
CTTGAN: Traffic Data Synthesizing Scheme Based on Conditional GAN


Abstract
:1. Introduction
- We proposed the CTTGAN scheme to expand the small category samples in the traffic datasets. After the expansion, all the indicators have been improved, and the effect is stable.
- In the field of traffic data synthesizing, our research focuses on one-dimensional tabular feature data rather than image data, which are applicable to machine learning models and greatly reduce the storage and computing costs.
- The scheme uses the CTGAN model, which can obtain better results when processing discrete variables and continuous variables in traffic data at the same time.
2. Preliminaries
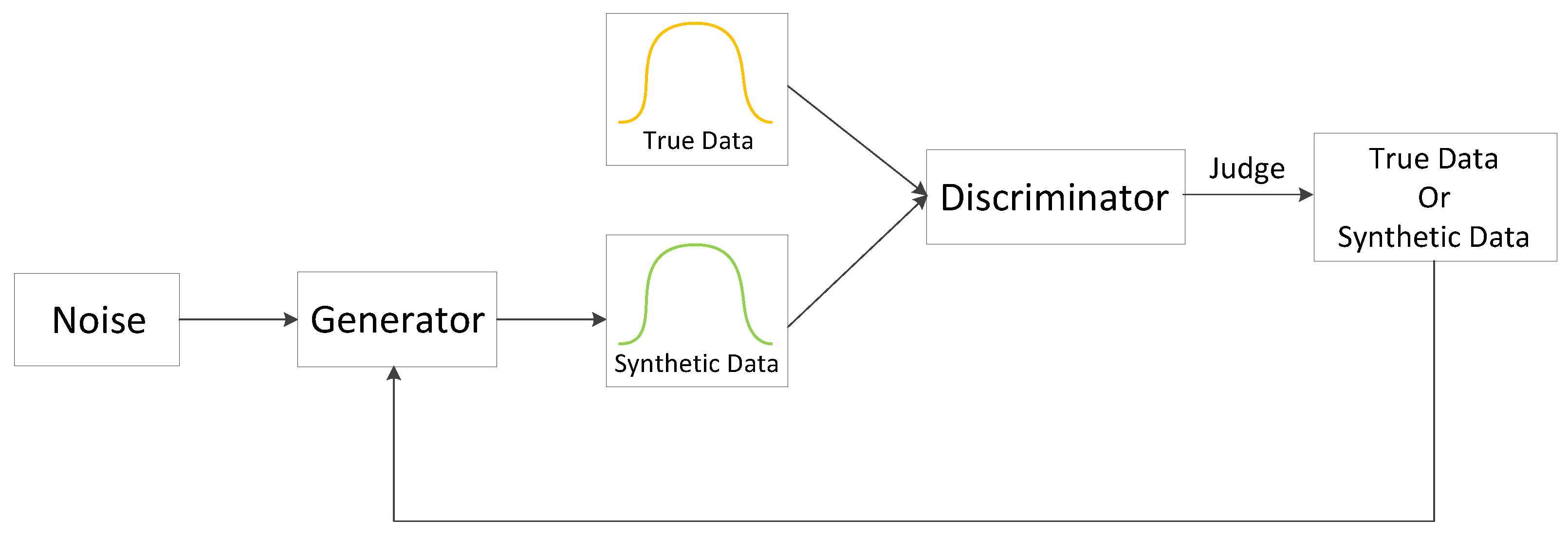
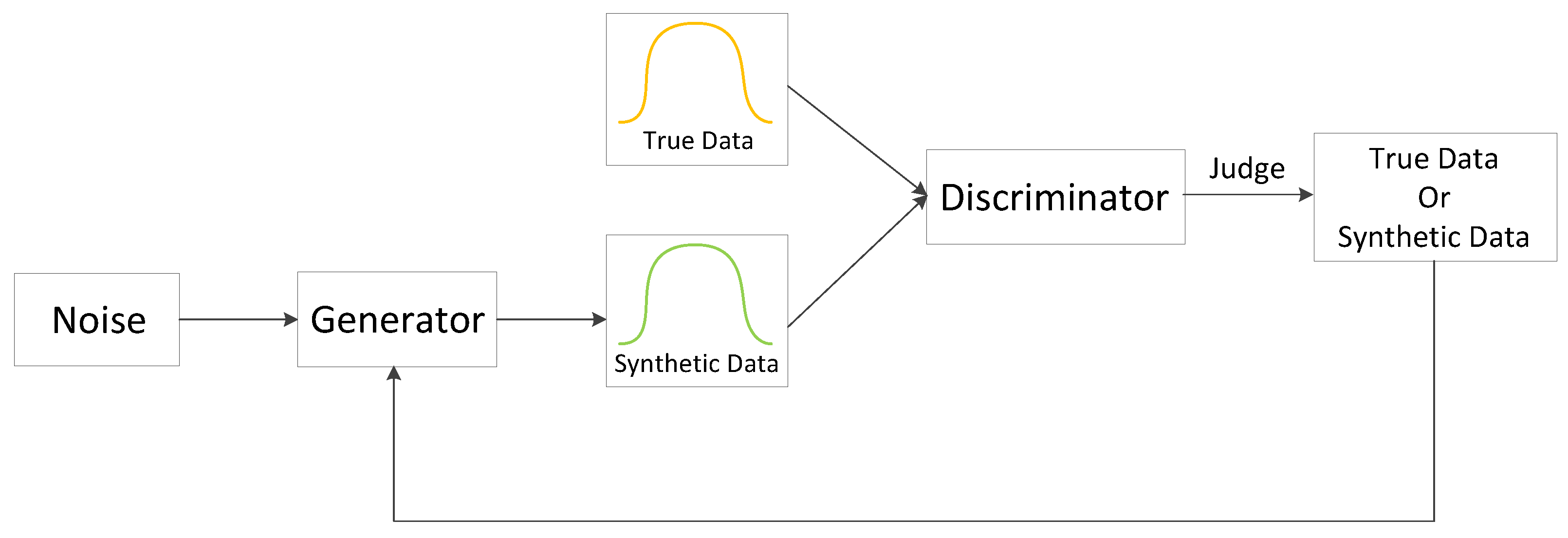
2.1. GAN and Conditional GAN
2.2. GAN in Generating Tabular Data
2.3. Conditional Tabular GAN (CTGAN)
3. Proposed Scheme
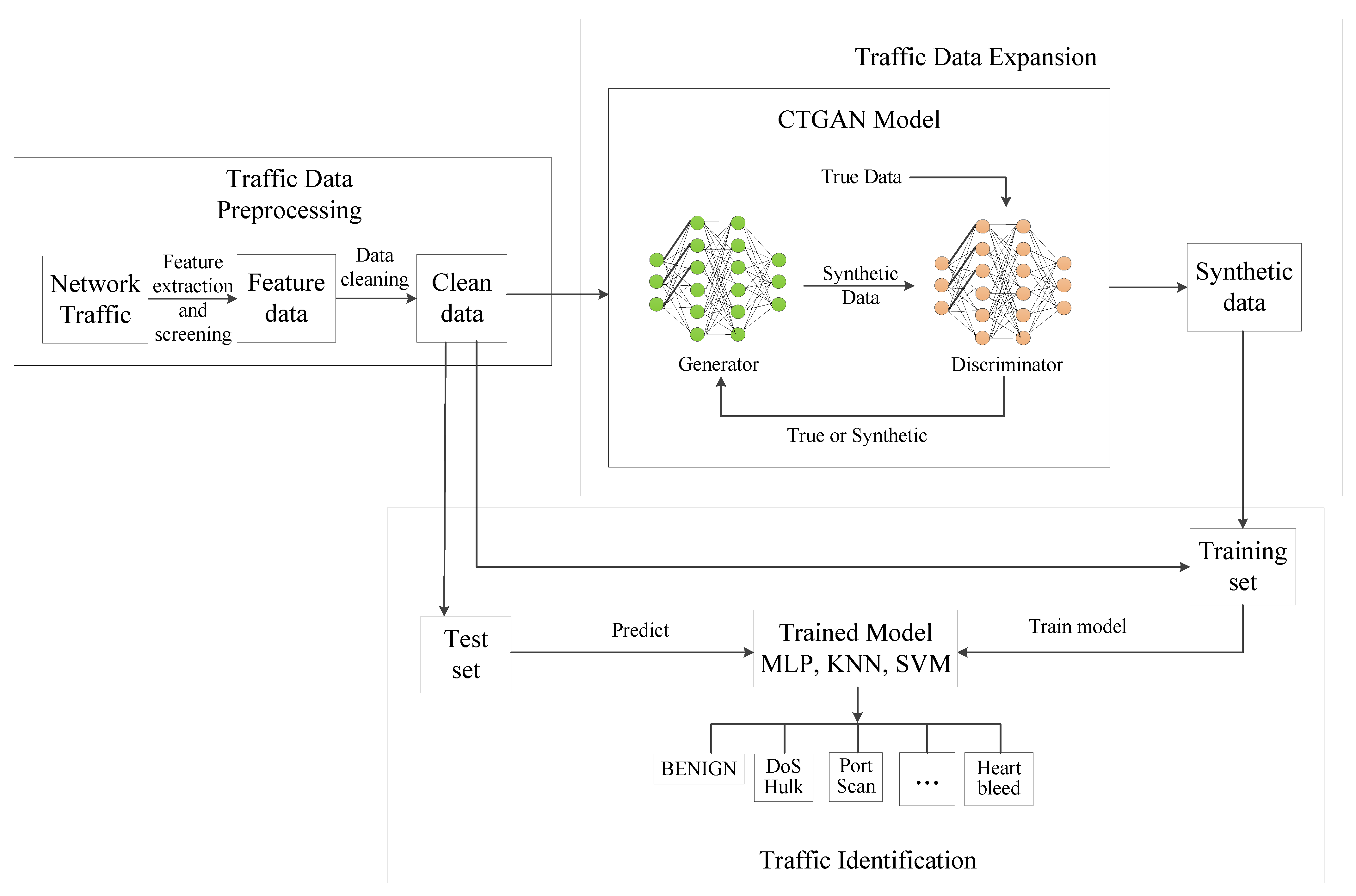
3.1. Design Concept
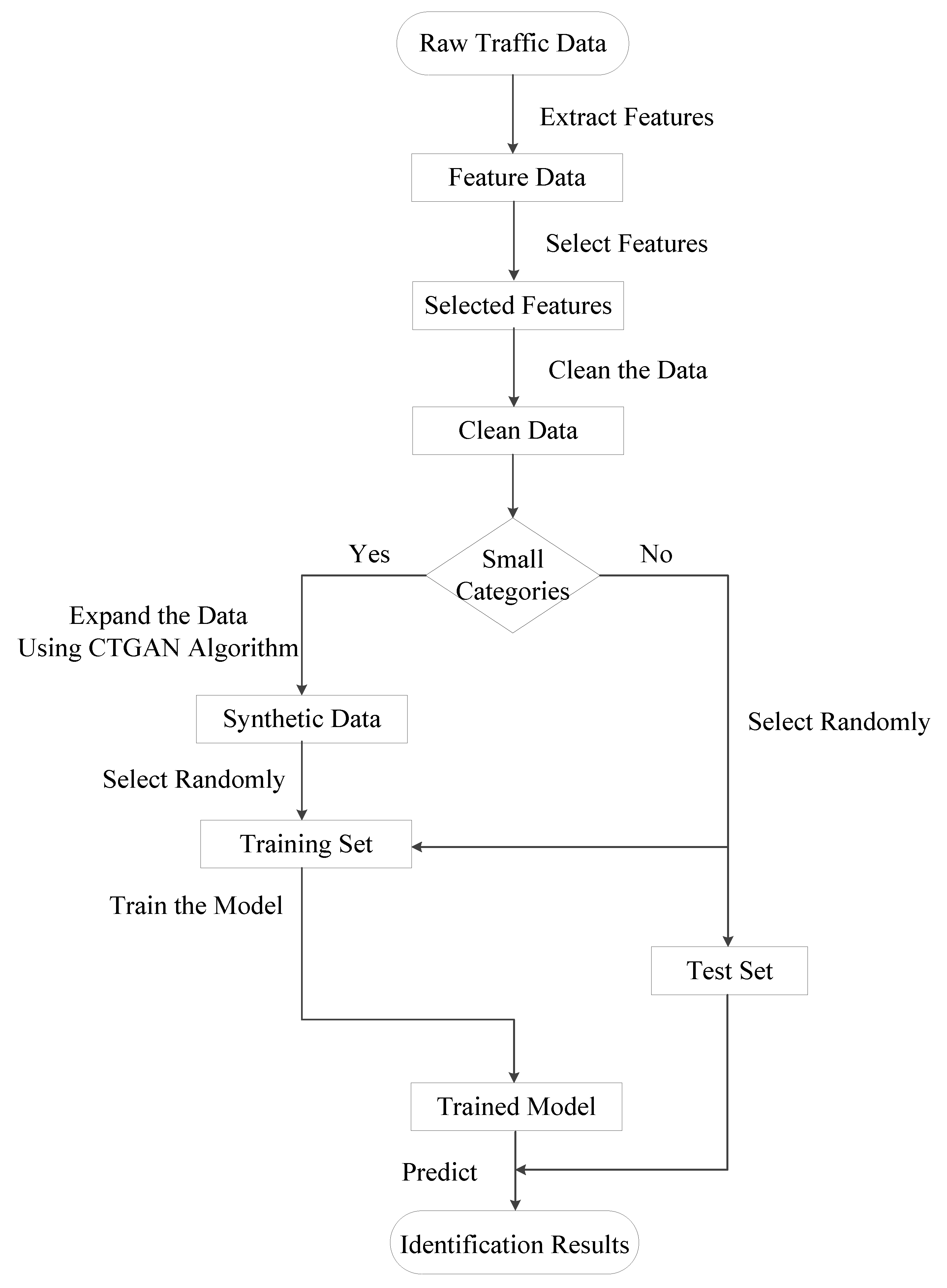
3.2. Scheme Process
3.3. Scheme Steps
| Algorithm 1: The Proposed CTTGAN |
 |
4. Experimental Results
4.1. Dataset Description
4.2. Evaluation Indicators
4.3. Experimental Platform Configuration
4.4. Experimental Results and Analysis
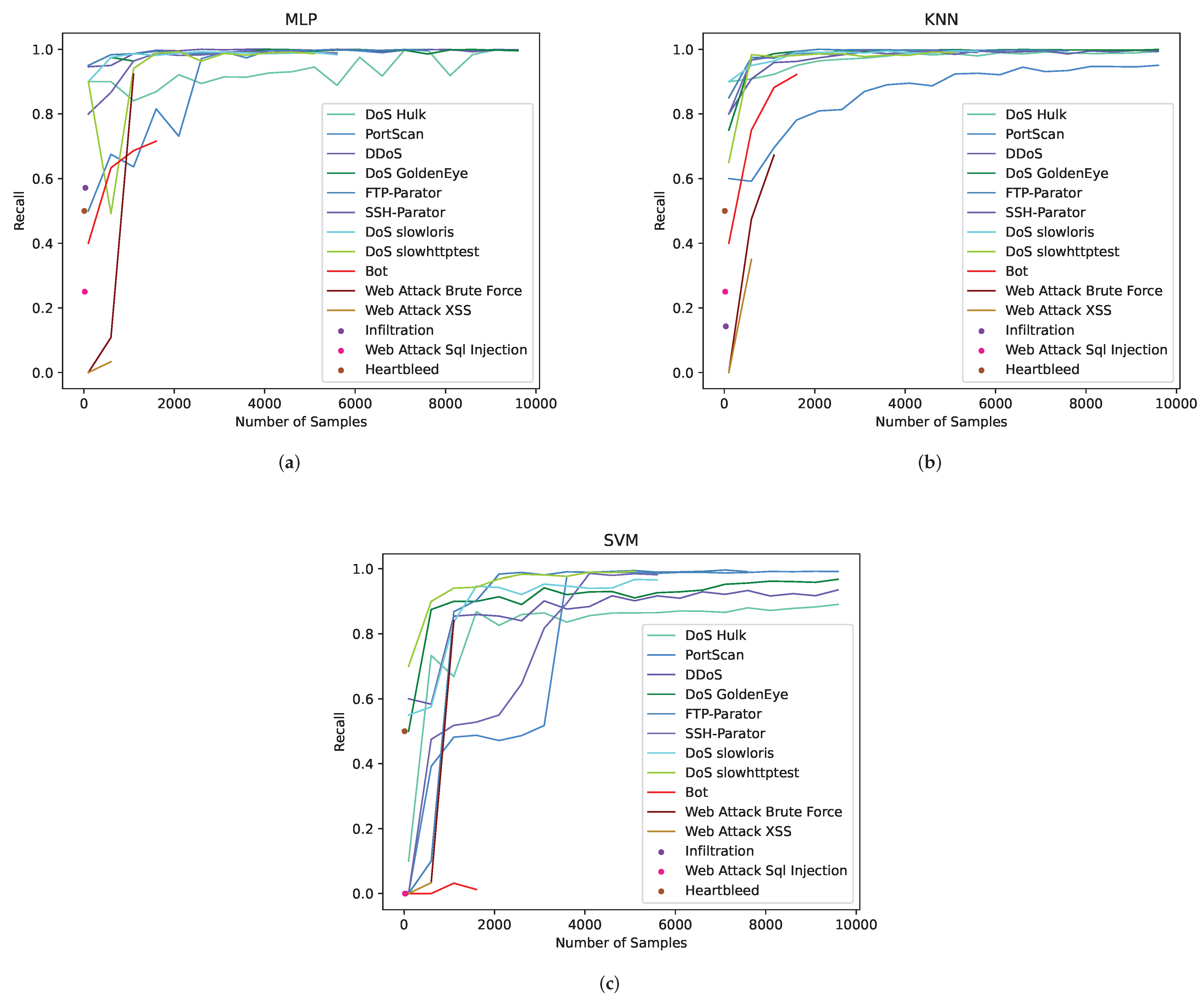
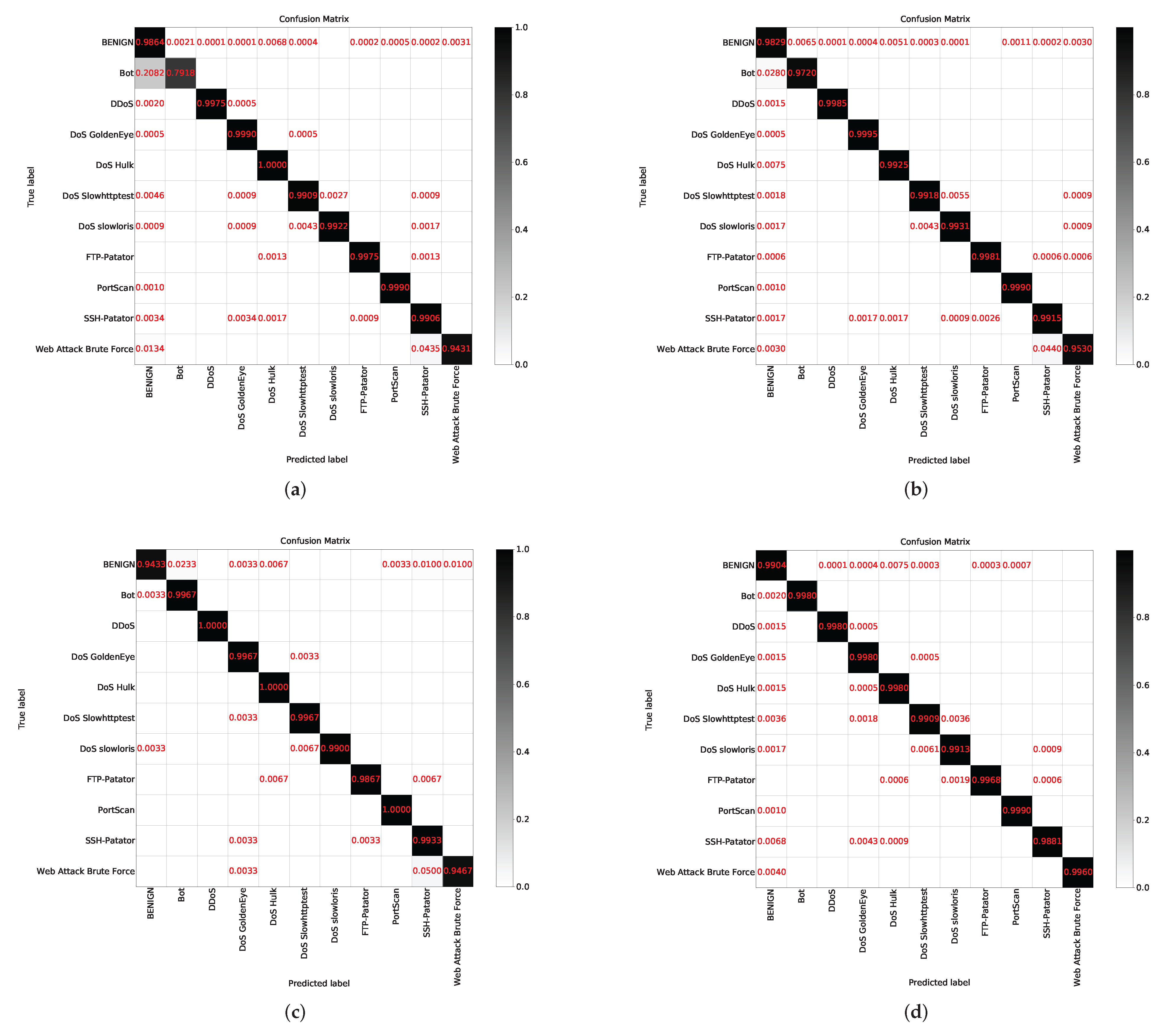
4.4.1. Identification Results of Raw Data
4.4.2. Identification Results after CTTGAN Expansion
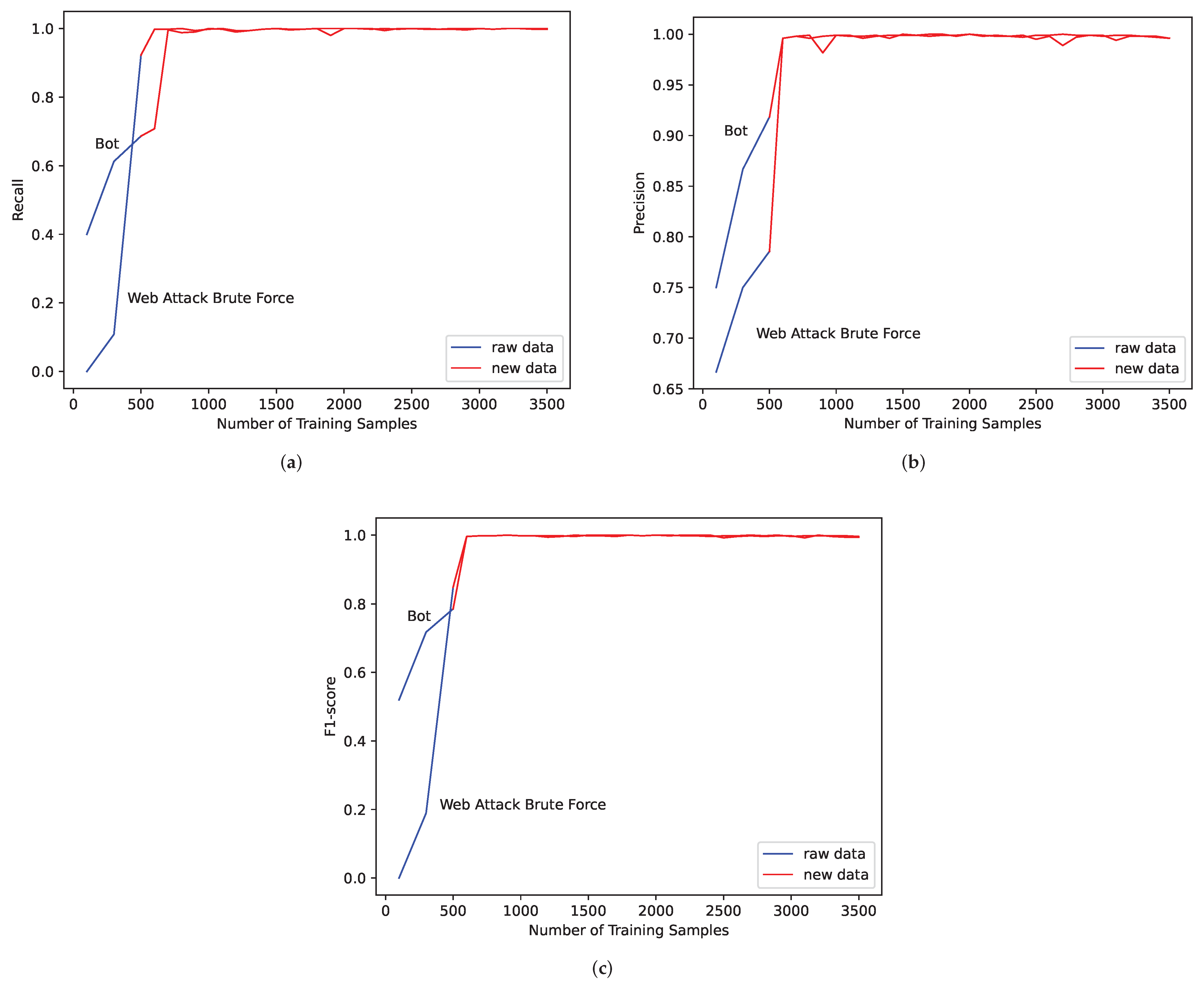
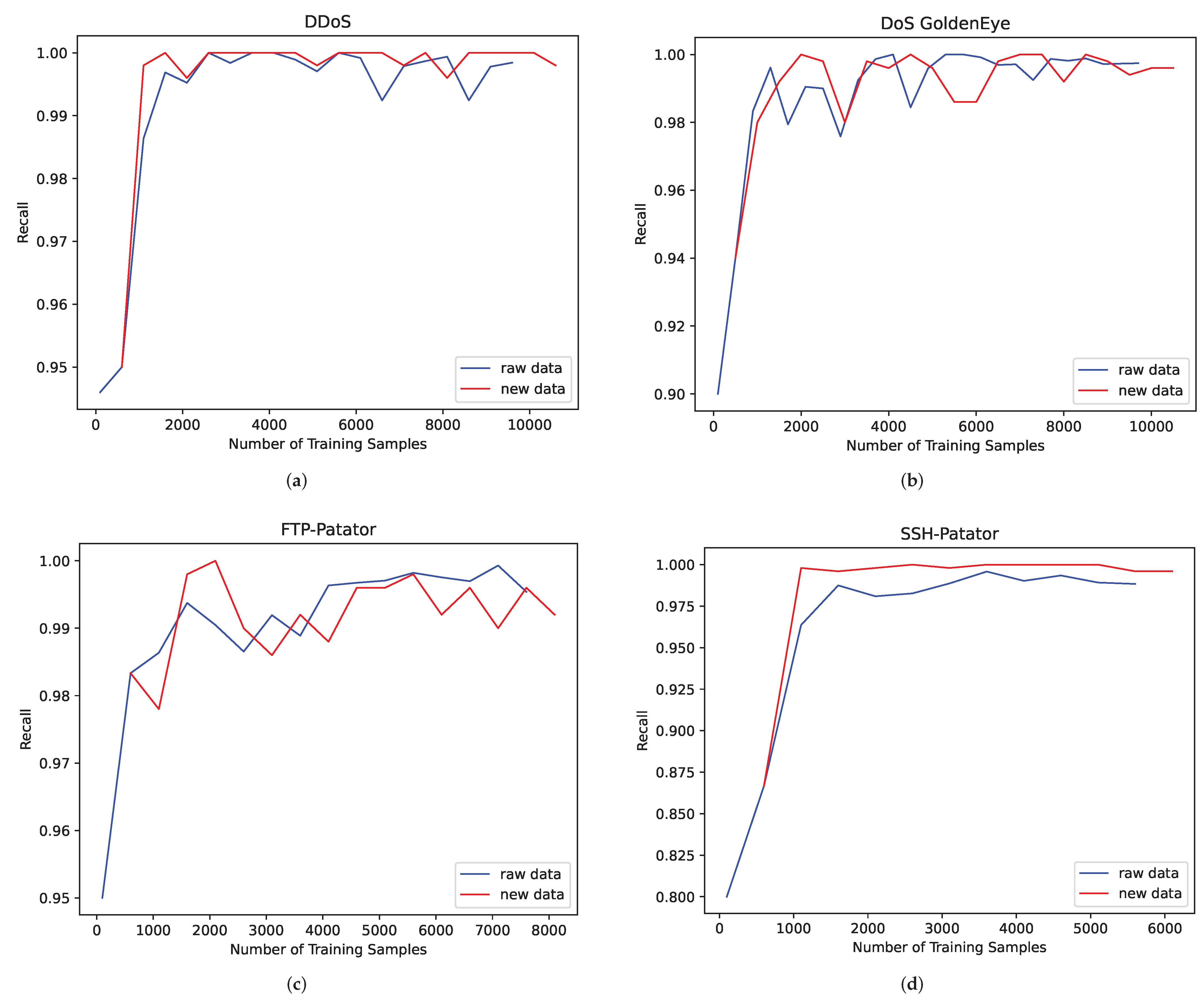
4.4.3. Comparative Experiments
4.4.4. Discussion and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Xiao, C.; Yang, X.; Zhou, W.; Jie, W. Robust Network Traffic Classification. IEEE/ACM Trans. Netw. 2015, 23, 1257–1270. [Google Scholar] [CrossRef]
- Park, J.S.; Yoon, S.H.; Kim, M.S. Performance improvement of payload signature-based traffic classification system using application traffic temporal locality. In Proceedings of the 2013 15th Asia-Pacific Network Operations and Management Symposium (APNOMS), Hiroshima, Japan, 25–27 September 2013. [Google Scholar]
- Lee, S.H.; Park, J.S.; Yoon, S.H.; Kim, M.S. High performance payload signature-based Internet traffic classification system. In Proceedings of the 2015 17th Asia-Pacific Network Operations and Management Symposium (APNOMS), Busan, Korea, 19–21 August 2015. [Google Scholar]
- de Lucia, M.J.; Cotton, C. Detection of Encrypted Malicious Network Traffic using Machine Learning. In Proceedings of the MILCOM 2019—2019 IEEE Military Communications Conference (MILCOM), Norfolk, VA, USA, 12–14 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Shekhawat, A.S.; Troia, F.D.; Stamp, M. Feature Analysis of Encrypted Malicious Traffic. Expert Syst. Appl. 2019, 125, 130–141. [Google Scholar] [CrossRef]
- Ma, R.; Qin, S. Identification of unknown protocol traffic based on deep learning. In Proceedings of the 2017 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 13–16 December 2017. [Google Scholar]
- Liu, Z.; Li, S.; Zhang, Y.; Yun, X.; Cheng, Z. Efficient Malware Originated Traffic Classification by Using Generative Adversarial Networks. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020. [Google Scholar]
- Dong, S.; Xia, Y.; Peng, T. Traffic identification model based on generative adversarial deep convolutional network. Ann. Telecommun. 2021. [Google Scholar] [CrossRef]
- He, M.; Wang, X.; Zhou, J.; Xi, Y.; Wang, X. Deep-Feature-Based Autoencoder Network for Few-Shot Malicious Traffic Detection. Secur. Commun. Netw. 2021, 2021, 6659022. [Google Scholar] [CrossRef]
- Zhong, Y.; Chen, W.; Wang, Z.; Chen, Y.; Li, K. HELAD: A novel network anomaly detection model based on heterogeneous ensemble learning. Comput. Netw. 2019, 169, 107049. [Google Scholar] [CrossRef]
- Telikani, A.; Gandomi, A.H.; Choo, K.K.R.; Shen, J. A Cost-Sensitive Deep Learning-Based Approach for Network Traffic Classification. IEEE Trans. Netw. Serv. Manag. 2022, 19, 661–670. [Google Scholar] [CrossRef]
- Gu, X.; Angelov, P.P.; Soares, E. A Self-Adaptive Synthetic Over-Sampling Technique for Imbalanced Classification. Int. J. Intell. Syst. 2019, 35, 923–943. [Google Scholar] [CrossRef]
- Peng, M.; Qi, Z.; Xing, X.; Tao, G.; Huang, X. Trainable Undersampling for Class-Imbalance Learning. Proc. AAAI Conf. Artif. Intell. 2019, 33, 4707–4714. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Qian, Y.; Min, Z. P2P Traffic Identification Based Over-Sampling Technique. Telecommun. Sci. 2014, 30, 109–113. [Google Scholar]
- Yan, B.H.; Han, G.D.; Huang, Y.J.; Yu, X.L. DPCS2017+41+A Novel traffic Classification Method Based on Imbalanced Data. J. Comput. Appl. 2017. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Vu, L.; Bui, C.T.; Nguyen, Q.U. A Deep Learning Based Method for Handling Imbalanced Problem in Network Traffic Classification. In Proceedings of the Eighth International Symposium on Information & Communication Technology, Nha Trang, Vietnam, 7–8 December 2017; pp. 333–339. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis With Auxiliary Classifier GANs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Kim, J.Y.; Bu, S.J.; Cho, S.B. Zero-day malware detection using transferred generative adversarial networks based on deep autoencoders. Inf. Sci. 2018, 460, 83–102. [Google Scholar] [CrossRef]
- Lin, Z.; Shi, Y.; Xue, Z. IDSGAN: Generative Adversarial Networks for Attack Generation against Intrusion Detection. arXiv 2018, arXiv:1809.02077. [Google Scholar]
- Merino, T.; Stillwell, M.; Steele, M.; Coplan, M.; Patton, J.; Stoyanov, A.; Deng, L. Expansion of Cyber Attack Data from Unbalanced Datasets Using Generative Adversarial Networks. In Software Engineering Research, Management and Applications; Lee, R., Ed.; Springer: Cham, Switzerland, 2020; pp. 131–145. [Google Scholar] [CrossRef]
- Shahriar, M.H.; Haque, N.I.; Rahman, M.A.; Alonso, J.M. G-IDS: Generative Adversarial Networks Assisted Intrusion Detection System. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020. [Google Scholar]
- Huang, S.; Lei, K. IGAN-IDS: An Imbalanced Generative Adversarial Network towards Intrusion Detection System in Ad-hoc Networks. Ad Hoc Netw. 2020, 105, 102177. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular data using Conditional GAN. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Huang, H.; Yu, P.S.; Wang, C. An Introduction to Image Synthesis with Generative Adversarial Nets. arXiv 2018, arXiv:1803.04469. [Google Scholar]
- Jhamtani, H.; Berg-Kirkpatrick, T. Modeling Self-Repetition in Music Generation using Generative Adversarial Networks. In Proceedings of the Machine Learning for Music Discovery Workshop, ICML, Long Beach, CA, USA, 15 June 2019. [Google Scholar]
- Rajeswar, S.; Subramanian, S.; Dutil, F.; Pal, C.; Courville, A. Adversarial Generation of Natural Language. arXiv 2017, arXiv:1705.10929. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. Comput. Sci. 2014, 2672–2680. [Google Scholar]
- Yahi, A.; Vanguri, R.; Elhadad, N.; Tatonetti, N.P. Generative Adversarial Networks for Electronic Health Records: A Framework for Exploring and Evaluating Methods for Predicting Drug-Induced Laboratory Test Trajectories. arXiv 2017, arXiv:1712.00164. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yong, Y. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Choi, E.; Biswal, S.; Malin, B.; Duke, J.; Sun, J. Generating Multi-label Discrete Patient Records using Generative Adversarial Networks. In Proceedings of the Machine Learning for Healthcare Conference, Boston, MA, USA, 18–19 August 2017. [Google Scholar]
- Lederrey, G.; Hillel, T.; Bierlaire, M. DATGAN: Integrating expert knowledge into deep learning for synthetic tabular data. arXiv 2022, arXiv:2203.03489. [Google Scholar]
- Drummond, C.; Holte, R. C4.5, Class Imbalance, and Cost Sensitivity: Why Under-Sampling beats Over-Sampling. In Proceedings of the Workshop on Learning from Imbalanced Datasets II, Washington, DC, USA, 21 August 2003. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Traffic Category |
|---|---|
| Monday | BENIGN |
| Tuesday | BENIGN, FTP-Parator, SSH-Parator |
| Wednesday | BENIGN, DoS Hulk, DoS GoldenEye, DoS slowloris, DoS slowhttptest, Heartbleed |
| Thursday | BENIGN, Web Attack Brute Force, Web Attack XSS, Web Attack Sql Injection, Infiltration |
| Friday | BENIGN, PortScan, DDoS, Bot |
| Traffic Category | Quantity | Proportion |
|---|---|---|
| BENIGN | 2,260,360 | 80.33% |
| DoS Hulk | 229,198 | 8.15% |
| PortScan | 157,703 | 5.60% |
| DDoS | 127,082 | 4.52% |
| DoS GoldenEye | 10,289 | 0.37% |
| FTP-Patator | 7894 | 0.28% |
| SSH-Patator | 5861 | 0.21% |
| DoS slowloris | 5771 | 0.21% |
| DoS slowhttptest | 5485 | 0.19% |
| Bot | 1943 | 0.07% |
| Web Attack Brute Force | 1497 | 0.05% |
| Web Attack XSS | 648 | 0.02% |
| Infiltration | 34 | 0.0012% |
| Web Attack Sql Injection | 21 | 0.0007% |
| Heartbleed | 11 | 0.0004% |
| Library | Download Website | Description | Used Function |
|---|---|---|---|
| sklearn | https://scikit-learn.org | Tools for predictive data analysis | confusion_matrix, train_test_split, preprocessing, MLPClassifier, KNeighborsClassifier, SVC |
| sdv | https://github.com/sdv-dev/SDV | A synthetic data generation ecosystem | CTGAN, evaluate |
| pandas | https://pandas.pydata.org | A data analysis and manipulation tool | read_csv, factorize, DataFrame |
| numpy | https://numpy.org | A scientific computing package | diag, sum, mean |
| matplotlib | https://matplotlib.org | A comprehensive visualization library | pyplot |
| Traffic Category | Quantity |
|---|---|
| BENIGN | 100,000 |
| DoS Hulk | 10,000 |
| PortScan | 10,000 |
| DDoS | 10,000 |
| DoS GoldenEye | 10,000 |
| FTP-Patator | 7894 |
| SSH-Patator | 5861 |
| DoS slowloris | 5771 |
| DoS slowhttptest | 5485 |
| Bot | 1943 |
| Web Attack Brute Force | 1497 |
| Web Attack XSS | 648 |
| Infiltration | 34 |
| Web Attack Sql Injection | 21 |
| Heartbleed | 11 |
| Data Category | Recall | ||
|---|---|---|---|
| MLP | KNN | SVM | |
| BENIGN | 0.9904 | 0.9881 | 0.9682 |
| DoS Hulk | 0.9980 | 0.9925 | 0.9015 |
| PortScan | 0.9990 | 0.9590 | 0.9910 |
| DDoS | 0.9980 | 0.9940 | 0.9350 |
| DoS GoldenEye | 0.9980 | 0.9975 | 0.9730 |
| FTP-Patator | 0.9968 | 0.9987 | 0.9899 |
| SSH-Patator | 0.9981 | 0.9949 | 0.9889 |
| DoS slowloris | 0.9913 | 0.9931 | 0.9671 |
| DoS slowhttptest | 0.9909 | 0.9918 | 0.9854 |
| Bot | 0.9980 | 0.9960 | 0.9980 |
| Web Attack Brute Force | 0.9960 | 0.9960 | 1.0000 |
| Data Category | Recall | |||
|---|---|---|---|---|
| Raw Data (Amount) | Over Sampling (Amount) | Under Sampling (Amount) | CTTGAN (Amount) | |
| BENIGN | 0.9864 (100,000) | 0.9829 (100,000) | 0.9433 (1500) | 0.9904 (100,000) |
| DoS Hulk | 1.0000 (10,000) | 0.9925 (10,000) | 1.0000 (1500) | 0.9980 (10,000) |
| PortScan | 0.9990 (10,000) | 0.9990 (10,000) | 1.0000 (1500) | 0.9990 (10,000) |
| DDoS | 0.9975 (10,000) | 0.9985 (10,000) | 1.0000 (1500) | 0.9980 (10,000) |
| DoS GoldenEye | 0.9990 (10,000) | 0.9995 (10,000) | 0.9967 (1500) | 0.9980 (10,000) |
| FTP-Patator | 0.9975 (7894) | 0.9981 (7894) | 0.9867 (1500) | 0.9968 (7894) |
| SSH-Patator | 0.9906 (5861) | 0.9915 (5861) | 0.9933 (1500) | 0.9881 (5861) |
| DoS slowloris | 0.9922 (5771) | 0.9931 (5771) | 0.9900 (1500) | 0.9913 (5771) |
| DoS slowhttptest | 0.9909 (5485) | 0.9918 (5485) | 0.9967 (1500) | 0.9909 (5485) |
| Bot | 0.7918 (1943) | 0.9720 (5000) | 0.9967 (1500) | 0.9980 (5000) |
| Web Attack Brute Force | 0.9431 (1497) | 0.9530 (5000) | 0.9467 (1497) | 0.9960 (5000) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Yan, X.; Liu, L.; Li, L.; Yu, Y. CTTGAN: Traffic Data Synthesizing Scheme Based on Conditional GAN. Sensors 2022, 22, 5243. https://doi.org/10.3390/s22145243
Wang J, Yan X, Liu L, Li L, Yu Y. CTTGAN: Traffic Data Synthesizing Scheme Based on Conditional GAN. Sensors. 2022; 22(14):5243. https://doi.org/10.3390/s22145243
Chicago/Turabian StyleWang, Jiayu, Xuehu Yan, Lintao Liu, Longlong Li, and Yongqiang Yu. 2022. "CTTGAN: Traffic Data Synthesizing Scheme Based on Conditional GAN" Sensors 22, no. 14: 5243. https://doi.org/10.3390/s22145243
APA StyleWang, J., Yan, X., Liu, L., Li, L., & Yu, Y. (2022). CTTGAN: Traffic Data Synthesizing Scheme Based on Conditional GAN. Sensors, 22(14), 5243. https://doi.org/10.3390/s22145243