1. Introduction
Fingerprint recognition is one of the oldest and most prevalent biometric modalities. It has shown attractive features such as high accuracy and user convenience; accordingly, it has been applied in applications such as forensics, identity control, physical access control, and mobile devices. A recent study by Juniper anticipates having 4.5 billion mobile devices using fingerprint sensors by 2030 [
1].
Unfortunately, the use of a biometric sub-system for authentication processes does not imply that the system is secured. The generic biometric scheme is vulnerable at different points starting from the sensor to the recognition score/decision [
2]. Based on those vulnerabilities, biometric security is categorized in two main areas: (a) electronic security which concerns the digital process of the captured biometric trait (b) physical security which questions whether the biometric trait presentation is performed by a bona fide (i.e., genuine user) or by an attacker. This investigation is tended to focus on the second type and propose a potential software countermeasure.
Presentation Attack (PA), informally known as spoofing attack, is defined as a suspicious presentation that aims to manipulate the biometric decision using a Presentation Attack Instrument (PAI). The definition implicitly refers to two classes of attackers (a) concealer: aims to evade being recognized as him/herself (b) impersonator: seeks to claim an identity other than himself. In both cases, the attack might be performed with the bona fide cooperation, e.g., research studies, or without the bona fide consent, e.g., identity theft.
Despite the fact that fingerprint ridge/valley patterns are unique, fingerprints have other phenomena such as perspiration which causes the moisturized skin, consequently, fingerprints leave traces at touched surfaces. By using proper methods and tools, those traces can be captured and used to duplicate a PAI in order to impersonate one’s identity. A group of forensic researchers has conducted an experiment demonstrating that fingerprint traces can be captured from problematic metal surfaces after over 26 days of deposition [
3]. The experiment involves a sophisticated method along with advanced tools, which must be considered when calculating the attack potential, but it proves the possibility of capturing latent fingerprints when proper method and tools exist (
Table 1).
In order to overcome the issue of PA, researchers have been investigating Presentation Attack Detection (PAD) mechanisms that are capable of eliminating or mitigating PAs. PA and PAD on fingerprint recognition have been widely studied in different investigations [
4,
13,
14,
15]. In our previous work [
14], we classified PAs considering the attacker’s intention, the used materials for creating the PAI, and whether a PAI contains dynamic or static information. On the other hand, different taxonomies have been proposed to classify PAD mechanisms [
15]: (a) hardware/software classification sorts the PAD mechanisms by implying the necessity of modifying the hardware design of the biometric sensor, (b) dynamic/static classification clarify whether the temporal biometric information is needed for a PAD mechanism, and (c) collateral-means/natural-phenomena classification investigate whether the PAD features are natural characteristics of the biometric trait or just collateral information.
A key observation regarding the literature of fingerprint PAD mechanisms is that most studies tend to study the static fingerprint pattern, e.g., 2-D textures and fingerprint quality, rather than fingerprint dynamic features. This can be explained by the fact that collecting dynamic datasets requires extensive time, effort, and expertise which consequently had led to limited dynamic datasets. In addition, integrating dynamic PAD algorithms into the biometric system may require higher computational power and potentially adds more load to the overall system. Section II briefly demonstrates the literature studies about dynamic fingerprint PAD and conducts an accuracy performance comparison between those mechanisms.
Based on these disadvantages, one may ask what the advantages are of analyzing fingerprint dynamics. The primary motivation for this study is that when expert attackers perform attacks, the 2-D impression of the attack presentation resembles the genuine fingerprint pattern, leading to a higher possibility that the attack will be classified as a bona fide presentation. In this context, two recent investigations were carried out to support this claim. First, it has been shown by Goicoechea [
16] that attackers with an advanced level of knowledge and expertise can perform attacks with a higher success rate when considering black box fingerprint systems (i.e., mobile devices). Secondly, Casula et al. [
17] had conducted an experiment that compares the accuracy of the most efficient state-of-the-art static PAD mechanisms considering: (1) expert attacks called “ScreenSpoof” and (2) LiveDet 2019 attacks. Their results showed that ScreenSpoof attacks decrease the full system accuracy by increasing the Impostor Attack Presentation Match Rate (IAPMR) from 8.7% to 22.8% for the ZJUT mechanism and 14.2% for the JLW mechanism.
In this paper, we propose a PAD mechanism that exploits the dynamic texture of the fingerprint as the discriminative foundation. The dynamic model was chosen because we have experimentally noticed that genuine fingerprint presentations demonstrate a unique development of the ridge/valley pattern due to natural phenomena such as elasticity and perspiration. Moreover, PAs have shown perceptual and statistical dynamic differences as shown in our previous work [
5]. Thus, five state-of-the-art dynamic texture descriptors are selected to investigate fingerprint spatiotemporal features aiming to obtain high PAD classification accuracy.
The experimental protocol and evaluation methodology have been conducted following the standard ISO/IEC 30107-3:2017—“Information technology—Biometric presentation attack detection—Part 3: Testing and reporting” [
18]. Our proposed PAD subsystem demonstrates the capability of detecting PAs while having a low proportion of misclassified bona fide presentation.
The importance of this work lies in consolidating the spatial fingerprint features of the fingerprint impression with the temporal variations by investigating fingerprint videos instead of studying static fingerprint impressions. This paper investigate three groups of spatio-temporal features: (1) local features extracted from 3-D patches, (2) local features extracted from the XY, XT, and YT planes, and (3) global features extracted from the complete fingerprint video. Our results show an accuracy improvement over the dynamic methods that combine the 2-D features of the fingerprint sequence. Moreover, it is noticed that the first group of features achieves the highest accuracy for the optical technology and the second group performs the best for the thermal technology.
The rest of this paper is structured as follows.
Section 2 presents a brief overview of the related work. In the
Section 3, we describe the framework of the proposed PAD subsystem. The experiment is characterized in
Section 4.
Section 5 reports and discusses the experimental results. Finally, we draw our conclusions in
Section 6.
3. Proposed Presentation Attack Detection Subsystem
The proposed PAD subsystem is designed in a fashion that leverages the dynamic information provided during the fingerprint presentation (
Figure 1). Thus, the proposed feature extraction approach suggests exploiting the spatio-temporal features to achieve a robust description that characterizes the complete interaction between the fingerprint and the sensor’s surface. Toward this end, we propose three modes to investigate fingerprint dynamics in frequency and time domains. Five feature extractors are therefore selected to achieve a description that discriminates genuine from attack presentations. By feeding the extracted features into a pre-trained classifier, the PAD subsystem finally decides whether the input video is a bona fide or attack presentation. The following subsections expound the processing modes, feature extractors, and classification method.
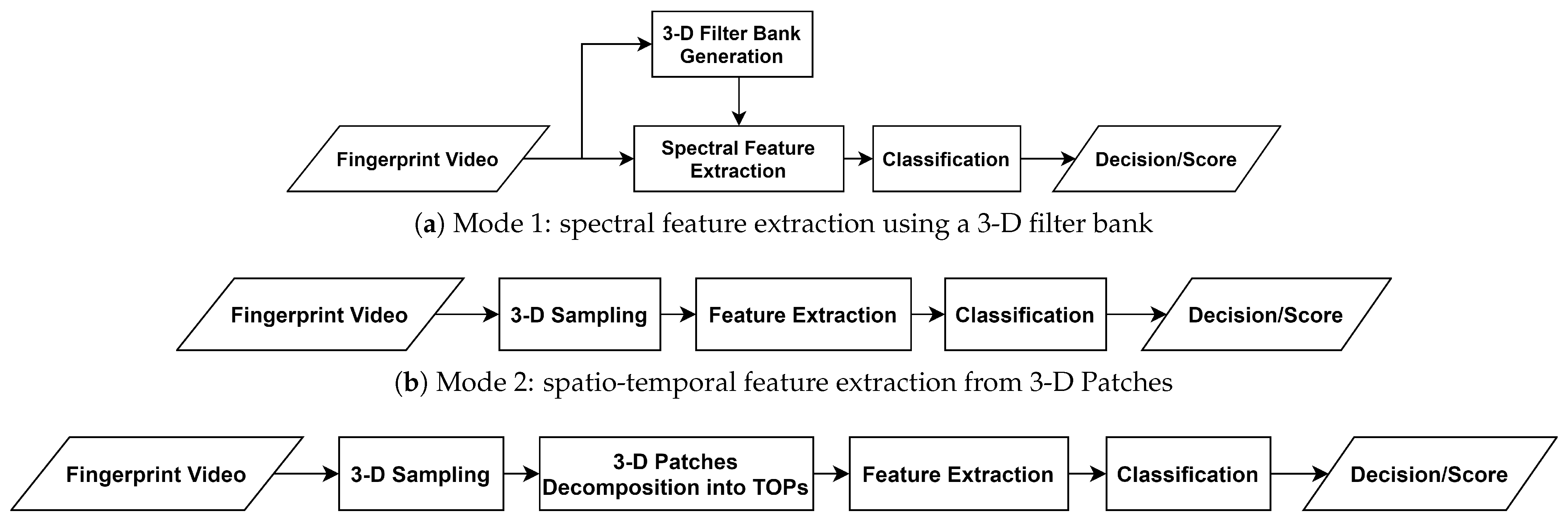
3.1. Feature Extraction Modes
In order to investigate different aspects of fingerprint dynamics, three feature extraction modes are elaborated in this subsection. The first mode investigates dynamic fingerprint features in the frequency domain whereas a 3-D filter bank is utilized to extract spectral features in a diverse range of scales and orientations. As the video’s frequency components effectively represent the static fingerprint pattern and the temporal variations, it is expected that the differences between natural skin and attack species produce frequency components in different planes. Hence, this mode captures the spatio-temporal information by filtering the video frequency spectrum in different orientations and center frequencies.
The second mode samples the fingerprint video on space-time domain into small 3-D patches, extracts the spatio-temporal features from those samples, and provides the description as the frequency distribution of the extracted features. This mode has two main interesting features, primarily, it has the capacity to define local features in a stack of XY patches so that any anomalous formation in the fingerprint video is detected. Secondly, it provides the possibility of processing the 3-D patches in space-time and/or frequency domains.
The third mode resembles the second mode, a small brick is added after the sampling to decompose the 3-D patches into the Three Orthogonal Planes (TOP) XY, XT, and YT planes. Over the advantages of the second mode, the third mode had proved significantly reduced complexity for the adopted feature extractor while preserving a high accuracy when the local binary patterns are extracted [
20].
Figure 2 illustrates these modes and
Figure 3 shows an example of a fingerprint video and its sampling into 3-D patches and TOPs.
3.2. Feature Extractors
The feature extractors were selected in order to comply with the proposed modes, moreover, to analyze the features in spatio-temporal and spectral domains.
Table 2 summarizes the proposed scenarios with the corresponding dynamic feature extractors and the following subsections reviews these algorithms.
3.2.1. GIST 3-D Descriptor
GIST 3-D is a global spatio-temporal descriptor that had been proposed for video classification problems. The method integrates the motion information and the scene structure in one feature vector without applying background subtraction or salient point detection at the input video, achieving performance better than SoA dynamic descriptors. In our experiment, the GIST 3-D works as follows: first, the frequency spectrum of the complete fingerprint video is achieved by applying 3-D Discrete Fourier Transform; as computed by Equation (1).
Then, a bank of narrow band 3-D Gabor filters
is generated and each 3-D filter
is applied to the frequency spectrum as given by Equation (2). The filter bank is composed by 3-D filters with different orientations and scales, which allows capturing the components at various intervals of the video’s frequency spectrum.
After taking the inverse 3-D DFT as in Equation (3) for each filter in the bank, the output volume is quantized in fixed sub-volumes and the sum of each sub-volume is taken, thus, a feature vector is obtained to represent the video description.
3.2.2. Volume Local Binary Patterns
The basic Local Binary Patterns method was extended to VLBP in order to describe the dynamic texture in a sequence of successive images [
12]. The algorithm starts by sampling the gray level volume input into small 3D samples considering a certain number of local neighbors (P), time interval (L), and radius (R) in x-y plane, then every neighbor pixel in the 3D sample is given a binary value based on a comparison with the center pixel of the sample. Finally, each binary value is multiplied by a corresponding weight and all results are summed to form the sample’s VLBP
L,P,R code; Equation (4). The distribution of the codes is used to compose the dynamic texture feature vector.
where
and
correspond to the gray values of the central pixel and neighbours in the 3-D sample.
The authors in [
20] also proposed two additional modes for the method: (1) rotation-invariant VLBP mode (
) which is based on the assumption that volume data rotates only around t-axis, (2) uniform VLBP mode (
), where the VLBP histogram consists of uniform patterns (i.e., patterns contain at most 2 bitwise transitions between 0 and 1) and sums up all non-uniform patterns in 1 bin.
3.2.3. Volume Local Phase Quantizer
The VLPQ method [
25] is an extension to the local phase quantization which was originally proposed as an image descriptor [
26]. VLPQ essentially encodes local Fourier transform’s phase information at low-frequency points. The method consists of three steps: (1) local Fourier transform is applied, using Short Term Fourier Transform (STFT), over
neighborhood N
x centered at each pixel position x using 1-D convolutions for each dimension, (2) the dimensionality of the achieved data is reduced using Principal Component Analysis (PCA), and (3) a scalar quantization is applied to produce an integer value. The histogram of the binary codewords is computed to form the VLPQ
M,N feature vector.
3.2.4. Local Binary Patterns from Three Orthogonal Planes
Although VLBP method is interesting, it suffers from two major issues. First, initializing the algorithm with a large number of neighbors P results in a very large number of patterns in the VLBP feature vector, limiting the method’s applicability. Second, choosing a time radius L larger than 1 excludes the frames with a time variance less than L.
To address these issues, VLBP-TOP
L,P,R method had been proposed in [
20] to concatenate the local binary patterns on the three orthogonal planes: XY-LBP, XT-LBP, and YT-LBP. With this approach, spatial patterns are obtained from XY plane and space-time transitions information is attained from XT and YT planes. As a result, the number of patterns on the feature vector is significantly reduced from
to
which allows considering a large number of neighbors with reduced computational cost, moreover, including neighbor pixels from frames with a time variance less than L, when L is larger than 1.
3.2.5. Local Phase Quantizer from Three Orthogonal Planes
LPQ-TOP
Rx,Ry,Rz is implemented by calculating LPQ histograms from three orthogonal planes similar to LBP-TOP. The histograms are normalized and concatenated to form the LPQ-TOP descriptor [
25].
3.3. PAD Classification
Through our experiment, we have tested different classification algorithms, specifically: Classification Trees, Discriminant Analysis, Naive Bayes, Nearest Neighbors, SVM Classification, and Classification Ensembles. SVM classification has been chosen due to its highest accuracy, while the other classification methods are not considered in this paper. Moreover, we have examined the impact of changing the SVM kernel whereas a second polynomial kernel demonstrated the best accuracy. A binary classification scheme has been utilized to evaluate the PAD subsystem performance and to assess the influence of specific PAI species on system security and usability.
4. Experiment
To evaluate the performance of the proposed PAD subsystem, we use the dynamic dataset presented in [
5]. In the initial stage of the experiment, a volume segmentation is applied to the database. This sets the input fingerprint videos to the feature extraction step. At this point, we utilize the scheme in
Figure 2 to extract the features and train the SVM model. As soon as these steps have been carried out, the testing process is performed, and the PAD subsystem accuracy is assessed.
4.1. Database Description
The database had been collected to capture genuine and cooperative-attack presentations as videos using optical and thermal sensors. The database comprises 66 genuine fingerprints (thumb, index middle) taken from both hands of 11 independent subjects, and attacks using seven PAI species. A definite characterization of the protocol applied to produce this database is introduced in [
5].
Table 3 summarizes the 3564 bona fide and attack presentations in the database with the corresponding presentation type.
The Common Criteria (CC) defines the attack potential as a function of expertise, resources, and motivation of the attacker. Reporting those aspects in biometric databases is therefore indispensable to the coherence of the PAD evaluation. We thus report that all attacks were carried out by one attacker, he has an advanced knowledge in biometric systems and had proven practical experience in attacking fingerprint sensors embedded in smartphones. Furthermore, the attacker obtained all required materials from local shops and online stores for a very low cost. Accordingly, the attacker has prepared each PAI species with a particular recipe and determined that a PAI can be used multiple times for all species except the Play-Doh instrument where each attack requires a new PAI.
4.2. Volume Segmentation
The dataset was collected using optical and thermal sensors where each sensor acquires images with different characteristics. Taking into account the sensors’ features and database characteristics in
Table 4, the following subsections illustrate the adopted segmentation techniques.
4.2.1. Thermal Subset
The thermal sensor’s SDK provides a capturing mode that acquires only the central region of the sensor sized pixels. Thus, the acquired sequence is already segmented as a stack of 7 frames sized .
4.2.2. Optical Subset
Since our study analyzes the formation of fingerprints, we have implemented a simple volume segmentation tool that creates the boundaries of the entire Interaction between a fingerprint and the sensor and crop the 3-D volume; an example is shown in
Figure 4. Then, we have applied the segmentation to the entire subset of the optical sensor before feature extraction.
4.3. Experimental Protocol
Each sensor subset is evaluated independently due to the differences in the sensors’ technology, image size, resolution, noise, and capturing rate which produce different video characteristics. For a robust accuracy estimation, we have set a holdout validation scheme where the database is divided into training (55%) and testing (45%) sets. The database division into training/testing is randomized by independent subjects, meaning that presentations of each independent subject is either used for training or testing.
Since the work is focused on the PAD subsystem, we report the error rates following the recommendations of ISO/IEC 30107-3:2017 standard on PAD testing and reporting. The PAD subsystem evaluation determines the system’s capability of detecting attacks taking into account the measurement of false detections.
The following metrics are used in the results to evaluate PAD mechanisms:
Attack Presentation Classification Error Rate (APCER) presents the proportion of attack presentations incorrectly classified as bona fide presentations. Besides, APCERPAIS is outlined to denote the misclassified attack proportion for a given PAI species;
Bona Fide Presentation Classification Error Rate (BPCER) presents the proportion of bona fide presentations incorrectly classified as attack presentations;
Tradeoff Equal Error Rate (TEER) is when APCER and BPCER are equal. We introduce TEER, which is not defined in the standards, to compare with SoA mechanisms that were reported only in terms of TEER, and moreover to prevent the confusion with the conventional EER.
The use of TEER to compare different PAD mechanisms is not recommended because it shows the systems BPCER at different APCER points. It is preferable to evaluate the PAD mechanism in terms of BPCER at fixed APCER, for instance, reporting a PAD mechanism’s BPCER when APCER is 5% is standarized as BPCER20. Furthermore, showing the DET curves [
27] provides a precise description of the relationship between APCER and BPCER at different thresholds, allowing better comparison between different mechanisms.
6. Summary and Conclusions
In this paper, we present a novel fingerprint PAD approach in the dynamic scenario. We propose three modes to investigate the spatio-temporal and spectral features in fingerprint videos. We utilize five dynamic feature extractors to leverage the fingerprint features in space and time, then a binary SVM is used for classifying bona fide and attack presentations. The PAD mechanism is assessed using a database that was collected using optical and thermal sensors and consists of 792 bona fide presentations taken from 66 genuine fingerprints and 2772 attack presentations performed by an attacker using 7 PAI species.
The significance of the proposed approach is that it integrates the effect of all natural fingerprint phenomena from the acquired video using dynamic descriptors. For instance, the intensity of the fingerprint impression varies through the time series images due to the combination of: the pressure caused by the internal finger bone, the skin moistness caused by perspiration, and the sensitivity of the sensing technology to the human skin. Moreover, we noticed that the formation of the fingerprint pattern in the image sequence shows a homogeneous pattern development which can be mainly explained by the 3-D shape of the fingertip and the fingerprint elasticity. Additionally, the spatio-temporal methods have the capacity to detect anomalous patterns caused by the various PAI species. For example, the development of the contours of the fingerprint impression for some attack species such as gelatin and latex show rough edges in the early frames of the presentation sequence, consequently, enhance the PAD subsystem’s accuracy. Based on these observation we conclude that dynamic acquisition provides more information in comparison with analysing static fingerprint images.
The local spatio-temporal features were extracted using VLBP and LBP-TOP. On the other hand, spectral features were explored locally using VLPQ and LPQ-TOP, and globally using GIST 3-D. These feature extractors are evaluated for a thermal and an optical sensors showing an advantage for the latter due to its acquisition characteristics.
The experiment points out the importance of studying each sensing technology apart through comparing (i) the accuracy of the different feature extractors, and (ii) the potential of the attack species on the two sensors. The best accuracy is obtained by LBP-TOP for the optical sensor with 1.11 BPCER20, and by LPQ-TOP for the thermal sensor with 3.89 BPCER20.
These results would seem to suggest that our approach has an excellent capability of eliminating/mitigating PAs in different sensing technologies. Further, a comparison with SoA mechanisms shows that our method provides competitive error rates. However, given the small number of participants in the database, caution must be taken.
Our results are promising and should be validated by a larger database with additional attack species and sensing technologies. We recommend that further research should concentrate on fingerprint specific dynamic features such as the variation of fingerprint quality during the presentation.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}