
deepNIR: Datasets for Generating Synthetic NIR Images and Improved Fruit Detection System Using Deep Learning Techniques



Abstract
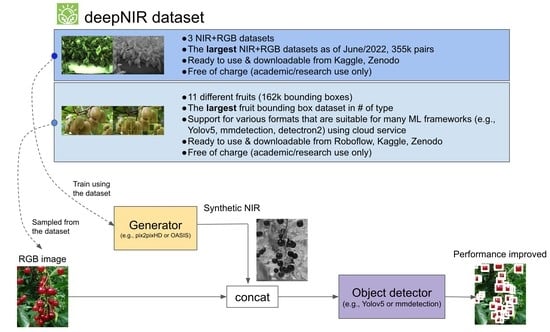
:
1. Introduction
- We made publicly available NIR+RGB datasets for synthetic image generation [12]. Note that we utilised 2 publicly available datasets, nirscene [13] and SEN12MS [14], in generating these synthetic datasets. For image pre-processing, oversampling with hard random cropping was applied to nirscene and image standardisation (i.e., , was applied. It is the first time to realise the capsicum NIR+RGB dataset. All datasets are split in a 8:1:1 (train/validation/test) ratio. This dataset follows a standard format so that it is straightforward to be exploited with any other synthetic image generating engine.
- We expanded our previous study [15], and we added four more fruit categories including their bounding box annotations. A total of 11 fruit/crops were rigorously evaluated and to our best knowledge, this is the largest type of dataset currently available.
2. Related Work
2.1. Near-Infrared (NIR) and RGB Image Dataset
2.2. Synthetic Image Generation
2.3. Object-Based Fruit Localisation
3. Methodologies
3.1. Synthetic Near-Infrared Image Generation
Datasets Used for Generating Synthetic Image
3.2. Fruit Detection Using Synthetic Images
Datasets Used for Fruit Detection (4ch)
4. Experiments and Results
4.1. Evaluation Metrics
4.1.1. Synthetic Image Evaluation Metrics
4.1.2. Object Detection Evaluation Metric
4.2. Quantitative Results for Synthetic NIR Image Generation
4.3. Qualitative Results for Synthetic NIR Image Generation
4.4. Applications for Fruit Detection Using Synthetic NIR and RGB Images
4.5. Quantitative Fruit Detection Results
4.6. Qualitative Object Detection Results
5. Remaining Challenges and Limitations
6. Conclusions and Outlook
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| NIR | Near-Infrared |
| GPU | Graphics Processing Unit |
| DN | Digital Number |
| FID | Frechet Inception Distance |
| mAP | Mean Average Precision |
| AP | Average Precision |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| NDVI | Normalised Difference Vegetation Index |
| NDWI | Normalised Difference Water Index |
| EVI | Enhanced Vegetation Index |
| LiDAR | Light Detection and Ranging |
| RGB-D | Red, Green, Blue and Depth |
| RTK-GPS | Real-Time Kinematic Global Positioning System |
| ESA | European Space Agency |
| GeoTIFF | Geostationary Earth Orbit Tagged Image File Format |
| GAN | Generative Adversarial Networks |
| cGAN | Conditional Generative Adversarial Networks |
| Pix2pix | Pixel to pixel |
| OASIS | You Only Need Adversarial Supervision for Semantic Image Synthesis |
| MRI | Magnetic Resonance Image |
| CTI | Computed Tomography Image |
| UNIT | Unsupervised Image-to-Image Translation Network |
| RPN | Region Proposal Network |
| DNN | Deep-Neural Networks |
| GDS | Ground Sample Distance |
| YOLOv5 | You Only Look Once |
| BN | Batch-Normalisation |
| ReLU | Rectified Linear Unit |
| CBL | Convolution Batch Normalisation and Leaky ReLU |
| CSP | Cross Stage Partial |
| SPP | Spatial Pyramid Pooling |
| FPN | Feature Pyramid Networks |
| PAN | Path Aggregation Network |
| SSD | Single Stage Detectors |
| GIoU | Generalised Intersection Over Union |
| IoU | Intersection Over Union |
| COCO | Common Objects in Context |
| GAM | Generative Adversarial Metric |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| P | Precision |
| R | Recall |
| MAE | Mean Absolute Error |
| SSIM | Structural Similarity |
References
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. arXiv 2019, arXiv:1912.04838. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 6000–6010. [Google Scholar]
- Korshunov, P.; Marcel, S. DeepFakes: A New Threat to Face Recognition? Assessment and Detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef] [PubMed]
- Degrave, J.; Felici, F.; Buchli, J.; Neunert, M.; Tracey, B.; Carpanese, F.; Ewalds, T.; Hafner, R.; Abdolmaleki, A.; de Las Casas, D.; et al. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature 2022, 602, 414–419. [Google Scholar] [CrossRef]
- Rouse, J.W., Jr.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation; Texas A&M University: College Station, TX, USA, 1973. [Google Scholar]
- An, L.; Zhao, J.; Di, H. Generating infrared image from visible image using Generative Adversarial Networks. In Proceedings of the 2019 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 17–19 October 2019. [Google Scholar]
- Yuan, X.; Tian, J.; Reinartz, P. Generating artificial near infrared spectral band from RGB image using conditional generative adversarial network. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 3, 279–285. [Google Scholar] [CrossRef]
- Bhat, N.; Saggu, N.; Pragati; Kumar, S. Generating Visible Spectrum Images from Thermal Infrared using Conditional Generative Adversarial Networks. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 1390–1394. [Google Scholar]
- Saxena, A.; Chung, S.; Ng, A. Learning depth from single monocular images. Adv. Neural Inf. Process. Syst. 2005, 18, 1161–1168. [Google Scholar]
- Zheng, C.; Cham, T.J.; Cai, J. T2net: Synthetic-to-realistic translation for solving single-image depth estimation tasks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Sa, I. deepNIR. 2022. Available online: https://tiny.one/deepNIR (accessed on 17 June 2022).
- Brown, M.; Süsstrunk, S. Multi-spectral SIFT for scene category recognition. In Proceedings of the CVPR, Springs, CO, USA, 20–25 June 2011; pp. 177–184. [Google Scholar]
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS—A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. arXiv 2019, arXiv:1906.07789. [Google Scholar] [CrossRef] [Green Version]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [Green Version]
- Chebrolu, N.; Lottes, P.; Schaefer, A.; Winterhalter, W.; Burgard, W.; Stachniss, C. Agricultural robot dataset for plant classification, localization and mapping on sugar beet fields. Int. J. Rob. Res. 2017, 36, 1045–1052. [Google Scholar] [CrossRef] [Green Version]
- Sa, I.; Chen, Z.; Popović, M.; Khanna, R.; Liebisch, F.; Nieto, J.; Siegwart, R. weedNet: Dense Semantic Weed Classification Using Multispectral Images and MAV for Smart Farming. IEEE Robot. Autom. Lett. 2018, 3, 588–595. [Google Scholar] [CrossRef] [Green Version]
- Sa, I.; Popović, M.; Khanna, R.; Chen, Z.; Lottes, P.; Liebisch, F.; Nieto, J.; Stachniss, C.; Walter, A.; Siegwart, R. WeedMap: A Large-Scale Semantic Weed Mapping Framework Using Aerial Multispectral Imaging and Deep Neural Network for Precision Farming. Remote Sens. 2018, 10, 1423. [Google Scholar] [CrossRef] [Green Version]
- Sa, I.; McCool, C.; Lehnert, C.; Perez, T. On Visual Detection of Highly-occluded Objects for Harvesting Automation in Horticulture. In Proceedings of the ICRA, Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Di Cicco, M.; Potena, C.; Grisetti, G.; Pretto, A. Automatic Model Based Dataset Generation for Fast and Accurate Crop and Weeds Detection. arXiv 2016, arXiv:1612.03019. [Google Scholar]
- Sa, I.; Lehnert, C.; English, A.; McCool, C.; Dayoub, F.; Upcroft, B.; Perez, T. Peduncle detection of sweet pepper for autonomous crop harvesting—Combined Color and 3-D Information. IEEE Robot. Autom. Lett. 2017, 2, 765–772. [Google Scholar] [CrossRef] [Green Version]
- Lehnert, C.; Sa, I.; McCool, C.; Upcroft, B.; Perez, T. Sweet pepper pose detection and grasping for automated crop harvesting. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2428–2434. [Google Scholar]
- Lehnert, C.; McCool, C.; Sa, I.; Perez, T. Performance improvements of a sweet pepper harvesting robot in protected cropping environments. J. Field Robot. 2020, 37, 1197–1223. [Google Scholar] [CrossRef]
- McCool, C.; Sa, I.; Dayoub, F.; Lehnert, C.; Perez, T.; Upcroft, B. Visual detection of occluded crop: For automated harvesting. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 2506–2512. [Google Scholar]
- Haug, S.; Ostermann, J. A Crop/Weed Field Image Dataset for the Evaluation of Computer Vision Based Precision Agriculture Tasks. In Proceedings of the Computer Vision—ECCV 2014 Workshops, Zurich, Switzerland, 6–7 September 2015; pp. 105–116. [Google Scholar]
- Segarra, J.; Buchaillot, M.L.; Araus, J.L.; Kefauver, S.C. Remote Sensing for Precision Agriculture: Sentinel-2 Improved Features and Applications. Agronomy 2020, 10, 641. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training Generative Adversarial Networks with Limited Data. In Proceedings of the NeurIPS, Virtual, 6–12 December 2020. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Schönfeld, E.; Sushko, V.; Zhang, D.; Gall, J.; Schiele, B.; Khoreva, A. You Only Need Adversarial Supervision for Semantic Image Synthesis. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Aslahishahri, M.; Stanley, K.G.; Duddu, H.; Shirtliffe, S.; Vail, S.; Bett, K.; Pozniak, C.; Stavness, I. From RGB to NIR: Predicting of near infrared reflectance from visible spectrum aerial images of crops. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1312–1322. [Google Scholar]
- Berg, A.; Ahlberg, J.; Felsberg, M. Generating visible spectrum images from thermal infrared. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1143–1152. [Google Scholar]
- Li, Q.; Lu, L.; Li, Z.; Wu, W.; Liu, Z.; Jeon, G.; Yang, X. Coupled GAN with relativistic discriminators for infrared and visible images fusion. IEEE Sens. J. 2021, 21, 7458–7467. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, Z.; Wang, F.; Wang, W.; Zhong, Y.; Dai, H. Deep learning for in vivo near-infrared imaging. Proc. Natl. Acad. Sci. USA 2021, 118, e2021446118. [Google Scholar] [CrossRef] [PubMed]
- Welander, P.; Karlsson, S.; Eklund, A. Generative Adversarial Networks for Image-to-Image Translation on Multi-Contrast MR Images - A Comparison of CycleGAN and UNIT. arXiv 2018, arXiv:1806.07777. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised Image-to-Image Translation Networks. arXiv 2017, arXiv:1703.00848. [Google Scholar]
- Soni, R.; Arora, T. A review of the techniques of images using GAN. Gener. Advers. Netw.-Image-Image Transl. 2021, 5, 99–123. [Google Scholar]
- Fawakherji, M.; Potena, C.; Pretto, A.; Bloisi, D.D.; Nardi, D. Multi-Spectral Image Synthesis for Crop/Weed Segmentation in Precision Farming. Rob. Auton. Syst. 2021, 146, 103861. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Jocher, G. Yolov5. 2021. Available online: https://github.com/ultralytics/yolov5 (accessed on 17 June 2022).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Yang, H.; Deng, R.; Lu, Y.; Zhu, Z.; Chen, Y.; Roland, J.T.; Lu, L.; Landman, B.A.; Fogo, A.B.; Huo, Y. CircleNet: Anchor-free Glomerulus Detection with Circle Representation. Med. Image Comput. Comput. Assist. Interv. 2020, 2020, 35–44. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision—ECCV 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with Noisy Student improves ImageNet classification. arXiv 2019, arXiv:1911.04252. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4217–4228. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing Aided Hyper Inference and Fine-tuning for Small Object Detection. arXiv 2022, arXiv:2202.06934. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 17 June 2022).
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. arXiv 2018, arXiv:1803.01534. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar]
- Borji, A. Pros and Cons of GAN Evaluation Measures. arXiv 2018, arXiv:1802.03446. [Google Scholar] [CrossRef] [Green Version]
- Padilla, R.; Netto, S.L.; da Silva, E.A.B. A Survey on Performance Metrics for Object-Detection Algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Rio de Janeiro, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Lawrence Zitnick, C.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Birodkar, V.; Mobahi, H.; Bengio, S. Semantic Redundancies in Image-Classification Datasets: The 10% You Don’t Need. arXiv 2019, arXiv:1901.11409. [Google Scholar]
- Kodali, N.; Abernethy, J.; Hays, J.; Kira, Z. On Convergence and Stability of GANs. arXiv 2017, arXiv:1705.07215. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Advantages | Can Improve |
|---|---|---|
| Brown et al. [13] | Outdoor daily-life scenes | A temporal discrepancy in a pair Lack of radiometric calibration Small scale dataset to use |
| Chebrolu et al. [16] | Comprehensive large-scale dataset | Lack of comprehensive dataset summary table |
| Schmitt et al. [14] | Sampling from different locations over 4 seasons | Requires preprocessing to use |
| Name | Desc. | # Train | # Valid | # Test | Total | Img Size (wxh) | Random Cropping | Over Sampling | Spectral Range (nm) |
|---|---|---|---|---|---|---|---|---|---|
| nirscene1 | 2880 | 320 | 320 | 3520 | 256 × 256 | Yes | ×10 | 400–850 | |
| 14,400 | 1600 | 1700 | 17,700 | 256 × 256 | Yes | ×100 | |||
| 28,800 | 3200 | 3400 | 35,400 | 256 × 256 | Yes | ×200 | |||
| 57,600 | 6400 | 6800 | 70,800 | 256 × 256 | Yes | ×400 | |||
| SEN12MS | All seasons | 144,528 | 18,067 | 18,067 | 180,662 | 256 × 256 | No | N/A | 450–842 |
| Summer | 36,601 | 4576 | 4576 | 45,753 | 256 × 256 | No | N/A | ||
| capsicum | 1291 | 162 | 162 | 1615 | 1280 × 960 | No | N/A | 400–790 |
| Name | Train (80%) | # Images Valid (10%) | Test (10%) | Total | # Instances | Median Image Ratio (wxh) |
|---|---|---|---|---|---|---|
| apple | 49 | 7 | 7 | 63 | 354 | 852 × 666 |
| avocado | 67 | 7 | 10 | 84 | 508 | 500 × 500 |
| blueberry | 63 | 8 | 7 | 78 | 3176 | 650 × 600 |
| capsicum | 98 | 12 | 12 | 122 | 724 | 1290 × 960 |
| cherry | 123 | 15 | 16 | 154 | 4137 | 750 × 600 |
| kiwi | 100 | 12 | 13 | 125 | 3716 | 710 × 506 |
| mango | 136 | 17 | 17 | 170 | 1145 | 500 × 375 |
| orange | 52 | 6 | 8 | 66 | 359 | 500 × 459 |
| rockmelon | 77 | 9 | 11 | 97 | 395 | 1290 × 960 |
| strawberry | 63 | 7 | 9 | 79 | 882 | 800 × 655 |
| wheat | 2699 | 337 | 337 | 3373 | 147,793 | 1024 × 1024 |
| Type | Name | Desc. | GPU | Epoch | Train (h) | Test (ms/Image) | Img Size | # Samples |
|---|---|---|---|---|---|---|---|---|
| Synthetic image generation | nirscene | 10× | P100 | 300 | 8 | 500 | w:256 h:256 | 2880 |
| 100× | 300 | 72 | 14,400 | |||||
| 200× | 300 | 144 | 28,800 | |||||
| 400× | 164 | 113 | 57,600 | |||||
| SEN12MS | All | RTX 3090 | 112 | 58 | 250 | w:256 h:256 | 144,528 | |
| Summer | 300 | 140 | 36,601 | |||||
| Capsicum | RTX 3090 | 300 | 29 | 780 | w:1280 h:960 | 129 | ||
| Fruit detection | 10 Fruits | Yolov5s | RTX 3090 | 600 | min: 4 min, max: 36 min | 4.2–10.3 | w:640 h:640 | <5000 |
| Yolov5x | ||||||||
| Wheat | Yolov5s | RTX 3090 | 1 h 16 min | 4.2–10.3 | w:640 h:640 | 147,793 | ||
| Yolov5x | 2 h 16 min | |||||||
| FID ↓ | # Train | # Valid | # Test | Img Size | Desc. | |
|---|---|---|---|---|---|---|
| [7] | 28 | 3691 | N/A | N/A | 256 × 256 | 10 layer attentions, 16 pixels, 4 layers, encoding+decoding |
| nirscene1 | 109.25 | 2880 | 320 | 320 | 256×256 | ×10 oversample |
| 42.10 | 14,400 | 1600 | 1700 | 256 × 256 | ×100 oversample | |
| 32.10 | 28,800 | 3200 | 3400 | 256 × 256 | ×200 oversample | |
| 27.660 | 57,600 | 6400 | 6800 | 256 × 256 | ×400 oversample, epoch 89 | |
| 26.53 | 86,400 | 9600 | 9600 | 256 × 256 | ×400 oversample, epoch 114 | |
| SEN12MS | 16.47 | 36,601 | 4576 | 4576 | 256 × 256 | Summer, 153 epoch |
| 11.36 | 144,528 | 18,067 | 18,067 | 256 × 256 | All season, 193 epoch | |
| capsicum | 40.15 | 1102 | 162 | 162 | 1280 × 960 | 150 epoch |
| Name | Model | Input | ↑ | ↑ | Precision↑ | Recall↑ | F1↑ |
|---|---|---|---|---|---|---|---|
| apple | yolov5s | RGB | 0.9584 | 0.7725 | 0.9989 | 0.913 | 0.9540 |
| RGB+NIR | 0.9742 | 0.7772 | 0.9167 | 0.9565 | 0.9362 | ||
| yolov5x | RGB | 0.9688 | 0.7734 | 0.9989 | 0.9130 | 0.9540 | |
| RGB+NIR | 0.9702 | 0.7167 | 0.8518 | 0.9999 | 0.9199 | ||
| avocado | yolov5s | RGB | 0.8419 | 0.4873 | 0.9545 | 0.8077 | 0.8750 |
| RGB+NIR | 0.8627 | 0.4975 | 0.8749 | 0.8071 | 0.8396 | ||
| yolov5x | RGB | 0.9109 | 0.6925 | 1.0000 | 0.8461 | 0.9166 | |
| RGB+NIR | 0.8981 | 0.6957 | 0.9583 | 0.8846 | 0.9200 | ||
| blueberry | yolov5s | RGB | 0.9179 | 0.5352 | 0.8941 | 0.9018 | 0.8979 |
| RGB+NIR | 0.8998 | 0.5319 | 0.9224 | 0.8354 | 0.8767 | ||
| yolov5x | RGB | 0.9093 | 0.5039 | 0.9345 | 0.8494 | 0.8899 | |
| RGB+NIR | 0.8971 | 0.4657 | 0.9063 | 0.8476 | 0.8760 | ||
| capsicum | yolov5s | RGB | 0.8503 | 0.4735 | 0.8159 | 0.8473 | 0.8313 |
| RGB+NIR | 0.8218 | 0.4485 | 0.848 | 0.8091 | 0.8281 | ||
| yolov5x | RGB | 0.8532 | 0.4909 | 0.8666 | 0.8429 | 0.8546 | |
| RGB+NIR | 0.8642 | 0.4812 | 0.8926 | 0.8244 | 0.8571 | ||
| cherry | yolov5s | RGB | 0.9305 | 0.6045 | 0.9300 | 0.8586 | 0.8929 |
| RGB+NIR | 0.9034 | 0.5655 | 0.8994 | 0.8505 | 0.8743 | ||
| yolov5x | RGB | 0.9415 | 0.6633 | 0.929 | 0.8747 | 0.9010 | |
| RGB+NIR | 0.9300 | 0.6325 | 0.9129 | 0.8687 | 0.8903 | ||
| kiwi | yolov5s | RGB | 0.8642 | 0.5651 | 0.9196 | 0.7831 | 0.8459 |
| RGB+NIR | 0.8154 | 0.5195 | 0.9039 | 0.7188 | 0.8008 | ||
| yolov5x | RGB | 0.8935 | 0.6010 | 0.9056 | 0.8326 | 0.8676 | |
| RGB+NIR | 0.8240 | 0.5139 | 0.8625 | 0.7643 | 0.8104 | ||
| mango | yolov5s | RGB | 0.9431 | 0.6679 | 0.9516 | 0.879 | 0.9139 |
| RGB+NIR | 0.9032 | 0.6033 | 0.9347 | 0.8217 | 0.8746 | ||
| yolov5x | RGB | 0.9690 | 0.6993 | 0.9333 | 0.8917 | 0.9120 | |
| RGB+NIR | 0.9339 | 0.6681 | 0.9221 | 0.9044 | 0.9132 | ||
| orange | yolov5s | RGB | 0.9647 | 0.707 | 0.9409 | 0.9697 | 0.9551 |
| RGB+NIR | 0.9488 | 0.7669 | 0.9655 | 0.8482 | 0.9031 | ||
| yolov5x | RGB | 0.9662 | 0.8484 | 0.9998 | 0.9091 | 0.9523 | |
| RGB+NIR | 0.9584 | 0.8277 | 1.0000 | 0.9091 | 0.9524 | ||
| rockmelon | yolov5s | RGB | 0.9588 | 0.6321 | 0.9198 | 0.8846 | 0.9019 |
| RGB+NIR | 0.9205 | 0.6701 | 0.9999 | 0.8462 | 0.9167 | ||
| yolov5x | RGB | 0.9612 | 0.7161 | 0.9259 | 0.9615 | 0.9434 | |
| RGB+NIR | 0.9444 | 0.7018 | 0.8926 | 0.9615 | 0.9258 | ||
| strawberry | yolov5s | RGB | 0.9553 | 0.6995 | 0.9559 | 0.8784 | 0.9155 |
| RGB+NIR | 0.8913 | 0.6210 | 0.9000 | 0.8513 | 0.8750 | ||
| yolov5x | RGB | 0.8899 | 0.5237 | 0.8954 | 0.8108 | 0.8510 | |
| RGB+NIR | 0.9071 | 0.4882 | 0.9375 | 0.8106 | 0.8694 | ||
| wheat | yolov5s | RGB | 0.9467 | 0.5585 | 0.929 | 0.9054 | 0.9170 |
| RGB+NIR | 0.9412 | 0.5485 | 0.9258 | 0.8926 | 0.9089 | ||
| yolov5x | RGB | 0.9472 | 0.5606 | 0.9275 | 0.9035 | 0.9153 | |
| RGB+NIR | 0.9294 | 0.5329 | 0.9163 | 0.9005 | 0.9083 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sa, I.; Lim, J.Y.; Ahn, H.S.; MacDonald, B. deepNIR: Datasets for Generating Synthetic NIR Images and Improved Fruit Detection System Using Deep Learning Techniques. Sensors 2022, 22, 4721. https://doi.org/10.3390/s22134721
Sa I, Lim JY, Ahn HS, MacDonald B. deepNIR: Datasets for Generating Synthetic NIR Images and Improved Fruit Detection System Using Deep Learning Techniques. Sensors. 2022; 22(13):4721. https://doi.org/10.3390/s22134721
Chicago/Turabian StyleSa, Inkyu, Jong Yoon Lim, Ho Seok Ahn, and Bruce MacDonald. 2022. "deepNIR: Datasets for Generating Synthetic NIR Images and Improved Fruit Detection System Using Deep Learning Techniques" Sensors 22, no. 13: 4721. https://doi.org/10.3390/s22134721
APA StyleSa, I., Lim, J. Y., Ahn, H. S., & MacDonald, B. (2022). deepNIR: Datasets for Generating Synthetic NIR Images and Improved Fruit Detection System Using Deep Learning Techniques. Sensors, 22(13), 4721. https://doi.org/10.3390/s22134721