
Human Action Recognition: A Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion

 , ,
, ,  and
and
Abstract
:1. Introduction
- Selected two pre-trained deep learning models and removed the last three layers. The new layers are added and trained on the target datasets (action recognition dataset). In the training process, the first 80% of the layers are frozen instead of using all the layers, whereas the training process was conducted using transfer learning.
- Proposed a Serial based Extended (SbE) approach for multiple deep learning features fusion. This approach fused features in two phases for better performance and to reduce redundancy.
- Proposed a feature selection technique named Kurtosis-controlled Weighted KNN (KcWKNN). A threshold function is defined which is further analyzed using a fitness function.
- Performed an ablation study to investigate the performance of each step in terms of advantages and disadvantages.
2. Related Work
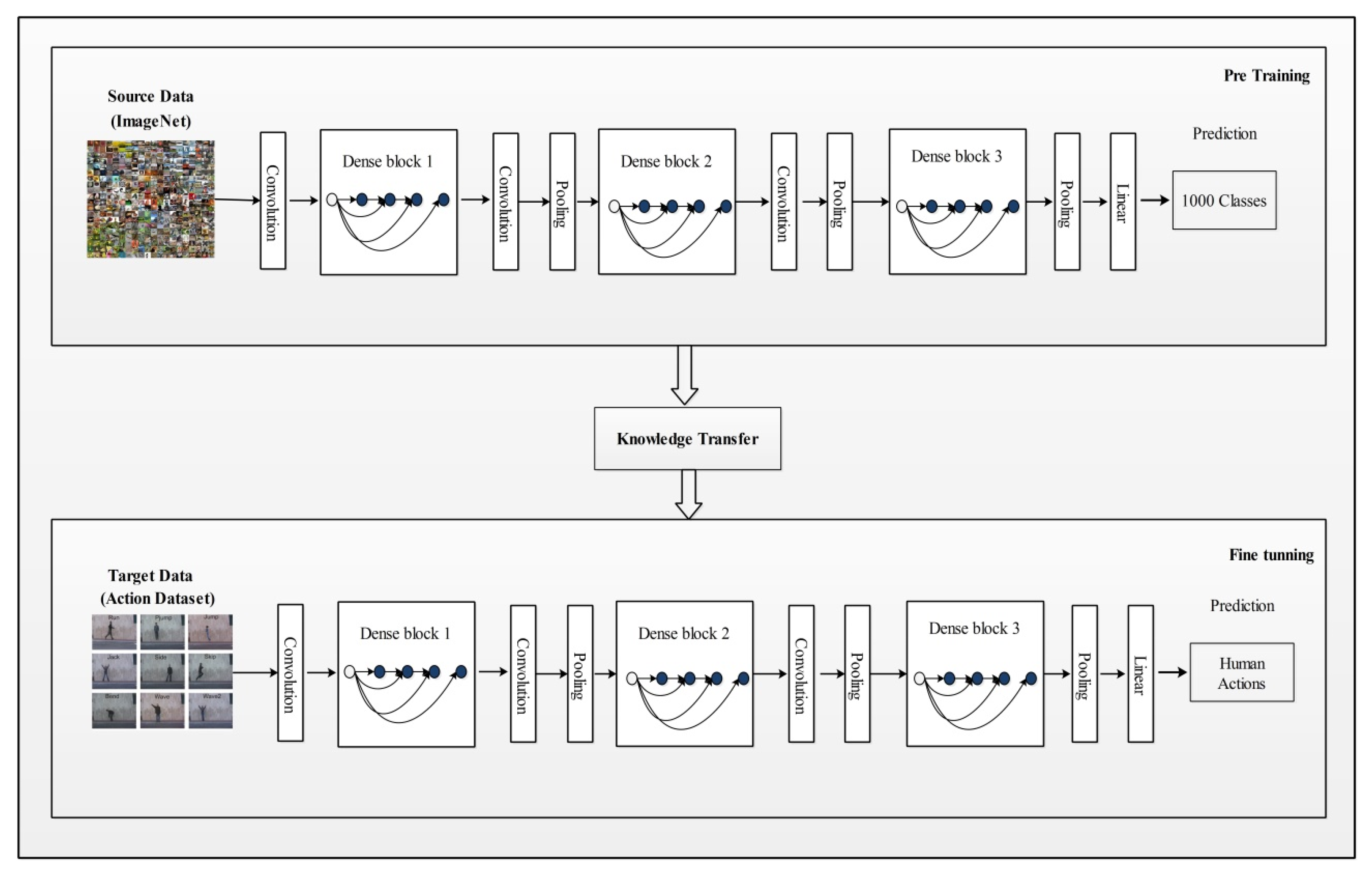
3. Proposed Methodology
3.1. Convolutional Neural Network (CNN)
3.2. Densenet201 Pre-Trained Deep Model
3.3. Inception V3 Pre-Trained Deep Model
3.4. Transfer Learning Based Learning
3.5. Features Extraction
3.6. Serial Based Extended Fusion
3.7. Serial Based Extended Fusion
- (a)
- Compute the Euclidian distance between and each , formal given in Equation (8).
- (b)
- Arrange all values in ascending order
- (c)
- Assign a weight to the th nearest neighbor using Equation (9).
- (d)
- Assign for the equally weighted KNN rule,
- (e)
- The class label of is assigned on the basis of majority votes from the neighbors by Equation (10).where is the class label, is the class label for th nearest neighbor and is the Dirac-Delta function that takes value = 1 if its argument is true and 0 otherwise.
- (f)
- Compute error.
| Algorithm 1. The complete work of the proposed design. |
| Input: Action Recognition Datasets |
| Output: Predicted Action Class |
| Step 1: Input action datasets |
Step 2: Load Pre-trained Deep Models;
|
| Step 3: Fine Deep Models |
| Step 4: Trained Deep Models using TL |
| Step 5: Feature Extraction from Avg Pooling Layers |
| Step 6: SbE approach for Features Fusion |
| Step 7: Best Features Selection using Proposed KcWKNN |
| Step 8: Predict Action Label |
4. Results and Analysis
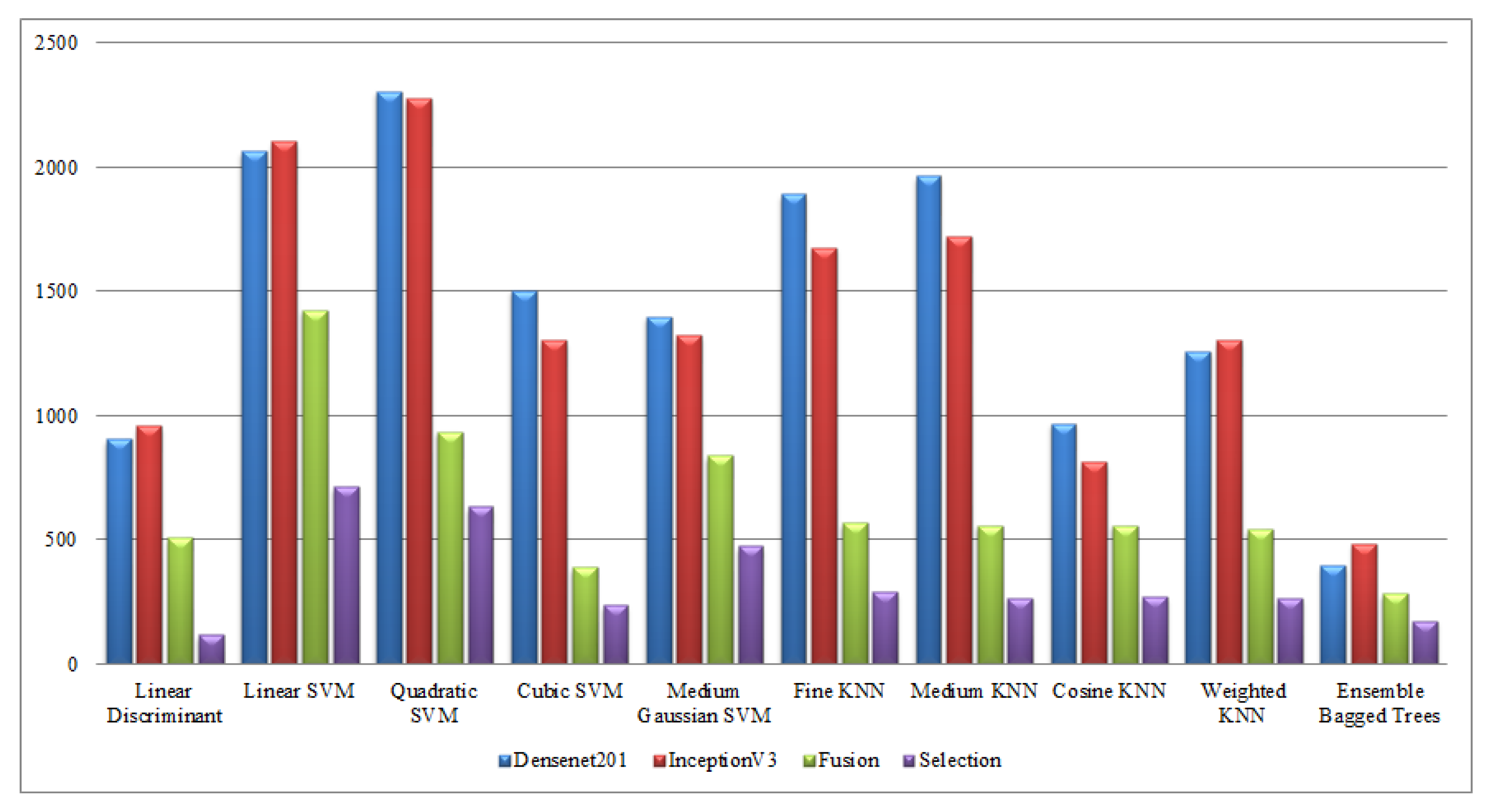
4.1. Results
4.2. Comparison with SOTA
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, D.; Lee, I.; Kim, D.; Lee, S. Action Recognition Using Close-Up of Maximum Activation and ETRI-Activity3D LivingLab Dataset. Sensors 2021, 21, 6774. [Google Scholar] [CrossRef]
- Mishra, O.; Kavimandan, P.S.; Tripathi, M.; Kapoor, R.; Yadav, K. Human Action Recognition Using a New Hybrid Descriptor. In Advances in VLSI, Communication and Signal Processing; Springer: Singapore, 2021. [Google Scholar]
- Chen, X.; Xu, L.; Cao, M.; Zhang, T.; Shang, Z.; Zhang, L. Design and Implementation of Human-Computer Interaction Systems Based on Transfer Support Vector Machine and EEG Signal for Depression Patients’ Emotion Recognition. J. Med. Imaging Health Inform. 2021, 11, 948–954. [Google Scholar] [CrossRef]
- Javed, K.; Khan, S.A.; Saba, T.; Habib, U.; Khan, J.A.; Abbasi, A.A. Human action recognition using fusion of multiview and deep features: An application to video surveillance. Multimed. Tools. Appl. 2020, 1–27. [Google Scholar] [CrossRef]
- Liu, D.; Xu, H.; Wang, J.; Lu, Y.; Kong, J.; Qi, M. Adaptive Attention Memory Graph Convolutional Networks for Skeleton-Based Action Recognition. Sensors 2021, 21, 6761. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.; Ramzan, M.; Khan, H.U.; Iqbal, S.; Choi, J.-I.; Nam, Y.; Kady, S. Real-Time Violent Action Recognition Using Key Frames Extraction and Deep Learning. Comput. Mater. Continua 2021, 69, 2217–2230. [Google Scholar] [CrossRef]
- Wang, J.; Cao, D.; Wang, J.; Liu, C. Action Recognition of Lower Limbs Based on Surface Electromyography Weighted Feature Method. Sensors 2021, 21, 6147. [Google Scholar] [CrossRef]
- Zin, T.T.; Htet, Y.; Akagi, Y.; Tamura, H.; Kondo, K.; Araki, S.; Chosa, E. Real-Time Action Recognition System for Elderly People Using Stereo Depth Camera. Sensors 2021, 21, 5895. [Google Scholar] [CrossRef] [PubMed]
- Farnoosh, A.; Wang, Z.; Zhu, S.; Ostadabbas, S. A Bayesian Dynamical Approach for Human Action Recognition. Sensors 2021, 21, 5613. [Google Scholar] [CrossRef] [PubMed]
- Buehner, M.J. Awareness of voluntary and involuntary causal actions and their outcomes. Psychol. Conscious. Theory Res. Pract. 2015, 2, 237. [Google Scholar] [CrossRef]
- Hassaballah, M.; Hosny, K.M. Studies in Computational Intelligence. In Recent Advances In Computer Vision; Hassaballah, M., Hosny, K.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Sharif, M.; Akram, T.; Raza, M.; Saba, T.; Rehman, A. Hand-crafted and deep convolutional neural network features fusion and selection strategy: An application to intelligent human action recognition. Appl. Soft Comput. 2020, 87, 105986. [Google Scholar]
- Kolekar, M.H.; Dash, D.P. Hidden markov model based human activity recognition using shape and optical flow based features. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016. [Google Scholar]
- Hermansky, H. TRAP-TANDEM: Data-driven extraction of temporal features from speech. In Proceedings of the 2003 IEEE Workshop on Automatic Speech Recognition and Understanding (IEEE Cat. No. 03EX721), St Thomas, VI, USA, 30 November–4 December 2003. [Google Scholar]
- Krzeszowski, T.; Przednowek, K.; Wiktorowicz, K.; Iskra, J. The Application of Multiview Human Body Tracking on the Example of Hurdle Clearance. In Sport Science Research and Technology Support; Cabri, J., Pezarat-Correia, P., Vilas-Boas, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Hassaballah, M.; Awad, A.I. Deep Learning In Computer Vision: Principles and Applications; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018. [Google Scholar] [CrossRef] [PubMed]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Palacio-Niño, J.-O.; Berzal, F. Evaluation metrics for unsupervised learning algorithms. arXiv 2019, arXiv:1905.05667. [Google Scholar]
- Kiran, S.; Khan, M.A.; Javed, M.Y.; Alhaisoni, M.; Tariq, U.; Nam, Y.; Damaševičius, R.; Sharif, M. Multi-Layered Deep Learning Features Fusion for Human Action Recognition. Comput. Mater. Cont. 2021, 69, 4061–4075. [Google Scholar] [CrossRef]
- Khan, M.A.; Alhaisoni, M.; Armghan, A.; Alenezi, F.; Tariq, U.; Nam, Y.; Akram, T. Video Analytics Framework for Human Action Recognition. Comput. Mater. Cont. 2021, 68, 3841–3859. [Google Scholar]
- Sharif, M.; Akram, T.; Yasmin, M.; Nayak, R.S. Stomach deformities recognition using rank-based deep features selection. J. Med. Econ. 2019, 43, 329. [Google Scholar]
- Saleem, F.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Armghan, A.; Alenezi, F.; Choi, J.; Kadry, S. Human Gait Recognition: A Single Stream Optimal Deep Learning Features Fusion. Sensors 2021, 21, 7584. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Javed, M.Y.; Alhaisoni, M.; Tariq, U.; Kadry, S.; Choi, J.; Nam, Y. Human Gait Recognition Using Deep Learning and Improved Ant Colony Optimization. Comput. Mater. Cont. 2022, 70, 2113–2130. [Google Scholar] [CrossRef]
- Mehmood, A.; Tariq, U.; Jeong, C.-W.; Nam, Y.; Mostafa, R.R.; Elaeiny, A. Human Gait Recognition: A Deep Learning and Best Feature Selection Framework. Comput. Mater. Cont. 2022, 70, 343–360. [Google Scholar] [CrossRef]
- Wang, H.; Yu, B.; Xia, K.; Li, J.; Zuo, X. Skeleton Edge Motion Networks for Human Action Recognition. Neurocomputing 2021, 423, 1–12. [Google Scholar] [CrossRef]
- Bi, Z.; Huang, W. Human action identification by a quality-guided fusion of multi-model feature. Future Gener. Comput. Syst. 2021, 116, 13–21. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process 2020, 138, 106587. [Google Scholar] [CrossRef]
- Manivannan, A.; Chin, W.C.B.; Barrat, A.; Bouffanais, R. On the challenges and potential of using barometric sensors to track human activity. Sensors 2020, 20, 6786. [Google Scholar] [CrossRef] [PubMed]
- Ahmed Bhuiyan, R.; Ahmed, N.; Amiruzzaman, M.; Islam, M.R. A robust feature extraction model for human activity characterization using 3-axis accelerometer and gyroscope data. Sensors 2020, 20, 6990. [Google Scholar] [CrossRef]
- Zhao, B.; Li, S.; Gao, Y.; Li, C.; Li, W. A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition. Sensors 2020, 20, 6984. [Google Scholar] [CrossRef] [PubMed]
- Muhammad, K.; Ullah, A.; Imran, A.S.; Sajjad, M.; Kiran, M.S.; Sannino, G.; Albuquerque, V.H.C. Human action recognition using attention based LSTM network with dilated CNN features. Future Gener. Comput. Syst. 2021, 125, 820–830. [Google Scholar] [CrossRef]
- Li, C.; Xie, C.; Zhang, B.; Han, J.; Zhen, X.; Chen, J. Memory attention networks for skeleton-based action recognition. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Im, W.; Kim, T.-K.; Yoon, S.-E. Unsupervised Learning of Optical Flow with Deep Feature Similarity. In Computer Vision—ECCV 2020. ECCV 2020; Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; Volume 12369. [Google Scholar]
- Liu, W.; Zha, Z.-J.; Wang, Y.; Lu, K.; Tao, D. $p$-Laplacian regularized sparse coding for human activity recognition. IEEE Trans. Ind. Electron. 2016, 63, 5120–5129. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. A Depth Video-based Human Detection and Activity Recognition using Multi-features and Embedded Hidden Markov Models for Health Care Monitoring Systems. Int. J. Interact. Multimed. Artif. Intell. 2017, 4, 54. [Google Scholar] [CrossRef] [Green Version]
- Effrosynidis, D.; Arampatzis, A. An evaluation of feature selection methods for environmental data. Ecol Inform. 2021, 61, 101224. [Google Scholar] [CrossRef]
- Melhart, D.; Liapis, A.; Yannakakis, G.N. The Affect Game AnnotatIoN (AGAIN) Dataset. arXiv 2021, arXiv:2104.02643. [Google Scholar]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Joshi, A.B.; Kumar, D.; Gaffar, A.; Mishra, D. Triple color image encryption based on 2D multiple parameter fractional discrete Fourier transform and 3D Arnold transform. Opt. Lasers. Eng. 2020, 133, 106139. [Google Scholar] [CrossRef]
- Cervantes, J.; Garcia-Lamont, F.; Rodríguez-Mazahua, L.; Lopez, A. A comprehensive survey on support vector machine classification: Applications, challenges and trends. Neurocomputing 2020, 408, 189–215. [Google Scholar] [CrossRef]
- Wang, L.; Xu, Y.; Cheng, J.; Xia, H.; Yin, J.; Wu, J. Human action recognition by learning spatio-temporal features with deep neural networks. IEEE Access 2018, 6, 17913–17922. [Google Scholar] [CrossRef]
- Gumaei, A.; Hassan, M.M.; Alelaiwi, A.; Alsalman, H. A hybrid deep learning model for human activity recognition using multimodal body sensing data. IEEE Access 2019, 7, 99152–99160. [Google Scholar] [CrossRef]
- Gao, Z.; Xuan, H.-Z.; Zhang, H.; Wan, S.; Choo, K.-K.R. Adaptive fusion and category-level dictionary learning model for multiview human action recognition. IEEE Internet Things J. 2019, 6, 9280–9293. [Google Scholar] [CrossRef]
- Khan, M.A.; Zhang, Y.-D.; Khan, S.A.; Attique, M.; Rehman, A.; Seo, S. A resource conscious human action recognition framework using 26-layered deep convolutional neural network. Multimed. Tools. Appl. 2020. [Google Scholar] [CrossRef]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN architecture for human activity recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Rashid, M.; Sharif, M.; Raza, M.; Sarfraz, M.M.; Afza, F. Object detection and classification: A joint selection and fusion strategy of deep convolutional neural network and SIFT point features. Multimed. Tools. Appl. 2019, 78, 15751–15777. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE Press: Piscataway, NJ, USA. [Google Scholar]
- Hussain, N.; Sharif, M.; Khan, S.A.; Albesher, A.A.; Saba, T.; Armaghan, A. A deep neural network and classical features based scheme for objects recognition: An application for machine inspection. Multimed. Tools. Appl. 2020, 1–23. [Google Scholar] [CrossRef]
- Akram, T.; Zhang, Y.-D.; Sharif, M. Attributes based skin lesion detection and recognition: A mask RCNN and transfer learning-based deep learning framework. Pattern Recognit. Lett. 2021, 143, 58–66. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image databas e. In Proceedings of the 2009 IEEE conference on computer vision and pattern recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. NIPS 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Naheed, N.; Shaheen, M.; Khan, S.A.; Alawairdhi, M.; Khan, M.A. Importance of features selection, attributes selection, challenges and future directions for medical imaging data: A review. Comput. Sci. Eng. 2020, 125, 314–344. [Google Scholar] [CrossRef]
- Nadeem, A.; Jalal, A.; Kim, K. Automatic human posture estimation for sport activity recognition with robust body parts detection and entropy markov model. Multimed. Tools. Appl. 2021, 22, 1–34. [Google Scholar] [CrossRef]
- Sharif, M.; Zahid, F.; Shah, J.H.; Akram, T. Human action recognition: A framework of statistical weighted segmentation and rank correlation-based selection. Pattern Anal. Appl. 2020, 23, 281–294. [Google Scholar] [CrossRef]
- Akram, T.; Sharif, M.; Javed, M.Y.; Muhammad, N.; Yasmin, M. An implementation of optimized framework for action classification using multilayers neural network on selected fused features. Pattern Anal. Appl. 2019, 22, 1377–1397. [Google Scholar]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Datasets Accuracy on DenseNet201 Deep Model | |||
|---|---|---|---|---|
| KTH | Hollywood | WVU | IXAMAS | |
| Linear Discriminant | 98.8 | 99.6 | 98.3 | 92.1 |
| Linear SVM | 98.0 | 98.3 | 97.1 | 86.6 |
| Quadratic SVM | 98.9 | 99.6 | 99.7 | 96.4 |
| Cubic SVM | 99.3 | 99.8 | 99.8 | 95.4 |
| Medium Gaussian SVM | 98.6 | 99.5 | 97.8 | 93.1 |
| Fine KNN | 98.7 | 99.9 | 99.3 | 97.3 |
| Medium KNN | 96.7 | 98.8 | 97.3 | 88.0 |
| Cosine KNN | 96.9 | 98.8 | 97.4 | 88.3 |
| Weighted KNN | 97.2 | 99.7 | 98.0 | 92.9 |
| Ensemble Bagged Trees | 89.6 | 98.2 | 94.5 | 82.9 |
| Classifier | Datasets Accuracy on DenseNet201 Deep Model | |||
|---|---|---|---|---|
| KTH | Hollywood | WVU | IXAMAS | |
| Linear Discriminant | 96.6 | 98.8 | 96.5 | 87.3 |
| Linear SVM | 95.4 | 96.3 | 93.5 | 81.3 |
| Quadratic SVM | 97.6 | 99.3 | 99.0 | 92.1 |
| Cubic SVM | 98.1 | 99.5 | 99.1 | 93.6 |
| Medium Gaussian SVM | 97.0 | 99.3 | 97.7 | 91.2 |
| Fine KNN | 97.6 | 99.8 | 98.4 | 96.0 |
| Medium KNN | 95.00 | 98.1 | 94.8 | 83.8 |
| Cosine KNN | 95.6 | 98.5 | 95.1 | 84.7 |
| Weighted KNN | 95.9 | 99.1 | 95.8 | 90.0 |
| Ensemble Bagged Trees | 89.0 | 92.4 | 90.5 | 73.3 |
| Classifier | Recall Rate (%) | Precision Rate (%) | FNR | Time (s) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Linear Discriminant | 99.200 | 99.300 | 0.80 | 424.10 | 99.249 | 99.2 |
| Linear SVM | 98.400 | 98.616 | 1.60 | 487.10 | 98.508 | 98.4 |
| Quadratic SVM | 99.150 | 98.283 | 0.85 | 706.56 | 98.714 | 99.2 |
| Cubic SVM | 99.300 | 99.433 | 0.70 | 893.23 | 99.366 | 99.3 |
| Medium Gaussian SVM | 98.916 | 99.083 | 1.08 | 1445.8 | 98.999 | 98.9 |
| Fine KNN | 99.083 | 99.216 | 0.91 | 450.55 | 99.149 | 99.1 |
| Medium KNN | 96.700 | 97.233 | 3.30 | 447.37 | 96.965 | 96.8 |
| Cosine KNN | 97.516 | 97.716 | 2.48 | 459.33 | 97.616 | 97.5 |
| Weighted KNN | 97.483 | 97.916 | 2.51 | 447.59 | 97.699 | 97.6 |
| Ensemble Bagged Trees | 94.233 | 94.733 | 5.76 | 192.96 | 94.482 | 94.3 |
| Classifier | Recall Rate (%) | Precision Rate (%) | FNR | Time (s) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Linear Discriminant | 99.775 | 99.825 | 0.22 | 469.75 | 99.800 | 99.9 |
| Linear SVM | 99.887 | 99.25 | 1.11 | 734.42 | 99.567 | 99.2 |
| Quadratic SVM | 99.550 | 99.725 | 0.45 | 1065.4 | 99.637 | 99.7 |
| Cubic SVM | 99.575 | 99.775 | 0.42 | 1337.4 | 99.674 | 99.8 |
| Medium Gaussian SVM | 99.287 | 99.675 | 0.71 | 2227.1 | 99.480 | 99.7 |
| Fine KNN | 99.182 | 99.837 | 0.18 | 447.76 | 99.508 | 99.9 |
| Medium KNN | 98.500 | 99.0125 | 1.50 | 437.47 | 98.755 | 99.1 |
| Cosine KNN | 99.037 | 98.975 | 0.96 | 449.13 | 99.006 | 99.3 |
| Weighted KNN | 99.250 | 99.45 | 0.75 | 439.29 | 99.349 | 99.6 |
| Ensemble Bagged Trees | 94.425 | 97.562 | 5.57 | 209.63 | 95.968 | 96.7 |
| Classifier | Recall Rate (%) | Precision Rate (%) | FNR (%) | Time (s) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Linear Discriminant | 99.79 | 99.78 | 0.21 | 2073.1 | 99.785 | 99.8 |
| Linear SVM | 97.74 | 97.77 | 2.26 | 2567.7 | 97.755 | 97.7 |
| Quadratic SVM | 99.56 | 99.56 | 0.44 | 2824.5 | 99.560 | 99.6 |
| Cubic SVM | 99.56 | 99.57 | 0.44 | 2267 | 99.565 | 99.6 |
| Medium Gaussian SVM | 98.56 | 98.34 | 1.66 | 2749 | 98.449 | 98.3 |
| Fine KNN | 97.0 | 97.03 | 3.00 | 3486 | 97.015 | 97.0 |
| Medium KNN | 87.15 | 88.34 | 12.8 | 3933.5 | 87.741 | 87.2 |
| Cosine KNN | 87.98 | 89.01 | 12.1 | 2825.4 | 88.492 | 88.0 |
| Weighted KNN | 90.89 | 91.51 | 9.11 | 2716.7 | 91.198 | 90.9 |
| Ensemble Bagged Trees | 94.08 | 94.12 | 5.92 | 965.78 | 94.100 | 94.1 |
| Classifier | Recall Rate (%) | Precision Rate (%) | FNR (%) | Time (s) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Linear Discriminant | 96.460 | 96.310 | 3.54 | 508.35 | 96.384 | 96.5 |
| Linear SVM | 91.030 | 91.230 | 8.97 | 1428 | 91.129 | 91.3 |
| Quadratic SVM | 96.670 | 96.680 | 3.33 | 936.8 | 96.675 | 96.7 |
| Cubic SVM | 97.216 | 97.225 | 2.78 | 390.9 | 97.220 | 97.3 |
| Medium Gaussian SVM | 96.016 | 96.066 | 3.98 | 840.3 | 96.041 | 96.1 |
| Fine KNN | 97.180 | 97.250 | 2.82 | 570.56 | 97.215 | 97.4 |
| Medium KNN | 88.360 | 88.890 | 11.6 | 560.06 | 88.624 | 88.9 |
| Cosine KNN | 89.141 | 89.516 | 10.8 | 559.83 | 89.328 | 89.7 |
| Weighted KNN | 92.475 | 92.625 | 7.52 | 543.5 | 92.549 | 92.8 |
| Ensemble Bagged Trees | 80.291 | 81.550 | 19.7 | 284.31 | 80.915 | 81.4 |
| Classifier | Recall Rate (%) | Precision Rate (%) | FNR (%) | Time (s) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Linear Discriminant | 98.080 | 98.516 | 1.92 | 87.805 | 98.297 | 98.1 |
| Linear SVM | 97.633 | 97.933 | 2.36 | 255.42 | 97.783 | 97.7 |
| Quadratic SVM | 98.600 | 98.866 | 1.40 | 360.10 | 98.733 | 98.7 |
| Cubic SVM | 98.916 | 99.116 | 1.09 | 451.40 | 99.016 | 99.0 |
| Medium Gaussian SVM | 98.2833 | 98.483 | 1.71 | 687.37 | 98.383 | 98.3 |
| Fine KNN | 98.616 | 98.833 | 1.38 | 237.93 | 98.724 | 98.7 |
| Medium KNN | 95.483 | 96.366 | 4.51 | 231.39 | 95.922 | 95.7 |
| Cosine KNN | 97.016 | 97.183 | 2.98 | 230.18 | 97.099 | 97.0 |
| Weighted KNN | 96.233 | 97.000 | 3.76 | 222.90 | 96.615 | 96.4 |
| Ensemble Bagged Trees | 94.150 | 93.716 | 5.8 | 140.57 | 93.632 | 94.2 |
| Classifier | Recall Rate (%) | Precision Rate (%) | FNR (%) | Time (s) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Linear Discriminant | 99.087 | 99.450 | 0.912 | 88.375 | 99.268 | 99.4 |
| Linear SVM | 97.937 | 98.687 | 2.062 | 323.99 | 98.311 | 98.6 |
| Quadratic SVM | 99.262 | 99.587 | 0.737 | 439.41 | 99.424 | 99.5 |
| Cubic SVM | 99.387 | 99.675 | 0.612 | 501.67 | 99.531 | 99.7 |
| Medium Gaussian SVM | 98.587 | 99.500 | 1.412 | 910.78 | 99.041 | 99.5 |
| Fine KNN | 99.812 | 99.837 | 0.187 | 213.33 | 99.825 | 99.8 |
| Medium KNN | 97.225 | 98.550 | 2.775 | 224.52 | 97.883 | 98.5 |
| Cosine KNN | 98.325 | 98.862 | 1.675 | 221.19 | 98.593 | 98.9 |
| Weighted KNN | 98.575 | 99.412 | 1.425 | 215.89 | 98.992 | 99.2 |
| Ensemble Bagged Trees | 87.050 | 94.287 | 12.95 | 126.72 | 90.524 | 97.7 |
| Classifier | Recall Rate (%) | Precision Rate (%) | FNR (%) | Time (s) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Linear Discriminant | 98.50 | 98.53 | 1.50 | 241.48 | 98.515 | 98.5 |
| Linear SVM | 96.51 | 96.57 | 3.49 | 293.2 | 96.539 | 96.5 |
| Quadratic SVM | 99.37 | 99.38 | 0.63 | 1064.6 | 99.375 | 99.4 |
| Cubic SVM | 99.43 | 99.44 | 0.57 | 1124.0 | 99.435 | 99.4 |
| Medium Gaussian SVM | 98.24 | 98.25 | 1.76 | 1363.7 | 98.245 | 98.2 |
| Fine KNN | 96.55 | 96.59 | 3.45 | 1365.1 | 96.570 | 96.5 |
| Medium KNN | 86.80 | 87.98 | 13.2 | 1322.0 | 87.386 | 86.8 |
| Cosine KNN | 87.61 | 88.73 | 12.39 | 1316.2 | 88.166 | 87.6 |
| Weighted KNN | 90.33 | 91.07 | 9.67 | 1236.8 | 90.698 | 90.3 |
| Ensemble Bagged Trees | 94.71 | 94.75 | 5.29 | 423.37 | 94.730 | 95.7 |
| Classifier | Recall Rate (%) | Precision Rate (%) | FNR (%) | Time (s) | F1 Score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|
| Linear Discriminant | 91.583 | 91.516 | 8.41 | 119.8 | 91.549 | 91.7 |
| Linear SVM | 88.050 | 88.400 | 11.95 | 714.13 | 88.224 | 88.5 |
| Quadratic SVM | 95.008 | 95.083 | 4.99 | 634.7 | 95.045 | 95.1 |
| Cubic SVM | 95.783 | 95.866 | 4.21 | 239.4 | 95.824 | 95.9 |
| Medium Gaussian SVM | 94.466 | 94.933 | 5.53 | 475.5 | 94.699 | 94.6 |
| Fine KNN | 97.075 | 96.991 | 2.92 | 290.69 | 97.033 | 97.1 |
| Medium KNN | 86.383 | 86.925 | 13.61 | 266.24 | 86.653 | 86.9 |
| Cosine KNN | 88.066 | 88.233 | 11.93 | 270.74 | 88.149 | 88.5 |
| Weighted KNN | 90.975 | 91.966 | 9.02 | 263.74 | 91.468 | 91.2 |
| Ensemble Bagged Trees | 83.433 | 85.108 | 16.5 | 175.78 | 84.261 | 84.8 |
| Reference | Dataset | Accuracy (%) |
|---|---|---|
| Muhammad et al. [45], 2020 | KTH | 98.30 |
| Proposed method | KTH | 99.00 |
| Muhammad et al. [4], 2020 | IXMAS | 95.20 |
| Amir et al. [55], 2021 | IXMAS | 87.48 |
| Proposed method | IXMAS | 97.10 |
| Muhammad et al. [56], 2020 | WVU | 99.10 |
| Muhammad et al. [57], 2019 | WVU | 99.90 |
| Proposed method | WVU | 99.40 |
| Evan et al. [58], 2008 | Hollywood | 91.80 |
| Proposed method | Hollywood | 99.20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, S.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Yong, H.-S.; Armghan, A.; Alenezi, F. Human Action Recognition: A Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion. Sensors 2021, 21, 7941. https://doi.org/10.3390/s21237941
Khan S, Khan MA, Alhaisoni M, Tariq U, Yong H-S, Armghan A, Alenezi F. Human Action Recognition: A Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion. Sensors. 2021; 21(23):7941. https://doi.org/10.3390/s21237941
Chicago/Turabian StyleKhan, Seemab, Muhammad Attique Khan, Majed Alhaisoni, Usman Tariq, Hwan-Seung Yong, Ammar Armghan, and Fayadh Alenezi. 2021. "Human Action Recognition: A Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion" Sensors 21, no. 23: 7941. https://doi.org/10.3390/s21237941
APA StyleKhan, S., Khan, M. A., Alhaisoni, M., Tariq, U., Yong, H.-S., Armghan, A., & Alenezi, F. (2021). Human Action Recognition: A Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion. Sensors, 21(23), 7941. https://doi.org/10.3390/s21237941