
A Two-Phase Machine Learning Framework for Context-Aware Service Selection to Empower People with Disabilities

 ,
, 
 , ,
, ,  and
and
Abstract
:1. Introduction
- A two-phase machine learning framework to optimize the selection of accessible services while satisfying various disability needs and constraints;
- Extended datasets of accessible web services containing relevant disability aspects (e.g., types of disability supported, interaction modalities, physical environment, etc.). The accessibility datasets are deposited online for reuse by other researchers and practitioners in the field;
- A succinct ontology of accessibility aspects to empower assistive service selection;
- A practical solution was devised by following a scenario-based design approach. The approach was effective in motivating and guiding various activities of our research;
- Multi-criteria consideration of the context of use, user capabilities, and preferences during the selection process. We devised an approach to evaluate and rank services based on a wealth of service quality properties.
2. Background
2.1. Service Selection
2.2. Service Selection for People with Disabilities
2.3. Quality of Service Factors
2.4. Service Selection Models and Major Challenges

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Service Selection Model/Algorithm | Dataset | Accessibility Features | Strengths | Weaknesses |
|---|---|---|---|---|
| EK-GA [38] | Collected | No |
| Significant latency |
| Gale–Shapley algorithm (GSA) [39] | Random | Yes |
| Low availability, Long reaction time |
| Chaos control optimal algorithm (CCOA) [40] | N/A | No |
| Limited scalability |
| HICA [41] | Random | Yes |
| Low scalability, Low reliability |
| Hybrid teaching–learning-based optimization (TLO) [42] | Random | Yes |
| Poor accuracy |
| Genetic algorithm (GA) [43] | Random | Yes |
| Long response time |
| Cross-modified artificial bee colony (CMABC) [44] | Random | Yes |
| Low scalability, High complexity, High energy |
| Intelligent water droplet (IWD) [45] | Random | Yes |
| Low scalability |
| ABC [46] | Random | Yes |
| Latency, Low scalability |
| Metaheuristic GA [47] | Random | Yes |
| Low scalability, Low reliability |
| Our proposed model | Systematically generated | Yes |
| Lack of testing in real situations |
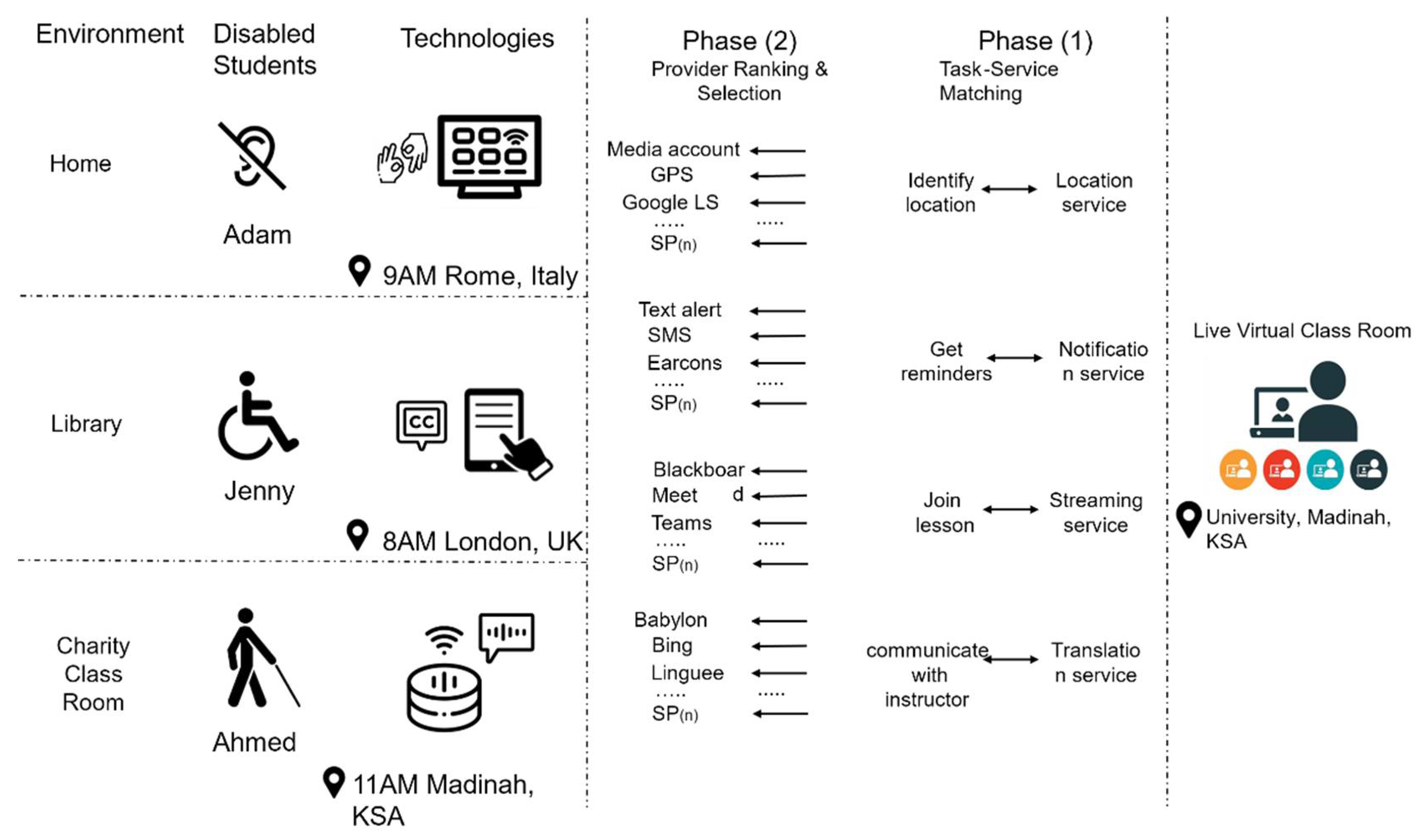
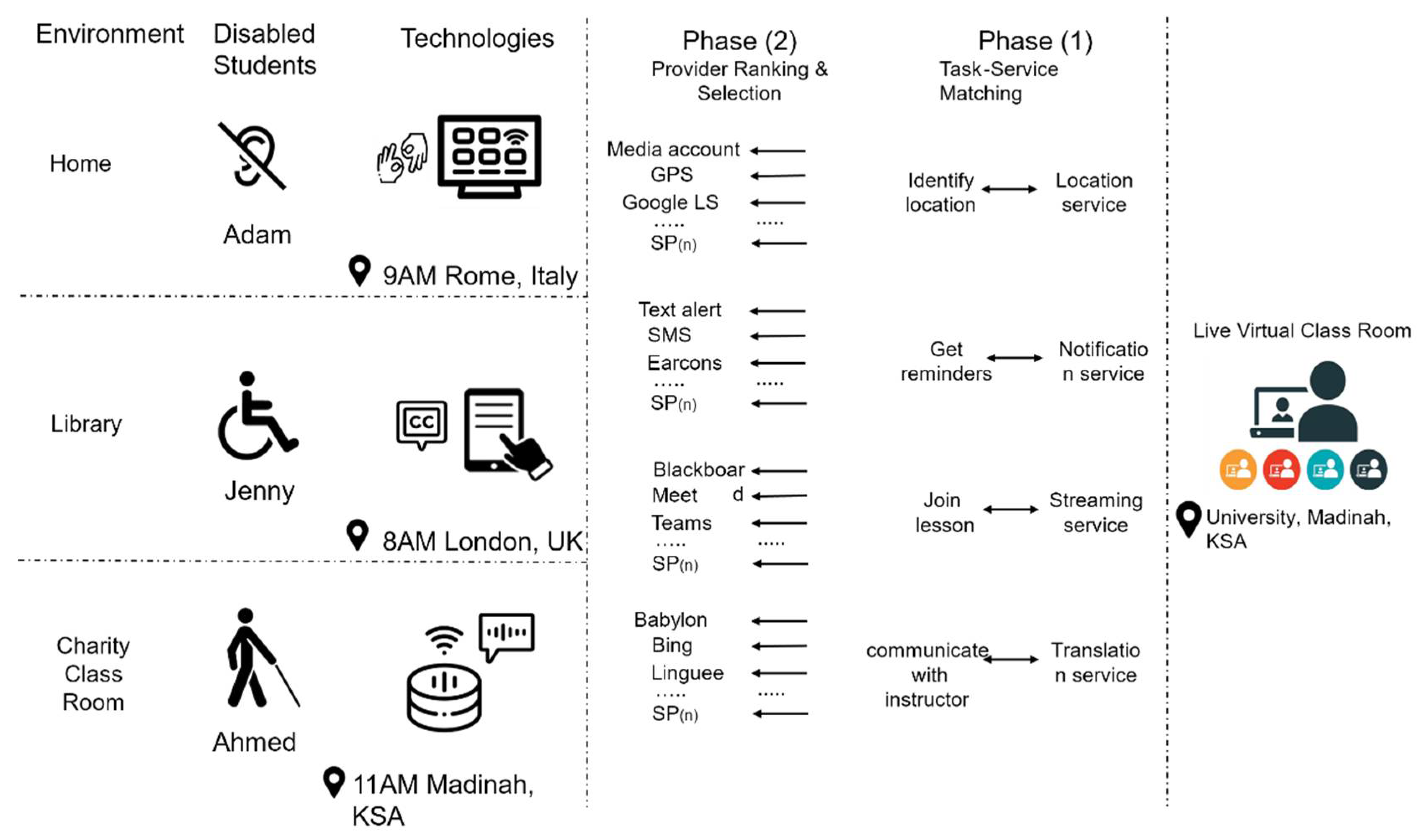
3. A Motivating Scenario for Accessible Service Selection
- All typical users (in this case, students) in the scenario have some form of disability;
- User demographics, disabilities, characteristics, and goals are collected and stored within dedicated user profiles;
- Users have access to high-speed Internet (e.g., WLAN, WIFI, 4G LTE) during their lectures;
- Users are equipped with smart mobile devices and assistive technologies (AT) to access compatible services; examples of these technologies include smart TVs, smart watches, etc.;
- Location services are enabled on user devices to detect their exact location at the time of online courses;
- Service selection must consider the current user environment and preferences (i.e., context-aware).
4. An Accessibility Ontology for Service Selection
- The ontology classes help achieve the specifics of the scenario detailed in Section 3; and
- The concepts of disability ontology help model online education services.
- User profile;
- Disability;
- Ability;
- User goals;
- Context;
- Services;
- Assistive mechanisms
5. Assistive Services Datasets and Proposed ML-Driven Selection Framework
5.1. Generation of Accessible Services Datasets
- T0: identify user location;
- T1: notify user about class;
- T2: live stream the classroom;
- T3: speech to text (STT);
- T4: text to speech (TTS);
- T5: speech to sign language (STSL);
- T6: sign language to speech (SLTS);
- T7: show subtitles or captions on screen;
- T8: translate text from Arabic to English;
- T9: customize screen color contrast (for visually impaired/low-vision users);
- T10: image text reader (i.e., alternative image text to describe images);
- T11: speech commands (SC).
- Time is randomly selected from [‘Morning’, ‘Afternoon’, ‘Evening’];
- Location is randomly selected from [‘Public’, ‘Private’];
- QoS metrics are extracted from a randomly chosen row corresponding to a unique service from the QWSDATA Ver2.0 dataset. The following four QoS metrics are selected: response time, availability, successability, and latency;
- For each of the four QoS metric values extracted from the file, a randomly selected percentage (0–100%) of the same metric value is randomly added to or subtracted from the original value to obtain the new, modified metric value for the dataset;
- The QoSMean value is obtained by averaging the modified metric values for response time, availability, successability, and latency while inverting the sign for response time and latency;
- The cost value is randomly selected from a uniform random distribution between 0 and 1.
- The QoSMean field is normalized across the complete dataset to a range of 0–1;
- The QoSRating for each entry in the dataset is obtained by averaging the QoSMean with the ‘cost’ and then converting the result to a categorical integer value between 1 and 5 (by integer sampling after multiplying by 5 and adding 1);
- The AccessibilityRating for each dataset entry is obtained by weighted averaging of the QoSMean with a random rating value sampled from a continuous uniform distribution between 0 and 1. The weights for weighted averaging can be set manually and were selected as 2 and 1 for random-value and QoSMean, respectively, in the current dataset.
5.2. Machine-Learning-Driven Service Selection Framework
5.3. Multi-Task Classification and Service Provider Matchmaking Algorithms

| Algorithm 1: Training procedure to select the best accuracy classifier, C∗. |
| Input:D = [I, T]: a training dataset with I instances and T tasks (labeled tasks obtained from our ontology model, containing attributes, e.g., UID, Goal, Language, Country, Current Place, Current Time, User Device, Disability Type), such that each ti ∈ [0, 1]. {Ci, i = 1, …, j}: a set of classification algorithms. Output: C∗: a multi-task classifier with the highest training accuracy. / / Dataset preprocessing: D’ ← encode(D[0, I: ∗, ∗]) convert all ts tasks values in I independently to a binary value. D’’ ← standardize(D’ [∗, ∗: 0, T]) normalize all features using min-max scaling. / / Training and identifying the best classifier according to Equation (3): C∗ ← ∅ for i ← 1 to j do ← train(D’’, Ci) training using one-vs-all method If > then ← return C* |
| Algorithm 2: Validation procedure to predict a set of tasks, T, using C∗ classifier for each disabled user. |
| Input:C∗: a multi-task classifier with the highest training accuracy, obtained by Algorithm 1. VI×N: a validation dataset containing I examples with N input features. θ: a predefined probability threshold with a default setting of θ = 0.5. Output: OI×|T|: a set of predicted tasks (ontological atomic tasks) for all users, I. V ← preprocessing(VI×N) / / preprocessing the validation dataset as shown in Algorithm 1. O ← C∗.predict(V) for j ← 1 to I do If O[j,k] > θ then O[j.k] ← 1: O[j.k] ← 0 return O |
| Algorithm 3: Training procedure to select the best training-accuracy regressor, R∗. |
| Input:D = [I, S]: a training dataset with I instances and S labeled service providers. {Ri, i = 1, …, j}: a set of regressor algorithms. Output: R∗: a regressor model with the highest training accuracy. / / Dataset preprocessing: D ← preprocessing(D) / / preprocessing the training dataset almost the same as performed in Algorithm 1 / / Training and identifying the best regressor: R* ← ∅ for i ← 1 to j do ← train (D, Ri) training with applying a grid-searching method for optimizing the hyperparameters. If > then ← return R* |
| Algorithm 4: Validation procedure to predict the best service provider, Si, for each task, Ti, using R∗ model. |
| Input:R∗: a regressor model with the highest training accuracy, obtained by Algorithm 3. VT×N: a validation dataset containing T tasks with N input features. θ: a predefined probability threshold with a default setting of θ = 0.5. Output: OT×|S|: a predicted service provider for each task, T. V ← preprocessing(VI×N) / / preprocessing the validation dataset as performed in Algorithm 1. O ← R∗.predict(V) for j ← 1 to I do for k ← 1 to |T| do If O[j,k] < θ then O[j.k] ← ∅ return O |
6. Results
6.1. Performance Evaluation Metrics
6.2. Benchmark Selection Approaches
6.3. Comparative Analysis
7. Discussion
7.1. Key Findings
7.2. Limitations and Threats to Validity
8. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Infographic—Better Health for People with Disabilities; World Health Organization: Geneva, Switzerland, 2022; Available online: https://www.euro.who.int/en/health-topics/Life-stages/disability-and-rehabilitation/multimedia/infographic-better-health-for-people-with-disabilities (accessed on 5 March 2022).
- World Health Organization. WHO Global Disability Action Plan 2014–2021: Better Health for All People with Disability; World Health Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Domingo, M.C. An overview of the Internet of Things for people with disabilities. J. Netw. Comput. Appl. 2012, 35, 584–596. [Google Scholar] [CrossRef]
- Da Silva, A.S.; Ma, H.; Mei, Y.; Zhang, M. A survey of evolutionary computation for Web service composition: A technical perspective. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 4, 538–554. [Google Scholar] [CrossRef]
- Asghari, P.; Rahmani, A.M.; Javadi, H.H.S. Service composition approaches in IoT: A systematic review. J. Netw. Comput. Appl. 2018, 120, 61–77. [Google Scholar] [CrossRef]
- Hayyolalam, V.; Kazem, A.A.P. A systematic literature review on QoS-aware service composition and selection in cloud environment. J. Netw. Comput. Appl. 2018, 110, 52–74. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Hama, H.K.; Ghafour, M.Y.; Masdari, M.; Ahmed, O.H.; Khezri, H. Service selection using multicriteria decision making: A comprehensive overview. J. Netw. Syst. Manag. 2020, 28, 1639–1693. [Google Scholar] [CrossRef]
- Al-Faifi, A.; Song, B.; Hassan, M.M.; Alamri, A.; Gumaei, A. A hybrid multi criteria decision method for cloud service selection from Smart data. Future Gener. Comput. Syst. 2019, 93, 43–57. [Google Scholar] [CrossRef]
- Cho, J.H.; Ko, H.G.; Ko, I.Y. Adaptive service selection according to the service density in multiple QoS aspects. IEEE Trans. Serv. Comput. 2015, 9, 883–894. [Google Scholar] [CrossRef]
- Li, Y.; Huang, Y.; Zhang, M.; Rajabion, L. Service selection mechanisms in the Internet of Things (IoT): A systematic and comprehensive study. Clust. Comput. 2020, 23, 1163–1183. [Google Scholar] [CrossRef]
- Abosaif, A.N.; Hamza, H.S. Quality of service-aware service selection algorithms for the internet of things environment: A review paper. Array 2020, 8, 100041. [Google Scholar] [CrossRef]
- Rahimi, M.; Navimipour, N.J.; Hosseinzadeh, M.; Moattar, M.H.; Darwesh, A. Toward the efficient service selection approaches in cloud computing. Kybernetes 2021, 51, 1388–1412. [Google Scholar] [CrossRef]
- Mohammadi, M.; Rezaei, J. Ensemble ranking: Aggregation of rankings produced by different multicriteria decision-making methods. Omega 2020, 96, 102254. [Google Scholar] [CrossRef]
- Masdari, M.; Khezri, H. Service selection using fuzzy multicriteria decision making: A comprehensive review. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 2803–2834. [Google Scholar] [CrossRef]
- Tiwari, R.K.; Kumar, R. A robust and efficient MCDM-based framework for cloud service selection using modified TOPSIS. Int. J. Cloud Appl. Comput. 2021, 11, 21–51. [Google Scholar] [CrossRef]
- Rodríguez, G.; Soria, Á.; Campo, M. Artificial intelligence in service-oriented software design. Eng. Appl. Artif. Intell. 2016, 53, 86–104. [Google Scholar] [CrossRef]
- Baek, K.; Ko, I.Y. Spatio-cohesive service selection using machine learning in dynamic IoT environments. In International Conference on Web Engineering; Springer: Cham, Switzerland, 2018; pp. 366–374. [Google Scholar]
- Qolomany, B.; Mohammed, I.; Al-Fuqaha, A.; Guizani, M.; Qadir, J. Trust-based cloud machine learning model selection for industrial IoT and smart city services. IEEE Internet Things J. 2020, 8, 2943–2958. [Google Scholar] [CrossRef]
- Owrak, A.; Namoun, A.; Mehandjiev, N. Quality Evaluation within Service-Oriented Software: A Multi-Perspective Approach. In Proceedings of the 2012 IEEE 9th International Conference on Services Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 594–601. [Google Scholar]
- Moser, O.; Rosenberg, F.; Dustdar, S. Domain-specific service selection for composite services. IEEE Trans. Softw. Eng. 2012, 38, 828–843. [Google Scholar] [CrossRef]
- Stavrotheodoros, S.; Kaklanis, N.; Votis, K.; Tzovaras, D.; Astell, A. A hybrid matchmaking approach in the ambient assisted living domain. Univers. Access Inf. Soc. 2022, 21, 53–70. [Google Scholar] [CrossRef]
- Baldissera, T.A.; Camarinha-Matos, L.M. Scope: Service composition and personalization environment. Appl. Sci. 2018, 8, 2297. [Google Scholar] [CrossRef] [Green Version]
- Fattah, S.M.M.; Chong, I. Restful web services composition using semantic ontology for elderly living assistance services. J. Inf. Process. Syst. 2018, 14, 1010–1032. [Google Scholar]
- Hussain, A.; Wenbi, R.; da Silva, A.L.; Nadher, M.; Mudhish, M. Health and emergency-care platform for the elderly and disabled people in the Smart City. J. Syst. Softw. 2015, 110, 253–263. [Google Scholar] [CrossRef]
- Yin, Z.; Wang, D.; Liu, J. A Method of Constructing Robotics Service Platform for Assisting Handicapped or Elderly People. J. Robot. 2020. [Google Scholar] [CrossRef]
- Doukas, C.; Antonelli, F. A Full End-to-End Platform as a Service for Smart City Applications. In Proceedings of the 2014 IEEE 10th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Larnaca, Cyprus, 8–10 October 2014; pp. 181–186. [Google Scholar]
- Lambrinos, L.; Dosis, A. DisAssist: An Internet of Things and Mobile Communications Platform for Disabled Parking Space Management. In Proceedings of the 2013 IEEE Global Communications Conference (GLOBECOM), Atlanta, GA, USA, 9–13 December 2013; pp. 2810–2815. [Google Scholar]
- Nganji, J.T.; Brayshaw, M.; Tompsett, B. Ontology-driven disability-aware e-learning personalisation with ONTODAPS. Campus-Wide Inf. Syst. 2013, 30, 17–34. [Google Scholar] [CrossRef]
- Melis, A.; Mirri, S.; Prandi, C.; Prandini, M.; Salomoni, P.; Callegati, F. Crowdsensing for Smart Mobility through a Service-Oriented Architecture. In Proceedings of the 2016 IEEE International Smart Cities Conference (ISC2), Trento, Italy, 12–15 September 2016; pp. 1–2. [Google Scholar]
- Callegati, F.; Delnevo, G.; Melis, A.; Mirri, S.; Prandini, M.; Salomoni, P. I Want to Ride My Bicycle: A Microservice-Based Use Case for a Maas Architecture. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 18–22. [Google Scholar]
- Ali, S.; Kim, H.S.; Chong, I. Implementation Model of WoO Based Smart Assisted Living IoT Service. In Proceedings of the 2016 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 19–21 October 2016; pp. 816–818. [Google Scholar]
- Canali, C.; Colajanni, M.; Malandrino, D.; Scarano, V.; Spinelli, R. A novel intermediary framework for dynamic edge service composition. J. Comput. Sci. Technol. 2012, 27, 281–297. [Google Scholar] [CrossRef] [Green Version]
- Giacomo, G.D.; Mecella, M.; Patrizi, F. Automated service composition based on behaviors: The roman model. In Web Services Foundations; Springer: New York, NY, USA, 2014; pp. 189–214. [Google Scholar]
- Alamo, J.M.R.; Yang, H.I.; Wong, J.; Chang, C.K. Automatic service composition with heterogeneous service-oriented architectures. In International Conference on Smart Homes and Health Telematics; Springer: Berlin/Heidelberg, Germany, 2010; pp. 9–16. [Google Scholar]
- Fei, L.; Na, L.; Jian, L. A New Service Composition Method for Service Robot Based on Data-Driven Mechanism. In Proceedings of the 2014 9th International Conference on Computer Science & Education, Vancouver, Canada, 22–24 August 2014; pp. 1038–1043. [Google Scholar]
- Moumtzi, V.; Wills, C.; Koumpis, A. Service Composition to Support Ambient Assisted Living Solutions for the Elderly. In XII Mediterranean Conference on Medical and Biological Engineering and Computing 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 780–783. [Google Scholar]
- Tarawneh, H.; Alhadid, I.; Khwaldeh, S.; Afaneh, S. An Intelligent Cloud Service Composition Optimization Using Spider Monkey and Multistage Forward Search Algorithms. Symmetry 2022, 14, 82. [Google Scholar] [CrossRef]
- Li, T.; He, T.; Wang, Z.; Zhang, Y. An Approach to IoT Service Optimal Composition for Mass Customization on Cloud Manufacturing. IEEE Access 2018, 6, 50572–50586. [Google Scholar] [CrossRef]
- Li, F.; Zhang, L.; Liu, Y.; Laili, Y. QoS-Aware Service Composition in Cloud Manufacturing: A Gale-Shapley Algorithm-Based Approach. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 2386–2397. [Google Scholar] [CrossRef]
- Huang, B.; Li, C.; Tao, F.A. A chaos control optimal algorithm for QoS-based service composition selection in cloud manufacturing system. Enterp. Inf. Syst. 2014, 8, 445–463. [Google Scholar] [CrossRef]
- Akbaripour, H.; Houshmand, M. Service composition and optimal selection in cloud manufacturing: Landscape analysis and optimization by a hybrid imperialist competitive and local search algorithm. Neural Comput. Appl. 2018, 32, 10873–10894. [Google Scholar] [CrossRef]
- Zhou, J.; Yao, X. Hybrid teaching–learning-based optimization of correlation-aware service composition in cloud manufacturing. Int. J. Adv. Manuf. Technol. 2017, 91, 3515–3533. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Z. QoS-aware service composition for cloud manufacturing based on the optimal construction of synergistic elementary service groups. Int. J. Adv. Manuf. Technol. 2017, 88, 2757–2771. [Google Scholar] [CrossRef]
- Huo, L.; Wang, Z. Service composition instantiation based on cross-modified artificial Bee Colony algorithm. China Commun. 2016, 13, 233–244. [Google Scholar] [CrossRef]
- Yongdong, P. Bi-level programming optimization method for cloud manufacturing service composition based on harmony search. J. Comput. Sci. 2018, 27, 462–468. [Google Scholar] [CrossRef]
- Zhou, J.; Yao, X.; Lin, Y.; Chan, F.T.; Li, Y. An adaptive multipopulation differential artificial bee colony algorithm for many objective service composition in cloud manufacturing. Inf. Sci. 2018, 456, 50–82. [Google Scholar] [CrossRef] [Green Version]
- Assari, M.; Delaram, J.; Valilai, O.F. Mutual manufacturing service selection and routing problem considering customer clustering in cloud manufacturing. Prod. Manuf. Res. 2018, 6, 345–363. [Google Scholar] [CrossRef] [Green Version]
- Rosson, M.B.; Carroll, J.M. Scenario-Based Design. In Human-Computer Interaction; CRC Press: Boca Raton, FL, USA, 2009; pp. 161–180. [Google Scholar]
- Ronzhyn, A.; Spitzer, V.; Wimmer, M. Scenario technique to elicit research and training needs in digital government employing disruptive technologies. In Proceedings of the 20th Annual International Conference on Digital Government Research 2019, Dubai, United Arab Emirates, 18–20 June 2019; pp. 41–47. [Google Scholar]
- D’Ettole, G.; Bjørner, T.; De Götzen, A. How to Design Potential Solutions for a Cross-country Platform that Leverages Students’ Diversity: A User-Centered Design Approach–and Its Challenges. In International Conference on Human-Computer Interaction; Springer: Cham, Switzerland, 2020; pp. 415–426. [Google Scholar]
- Molich, R.; Woletz, N.; Winter, D. Living in UX Paradise–A UX Future Vision-Scenarios from a company at the highest level of UX maturity. In Mensch und Computer 2020-Usability Professionals; ACM: Magdeburg, Germany, 6–9 September 2020. [Google Scholar]
- Tarus, J.K.; Niu, Z.; Mustafa, G. Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artif. Intell. Rev. 2018, 50, 21–48. [Google Scholar] [CrossRef]
- Staab, S.; Studer, R. (Eds.) Handbook on Ontologies; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Abdalazeim, A.; Meziane, F. A review of the generation of requirements specification in natural language using objects UML models and domain ontology. Procedia Comput. Sci. 2021, 189, 328–334. [Google Scholar] [CrossRef]
- Rashmi, S.R.; Krishnan, R. Domain ontologies and their use in building intelligent systems: A comprehensive survey. In Proceedings of the 2017 International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bengaluru, India, 21–23 February 2017; pp. 611–616. [Google Scholar]
- Berrani, S.; Yachir, A.; Djamaa, B.; Mahmoudi, S.; Aissani, M. Towards a new semantic middleware for service description, discovery, selection, and composition in the Internet of Things. Trans. Emerg. Telecommun. Technol. 2022, e4544. [Google Scholar] [CrossRef]
- Pahariya, R.; Purohit, L. Recent Advancements in Semantic Web Service Selection. IETE J. Res. 2022, 1–10. [Google Scholar] [CrossRef]
- Zhao, X.; Li, R.; Zuo, X. Advances on QoS-aware web service selection and composition with nature-inspired computing. CAAI Trans. Intell. Technol. 2019, 4, 159–174. [Google Scholar] [CrossRef]
- Cardoso, J.; Pinto, A.M. The web ontology language (owl) and its applications. In Encyclopedia of Information Science and Technology, 3rd ed.; IGI Global: Hershey, PA, USA, 2015; pp. 7662–7673. [Google Scholar]
- Musen, M.A. The protégé project: A look back and a look forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef]
- Horridge, M.; Gonçalves, R.S.; Nyulas, C.I.; Tudorache, T.; Musen, M.A. Webprotégé: A cloud-based ontology editor. In Companion Proceedings of The 2019 World Wide Web Conference; Association for Computing Machinery: New York, NY, USA, 2019; pp. 686–689. [Google Scholar]
- Kapoor, B.; Sharma, S. A comparative study ontology building tools for semantic web applications. Int. J. Web Semant. Technol. 2010, 1, 1–13. [Google Scholar] [CrossRef]
- Dudáš, M.; Lohmann, S.; Svátek, V.; Pavlov, D. Ontology visualization methods and tools: A survey of the state of the art. Knowl. Eng. Rev. 2018, 33, e10. [Google Scholar] [CrossRef]
- Slimani, T. Ontology development: A comparing study on tools, languages and formalisms. Indian J. Sci. Technol. 2015, 8, 1–12. [Google Scholar] [CrossRef]
- Rosales-Huamani, J.A.; Castillo-Sequera, J.L.; Paredes-Larroca, F.; Landauro-Abanto, A.; Zuloaga-Rotta, L. A Review of Ontological Models Applied for the Assistance of Persons with Disabilities. Preprints 2020, 2020030383. [Google Scholar]
- Kehagias, D.D.; Tzovaras, D. An Ontology-Based Framework for Web Service Integration and Delivery to Mobility Impaired users. In World Summit on Knowledge Society; Springer: Berlin/Heidelberg, Germany, 2010; pp. 555–563. [Google Scholar]
- Zakraoui, J.; Zagler, W. An Ontology for Representing Context in User Interaction for Enhancing Web Accessibility for All. In Proceedings of the LEAFA 2010 The First International Conference on e-Learning For All, Hammamet, Tunisia, 3–5 June 2010. [Google Scholar]
- Gharebaghi, A.; Mostafavi, M.A.; Edwards, G.; Fougeyrollas, P.; Gamache, S.; Grenier, Y. Integration of the social environment in a mobility ontology for people with motor disabilities. Disabil. Rehabil. Assist. Technol. 2018, 13, 540–551. [Google Scholar] [CrossRef]
- Ali, F.; Kwak, D.; Khan, P.; Ei-Sappagh, S.H.A.; Islam, S.R.; Park, D.; Kwak, K.S. Merged ontology and SVM-based information extraction and recommendation system for social robots. IEEE Access 2017, 5, 12364–12379. [Google Scholar] [CrossRef]
- Braham, A.; Buendía, F.; Khemaja, M.; Gargouri, F. User interface design patterns and ontology models for adaptive mobile applications. Pers. Ubiquitous Comput. 2021, 1–17. [Google Scholar] [CrossRef]
- Hadjadj, A.; Halimi, K. Improving Health Disabled People through Smart Wheelchair based on Fuzzy Ontology. In Proceedings of the 2021 8th International Conference on Internet of Things: Systems, Management and Security (IOTSMS), Gandia, Spain, 6–9 December 2021; pp. 1–6. [Google Scholar]
- Zerkouk, M.; Cavalcante, P.; Mhamed, A.; Boudy, J.; Messabih, B. Behavior and capability based access control model for personalized telehealthcare assistance. Mob. Netw. Appl. 2014, 19, 392–403. [Google Scholar] [CrossRef]
- Torres-Carazo, M.I.; Rodríguez-Fórtiz, M.J.; Espin-Martin, V.; Hurtado, M.V. Ontology-based user profile modelling to facilitate inclusion of visual impairment people. In International Conference on Model and Data Engineering; Springer: Cham, Switzerland, 2017; pp. 386–394. [Google Scholar]
- Torres-Carazo, M.I.; Rodríguez-Fórtiz, M.J.; Hurtado, M.V.; Samos, J.; Espín, V. Architecture of a mobile app recommender system for people with special needs. In International Conference on Ubiquitous Computing and Ambient Intelligence; Springer: Cham, Switzerland, 2014; pp. 288–291. [Google Scholar]
- Nganji, J.T.; Brayshaw, M.; Tompsett, B. Ontology-based e-learning personalisation for disabled students in higher education. Innov. Teach. Learn. Inf. Comput. Sci. 2014, 10, 1–11. [Google Scholar] [CrossRef]
- Stancin, K.; Hoic-Bozic, N. The Importance of Using Digital Games for Educational Purposes for Students with Intellectual Disabilities. In Proceedings of the International Scientific Conference on Innovative Approaches to the Application of Digital Technologies in Education, Stavropol, Russia, 12–13 November 2021. [Google Scholar]
- Gupta, S.; Garg, D. Ontology Based Information Retrieval for Learning Styles of Autistic People. In International Conference on High Performance Architecture and Grid Computing; Springer: Berlin/Heidelberg, Germany, 2011; pp. 293–298. [Google Scholar]
- Abdulrazak, B.; Chikhaoui, B.; Gouin-Vallerand, C.; Fraikin, B. A standard ontology for smart spaces. Int. J. Web Grid Serv. 2010, 6, 244–268. [Google Scholar] [CrossRef]
- Vassilev, V.; Ulman, M.; Ouazzane, K. Ontocarer: An ontological framework for assistive agents for the disabled. In Proceedings of the 3rd International Conference on Digital Information Processing and Communications (ICDIPC 2013), Dubai, United Arab Emirates, 30–31 January 2013. [Google Scholar]
- Djaid, N.T.; Dourlens, S.; Saadia, N.; Ramdane-Cherif, A. Fusion and fission engine for an assistant robot using an ontology knowledge base. J. Ambient. Intell. Smart Environ. 2017, 9, 757–781. [Google Scholar] [CrossRef]
- Ng, W. Disabled Entrepreneurs. In World Encyclopedia of Entrepreneurship; Edward Elgar Publishing: Cheltenham, UK, 2021. [Google Scholar]
- Talens, G.; Wintergerst, C. Ontologies Cooperation to Model the Needs of Disabled Persons. In IFIP International Workshop on Artificial Intelligence for Knowledge Management; Springer: Cham, Switzerland, 2021; pp. 19–34. [Google Scholar]
- Fernandez, C.; Zallio, M.; Berry, D.; McGrory, J. Towards a people-first engineering design approach. A comprehensive ontology for designing inclusive environments. Proc. Des. Soc. 2021, 1, 3179–3188. [Google Scholar] [CrossRef]
- Alonso, K.; Aginako, N.; Lozano, J.; Olaizola, I.G. Ontology Based Middleware for Ranking and Retrieving Information on Locations Adapted for People with Special Needs. In International Conference on Computers for Handicapped Persons; Springer: Berlin/Heidelberg, Germany, 2012; pp. 351–354. [Google Scholar]
- Escobedo, L.; Tentori, M. Mobile Augmented Reality to Support Teachers of Children with Autism. In International Conference on Ubiquitous Computing and Ambient Intelligence; Springer: Cham, Switzerland, 2014; pp. 60–67. [Google Scholar]
- Burns, W.; Nugent, C.; McCullagh, P.; Zheng, H. Design and Evaluation of a Smartphone Based Wearable Life-Logging and Social Interaction System. In Proceedings of the 2014 IEEE 27th International Symposium on Computer-Based Medical Systems, New York, NY, USA, 27–29 May 2014; pp. 435–440. [Google Scholar]
- Torres-Carazo, M.I.; Rodríguez-Fórtiz, M.J.; Torres, M.V.H. Development of an ontology for the inclusion of app users with visual impairments. IEEE Access 2021, 9, 44339–44353. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhang, Y.; Lyu, M.R. Investigating QoS of real-world web services. IEEE Trans. Serv. Comput. 2012, 7, 32–39. [Google Scholar] [CrossRef]
- WS-DREAM. Towards Open Datasets and Source Code for Web Service Research. 2011. Available online: https://wsdream.github.io/#dataset (accessed on 15 February 2022).
- Al-Masri, E.; Mahmoud, Q.H. Investigating Web Services on the World Wide Web. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 795–804. [Google Scholar]
- QWS Dataset Ver 2.0 (The Quality of Service for Web Services Dataset). 2008. Available online: https://qwsdata.github.io/ (accessed on 15 February 2022).
- Hasnain, M.; Pasha, M.F.; Ghani, I.; Mehboob, B.; Imran, M.; Ali, A. Benchmark dataset selection of Web services technologies: A factor analysis. IEEE Access 2020, 8, 53649–53665. [Google Scholar] [CrossRef]
- GitHub. 2022. Available online: https://github.com/anamoun/servicesfordisabled.git (accessed on 15 May 2022).
- Pawara, P.; Okafor, E.; Groefsema, M.; He, S.; Schomaker, L.R.; Wiering, M.A. One-vs-One classification for deep neural networks. Pattern Recognit. 2020, 108, 107528. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Widianta, M.M.D.; Rizaldi, T.; Setyohadi, D.P.S.; Riskiawan, H.Y. Comparison of multicriteria decision support methods (AHP, TOPSIS, SAW & PROMENTHEE) for employee placement. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2018; Volume 953, p. 012116. [Google Scholar]
- Serrai, W.; Abdelli, A.; Mokdad, L.; Hammal, Y. Towards an efficient and a more accurate web service selection using MCDM methods. J. Comput. Sci. 2017, 22, 253–267. [Google Scholar] [CrossRef]
- Gandhi, U.; Bothera, A.; Garg, N.; Gupta, I. A Machine Learning-Based Approach for Efficient Cloud Service Selection. In International Advanced Computing Conference; Springer: Cham, Switzerland, 2021; pp. 626–632. [Google Scholar]
- Beingolea, J.R.; Zea-Vargas, M.A.; Huallpa, R.; Vilca, X.; Bolivar, R.; Rendulich, J. Assistive Devices: Technology Development for the Visually Impaired. Designs 2021, 5, 75. [Google Scholar] [CrossRef]







| Study | Concepts | Domains of Ontology |
|---|---|---|
| [66] |
| Transportation, tourism, and education |
| [67] |
| E-learning |
| [68] |
| Mobility |
| [69] |
| Hotels, transportation; medicine, and cities |
| [23] |
| IoT-based smart home environment |
| [70] |
| Mobile applications |
| [71] |
| Health and IoT |
| Feature Variable | Type | Explanation | Possible Values |
|---|---|---|---|
| User ID | Long | Unique Identifier | 1–1000 (number of generated users) |
| Time | String | The local time of the user when accessing the services | Morning, afternoon, evening |
| Language | String | The main language that the user can use to communicate fluently | Arabic, non-Arabic |
| Location | String | The location from which the user is accessing the services | Public, private |
| Disability type | String | The type of impairment suffered by the user | Blind, visual (Impairment), deaf, hearing (Impairment), speech, physical, none |
| User device | String | The interactive technology used to access the assistive services | PC, smart TV, tablet, smart phone, smart watch, voice assistant |
| Tasks (T0 to T11) | Integer | The possible tasks necessary to access the online course | 0 (= not supported), 1 (= supported) |
| Feature Variable | Type | Explanation | Possible Values |
|---|---|---|---|
| User ID | Long | Unique Identifier | 1–1000 (number of generated users in Dataset 1) |
| Task ID (0–11) | Integer | The task ID | 0–11 |
| Task name | String | The name of the task/service that helps fulfill the online course scenario | Task name from the above list |
| Service provider name | String | The corresponding service providers for each possible task | Each task is accomplished by five different service providers |
| Time | String | The local time of the user when accessing the service providers | Morning, afternoon, evening |
| Location | String | The location from which the user is accessing the services | Public, private |
| Response | Double | The average time spent to send a request to the service provider and receive a response | Any number of milliseconds |
| Availability | Double | The number of successful SP invocations (out of total invocations) | Generally varies in the range of 0–100 |
| Successability | Double | The number of successful responses (out of total request messages) | Generally varies in the range of 0–100 |
| Latency | Double | The time spent by the service provider to respond to a specific request | Any number of milliseconds |
| Cost | Double | The cost of using the service provider | Ranges from 0 to 1 |
| QoSMean | Double | The average QoS of four metrics (response, availability, successability, and latency) | The mean ranges from 0 to 1 |
| QoSRating | Integer | The average user rating of the QoS factors of the service provider | The rating ranges from 1 to 5 |
| Accessibility rating | Integer | The average user rating of the accessibility features of the service provider | The rating ranges from 1 to 5 |
| Task Name | Competing Service Providers |
|---|---|
| ‘Identify user location’ | ‘Location_service’, ‘Geo_location’, ‘Online_location’, ‘Live_location’, ‘Location_detection’ |
| ‘Notify user about class’ | ‘Notifications’, ‘Notify’, ‘Push_notifications’, ‘Notify_messages’, ‘Notify_emails’ |
| ‘Live stream the classroom’ | ‘Google_meet’, ‘Zoom’, ‘Microsoft_teams’, ‘Skype’, ‘Slack’ |
| ‘Speech to text’ | ‘Google_ASR’, ‘Microsoft_ASR’, ‘Apple_ASR’, ‘Free_ASR_service’, ‘Online_ASR’ |
| ‘Text to speech’ | ‘Google_TTS’, ‘Microsoft_TTS’, ‘Apple_TTS’, ‘Free_TTS_service’, ‘Online_TTS’ |
| ‘Speech to sign language’ | ‘Sign_language_creation’, ‘Signaling’, ‘Sign_speech’, ‘Gestures_service’, ‘Sign_language’ |
| ‘Sign language to speech’ | ‘Sign_language_interpretation’, ‘Signaling’, ‘Sign_speech’, ‘Gestures_service’, ‘Sign_language’ |
| ‘Show subtitles or captions on screen’ | ‘Subtitles’, ‘Captions’, ‘Transliteration’, ‘Google_STT’, ‘Caption_service’ |
| ‘Translate text from Arabic to English’ | ‘Machine_translation’, ‘Google_translate_API’, ‘Online_translation’, ‘Arabic_translation’, ‘Live_translation’ |
| ‘Customize screen color contrast’ | Apple_resolution’, ‘Windows_resolution’, ‘color_contrast’, ‘High_res_colors’, ‘Greyscale_conversion’ |
| ‘Image text reader’ | ‘Image_caption’, ‘OCR’, ‘Image_characters’, ‘Image_to_text’, ‘Image_reader’ |
| ‘Speech commands’ | ‘Alexa’, ‘Voice_assistance’, ‘Apple_assistant’, ‘Google_commands’, ‘speech_keywords’ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Namoun, A.; Abi Sen, A.A.; Tufail, A.; Alshanqiti, A.; Nawaz, W.; BenRhouma, O. A Two-Phase Machine Learning Framework for Context-Aware Service Selection to Empower People with Disabilities. Sensors 2022, 22, 5142. https://doi.org/10.3390/s22145142
Namoun A, Abi Sen AA, Tufail A, Alshanqiti A, Nawaz W, BenRhouma O. A Two-Phase Machine Learning Framework for Context-Aware Service Selection to Empower People with Disabilities. Sensors. 2022; 22(14):5142. https://doi.org/10.3390/s22145142
Chicago/Turabian StyleNamoun, Abdallah, Adnan Ahmed Abi Sen, Ali Tufail, Abdullah Alshanqiti, Waqas Nawaz, and Oussama BenRhouma. 2022. "A Two-Phase Machine Learning Framework for Context-Aware Service Selection to Empower People with Disabilities" Sensors 22, no. 14: 5142. https://doi.org/10.3390/s22145142
APA StyleNamoun, A., Abi Sen, A. A., Tufail, A., Alshanqiti, A., Nawaz, W., & BenRhouma, O. (2022). A Two-Phase Machine Learning Framework for Context-Aware Service Selection to Empower People with Disabilities. Sensors, 22(14), 5142. https://doi.org/10.3390/s22145142