1. Introduction
Laparoscopic surgery is the minimally invasive alternative to open surgery of the abdomen. Two or more surgical instruments, along with an endoscope that allows the patient to be observed internally, are introduced into the abdominal cavity through several small incisions. The reduced size of these incisions makes it possible to achieve a faster recovery rate, minimize the risk of infections and cause less pain compared to open surgery. These medical benefits have led to the widespread use of laparoscopy in numerous operations, becoming the standard for many organ systems, especially gynecological and digestive [
1].
Unfortunately, laparoscopic operations are not easy to perform. The surgeon loses tactile feedback on the patient’s tissues as the clinician must manipulate them using long laparoscopic instruments. Furthermore, clinicians cannot perceive a three-dimensional scenario as in open surgery. Laparoscopic operations are always observed through a monitor that significantly restricts the field of vision and on which the surgeon completely loses the sensation of depth. These technical difficulties make any manipulation of tissues more complicated.
To facilitate clinicians’ work during surgeries, as well as allowing robots to collaborate with them in a wide range of tasks, intensive efforts have been made to improve automation and to increase surgeons’ capabilities [
2]. A part of these efforts are focused on obtaining information from a laparoscopic video signal, where different tasks have been tackled, e.g., replacing physical sensors through the estimation of forces using images [
3]; classifying actions such as the different steps of a suture procedure [
4]; allowing collaborative robots to understand what actions the surgeon is carrying out; or evaluating different surgery-related skills [
5,
6,
7,
8].
Furthermore, multiple studies are centered on enhancing artificial perception of surgery-related elements, as localizing, detecting, and tracking these elements are crucial for robotic applications; for example, tracking surgical tools [
9,
10,
11,
12], which can be used in multiple tasks [
13] such as surgery-video analysis based on tool presence [
14,
15] or classification of different surgical phases based on the tools that appear in the video signal [
16]. Additionally, although many of the studies deal with 2D estimation, proposals working with 3D model estimates of surgery elements can also be found [
17,
18].
Although extensive work has been done in surgical tool detection using deep learning architectures, to the best of our knowledge, this has not been extended to surgical gauzes. Gauze detection algorithms not only allow for greater accuracy and reliability in the determination of the operation phase, but also enable the development of other more immediate applications. In not-robotized laparoscopic surgery, it is feasible to track the gauze by processing the captured video signal provided by the endoscope in a transparent and unattended way for the health personnel [
19,
20,
21]. Automated gauze tracking relieves medical staff from routine counting and control tasks to avoid the inadvertent retention of these items, a medical error that occurs rarely, but it can cause serious complications in the patient’s health [
22,
23,
24].
It seems clear that the detection and localization of gauze in the images from the endoscope can provide valuable information to automate numerous tasks in the operating room. However, gauze detection in images is not straightforward due to its variable appearance, and because, when they are soaked in blood or other body fluids, they blend with the patient’s internal tissues [
21]. Furthermore, in surgical operations, the illumination inside the patient’s body is not uniform and it often generates frequent brightness on the organs. Additionally, the endoscopic camera is subject to movements that are not always smooth, and smoke can appear on the scene due to tissue cauterization. All these practical difficulties cause poor image quality due to saturation, blurring or defocusing.
In other circumstances, under steady imaging conditions, gauze texture features could be modelled explicitly with hand-crafted descriptors, expecting good results in classification. However, previous work in surgical gauze detection in images [
19,
20,
21] shows that it is challenging to achieve good robustness with traditional methods for feature extraction in these complex situations and they always require a great deal of programming effort. In uncontrolled environments where imaging conditions fluctuate and when the intra-class variability of the features is important, it is known that Convolutional Neural Networks (CNNs) are more robust and deliver superior results than traditional descriptors [
21,
25] with the only shortcoming of their computational burden.
In this article, we present a gauze presence and location dataset [
26] for training machine learning models, allowing the development of automated models to detect surgical gauze on endoscopic video signal, which provides key information to infer the stage of the operation, crucial in tasks such as in autonomous robotic assistants and temporal segmentation of laparoscopic videos into surgical phases. Alongside the gauze presence and location dataset for training models presented in this paper, we analyzed a set of baselines using well-established computer vision machine learning architectures that have been trained and tested using our data. These baselines are object detection using YOLOv3, coarse segmentation using various convolutional backbones, and semantic segmentation using a U-Net architecture. Special attention has been paid to runtime due to the need to process video frames in real time in most applications, such as in the case of autonomous robot guidance or in gauze tracking to avoid inadvertent retentions.
The rest of the document is organized as follows. In the following section, we introduce our dataset and the proposed train/evaluation distribution, the localization tasks which we present baselines for, and the architectures we have trained.
Section 3 reports on the experimental results, with
Section 4 focused on the discussion of those and the conclusions of the study.
2. Materials and Methods
In the following section, the main contribution of the paper, the dataset, is presented. Furthermore, we detail the different techniques used for the image analysis tasks, as well as the hardware and software used during the study, followed by the evaluation methodology.
2.1. Dataset
The presented dataset [
26] consists of 42 video files (30 with gauze presence, ~33 min in total and 12 without gauze presence, ~13 min), collected in different settings. The videos were acquired using a STORZ TELECAM One-Chip Camera Head 20212030, color system PAL with integrated focal Zoom Lens, f = 25–50 mm (2×), with an image sensor of ½ inch CCD and 752 (H) × 582 (V) pixels per chip (PAL) equipped with a Hopkins telescope 0°, 10 mm, 31 cm.
The videos have not been recorded in laparoscopic surgery operations on real patients. In order to test the gauze detection algorithm under the different conditions, diverse operation scenarios have been recreated in a laparoscopic simulator (
Figure 1) using animal organs (No live animals have been used in our experiments. The pig organs used in our scenarios were provided by a certified local slaughterhouse). The scenarios include the following situations: absence of gauze, absence of gauze with tools presence, presence of a unique clean gauze and tools, presence of a unique stained gauze and tools, and presence of multiple gauzes in different states. Some frames from different videos are shown in
Figure 2. An overview of the characteristics of each video, as well as the directory structure, are included in
Appendix A.
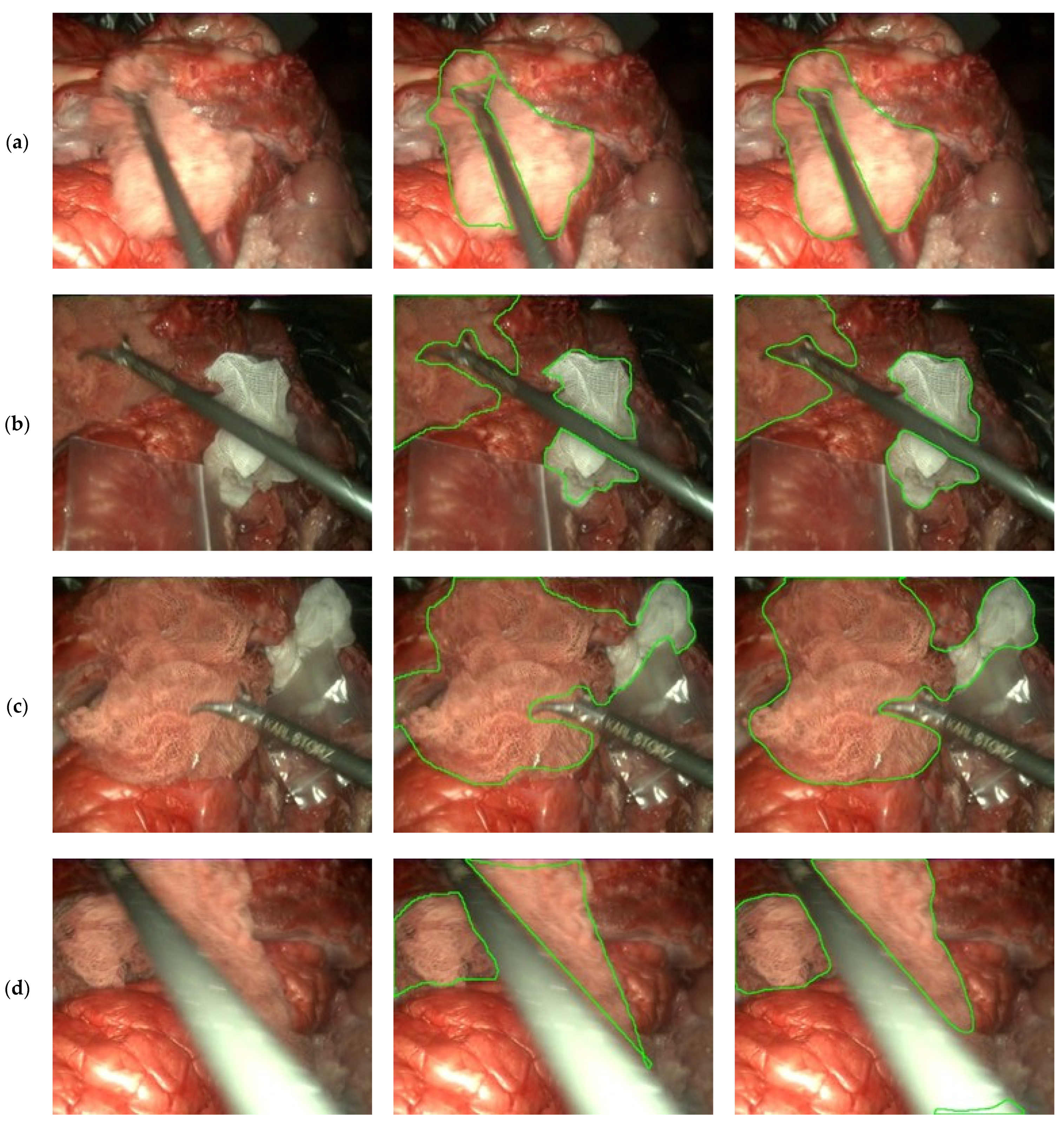
A subset of these videos (18 out of the 30 videos with gauze) has been sampled every 10 frames, resulting in 4003 frames, where a binary mask for the gauze has been manually traced. Some samples of these generated masks are presented in
Figure 3. This way, the dataset enables supervised training in semantic segmentation tasks.
The human-generated masks have been used to automatically generate and classify fragments of 100 × 100 pixels based on the presence or absence of gauze in the mask corresponding to each frame. This automatic generation results in 168,126 fragments (80,918 with gauze and 87,208 without), which are extensively used in our work and are therefore included in the presented dataset (As the fragments are generated and classified automatically based on the masks, it is trivial to generate them of any desired size. A Python script to do so is included in the dataset).
2.2. Train-Evaluation Split of the Dataset
To ensure independence between training and evaluation sets, as consecutive frames in a video may be too similar and pollute the evaluation set, random splits have been discarded. Instead, the dataset has been split video-wise in the following fashion (
Table 1), ensuring equilibrium between tool presence, blood impregnation and movement of the telecam in both partitions. The resulting distribution of fragments and masks is presented in
Table 2.
2.3. Gauze Detection
Object detection is the pillar of many computer vision applications ranging from face detection in security systems to pedestrian detection in autonomous vehicle driving. Detection techniques have undergone enormous development in the last five years thanks to the advance of convolutional neural networks. Given an image or video stream, object detection involves locating and classifying the searched objects present in the image. The outcome of a detection algorithm is usually represented by labelled bounding boxes marked on the items that appear in the image.
Region-based CNNs methods consider object detection as a two-stage problem: generating the region proposals and then classifying those regions. However, a few recent algorithms pose object detection from an integrated approach by feeding the input image into a single convolutional network that predicts the bounding boxes and their class probabilities. The YOLO (You Only Look Once) algorithm, proposed by Redmon et al. [
27] in 2016, implemented a unified approach by posing object detection as a regression problem. YOLO is recognized as one of the most efficient algorithms, suitable for real-time processing, due to this evaluation with a single convolutional network.
In YOLO, the input image is initially divided into 13 × 13 square cells and then each cell predicts B = 2 bounding boxes. The size of these bounding boxes is preset from the ground truth in the data set. Each bounding box is associated with the probability that an object is contained inside the box (objectness score) and the probabilities of the detected object belonging to a particular class (class confidences).
The third version of the algorithm, YOLOv3 [
28], increased its performance even more introducing an improved backbone classifier, Darknet-53. This backbone includes residual connections and has more layers than its predecessor (Darknet-19). YOLOv3 carries out the prediction at three different scales, downsampling the input image’s dimensions by a factor of 32, 16 and 8. This multiscale approach enhances YOLOv3 capacity to deal with different scales.
We have implemented this object detector as the authors propose in their paper [
28], which includes Darknet-53 as a backbone classifier.
2.4. Gauze Coarse Segmentation
Gauze inside the patient’s body does not exhibit a defined shape like the tools used in surgery. The form that gauzes adopt in operations is unpredictable and variable. Its texture, on the other hand, is highly discriminating.
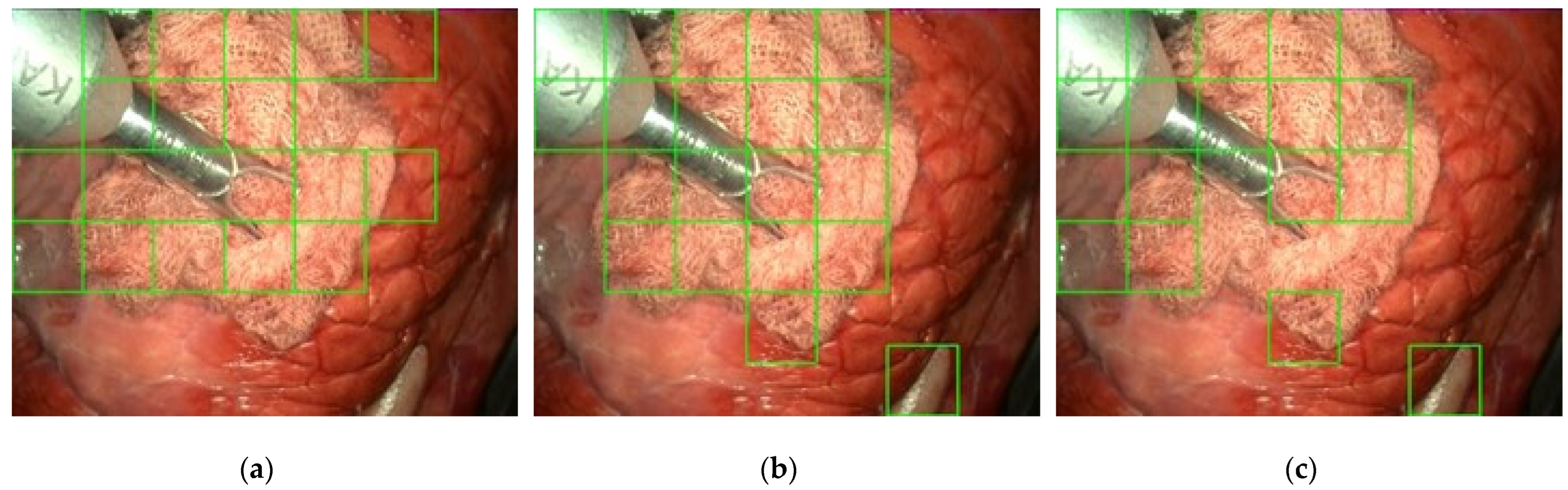
In order to mainly consider gauze texture, we propose a coarse segmentation approach that focuses on area analysis rather than on shape analysis. For this reason, in this second approach, the image has been divided into square cells (
Figure 4) to categorize each one individually as gauze or background. This approach is not feasible in the case of a general detector because it is always required that the entire object appears in the analyzed window. However, in the case of gauze, the analysis of a fragment allows a reliable classification due to its particular texture.
Some tests have been carried out to establish the most appropriate size of the image cells. A priori, the use of small cells would seem to be the right option because they would allow to define more precisely the gauze in the image. However, the poor results obtained in the tests indicate that classifying very small cells is not a good option, probably because their low area makes them statistically more unstable in the classification. On the other hand, if the size is too large, the area of analysis is more significant, but the detection is subject to the gauze occupying a good part of the cell, which can be difficult when cell dimensions are excessive. Tests have suggested that a cell size of 100 × 100 pixels is a good compromise between these two situations.
However, as the size of the images provided by the endoscope is 720 × 576, smaller cells will be generated at the left and lower edges of the image. Cells on the right edge (cells number 7, 15, …, 47 in
Figure 4) will not be processed due to their irrelevant size (20 × 100). However, the last row of the image (cells number 40 to 46 in
Figure 4) will be considered because they are more significant. In this case, the 100 × 100 areas have been sampled from the bottom edge. This generates a small overlap of 100 × 24 with the squares of the previous row but allows to preserve the square shape of cells.
Classification of cells in the image have been solved with CNNs through transfer learning. We have analyzed the performance in gauze detection using three different CNN models: InceptionV3 [
29], MobileNetV2 [
30] and ResNet-50 [
31]. All these architectures are formed by a set of convolutional layers that extract features from the images progressively, this is, starting with low-level features and transitioning into high-level features as the input advances through the network layers. However, each one of the mentioned networks is characterized by different additional mechanisms, such as inception modules in InceptionV3, depthwise and pointwise convolutions along linear bottlenecks in MobileNetV2, or residual connections in the ResNet-50 model.
In order to perform binary classifications, every model last layer has been modified to have only one output neuron. Also, image fragments have been scaled to each model input size. The number of layers and parameters, as well as the input size in each of these networks, is summarized in
Table 3.
2.5. Gauze Segmentation
Some applications such as robotic manipulation, however, require an as-exact-as-possible shape detection solution. Given an input image, either static or from a video frame, semantic segmentation architectures label each pixel in said image, classifying them in one of the possible classes. Supervised segmentation approaches are usually difficult to train, as non-synthetic ground truth is scarce and difficult to obtain, therefore the value of the hand-traced masks of gauzes in our dataset [
26] for this type of task.
Along the past years, multiple semantic-segmentation-oriented approaches have been proposed using fully convolutional networks [
32] models based on regional convolutional networks (Mask R-CNN [
33] which extends Faster R-CNN [
34], encoder–decoder-based models such as SegNet [
35], and dilated convolutions as in DeepLab publications [
36,
37].
In this work, we present a baseline for gauze semantic segmentation using a U-Net-based architecture (implementation from [
38]). This architecture is formed by an encoding block, where each layer extracts and downsamples feature maps from the previous input to pass them to the next layer, and a decoder block where each layer fuses the corresponding representation from the encoder and the previous layer upsampled output to generate the segmentation map. The encoder in our study has an unfrozen MobileNetV2 [
39] pretrained on the 2012 ILSVRC ImageNet dataset [
40] as the feature extractor and a decoder with blocks of {256, 128, 64, 32, 16} kernels. During training, an Adam [
41] optimizer was used with a learning rate of 0.0001, and, following the original Adam paper proposal, β1, β2 and ε values of 0.9, 0.999 and 1 × 10
−7, respectively. The optimized function has been Dice Loss [
42]. Furthermore, as input image size to the network is 320 × 320, a bilinear interpolation resizing operation is incorporated in the preprocessing of the image, allowing training and inference on original size images.
Due to the nature of the task, segmentation training can be improved if the dataset is augmented to present image flips, scale variations, rotations, and changes to the brightness and sharpness of the image. The intuition behind these transformations is that both gauzes and the laparoscopic telecam are constantly changing orientation and position, hence the geometric transformations. Blurriness due to stains in the lens and movement is also common, which motivates the application of Gaussian blur, sharpness filters, and movement blur augmentations. Ultimately, as light coming from the telecam can also affect the appearance of gauze and surgical instruments, contrast and brightness augmentations are also considered. This set of transformations is randomly parametrized and applied each epoch, increasing the number of relevant images and reducing the variance of the trained model. The final model was obtained training on the augmented dataset for 10 epochs.
2.6. Hardware and Software
The models presented in this paper are public-domain implementations of well-established models, mentioned in their corresponding sections, which have been trained and tested using Python 3.7 (Python Software Foundation, Wilmington, NC, USA) and the deep learning framework Keras 2.6 (Various authors, no location). Image pre-processing and labelling have been carried out using the OpenCV 4.5 (OpenCV, Palo Alto, CA, USA) Python package. Training (fine tuning) and test inference of all models have been carried out using a system with the following specifications (
Table 4).
2.7. Evaluation
Regarding the evaluation of the performance of the methods presented, based on the task the model takes on, different metrics such as Intersection over Union (IoU), accuracy, precision, recall, F1 Score, and the frames processed per second (FPS) have been computed.
Intersection over Union (IoU) measures the relation between overlapped area in the ground truth and predicted mask or bounding box and area of the union of said elements. In this work, we consider binary masks for semantic segmentation.
Accuracy is the most intuitive evaluation of performance, and it is simply the relation between the image cells that are correctly classified to the total of cells:
where
TP: true positives, image cells correctly marked as gauze.
TN: true negatives, cells correctly marked as background.
FP: false positives, cells wrongly marked as gauze.
FN: false negatives, cells wrongly marked as background.
Precision estimates what fraction of image cells classified as gauze are correct. It is defined as the number of fragments correctly marked as gauze (TP) divided by the overall number of them marked as gauze (TP + FP):
The recall or sensitivity refers to the fraction of the image cells with gauze that are detected:
The proper algorithm should have a balance between precision and sensitivity. This means, in our case, that the algorithm should detect all the cells in the image where gauze is present and should not misclassify as gauze the samples corresponding to the background. The F1 Score combines the precision and recall of a classifier into a single metric. The value of the F1 Score ranges from zero, if either the precision or the recall is zero, to one, for a classifier with perfect precision and recall.
Another balanced metric is the Matthews Correlation coefficient (MCC), which takes into account the ratios of every category in the confusion matrix.
Average precision (AP) estimates the average precision value for recall value over 0 to 1, this means the area under the precision-recall curve.
Mean average precision (mAP) is the average AP for all the classes, this metric measures the net’s accuracy doing a location and classification of the object.
Finally, the speed of each network, in Frames Per Second (FPS), has been calculated as the average amount of frames of video the CNN can process per second.
4. Discussion
The detection of surgical tools in laparoscopic video using CNNs is a very active area of research. However, gauze detection and localization has been almost unexplored even though these techniques can provide a considerable amount of supplementary information to automatize surgical applications. The variable appearance of gauze and their tendency to blend with a patient’s tissues may have prevented the development of detection algorithms. Although several datasets have been proposed in the context of laparoscopic surgery, these datasets focus on surgical tools, both presence detection [
43] and segmentation [
44,
45] also covering anatomical [
46,
47] and surgical actions [
46,
47,
48]. To the best of our knowledge, no dataset labelling gauzes has been published. The lack of a dataset with ground truth annotations of gauzes during a surgical procedure hinders the research of new approaches to this problem. Our dataset [
26] amends this, with hand-labelled images of gauzes in different situations and environments.
In respect of the results obtained from the proposed baselines, the YOLOv3 architecture underperforms when compared with the other two methods with a recall of around 76%; however, it can process images at more than 30 FPS. This limitation in results quality is probably due to the virtually unlimited number of shapes the gauzes can take, which conflicts with the limited predefined anchors of these models.
The coarse segmentation approach, which is patch-based and has been tested with different backbones, presents satisfactory results (accuracy of around 90% using ResNet-50) when considering that no pre-processing has been applied to the resulting patches (e.g., thresholding the number of patches to eliminate outliers, or taking into consideration neighbor patches classification to ensure consistency). However, this approach lacks inference speed, mainly because an actual frame is composed of 42 patches, and therefore, an inference speed of 30 FPS with this method requires the classification of 1260 images every second by the entire network, which limits the execution of these models at real-time speeds.
In the U-Net segmentation baseline, using a MobileNetV2 architecture has resulted in a good compromise between inference speed and results quality, as it is possible to execute the model at real-time speeds (above 30 FPS) on a video signal while obtaining an IoU of more than 0.85 on the defined evaluation set of the dataset. The accuracy reached by U-Net in gauze segmentation and its speed of execution make this architecture perfectly suited for real-time applications such as gauze manipulation in autonomous robots. The errors visualized on these results come mainly from movement blur in anatomical structures and extreme brightness in surgical tools. To remediate this, a model trained on the previously mentioned datasets containing tools and anatomic information would relieve false gauze positives since the system could identify tools as the correct object.
Finally, as the proposed dataset [
26] enables the development of novel architectures and applications related to laparoscopic surgery, further work englobes multiple paths such as the training of transformers architectures [
49,
50] for different tasks, as these have been proven to present outstanding results in various domains, the development of temporal sequence models that take into account past frames to enhance the results, or, as previously mentioned, the incorporation of gauze detection into a laparoscopic surgery segmentation framework capable of complete scene segmentation.
In conclusion, these results are encouraging and demonstrate that the dataset proposed in this paper enables accurate gauze detection and segmentation using CNNs, even in real time, paving the way for the development of new practical applications such as enhancing perception of autonomous surgical robots, making them capable of tracking and manipulating gauzes in real time to manipulate during different surgical procedures; not-robotized minimally invasive surgery applications like gauze tracking in the endoscope video to avoid inadvertent gauze retention, serving as an additional tool for surgery nurses during laparoscopic procedures; or cataloging tasks, such as offline scene labelling and video indexing to separate different stages of surgeries, which facilitates multimedia querying by students and professionals.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







