1. Introduction
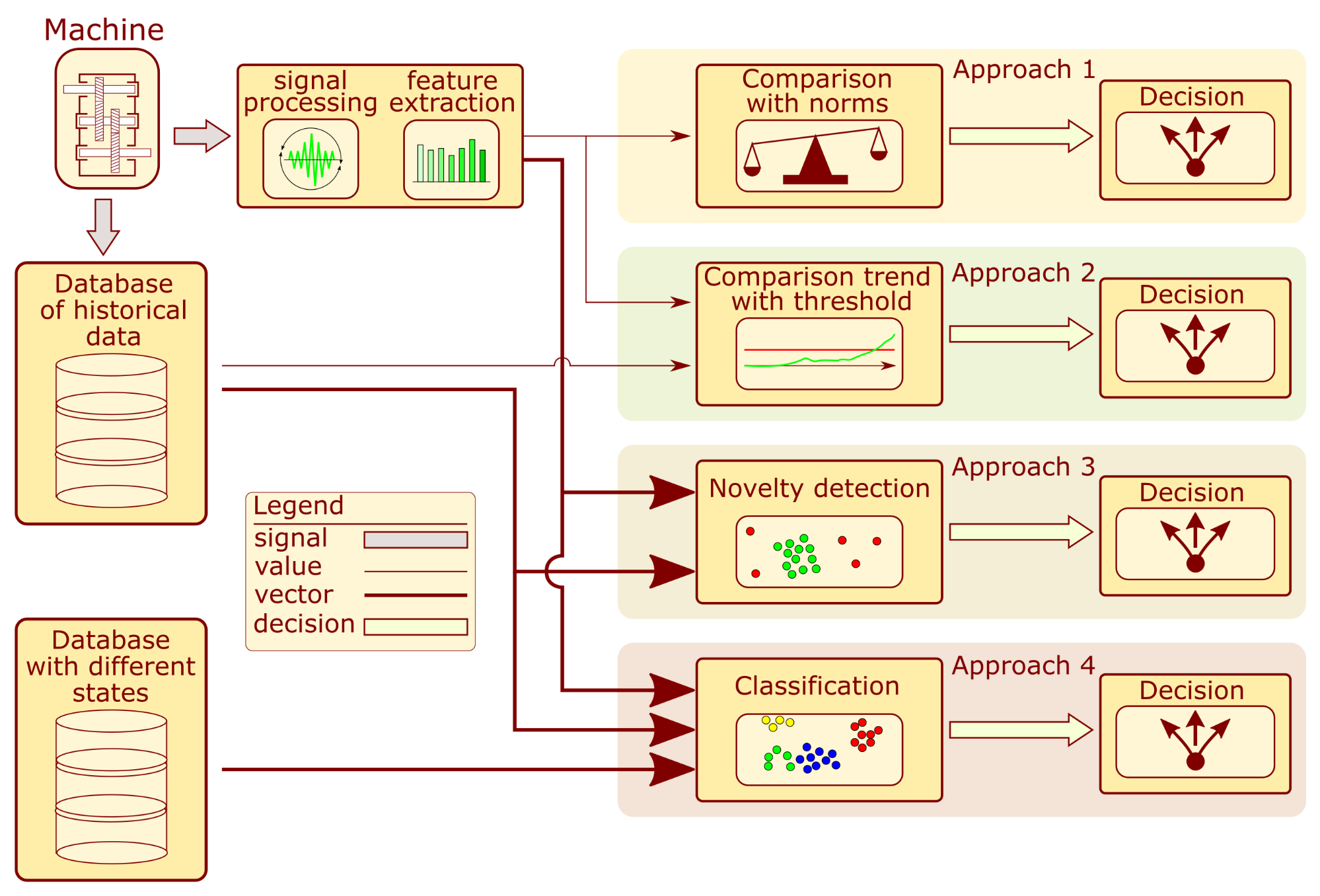
Choosing an appropriate structure state assessment algorithm is a fundamental problem in condition monitoring (CM). The block diagram presenting different approaches to algorithm development is presented in
Figure 1. The foundation of each system is usually the analysis of vibration signals recorded from the machine. Based on them and an in-depth analysis of the diagnostics problem for similar structures, the processing algorithms are determined to extract features that allow for a proper assessment of the structure state [
1].
In approach 1, the indicator value is compared with the norms for the intact machine. If they are exceeded, an alarm is reported. These systems seem simple to develop. However, the proper establishment of a relevant standard can be challenging task. The authors of [
2] describe a method for automatic threshold selection based on data distribution estimation. When historical diagnostic information is available, it is possible to develop more sophisticated systems based on a trend analysis of the calculated indicators. By determining the indicator distribution over a certain monitoring period, one can obtain a threshold value. If the value exceeds the threshold, the system triggers an alarm. Additionally, the trend analysis uses the trend slope and noise values, which are also considered when reporting alarm situations. The successfully implemented examples of this were introduced for wind [
3,
4] and gas [
5] turbines. Unfortunately, proposing a single indicator that contains enough information is a problematic and sometimes even impossible task. Therefore, a group of features is used to address the structure assessment multidimensional problem. Instead of a threshold value, a subspace is employed to determine failure presence. If the coordinates of the new sample are outside the designated space, an alarm is reported. This approach is described in the literature as novelty detection or anomaly detection. The cited examples of this strategy are related to bridge tendons [
6], where the authors developed a convolutional autoencoder. Another example dedicated to bridges is presented in [
7], where the authors propose a one-class kNN model based on Mahalanobis-squared distance. Another example is described in [
8], where several online novelty detection algorithms for gearboxes were proposed. When appropriate labels are assigned to multidimensional data, it is possible to develop a classifier. It extends the capabilities of novelty algorithms by dividing the feature space into subspaces that different machine states define. Some examples of this strategy are concerned with gearbox monitoring. The authors of [
9] present a system based on a morphological filter and a binary tree support vector machine (BT-SVM). The second reviewed work [
10] related to gearboxes describes the application of decision trees and SVM. Other reviewed works were dedicated to the monitoring of bearings. In [
11,
12], the authors proposed a quadratic classifier; in [
13], features were extracted using an autoencoder and applied for state assessment. Other approaches are depicted in [
14,
15], where the authors describe classifiers trained on the dataset with a low number of labels. In [
14], the researchers used a convolutional autoencoder, and in [
15], a semi-supervised deep learning model was developed.
The approaches described above are templates. Detailed implementation requires specialist knowledge and experience in developing diagnostic systems for similar devices. Therefore, an idea emerged of proposing a recommendation system that would support the work of diagnostic system designers. The proposed system should tackle two main challenges. Firstly, each structure requires a specific monitoring approach due to potential sources of failure. Thus, the developed system should determine the analyzed structure profile based on contextual information. The second issue is related to a measure of the recommendation quality. In CM, such information is achievable as diagnostic results. However, it is often qualitative in form, which is not suitable as feedback information in recommendation system development. Therefore, it was necessary to propose a quantitative measure appropriate for the system.
Considering the paragraph, it is reasonable to apply fuzzy logic systems (FLSs). This would allow for the incorporation of expert knowledge into the recommendation system. The only example of an autonomous recommendation system for SHM can be found in a paper by Kung et al. [
16]. It is an ontology-based approach that contains a glossary of terms developed for data exchange between collaborating teams. At each step, the system interacts with the user via mediators. This part of the system searches a constructed ontology to propose tools useful at a given analysis step.
The data exchange that underpins the proposed decision support system is also related to a new monitoring approach called population-based structural health monitoring (PBSHM). In contrast to the current monitoring strategy, where only data collected for a structure are used for the condition assessment, in PBSHM the information on the similar object population is applied. If the objects are identical and operate under very similar conditions, then it is possible to transfer diagnostic information to determine the range of damage indices considered to be the undamaged condition of the object [
17]. For structures that do not satisfy the above requirement, the similarity measure must be calculated [
18] in order to determine which part of the diagnostic information can be transferred [
19,
20]. The recommendation system presented in this paper is a solution to the problem of knowledge transfer between non-identical structures. It utilizes a database containing data for different objects operating under various conditions. The system proposes the processing algorithms that provided the best result when monitoring structures with the highest similarity to the analyzed one.
Thus, the main goal of this paper was to propose a framework for a system dedicated to supporting the process of processing algorithms development for condition monitoring. The system requires a database with historical data from previously analyzed structures and contextual information described in a quantified manner. Based on these, the system suggests processing algorithms that are the most appropriate for the considered monitoring problem. The remaining part of the paper is organized as follows:
Section 2 presents a short overview of recommendation systems and the usage of fuzzy logic in recommendation systems.
Section 3 contains details of the proposed fuzzy-logic-based processing recommendation system.
Section 4 describes the framework implementation dedicated to gearboxes. The developed system evaluation and results are explained in
Section 5. Finally,
Section 6 presents the conclusions.
2. Related Work
Recommendation systems are inseparably related to the Internet and especially web browsers. Without them, it would be impossible to search the massive collections of data stored. The foundation of all recommendation agents is information filtration [
21]. Four basic approaches are mentioned among researchers dealing with this topic: collaborative-filtering-based, demographic-filtering-based, content-based, and knowledge-based approaches [
22]. In addition to these, other concepts have also been developed, such as social-network-based, context-awareness-based, and grouped-recommendation approaches, as well as hybrid methods that are a combination of those previously mentioned [
23].
In a content-based approach, the system uses item features to recommend another item similar to user preferences based on their previous actions or explicit feedback [
24]. The collaborative filtering approach employs the recommendation pipeline similarity of users and items to provide suitable items. The collaborative filtering models can recommend an item to user A based on the interests of a similar user, B [
24]. Demographic filtering has in common with collaborative filtering the similarity between users. However, the similarity measure is calculated based on demographic data such as age, gender, and occupation. Users are classified into stereotyped sets. The system generates recommendations that have found the highest approval in this group [
22].
The recommendation system is knowledge-based when it makes recommendations based on specific user queries. It may encourage the user to provide a series of rules or guidance on what results are required or provide an example of an item [
25]. There are two types of knowledge-based recommendation approaches: case-based and constraint-based approaches. Both utilize similar fractures of knowledge, but they differ in the way solutions are calculated. Specifically, case-based recommenders generate recommendations based on similarity metrics, whereas constraint-based recommenders mainly exploit predefined knowledge bases that contain explicit rules about how to relate user requirements with item features [
22]. Defining the problem as described allows for the application of FLS. Such a system contains implemented rules which establish the main operation and generalize in unforeseen cases. The mentioned approach enables the development of recommendation systems that rely on imprecise information provided by users.
The FLS was implemented in various recommendation applications [
26]. The most commonly used application is the recommendation of services or wares. One such system is described in [
27] for consumer advice in computer parts selection. Another customer application is presented in the paper [
28], where, based on contextual information such as time duration and desired condition, the system selects the best offer for the buyer.
Fuzzy logic systems have found utilization in other applications not related to e-commerce. The majority of them are not dedicated to engineering problems. One can be found in [
29], which supports the online learning process, proposing suggestions about class activities. As feedback, the students’ engagement is measured by the facial expressions captured by the camera. Another application described in paper [
30] is a system recommending a diet for people with diabetes. The authors proposed a system structure based on an ontology model representing domain knowledge as a graph of concepts. Another based on an ontology system [
31] is built on a patient’s medical history and can recommend diet and medication. Medical measurements such as blood pressure, sugar level, or heart rate are used as input data. Along with the Internet of Things network, it provides the doctor with data by enabling constant monitoring of the patient’s condition. The last presented in this review of examples of fuzzy-logic-based recommenders are presented in [
32]. An application of a developed knowledge-based system is for a field engineers’ work assistant by suggesting the most suitable tasks.
The overview presented in the above paragraphs revealed that the dominant trend in recommendation systems using fuzzy logic is the knowledge-based structure. Therefore in the developed recommendation system, the knowledge-based approach is also employed. According to the system’s terminology, the cases are previously monitored machines, and the constraints are context information that includes experiment conditions, the variability of measured signals, and expected diagnostic problems. The following section is devoted to the description of the framework.
3. System Framework
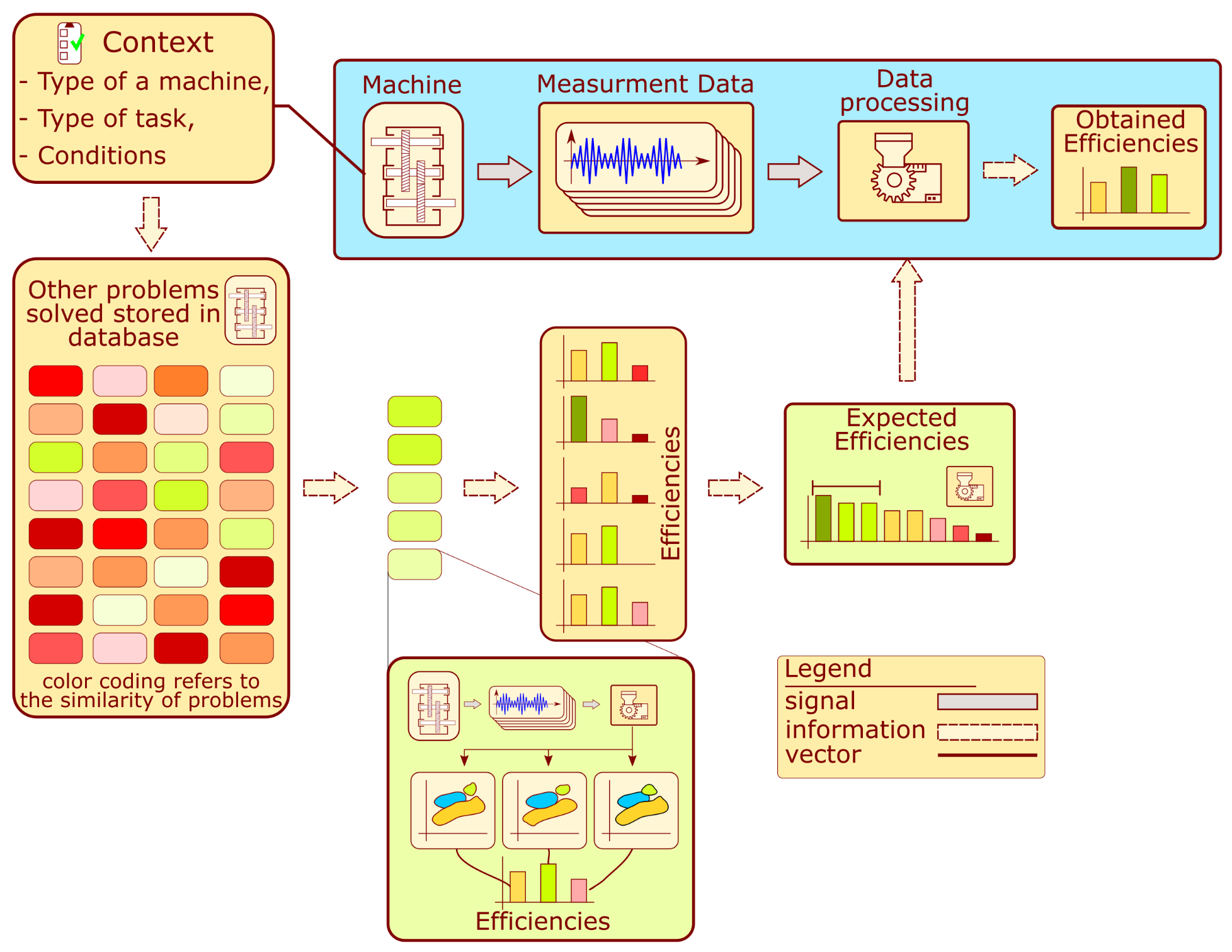
The operation of the system is described by the block diagram shown in
Figure 2. The monitoring system development for a given machine requires contextual information about its type, the conditions under which it operates, and the collection of measurements. The context information is acquired by filling out a survey, which is further processed to determine the similarity measure. The similarity is calculated concerning other problems analyzed in the past and stored in the database. Each machine analyzed in the past presented on the schematic is represented by a color rectangle. The green color indicates that a given problem from the past has a high similarity value, while red has a low similarity. The several machines analyzed in the past which have achieved the highest similarity value are selected. Each problem contains several solutions proposed during the development of the processing algorithms. These solutions are compared with each other using an efficiency measure. Unique processing algorithms are selected and sorted according to past performance and similarity to the analyzed problem. The several algorithms that achieved the highest score from the comparison are chosen. These algorithms are proposed for the development of a machine condition evaluation algorithm.
The following assumptions are required regarding the set of structures analyzed in the past:
The database contains signal processing prescriptions and diagnostic outcomes from many objects with different levels of similarity to the problem at hand. At least some of these similarity levels are very high in meaning, and the very similar problems were already solved.
These structures were previously monitored using various signal processing and classification approaches.
There exists a description of the structures regarding their design and the conditions under which they operate.
Note that the proposed approach is expected not to provide a completely new set of processing methods but rather to choose a solution that is likely to produce a high outcome in a given scenario. For that reason, the database is required to contain at least some very similar objects. For instance, diagnosing an epicyclic gearbox for a wind turbine would indicate that other epicyclic gearboxes working under similar operational conditions should be available in the reference set.
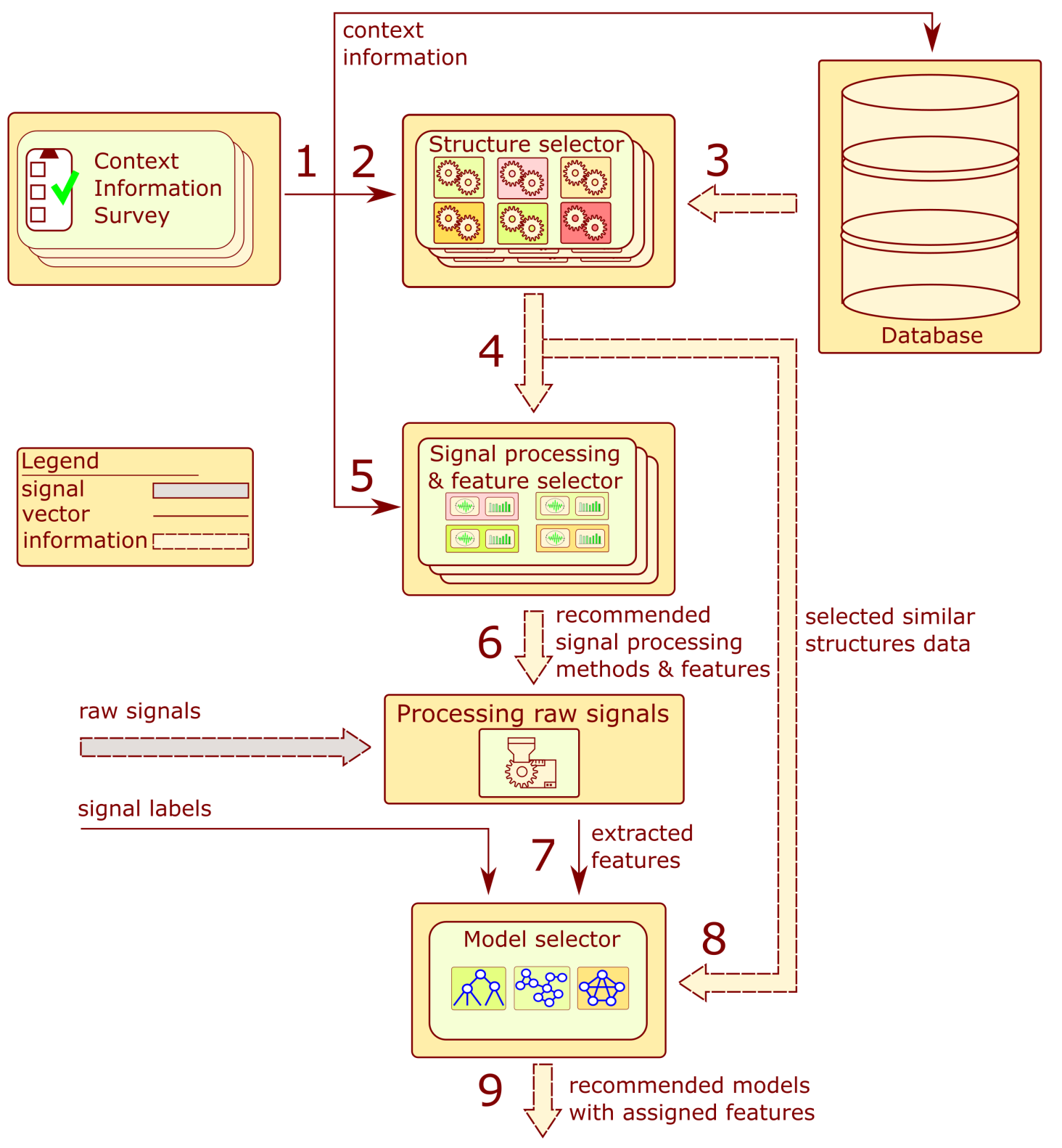
A more detailed framework of the recommendation system is presented in
Figure 3. The system consists of six main components: the context information surveys, database, structure selector blocks, signal processing, feature selection blocks, processing raw signal block, and model selector. The arrows indicate a flow of data within the system. The order of operations performed by the system corresponds to numbers in
Figure 3.
In the first step, an adequate survey is completed for context information about the structure. Steps 2 to 6 are performed without human intervention. The context information is employed to calculate a measure of similarity to the structures stored in the database. A list of structures with the highest similarity value is selected. The historical information about signal processing and extracted features from those objects is applied to develop a list of recommended signal processing methods and features.
The signals provided by the user are processed according to the proposed algorithms to extract feature values from signals. The calculated values with the provided labels constitute the training set employed to recommend the model type. The following subsections contain a detailed description of the hinted blocks.
3.1. Context Information Survey
The context information is provided utilizing surveys filled out by an operator. The questions in the survey belong to the following thematic categories:
Variability in operational parameters associated with speed and load variations. This group includes context inputs with the following tags: speed_variability, speed_order, load_variability, load_order.
The method of conducting the experiment related to the sensor, its location, and the phase marker signal. This group includes context inputs with the following tags: phase_marker, sensors_bandwidth, sensors_location, sensors_direction, sensors_type.
Type of problem indicating a potentially damaged component and an indicative number of measurement data. This group includes context inputs with the following tags: problem_component, problem_labels, problem_type.
The specific questions depend on the category into which the monitored structure falls. The developed questionnaire can be found in
Appendix A.
3.2. Structure Selector Module
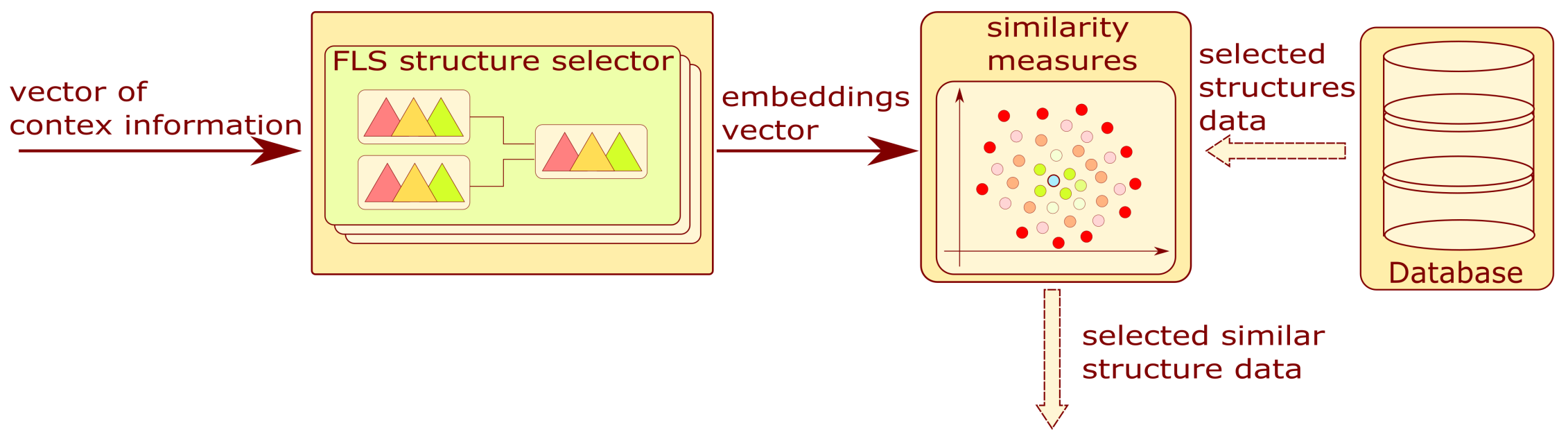
The block diagram is shown in
Figure 4. This module allows for the selection of similar structures. As a result of the completed survey, the context information is quantitatively encoded in a vector.
The mentioned vector is the input to the group of FLSs. Based on context information, one fuzzy system is selected. Each of these systems has four categorized outputs:
Embedding 1—Variation in operational parameters;
Embedding 2—Method of experimenting;
Embedding 3, 4—Type of problem.
The structure data were extracted as a result of the database query. For each selected structure, the similarity value is calculated from the Euclidean measure with the formula presented below:
where
is the Euclidean similarity measure,
are the values of the four embeddings calculated using the fuzzy logic system, and
are the values of the four embeddings for the
i-th structure acquired from the database.
The operation allows the system to narrow down the number of structures analyzed in the next step. The final result of this block is a list of structures with similarity measures.
The FLS structure selector is a parallel fuzzy tree where each branch is designated to evaluate the value of an assigned embedding. The architecture of the aforementioned subsystem will be considered in
Section 3.2.1.
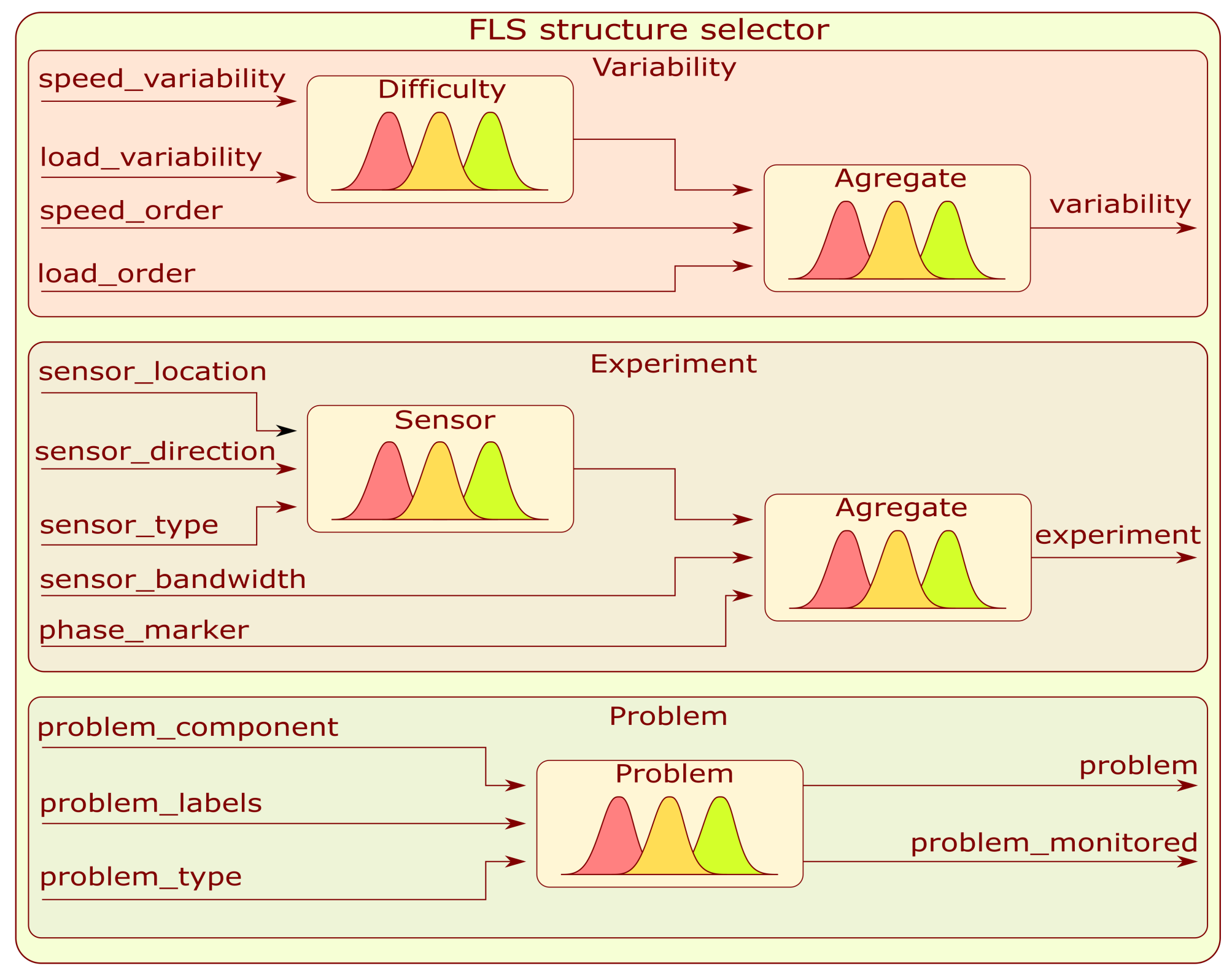
3.2.1. FLS Structure Selector
The FLS structure selector has a tree architecture with highlighted branches dedicated to a single embedding value. The first in order is the branch labeled as Variability. This system is a fuzzy tree composed of two fuzzy subsystems in a manner presented in
Figure 5. The first Sugeno-type FLS combines information about load with the speed variation to form a hidden variable called difficulty. The second Mamdani FLS combines the calculated hidden variable with load and speed order to determine the embedding value labeled as variability.
The second embedding branch labeled as Experiment is another fuzzy tree with a similar structure to Variability—
Figure 5. The first Sugeno subsystem is designed to merge sensor location, direction, and type to form a continuous hidden variable. Based on the extracted hidden variable, sensor bandwidth, and speed information, the second Mamdani subsystem produces an embedding value labeled as experiment.
The last developed subsystem labeled as Problem is dedicated to the type of condition assessment problem and a particular part that is to be monitored. It is composed of a single Mamdani-type FLS with three inputs: problem_component, problem_labels, and problem_type and two outputs: problem and problem_monitored. Information on the number of membership functions and rules depends on the type of survey conducted and the question. Details are provided in
Appendix B.
3.3. Signal Processing and Feature Selector Module
This module proposes signal processing methods and features. The signal processing methods are represented within the system as signal processing chains which contain algorithms divided into subroutines representing all necessary steps performed on the signal.
For instance, to detect the shaft imbalance, the speed signal needs to be examined for the extraction of the rotating velocity harmonics amplitudes. In the majority of monitoring systems, vibrations are measured as acceleration. To obtain the speed signal, it is necessary to integrate it numerically. This operation results in a trend related to the introduced integration error that can be removed with a high-pass filter or a detrending algorithm. The harmonics analysis is best for representing the signal in the frequency domain by carrying out a digital Fourier transform (DFT). In a derived processing chain, the operation can be expressed as signal detrending–integration–high-pass filtering–DFT.
The block diagram of the analyzed module is presented in
Figure 6. The input is a vector of context information and selected similar structure data. The algorithm filters the processing chains and features related to a structure by assigning probability values to them. The result of the subsystem is a list of chain collections and features sorted in probability value order. More information on the data filtering algorithm and chain collections can be found in
Section 3.4 and
Section 3.6.
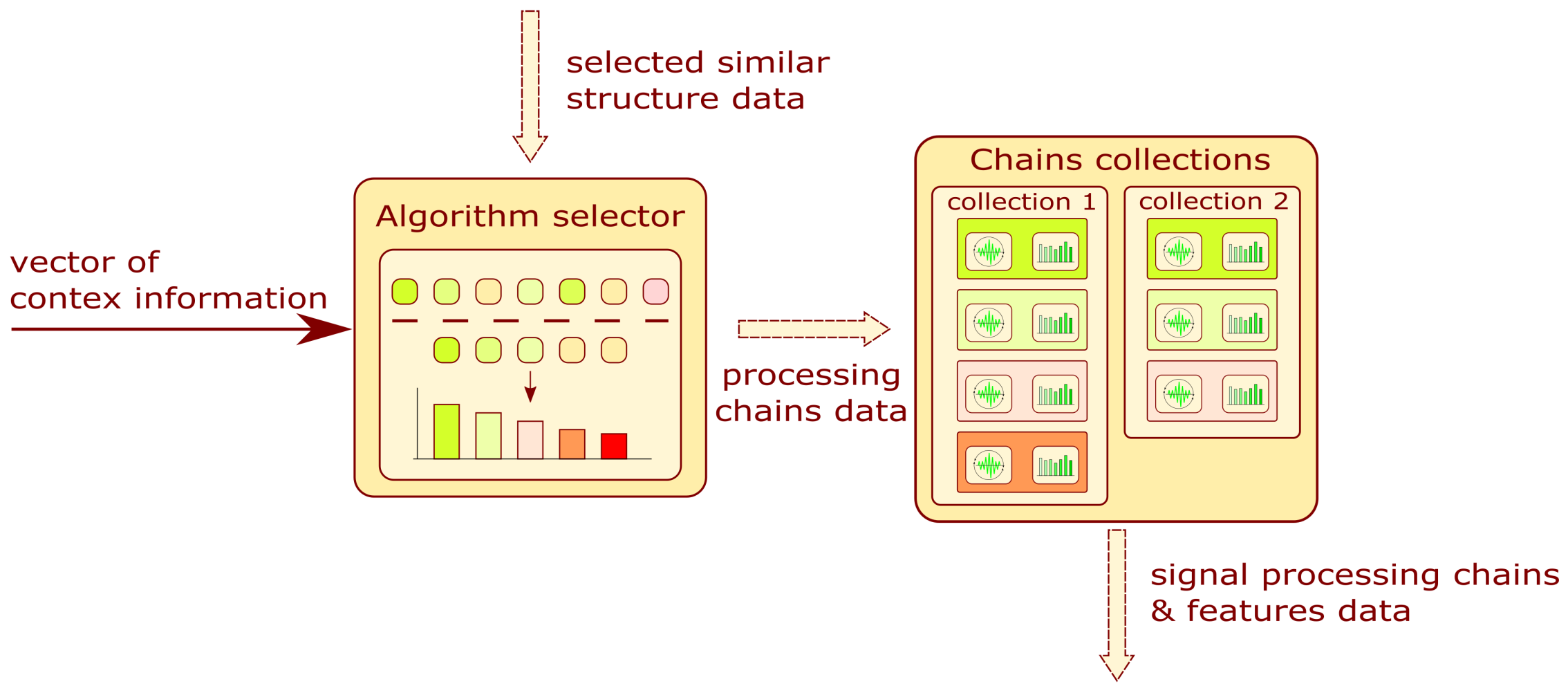
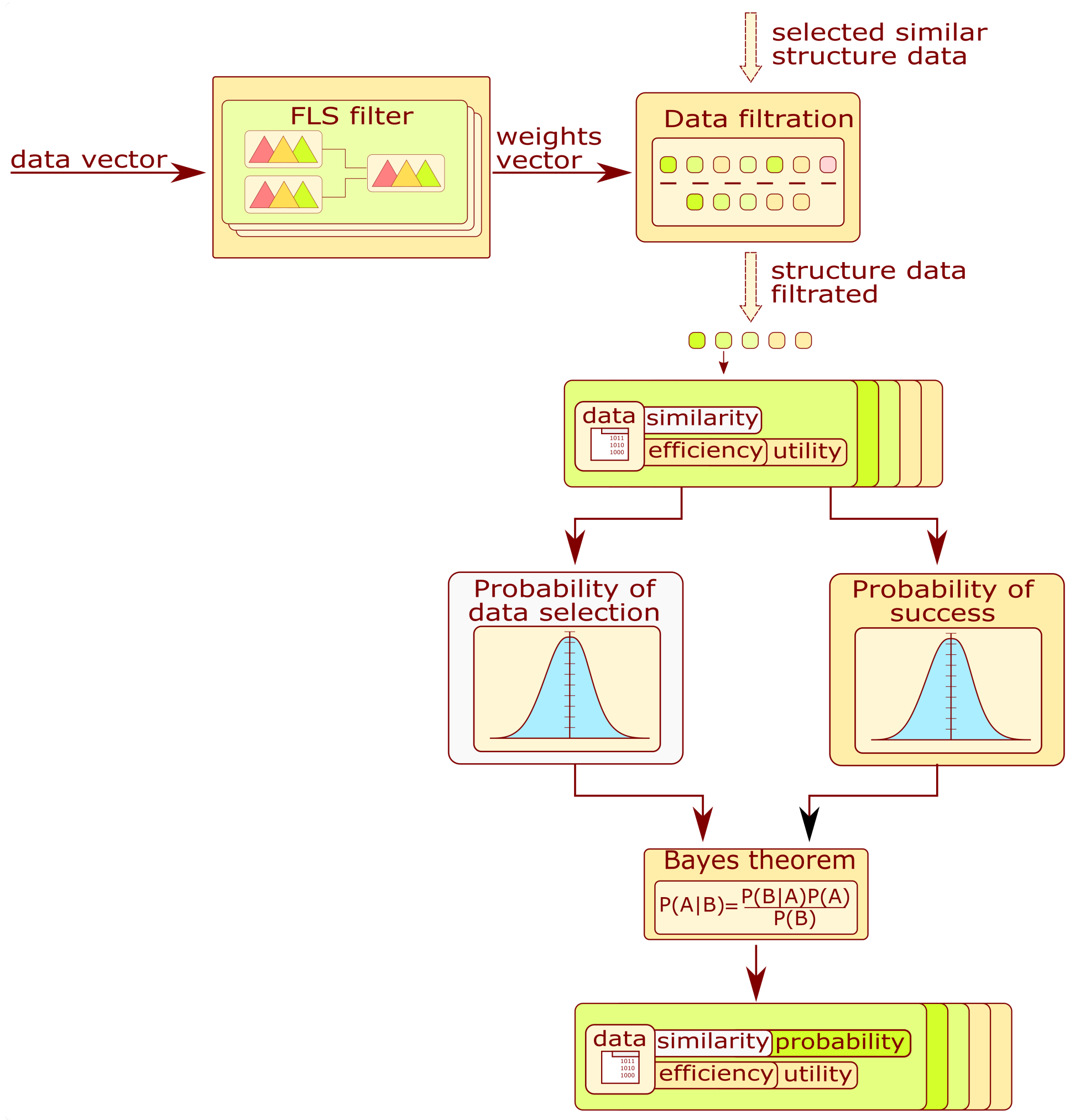
3.4. Algorithm Selector
The purpose of this subsystem is the proposition of algorithms applied for signal processing or the assessment of the structure state. The block diagram describing information flow in the module is presented in
Figure 7. The fuzzy system is selected and fed with this vector to produce the weight for each signal processing chain or model type. That values are employed to filter structure data obtained by structure selectors (
Section 3.2). Each algorithm is assigned the utility value calculated from the weights. The utility value for an algorithm can be expressed by the geometric mean:
where
is the weight value obtained from the FLS, and
n is the number of data subentities. For the signal processing and feature selector,
n is related to the number of methods in the processing chain. For the model selector, the value is set to 1. After these calculations, the system discards the data entities whose utility level is below the threshold of 0.5. As a result of filtration, their number is reduced.
In the next step, the probability of selecting an algorithm given the condition of success is calculated. The algorithm for calculating the coefficient is presented in
Figure 7. The similarity value is assigned to the algorithms related to database structures. Based on those values and the number of algorithms, the probability of selecting the algorithm is formulated as
where
is the
i-th algorithm,
is the similarity value for the
i-th structure for which the algorithm was used, and
is the number of unique algorithms. Each algorithm contains an attribute called the efficiency coefficient. It describes the result obtained during the structure condition evaluation on the test set. By applying this information and the utility value, the probability of a correct assessment (
) given the algorithm selection is calculated from the following equation:
where
is the efficiency value of the
i-th algorithm and
is the utility value.
The probability of selecting an algorithm given the prior knowledge of a correct assessment can be expressed by introducing the Bayes theorem.
As a subsystem result, filtered data entities are sorted in decreasing order of probability. The probability expressed by Equation (
5) is expressed for the signal processing and feature selector as
,
and
and for model selectors
,
, and
.
The fuzzy system configuration for the data filter is a parallel fuzzy tree where a single branch is designated to recommend a single data entity. The architecture of the mentioned tree will be considered in
Section 3.4.1 for the signal processing selector and in
Section 3.5.2 for the model selector.
3.4.1. Data Filter for Signal Processing Methods
Each signal processing method filter branch is a Mamdani-based fuzzy system dedicated to a single processing method. Each of the mentioned systems contain four inputs. Three of them correspond to three values from the context information described in
Section 3.1: phase_marker, sensors_type, and problem_component. The fourth input is the variability value extracted from the model described in
Section 3.2.1. The number of Gaussian membership functions is different for each input, but together they cover the whole input range evenly. The output contains five Gaussian membership functions (very_low, low, medium, high, and very_high) that evenly cover the value range from 0 to 1. Information on the construction of fuzzy rules can be found in
Appendix C.
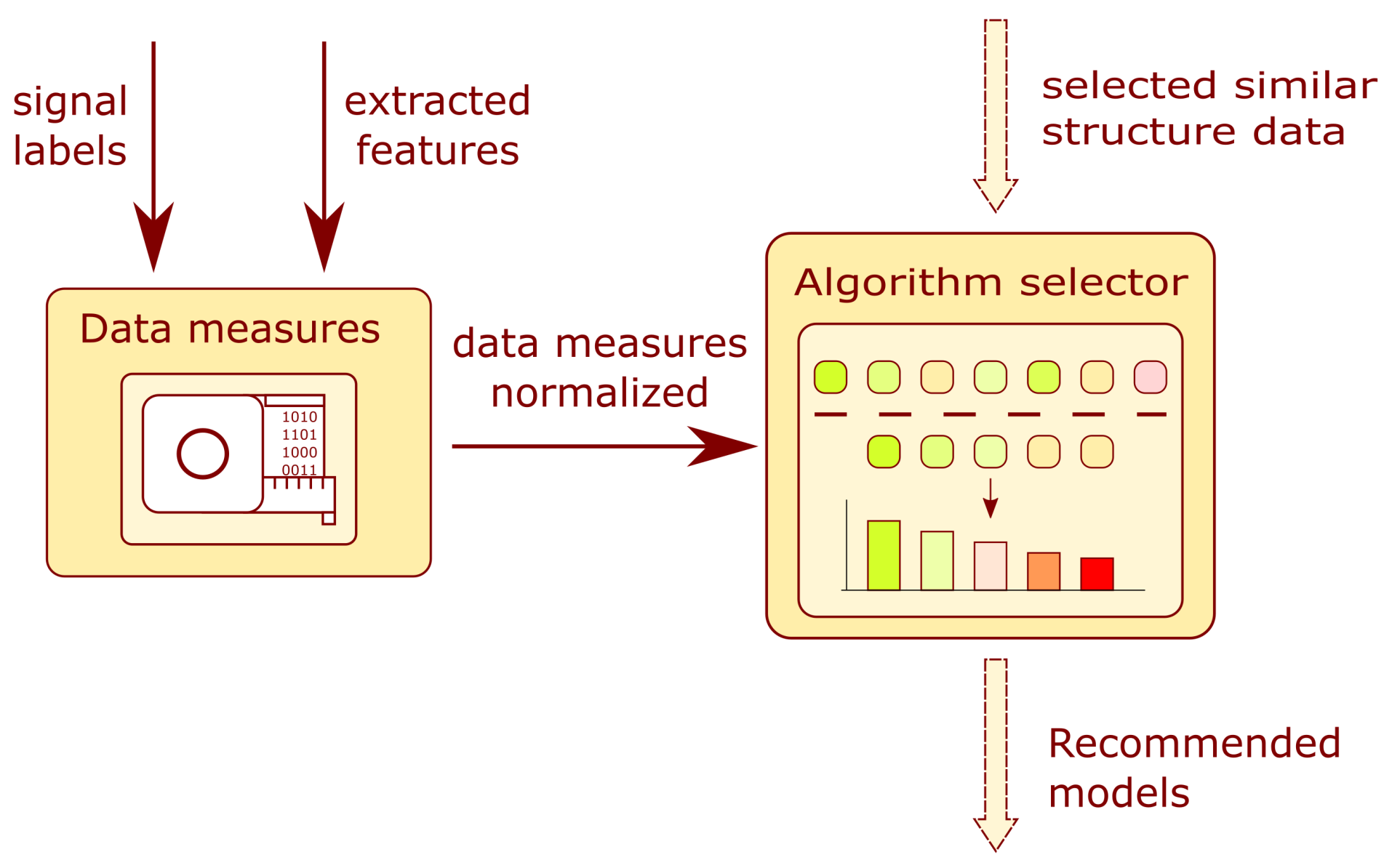
3.5. Model Selector Module
The module schematic is presented in
Figure 8. The module is composed of two main blocks: the data measures and the algorithm selector. The arrows indicate the flow of information in the system. The user provides the system with a prepared training dataset. For the prepared dataset, measures are calculated which describe the data structure. Combining both information forms, the data measures and the similarity of the structures, the data selector determines a list of recommended models applying a data filtering algorithm. More information on the topic can be found in
Section 3.4.
3.5.1. Data Measures
This subsystem allows for a quantitative description of the data structure in the training dataset. The input to the block is a vector containing training examples of form such that is the feature vector and is the target label of the i-th sample. The output of the subsystem is a vector of the following measures:
The number of training examples—;
The number of input features—;
The number of output target labels—;
The measure of a non-uniform spread of data among clusters—;
The clusters-to-targets ratio—;
The clusters’ mean diversity—.
All extracted measures from the training set are subject to normalization.
The measure of a non-uniform spread of data among the clusters coefficient is calculated as a standard deviation of a class presence probability. The feature allows for measuring whether the training samples are uniformly distributed among classes or whether some classes are under-represented. It is calculated using the following formula:
The clusters-to-targets ratio is defined by following equation:
where
is the number of the selected clusters by algorithm and
is the number of target classes. The
value is obtained by performing the following algorithm:
Estimate four optimal numbers of clusters by using four different cluster evaluation criteria:
The Calinski–Harabasz criterion;
The Davies–Bouldin criterion;
The Silhouette value criterion;
The Gap value criterion.
For each criterion, the optimal cluster value is stored in the memory. A more detailed description of the listed criteria can be found in the literature [
33].
From the calculated collection of optimal cluster amounts, the most frequent value is selected and assigned as the cluster number .
Clusters’ mean diversity measures target variability within clusters. The algorithm for the described feature contains the following steps:
The input feature space is divided into an optimal number of clusters ().
For each cluster, the probability of selecting a sample belonging to a given class () is calculated.
The dominant class with the highest probability calculated in the previous step is selected.
The probability of selecting a sample from the other classes is calculated according the following relation:
where
is the probability of selecting a sample from the dominant class
D given the
i-th cluster
.
Steps 3 and 4 are repeated until the probability is calculated for all defined clusters.
The cluster mean diversity is obtained from the following equation:
where
is the optimal number of clusters, and
is the weight factor for the
i-th cluster, defined by:
where
is the number of examples belonging to the
i-th cluster and
is the number of training examples.
3.5.2. Data Filter for Model Type
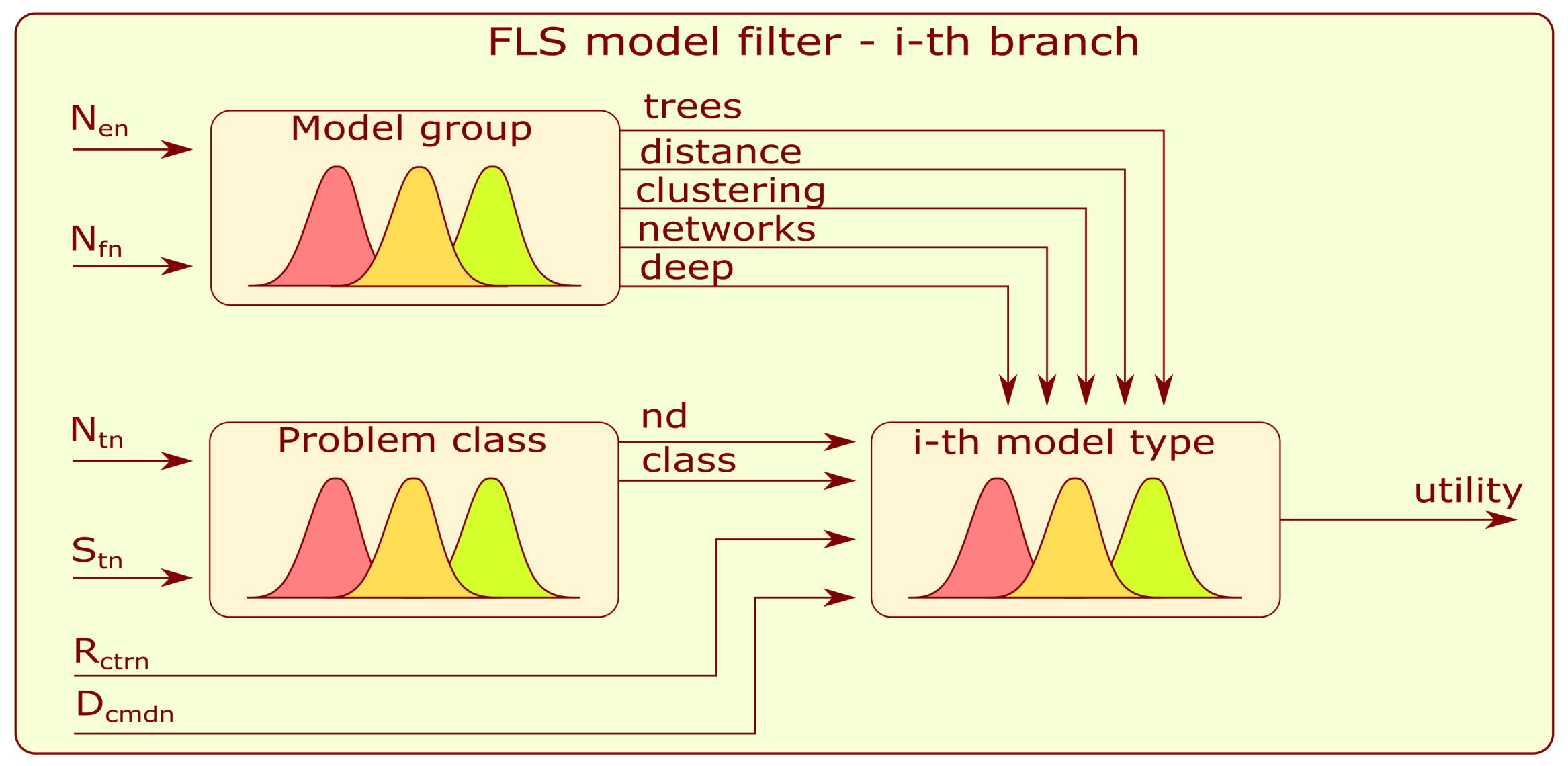
Figure 9 presents a detailed block diagram of the selected
i-th branch of model filter FLS. Each branch is composed of three subsystems: model group, problem class, and ith type of model.
Each FLS mentioned in this subsection is of the Mamdani type. The first to be described is the model-group FLS. Its five outputs are related to the following groups of algorithms: trees, distance-based, clustering-based, neural networks, and deep learning. The inputs to the subsystem are a normalized number of training examples and a number () of input features (). Each input and output contains five Gaussian membership functions (very_low, low, medium, high, and very_high) that evenly cover the value range from 0 to 1.
The FLS problem class has a similar structure to the first-mentioned model. The novelty detection () and classification () outputs refer to types of machine learning. The inputs to the subsystem are normalized values of the output target’s labels number () and the standard deviation of target classes (). Five Gaussian-type membership functions are assigned for input fuzzification.
The
i-th type of model combines information from the above-mentioned submodels and the additional normalized inputs: the clusters to targets ratio (
) and clusters mean diversity (
)—
Figure 9. The fuzzification and defuzzification procedures are similar to those for the two models described above, and five Gaussian-type membership functions are applied. The rules developed for the model filter can be found in
Appendix D.
3.6. Chain Collections
The recommended processing chains and features with assigned similarity, efficiency, and probability values are grouped into chain collections. The collections are prepared based on information about features used for training the recommended models. After preparing the collection, the algorithm discriminates in terms of its utility. The equation for this measure, for the n-th collection, is the following:
where
is the maximum value of efficiency obtained for the collection,
is the maximum similarity value obtained for the collection, and
is the sum of probabilities obtained for chains included in the collection. From the utility value
, a probability value of the collection recommendation is calculated, according to the following formula:
where
is the number of the collections.
4. Implementation of the Recommendation System
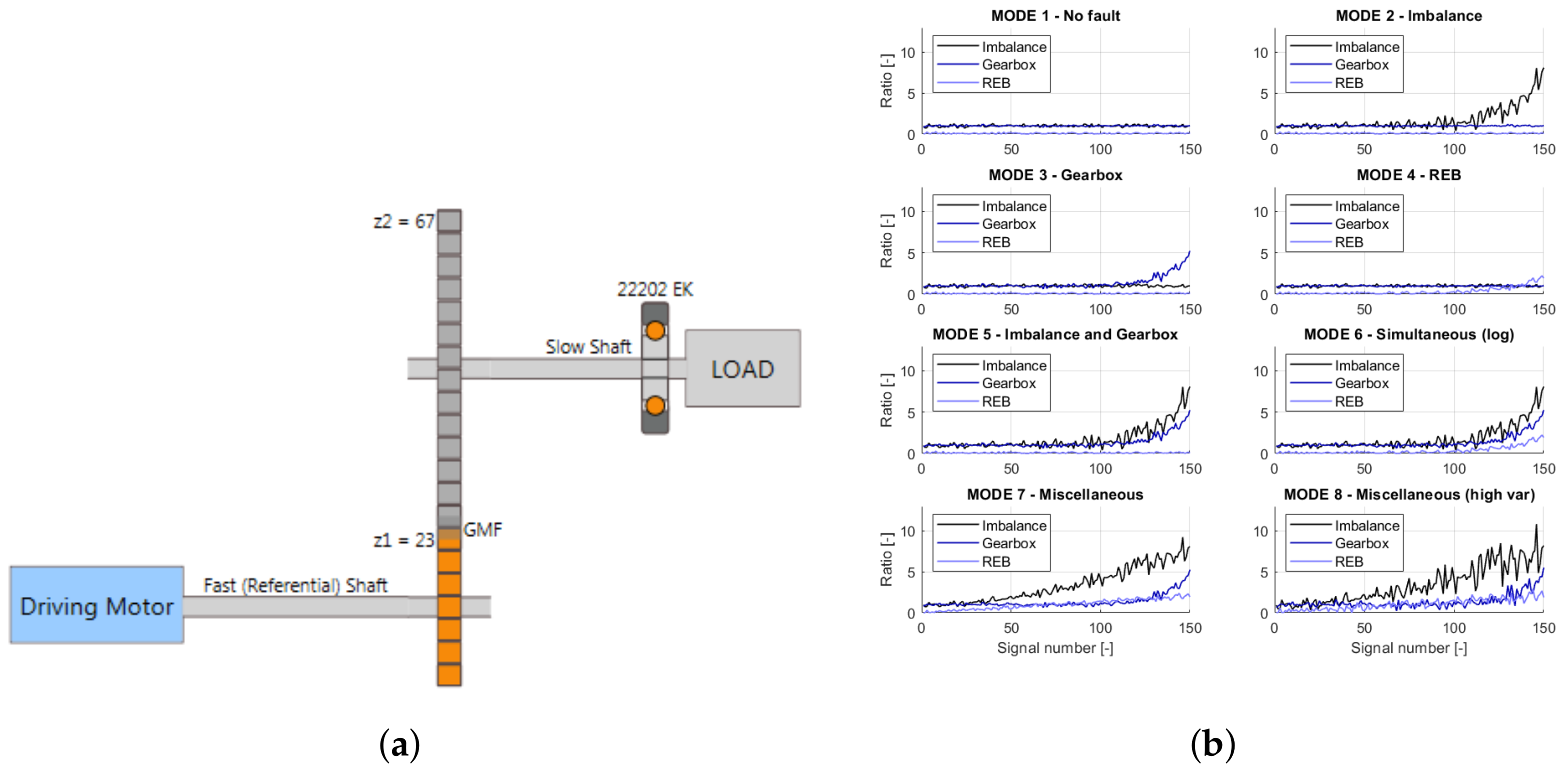
The framework was used to develop the system for parallel gearboxes. This involved developing a database of historically monitored gears. As a monitored structure, the object representing a simulated drivetrain was utilized. It included a driving shaft associated with referential speed, a one-stage gearbox, a slow shaft, and a rolling element bearing (REB) 22202EK. The gearbox was used for speed reduction, with 23 teeth on the driving shaft gear and 67 teeth on the slow shaft gear. The total transmission ratio was 23/67 = 0.34328. The kinetostatic diagram of the simulated object is presented in
Figure 10a.
The simulated object operates at several nominal speeds from 2400 to 6000 rpm, with a different speed fluctuation from around 3 to 3000 rpm. The simulated data represent eight modes of object structural failures. The list of existing failure modes is presented in
Table 1. Each failure mode is represented by the failure development function (FDF) that determines the particular fault evolution. For vibrational signal generation in the failure mode, the simulated object requires three FDFs, which indicate the shaft, gearbox, or bearing faults. The sample FDFs for a nominal velocity of 3000 rpm are presented in
Figure 10b. Each mode contains 150 independent vibrational signals, a 10 s time window, and a sampling frequency of 25 kHz. In addition to the vibration signals, a phase marker signal was generated for half of the objects. More information about the simulated object itself and the algorithms behind signal generation can be found in [
34].
4.1. Signal Processing and Feature Extraction
The prepared dataset was processed to extract indicators sensitive to the presence of damage. During years of research related to vibrodiagnostics, many signal processing and feature extraction algorithms have been proposed, from the fundamental calculation of the raw-signal root mean square (RMS) to more sophisticated spectral kurtosis. A detailed description of various processing algorithms dedicated to CM can be found in [
34,
35]. Based on the information in the literature and the visual inspection of the indicators, the signals were processed. A detailed list of the signal processing algorithms and the extracted features is collected in
Table 2.
4.2. Trained Models
For the calculated features and labels stored in the database, a training set was prepared. The final goal of this operation was to obtain a quantitative assessment of the extracted features by training multiple models. These algorithms were diversified in terms of type and operations related to the clusters division of the training set, distances, or trained weights. The list of model types and their parameters are presented in
Table 3.
4.3. Test Structures
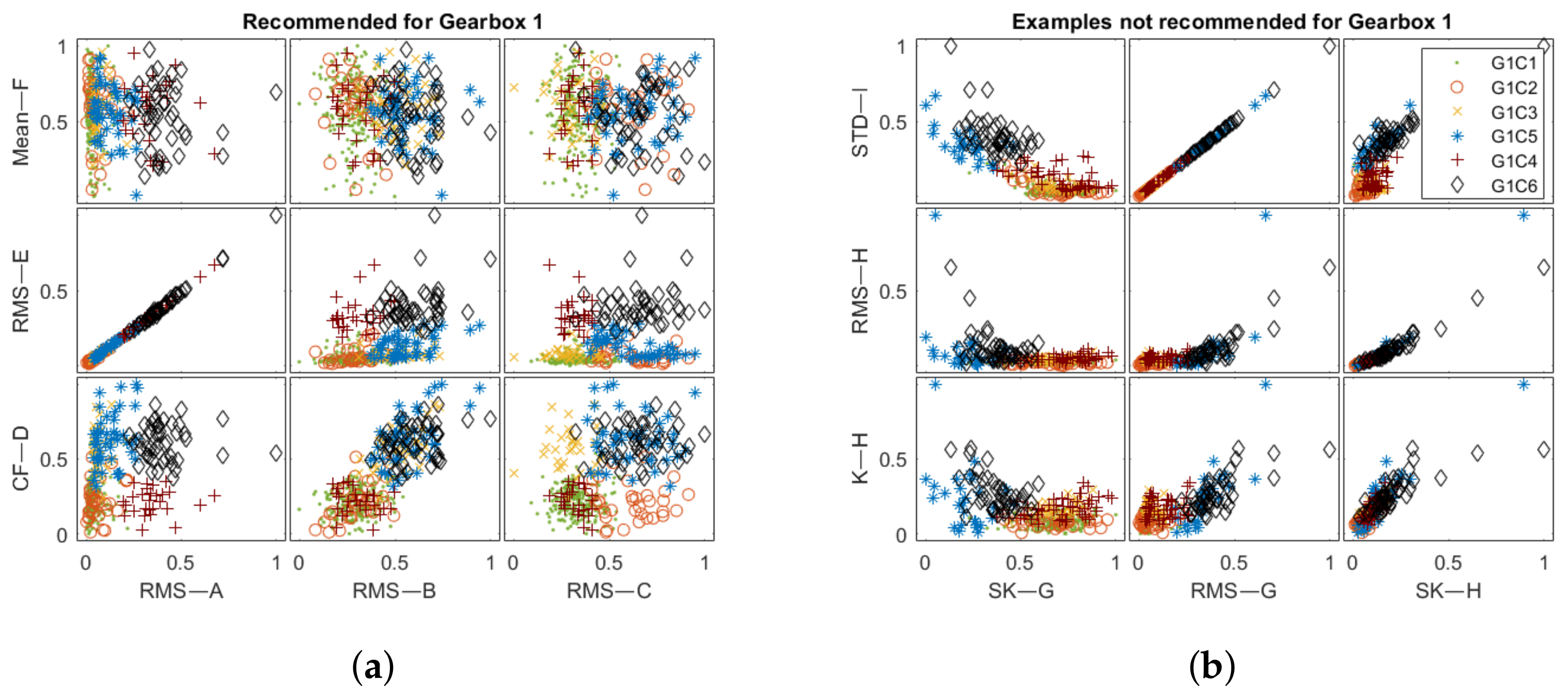
To evaluate the developed system, two datasets for parallel gearboxes were prepared. The first dataset was obtained for the simulated object of a one-stage gearbox (Gearbox 1), the schematic for which is presented in
Figure 10a. The vibration signals were acquired for eight fault modes presented in
Figure 10b, where the object worked at a nominal rotational velocity of 4200 rpm with 1020 rpm fluctuations, not present in the database. The 400 signals with phase markers were generated to construct the test set. For this structure, labels were designated based on the failure development function values presented in
Figure 10b. If the function values exceeded those for mode 1 (
Table 1), a label was assigned to the signal. In total, a set of six different labels describing the following states of the structure was prepared: G1C1, undamaged; G1C2, imbalance; G1C3, gear meshing fault; G1C4, bearing fault; G1C5, imbalance and gear meshing fault; and G1C6, imbalance, gear meshing fault, and bearing fault.
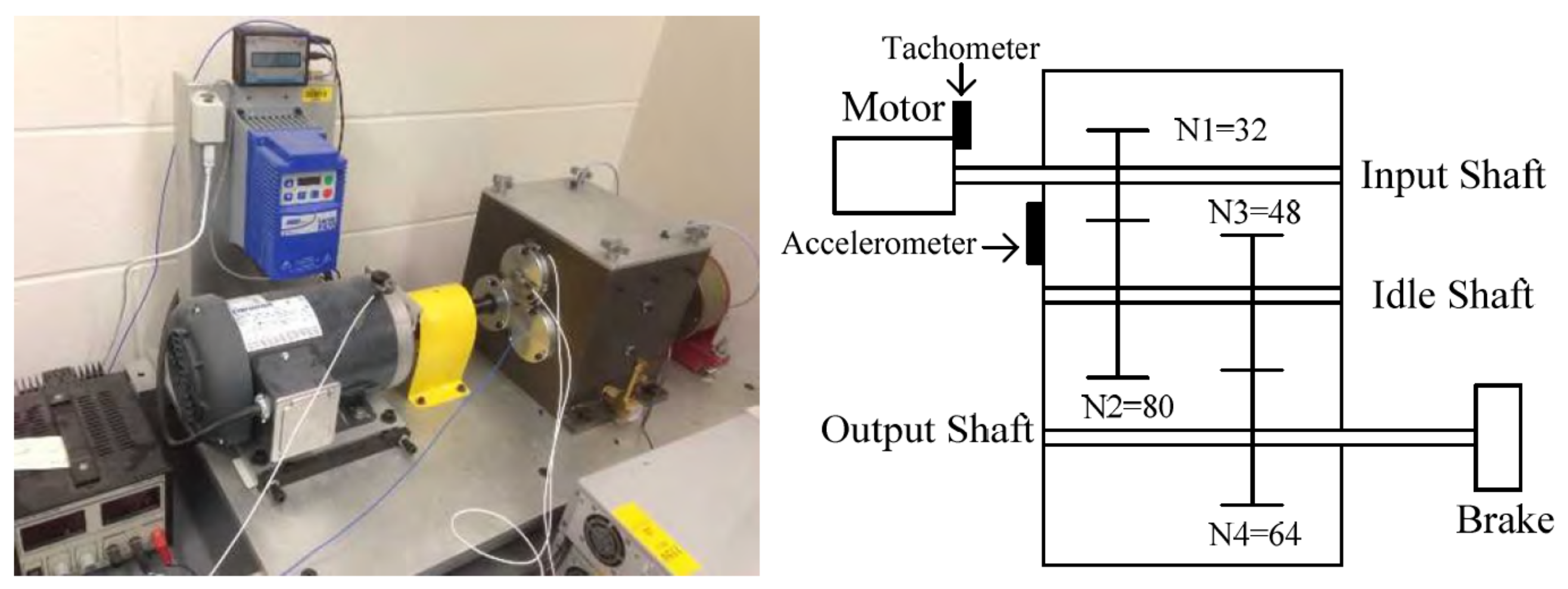
The second dataset was obtained for a two-stage gearbox (Gearbox 2), the schematics for which are presented in
Figure 11. The signals were acquired for multiple faults, such as missing tooth, root crack, spalling, and chipping tip with five different levels of severity. The data were recorded in the angle domain with 900 samples per revolution. The dataset was first presented in [
36] and is available for free. The inputs vector for the analyzed gearboxes and vectors for similar structures are stored in
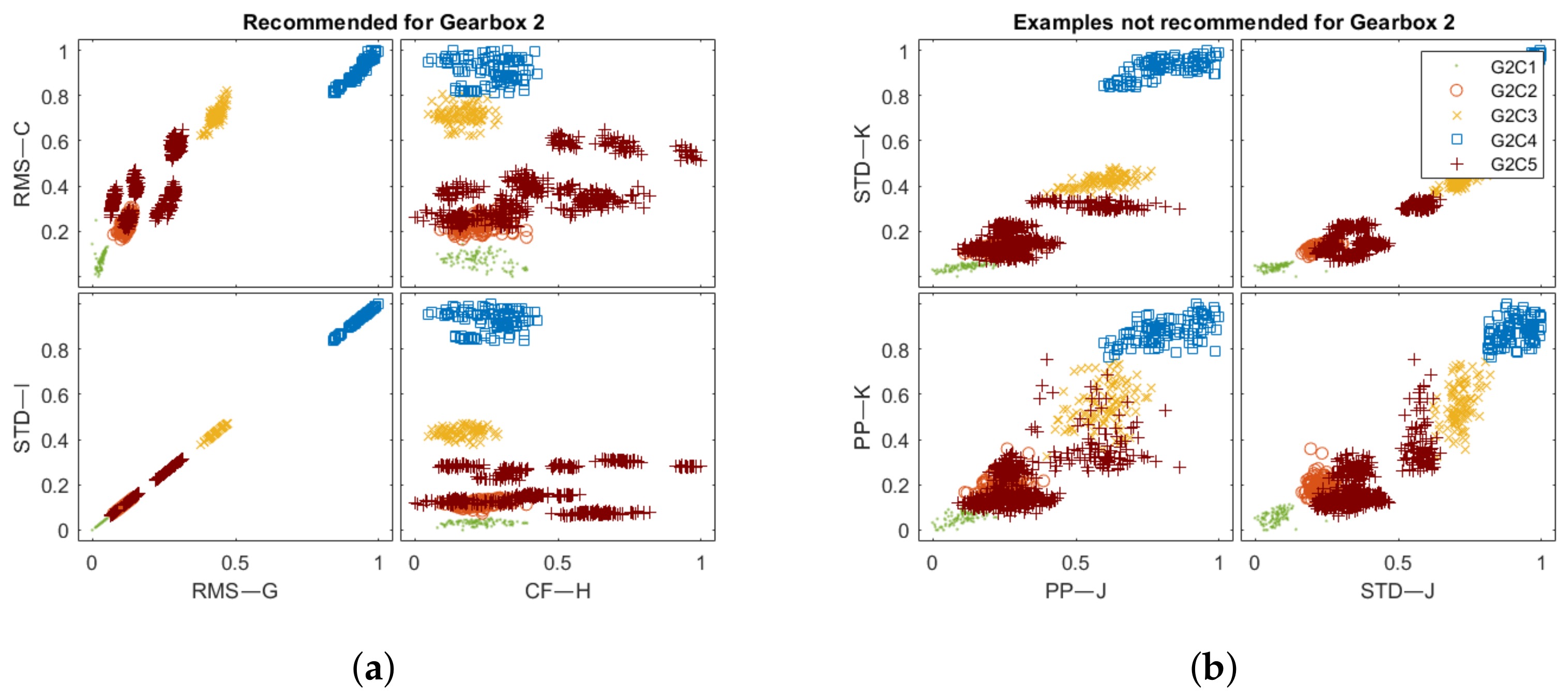
Table 4. For Gearbox 2, the labels were assigned directly from the measurement series names. In total, the set of five different labels describe the following states of the structure: G2C1, undamaged; G2C2, missing tooth; G2C3, cracked tooth root; G2C4, spalled tooth surface; and G2C5, chipping tooth tip.
4.4. Recommendation Algorithms Accuracy
To evaluate recommendation algorithms, two metrics were proposed: class accuracy and total accuracy. The class accuracy is defined as:
where
is the number of correct model predictions within the class in the test set,
is the total number of samples belonging to the mentioned class in the test set, and
is the class accuracy. The formula for the second measure is presented by the following equation:
where
is the number of correct model predictions in the test set,
is the total number of samples in the test set, and
is the accuracy value. For an unbiased selection of the test set, cross-validation was performed. The procedure contained 30 iterations, while each model was trained 10 times by randomly selecting 10% of the samples for the test set.
6. Summary and Conclusions
This article presents a processing recommendation system for condition monitoring based on fuzzy logic. The system structure is knowledge-based, and the recommendations are proposed based on contextual information. The main part of the proposed system is a database in which historical data from previously analyzed structures are stored. Based on calculated embedding values, similar objects are selected. The obtained data are further filtered by subsequent subsystems for better adjustment to the analyzed problem.
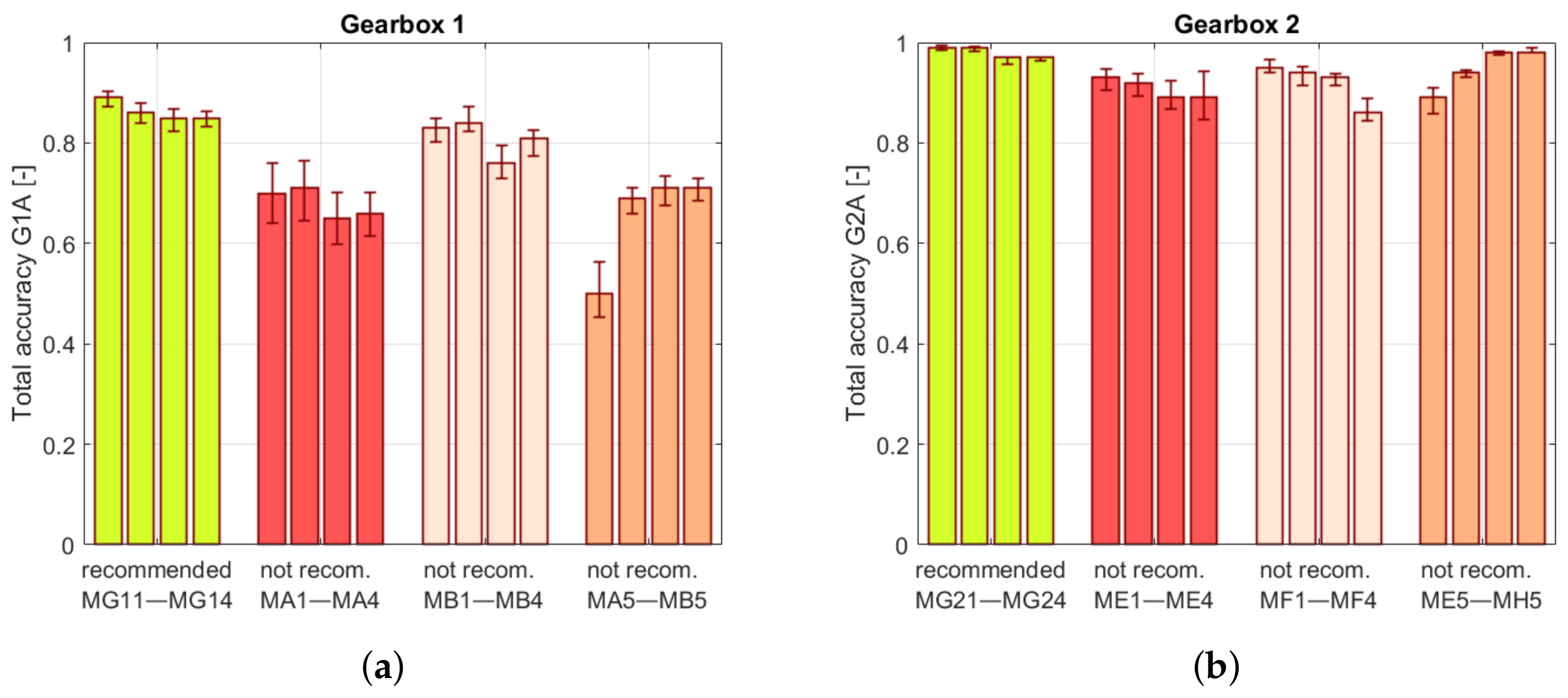
The article contains an implementation of the framework and a test of the presented system by processing data for two structures. The first is virtual objects that simulate signals collected from a single-stage parallel gearbox. The second is a two-stage gearbox. The system recommended processing algorithms, which were then compared with others that were not recommended, selected arbitrarily. All algorithms were applied for processing data from test objects. The obtained results reveal the feature space and classifier accuracies. The results presented prove that the processing algorithms proposed by the system showed, on average, a from 5 to 14.5% higher accuracy according to all proposed metrics. It indicates that the recommender system structure can produce valuable processing recommendations which facilitate the condition evaluation process.
The proposed recommendation system also contains limitations. The processing algorithms were selected from those available in the database. Thus, the problem solution is not necessarily optimal in global terms. However, by increasing the amount of historical data from structures operating under various conditions, the recommended result will be closer and closer to the optimal solution.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













