
Multimodal Deep Reinforcement Learning with Auxiliary Task for Obstacle Avoidance of Indoor Mobile Robot



Abstract
:1. Introduction
2. Materials and Methods
2.1. Problem Definition
2.2. Network Architecture
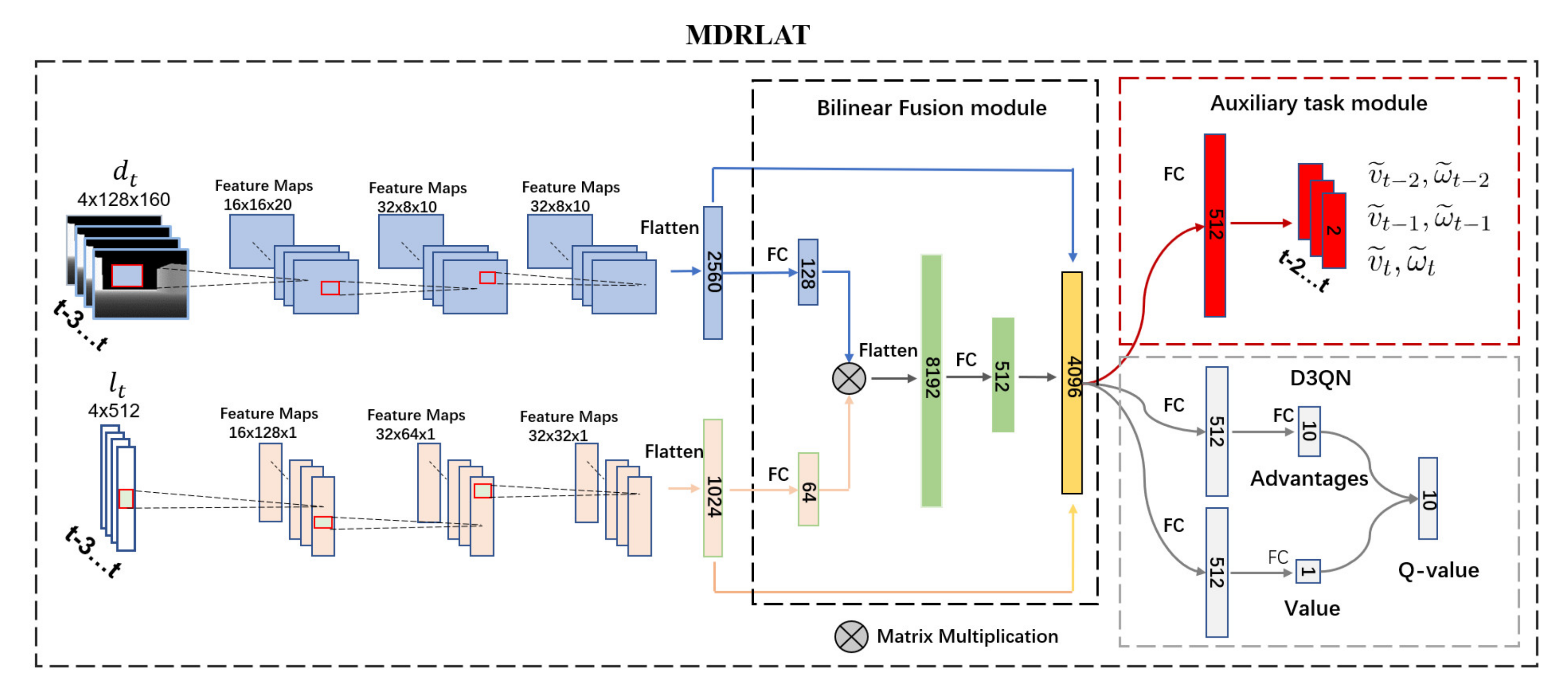
2.2.1. Network Architecture for Multimodal Representation
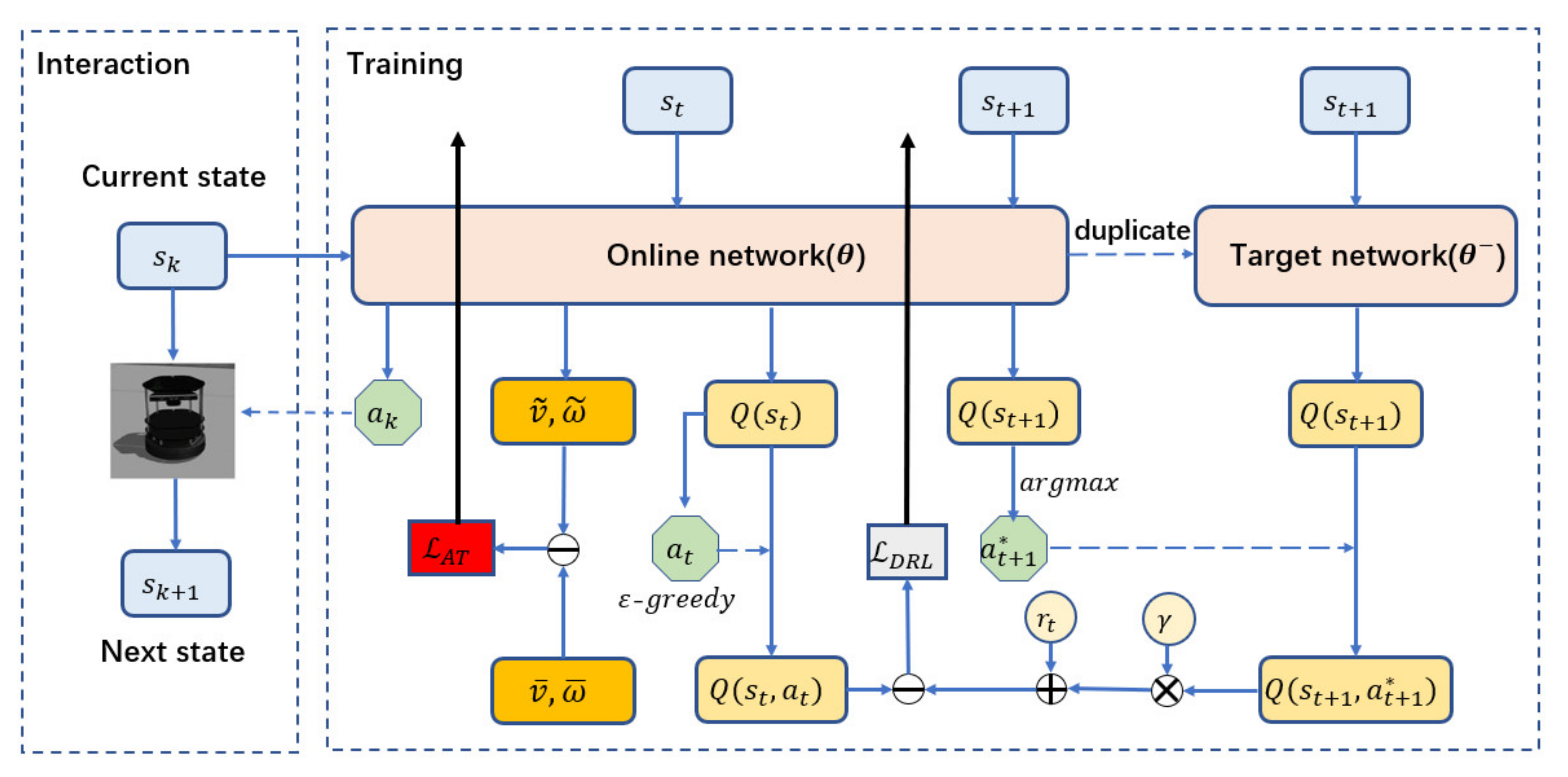
2.2.2. Dueling Double Deep Q-Network
2.2.3. Auxiliary Task Module
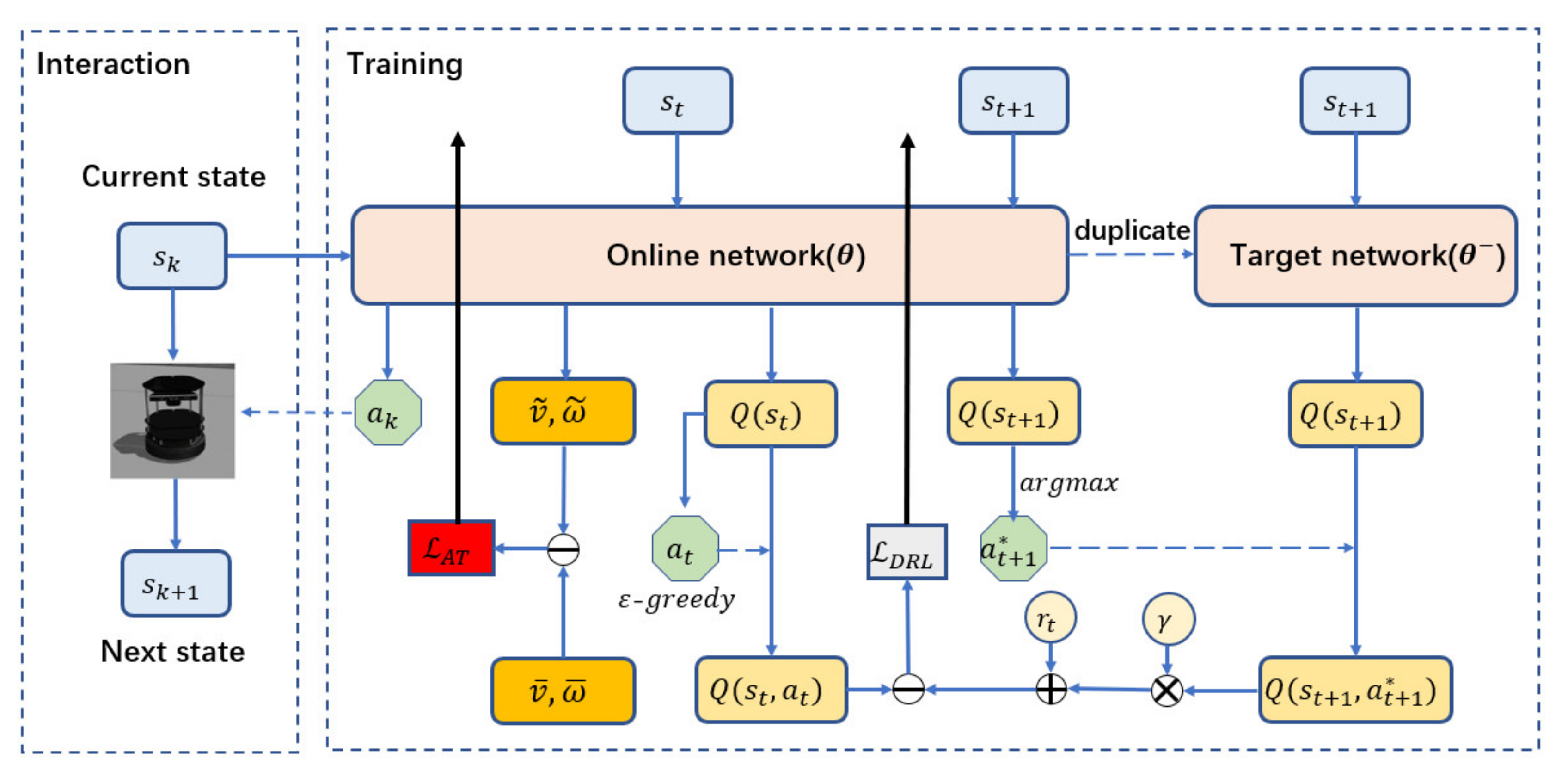
2.3. Training Framework
| Algorithm 1: MDRLAT |
| 1: Initialize experience replay buffer to capacity , parameters of online network , parameters of target network , frequency to update target network |
| 2: for do |
| 3: Obtain from the environment, with probability select a random action , otherwise select |
| 4: Execute action , transit to next state and receive a reward |
| 5: Store transition in |
| 6: Randomly sample a batch of transition from |
| 7: if episode terminates at step then |
| 8: Set |
| 9: else |
| 10: Set |
| 11: end if |
| 12: Compute loss |
| 13: Feed into the online network to get estimated velocity , |
| 14: Compute loss |
| 15: Update the parameters of the online network |
| 16: if mod then |
| 17: Update the parameters of the target network |
| 18: end if |
| 19: end for |
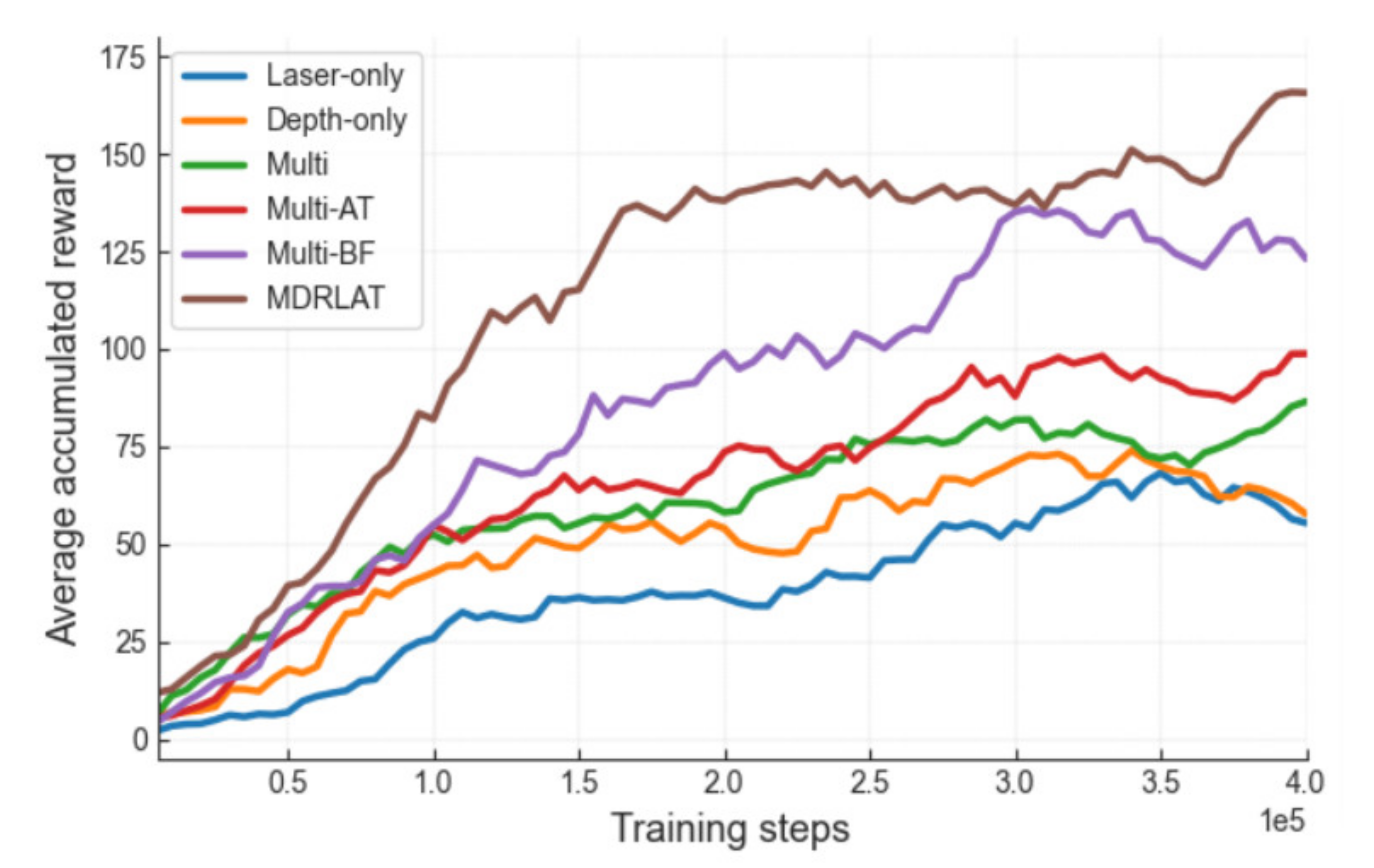
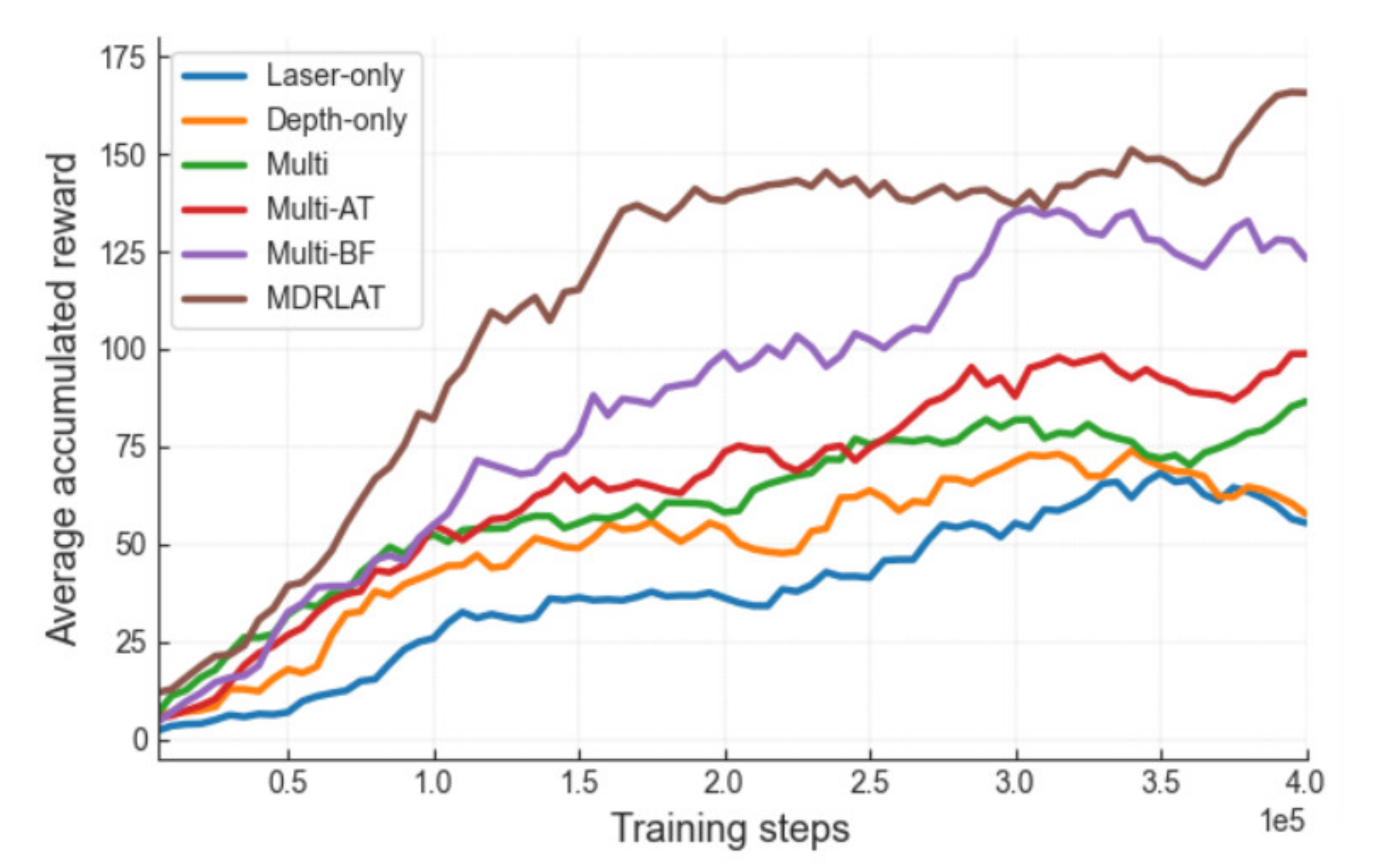
3. Results
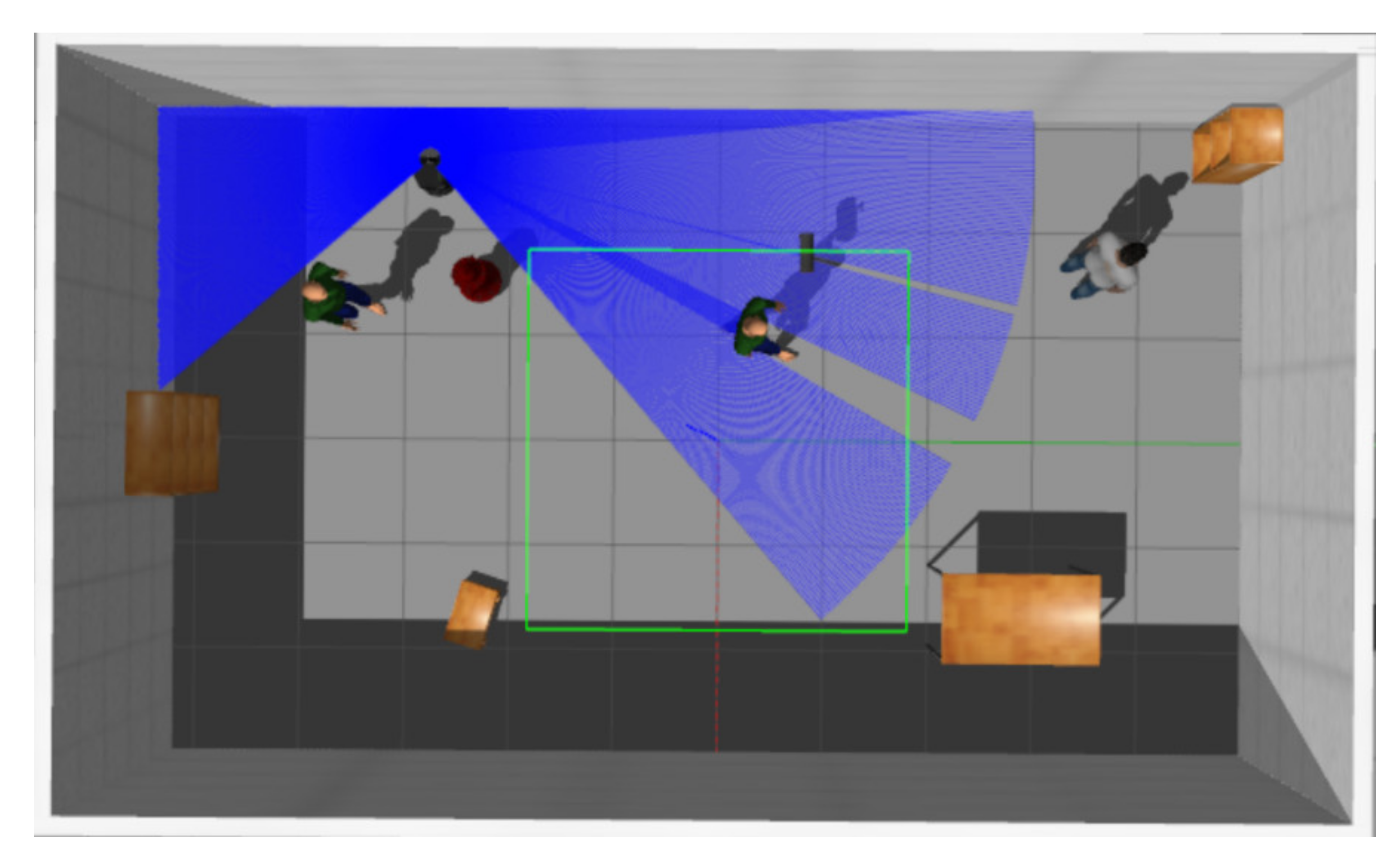
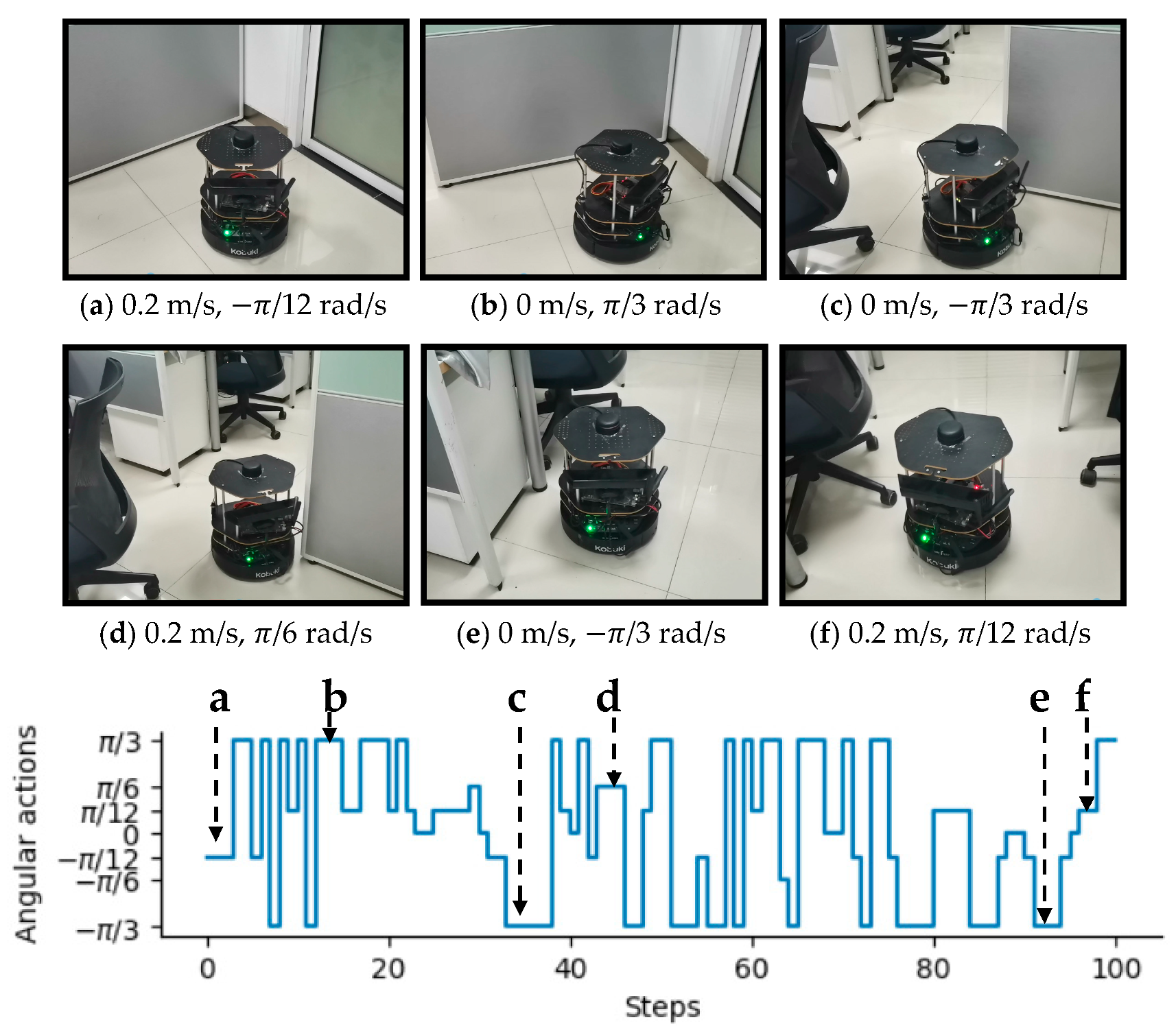
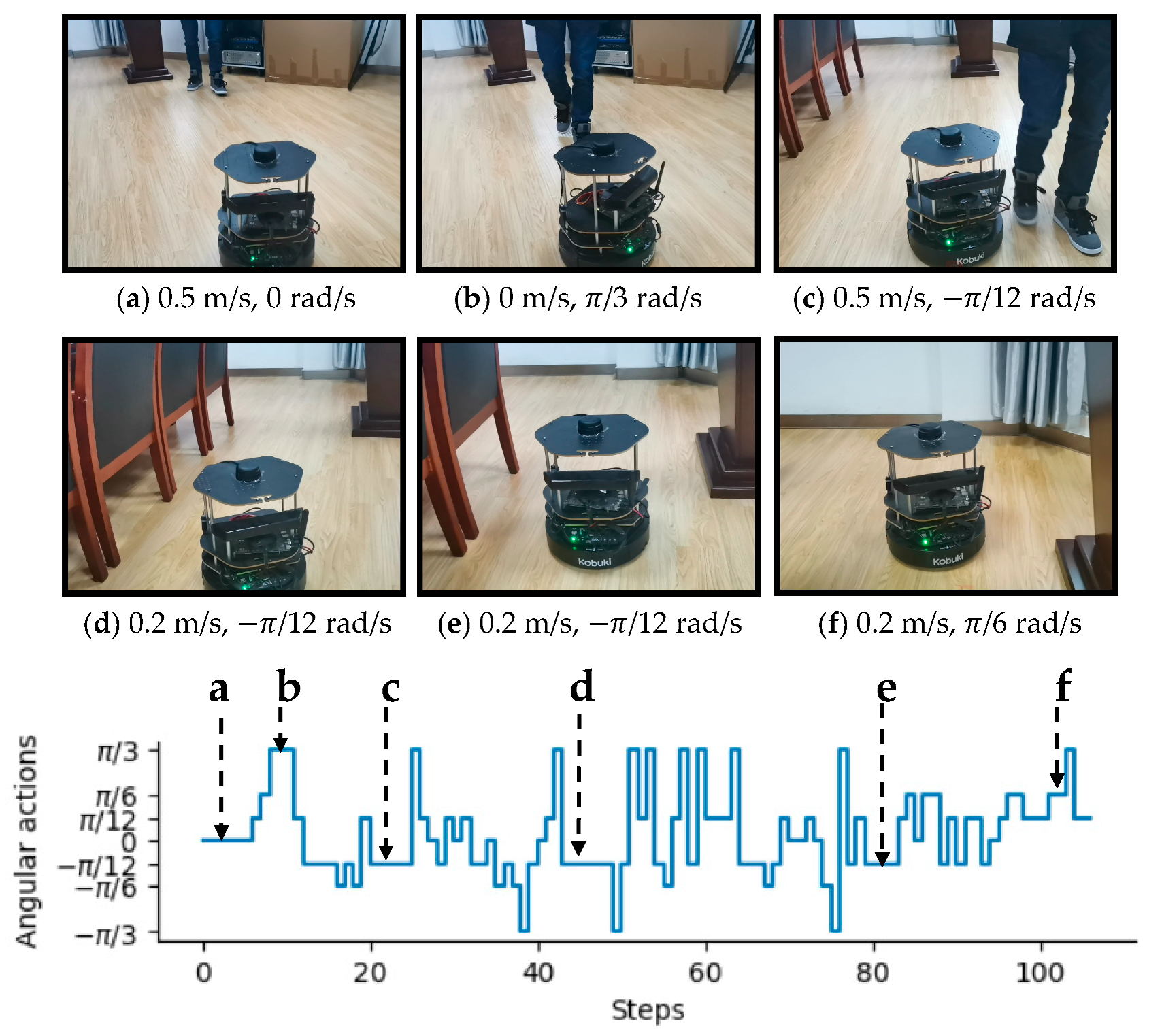
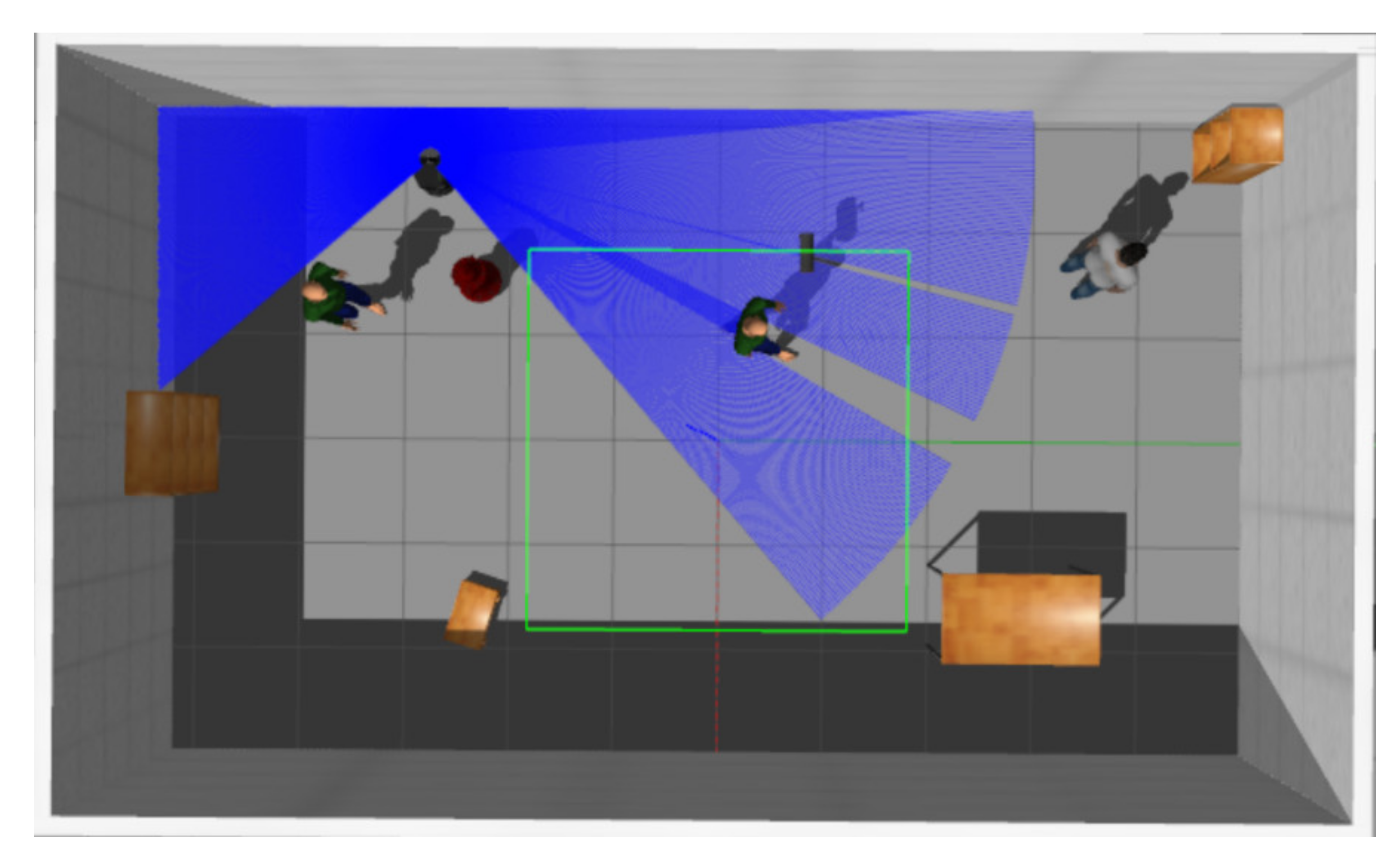
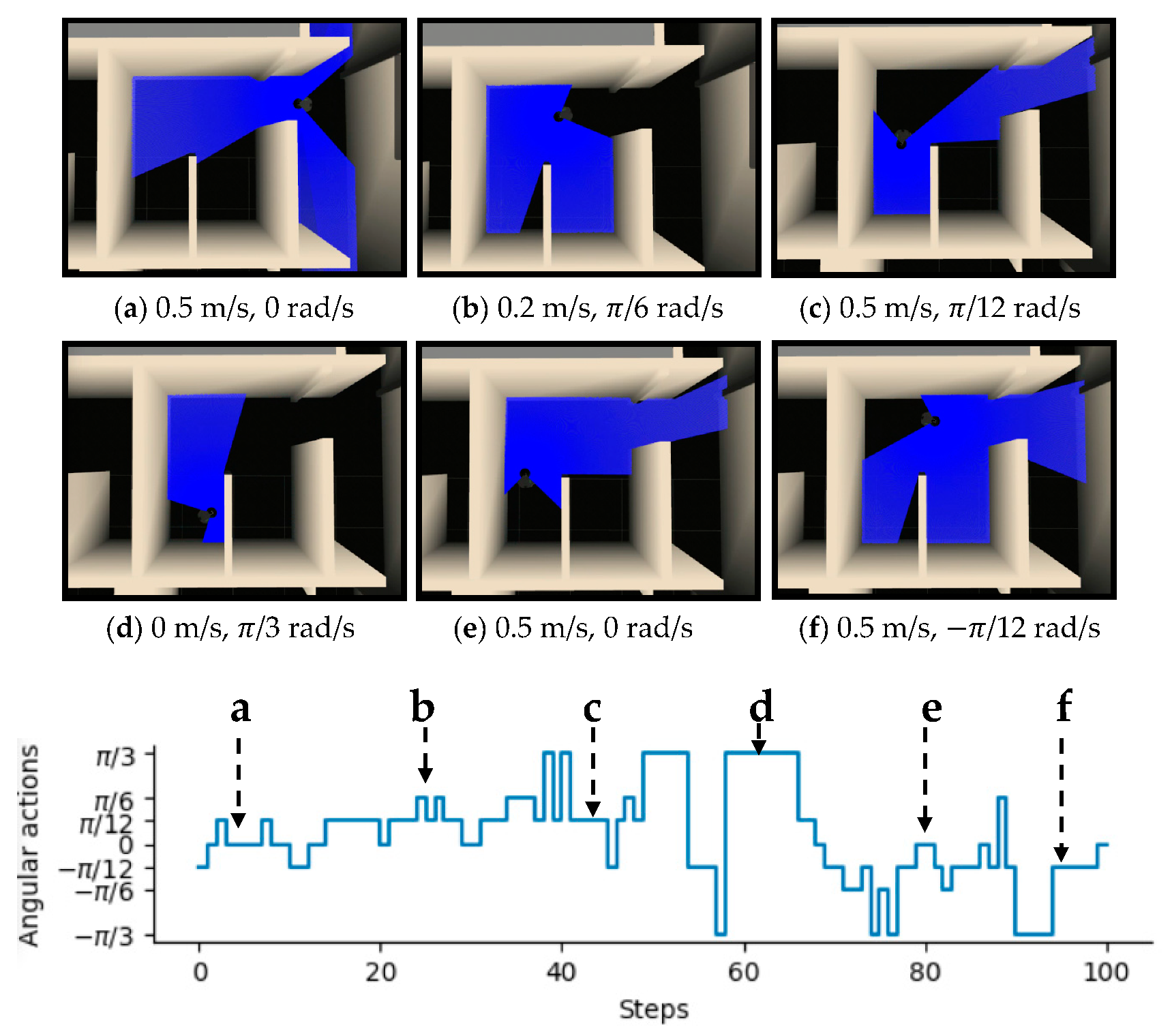
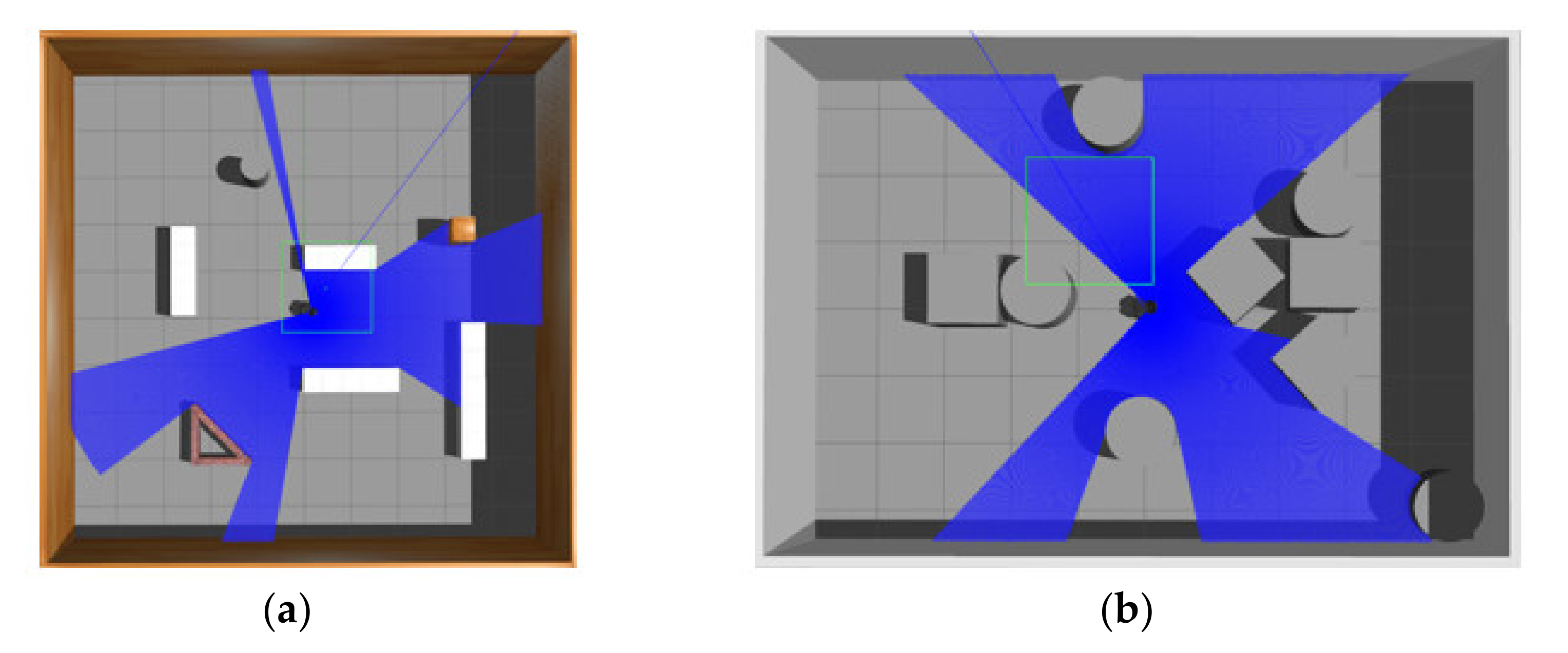
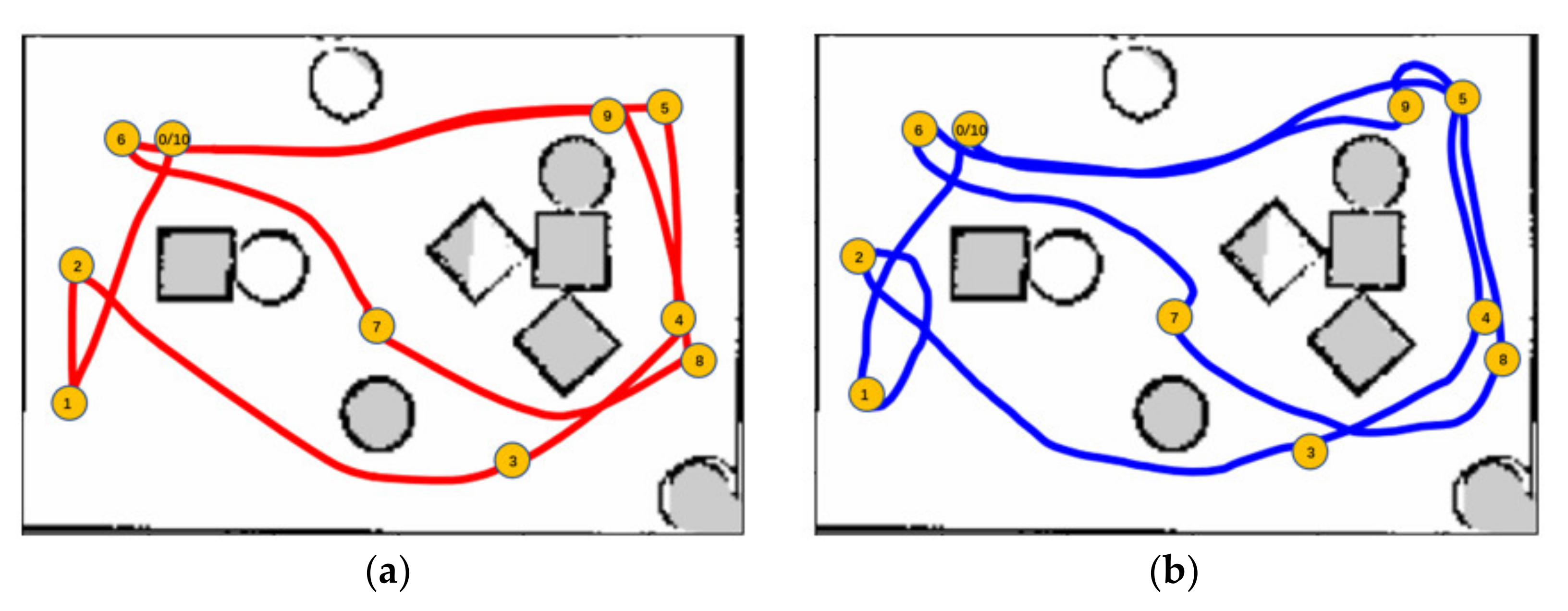
3.1. Experiments in Virtual Environments
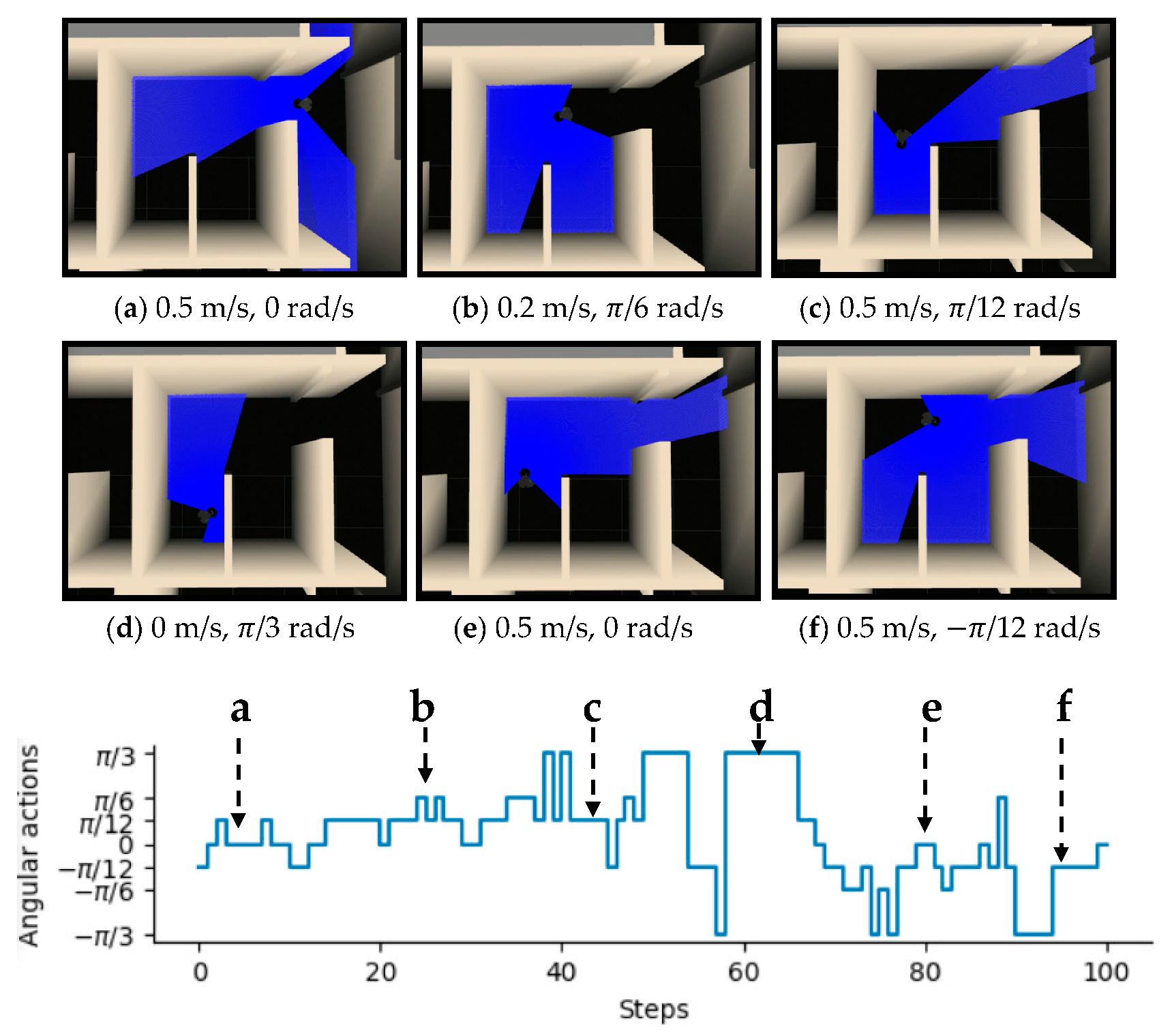
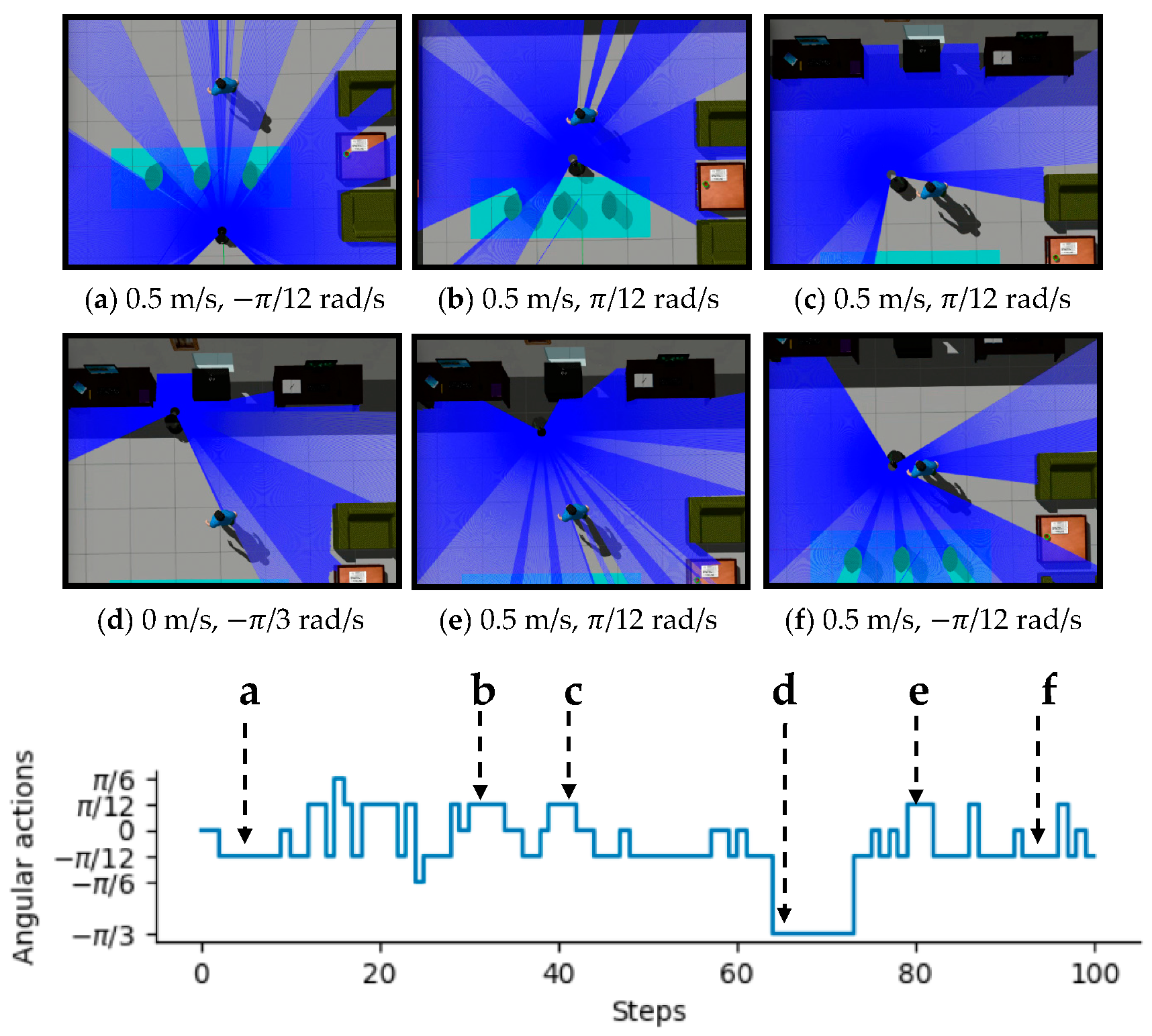
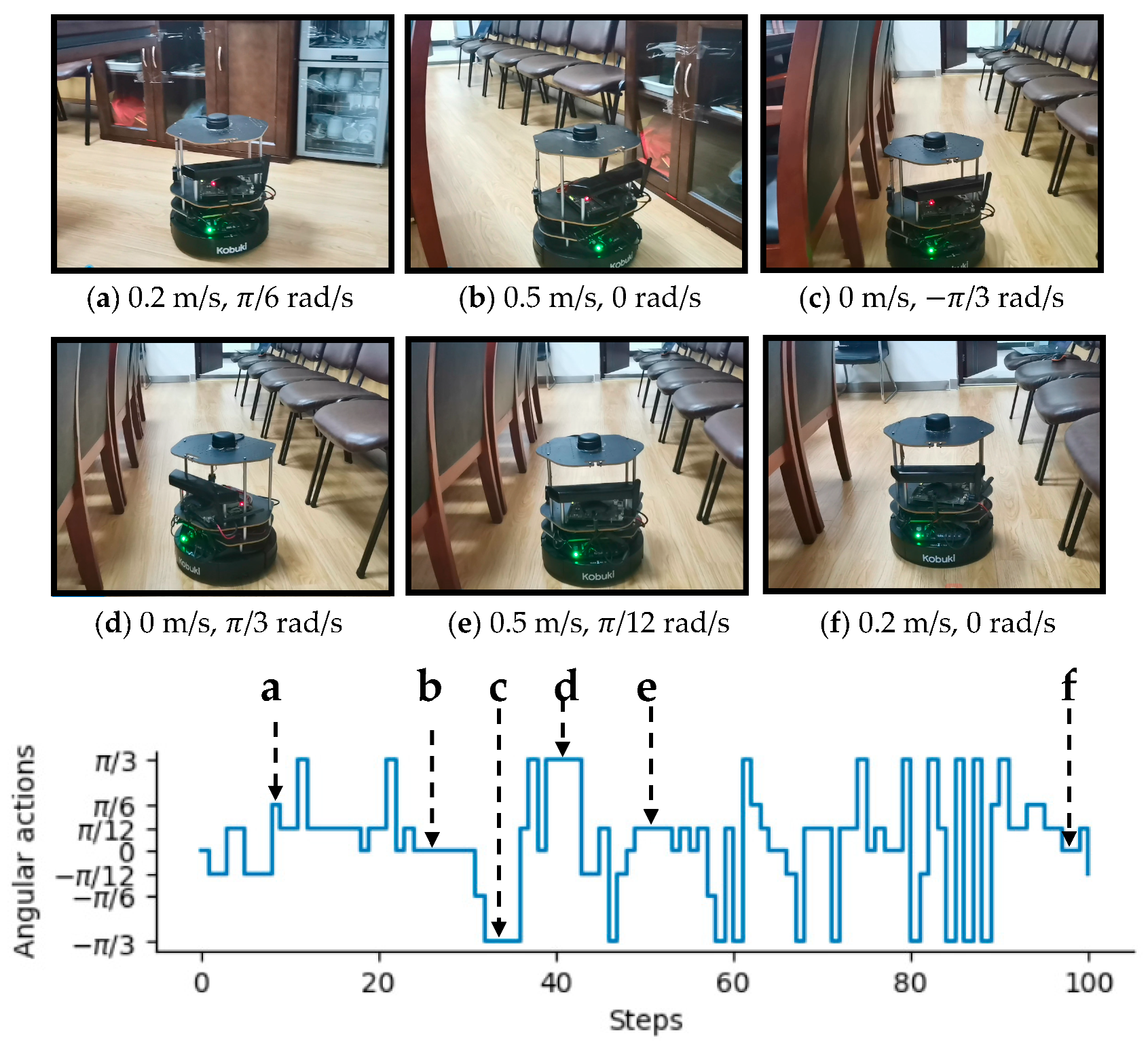
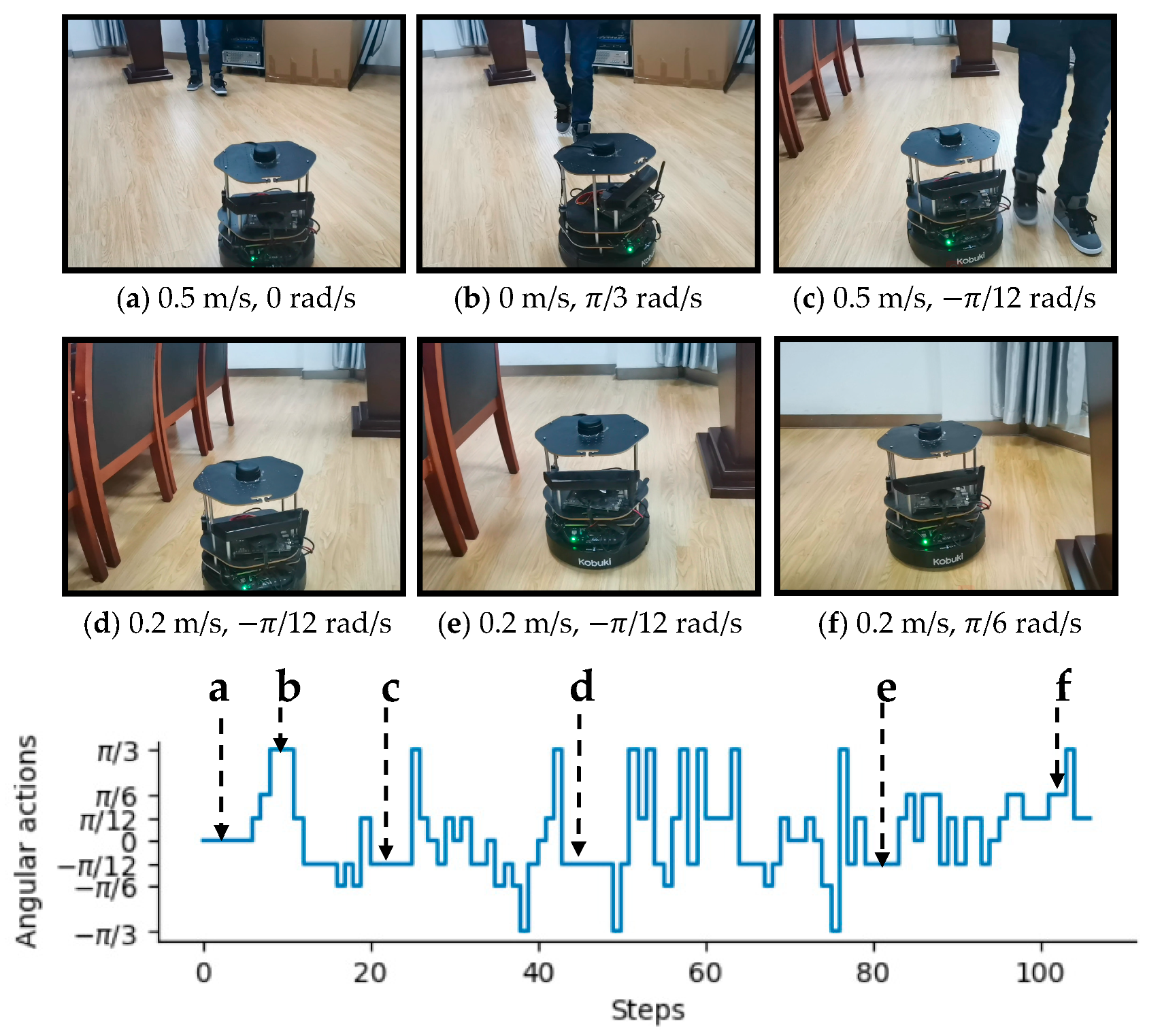
3.2. Experiments in Real-World Environments
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ingrand, F.; Ghallab, M. Deliberation for autonomous robots: A survey. Artif. Intell. 2017, 247, 10–44. [Google Scholar] [CrossRef] [Green Version]
- Pandey, A.; Pandey, S.; Parhi, D. Mobile robot navigation and obstacle avoidance techniques: A review. Int. Rob. Auto. J. 2017, 2, 96–105. [Google Scholar] [CrossRef] [Green Version]
- Jin, Z.; Shao, Y.; So, M.; Sable, C.; Shlayan, N.; Luchtenburg, D.M. A Multisensor Data Fusion Approach for Simultaneous Localization and Mapping. In Proceedings of the IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1317–1322. [Google Scholar]
- Long, P.; Fanl, T.; Liao, X.; Liu, W.; Zhang, H.; Pan, J. Towards optimally decentralized multi-robot collision avoidance via deep reinforcement learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 6252–6259. [Google Scholar]
- Peng, Y.; Qu, D.; Zhong, Y.; Xie, S.; Luo, J.; Gu, J. The obstacle detection and obstacle avoidance algorithm based on 2-d lidar. In Proceedings of the IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 1648–1653. [Google Scholar]
- Baltzakis, H.; Argyros, A.; Trahanias, P. Fusion of laser and visual data for robot motion planning and collision avoidance. Mach. Vis. Appl. 2003, 15, 92–100. [Google Scholar] [CrossRef]
- Kwon, Y.D.; Lee, J.S. A stochastic map building method for mobile robot using 2-d laser range finder. Auton. Robot. 1999, 7, 187–200. [Google Scholar] [CrossRef]
- Misono, Y.; Goto, Y.; Tarutoko, Y.; Kobayashi, K.; Watanabe, K. Development of laser rangefinder-based SLAM algorithm for mobile robot navigation. In Proceedings of the SICE Annual Conference, Takamatsu, Japan, 17–20 September 2007; pp. 392–396. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Xie, L.; Wang, S.; Rosa, S.; Markham, A.; Trigoni, N. Learning with training wheels: Speeding up training with a simple controller for deep reinforcement learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 6276–6283. [Google Scholar]
- Wu, K.; Abolfazli Esfahani, M.; Yuan, S.; Wang, H. Learn to steer through deep reinforcement learning. Sensors 2018, 18, 3650. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, S.; Gupta, D.; Yadav, S. Sensor fusion of laser and stereo vision camera for depth estimation and obstacle avoidance. Int. J. Comput. Appl. 2010, 1, 22–27. [Google Scholar] [CrossRef]
- Wu, K.; Wang, H.; Esfahani, M.A.; Yuan, S. BND*-DDQN: Learn to Steer Autonomously through Deep Reinforcement Learning. IEEE Trans. Cogn. Dev. Syst. 2019. [Google Scholar] [CrossRef]
- Tai, L.; Liu, M. Towards cognitive exploration through deep reinforcement learning for mobile robots. arXiv 2016, arXiv:1610.01733. [Google Scholar]
- Xie, L.; Wang, S.; Markham, A.; Trigoni, N. Towards monocular vision based obstacle avoidance through deep reinforcement learning. arXiv 2017, arXiv:1706.09829. [Google Scholar]
- Choi, J.; Park, K.; Kim, M.; Seok, S. Deep reinforcement learning of navigation in a complex and crowded environment with a limited field of view. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5993–6000. [Google Scholar]
- Li, X.; Li, S.; Jia, S.; Xu, C. Mobile robot map building based on laser ranging and kinect. In Proceedings of the IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016; pp. 819–824. [Google Scholar]
- Lara-Guzmán, O.; Serrano, S.A.; Carrillo-López, D.; Sucar, L.E. Rgb-d camera and 2d laser integration for robot navigation in dynamic environments. In Proceedings of the Mexican International Conference on Artificial Intelligence, Xalapa, Mexico, 27 October–2 November 2019; pp. 661–674. [Google Scholar]
- Chavez, A.; Karstoft, H. Map building based on a xtion pro live rgbd and a laser sensors. J. Inf. Technol. Softw. Eng. 2014, 4, 126. [Google Scholar] [CrossRef] [Green Version]
- Qureshi, A.H.; Nakamura, Y.; Yoshikawa, Y.; Ishiguro, H. Robot gains social intelligence through multimodal deep reinforcement learning. In Proceedings of the IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 5–17 November 2016; pp. 745–751. [Google Scholar]
- Lee, M.A.; Zhu, Y.; Srinivasan, K.; Shah, P.; Savarese, S.; Fei-Fei, L.; Garg, A.; Bohg, J. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In Proceedings of the International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8943–8950. [Google Scholar]
- Liu, G.-H.; Siravuru, A.; Prabhakar, S.; Veloso, M.; Kantor, G. Learning end-to-end multimodal sensor policies for autonomous navigation. arXiv 2017, arXiv:1705.10422. [Google Scholar]
- Alatise, M.B.; Hancke, G.P. A Review on Challenges of Autonomous Mobile Robot and Sensor Fusion Methods. IEEE Access 2020, 8, 39830–39846. [Google Scholar] [CrossRef]
- Geibel, P.; Wysotzki, F. Risk-sensitive reinforcement learning applied to control under constraints. J. Artif. Intell. Res. 2005, 24, 81–108. [Google Scholar] [CrossRef] [Green Version]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. arXiv 2015, arXiv:1509.06461. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israsel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Kim, J.-H.; On, K.-W.; Lim, W.; Kim, J.; Ha, J.-W.; Zhang, B.-T. Hadamard product for low-rank bilinear pooling. arXiv 2016, arXiv:1610.04325. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1995–2003. [Google Scholar]
- Lin, X.; Baweja, H.; Kantor, G.; Held, D. Adaptive Auxiliary Task Weighting for Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 4772–4783. [Google Scholar]
- Kartal, B.; Hernandez-Leal, P.; Taylor, M.E. Terminal prediction as an auxiliary task for deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Atlanta, GA, USA, 8–12 October 2019; pp. 38–44. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Sendai, Japan, 28 September–2 October 2004; pp. 2149–2154. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th Symposium on Operating Systems Design and Implementation (OSDI), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Rasouli, A.; Tsotsos, J.K. The Effect of Color Space Selection on Detectability and Discriminability of Colored Objects. arXiv 2017, arXiv:1702.05421. [Google Scholar]
- Move_Base. Available online: http://wiki.ros.org/move_base/ (accessed on 6 February 2021).
- Turtlebot2. Available online: https://www.turtlebot.com/turtlebot2/ (accessed on 6 February 2021).
- Souhila, K.; Karim, A. Optical flow based robot obstacle avoidance. Int. J. Adv. Robot. Syst. 2007, 4, 13–16. [Google Scholar] [CrossRef] [Green Version]
- OroojlooyJadid, A.; Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. arXiv 2019, arXiv:1908.03963. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.5 | 0.5 | 0.5 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0 | 0 | |
| −π/12 | 0 | π/12 | −π/6 | −π/12 | 0 | π/12 | π/6 | −π/3 | π/3 |
| Env | Laser-Only | Depth-Only | Multi | Multi-AT | Multi-BF | MDRLAT |
|---|---|---|---|---|---|---|
| Env1 | 67.6 4.8 | 69.2 3.5 | 76.8 4.1 | 86.0 4.2 | 89.6 1.5 | 94.4 2.3 |
| Env2 | 61.6 4.6 | 55.2 4.8 | 73.6 5.3 | 78.8 2.7 | 81.2 3.0 | 87.2 2.4 |
| Env3 | 64.8 3.2 | 63.2 2.7 | 70.8 4.1 | 78.4 5.0 | 79.6 3.4 | 83.6 3.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, H.; Li, A.; Wang, T.; Wang, M. Multimodal Deep Reinforcement Learning with Auxiliary Task for Obstacle Avoidance of Indoor Mobile Robot. Sensors 2021, 21, 1363. https://doi.org/10.3390/s21041363
Song H, Li A, Wang T, Wang M. Multimodal Deep Reinforcement Learning with Auxiliary Task for Obstacle Avoidance of Indoor Mobile Robot. Sensors. 2021; 21(4):1363. https://doi.org/10.3390/s21041363
Chicago/Turabian StyleSong, Hailuo, Ao Li, Tong Wang, and Minghui Wang. 2021. "Multimodal Deep Reinforcement Learning with Auxiliary Task for Obstacle Avoidance of Indoor Mobile Robot" Sensors 21, no. 4: 1363. https://doi.org/10.3390/s21041363
APA StyleSong, H., Li, A., Wang, T., & Wang, M. (2021). Multimodal Deep Reinforcement Learning with Auxiliary Task for Obstacle Avoidance of Indoor Mobile Robot. Sensors, 21(4), 1363. https://doi.org/10.3390/s21041363