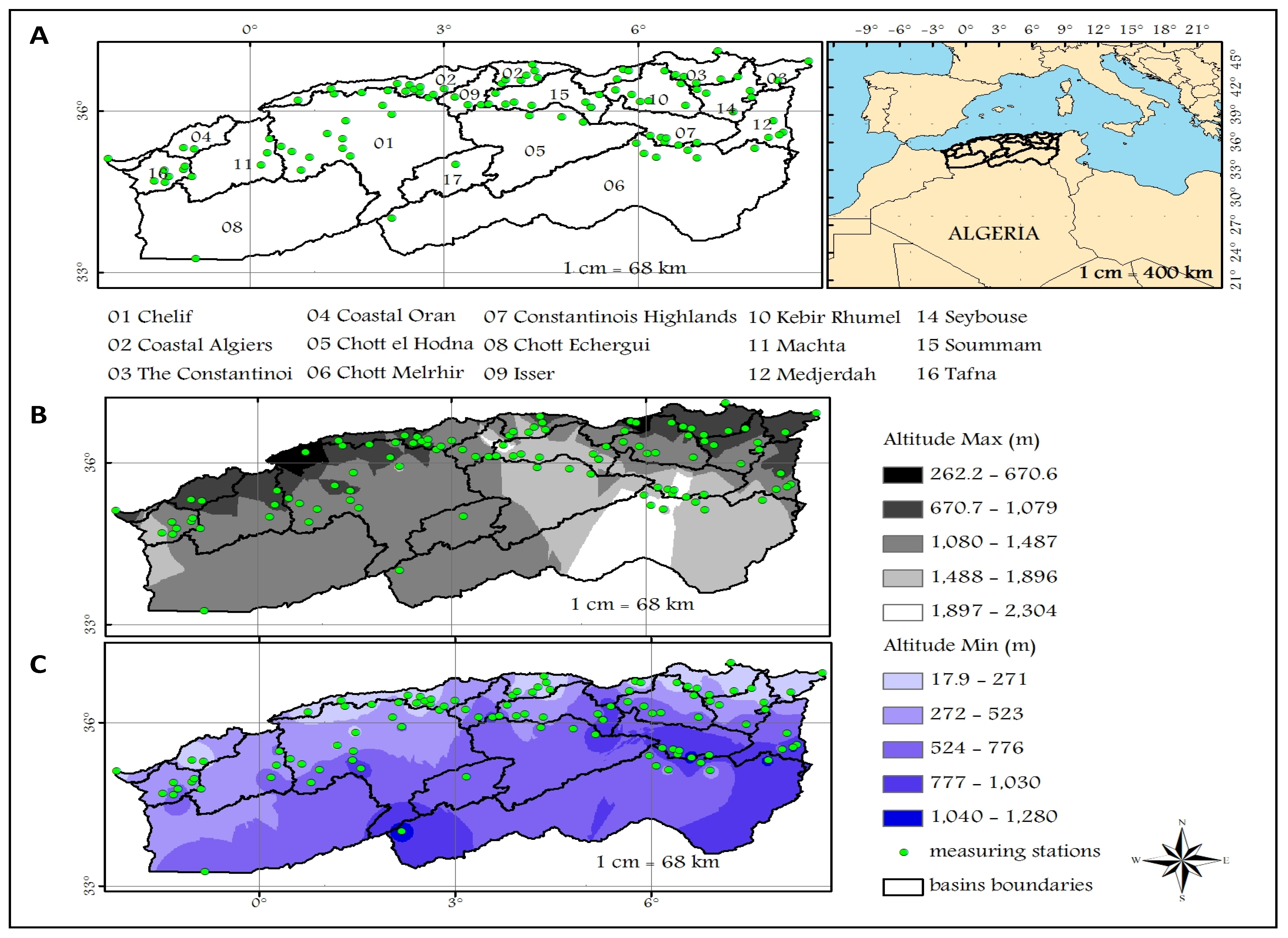
In this section, we start our study by spatially analyzing and classifying the input data used by each sub-model. Then we show the ANN design, such as the choice of input data by the selection criteria, the regression equation used as a transfer function, and the output results, which are mainly used to estimate the residual data (IARR’). Finally, the computational and calibration steps followed to obtain the runoff equation are given in detail in the last part.
3.1. Data Description and Classification
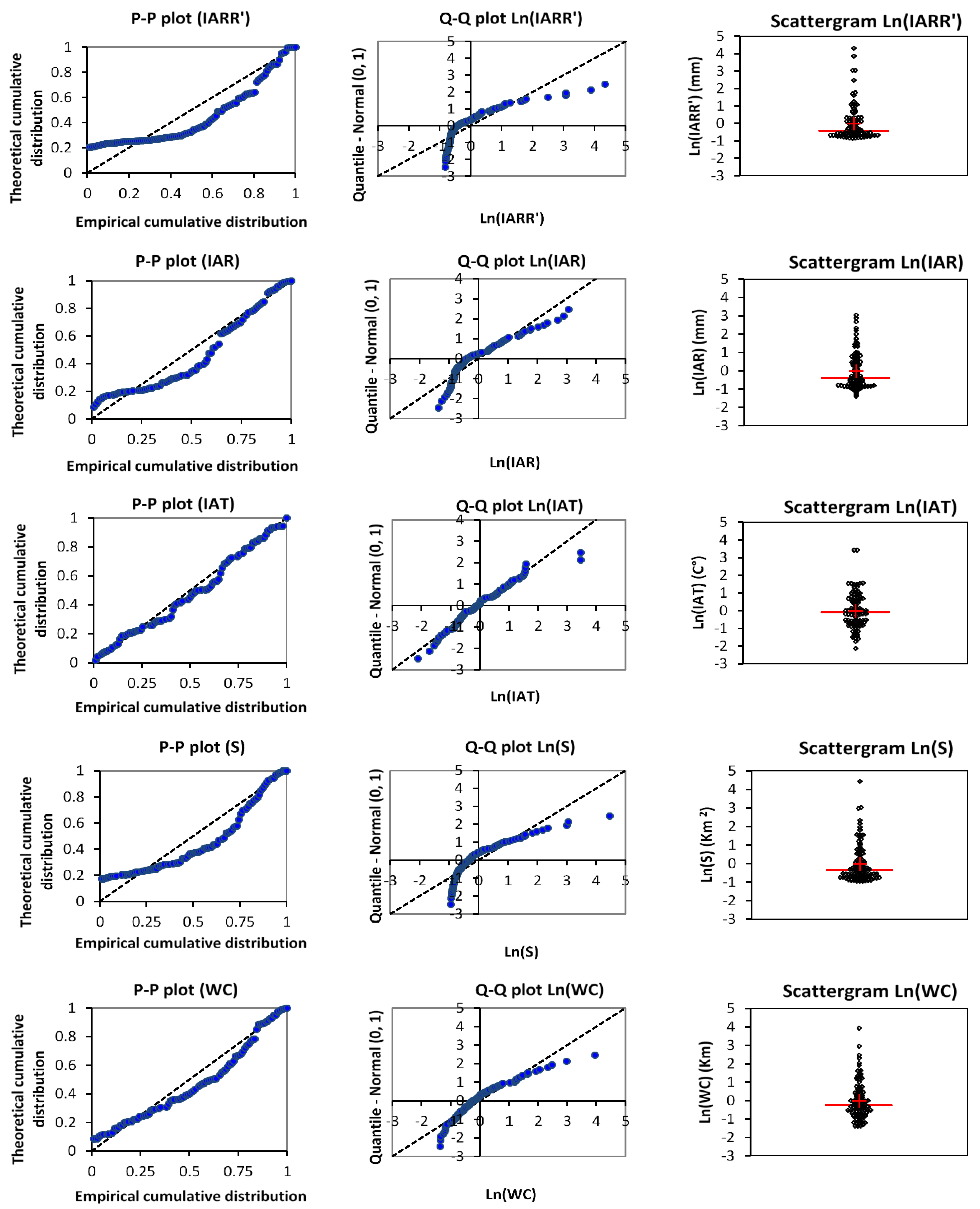
Data distribution and variability analyses of selected variables used for modeling IARR’ are shown in this section, which aims to study the behavior and the regression relationship between input variables and the IARR’ dataset. This study is based mainly on qualitative and quantitative tests, where the results of the data distribution are given by P–P plot, Q–Q plot (which allowed us to compare the empirical and theoretical distribution of data and cumulative quartiles, respectively, using normal law), and scattergram graph (
Figure 2). The Q–Q plot and the scattergram graph are obtained after linearizing the used variables by applying the Ln function, to simplify the comparison between data series distributions, which have different measurement units. Moreover,
Table 2 gives us a set of statistical parameters to quantify the variability of the data series. The P–P plot and the Q–Q plot show that IAR, S, and WC data series have a similar variability to the IARR’s dataset. However, IAR and S data distributions are closer to IARR than the WC data series (
Figure 2). On the other hand, IAT shows a different behavior of data distribution, where the graphs prove that the stochastic model, which defines the IAT variability, is closer to the normal law. The
p-value results obtained by the D
KS fit test using a set of distribution laws (
Table 2) show that IARR’ and IAR follow the Weibull 3 law, where the
p-values equal 0.9789 and 0.8572, respectively. On contrary, IAT data have a GEV distribution, where the
p-value is equal to 0.8764. Moreover, S and WC show a similar distribution, in which both variables follow the law of gamma 2. According to the fit results, the last three variables accept the Weibull 3 as a second closest fit model, where
p-values equal 0.6136, 0.8363, and 0.8263, respectively. In
Figure 2, the scattergram shows a descriptive comparison between the variability of data cited above. The graphs show a similar variability between IARR’, IAR, and S data series, where the majority of the values of each variable are very close between them and below the average of their series (which equals 49.113, 494.6529, and 719.7106, respectively). On the other hand,
Table 2 shows that 25% of the dataset, which is bounded between the third quartile and the maximum value, has very large variability, given by the interval of [64.3229, 284.3221], [607.00, 1107.00], and [1028.25, 4050.00], respectively. The WC variable shows a slight difference between data distribution. Inversely, the variability is more similar to IARR’. In this series, the mean and the median are close, and equal 45.60 and 51.10, respectively. However, 25% of the WC values give a very high variability, which is given by a value range of [65.5250, 179.80]. On the other hand, the IAT dataset shows a very low variability given by a variation coefficient of 0.1180. This last dataset proves a convergence between the median and the mean, which are equal to 15.2792 and 15.4569, respectively. Moreover, the scattergram shows that the upper and the lower IAT values, compared to the average, have a similar distance, given by the interval of [−2, 0] and [0, 2], respectively. In
Table 2, this similarity is given by [11.5833, 15.2792] and [15.2792, 21.7583], respectively. According to this analysis, the greatest variability was obtained from IARR’ and S datasets, whereby the variation coefficients equal 1.1039 and 1.0379, respectively.
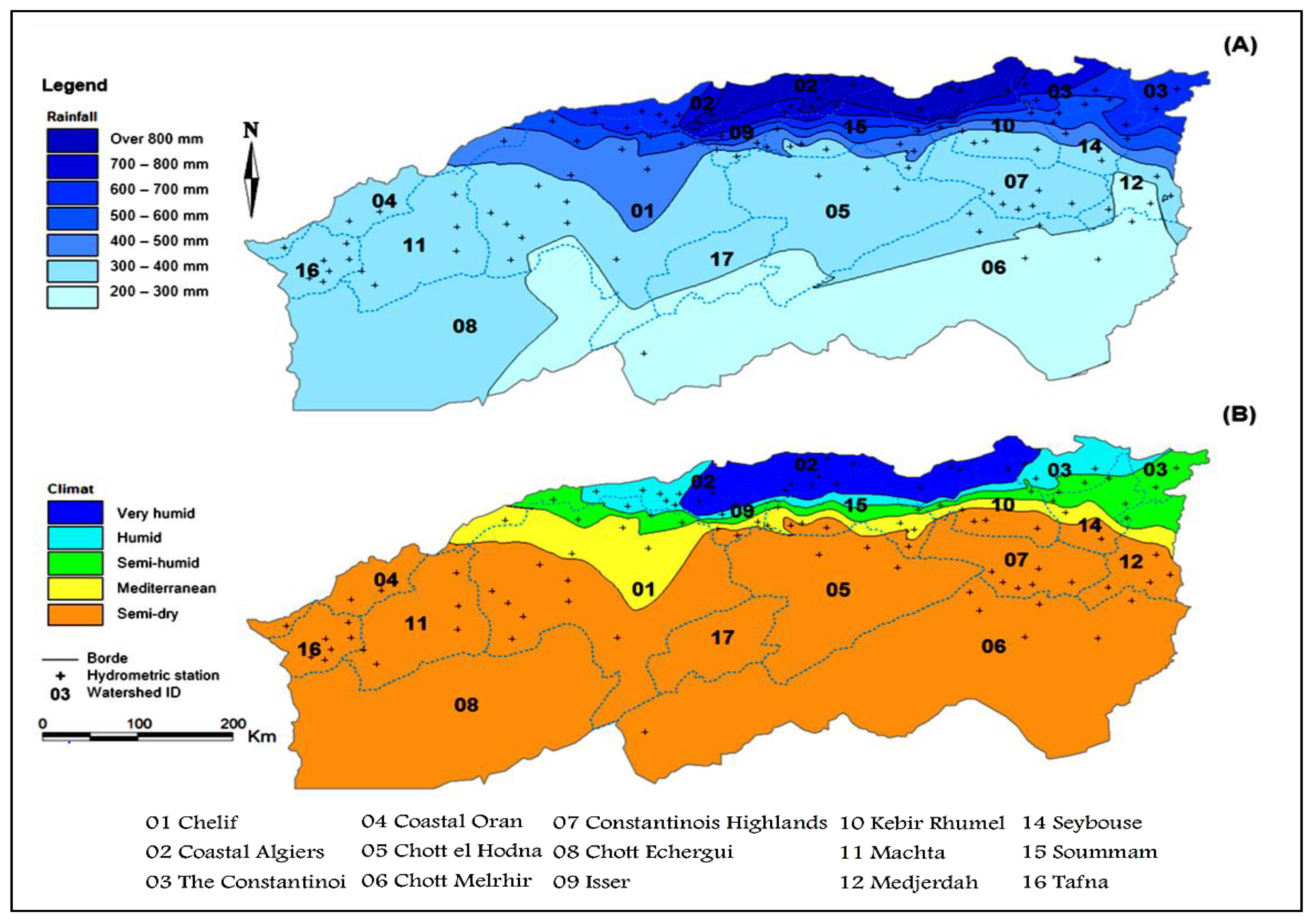
The spatial inter-annual rainfall distribution and the De Martonne index obtained by applying Equation (1) are mapped using the data of 102 meteorological stations to determine the bioclimatic floor of each watershed of northern Algeria between 1965 and 2020. This study helps to provide the application areas used to control the performance of the model proposed in this section. Climate classification analysis is shown in
Figure 3. A very large variability of rainfall from north to south is shown in Map (a), wherein the southern part, the IAR reaches up to 200 mm. However, in the north, the rainfall reaches values higher than 800 mm.
According to the bioclimatic classification given by [
45], northern Algeria has a climatic diversity spread over five floors, from very humid to very dry (
Figure 3B). The figure shows that watershed 02, which is located in the northern part and overlooking the Mediterranean Sea has a very humid climate, characterized by IAR values varying between 700 mm and >800 mm (
Figure 3A). On the other hand, watersheds 09, 15, and 10 have the greatest climatic diversity, varying between very humid, humid, semi-humid, Mediterranean, and semi-dry. Where in this area, the rainfall varies between 400 mm and >800 mm. This diversity depends mainly on the geographical and geological characteristics of the region. In the northeastern part, watershed 03 is characterized by a very humid, humid, and semi-humid climate, where the IAR varies between 500 mm and >800 mm. The catchment area 01, 14, and 12 have a climatic diversity which is between humid, semi-humid, Mediterranean, and semi-dry. In this area, the minimum rainfall was observed in watershed 14, which arrives at 300 mm. Differently, in watersheds 01 and 12, the minimum rainfall values reach up to 200 mm in the southern areas.
In addition, watersheds 16, 04, 11, 08, 17, 05, 06, and 07 are characterized by a semi-dry climate, where the rainfall varies generally between 300 mm and 400 mm. Contrariwise, the minimum rainfall of watersheds 08, 17, 05 and 06 reaches up to 200 mm.
3.2. Proposed ANNs
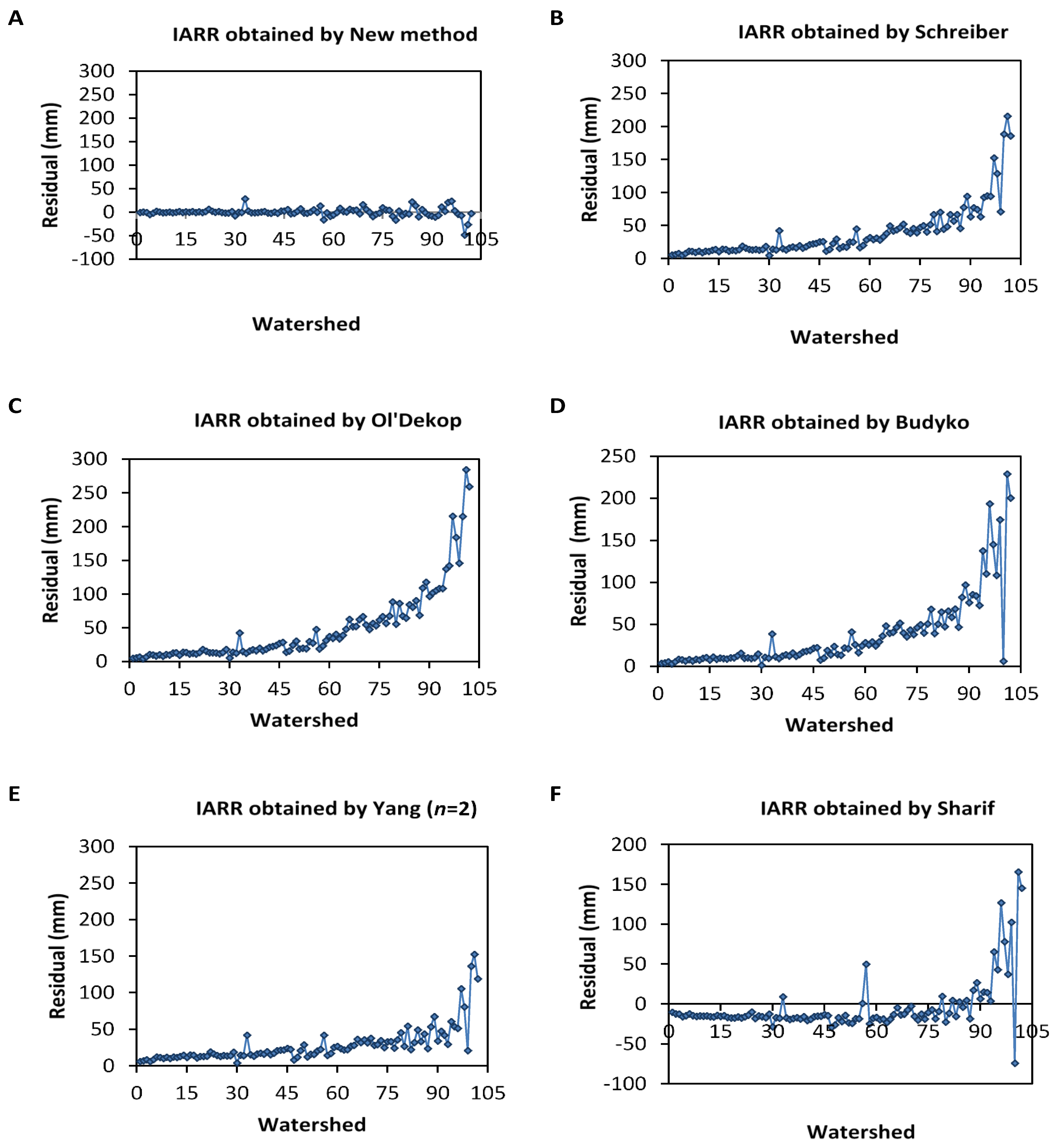
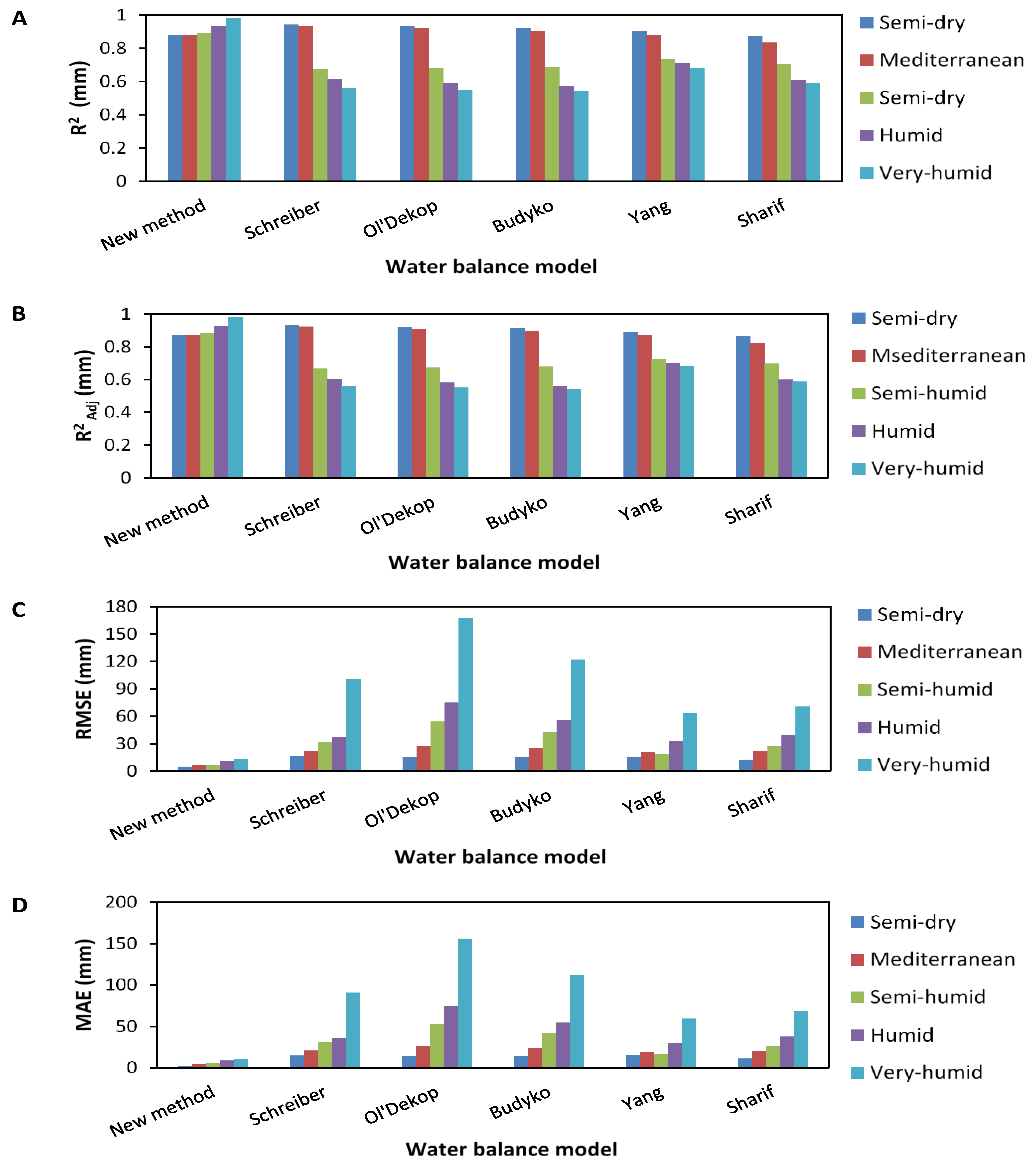
The different steps followed to obtain the best ANNs model for estimating the computational errors of IARR’ given by the Ol’Dekop model are represented in this section. This study allows us to develop a new form of water balance model based on a set of climatic and geomorphological variables, which can be applied in a different area, without being conditioned by the aridity state of the watershed. The statistical tests used in this study are: residual analysis curve, R
2, R
2Adj, MSE, RMSE, and Durbin–Watson (DW). These latter tests were used to analyze the performance of each transfer equation used by the ANN model, and also to quantify the reliability degree of the proposed model compared to a set of parametrical and non-parametrical water balance models, which are what is mostly used in the literature. Our model is classified into two steps, given as ANN
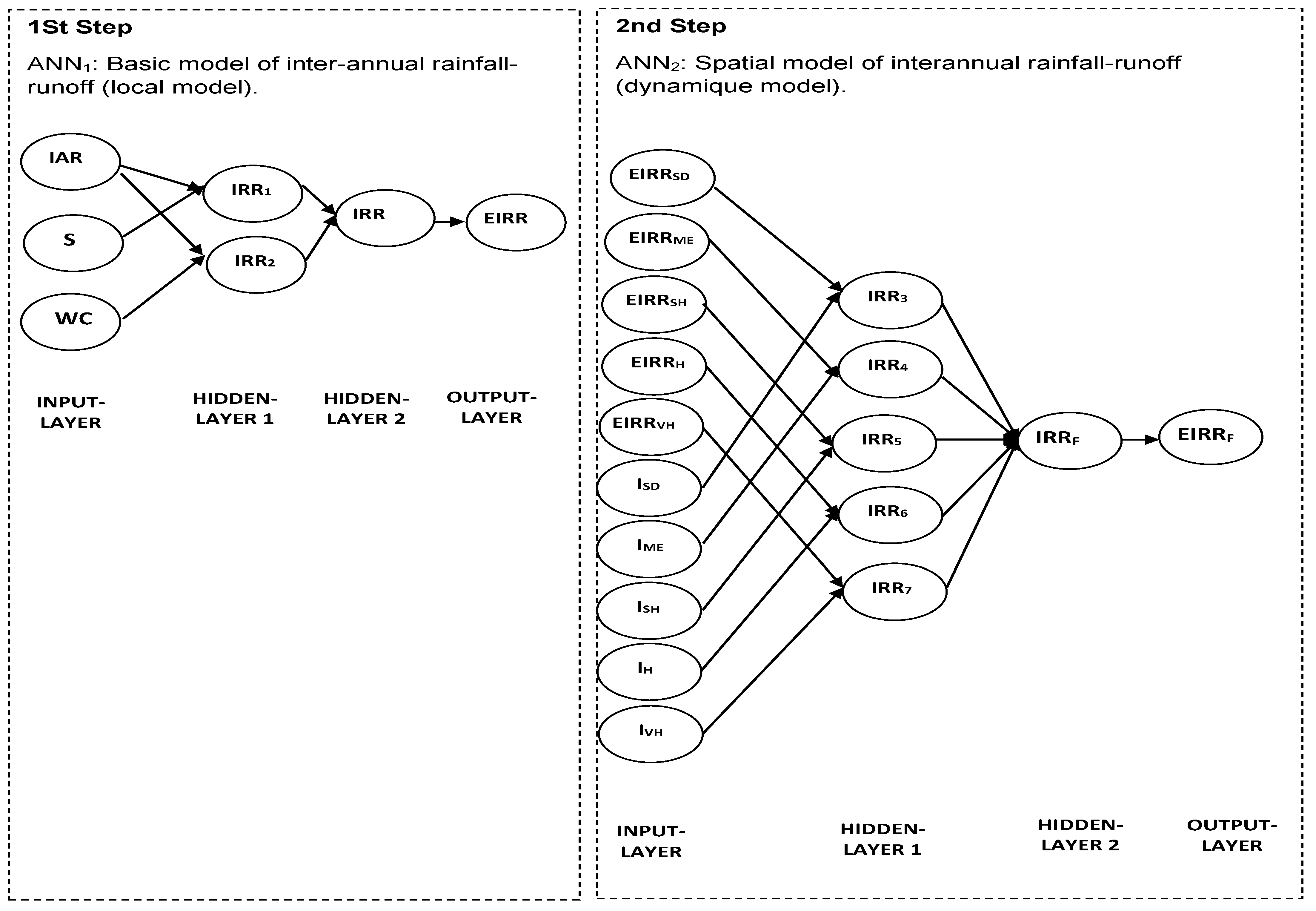
1 and ANN
2 (
Figure 4), which show that initially a local model (ANN
1) was given to estimate IARR in all northern Algeria watersheds. Then an improvement was made to increase the reliability of the previous model in each basin climatic area and to make it more dynamic and applicable in different regions (ANN
2).
Figure 4 shows that the two previous sub-models are the type of feed-forward network with the architecture of (3-2-1-1) and (10-5-1-1), respectively. In the first attempts of this modeling, we used IAR, S, and WC variables as input layers in the ANN
1 model. After that, we classified the estimation results that were obtained by this model in groups, according to each bioclimatic level. In this step, we also used the aridity index
I of each hydrological station as input data in the ANN
2 model to determine, in each climatic area, its transfer function, which allows us to deduce the final rainfall-runoff model.
Figure 4, shows that the intermediate nodes (denoted by IRR
1, IRR
2, IRR
3, IRR
4, IRR
5, IRR
6, and IRR
7, respectively) make it possible to apply sub-processing, using a summing and transfer function on the input data “output layer” to estimate the output data in each step of the ANN model. In our case, the summing function combines the input variables two by two to have the best modeling results. Moreover, the choice of combination between variables was justified by the results of the correlation test, which were applied to the linearized variables compared to the linearized IARR’ (IARR’*) (
Table 3). The table shows the degree of correlation between a set of candidate variables that were cited in the previous section of this study and IARR’*, using two correlation forms. A direct correlation was found between the IARR’* and (S*, WC*, IAT*, IAR*, and I*), then an indirect correlation between IARR’* and (WC*, S*), by studying the relationship between IARR’* and ((
), (
)) then between ((
), (
)) and (Wc*, S*), respectively.
Table 3 shows that IARR’* has the best correlation with IAR*, which equals 0.8513. It is also strongly correlated with climatic data obtained from the I* index. Contrariwise, the IAT* shows a weak correlation. However, the geo-hydrologic variables such as WC* and S* are slightly correlated with the response variable (IARR’*), which equals 0.5141 and 0.5023, respectively. The results highlight that the relation proposed by (
) and (
) shows a very good correlation with IARR’*, given by 0.8124 and 0.7322, respectively. Furthermore, the new variables also show a strong correlation with WC* and S*, respectively, given by correlation coefficients of 0.6168 and 0.7923, respectively.
3.3. IARR Modeling
Describing different modeling steps used to propose a new equation of IARR estimation is based mainly on the computational error analysis of the Ol’Dekop model in a set of bioclimatic floors. A non-linear regression relationship between IARR’ and selected input variables provided in (
Table 3) are shown graphically in
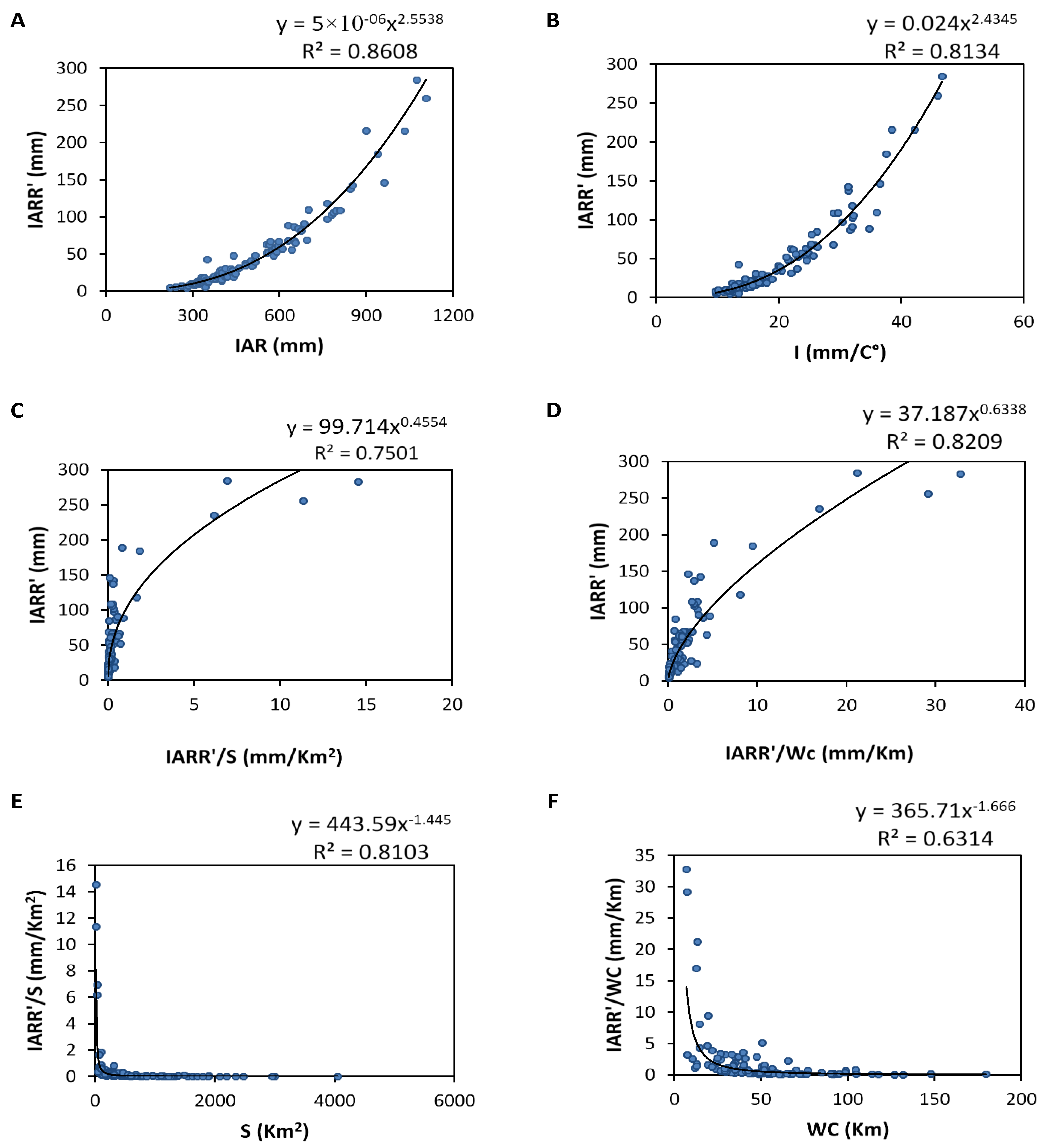
Figure 5 as the first step of this analysis. In this regard, a direct regression is applied between the response variable (IARR’) and the input variables (IAR, I). Then, intermediate variables were used to express the indirect relationship between (S, Wc) and IARR’. The results show a similar regression for each pair of the dataset (IARR ‘, IAR) and (IARR’, I), given by an R
2 which equals 0.8608 and 0.8134, respectively.
The graphs shown in
Figure 5A,B prove some trends of values, which are shown in the range of the maximum value. Regression models cited above are defined by Equations (12) and (13):
On the other hand, the figure also shows a good nonlinear regression between IARR’ and
, and also between IARR’ and
according to R
2 results, which equal 0.7501 and 0.8209, respectively, given by
Figure 5C,D. The regression relationship between both input variables are defined by Equations (14) and (15), respectively:
Moreover, both ratios (
) and (
) proved a good regression trend with S and WC variables, respectively. Where R
2 equals 0.8103 and 0.6314, respectively. Both statistical relationships between input and response variables are defined by Equations (16) and (17):
In this study, we found that all the cases of regression cited in
Figure 5 followed the power model trend.
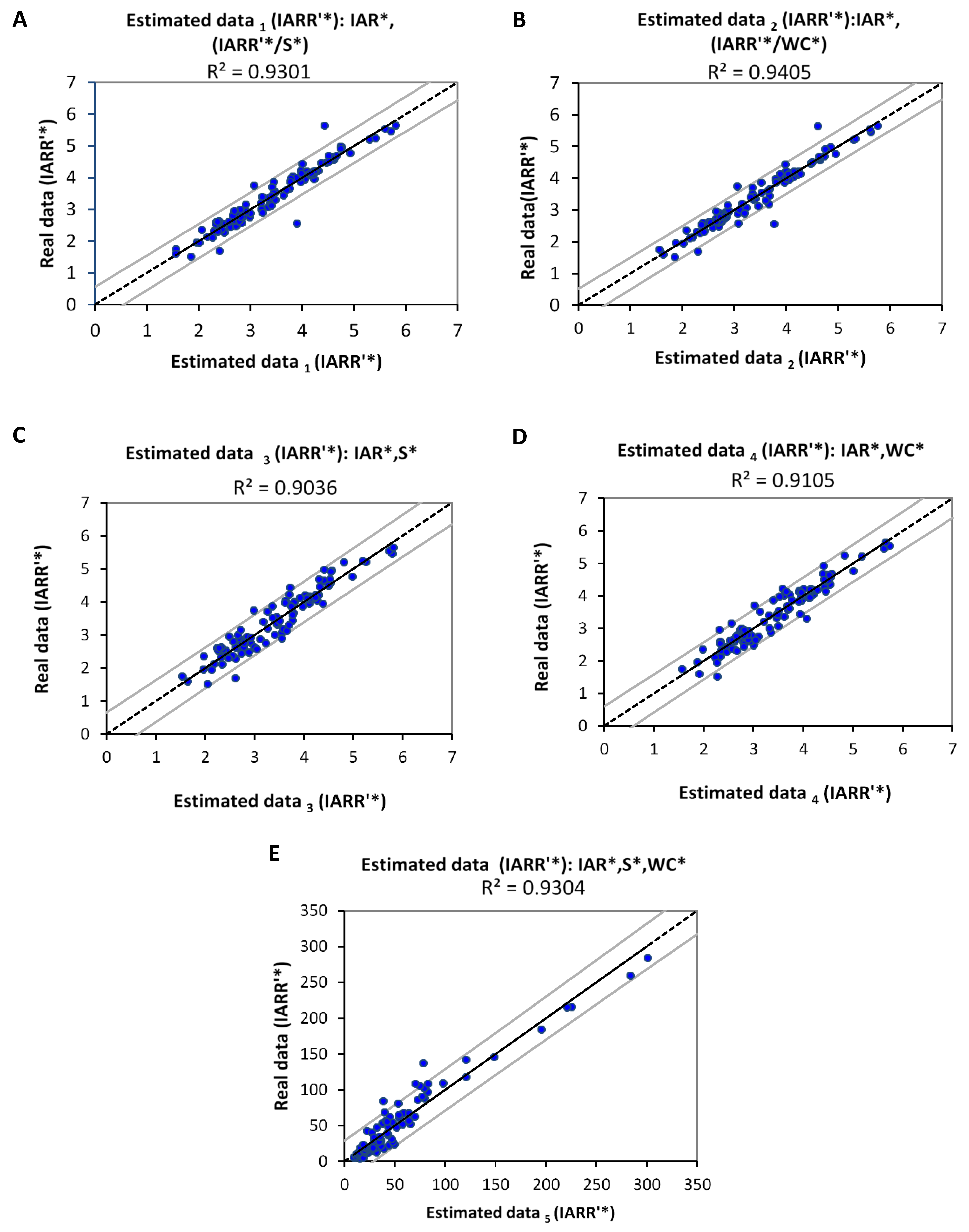
Figure 6 represents the linear regression graphs, which express the degree of correlation between the real values of IARR’* and the estimated values that were obtained by the IRR
1 and IRR
2 models. In this step, we proved the correlation’s degree and the reliability of the obtained model. We have well explained the different multiple regression models, which are applied to the pair of variables (IAR*, S*) and (IAR*, WC*), using the intermediate variable (
) and (
), respectively, which showed a good nonlinear regression with S and WC data, and also with IARR’ (
Figure 5). Moreover,
Table 4 shows a set of statistical parameters relating to this modeling, which gives information about the reliability and the trend analysis of the sub-models that are noted by (A, B, C, and D), compared to the linearized real data (IARR’*). According to the results, we found that the regression model obtained from (IAR*,
) and (IAR*,
) have a very good regression, proved by an (R
2, R
2adj) results which equal (0.9301, 0.9286) and (0.9405, 0.9393), respectively. Moreover, the errors given by MSE, RMSE, and DW show that all models did not prove a large trend deviation compared to IARR’* real data. The computational steps of IRR
1 and IRR
2 models are well detailed by the following Equations (18) and (19):
To deduce the previous equations as functions of fundamental variables IAR, S, and WC, we start with Equation (18) by replacing (
) with (S) using Equation (16). So we obtain:
On the other hand, we use Equation (17) to replace (
) with (WC) in Equation (19). We find:
Figure 6C,D shows the reliability of the results obtained by the IRR
1 and IRR
2 models that are given by Equations (18) and (19), respectively. The corresponding graphs show a good fit of regression between the actual and the estimated values of IARR’*. This reliability was shown by R
2, and R
2Adj statistical parameters, which equal (0.9036, 0.9006) and (0.9105, 0.909), respectively (
Table 4). We apply the Exp function in Equations (20) and (21), to obtain the IRR model used by ANN
1.
In this step, we found two reliable equations to estimate IARR’.
Figure 6E shows that the best regression can be obtained as a function of the three variables (IAR, S, and WC), which is given by Equation (24).
According to Equations (22) and (23), the general model IRR is defined as follows:
Table 4 shows that the IRR model gives a good estimation, proven by a set of statistical parameters. The results obtained by this model give an R
2 and R
2Adj, which are equal to 0.9518 and 0.9508, respectively. Moreover, the computational errors given by MSE, RMSE, and DW parameters show values of 208.539, 11.4409, and 0.7094, respectively. The ANN
1 model shows that the use of geomorphological parameters increases the reliability of estimation when compared with the simple regression model obtained by IAR only (
Figure 5A).
In the second step of this study, we improved the proposed model, which is defined by Equation (24) to be more dynamic and applicable to each bioclimatic region. We applied multiple linear regression to aridity index series (I) and the predicted data obtained previously by the IRR model. This technique was applied separately to each bioclimatic stage in order to find the corresponding estimation model of each area.
Table 5 shows all the statistical parameters relating to each local regression model. The results show that the model obtained in a very humid climate area gives a more reliable estimation compared to the performance models of other bioclimatic floors, where the R
2 and R
2Adj given for the IRR
7 model equal 0.9072 and 0.9001, respectively (
Figure 4 and
Table 5). The table shows that the obtained models have different reliability in each climate region, wherein the Mediterranean area, the R
2, and R
2Adj were proven to perform well, and equal 0.7804 and 0.7647, respectively.
On the other hand, in the semi-dry, semi-humid, and humid climate floor, the R
2, R
2Adj equal (0.6501, 0.6420), (0.6820, 0.6675) and (0.6533, 0.6448), respectively. Moreover, the trend pattern obtained by modeling the IARR’ in the dry climate floors is increased when compared to the estimated IARR’ in wet regions. The performance criteria show that the greatest values are given in the semi-dry climate level, where MSE, RMSE, and DW equal 0.0783, 0.298, and 1.6870, respectively. In the humid area, R
2 proved lower performance compared to the estimation obtained in the Mediterranean region. Contrariwise, the errors are more remarkable in the humid regression model, where MSE, RMSE, and DW values equal 0.0138, 0.1175, and 0.8625, respectively. On the other hand, on the Mediterranean climate floor, these parameters equal 0.0296, 0.1721, and 1.7861, respectively. The model named IRR
3, IRR
4, IRR
5, IRR
6, and IRR
7, which were obtained by modeling IARR’ in semi-dry, Mediterranean, semi-humid, humid, and very humid climate floors, respectively, are defined by Equations (25)–(29), as follows:
We apply the Exp function on Equations (25)–(29)to generate the final estimation model (IRR
F) in terms of IAR, S, WC, and I (
Table 5) So we find,
We apply the different models obtained in each bioclimatic area using all the datasets of northern Algeria to show the trend that can be caused by the static models. In this step, we want to propose a dynamic model, by eliminating all constants and finding a mathematical relationship with variables that can prove a good correlation.
Table 6 shows statistic results, obtained from IRR
3, IRR
4, IRR
5, IRR
6, IRR
7, and IRR
F models. The table shows that all previous models cited above proved an R
2 and R
2Adj greater than 0.80. Moreover, the error trends increase in these models, which are proven by MSE, RMSE, and DW parameters. On the other hand, the IRR
F model has the best reliability, given by an R2, which equals 0.9841. This model proved a low tendency, where the MSE, RMSE, and DW equal 62.5948, 5.9117, and 0.5250, respectively. The final model (IRR
F) was obtained by applying the weighted average using the R
2 values that are obtained in
Table 6 as weighting coefficients to estimate the
1 and a2 coefficients of this model. Where the IRR
F equation is defined as follows:
By replacing variables with values, we find:
We replace variables with values, we find:
Using the results obtained by Equations (36) and (37) in Equation (35), we find:
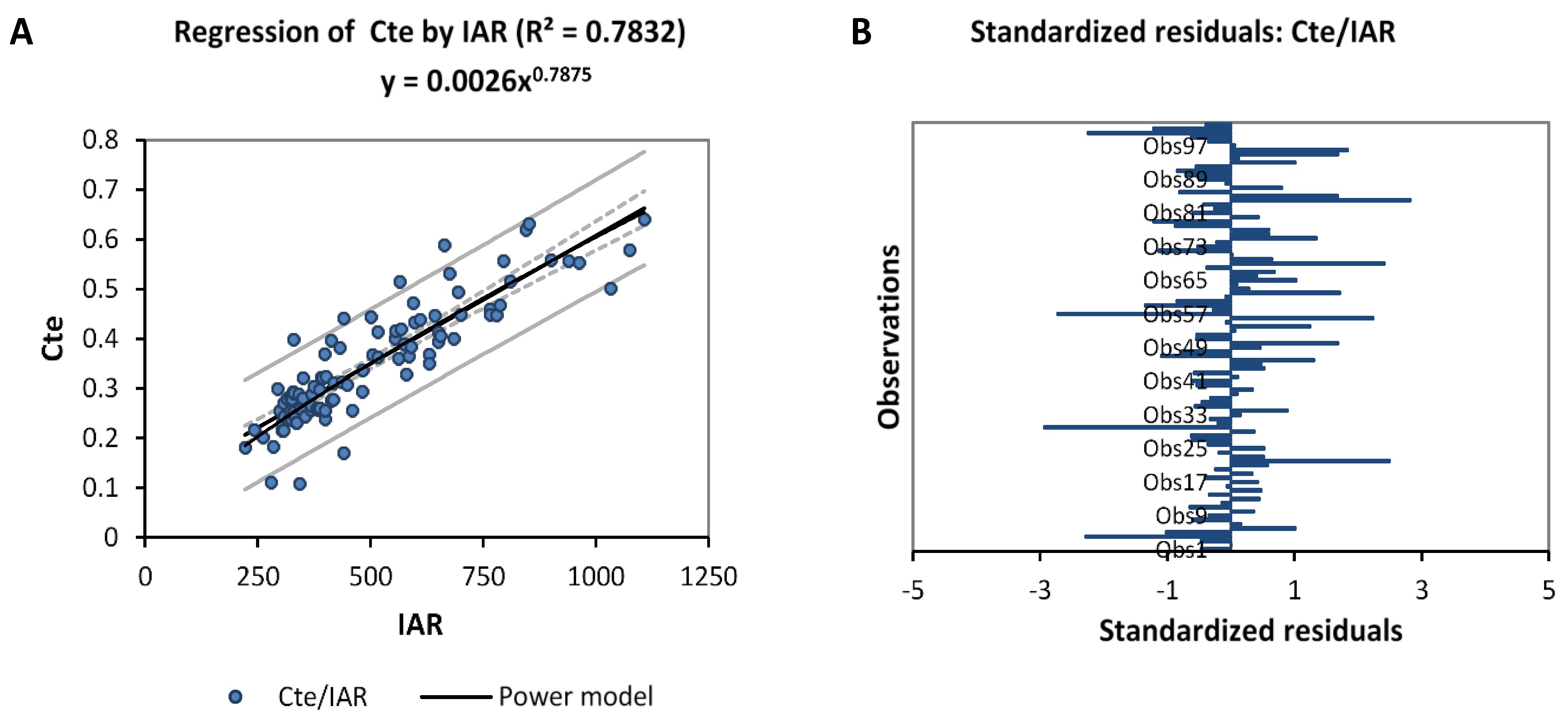
To make the obtained Equation (38) more dynamic, the constant (Cte) is defined in terms of IAR data, which is given by Equation (42). The Cte must be obtained by each watershed to take into consideration the variability of each climate area. For this, we propose in Equation (39) the hypothesis that the predicted and real data of the Ol’dekop residuals (IARR’) are almost equal.
We replace EIRR
F in Equation (39) by the formula defined in Equation (38), by doing so, we obtain
Figure 7 shows that Cte data has a very good correlation with IAR, where R
2 equals 0.7235. When we use the trend equation obtained from the regression model to represent the Cte variable as a function of IAR, we obtain:
When we use Equations (22) and (39) in Equation (36), we find:
In Equation (43), we used Equations (8) and (42) to define the new form of the Ol’Dekope model used for the IARR estimation.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}