
Heavy Rain Face Image Restoration: Integrating Physical Degradation Model and Facial Component-Guided Adversarial Learning

Abstract
:1. Introduction
1.1. Necessity of a New Scale-Aware Heavy Rain Model
1.2. Proposed Approach
1.3. Contributions
- To the best of our knowledge, this study is the first to introduce a new IDM, referred to as the scale-aware heavy rain model. With the rapid increase in intelligent CCTVs, face images can be captured with severe degradation in resolution and visibility, complicating face recognition. To address this issue, the proposed scale-aware heavy rain model that integrates low-resolution conversion and a synthetic rain model is required for accurate face image restoration.
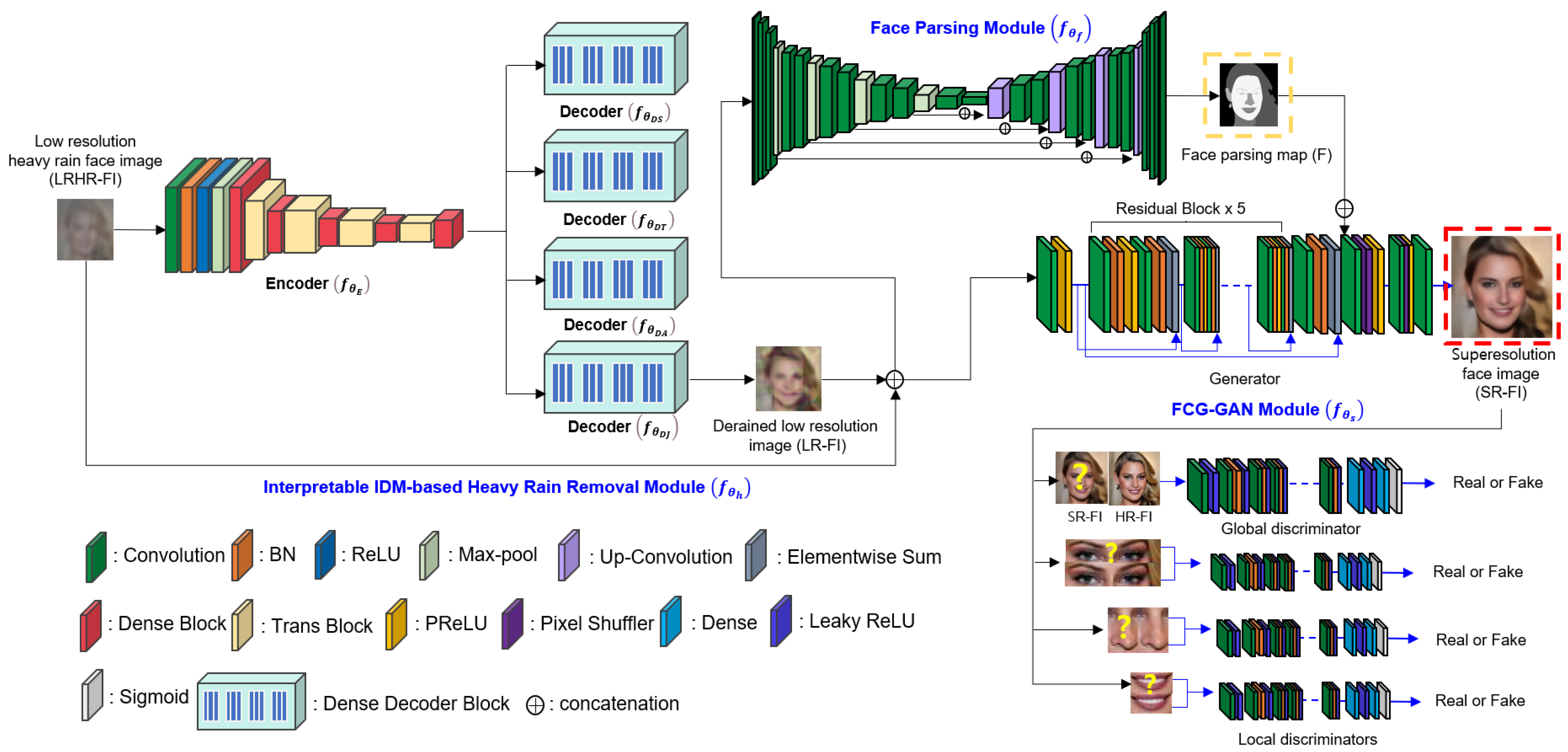
- This study proposes a unified framework for joint heavy rain removal and SR by employing an interpretable IDM-based network and FCGAL. For the inverse of the scale-aware heavy rain model, an interpretable IDM-based network is designed for physics-based heavy rain removal. In addition, for improved facial structure expressions, FCGAL is proposed for enabling the facial attention mechanism and learn local discriminators for facial authenticity examination.
- This study provides new training and test datasets for super-resolving LRHR-FIs with low resolutions and visibility. To generate synthetic LRHR-FIs, CelebA-HQ, which includes clean facial images, is used. The source code for generating LRHR-FIs, according to Equation (2), is available to the public for research purposes. This dataset can be used as a reference dataset, and the evaluation scores can be used for performance comparison.
2. Related Works
2.1. Rain Removal
2.2. Super Resolution
3. Proposed Heavy Rain Face Image Restoration
3.1. Synthetic Image Generation
3.2. Inverse Problem of the Proposed Scale-Aware Heavy Rain Model
3.3. Interpretable IDM-Based Heavy Rain Removal Module
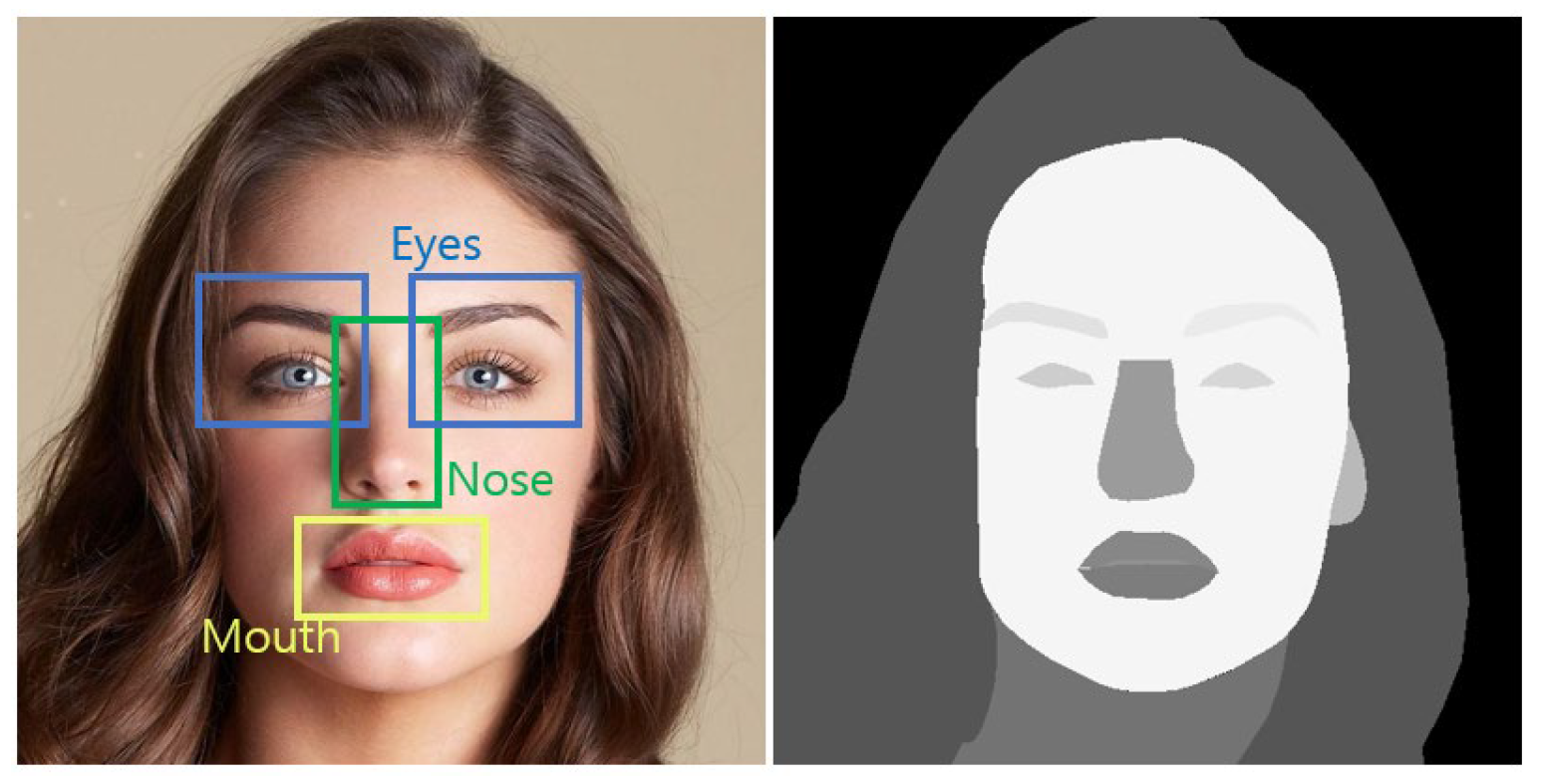
3.4. Face Parsing Module
3.5. FCG-GAN Module
3.6. Network Learning
3.7. Implementation Details
4. Experimental Results
4.1. Ablation Study
4.2. Visual Quality Evaluation
4.3. Quantitative Evaluation
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Farsiu, S.; Robinson, D.; Elad, M.; Milanfar, P. Fast and robust multi-frame super-resolution. IEEE Trans. Image Process. 2004, 13, 1327–1344. [Google Scholar] [CrossRef] [PubMed]
- Krishnan, D.; Fergus, R. Fast image deconvolution using hyper-laplacian priors. In Proceedings of the Neural Information Processing Systems, Vancouver, Canada, 7–10 December 2009; pp. 1033–1041. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1956–1963. [Google Scholar]
- Son, C.-H.; Zhang, X.-P. Near-infrared fusion via color regularization for haze and color distortion removals. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3111–3126. [Google Scholar] [CrossRef]
- Liu, Y.-F.; Jaw, D.-W.; Huang, S.-C.; Hwang, J.-N. DesnowNet: Context-aware deep network for snow removal. IEEE Trans. Image Process. 2018, 27, 3064–3073. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, L.-W.; Lin, C.-W.; Fu, Y.-H. Automatic single-image-based rain steaks removal via image decomposition. IEEE Trans. Image Process. 2012, 21, 1742–1755. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Li, R.; Cheong, L.-F.; Tan, R.T. Heavy rain image restoration: Integrating physics model and conditional adversarial learning. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1633–1642. [Google Scholar]
- Luo, Y.; Xu, Y.; Ji, H. Removing rain from a single image via discriminative sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, CA, USA, 11–18 December 2015; pp. 3397–3405. [Google Scholar]
- Son, C.-H.; Zhang, X.-P. Rain removal via shrinkage of sparse codes and learned rain dictionary. In Proceedings of the IEEE International Conference on Multimedia and Expo Workshop, Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Single image rain steak decomposition using layer priors. IEEE Trans. Image Process. 2017, 26, 3874–3885. [Google Scholar] [CrossRef] [PubMed]
- Sun, G.; Leng, J.; Cattani, C. A particular directional multilevel transform based method for single-image rain removal. Knowl. Based Syst. 2020, 200, 106000. [Google Scholar] [CrossRef]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J. Removing rain from single images via a deep detail network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 1–9. [Google Scholar]
- Zhang, H.; Paterl, V.M. Density-aware single image deraining using a multi-stream dense network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 695–704. [Google Scholar]
- Ren, Y.; Nie, M.; Li, S.; Li, C. Single image de-raining via improved generative adversarial nets. Sensors 2020, 20, 1591. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, X.; Liang, B.; Huang, Y.; Ding, X.; Paisley, J. Lightweight pyramid networks for image deraining. IEEE Trans. Neur. Netw. Learn. Syst. 2020, 31, 1794–1807. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3937–3946. [Google Scholar]
- Zhu, L.; Hu, H.; Xie, H.; Qin, J.; Heng, P.-A. Learning gated non-local residual for single-image rain streak removal. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2147–2159. [Google Scholar] [CrossRef]
- Li, X.; Wu, J.; Lin, Z.; Liu, H.; Zha, H. Recurrent squeeze-and-excitation context aggregation net for single image deraining. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 254–269. [Google Scholar]
- Zhang, L.; Wu, X. An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 2006, 15, 2226–2238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Tang, X. Hallucinating face by eigentransformation. IEEE Trans. Syst. Man Cyber. 2005, 35, 425–434. [Google Scholar] [CrossRef]
- Sun, J.; Xu, Z.; Shum, H.-Y. Image super-resolution using gradient profile prior. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Anchorage, AL, USA, 24–28 June 2018; pp. 1–8. [Google Scholar]
- Roth, S.; Black, M.J. Fields of Experts: A framework for learning image priors. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 860–867. [Google Scholar]
- Zhang, K.; Gao, X.; Tao, D.; Li, X. Single image super-resolution with non-local means and steering kernel regression. IEEE Trans. Image Process. 2012, 21, 4544–4556. [Google Scholar] [CrossRef] [PubMed]
- Ledig, C.; Theis, L.; Herenc, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Kim, J.; Kwon, J.-L.; Lee, K.-M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Zhang, Y.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 63–79. [Google Scholar]
- Ma, C.; Rao, Y.; Cheng, Y.; Chen, C.; Lu, J.; Zhou, J. Structure-preserving super-resolution with gradient guidance. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 7769–7778. [Google Scholar]
- Song, Y.; Zhang, J.; Gong, L.; He, S.; Bao, L.; Pan, J.; Yang, Q.; Yang, M.-H. Joint face hallucination and deblurring via structure generation and detail enhancement. Int. J. Comput. Vis. 2019, 127, 785–800. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Tai, Y.; Liu, X.; Shen, C.; Yang, J. FSRNet: End-to-end learning face super-resolution with facial priors. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2492–2501. [Google Scholar]
- Kim, D.; Kim, M.; Kown, G.; Kim, D.-S. Progressive face super-resolution via attention to facial landmark. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. article no. 192. [Google Scholar]
- Yu, X.; Porikli, F. Hallucinating very low-resolution unaligned and noisy face images by transformative discriminative autoencoders. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 5367–5375. [Google Scholar]
- Xiao, J.; Yong, H.; Zhang, L. Degradation model learning for real-world single image super-resolution. In Proceedings of the Asian Conference on Computer Vision, Virtual, Kyoto, Japan, 30 November–4 December 2020; pp. 1–17. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, S.S. Progressive growing of GANs for improved quality, stability, and variation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–26. [Google Scholar]
- Zhang, K.; Gool, L.V.; Timofte, R. Deep unfolding network for image super-resolution. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 3217–3226. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the International Conference on Computer Vision, Virtual, 4–6 October 2021; pp. 10012–10022. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–16 July 2017; pp. 1125–1134. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structure similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| I | Low-resolution heavy rain face images (LRHR-FI) |
| J | Low-resolution face images (LR-FI) |
| H | High-resolution face images (HR-FI) |
| F | Parsed low-resolution face image (Parsed LR-FI) |
| S | Rain layer |
| T | Transmission map |
| A | Atmospheric light map |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, C.-H.; Jeong, D.-H. Heavy Rain Face Image Restoration: Integrating Physical Degradation Model and Facial Component-Guided Adversarial Learning. Sensors 2022, 22, 5359. https://doi.org/10.3390/s22145359
Son C-H, Jeong D-H. Heavy Rain Face Image Restoration: Integrating Physical Degradation Model and Facial Component-Guided Adversarial Learning. Sensors. 2022; 22(14):5359. https://doi.org/10.3390/s22145359
Chicago/Turabian StyleSon, Chang-Hwan, and Da-Hee Jeong. 2022. "Heavy Rain Face Image Restoration: Integrating Physical Degradation Model and Facial Component-Guided Adversarial Learning" Sensors 22, no. 14: 5359. https://doi.org/10.3390/s22145359
APA StyleSon, C.-H., & Jeong, D.-H. (2022). Heavy Rain Face Image Restoration: Integrating Physical Degradation Model and Facial Component-Guided Adversarial Learning. Sensors, 22(14), 5359. https://doi.org/10.3390/s22145359