
Study on the Optimization of Hyperspectral Characteristic Bands Combined with Monitoring and Visualization of Pepper Leaf SPAD Value


Abstract
:
1. Introduction
2. Materials and Methods
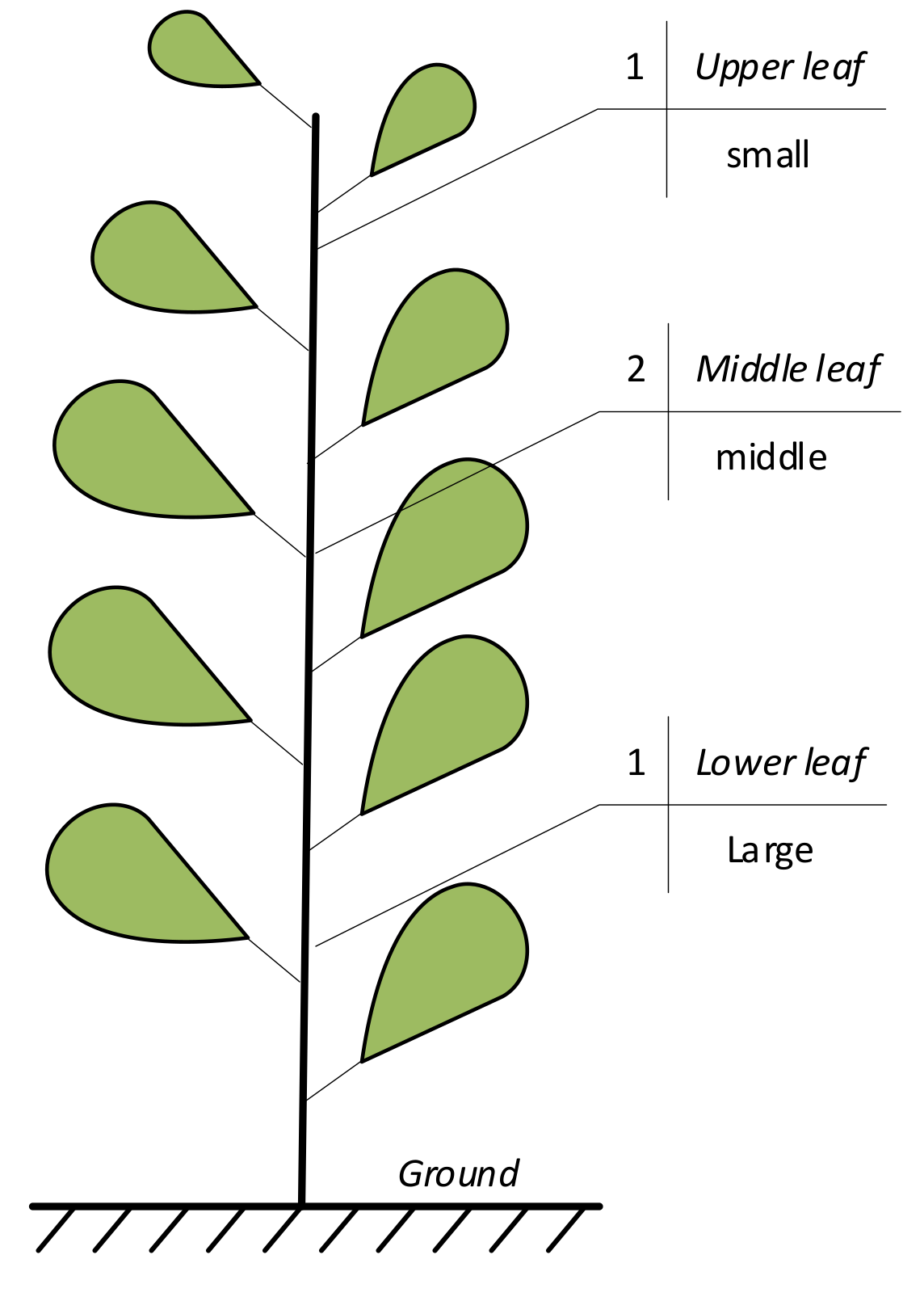
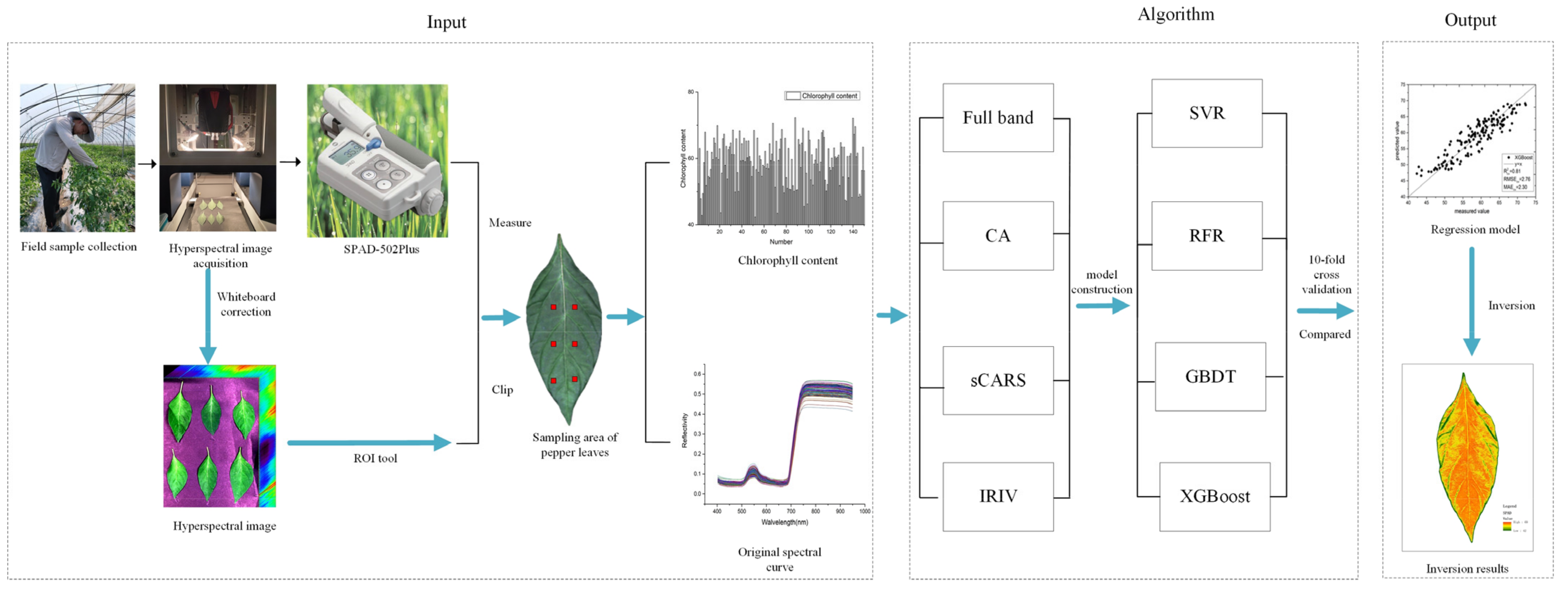
2.1. Sample Collection
2.2. Chlorophyll Determination
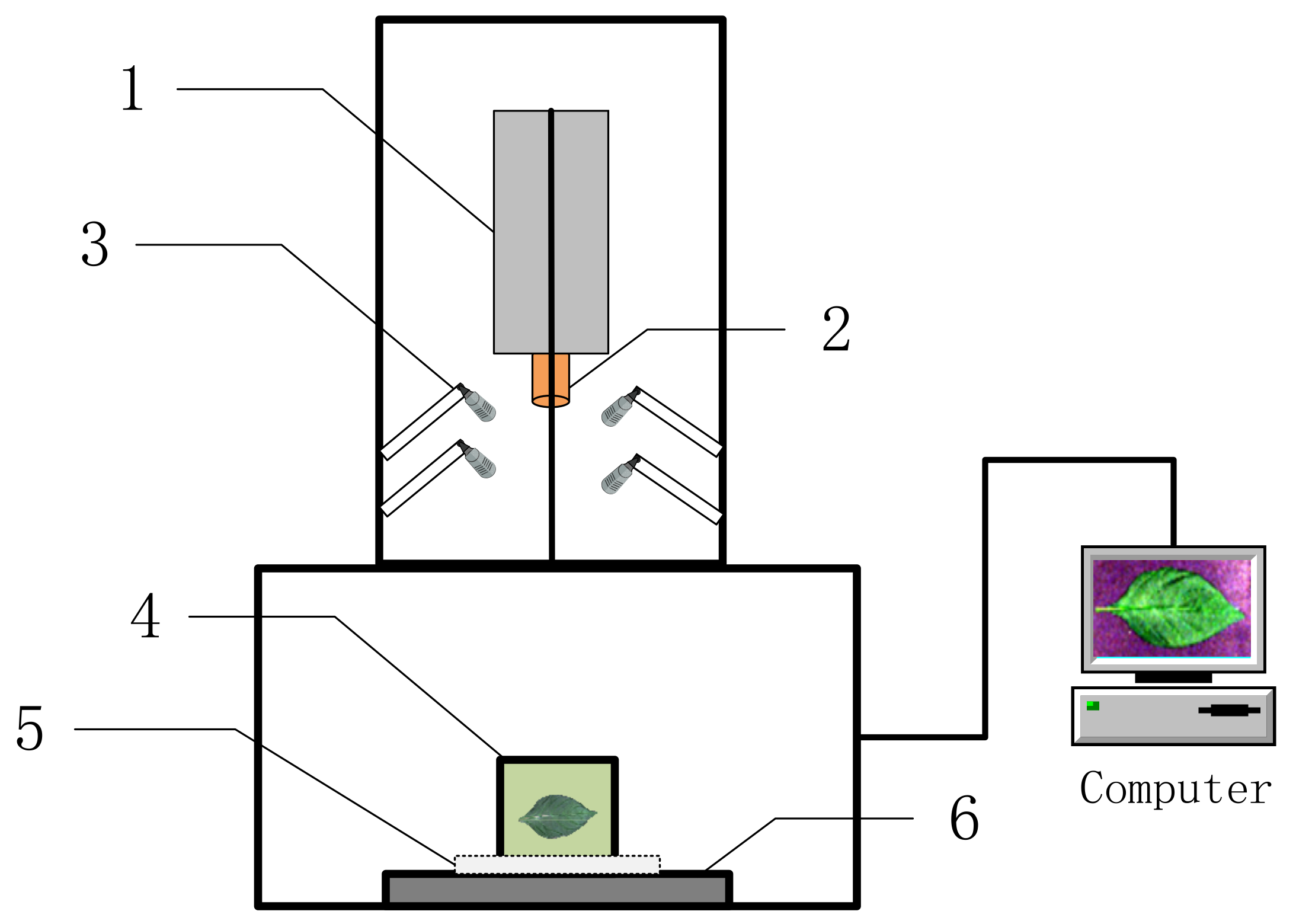
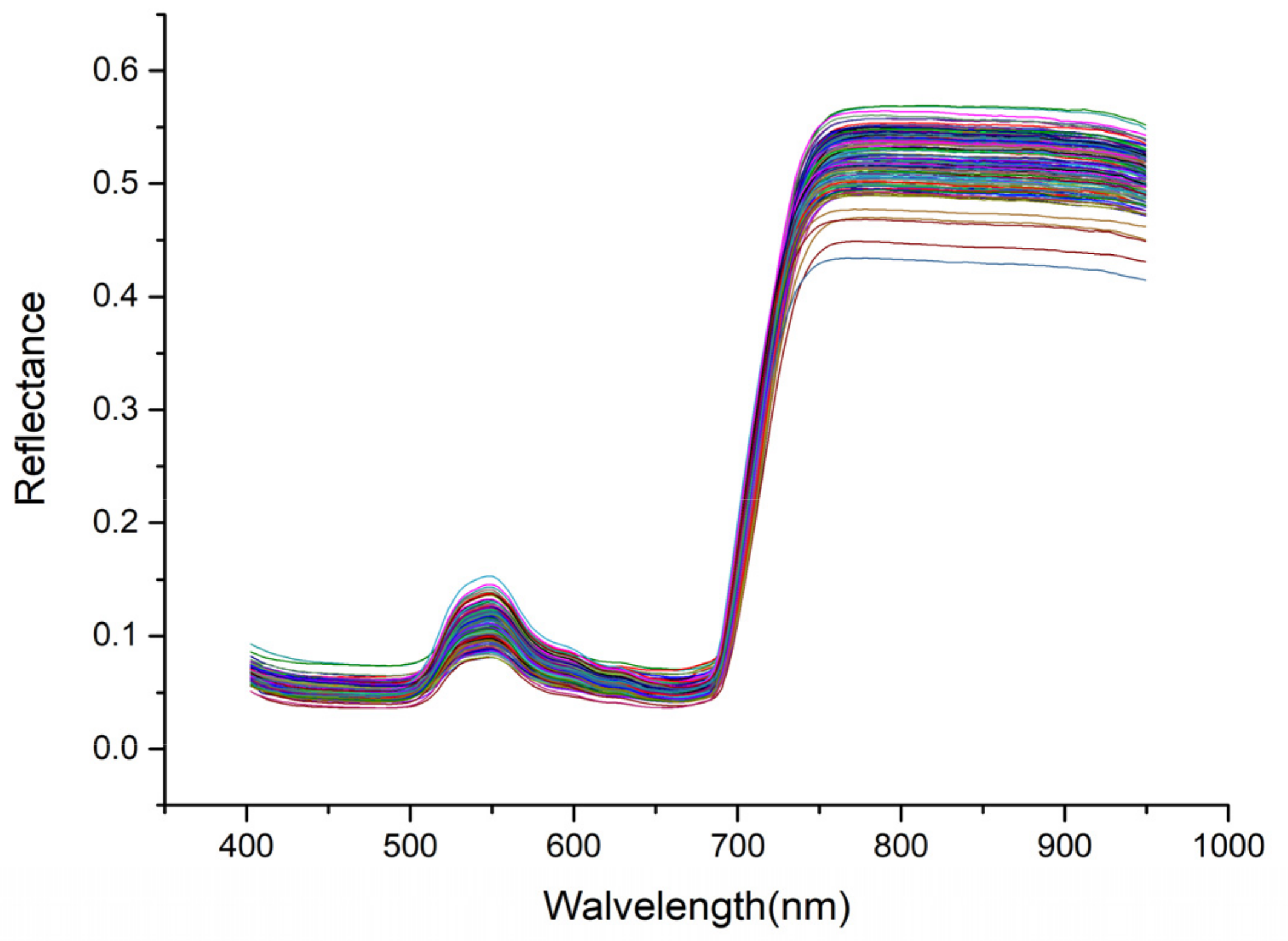
2.3. Hyperspectral Data Collection
2.4. Spectral Extraction
2.5. Research Methods
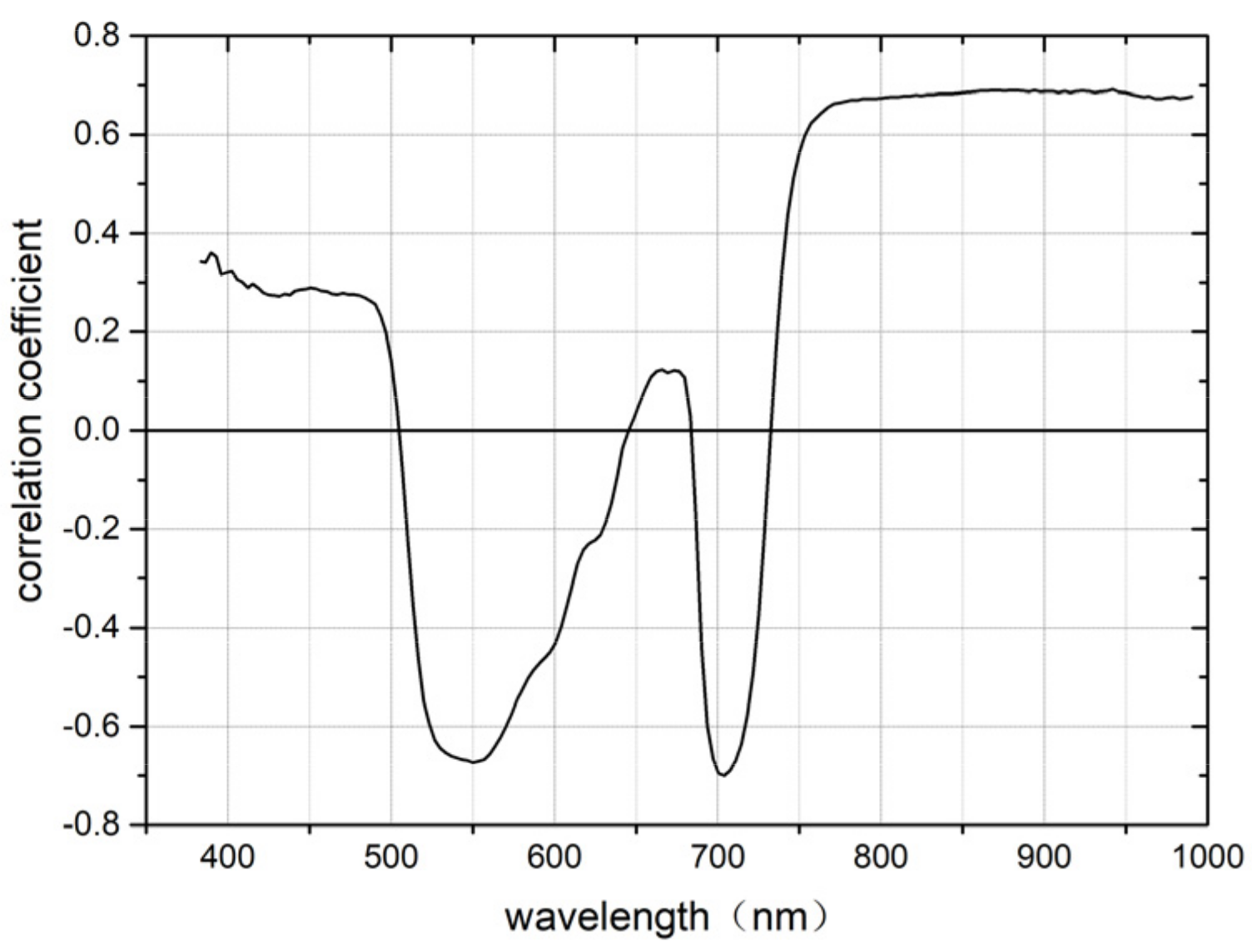
2.5.1. Correlation Coefficient Method
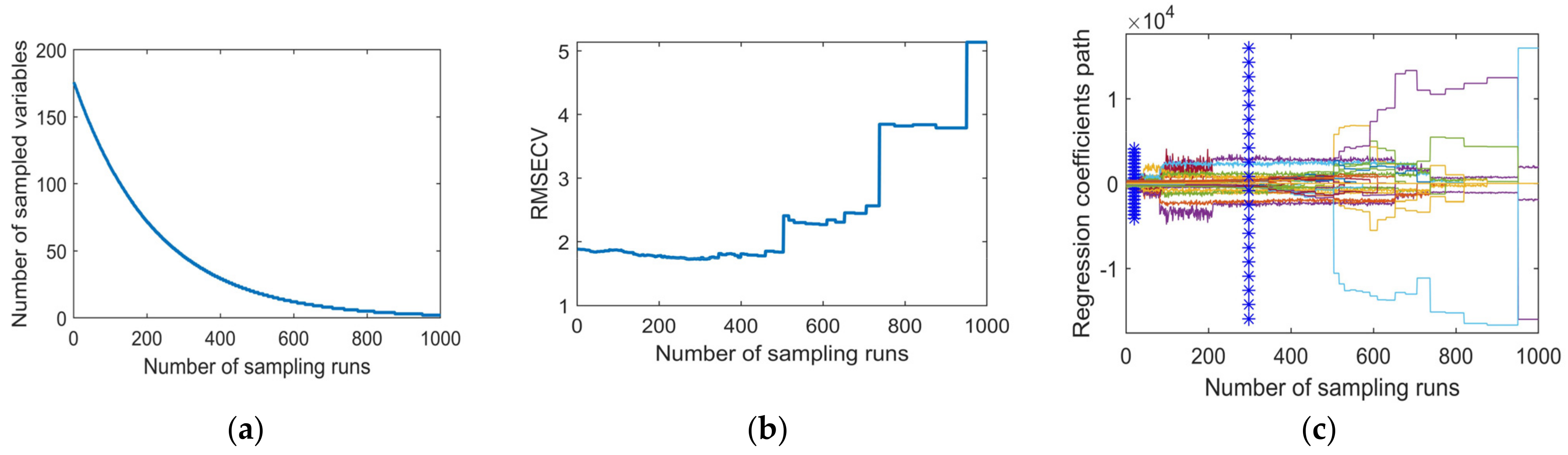
2.5.2. Stability Competitive Adaptive Reweighted Sampling (sCARS)
- Select N wavelength subsets from N Monte Carlo sampling [19] runs in an iterative and competitive manner. In each sampling process, a fixed proportion of samples is randomly selected to establish a calibration model.
- Perform a two-step process to select characteristic wavelengths: use an exponential decrease function [17] for wavelength selection and use adaptive reweighted sampling to achieve competitive wavelength selection.
- Use cross-validation [20] to select the subset with the smallest cross-validation root mean square error (RMSECV).
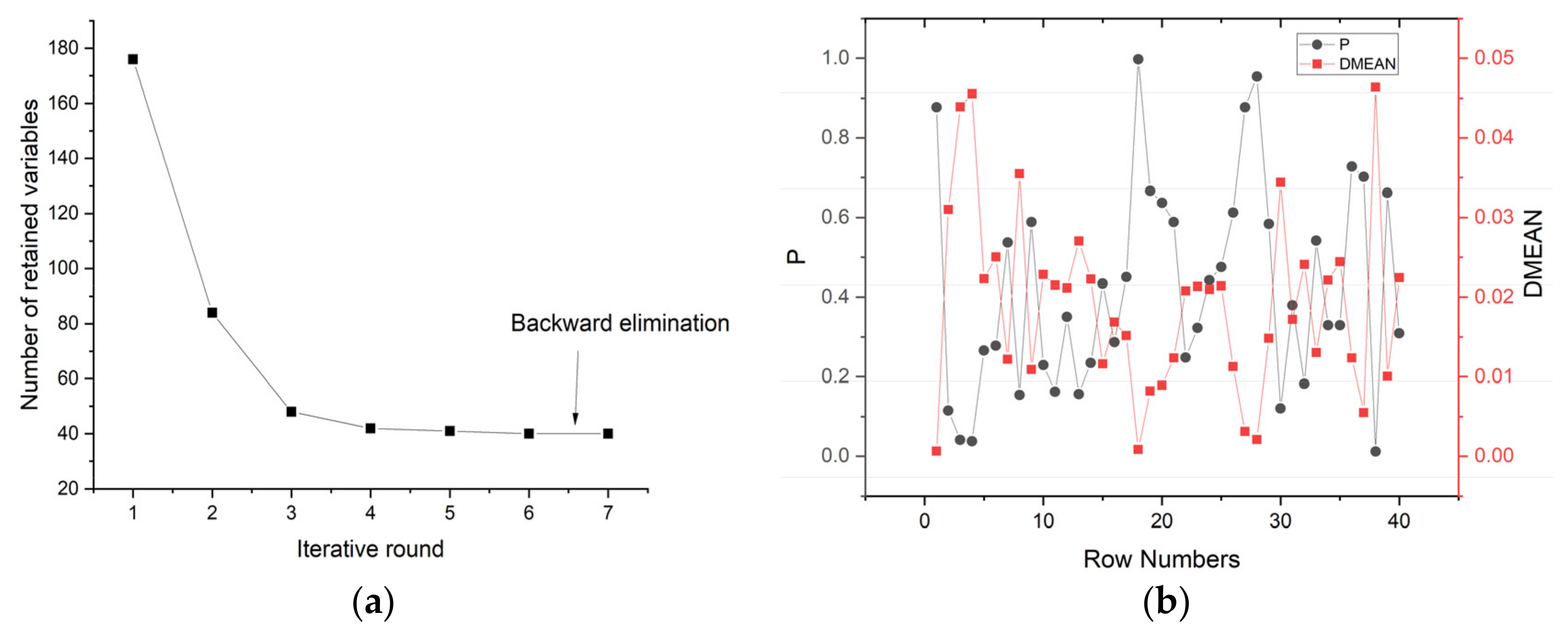
2.5.3. Iteratively Retaining Informative Variables
2.5.4. Partial Least-Squares Regression
2.5.5. Extreme Gradient Boosting (XGBoost)
2.5.6. Random Forest Regression (RFR)
2.5.7. Gradient Boosting Decision Tree (GBDT)
2.6. Accuracy Evaluation
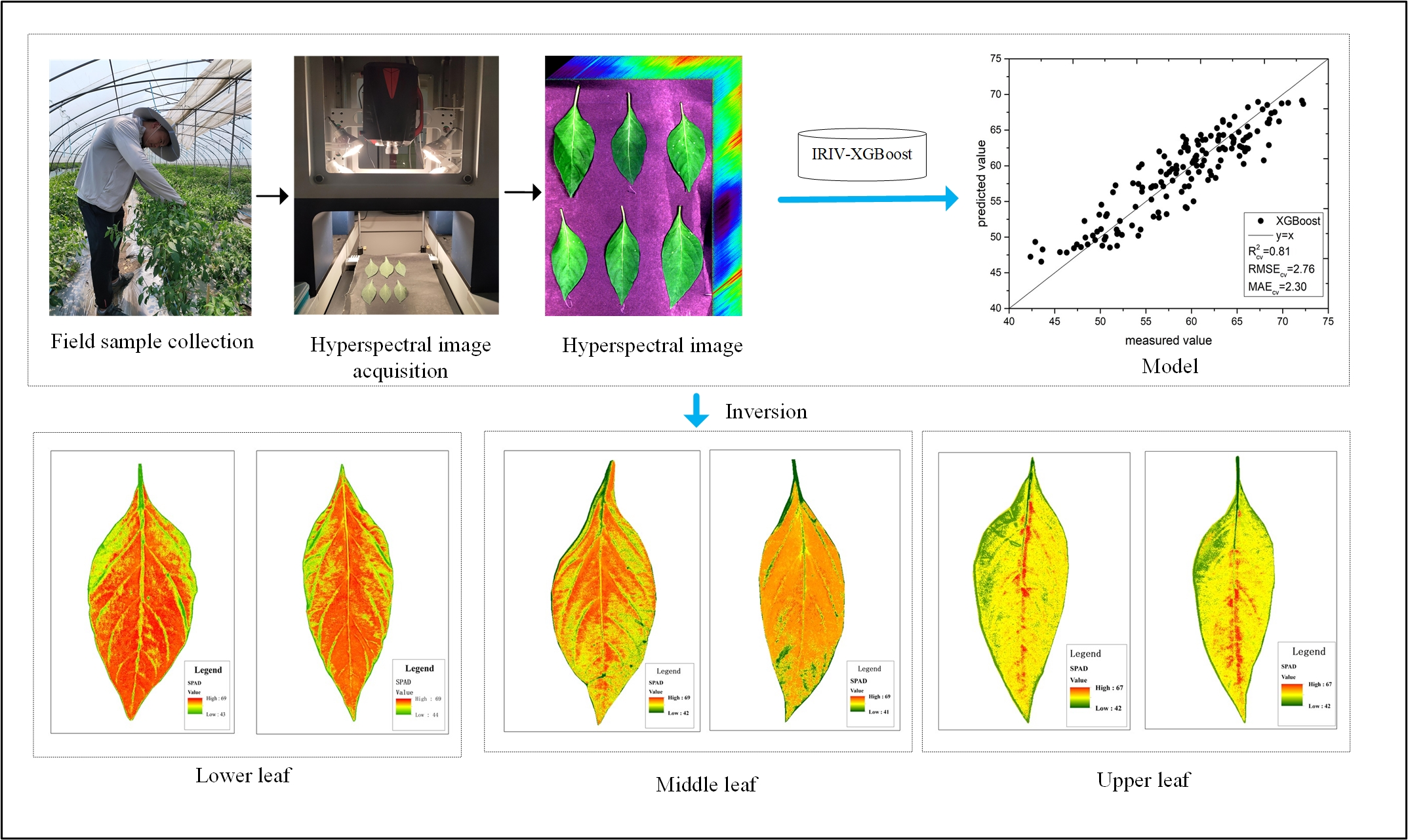
2.7. Technical Roadmap
3. Results
3.1. Selection of Characteristic Band Based on CA Algorithm
3.2. Selection of Characteristic Band Based on SCARS Algorithm
3.3. Selection of Characteristic Band Based on IRIV Algorithm
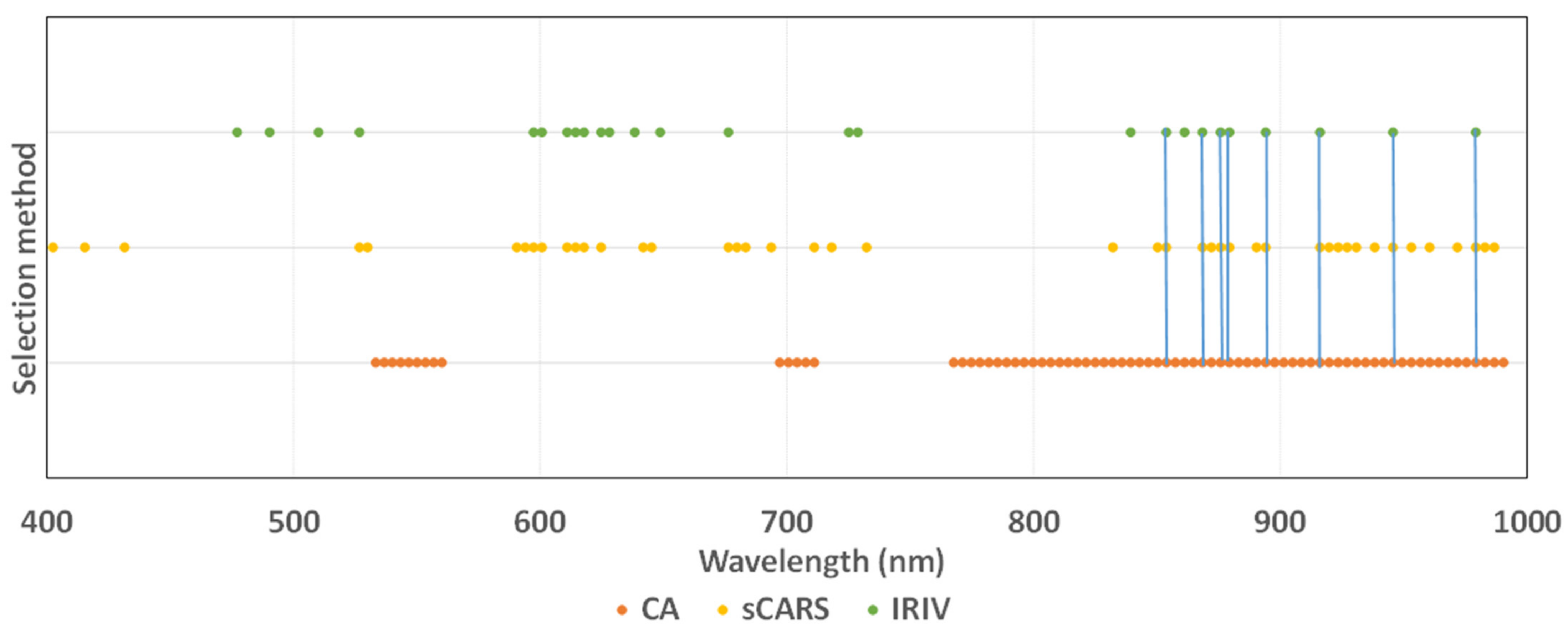
3.4. Screening Results
3.5. Optimal Algorithm Selection
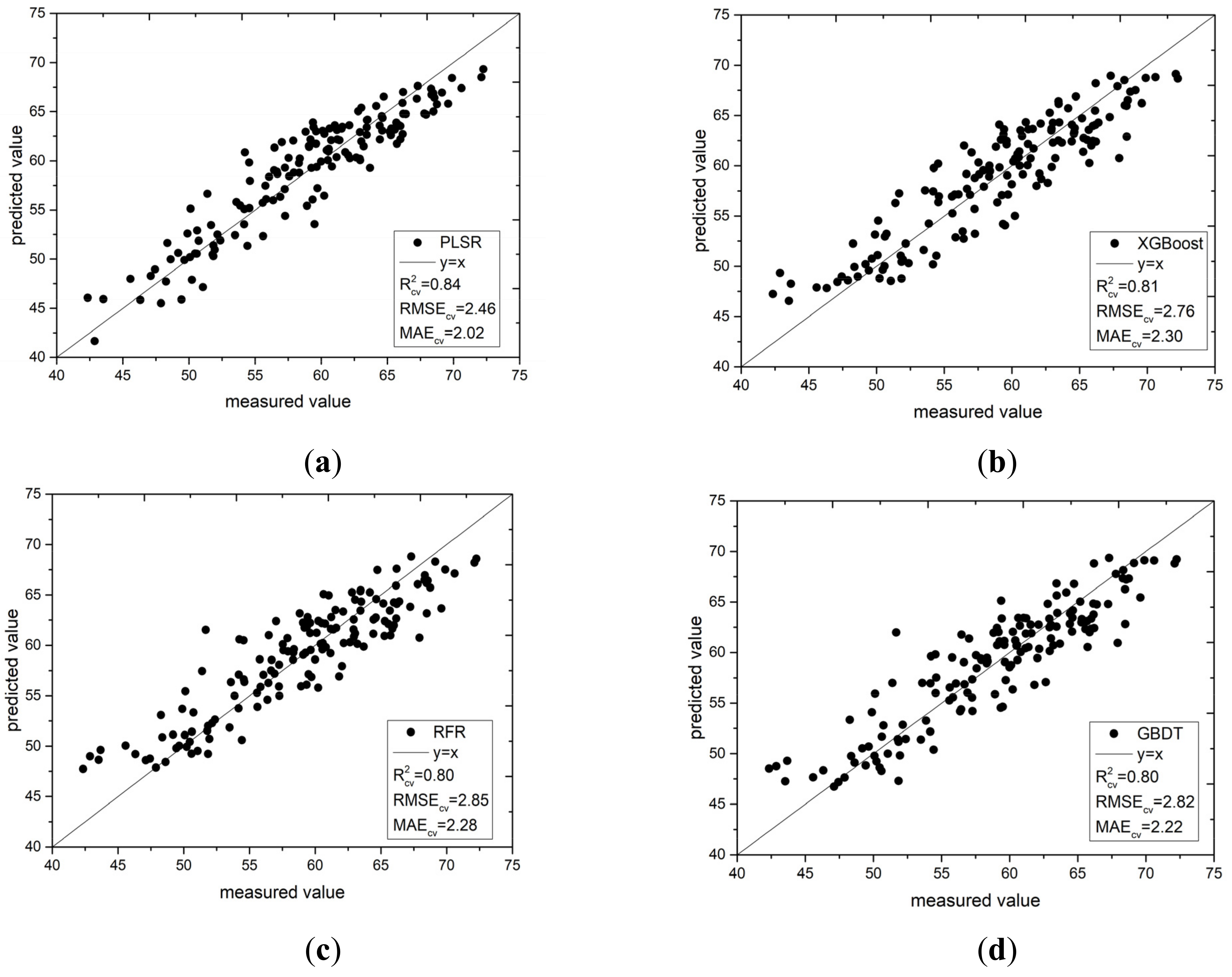
3.5.1. Accuracy Comparison of Different Methods
3.5.2. Model Construction Based on the Bands selected by the IRIV Algorithm
3.6. Chlorophyll Distribution of Pepper Leaves
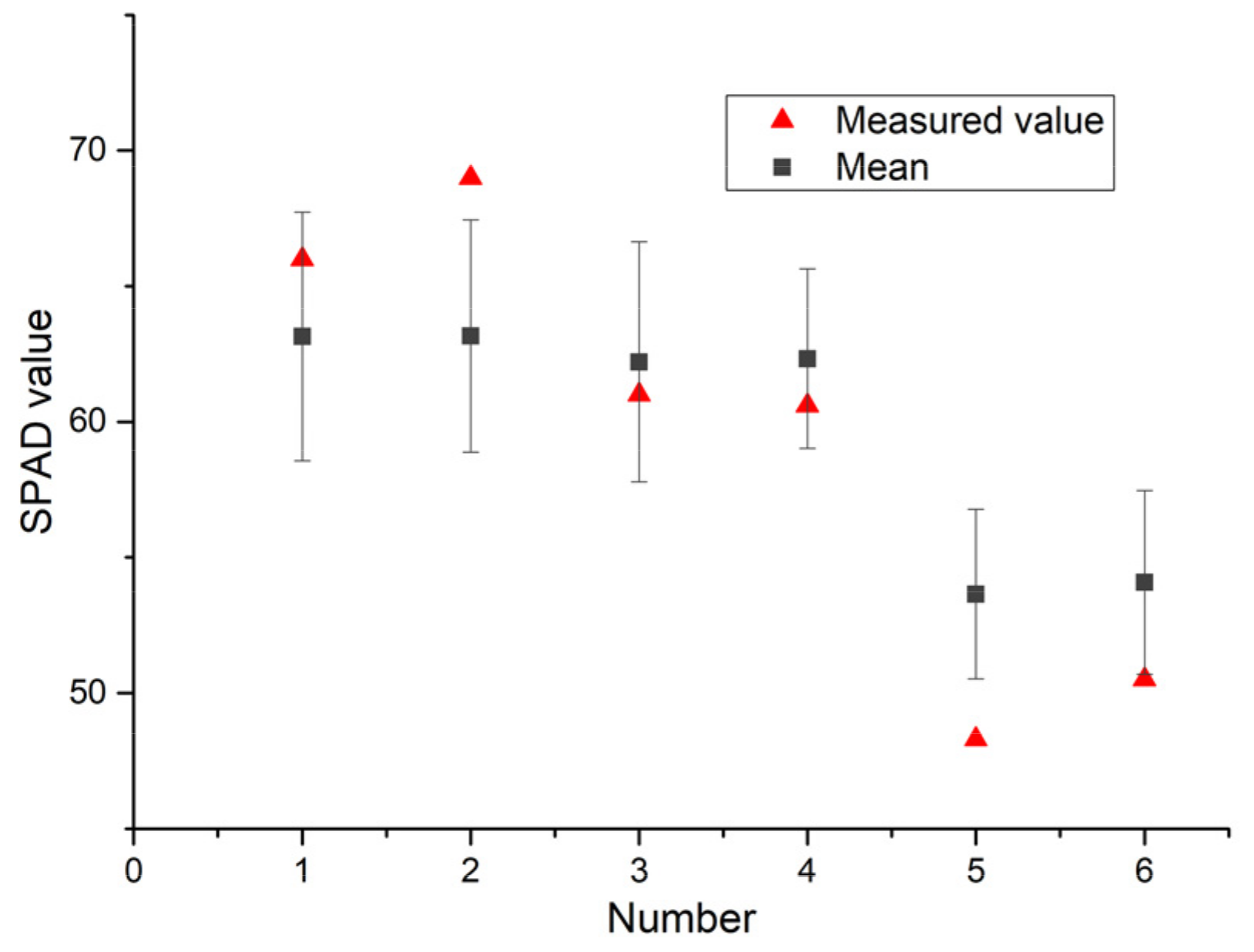
3.7. Statistical Summary Based on the IRIV-XGBoost Algorithm
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dordas, C. Nitrogen Nutrition Index and Leaf Chlorophyll Concentration and its relationship with Nitrogen Use Efficiency in Barley (Hordeum vulgare L.). J. Plant Nutr. 2017, 40, 1190–1203. [Google Scholar]
- Ata-Ul-Karim, S.T.; Cao, Q.; Zhu, Y.; Tang, L.; Rehmani, M.I.A.; Cao, W. Non-destructive Assessment of Plant Nitrogen Parameters Using Leaf Chlorophyll Measurements in Rice. Front. Plant Sci. 2016, 7, 1829. [Google Scholar]
- Liu, B.; Shen, W.; Yue, Y.M.; Li, R.; Tong, Q.; Zhang, B. Combining spatial and spectral information to estimate chlorophyll contents of crop leaves with a field imaging spectroscopy system. Precis. Agric. 2017, 18, 491–506. [Google Scholar]
- Manley, M. Near-infrared spectroscopy and hyperspectral imaging: Non-destructive analysis of biological materials. Chem. Soc. Rev. 2014, 43, 8200. [Google Scholar]
- Sun, H.; Zheng, T.; Liu, N.; Cheng, M.; Li, M.; Zhang, Q. Vertical distribution of chlorophyll in potato plants based on hyperspectral imaging. Trans. Chin. Soc. Agric. Eng. 2018, 34, 149–156. [Google Scholar]
- Liu, D.; Sun, D.W.; Zeng, X.A. Recent Advances in Wavelength Selection Techniques for Hyperspectral Image Processing in the Food Industry. Food Bioprocess Technol. 2014, 7, 307–323. [Google Scholar]
- Ji-Yong, S.; Xiao-Bo, Z.; Jie-Wen, Z.; Kai-Liang, W. Nondestructive diagnostics of nitrogen deficiency by cucumber leaf chlorophyll distribution map based on near infrared hyperspectral imaging. Sci. Horticult. 2012, 138, 190–197. [Google Scholar]
- Zhao, T.; Nakano, A.; Iwaski, Y.; Umeda, H. Application of Hyperspectral Imaging for Assessment of Tomato Leaf Water Status in Plant Factories. Appl. Sci. 2020, 10, 4665. [Google Scholar]
- Daughtry, C.; Walthall, C.L.; Kim, M.S.; Colstoun, E.; Iii, M.M. Estimating Corn Leaf Chlorophyll Concentration from Leaf and Canopy Reflectance. Remote Sens. Environ. 2000, 74, 229–239. [Google Scholar]
- Wu, C.; Zheng, N.; Tang, Q.; Huang, W. Estimating chlorophyll content from hyperspectral vegetation indices: Modeling and validation. Agric. For. Meteorol. 2008, 148, 1230–1241. [Google Scholar]
- Yu, K.Q.; Zhao, Y.R.; Li, X.L.; Shao, Y.N.; Fei, L.; Yong, H. Hyperspectral Imaging for Mapping of Total Nitrogen Spatial Distribution in Pepper Plant. PLoS ONE 2014, 9, e116205. [Google Scholar]
- Liu, Y.; Fan, M. Application Feasibility of SPAD-502 in Diagnosis of Potato Nitrogen Nutrient Status. Chin. Potato J. 2012, 26, 45–48. [Google Scholar]
- Coste, S.; Baraloto, C.; Leroy, C.; Marcon, É.; Renaud, A.; Richardson, A.D.; Roggy, J.C.; Schimann, H.; Uddling, J.; Hérault, B. Assessing foliar chlorophyll contents with the SPAD-502 chlorophyll meter: A calibration test with thirteen tree species of tropical rainforest in French Guiana. Ann. For. Sci. 2010, 67, 607. [Google Scholar]
- Nau, J.; Prokopová, J.; Ebíek, J.; Pundová, M. SPAD chlorophyll meter reading can be pronouncedly affected by chloroplast movement. Photosynth. Res. 2010, 105, 265–271. [Google Scholar]
- Wang, D.; Aixia, S.U.; Liu, W. Trend Analysis of Vegetation Cover Changes Based on Spearman Rank Correlation Coefficient. J. Appl. Sci. 2019, 37, 519–528. [Google Scholar]
- Amarkhil, Q.; Elwakil, E.; Hubbard, B. A Meta-Analysis of Critical Causes of Project Delay Using Spearman’s Rank and Relative Importance Index Integrated Approach. Can. J. Civil. Eng. 2020, 48, 1498–1507. [Google Scholar]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar]
- Liu, G.H.; Xia, R.S.; Jiang, H.; Mei, C.-L.; Huanng, Y.-H. A Wavelength Selection Approach of Near Infrared Spectra Based on SCARS Strategy and Its Application. Spectrosc. Spectr. Anal. 2014, 34, 2094–2097. [Google Scholar]
- Holmes, E.W.; Kahn, S.E.; Molnar, P.A.; Bermes, E.W. Verification of reference ranges by using a Monte Carlo sampling technique. Clin. Chem. 2020, 40, 2216–2222. [Google Scholar]
- Guo, L.N.; Fan, G.S. Support Vector Machines for Surface Soil Density Prediction based on Grid Search and Cross Validation. Chin. J. Soil Sci. 2018, 49, 512–518. [Google Scholar]
- Zhang, H.; Wang, Y.; Liu, C.; Jiang, H. Influence of surfactant CTAB on the electrochemical performance of manganese dioxide used as supercapacitor electrode material. J. Alloys Compd. 2012, 517, 8. [Google Scholar]
- Yun, Y.H.; Wang, W.; Tan, M.; Liang, Y.; Li, H.; Cao, D.; Lu, H.; Xu, Q. A strategy that iteratively retains informative variables for selecting optimal variable subset in multivariate calibration. Anal. Chim. Acta 2014, 807, 36–43. [Google Scholar]
- Zhang, H.; Wang, H.; Dai, Z.; Chen, M.S.; Yuan, Z. Improving accuracy for cancer classification with a new algorithm for genes selection. BMC Bioinform. 2012, 13, 298. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar]
- Nawar, S.; Buddenbaum, H.; Hill, J.; Kozak, J. Modeling and Mapping of Soil Salinity with Reflectance Spectroscopy and Landsat Data Using Two Quantitative Methods (PLSR and MARS). Remote Sens. 2014, 6, 10813–10834. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, Y.; Wang, M.; Zhao, Y.; Li, J. SPA-Based Methods for the Quantitative Estimation of the Soil Salt Content in Saline-Alkali Land from Field Spectroscopy Data: A Case Study from the Yellow River Irrigation Regions. Remote Sens. 2019, 11, 967. [Google Scholar]
- Weng, Y.; Qi, H.; Fang, H. PLSR-Based Hyperspectral Remote Sensing Retrieval of Soil Salinity of Chaka-Gonghe Basin in Qinghai Province. Acta Pedol. Sin. 2010, 47, 1255–1263. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Jia, Y.; Jin, S.; Savi, P.; Gao, Y.; Tang, J.; Chen, Y.; Li, W. GNSS-R Soil Moisture Retrieval Based on a XGboost Machine Learning Aided Method: Performance and Validation. Remote Sens. 2019, 11, 1655. [Google Scholar]
- Loggenberg, K.; Strever, A.; Greyling, B.; Poona, N. Modelling Water Stress in a Shiraz Vineyard Using Hyperspectral Imaging and Machine Learning. Remote Sens. 2018, 10, 202. [Google Scholar]
- Tong, Y.; Lu, K.; Yang, Y.; Li, J.; Qian, J. Can Natural Language Processing Help Differentiate Inflammatory Intestinal Diseases in China? Models Applying Random Forest and Convolutional Neural Network Approaches. BMC 2020, 20, 248. [Google Scholar]
- Liu, L.; Ji, M.; Dong, Y.; Zhang, R.; Buchroithner, M. Quantitative Retrieval of Organic Soil Properties from Visible Near-Infrared Shortwave Infrared (Vis-NIR-SWIR) Spectroscopy Using Fractal-Based Feature Extraction. Remote Sens. 2016, 8, 1035. [Google Scholar]
- Jin, X.; Zhu, X.; Li, S.; Wang, W.; Qi, H. Predicting Soil Available Phosphorus by Hyperspectral Regression Method Based on Gradient Boosting Decision Tree. Laser Optoelectron. Prog. 2019, 56. [Google Scholar]
- Zhao, Z.H.; Zhang, C.Z.; Zhang, J.B.; Wu, Y.J.; Zhang, H.M.; Lu, C.Y. The Hyperspectral Inversion for Estimating Maize Chlorophyll Contents Based on Regression Analysis. Chin. Agric. Sci. Bull. 2021, 35, 7–16. [Google Scholar]
- Sarathjith, M.C.; Das, B.S.; Wani, S.P.; Sahrawat, K.L. Variable indicators for optimum wavelength selection in diffuse reflectance spectroscopy of soils. Geoderma 2016, 267, 1–9. [Google Scholar]
- Xu, S.; Zhao, Y.; Wang, M.; Shi, X. Determination of rice root density from Vis–NIR spectroscopy by support vector machine regression and spectral variable selection techniques. Catena 2017, 157, 12–23. [Google Scholar]
- Pinto, C.F.; Parab, J.S.; Sequeira, M.D.; Naik, G.M. Development of Altera NIOS II Soft-core system to predict total Hemoglobin using Multivariate Analysis. J. Phys. Conf. Ser. 2021, 1921, 12039. [Google Scholar]
- Wei, L.; Yuan, Z.; Yu, M.; Huang, C.; Cao, L. Estimation of Arsenic Content in Soil Based on Laboratory and Field Reflectance Spectroscopy. Sensors 2019, 19, 3904. [Google Scholar]
- Raissi, M.; Karniadakis, G.E. Hidden Physics Models: Machine Learning of Nonlinear Partial Differential Equations. J. Comput. Phys. 2018, 357, 125–141. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wavelength Variable Type | Classification Rules |
|---|---|
| Strongly informative | |
| Weakly informative | |
| Uninformative | |
| Interfering |
| Selection Method | Number of Bands | Modeling Algorithm | |||
|---|---|---|---|---|---|
| Full bands | 176 | PLSR | 0.52 | 2.57 | 2.11 |
| XGBoost | 0.48 | 2.80 | 2.28 | ||
| RFR | 0.42 | 2.95 | 2.83 | ||
| GBDT | 0.50 | 2.76 | 2.19 | ||
| CA | 76 | PLSR | 0.48 | 2.59 | 2.1 |
| XGBoost | 0.29 | 3.00 | 2.39 | ||
| RFR | 0.41 | 2.95 | 2.4 | ||
| GBDT | 0.44 | 2.84 | 2.23 | ||
| sCARS | 46 | PLSR | 0.55 | 2.59 | 2.13 |
| XGBoost | 0.54 | 2.68 | 2.17 | ||
| RFR | 0.43 | 2.92 | 2.32 | ||
| GBDT | 0.53 | 2.74 | 2.17 | ||
| IRIV | 26 | PLSR | 0.84 | 2.46 | 2.02 |
| XGBoost | 0.81 | 2.76 | 2.30 | ||
| RFR | 0.80 | 2.85 | 2.28 | ||
| GBDT | 0.80 | 2.82 | 2.22 |
| Leaf Position | Measured Value | Model Method | Min Value | Max Value |
|---|---|---|---|---|
| Lower leaf | 66.0 | PLSR | 19 | 82 |
| XGBoost | 43 | 69 | ||
| RFR | 46 | 67 | ||
| GBDT | 43 | 70 | ||
| 69.0 | PLSR | 21 | 85 | |
| XGBoost | 44 | 69 | ||
| RFR | 47 | 67 | ||
| GBDT | 45 | 69 | ||
| Middle leaf | 61.0 | PLSR | 14 | 82 |
| XGBoost | 42 | 69 | ||
| RFR | 45 | 66 | ||
| GBDT | 42 | 69 | ||
| 60.6 | PLSR | 12 | 83 | |
| XGBoost | 41 | 69 | ||
| RFR | 45 | 66 | ||
| GBDT | 44 | 69 | ||
| Upper leaf | 48.3 | PLSR | 3 | 73 |
| XGBoost | 42 | 67 | ||
| RFR | 45 | 65 | ||
| GBDT | 42 | 68 | ||
| 50.5 | PLSR | 2 | 72 | |
| XGBoost | 42 | 67 | ||
| RFR | 45 | 64 | ||
| GBDT | 42 | 68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Z.; Ye, Y.; Wei, L.; Yang, X.; Huang, C. Study on the Optimization of Hyperspectral Characteristic Bands Combined with Monitoring and Visualization of Pepper Leaf SPAD Value. Sensors 2022, 22, 183. https://doi.org/10.3390/s22010183
Yuan Z, Ye Y, Wei L, Yang X, Huang C. Study on the Optimization of Hyperspectral Characteristic Bands Combined with Monitoring and Visualization of Pepper Leaf SPAD Value. Sensors. 2022; 22(1):183. https://doi.org/10.3390/s22010183
Chicago/Turabian StyleYuan, Ziran, Yin Ye, Lifei Wei, Xin Yang, and Can Huang. 2022. "Study on the Optimization of Hyperspectral Characteristic Bands Combined with Monitoring and Visualization of Pepper Leaf SPAD Value" Sensors 22, no. 1: 183. https://doi.org/10.3390/s22010183
APA StyleYuan, Z., Ye, Y., Wei, L., Yang, X., & Huang, C. (2022). Study on the Optimization of Hyperspectral Characteristic Bands Combined with Monitoring and Visualization of Pepper Leaf SPAD Value. Sensors, 22(1), 183. https://doi.org/10.3390/s22010183