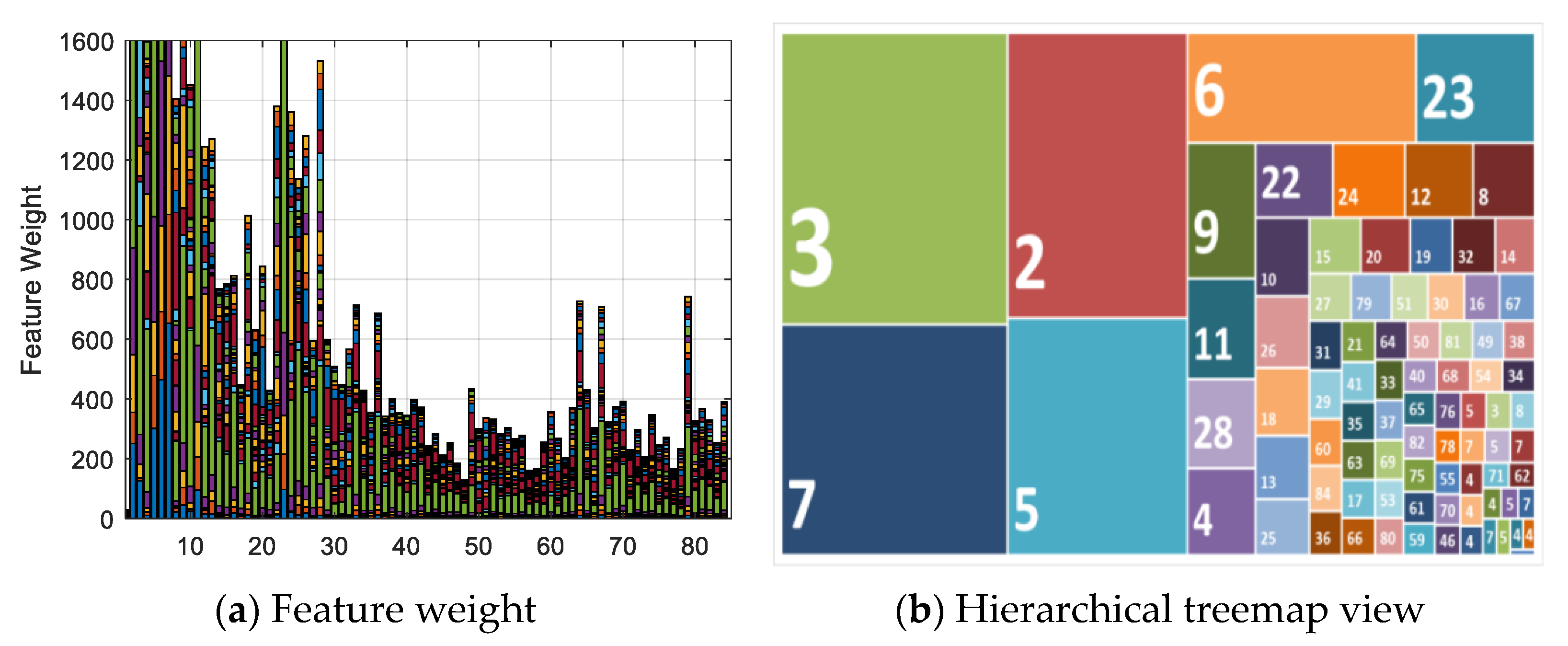
Figure 5a illustrates the feature selection weights of 84 extended third-order polynomial feature items from six-channel camera responses using neighborhood component analysis (NCA). Over half of the feature weights are less than 400. Calculating the loss using the test set as a measure of the performance, the weights of the irrelevant features should be close to zero, and the performance of feature selection using five-fold cross-validation should improve. Figure 5b shows a hierarchical treemap view of the feature weights and shows the obvious patterns, including which items are most important for spectral estimation. The relationship between each feature is shown by color and proximity. The 30 most relevant features were identified and are summarized in Table 1. There are 6 first-order terms, 17 s-order terms, and 7 third-order terms that are most important for spectral estimation. This means that not all terms are necessary for spectral estimation; part of the second-order and third polynomial expansion are negative, irrelevant, and decrease the estimation performance. In addition, it should be noted that the selection of features might depend on the camera, illumination, and training dataset.
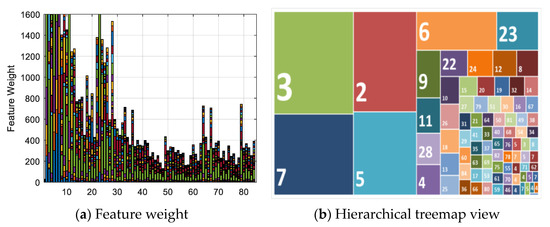
Figure 5.
Feature selection among 84 items. (a) Feature weight of 84 extended feature items. (b) Hierarchical treemap view of feature weights.

Table 1.
Selected terms of the polynomial regression.
Based on the proposed multispectral camera system, the performance of the spectral reflectance estimation with different expansions (including the linear expansion, the second-order polynomial expansion, the third-order polynomial expansion, and finally, the third-order polynomial expansion with the proposed 30 features) was evaluated in terms of both the colorimetric error and spectral difference. All results are given in Table 2: compare the evaluation results of different polynomial expansion methods, it can be seen that the best performance, i.e., the smallest average color difference between the predicted and measured spectra, is achieved by selecting 30 feature items from the third-order polynomial expansion; it has the smallest value in root-means-square error (RMS), CIEDE2000 color difference under D65 illumination, lowest standard deviation (SD), and largest value in Student’s t variance (t-stat). Student’s t variance is used in the testing the variance for Student’s t distribution. The higher the t-stat value, the greater the confidence we have in the coefficient as a predictor. It is not safe to conclude that more feature numbers are needed to obtain more accurate results. Excessive training numbers would cause overfitting and thus reduce accuracy.
Table 2.
Performance of reflectance estimation using two illuminants with different polynomial expansions.
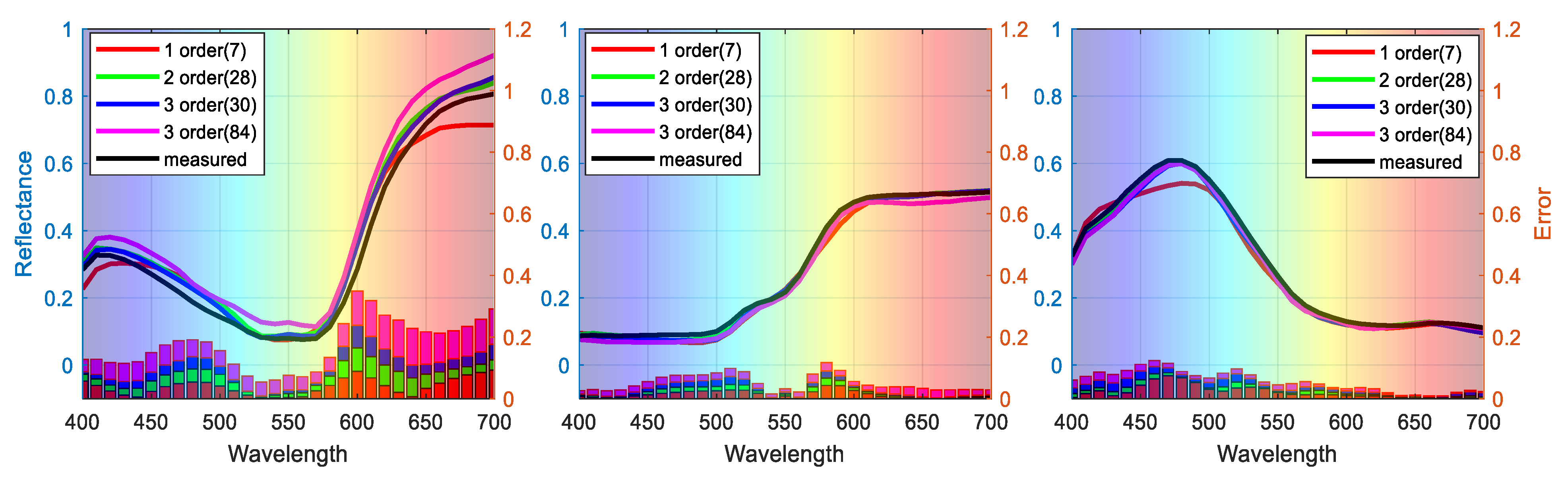
To visualize the performance of different signal expansion methods, the estimated spectra of three randomly selected samples (No. 54, No. 180, and No. 288) are plotted in Figure 6, where the left axis shows the estimated spectra of samples with different polynomial expansions and the right axis shows the ΔR error between estimated and measured spectra. Our feature selection method outperforms the traditional expansion methods in terms of both spectral and colorimetric accuracy.
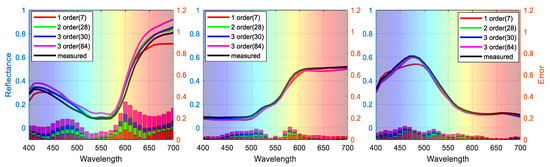
Figure 6.
Representative samples of reconstructed spectra with different polynomial expansions.
3.3. The Influence of the Regression Model on the Proposed Method
The proposed method was implemented and compared with currently existing methods. These included the regularized least-squares (RLS) [34], Tik regularized least-squares [36], Wiener method [5], ordinary least-squares method (OLS) [10], principal component analysis (PCA) [7], and partial least-squares method (PLS) [33]. All the existing methods were implemented in their optimal conditions, while six principal components were used conventionally for the PCA- and PLS-based methods, as the first six (instead of the total 84) components explain over 95% of the total variance.
Table 3 and Table 4 compare the evaluation results of the spectral metric in RMS and CIEDE2000 color difference between 84 items (third-order polynomial expansion) and 30 items (feature-selected). They show that our proposed method, the iteratively reweighted regularization model (IRWR), improves the precision of spectral reconstruction in color and spectral using feature selection, while the traditional methods exhibit a large discrepancy without considering the overfitting effect caused by an excessive number of features. Especially for the feature-selected model (30 items), IRWR has the smallest value in RMSE (mean value of 2.14%, maximum value of 9.35%, standard deviation (SD) of 1.77%) and smallest CIEDE2000 color difference (mean value is 1.79, the maximum value is 7.31, standard deviation (SD) is 1.39) compared to other methods. Furthermore, the predictive error of the feature-selected method is reduced by approximately 0.19 for the CIEDE2000 color difference compared to the unselected 84 items. Compared with the fully expanded items, our feature-selected model has the lowest standard deviation (SD), which indicates that the spectral estimation errors tend to be close to the mean value and the model has strong performance.
Table 3.
The comparison of estimation accuracy in terms of RMS using ten-fold cross-validation.
Table 4.
Comparison of estimation accuracy in terms of CIEDE2000 using ten-fold cross-validation.
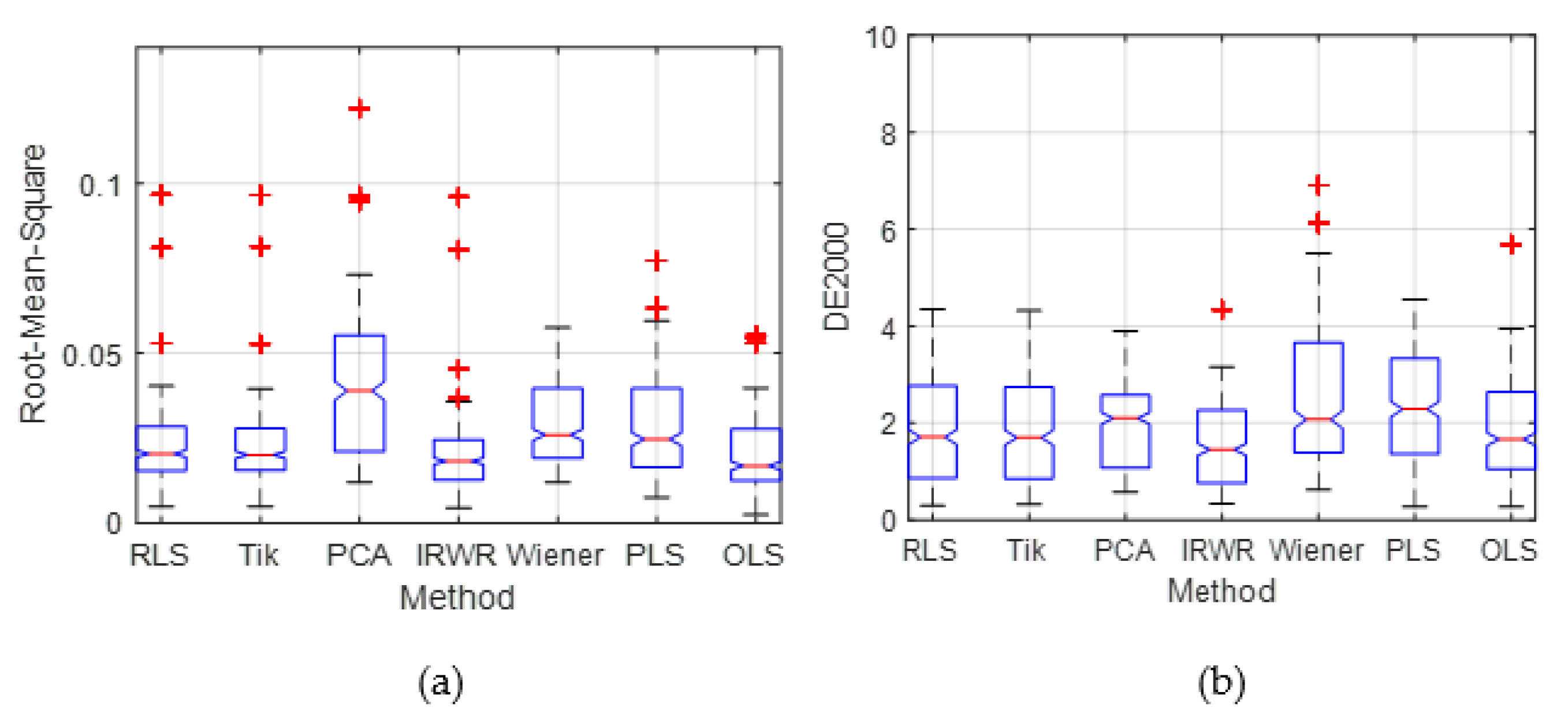
To illustrate both the overall predictive accuracy and the error distribution of all methods, Figure 7 is plotted using boxplots to represent the distribution of the color difference and spectral RMS error compared with other estimation methods. The boxplot distribution of the estimation result of the proposed method is more compact than that of the existing methods, of which most of the CIEDE2000 and spectral RMS are less than those of the other traditional methods. The top of the blue rectangle indicates the upper quartile, a horizontal red line near the middle of the rectangle indicates the median, and the bottom of the blue rectangle indicates the lower quartile. The topmost outlier is represented by a vertical line that extends from the top of the rectangle to indicate the maximum value, and the bottom end outlier is represented by the vertical line that extends from the bottom of the rectangle to indicate the minimum value. The outliers (red cross) that are above or below the box body indicate that their values are greater than the upper quartile plus 1.5 times the interquartile range or less than the lower quartile minus 1.5 times the interquartile range. In addition, the boxplot of the overall error distribution for the ten-fold validation in Figure 7 shows that there are more small error samples estimated by the proposed method, which is more intuitive to prove the superiority of the proposed method.
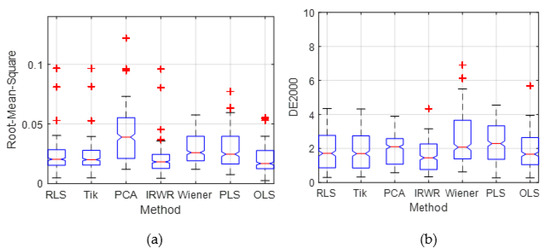
Figure 7.
The relevant summary statistics of the proposed method and the existing methods, the outliers are plotted individually using the ‘+’ symbol. (a) Boxplot distributions of the RMS. (b) Boxplot distributions of the CIEDE2000 color difference.
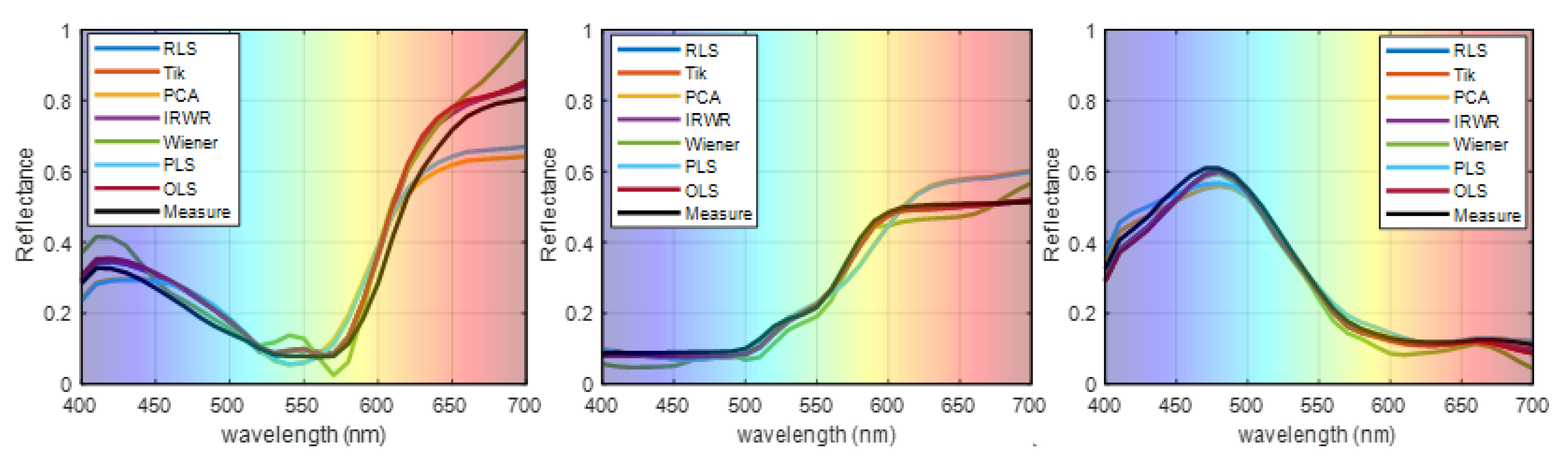
The reconstruction of the spectral reflectance of three randomly selected samples (No. 54, No. 180, and No. 288) compared with those of the existing methods is shown in Figure 8, where the black line is the measured spectral reflectance. The reflectance reconstructed by the proposed method is found to be more accurate than those of the traditional methods. The experimental results using the simulated camera may, to some extent, prove the superiority of the proposed method.
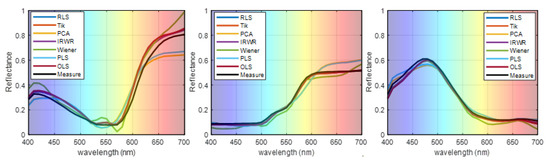
Figure 8.
Representative samples of reconstructed spectra of the proposed method and the traditional methods.
3.4. Methods Implementation and Comparison for Illuminant Metamerism
To evaluate whether the RGB camera under two illuminations can give a better spectral estimation than that of the camera under one illumination, our proposed model with the third polynomial regression was also investigated under each illumination (3500 K or 6500 K) separately. The performance of the spectral estimation under 3500 K, under 6500 K, nonfeature selection (84 items), and feature selection (30 items) is listed in Table 5 in terms of the mean error, maximum and minimum error, standard deviation (SD), and Student’s t mean and variance (t-stat) of the color differences under these five test conditions. All the color difference data were calculated according to CIE Special Metamerism Index: Change in Illuminant (CIE 015.2-1986), and the data listed in the table were CIE ΔE*76 color difference between estimated and measured spectra.
Table 5.
Metamerism performance of four methods under different illuminations.
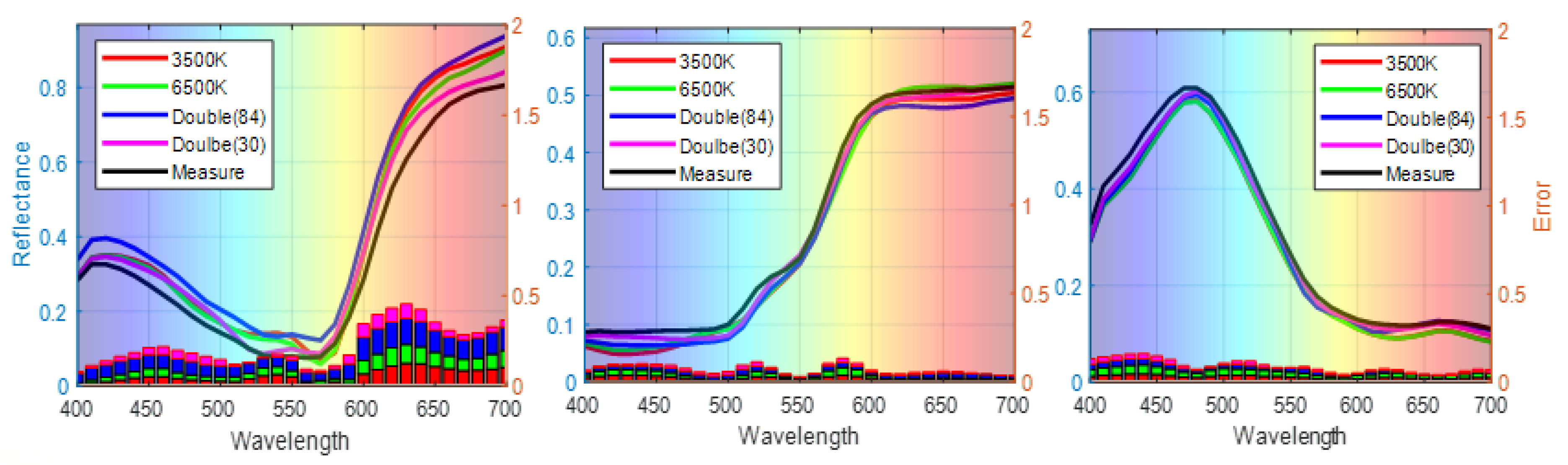
The results indicate that the three-channel signals of 3500 K and 6500 K with traditional quadratic expansions have high chromatic accuracy at the approximate color temperatures. The performance of the six channels under two illumination conditions is improved. It can be seen that the best performance, i.e., the smallest average color difference of color difference between the predicted and measured spectra, is achieved by our proposed method, which uses 30 items from the third-order polynomial expansion variables and six channels under both 3500 K and 6500 K illumination. The average color differences range from 2.14 (Illuminant D65) to 2.40 ΔE*ab units (Illuminant D50), with an overall mean of 2.23 ΔE*ab units, a maximum value of 5.41, and a standard deviation (SD) of 1.19. Additionally, the reconstructed spectral reflectance of the three randomly selected samples No. 54, No. 180, and No. 288) with single illumination (3500 K, 6500 K), double illumination, and feature-selected double illumination is shown in Figure 9. Our method achieves improved estimation accuracy by selecting features from polynomial expansions of camera response under two illumination conditions.
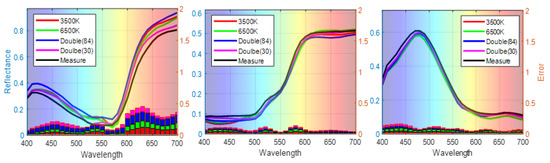
Figure 9.
Representative samples of the reconstructed spectra in various conditions.
3.5. Discussion
In this study, we developed a cross-polarized multispectral camera system by applying two commonly used illuminants and propose a new method to improve the accuracy of the estimation of the spectral data from the raw camera responses. The results illustrate that the performance of reflectance estimation from the camera images can be significantly improved when two broadband illuminations are used. This implies that multi-illumination with consumer-grade cameras can be an effective approach to construct a multispectral camera system. The factors that have contributed to the improvement in estimation accuracy are as follows.
(1) We found that the feature selection of the expanded camera response influences the estimation performance. We have shown that a small number of features can provide better performance than the full selection of features of the camera response expansion. The selection of features might depend on the camera, illumination, and training dataset. Further investigation of factors affecting the feature selection was conducted and reported in this paper.
(2) As outliers present in the training data could lead to poor estimates, the iteratively reweighted regulated model was proposed. An analysis of residuals was necessary to work around this by assigning weights to the training data. The weighting is done automatically and iteratively; weights are recomputed iteratively so that the points farther from the model predictions in the previous iteration are given a lower weight. Then, the influence of outliers is downweighted. The result supported our previous research.
(3) The most significant performance improvement was achieved by mapping the six-channel signals under two illumination conditions into the spectral reflectance, which minimized the degree of metamerism significantly compared to the three-channel mapping. As shown in Table 5, for each of the illumination conditions tested, the best performance, i.e., the smallest mean color difference between the predicted and the measured spectral data, was achieved by using six channels under two illumination conditions, where the mean color differences ranged from 2.14 (Illuminant D65) to 2.4 ΔE*ab units (Illuminant D50), with an overall average of 2.23 units.
4. Conclusions
This paper proposes a method for spectral estimation to calculate the spectral data from raw camera responses by feature-selected expansion items under two illumination conditions using an iteratively reweighted regulated model. The performance of the proposed method is evaluated using ColorChecker charts. The results show that our proposed method achieves good accuracy in terms of both spectral and colorimetric estimation. The factors that contributed to the proposed method are discussed in detail; downweighting the influence of the outliers in the training set and selecting some of the most important features obviously improves the performance of spectral estimation. However, there are still problems to be solved in the future. For example, our method can be slightly worse than some local weighted regression methods, although it is less computationally expensive than the traditional methods. The tradeoff between accuracy and computational complexity is the most common shortcoming for nearly all adaptive methods. The proposed method has potential applications for spectral reflectance measurement in many fields including textiles, printing, and cultural heritage.
Author Contributions
Conceptualization, K.X. and Z.L.; methodology, C.L. and M.R.P.; validation, Q.L., R.H.; data curation, R.H.; writing—original draft preparation, Z.L.; writing—review and editing, M.R.P.; visualization, X.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number 61405104; Shandong Provincial Natural Science Foundation, grant number ZR2020MF125, and European Union’s Horizon 2020 Research and Innovation Programme, grant number 814158.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data available in a publicly accessible repository. The data presented in this study are openly available in [https://zenodo.org/record/5730472#.YaE3PhrP23A] (accessed on 24 November 2021) at [DOI 10.5281/zenodo.5730471].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pan, Z.; Healey, G.; Prasad, M.; Tromberg, B.J. Face recognition in hyperspectral images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1552–1560. [Google Scholar]
- Uzair, M.; Mahmood, A.; Shafait, F.; Nansen, C.; Mian, A. Is spectral reflectance of the face a reliable biometric? Opt. Express 2015, 23, 15160–15173. [Google Scholar] [CrossRef] [Green Version]
- Berns, R.S. Digital color reconstructions of cultural heritage using color-managed imaging and small-aperture spectrophotometry. Color Res. Appl. 2019, 44, 531–546. [Google Scholar] [CrossRef]
- Kikuchi, K.; Masuda, Y.; Hirao, T. Imaging of hemoglobin oxygen saturation ratio in the face by spectral camera and its application to evaluate dark circles. Ski. Res. Technol. 2013, 19, 499–507. [Google Scholar] [CrossRef]
- Nishidate, I.; Maeda, T.; Niizeki, K.; Aizu, Y. Estimation of Melanin and Hemoglobin Using Spectral Reflectance Images Reconstructed from a Digital RGB Image by the Wiener Estimation Method. Sensors 2013, 13, 7902–7915. [Google Scholar] [CrossRef] [Green Version]
- Sun, G.; Wang, X.; Sun, Y. Measurement Method Based on Multispectral Three-Dimensional Imaging for the Chlorophyll Contents of Greenhouse Tomato Plants. Sensors 2019, 19, 3345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hardeberg, J.Y. Acquisition and Reproduction of Color Images: Colorimetric and Multispectral Approach. Ph.D. Thesis, Ecole Nationale Superieure des Telecommunications, Paris, France, 1999. [Google Scholar]
- Wang, X.; Liao, N.; Li, Y. The Research on Reconstruction of Spectral Reflectance in LCTF Imaging System Based on Comparative Measurement. Spectrosc. Spect. Anal. 2018, 38, 290–295. [Google Scholar]
- Shrestha, R.; Hardeberg, J. Evaluation and comparison of multispectral imaging systems. In Proceedings of the IS&T Color and Imaging Conference, Boston, MA, USA, 3–7 November 2014; pp. 107–115. [Google Scholar]
- Hardeberg, J.Y.; Schmitt, F.; Brettel, H. Multispectral color image capture using a liquid crystal tunable filter. Opt. Eng. 2002, 41, 2532–2548. [Google Scholar]
- Mathews, S.A. Design and fabrication of a low-cost, multispectral imaging system. Appl. Opt. 2008, 47, 71–76. [Google Scholar] [CrossRef] [Green Version]
- Tanksale, T.M.; Urban, P. Trichromatic Reflectance Capture Using a Tunable Light Source: Setup, Characterization and Reflectance Estimation. Electron. Imaging 2016, 27, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Gu, J. Recovering spectral reflectance under commonly available lighting conditions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Shen, H.L.; Cai, P.Q.; Shao, S.J.; Xin, J.H. Reflectance reconstruction for multispectral imaging by adaptive Wiener estimation. Opt. Express 2007, 15, 15545–15554. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Sato, I.; Okabe, T.; Sato, Y. Fast spectral reflectance recovery using DLP projector. Int. J. Comput. Vis. 2014, 110, 172–184. [Google Scholar] [CrossRef]
- Jiang, J. Evaluation and Improvement of Workflow of Digital Imaging of Fine Art Reproduction in Museums. Ph.D. Thesis, Rochester Institute of Technology, Rochester, NY, USA, 2013. [Google Scholar]
- Tominaga, S.; Horiuchi, T. Spectral imaging by synchronizing capture and illumination. J. Opt. Soc. Am. A 2012, 29, 1764–1775. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, Q.; Gao, G.; Li, C. Optimized spectral reconstruction based on adaptive training set selection. Opt. Express 2017, 25, 12435–12445. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Wang, Q.; Li, J.; Zhou, X.; Yang, I. Estimating spectral reflectance from camera responses based on CIE XYZ tristimulus values under multi-illuminants. Color Res. Appl. 2017, 42, 68–77. [Google Scholar] [CrossRef]
- Zhao, Y.; Berns, R.S. Image-based spectral reflectance reconstruction using the matrix R method. Color Res. Appl. 2017, 32, 343–351. [Google Scholar] [CrossRef]
- Imai, F.H.; Berns, R.S. High-Resolution Multi-Spectral Image Archives: A Hybrid Approach. In Proceedings of the Sixth Color Imaging Conference: Color Science, Systems, and Applications, Scottsdale, AZ, USA, 9–12 November 1998. [Google Scholar]
- Urban, P.; Rosen, M.R.; Berns, R.S. Spectral image reconstruction using an edge preserving spatio-spectral Wiener estimation. J. Opt. Soc. Am. A 2009, 26, 1865–1875. [Google Scholar] [CrossRef]
- Liu, Z.; Wan, X.X.; Huang, X.G.; Liu, Q. The study on spectral reflectance reconstruction based on wideband multi-spectral acquisition system. Spectrosc. Spectr. Anal. 2013, 33, 1076–1081. [Google Scholar]
- Yoo, J.H.; Kim, D.C.; Ha, H.G.; Ha, Y.H. Adaptive Spectral Reflectance Reconstruction Method based on Wiener Estimation Using a Similar Training Set. J. Imaging Sci. Technol. 2016, 60, 205031–205038. [Google Scholar] [CrossRef]
- Yamaguchi, M.; Ohyama, N.; Murakami, Y. Piecewise Wiener estimation for reconstruction of spectral reflectance image by multipoint spectral measurements. Appl. Opt. 2009, 48, 2188–2202. [Google Scholar]
- Wang, K.; Wang, H.; Wang, Z.; Yin, Y.; Zhang, Y. Medical imaging based spectral reflectance reconstruction combining PCA and regularized polynomial. Biomed. Res. 2018, 29, S380–S383. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Xu, H. Reconstructing spectral reflectance by dividing spectral space and extending the principal components in principal component analysis. J. Opt. Soc. Am. A 2008, 25, 371–378. [Google Scholar] [CrossRef]
- Harifi, T.; Amirshahi, S.H.; Agahian, F. Recovery of Reflectance Spectra from Colorimetric Data Using Principal Component Analysis Embedded Regression Technique. Opt. Rev. 2008, 15, 302–308. [Google Scholar] [CrossRef]
- Xiao, K.; Zhu, Y.; Li, C.; Connah, D.; Yates, J.M.; Wuerger, S. Improved method for skin reflectance reconstruction from camera images. Opt. Express 2016, 24, 14934–14950. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, R.; Mansouri, A.; Hardeberg, J.Y. Multispectral imaging using a stereo camera: Concept, design and assessment. EURASIP J. Adv. Signal Process. 2011, 26, 57–72. [Google Scholar] [CrossRef]
- Li, H.; Wu, Z.; Zhang, L.; Parkkinen, J. SR-LLA: A novel spectral reconstruction method based on locally linear approximation. In Proceedings of the IEEE International Conference on Image Processing, Victoria, Australia, 27–30 October 2014; pp. 2029–2033. [Google Scholar]
- Cao, B.; Liao, N.; Cheng, H. Spectral reflectance reconstruction from RGB images based on weighting smaller color difference group. Color Res. Appl. 2017, 42, 327–332. [Google Scholar] [CrossRef]
- Shen, H.L.; Wan, H.J.; Zhang, Z.C. Estimating reflectance from multispectral camera responses based on partial least-squares regression. J. Electron. Imaging 2010, 19, 020501. [Google Scholar] [CrossRef]
- Heikkinen, V.; Jetsu, T.; Parkkinen, J.; Hauta-Kasari, M.; Jaaskelainen, T. Regularized learning framework in the estimation of reflectance spectra from camera responses. J. Opt. Soc. Am. A 2007, 24, 2673–2683. [Google Scholar] [CrossRef]
- Amiri, M.M.; Fairchild, M.D. A strategy toward spectral and colorimetric color reproduction using ordinary digital cameras. Color Res. Appl. 2018, 43, 675–684. [Google Scholar] [CrossRef]
- Zhang, Z.C. Reconstruction of Spectral Reflectance in Imaging Systems. Master’s Thesis, Zhejiang University, Hangzhou, China, 2010. [Google Scholar]
- Liu, Z.; Xiao, K.; Pointer, M.; Li, C. Developing a multi-spectral system using a RGB camera under two illumination. In Proceeding of the IS&T Color and Imaging Conference, Chiba, Japan, 27–29 March 2020; pp. 277–281. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Menke, W. Geophysical Data Analysis: Discrete Inverse Theory (MATLAB Edition), 3rd ed.; Academic Press: London, UK, 2012. [Google Scholar]
- Luxburg, U.V. A tutorial on spectral clustering. Stat. Comput. 2004, 17, 395–416. [Google Scholar] [CrossRef]
- Yang, W.; Wang, K.; Zuo, W. Neighborhood component feature selection for high-dimensional data. J. Comput. 2012, 7, 161–168. [Google Scholar] [CrossRef]
- Khan, H.A.; Thomas, J.B.; Hardeberg, J.Y.; Laligant, O. Illuminant estimation in multispectral imaging. J. Opt. Soc. Am. A 2017, 34, 1085–1098. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).