
Lightweight Internet of Things Botnet Detection Using One-Class Classification

 , , ,
, , ,
Abstract
:1. Introduction
2. Related Work
3. Proposed Methodology
| Algorithm 1: Botnet detection using one-class KNN | |
| Input: datasets d1, d2, d3 | |
| 1. | Convert datasets d1, d2, d3 into PCAP format |
| 2. | Apply filtering based on source and destination IP |
| 3. | |
| 4. | Data preprocessing to eliminate missing, infinite, NAN and HEX values |
| 5. | Perform feature selection using |
| 6. | Filter method |
| 7. | Wrapper method |
| 8. | End feature selection |
| 9. | For each dataset d1, d2, d3 apply one-class KNN |
| 10. | Load the training dataset |
| 11. | Choose the value of k |
| 12. | Train the model |
| 13. | Load the test dataset |
| 14. | For each point in the test data until point = NULL |
| 15. | Find Euclidian distance d to all training data points |
| 16. | Store d in a list L and sort it |
| 17. | Choose the first k points |
| 18. | Assign class to the test points |
| 19. | End For |
| 20. | End For |
3.1. Data Assortment
3.2. PCAP Filtering
3.3. Feature Extraction
3.4. Shark Script
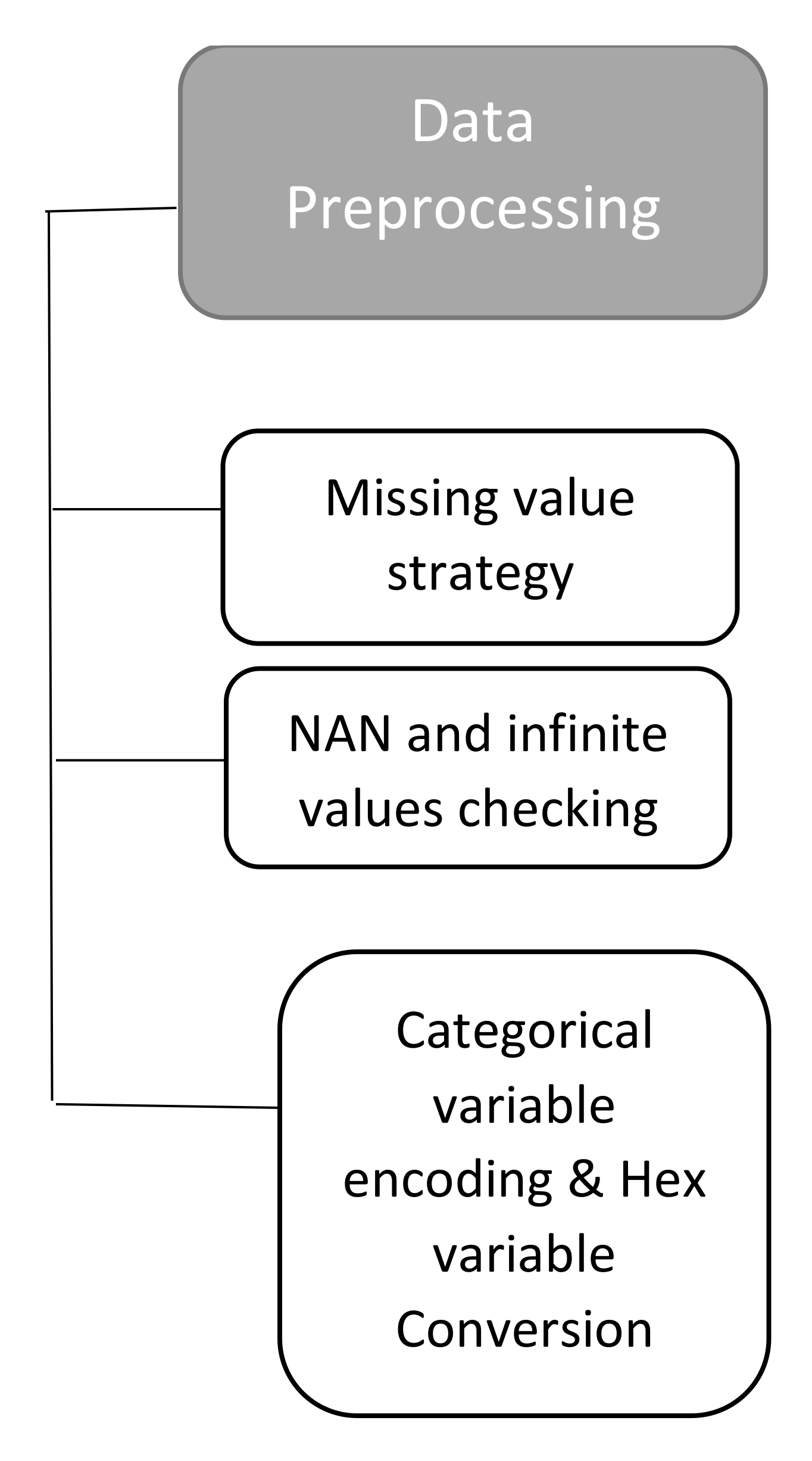
3.5. Data Preprocessing
3.5.1. NaN and Infinite Value Checking
3.5.2. Categorical Values
3.5.3. Hex Values
3.6. Feature Selection
3.6.1. Filter Method
Univariate Filter
- First, Jupyter Notebook was set up, and essential libraries were imported.
- Datasets that contained benign and malicious files were imported.
- Each feature was examined for missing value so that there should be no feature with a missing value in the dataset.
- Constant features were examined by setting the variance threshold equivalent to zero. A total of 14 features were found with constant values, and those features were discarded.
- Quasi-constant features were examined by adjusting the variance threshold to 0.1. A total of five features not meeting the criteria were deleted.
- Dataset was examined for repeated columns, and duplicate columns were deleted to make them distinct.
- At the end of the univariate filter method, the remaining features number 27.
Multivariate Filter
- After implementing the univariate filter method, the remaining 27 features were inspected for correlation utilizing Pearson’s correlation coefficient using library phik_matrix [35].
- For visualizing the correlation score, a heatmap was plotted as shown in Figure 5.
- Features with a score correlation value greater than 0.95 were filtered. As a result, 5 more features were dropped, leaving the feature count at 22.
- Resulting data frame comprised 22 features and was saved as CSV for additional utilization and filtering through the wrapper method.
3.6.2. Wrapper Method
Forward Feature Selection
Backward Feature Elimination
- In the first step, we imported machine-learning libraries, loaded the dataset and split it into training and testing sets.
- We performed the forward feature selection method in Python. Random forest classifier was used for feature selection.
- All 22 features were input to random forest that assigned a score to each feature using the mean decrease accuracy measure.
- Among the features, 13 features were selected based on their importance. These features produced the highest accuracy with random forest.
- The selected features were then used to train our algorithm as shown in Table 2.
- We then utilized the selected features to construct a full model utilizing our training and test datasets and then evaluated the accuracies.
4. Experiments with One-Class KNN
4.1. True Positive
4.2. False Positive
4.3. True Negative
4.4. False Negative
4.5. Precision
4.6. Recall
4.7. F-Measure
5. Results and Analysis
5.1. Dataset Description
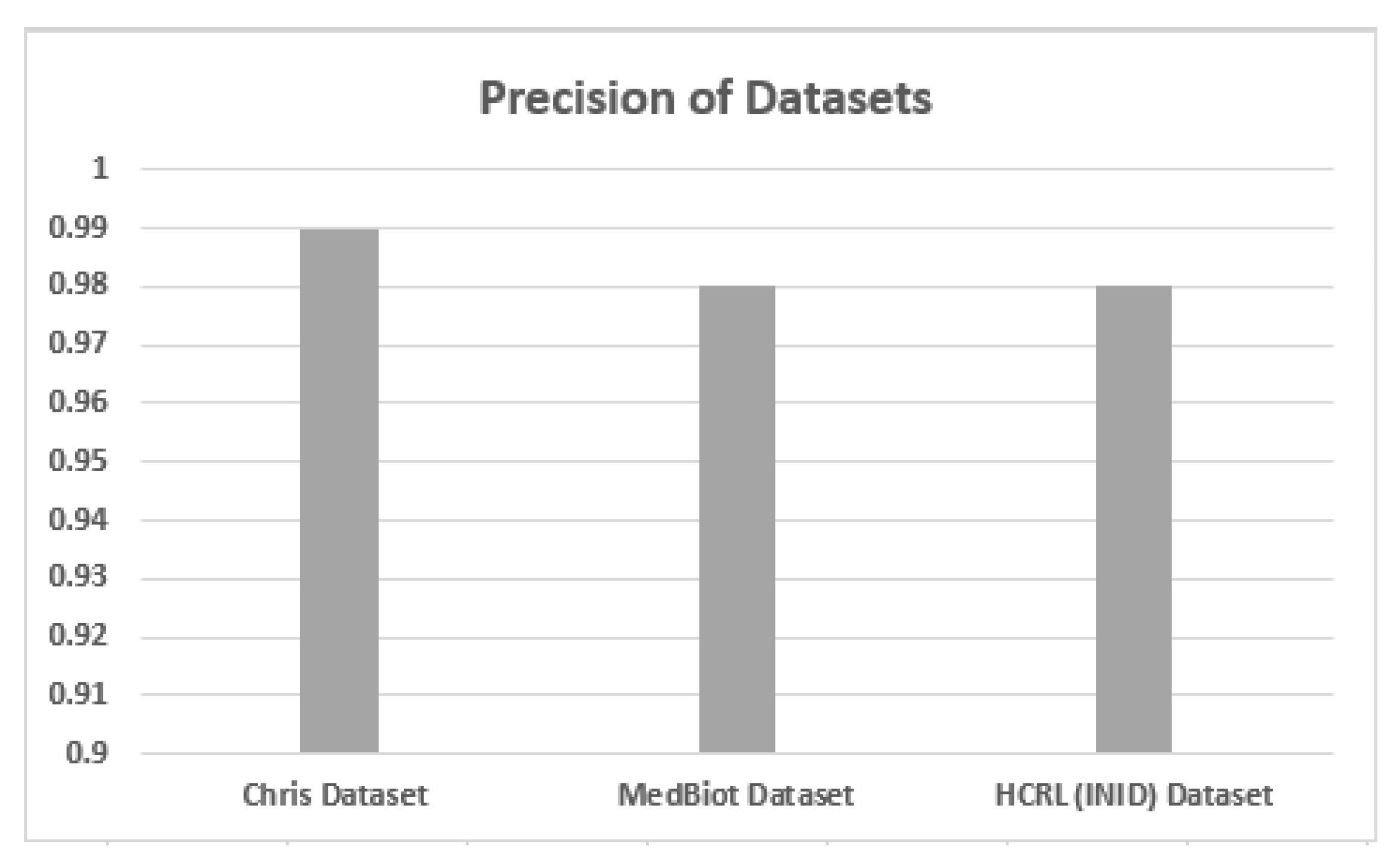
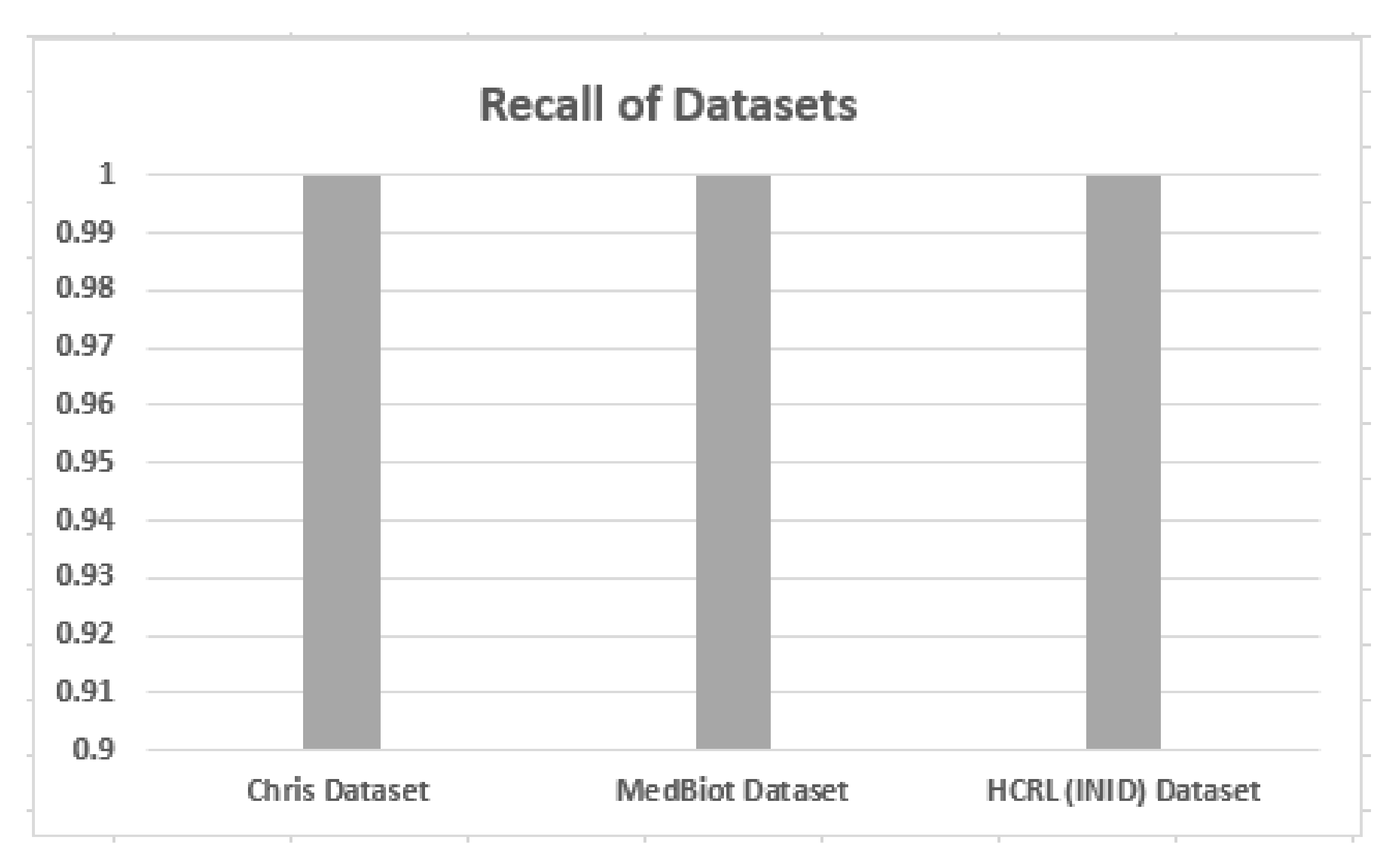
5.2. Accuracy, Precision and Recall
5.3. F1-Score on Different Datasets
5.4. Effect of Feature Selection
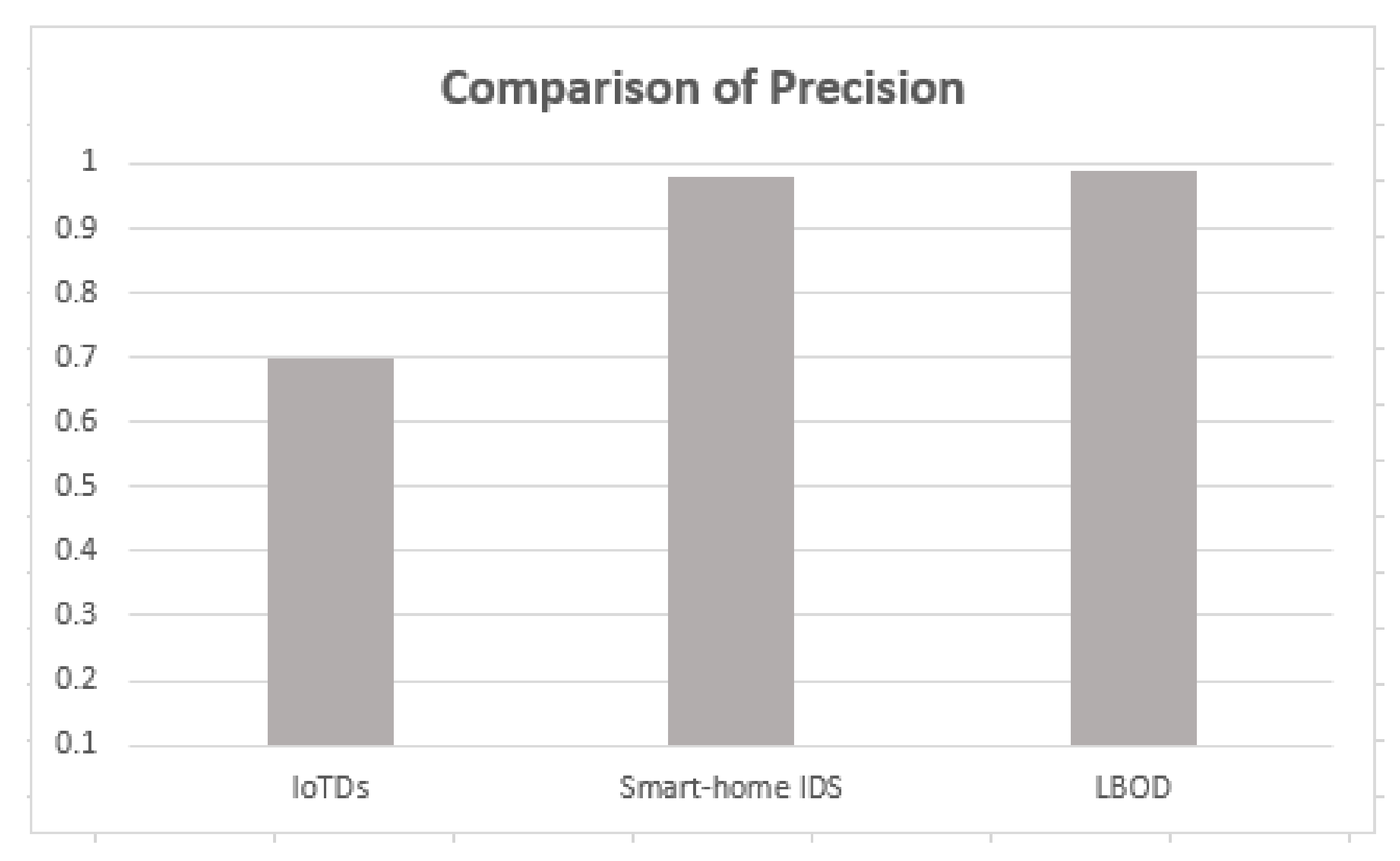
5.5. Comparison with Recent Research Works
5.6. Comparison of Training Time before and after Feature Selection
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Sahu, N.K.; Mukherjee, I. Machine Learning based anomaly detection for IoT Network:(Anomaly detection in IoT Network). In Proceedings of the 2020 4th International Conference on Trends in Electronics and Informatics (ICOEI)(48184), Tirunelveli, India, 15–17 June 2020; pp. 787–794. [Google Scholar]
- IDC Forecasts Worldwide Spending on the Internet of Things to Reach $772 Billion in 2018. Available online: https://www.idc.com/getdoc.jsp?containerId=prUS43295217 (accessed on 22 August 2020).
- Liu, X.; Liu, Y.; Liu, A.; Yang, L.T. Defending ON–OFF attacks using light probing messages in smart sensors for industrial communication systems. IEEE Trans. Ind. Inform. 2018, 14, 3801–3811. [Google Scholar] [CrossRef]
- Shahid, M.R.; Blanc, G.; Zhang, Z.; Debar, H. Anomalous communications detection in IoT networks using sparse autoencoders. In Proceedings of the 2019 IEEE 18th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 26–28 September 2019; pp. 1–5. [Google Scholar]
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for Internet of Things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Aboueata, N.; Alrasbi, S.; Erbad, A.; Kassler, A.; Bhamare, D. Supervised machine learning techniques for efficient network intrusion detection. In Proceedings of the 2019 28th International Conference on Computer Communication and Networks (ICCCN), Valencia, Spain, 29 July–1 August 2019; pp. 1–8. [Google Scholar]
- Jia, Y.; Zhong, F.; Alrawais, A.; Gong, B.; Cheng, X. FlowGuard: An Intelligent Edge Defense Mechanism Against IoT DDoS Attacks. IEEE Internet Things J. 2020, 7, 9552–9562. [Google Scholar] [CrossRef]
- Timčenko, V.; Gajin, S. Machine learning based network anomaly detection for IoT environments. In Proceedings of the ICIST 2018: 24th International Conference on Information and Software Technologies, Vilnius, Lithuania, 4–5 October 2018. [Google Scholar]
- Doshi, R.; Apthorpe, N.; Feamster, N. Machine learning ddos detection for consumer internet of things devices. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 29–35. [Google Scholar]
- Swersky, L.; Marques, H.O.; Sander, J.; Campello, R.J.; Zimek, A. On the evaluation of outlier detection and one-class classification methods. In Proceedings of the 2016 IEEE international conference on data science and advanced analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 1–10. [Google Scholar]
- Cui, L.; Yang, S.; Chen, F.; Ming, Z.; Lu, N.; Qin, J. A survey on application of machine learning for Internet of Things. Int. J. Mach. Learn. Cybern. 2018, 9, 1399–1417. [Google Scholar] [CrossRef]
- Hussain, F.; Hussain, R.; Hassan, S.A.; Hossain, E. Machine learning in IoT security: Current solutions and future challenges. IEEE Commun. Surv. Tutor. 2020, 22, 1686–1721. [Google Scholar] [CrossRef] [Green Version]
- Verma, A.; Ranga, V. Machine learning based intrusion detection systems for IoT applications. Wirel. Pers. Commun. 2020, 111, 2287–2310. [Google Scholar] [CrossRef]
- Branitskiy, A.; Kotenko, I.; Saenko, I.B. Applying Machine Learning and Parallel Data Processing for Attack Detection in IoT. IEEE Trans. Emerg. Top. Comput. 2020, 9, 1642–1653. [Google Scholar] [CrossRef]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Shabtai, A.; Breitenbacher, D.; Elovici, Y. N-baiot—Network-based detection of iot botnet attacks using deep autoencoders. IEEE Pervas. Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Lim, T.J. EDIMA: Early detection of IoT malware network activity using machine learning techniques. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019; pp. 289–294. [Google Scholar]
- Bezerra, V.H.; da Costa, V.G.T.; Junior, S.B.; Miani, R.S.; Zarpelão, B.B. IoTDS: A one-class classification approach to detect botnets in Internet of Things devices. Sensors 2019, 19, 3188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anthi, E.; Williams, L.; Słowińska, M.; Theodorakopoulos, G.; Burnap, P. A supervised intrusion detection system for smart home IoT devices. IEEE Internet Things J. 2019, 6, 9042–9053. [Google Scholar] [CrossRef]
- Hsu, H.-T.; Jong, G.-J.; Chen, J.-H.; Jhe, C.-G. Improve Iot Security System of Smart-Home by Using Support Vector Machine. In Proceedings of the 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), Singapore, 23–25 February 2019; pp. 674–677. [Google Scholar]
- Sivanathan, A.; Gharakheili, H.H.; Loi, F.; Radford, A.; Wijenayake, C.; Vishwanath, A.; Sivaraman, V. Classifying IoT devices in smart environments using network traffic characteristics. IEEE Trans. Mob. Comput. 2018, 18, 1745–1759. [Google Scholar] [CrossRef]
- Hasan, M.; Islam, M.M.; Zarif, M.I.I.; Hashem, M. Attack and anomaly detection in IoT sensors in IoT sites using machine learning approaches. Internet Things 2019, 7, 100059. [Google Scholar] [CrossRef]
- Vikram, A. Anomaly detection in Network Traffic Using Unsupervised Machine learning Approach. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 476–479. [Google Scholar]
- Popoola, S.I.; Adebisi, B.; Ande, R.; Hammoudeh, M.; Anoh, K.; Atayero, A.A. smote-drnn: A deep learning algorithm for botnet detection in the internet-of-things networks. Sensors 2021, 21, 2985. [Google Scholar] [CrossRef] [PubMed]
- Almiani, M.; AbuGhazleh, A.; Al-Rahayfeh, A.; Atiewi, S.; Razaque, A. Deep recurrent neural network for IoT intrusion detection system. Simul. Model. Pract. Theory 2020, 101, 102031. [Google Scholar] [CrossRef]
- Stiawan, D.; Arifin, M.A.S.; Rejito, J.; Idris, M.Y.; Budiarto, R. A Dimensionality Reduction Approach for Machine Learning Based IoT Botnet Detection. In Proceedings of the 2021 8th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Semarang, Indonesia, 20–21 October 2021; pp. 26–30. [Google Scholar]
- Rezaei, A. Using Ensemble Learning Technique for Detecting Botnet on IoT. SN Comput. Sci. 2021, 2, 148. [Google Scholar] [CrossRef]
- Guerra-Manzanares, A.; Medina-Galindo, J.; Bahsi, H.; Nõmm, S. MedBIoT: Generation of an IoT Botnet Dataset in a Medium-sized IoT Network. In Proceedings of the 6th International Conference on Information Systems Security and Privacy, ICISSP 2020, Valletta, Malta, 25–27 February 2020; pp. 207–218. [Google Scholar]
- McDermott, C.D.; Haynes, W.; Petrovksi, A.V. Threat Detection and Analysis in the Internet of Things using Deep Packet Inspection. IJCSA 2018, 3, 61–83. [Google Scholar] [CrossRef] [Green Version]
- Kang, H.; Ahn, D.; Lee, G.; Yoo, J.; Park, K.; Kim, H.; IoT network intrusion dataset. IEEE Dataport 2019. Available online: https://ieee-dataport.org/open-access/iot-network-intrusion-dataset (accessed on 15 March 2022).
- Kuang, C.; Hou, D.; Zhang, Q.; Zhao, K.; Li, W. A Network Traffic Collection System for Space Information Networks Emulation Platform. In Proceedings of the International Conference on Wireless and Satellite Systems, Nanjing, China, 17–18 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 217–225. [Google Scholar]
- Bash Terminal Scripting. Available online: https://www.gnu.org/software/bash/manual/html_node/What-is-Bash_003f.html (accessed on 22 August 2020).
- McKinney, W. Pandas: A foundational Python library for data analysis and statistics. Python High Perform. Sci. Comput. 2011, 14, 1–9. [Google Scholar]
- Seger, C. An Investigation of Categorical Variable Encoding Techniques in Machine Learning: Binary Versus One-Hot and Feature Hashing. 2018, p. 34. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1259073&dswid=-7789 (accessed on 15 March 2022).
- Khadka, N. General Machine Learning Practices Using Python. Bachelor’s Thesis, Oulu University of Applied Sciences, Oulu, Finland, 2019. [Google Scholar]
- Güner, M. Retail Data Predictive Analysis Using Machine Learning Models; MEF Üniversitesi Fen Bilimleri Enstitüsü: İstanbul, Türkiye, 2020. [Google Scholar]
- Khan, S.S.; Madden, M.G. One-class classification: Taxonomy of study and review of techniques. Knowl. Eng. Rev. 2014, 29, 345–374. [Google Scholar] [CrossRef] [Green Version]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd international conference on Machine learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No. | Feature Name | Description | S. No. | Feature Name | Description |
|---|---|---|---|---|---|
| 1. | ip.src | Source IP address | 24. | tcp.flags.syn | TCP Syn flag |
| 2. | ip.dst | Destination IP address | 25. | tcp.flags.ack | TCP ACK flag in packet |
| 3. | frame.len | Length of frame in bytes | 26. | tcp.flags.push | TCP PUSH flag in packet |
| 4. | ip.proto | IP protocol number | 27. | tcp.flags.reset | TCP RESET flag in packet |
| 5. | tcp.srcport | TCP source port | 28. | tcp.flags.fin | TCP fin flag in packet |
| 6. | tcp.dstport | TCP destination port | 29. | ip.flags | IP header flags, such as fragmentation |
| 7. | udp.srcport | UDP source port | 30. | ip.frag_offset | IP fragmentation flag |
| 8. | udp.dstport | UDP destination port | 31. | ip.ttl | Time to live of IP packet |
| 9. | tcp.seq | TCP sequence numbers | 32. | tcp.ack | TCP ACK packet of three-way handshake |
| 10. | frame.time_epoch | Packet timestamp | 33. | tcp.window_size | Windows size for TCP communication |
| 11. | tcp.stream | TCP streams between nodes | 34. | tcp.nxtseq | Next expected sequence number |
| 12. | frame.time_relative | Time since the first packet in frame received | 35. | tcp.analysis.flags | Flags for analysis TCP sequence number and Acknowledgment |
| 13. | ip.len | Total length of packet/size of IP frame | 36. | udp.stream | Statistics of UDP streams |
| 14. | tcp.len | Length of TCP payload | 37. | udp.length.bad | UDP bad length value message |
| 15. | udp.length | Length of UDP payload | 38. | udp.length.bad_zero | UPD length is zero |
| 16. | frame.time_delta | Difference time between frames | 39. | frame.packet_flags_fcs_length | FCS (frame check sequence) length |
| 17. | ip.hdr_len | Length of IP header | 40. | ip.fragment.error | Defragmentation error |
| 18. | tcp.hdr_len | Size of TCP header in 32 bits | 41. | tcp.analysis.keep_alive | TCP keep-alive segment |
| 19. | tcp.analysis.bytes_in_flight | Bytes in flight for each packet | 42. | tcp.analysis.window_full | TCP windows full specified by user |
| 20. | tcp.time_relative | Time since first frame in TCP session | 43. | tcp.analysis.window_update | TCP window update |
| 21. | tcp.time_delta | Elapsed time between current and prior packet | 44. | tcp.analysis.zero_window | TCP zero window segment |
| 22. | tcp.analysis.ack_rtt | TCP ack and RTT (round time trip) for packet | 45. | tcp.analysis.zero_window_probe | TCP zero window probe |
| 23. | tcp.flags | TCP flags | 46. | frame.cap_len | Length of the captured frame |
| 1 | frame.len | 8 | tcp.hdr_len |
| 2 | ip.proto | 9 | tcp.time_relative |
| 3 | udp.srcport | 10 | ip.flags |
| 4 | udp.dstport | 11 | tcp.ack |
| 5 | tcp.stream | 12 | tcp.nxtseq |
| 6 | frame.time | 13 | ip.frag_offset |
| 7 | ip.len |
| Dataset | IoT Devices | Source |
|---|---|---|
| MedBiot [27] | IoT device | TPLink smart switch |
| Chris Dataset [28] | IoT device | Camera |
| HCRL (INID) [29] | IoT device 1 | SKT NUGU (NU 100) Speaker |
| IoT device 2 | EZVIZ Wi-Fi Camera |
| Data Type | Chris Dataset | MedBiot Dataset | HCRL (INID) Dataset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1-Score | Accuracy | Recall | F1-Score | Accuracy | Recall | F1-Score | Accuracy | Recall | |
| Normal | 88% | 87% | 94% | 81% | 88% | 92% | 83% | 87% | 91% |
| FS Applied | 99% | 99% | 100% | 98% | 98% | 100% | 98% | 98% | 100% |
| Research | F1-Score | Feature Selection | Multiple Dataset | One-Class Classifier |
|---|---|---|---|---|
| IOTDS [17] | 94% | No | No | Yes |
| Smart home IDS [18] | 98% | No | No | No |
| Proposed Solution (LBOD) | 99% | Yes | Yes | Yes |
| Datasets | Chris Dataset | MedBiot Dataset | HCRL (INID) Dataset | |||
|---|---|---|---|---|---|---|
| Time (Seconds) | Training | Prediction | Training | Prediction | Training | Prediction |
| Before FS | 5.3457 | 0.5636 | 7.5342 | 2.2327 | 4.3283 | 0.7124 |
| After FS | 2.2340 | 0.1298 | 3.2345 | 0.4335 | 2.2134 | 0.3190 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malik, K.; Rehman, F.; Maqsood, T.; Mustafa, S.; Khalid, O.; Akhunzada, A. Lightweight Internet of Things Botnet Detection Using One-Class Classification. Sensors 2022, 22, 3646. https://doi.org/10.3390/s22103646
Malik K, Rehman F, Maqsood T, Mustafa S, Khalid O, Akhunzada A. Lightweight Internet of Things Botnet Detection Using One-Class Classification. Sensors. 2022; 22(10):3646. https://doi.org/10.3390/s22103646
Chicago/Turabian StyleMalik, Kainat, Faisal Rehman, Tahir Maqsood, Saad Mustafa, Osman Khalid, and Adnan Akhunzada. 2022. "Lightweight Internet of Things Botnet Detection Using One-Class Classification" Sensors 22, no. 10: 3646. https://doi.org/10.3390/s22103646
APA StyleMalik, K., Rehman, F., Maqsood, T., Mustafa, S., Khalid, O., & Akhunzada, A. (2022). Lightweight Internet of Things Botnet Detection Using One-Class Classification. Sensors, 22(10), 3646. https://doi.org/10.3390/s22103646