
Detail Preserving Low Illumination Image and Video Enhancement Algorithm Based on Dark Channel Prior




Abstract
:1. Introduction
2. Related Work
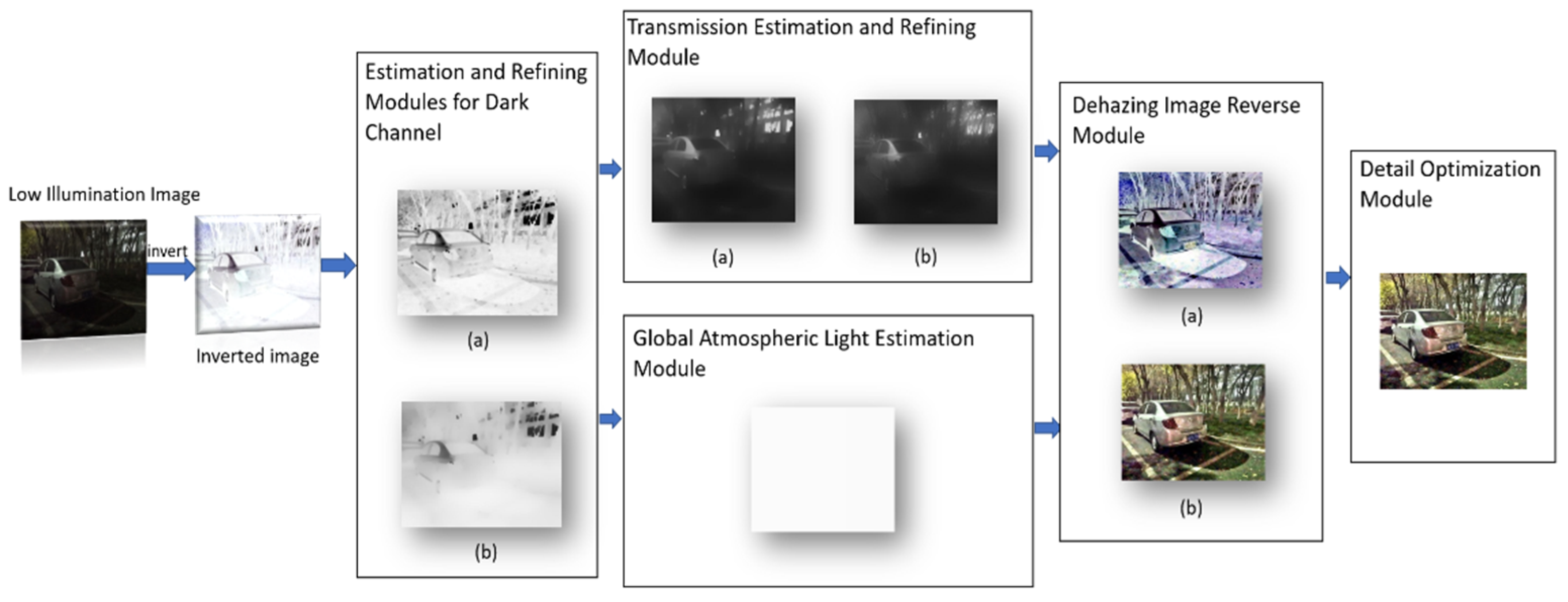
3. Proposed Method
3.1. Atmospheric Scattering Model
3.2. Dark Channel and Its Prosed Modification
3.2.1. Basic Concept of Dark Channel
3.2.2. Proposed Refined Method for Dark Channel
3.3. Transmission and Its Refined Method
3.3.1. Transmission Estimation
3.3.2. Proposed Refined Method for Transmission
3.4. Proposed Alternative Scheme for Video Detail Enhancement
4. Experimental Results and Analysis
4.1. Parameter Setting
4.2. Ablation Experiment
4.2.1. Comparative Analysis of Transmission Refined Method
4.2.2. Comparative Analysis before and after Dark Channel Refinement
4.2.3. Comparative Analysis before and after Detail Enhancement
4.3. Comparative Experiments and Analysis
4.3.1. Quantitative Analysis
4.3.2. Qualitative Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Park, S.; Kim, K.; Yu, S.; Paik, J. Contrast Enhancement for Low-light Image Enhancement: A Survey. IEIE Trans. Smart Process. Comput. 2018, 7, 36–48. [Google Scholar] [CrossRef]
- Wang, W.; Wu, X.; Yuan, X.; Gao, Z. An experiment-based review of low-light image enhancement methods. IEEE Access 2020, 8, 87884–87917. [Google Scholar] [CrossRef]
- Huang, S.-C.; Cheng, F.-C.; Chiu, Y.-S. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef] [PubMed]
- Panetta, K.; Agaian, S.; Zhou, Y.; Wharton, E.J. Parameterized logarithmic framework for image enhancement. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 41, 460–473. [Google Scholar] [CrossRef]
- Abdullah-Al-Wadud, M.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Land, E.H. The retinex theory of color vision. Sci. Am. 1977, 237, 108–129. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.-u.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, X.; Yao, H.; Zhang, S.; Lu, X.; Zeng, W. Night video enhancement using improved dark channel prior. In Proceedings of the 2013 IEEE International Conference on Image Processing (ICIP), Melbourne, VIC, Australia, 15–18 September 2013; pp. 553–557. [Google Scholar]
- Liu, S.; Long, W.; He, L.; Li, Y.; Ding, W. Retinex-Based Fast Algorithm for Low-Light Image Enhancement. Entropy 2021, 23, 746. [Google Scholar] [CrossRef] [PubMed]
- Zeng, B.W.; Kin, T.U. Low-Light Image Enhancement Algorithm Based on Lime with Pre-Processing and Post-Processing. In Proceedings of the 2020 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Adelaide, Australia, 2 December 2020. [Google Scholar]
- Ma, S.; Ma, H.; Xu, Y.; Li, S.; Lv, C.; Zhu, M. A Low-Light Sensor Image Enhancement Algorithm Based on HSI Color Model. Sensors 2018, 18, 3583. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, M.; Zhang, Y.; Jiang, Z.; Lv, X.; Guo, C. Low-Illumination Image Enhancement in the Space Environment Based on the DC-WGAN Algorithm. Sensors 2021, 21, 286. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Chang, Z.; Zhao, Y.; Hua, Z.; Li, S. Progressive Two-Stage Network for Low-Light Image Enhancement. Micromachines 2021, 12, 1458. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, X. MARN: Multi-Scale Attention Retinex Network for Low-Light Image Enhancement. IEEE Access 2021, 9, 50939–50948. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y.; Chen, Y.; Han, Y. LighterGAN: An Illumination Enhancement Method for Urban UAV Imagery. Remote Sens. 2021, 13, 1371. [Google Scholar] [CrossRef]
- Ren, W.; Liu, S.; Ma, L.; Xu, Q.; Xu, X.; Cao, X.; Du, J.; Yang, M.-H. Low-light image enhancement via a deep hybrid network. IEEE Trans. Image Process. 2019, 28, 4364–4375. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Gong, X.; Wang, J.; Zhao, L. Low-Light Image Enhancement Based on Multi-Path Interaction. Sensors 2021, 21, 4986. [Google Scholar] [CrossRef] [PubMed]
- Kim, G.; Kwon, D.; Kwon, J. Low-lightgan: Low-light enhancement via advanced generative adversarial network with task-driven training. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2811–2815. [Google Scholar]
- Zhang, Z.; Wen, J.; Xu, Y.; Fe, L. Review of Video and Image Defogging Algorithms and Related Studies on Image Restoration and Enhancement. IEEE Access 2016, 4, 165–188. [Google Scholar]
- Jobson, D.J.; Rahman, Z.-U.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Rahman, Z.-U.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing (ICIP), Lausanne, Switzerland, 19 September 1996; pp. 1003–1006. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Rahman, Z.-U.; Jobson, D.J.; Woodell, G.A. Retinex processing for automatic image enhancement. J. Electron. Imaging 2004, 13, 100–110. [Google Scholar]
- Guo, Y.; Lu, Y.; Liu, R.W.; Yang, M.; Chui, K.T. Low-light image enhancement with regularized illumination optimization and deep noise suppression. IEEE Access 2020, 8, 145297–145315. [Google Scholar] [CrossRef]
- Ren, Y.; Ying, Z.; Li, T.H.; Li, G. LECARM: Low-Light Image Enhancement Using the Camera Response Model. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 968–981. [Google Scholar] [CrossRef]
- Zhi, L.; Jia, Z.; Yang, J.; Kasabov, N. Low illumination video image enhancement. IEEE Photonics J. 2020, 12, 1–13. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Pang, J.; Zhang, S.; Bai, W. A novel framework for enhancement of the low lighting video. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 1366–1371. [Google Scholar]
- Wang, Y.-F.; Liu, H.-M.; Fu, Z.-W. Low-light image enhancement via the absorption light scattering model. IEEE Trans. Image Process. 2019, 28, 5679–5690. [Google Scholar] [CrossRef] [PubMed]
- Rao, Y.; Zhang, Y.; Gou, J. Gradient fusion method for night video enhancement. ETRI J. 2013, 35, 923–926. [Google Scholar] [CrossRef]
- Soumya, T.; Thampi, S.M. Recolorizing dark regions to enhance night surveillance video. Multimed. Tools Appl. 2017, 76, 24477–24493. [Google Scholar] [CrossRef]
- Lee, S.; Kim, N.; Paik, J. Adaptively partitioned block-based contrast enhancement and its application to low light-level video surveillance. SpringerPlus 2015, 4, 431. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, X.; Wang, G.; Pang, Y.; Li, W.; Wen, J.; Meng, W.; Lu, Y. Fast efficient algorithm for enhancement of low lighting video. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo (ICME), Barcelona, Spain, 11–15 July 2011; pp. 1–6. [Google Scholar]
- Underexposed Video Enhancement via Perception-Driven Progressive Fusion. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1773–1785. [CrossRef]
- Ko, S.; Yu, S.; Kang, W.; Park, C.; Lee, S.; Paik, J. Artifact-free low-light video enhancement using temporal similarity and guide map. IEEE Trans. Ind. Electron. 2017, 64, 6392–6401. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, S. Non-uniform Illumination Video Enhancement Based on Zone System and Fusion. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018. [Google Scholar]
- Buades, A.; Lisani, J.L. Enhancement of noisy and compressed videos by optical flow and non-local denoising. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1960–1974. [Google Scholar] [CrossRef]
- Ren, X.; Yang, W.; Cheng, W.-H.; Liu, J. LR3M: Robust low-light enhancement via low-rank regularized retinex model. IEEE Trans. Image Process. 2020, 29, 5862–5876. [Google Scholar] [CrossRef]
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; Phys Today: New York, NY, USA, 1976. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In Proceedings of the European conference on computer vision; 2010; pp. 1–14. [Google Scholar]
- Ochotorena, C.N.; Yamashita, Y. Anisotropic guided filtering. IEEE Trans. Image Process. 2019, 29, 1397–1412. [Google Scholar] [CrossRef] [PubMed]
- Kotecha, J.H.; Djuric, P.M. Gaussian sum particle filtering. IEEE Trans. Signal Process. 2003, 51, 2602–2612. [Google Scholar] [CrossRef] [Green Version]
- Prabhakar, K.R.; Srikar, V.S.; Babu, R.V. DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4724–4732. [Google Scholar]
- Wang, S.; Ma, K.; Yeganeh, H.; Wang, Z.; Lin, W. A patch-structure representation method for quality assessment of contrast changed images. IEEE Signal Process. Lett. 2015, 22, 2387–2390. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kasabov, N.K. Time-Space, Spiking Neural Networks and Brain-Inspired Artificial Intelligence; Springer: Berlin, Germany, 2019; Volume 7, pp. 169–199. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AG | IE | e | C | PSNR | SSIM | PCQI | Times |
|---|---|---|---|---|---|---|---|---|
| ALSM | 2.97 | 7.43 | 197.33 | 49.00 | 19.76 | 0.77 | 0.74 | 148.26 |
| Li et al. [26] | 2.81 | 5.56 | 245.69 | 46.14 | 12.32 | 0.52 | 0.53 | 1.63 |
| LR3M | 1.98 | 7.43 | 196.04 | 35.46 | 23.04 | 0.84 | 0.65 | 6171.03 |
| LIME | 3.15 | 7.58 | 201.14 | 51.09 | 19.96 | 0.78 | 0.73 | 2.37 |
| The proposed method | 4.49 | 7.54 | 386.20 | 69.63 | 20.15 | 0.70 | 0.75 | 6.38 |
| Method | AG | IE | e | C | PSNR | SSIM | PCQI | Times |
|---|---|---|---|---|---|---|---|---|
| ALSM | 2.07 | 7.00 | 134.13 | 37.23 | 27.12 | 0.81 | 0.87 | 66.04 |
| Li et al. [26] | 0.91 | 4.65 | 56.64 | 18.13 | 16.85 | 0.50 | 0.59 | 1.60 |
| LR3M | 2.38 | 7.35 | 266.64 | 42.17 | 24.74 | 0.82 | 0.82 | 5017.18 |
| LIME | 2.33 | 7.52 | 148.46 | 41.01 | 21.36 | 0.72 | 0.85 | 2.54 |
| The proposed method | 2.94 | 7.39 | 229.70 | 49.21 | 25.61 | 0.77 | 0.95 | 6.55 |
| Method | AG | IE | e | C | PSNR | SSIM | PCQI | Times |
|---|---|---|---|---|---|---|---|---|
| ALSM | 2.12 | 7.07 | 118.06 | 36.50 | 22.90 | 0.77 | 0.89 | 121.40 |
| Li et al. [26] | 1.79 | 4.69 | 136.97 | 30.89 | 15.64 | 0.56 | 0.67 | 1.61 |
| LR3M | 1.54 | 7.27 | 120.64 | 27.58 | 25.53 | 0.81 | 0.81 | 5797.49 |
| LIME | 2.43 | 7.44 | 147.31 | 41.57 | 22.46 | 0.72 | 0.92 | 2.51 |
| The proposed method | 3.13 | 7.21 | 228.92 | 50.43 | 22.06 | 0.72 | 0.96 | 6.17 |
| Data | Method | AG | IE | e | C | Times |
|---|---|---|---|---|---|---|
| 1 | ALSM | 6.92 | 7.75 | 626.01 | 98.34 | 14.21 |
| Li et al. [26] | 5.32 | 5.97 | 554.12 | 75.51 | 0.50 | |
| LR3M | 4.13 | 7.31 | 435.71 | 61.44 | 155.69 | |
| LIME | 7.80 | 7.73 | 747.25 | 110.03 | 1.04 | |
| The proposed method | 10.50 | 7.79 | 1266.27 | 139.26 | 1.77 | |
| 2 | ALSM | 4.32 | 6.40 | 369.98 | 62.76 | 14.73 |
| Li et al. [26] | 5.04 | 6.50 | 504.19 | 73.13 | 0.59 | |
| LR3M | 1.37 | 6.08 | 132.69 | 21.78 | 183.53 | |
| LIME | 5.78 | 6.98 | 594.95 | 83.49 | 1.05 | |
| The proposed method | 6.15 | 6.31 | 675.40 | 83.50 | 1.66 | |
| 3 | ALSM | 5.33 | 7.56 | 500.67 | 81.37 | 15.99 |
| Li et al. [26] | 5.57 | 7.40 | 513.40 | 84.73 | 0.62 | |
| LR3M | 3.11 | 6.79 | 544.24 | 50.35 | 171.63 | |
| LIME | 6.13 | 7.61 | 631.89 | 92.30 | 1.02 | |
| The proposed method | 7.88 | 7.58 | 930.76 | 114.40 | 1.70 | |
| 4 | ALSM | 12.41 | 7.80 | 1635.13 | 158.94 | 15.45 |
| Li et al. [26] | 7.51 | 5.01 | 1243.82 | 95.85 | 0.49 | |
| LR3M | 11.01 | 7.64 | 1698.36 | 145.12 | 183.92 | |
| LIME | 13.54 | 7.80 | 1791.22 | 171.36 | 1.22 | |
| The proposed method | 19.01 | 7.81 | 3101.19 | 226.43 | 1.84 |
| Method | AG | IE | e | C | Times |
|---|---|---|---|---|---|
| ALSM | 6.80 | 7.06 | 661.16 | 95.43 | 13.43 |
| Li et al. [26] | 7.40 | 6.79 | 921.97 | 104.22 | 0.59 |
| LR3M | 2.56 | 6.61 | 239.43 | 39.56 | 210.63 |
| LIME | 7.99 | 7.36 | 878.64 | 110.67 | 1.09 |
| The proposed method | 9.90 | 7.09 | 1268.28 | 130.07 | 1.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, L.; Jia, Z.; Yang, J.; Kasabov, N.K. Detail Preserving Low Illumination Image and Video Enhancement Algorithm Based on Dark Channel Prior. Sensors 2022, 22, 85. https://doi.org/10.3390/s22010085
Guo L, Jia Z, Yang J, Kasabov NK. Detail Preserving Low Illumination Image and Video Enhancement Algorithm Based on Dark Channel Prior. Sensors. 2022; 22(1):85. https://doi.org/10.3390/s22010085
Chicago/Turabian StyleGuo, Lingli, Zhenhong Jia, Jie Yang, and Nikola K. Kasabov. 2022. "Detail Preserving Low Illumination Image and Video Enhancement Algorithm Based on Dark Channel Prior" Sensors 22, no. 1: 85. https://doi.org/10.3390/s22010085
APA StyleGuo, L., Jia, Z., Yang, J., & Kasabov, N. K. (2022). Detail Preserving Low Illumination Image and Video Enhancement Algorithm Based on Dark Channel Prior. Sensors, 22(1), 85. https://doi.org/10.3390/s22010085