1. Introduction
Machine learning is the main technology for the development of contemporary artificial intelligence [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. With the improvement of hardware equipment, people are reinvesting in machine learning research. The most striking thing is that the AlphaGo [
11] developed by the DeepMind team combines the two major technologies of machine learning, deep Learning [
12] and reinforcement Learning [
13], to defeat the Go world champion in March 2016.
In 2013, the DeepMind team was the first to propose a combination of reinforcement learning (RL) and deep learning (DL), called Deep Q-Network (DQN) [
14], which was successfully practiced on Atari games and compared with other methods. By comparison, six of the seven games have scored more than other methods, and several have exceeded the level of professional players. Different from the previous method of manually extracting features, they proposed a model that combines reinforcement learning and deep learning. The gameplay strategy can be learned only through the original game screen as input, and it can be learned in other games without adjusting any neural network architecture and parameters, demonstrating its versatility. However, they used the same network to estimate the target value and the predicted value so that there was a great correlation between the two, which led to the problem of unstable training.
Based on the 2013 method, DeepMind added an improved method TargetNetwork [
15] in 2015 which aims to solve the shortcomings of the unstable Q value of prediction. This method expands the experimental games from 7 to 49, and in many games, it not only surpasses the past methods, but also surpasses professional players. At the same time, it is also found that DQN can achieve very good learning effects in some pure scoring games, such as Breakout, and for games that require specific steps to continue to break through, such as Montezuma’s revenge, it performs very badly. In other words, for different types of games, DQN has very different effects.
After DeepMind solved the problem of unstable Q value, it found that Q-Learning itself has the shortcoming of overestimating. The problem is that Q-Learning adopts a greedy method when selecting actions, so that when selecting or estimating the value of an action, if the value of the sub-optimal action is overestimated during the training process, and thus exceeds the value of the optimal action, it will cause the entire learning process to never find the optimal action. Based on the Double Q-Learning proposed by Hasselt [
16] in the Q-Learning experiment in 2010, DeepMind proposed a method of improving overestimation in 2015 called Double DQN (DDQN) [
17] to separate the selection and estimation actions. Since the DQN with Target Network has two networks at the same time, there is no need to make major adjustments to the overall architecture. Dong et al. [
18] designed a simple reinforcement learning (RL) agent that implements an optimistic version of Q-learning and establish through regret analysis that this agent can operate with some level of competence in any environment. They considered a general agent-environment interface and provide a novel agent design and analysis based on the concepts from the literature on provably efficient RL.
Based on the rapid development of current hardware equipment and software technology, this paper mainly combines reinforcement learning and deep learning technology, called Deep Q-Network (DQN), to process real-time action response of NS-SHAFT game with analysis of the game information by Cheat Engine. The detail is as follows. First of all, we build a real-time learning environment in a personal computer to automatically capture the screen of NS-SHAFT and then provide DQN to decide the action of moving left, moving right, or stay in same location, survey different parameters: such as the sample frequency, different reward function, and batch size etc. Next, we discuss the impact of different parameters in the DQN environment, such as sample frequency, reward function, batch size, and other parameters on learning effectiveness. Moreover, because NS-SHAFT does not provide any way to directly obtain game internal information and does not provide any game information API, we use open source software, Cheat Engine, to analyze game information to obtain relevant numerical memory addresses and required game information of Reward Function to achieve real-time training for NS-SHAFT game. Experimental results not only show that the relevant parameter settings have a certain degree of influence on the learning effect of DQN, but also successfully establish an instant learning environment and instant game training for the NS-SHAFT game.
The reset of this paper is organized as follows.
Section 2 reviews preliminaries and background. In
Section 3, we introduce the proposed method and system.
Section 4 shows the simulation results. Finally,
Section 5 concludes this work.
2. Preliminaries and Background
In this section, we review some preliminaries and background for later use.
2.1. Introduction to NS-SHAFT
NS-SHAFT is a PC game [
17]. As shown in
Figure 1, the player moves the character left and right in the game to increase the current number of floors as much as possible. The game provides a choice of three difficulty levels. During the game, when the number of floors becomes larger, the scrolling speed of the game will increase and the proportion of needle sticks will also increase, making the operation thinking time shorter and shorter. The game ends when the character falls to the bottom of the game screen. The character in the game has 12 points of life. When the character touches the fixed needle or the floor, the character will lose 5 points of life. When the character’s life returns to 0, the game also ends. However, the character will restore 1 point of life when it’s life is less than 12 points and land on the normal floor.
2.2. Reinforcement Learning
Reinforcement Learning is a major branch in the field of machine learning, focusing on how agents can deliver actions to the environment and find out a policy to maximize their future benefits (or reward) by trial-and-error where the method by which the agent selects the action from the environment state (
S) is called the policy [
19,
20,
21]. The detail is as follows. As shown in
Figure 2, the Agent will use the known policy or randomly select the action Action
according to the current state
St. At the time, the state
St will transfer to the new state
St+1, and get a reward
Rt.
In this learning process, when the correct action is taken, the system will give a positive reward, if it is a wrong action, it will give a negative reward. With the reward value, the Agent can learn the best action strategy to get the maximum reward. Generally speaking, we would like to choose the action that will bring the greatest reward every time. This strategy is called greedy. In other words, greedy is a way of choosing the best choice at every step to expect the best result. However, this method has the problem of falling into a local optimal solution. It is usually solved by using the ε-greedy algorithm which has a certain probability ε for randomly choosing actions.
In reinforcement learning, if only the reward value can only reflect the immediate situation in a certain state, it cannot accurately reflect the actual value from a certain state to the end of the round. In other words, the purpose is to evaluate if a state has the maximum value after taking an action instead of the current maximum reward value. Accordingly, a value function
V(
S) is defined by
where
is the total rewards obtained from state
S following policy
;
denotes the total rewards obtained under the policy
;
denotes the reward accumulated in state
s at time
t;
denotes the state at time
t, t = 1,2,3,…; and
,
, denotes the discount rate used to avoid excessive states leading to infinite total rewards for each strategy.
Value function is used to evaluate the value of each state, but, in fact, each state has different actions. We need to evaluate all the actions in the same state separately to obtain the value of each action in that state. Therefore, the action and state are regarded as a combination, and the action value function
Q(
s,
a) is derived.
where
is the total rewards obtained from that state
S select action
a and follow policy
;
denotes the total rewards obtained under the policy
;
denotes the reward accumulated in state
s with selection of action
a at time
t;
denotes the state at time
t, t = 1,2,3, …; and
,
, denotes the discount rate used to avoid excessive states leading to infinite total rewards for each strategy.
2.3. Q-Learning
The purpose of
-Learning is to record the entire learning process [
22]. All actions taken under the state and rewards will be fully recorded to form a
-Table as shown in
Table 1. From this table, the agent can know which action will get the greatest reward. The detail is shown in Algorithm 1. At the beginning of the algorithm, the initial value of
Q is arbitrarily set (determined by the developer), and training is performed for each step in each episode. After the action (
a) is given to the state (
s), the reward (
r) and the new state (
s’) can be obtained, and then the value
(
s,
a) is updated corresponding to the state
s and action
a in the
-Table. In the update formula,
(s, a) is the benefit obtained by taking action
a in the
s state, r is the reward value obtained by taking action
a in the current state
s,
α is the learning rate, and γ is the discount factor (Discount factor). When updating, the algorithm will care about the current reward (
r) and the reward in memory
. The reward in the memory represents the maximum reward value that the new state
s’ can give. If the agent takes an action in the past
s’ to obtain the reward value, this formula can make it learn the news early. When entering
s again, choose the correct action to continue entering
s’ in order to get rewards. Therefore, the larger γ the agent will pay more attention to the past experience, otherwise the agent will pay attention to the current reward
r. The algorithm is summarized as
| Algorithm 1.-Learning.
|
| Initialize (s, a) arbitrarily |
| Repeat (for each episode): |
| Initialize s |
| Repeat (for each step of episode): |
| Take action a, observe r, s^’ |
| Chose a from s using policy derived from (e.g., ε-greedy) |
| (s, a) ← (s, a) + α[r + γ〖max〗_a’(s^’, a^’) − (s, a)] |
| s ← s^’; |
| until s is terminal |
2.4. Deep Q-Network
In order to solve the shortcomings of Q-Learning in storing Q-Tables due to the excessive number of states and actions, the DeepMind team proposed Deep Q-Network [
14] and verified it on the Arcade Learning Environment (ALE) [
23] environment. Deep Q-Network directly uses the entire game screen as the input of the model, so that the model learns which features to obtain through a lot of training. For this reason, there is no need to consider which features the model finally obtains, as long as the model can output the maximum reward value in various states.
In addition, the pixels of the game screen are too large, and each pixel has 256
3 possibilities, but, in fact, there is a correlation between the pixels, and it is not necessary to treat each pixel as an input. Convolutional neural network (CNN) [
24,
25] can solve the problem at this time. Therefore, Deep Q-Network has a CNN model that can handle the input of the game screen, which is composed of one or more convolutional layers and fully connected layers. The model finally outputs the
Q value of each action.
Finally, in order to make the model more accurate prediction, a lot of data is used in the model to iterate. The data can be obtained through the continuous game process. The algorithm uses the Experience Replay technology [
26] to store the game process data in One is called replay memory. The stored data include state, action, reward, and {state}^’ (The next state entered after an action is taken). In the training process, a certain number of samples are selected from the replay memory as the model input for algorithm iteration. The overall algorithm is shown below.
Step 1. Initialize a space D with Size N for storing past experience.
Step 2. Randomly initialize the Q of the neural network, and then play M games, each end of the game represents an episode.
Step 3. At the beginning of each episode, set the game screen as the state (S1), and preprocess this game screen into = ∅().
Step 4. Each step in the game randomly selects the action at with probability ϵ, and the 1-ϵ probability uses the optimal action at predicted by the neural network Q.
Step 5. Following the Step 4, the action at of each ∅() has reward rt and next state St+1. Perform the same preprocessing on state St+1 to get = ∅() and ten save the relevant information of this state transition (, at, rt, ∅t+1) to replay memory.
Step 6. Randomly select a certain number of transitions information from the replay memory, and calculate the Q value according to the formula.
When is over (that is, taking action aj in state leads to the end of the game), make the target value to be yj = rj;
When is not over yet (that is, an action aj is taken in the state so that the game is not over), the target value is yj = rj + where θ stands for neural network.
Step 7. Finally, mini-batch gradient descent is used to reduce the loss function to improve the neural network.
2.5. Deep Q-Network with Target Network
In 2015, DeepMind added a method, Target Network, to improve Deep
-Network. It mainly calculates the error between TD target and the current estimated value
(
s, a), which is defined as follows:
where ∆w represents the weight to be updated for this difference,
α is the learning rate,
is the TD target, and
represents the estimated
Q value of the current state.
In fact, we don’t know the real TD target. We see that the TD target is only a reward for taking the action in this state, plus the highest worth discount for the next state. The problem is that we use the same network (weight) To estimate the TD target and value, so there is a great correlation between the TD target and the network (w) we are changing, which means that in each step of training, the Q value will move, but the target value (TD target) will also move. It is like chasing a moving target, which makes the training shock.
Compared with 2013, the 2015 version of DQN only modifies the calculation of the target value (TD target) and keeps the rest the same to get better results. After that, some scholars still made improvements to DQN. For example, Schaul et al. [
27] proposed Prioritized experience replay by extracting samples in a non-random manner, or Wang, Z. et al. [
28] modified the neural network in a small amount. In 2018, Horgan et al. [
29] used a distributed method to obtain data to improve stability. The above-mentioned studies all improved DQN step by step and enhanced its effectiveness.
2.6. Related Work
In 2013, the DeepMind team is the first to propose an algorithm that combines Reinforcement learning (RL) and Deep learning (DL) called Deep Q-Network (DQN) [
14] and successfully practiced it on Atari games. The model combining reinforcement learning and deep learning proposed in this paper is different from the previous method of manually extracting features, that is, the game strategy can be learned only by using the original game screen as input, and without adjusting any neural network architecture and parameters. Learning from other games shows its versatility. They compared the results of the practice with random, past methods [
13,
19] and human battle, as shown in
Table 2. Six of the seven games outperformed the random and the past methods [
13,
19], and several outperformed professional players. In 2015, DeepMind improved the instability of
Q value in DQN by adding the method TargetNetwork [
15] and then enhanced the performance as shown in the last row of
Table 2.
4. Experimental Results
The experiment in this paper will carry out seven kinds of comparative experiments. First, we test the performance of DQN and DQN with Target network, and then choose DQN with Target network as our method to test Sample frequency, Frame skipping, Mini-batch size, Target network Update period, discount value, and Reward function. We also show the significance of the trained neural network estimates on the game screen. In all experiments, the degree of difficulty is fixed to the most difficult level for experimentation.
4.1. Experimental Environment
Hardware:
PC with CPU I7-7700 3.60 GHz, memory 32 GB, and Graphics card NVDIA GTX 1050 Ti.
Software:
PC Windows 10 (64 bits), Python, Pycharm IDE, and Tensorflow + Keras.
4.2. Performance Comparison between DQN and DQN with Target Network
In order to understand whether the method with Target network has any difference in overall training, we trained DQN and DQN with Target network 26,000 rounds each and combined with the average floor reached every 100 rounds as an evaluation. The training trend is shown in
Figure 7. We can see that the difference between the two is the growth rate of training effectiveness. The method with Target network is higher than the original DQN at about 10,000 training. We also compared the average number of reached floors in the best 100 rounds. As shown in
Table 6, the results show that DQN with Target network is relatively good. Therefore, we choose DQN with Target network as our method.
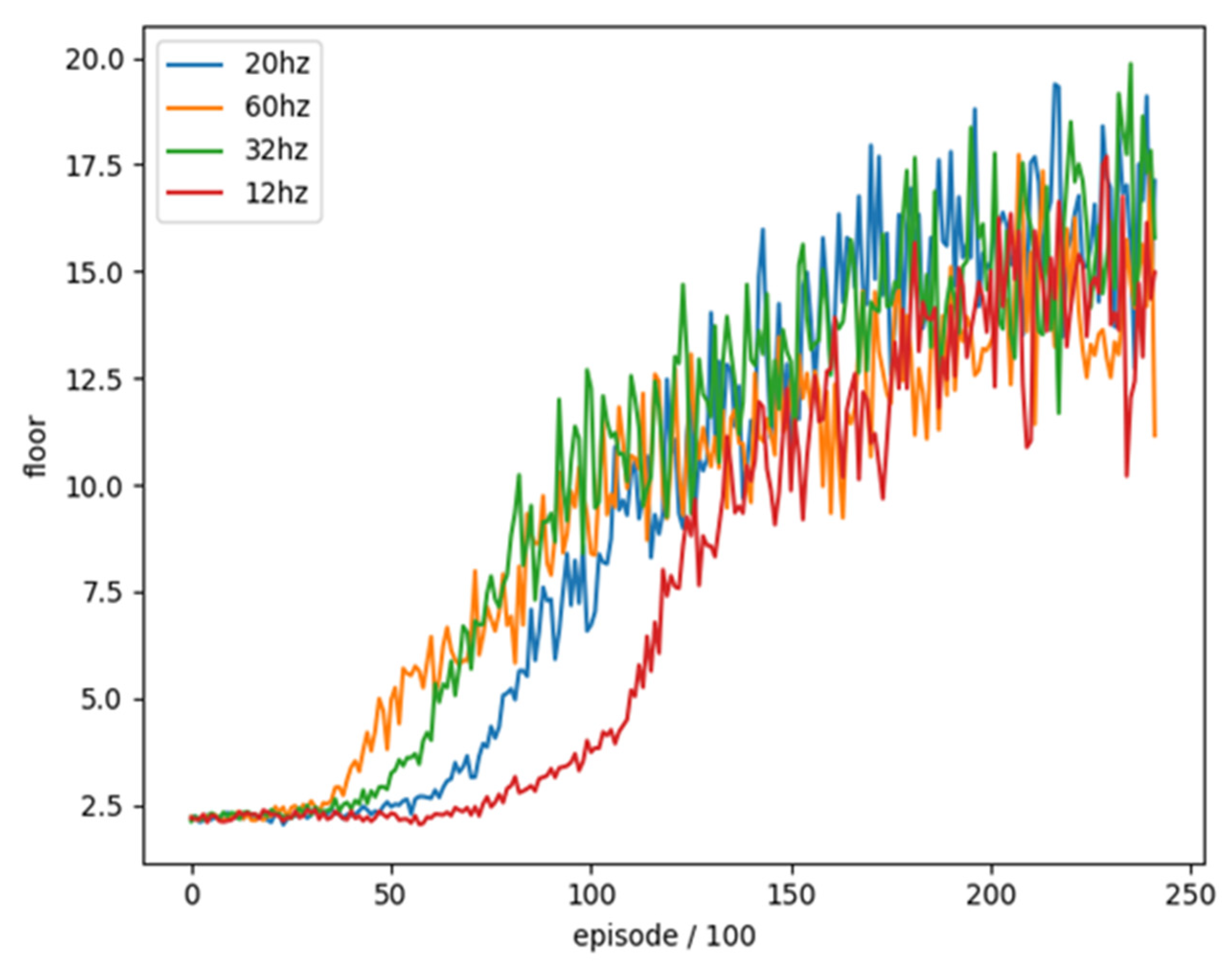
4.3. Effect of Sample Frequency
Sample frequency refers to how many pictures need to be captured per second for training, and the amount of sample frequency affects the amount of picture change. The schematic diagram is as shown in
Figure 8.
Taking 60 pictures per second, we can see that there is almost no change in the pictures at the three time points of T = 1~3. If taking 20 pictures per second, we can clearly see that the characters in the picture have been done. The action of moving to the right is now, and the difference is even greater at T = 20. The 60 Hz Sample frequency is about to leave the original floor, while the 20 Hz Sample frequency has already left the original floor, and the picture has changed. Then you can see the next floor with acupuncture.
In order to understand whether different Sample frequencies have an impact on the training of DQN with Target network, we use sample frequency as the test item and the rest of the parameters are unchanged, as shown in
Table 7.
We trained these four different Sample frequencies separately for 24,200 rounds and combined with the average floor reached every 100 rounds as an evaluation. The training trend is shown in
Figure 9.
We can see that the results of training at a too low sample frequency (12 Hz) are much slower than others and cannot achieve a good result in the end. Although the sample frequency (60 Hz) is too high at the beginning, the training effect has a better trend than others, but it is ultimately lower than other sample frequencies. We compared the best 100 rounds of average reaching floors as shown in
Table 8. The results show that sample frequency (20 Hz) is a relatively good setting, so we choose sample frequency (20 Hz) as the final training parameter.
4.4. Frame Skipping
Since we usually don’t take many actions in one second when playing a game, DQN does not calculate the value per frame, but predicts once every k frames to reduce the computational cost and collect more experience, which is called frame skipping. However, since different games may have different suitable methods and the NS-SHAFT game is more complicated, we re-evaluate whether to use frame skipping. Before the re-evaluation, we introduce the method with or without frame skipping separately as follows.
Figure 10 shows the case where frame skipping is not used. The game screens at the four time points of T = 1~4 are used as the input of Neural Network and predict an action. When T = 5, the screens of T = 2~5 are used as the input of Neural Network again to predict the next action.
Figure 11 shows the use of frame skipping. The game screens at the four time points of T = 1~4 are used as the input of Neural Network, and predict an action. However, the three time points of T = 5~7 continue to use the action adopted at T = 4. Until T = 8, the screens of T = 5~8 are used as the input of Neural Network to predict the next action.
In order to understand whether the different frame skipping settings have an impact on the training of DQN with target network, we use frame skipping as test item and the rest of the parameters are unchanged for the comparison of different frame skipping settings, as shown in
Table 9. We train four different frame skipping settings and compared them without frame skipping. A total of 25,900 rounds of training were combined and the average floor reached every 100 rounds was used as an evaluation. The training trend is shown in the
Figure 12.
One can see that the effectiveness of training in frame skipping (4, 8, 12) is much lower than the others and cannot achieve a good result in the end. The effectiveness is the best without using frame skipping (0). The average number of reached floors in the best 100 rounds is shown in
Table 10. The results also show that it is better to not use frame skipping in this experiment. Accordingly, we do not use frame skipping.
4.5. Mini-Batch Size
We update the Neural Network by using Mini-batch from Replay Memory to solve the problem of high correlation of samples obtained by reinforcement learning, as shown in the
Figure 13.
In order to understand whether the different settings of the Mini-batch size (number of samples taken) have an impact on the training of DQN target network, we conducted a training comparison of each mini-batch size. We used the Mini-batch size as the test item and the rest of the parameters were unchanged. The training parameters are shown in
Table 11.
We trained five different batch size settings, and trained a total of 20,500 rounds, combined with the average floor reached every 100 rounds as an evaluation. The training trend is shown in
Figure 14.
We can see that the effectiveness of training with too high batch size (64, 128) is much lower than others and cannot achieve a good result in the end, while the amplitude of vibration during training with too low batch size (8) is compared others are larger. Average number of reached floors in the best 100 rounds for different frame skipping settings is shown in
Table 12. The results show that the moderate batch size (32) in this experiment is a better setting, so we use batch size (32) as the final training parameter.
4.6. Update Period of Target Network
In order to understand whether the setting of the target network update period has an impact on the DQN training, we use the target network update period as the test item and the remaining parameters are unchanged to compare the training of different target network update periods. The training parameters are shown in
Table 13.
We train four different Target network Update periods separately, and train 17,100 rounds in total. The average floor is reached every 100 rounds as an evaluation. The training trend is shown in
Figure 15.
We can see that there is no significant difference in the comparison of the Target network Update period. It may be necessary to set the parameter to be larger to have a significant difference. Average number of reached floors in the best 100 rounds for different target network update periods is shown in
Table 14. Target network update period (10,000) is a better setting, so we use Target network update period (10,000) as the final training parameter.
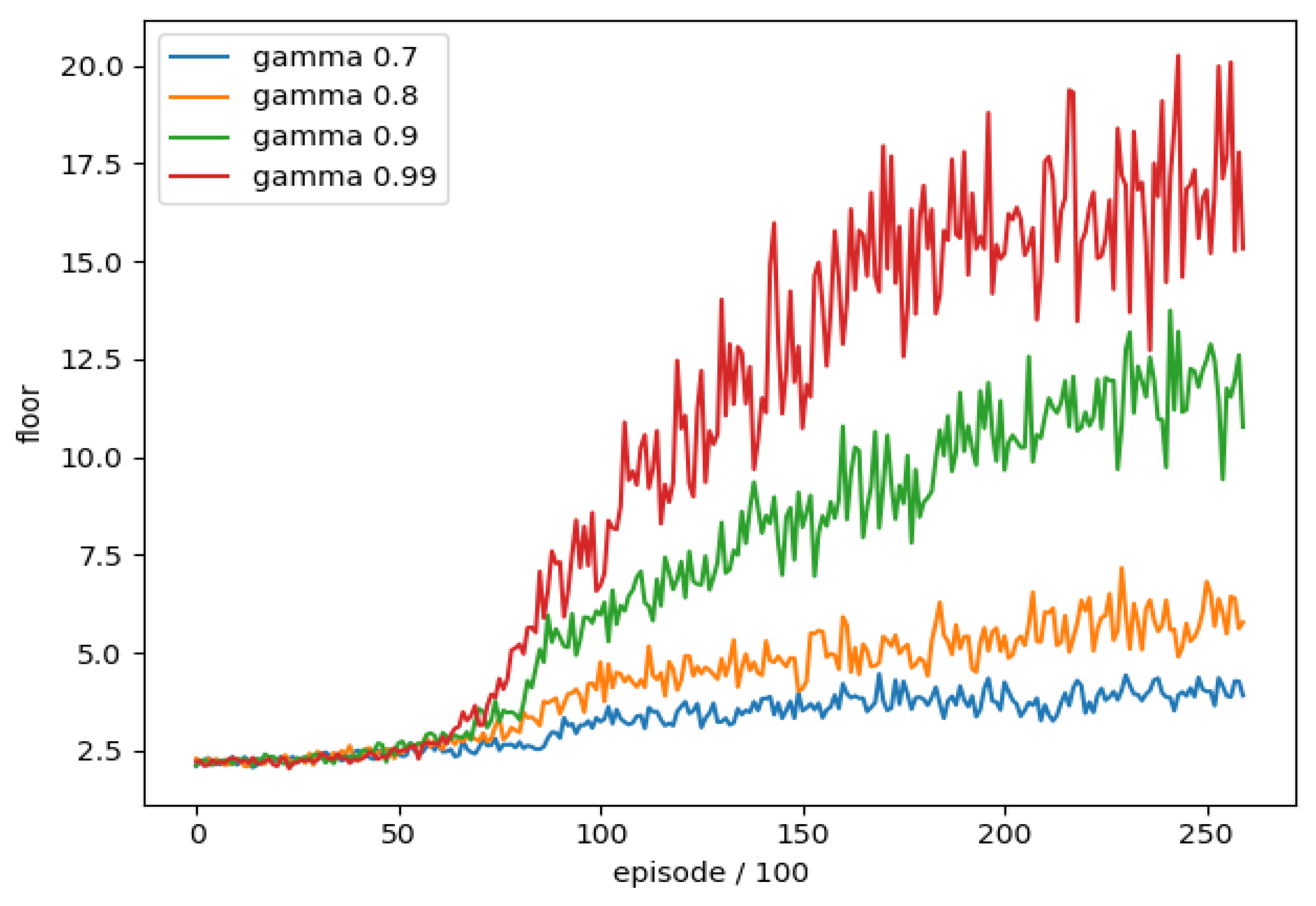
4.7. Discount Value
When DQN calculates the target value, it will multiply the future maximum action value by a discount value (γ), which means that we value the benefits that can be brought to us in the future when the discount is larger; otherwise, we value the benefits of the moment without considering the future.
In order to understand whether the different discount value (γ) settings have any difference in DQN training, we conducted a training comparison of each discount value (γ). We took the discount value (γ) as the experimental item and the rest of the parameters were unchanged, and we trained separately four different discount value (γ) settings, a total of 26,000 rounds of training combined with the average floor reached every 100 rounds as an evaluation, the training trend is shown in
Figure 16.
We can see that the lower discount value (0.7, 0.8) training effect is much lower than the others, and that closer (0.9, 0.99) gets better results from the higher value (0.99), so we use the discount value (0.99) is used as the final training parameter.
4.8. Reward Function
By the testing from 4.3 to 4.7, the parameters of DQN with target network for our architecture are determined as shown in
Table 15.
After finishing the parameter setting, we will compare the design of different reward. There are two ways to define the target value y in DQN. First, it is judged that if an action is taken that leads to the end of the game round, the terminal is set to true, which means that the actual value after the action is only the reward obtained at the moment, and there is no maximum action reward value that can be obtained in the next state. In another case, the game continues after the action has not ended. At this time, the terminal is false, which means that the actual value after the action includes not only the reward currently obtained, but also the maximum reward value of action in the next state. We assume the content of reward function as
Table 16.
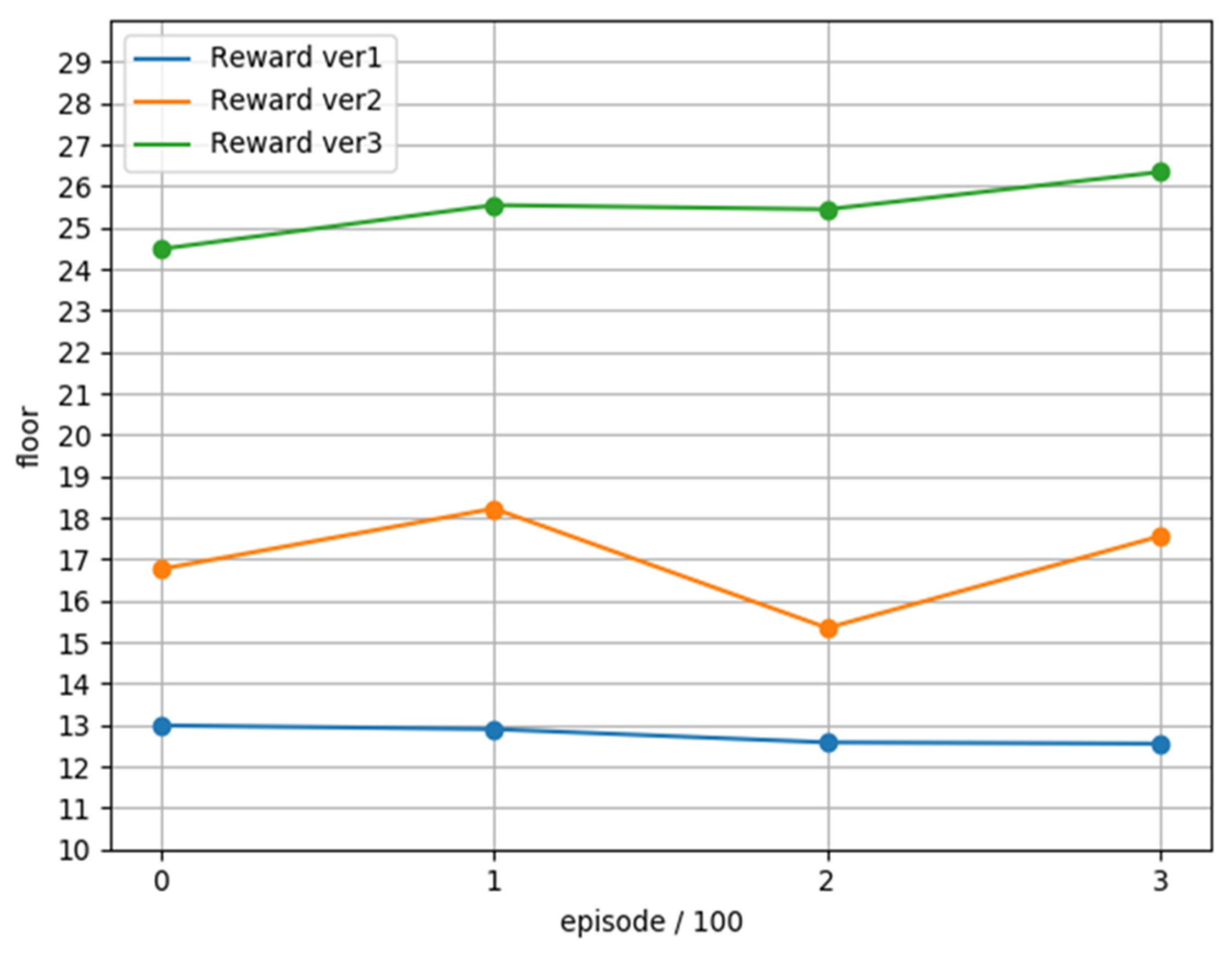
Then we trained these three versions of reward separately, and compared with the completely random selection of actions, a total of 26,000 rounds were trained and the average floor reached every 100 rounds was used as an evaluation. The training trend is shown in
Figure 17.
We can see that the performance of version 3 in training greatly exceeds the performance of other versions. Set terminal to true when the character loses blood, so that the neural network avoids blood loss actions, thereby increasing the possibility of survival for the game. Continue, and under the comparison of positive rewards, we found that version 1 only rewards when the floor increases after the action. It is too sparse for the neural network to effectively improve the overall performance, so we set the character Y axis value in the appropriate range It is correct to give positive rewards to motivate the character to stay in the proper range from time to time.
We use the ε-greedy strategy for action selection during training, and we set ε to eventually drop to 0.1 and remain unchanged, which means that every time an action is selected, there will be a 10% chance of randomly selecting the action output, in order to verify whether the model meets the training results; therefore, we will apply each trained model to the game for verification, and select the maximum Q value action as the output each time.
We tested the three versions of the model for 400 rounds, and plotted the average of each 100 rounds into
Figure 18. It can be found that the average achieved floor of each version is higher than the value achieved during training, which can confirm that each model can be applied the game, and we found that the average achieved floors of version 3 are all above 20 floors, while version 1 is below 15 floors, which once again confirms how to define the reward function is an important key in reinforcement learning.
Finally, we counted the highest reached floors and the highest 100 average floor information in 400 rounds of each version, as shown in
Figure 18.
We tested the three versions of the model for 400 rounds respectively, and plotted the average of each 100 rounds into the above figure. We can find that the average achieved floor of each version is higher than the value achieved during training, which can confirm that each model can be applied the game, and we found that the average achieved floors of version 3 are all above 20 floors, while version 1 is below 15 floors, which once again confirms how to define the reward function is an important key in reinforcement learning.
Finally, we counted the highest reached floor and the highest 100 average floor information in 400 rounds of each version, as shown in
Figure 19.
In 400 rounds, the highest floor of version 3 reached 90. The number of needles in the game increased sharply after the 80th floor, as shown in
Figure 20, so we can regard the 80th floor as the end of the game, and the average of the highest 100 pens reached 53 layers, it can be seen that in a few cases of this game, version 3 can reach the level of ordinary players or even surpass some players.
4.9. Q value Visualization
After training the model, in order to understand the meaning of the maximum action Q value estimated by the neural network in the game screen, we observed a period of the game. The trend of the maximum Q value is shown in
Figure 21.
We recorded the maximum action
Q value estimated by the neural network from the 1100th frame to the 1400th frame in the game. As shown in
Figure 22, we will use the game screen in which the Q values of the two parts of the trend graph increase from low to high for explanation.
First, we see the game screen marked 1 and we can find that the character in this state is in a very bad position, and there is no floor below to keep the character alive. At this time, the Q values given by the network to the three actions are: Still: 30, Move right: 33, Move left: 31, no matter what action is taken, it is not good for the game to continue. Then, we see that the game screen marked 2 and we can find that there is a normal floor under the character. If the character is at this point, it can continue the game, the Q values given to the three actions by the network at this time are: static: 65, moving right: 63, moving left: 67. Taking a leftward action is most beneficial to land on the floor, so the network The highest estimate is given for the movement to the left.
When we see that the game screen is marked 3, we can find that the character in this state is in a very bad position. The needles below will cause the character to reduce the blood volume. At this time, the Q value given by the network for the three actions are: static: 27. Move to the right: 25. Move to the left: 28. No matter what action is taken, it is not good for the game to continue. Then, when you see the game screen marked 4, you can find that there is a normal floor under the character. If the character moves to the left, it will If there is a chance at this point, the Q values given to the three actions by the network at this time are: static: 55, moving right: 39, moving left: 61, taking a leftward action is most beneficial to land on the floor, so the network gives the highest estimate of the movement to the left.
By analyzing the Q value predicted by the Neural Network one by one, we can find that the Neural Network we trained gives the correct estimation in each state of the game and clearly understands the actual meaning of its Q value in the game.
Finally, we give a comparison with other methods by the average number of reached floors in the best 100 rounds of 2600 rounds. From the results shown in
Table 17, the performance of the proposed method is better than the methods in Sarsa [
13] and HNeat Pixel [
18]. When comparing with the methods proposed in HNeat Best [
18], DQN [
14], and DQN best [
15], the proposed method shows comparable performance.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}