1. Introduction
Testing of MEMS is a challenging task due to the complexity of the systems, especially with the progressing miniaturization of the devices. On top of that, the test process is heavily time critical for economic reasons. Nevertheless, ensuring the robustness of parameter extraction methods is crucial, because calibration and fabrication process control require reliable determination of the system as well as process-related properties, which are often not directly measurable. For parameter identification from dynamic tests, as they are carried out during the final module testing of capacitive MEMS accelerometers, approaches based on numerical solutions are generally most desirable in terms of interpretability of the test results. However, due to nonlinear couplings and inhomogeneities in the system differential equations, the computation time of these approaches exceeds targeted limits especially for overdamped systems. Therefore, data-driven approaches have been suggested for the parameter extraction [
1,
2,
3], which results in a considerable reduction of the inference time. Parameter identification approaches applying machine learning (ML) methods, however, lack the reliability and interpretability of numerical methods. Thus, cautious evaluation of the models is necessary before deployment. Furthermore, the unknown behavior of data-driven approaches beyond their generalization regions usually makes a validation step necessary, for example in the form of calculating an ordinary differential Equation (ODE) solution based on the estimated parameters. Theoretically, anomaly or out-of-distribution (OOD) detection might also be addressed by additional evaluations, e.g., by analyzing the reconstruction loss of an autoencoder applied before the main data-driven model [
4]. However, such techniques extend the inference time as a subsequent ML procedure is still required to provide the actual prediction.
Whereas in classical ML methods, network parameters
are solely trained to predict some target parameters
from a feature set
, Bayesian inference, which is also called probabilistic or posterior inference, enables the estimation of a posterior distribution
of the network parameters given knowledge or assumptions, i.e., the prior, and observed data, i.e., the likelihood. Bayesian inference, therefore, offers a way to quantify the uncertainty of model outputs
[
5]. Thus, when a ML model using Bayesian inference trained on a dataset
with
M samples shows large uncertainty in one of the output parameters during evaluation, on the one hand, this might indicate the need for more data in this parameter region. On the other hand, if after deployment during inference in final test large uncertainty is returned for a sample, this information could be used to make the decision to apply a physical model or some heuristic methods instead of using the output of the ML network for this specific device under test (DUT) to identify abnormal or OOD samples and to deal with those separately.
Therefore, it is preferable to apply a ML Bayesian inference method, which computes parameters precisely and with computational efficiency with reliable uncertainty estimates providing interpretability and auditability.
1.1. Parameter Extraction from Dynamic MEMS Tests
During testing of capacitive MEMS accelerometers, dynamic measurements can be carried out by applying electrical voltages to the capacitors through the application-specific integrated circuit (ASIC) [
6,
7]. When the target parameters are ill-conditioned, i.e., are not identifiable from electrical excitation only, these electrical tests are augmented by applying mechanical stimuli, e.g., ±1 g deflections.
The system response appearing as capacitive changes can then be analyzed with respect to the parameters of interest [
1,
7]. For capacitive MEMS accelerometers, these usually include the damping factor
, resonance frequency
, inertial mass
m, and offset
to the initial position of the mass. Moreover, the Brownian noise and the sensitivity are also often of interest [
1], as well as process parameters such as the epitaxial layer thickness and edge loss.
Solving the underlying differential equations numerically becomes cumbersome when inhomogeneities and nonlinearities, e.g., originating from electrical force feedback of the ASIC, cannot be straightened out from the system differential equations [
3].
1.2. Uncertainty in MEMS Testing
A variety of causes and influencing factors leads to uncertainties during the testing of MEMS devices. To a large extent they can be attributed to fabrication process variations [
8,
9,
10,
11]. Slight changes in material properties, for example, changes in the Young’s modulus of the polysilicon [
9] or a change in the thermal conductivity [
12] as well as material inhomogeneities such as varying grain size [
13], can affect the etch processes, and therefore lead to differences in geometry, e.g., changing stiffness coefficients, gap distances, and capacitor areas. Furthermore, variation can be introduced by machine wear and aging [
9], which does not only affect the tools in production, but also the measurement equipment, which might lead to different measurement errors depending on individual test benches. Moreover, generation-recombination, flicker, and Brownian noise [
14], as well as the signal processing path of the sensor itself can lead to uncertainties in the estimation of system parameters. An example for the latter are low pass filters of the ASIC, which are applied for economic reasons and can also impede the distinction between actual changes in the signal and noise. Finally, approximation errors in numerical methods used for system identification especially in the presence of ill-conditioned parameters also provide sources of uncertainty.
The goal of this paper is to answer the question as to how to make parameter extraction from dynamic measurements in MEMS testing more robust by analyzing the uncertainty of neural network estimations. Four ML Bayesian inference architectures are investigated, focusing on two main aspects. The first objective is to compare the architectures regarding their general predictive performance. The second objective is to evaluate the reliability of the uncertainty estimates given by the four architectures within the training distribution as well as under OOD conditions. Thus, three scenarios are investigated using simulated turn-off transients of capacitive MEMS accelerometers, namely the available training set size, sudden increase of measurement noise, and a change in damping factor, e.g., due to leakage.
The paper is organized as follows.
Section 2 briefly categorizes and summarizes related work on uncertainty quantification in the context of MEMS fabrication and testing.
Section 3 introduces important concepts and methods for uncertainty quantification with neural networks including the relevant evaluation metrics.
Section 4 describes the datasets used and provides details on the experimental procedure and the applied ML methods. In
Section 5, the results are divided into the comparison of the ML methods on the synthetic data, evaluation on noisy data, and evaluation of systems with increased damping factor, which are subsequently discussed in
Section 6. The conclusion is drawn in
Section 7.
2. Related Work
The related work is a summary of uncertainty quantification in MEMS concerning applications. Extracting relevant system parameters from either electrically or mechanically excited MEMS tests during wafer-level testing (WLT) [
7,
15] as well as final testing (FT) [
1] is targeted by various approaches, depending on the complexity of the underlying system. Whereas for some systems, the fitting of coefficients of an equation for sensitivity determination [
1] provides sufficient precision, other systems require the application of multivariate adaptive regression splines (MARS) [
16], building ensembles of MARS or support vector machines (SVMs) [
2], or different variants of neural networks [
3].
Most UQ related work in the application area of MEMS focuses on the analysis of uncertainty arising from material properties and geometrical changes studying the resulting effects on performance parameters. These include sensitivity studies based on Monte-Carlo simulations from finite element models analyzing uncertainty propagation [
9], sensitivity due to uncertainty of diaphragm parameter [
17], and the quantification of uncertainty originating from process variations via tensor recovery [
11]. Furthermore, stochastic effects from the micro structure of polysilicon films [
13], uncertainties in stiction [
18], or uncertainty arising from creep failure [
19] have been evaluated. The work whose objectives come closest to the work presented in this paper was made by Gennat et al. [
20]. In the context of rapid optical testing of a MEMS resonator, through multivariable finite element analysis, a polynomial was developed describing the DUT-specific parameters mechanical stress, flexure thickness and flexure width dependent on eigenfrequencies measured during WLT, while providing uncertainty estimates for each parameter and DUT from the Chebyshev optimization. However, for the overdamped MEMS accelerometers targeted within the present paper, parameter identification relying on numerical solutions does not meet the strict time constraints and therefore the use of ML-driven approaches is required, for which uncertainty estimates need to be obtained in a different manner as described in
Section 3.
Dealing with model selection for radio-frequency MEMS switches, Ling and Mahadevan [
21] evaluated a general polynomial chaos surrogate model through classical and Bayesian hypothesis testing, reliability-based evaluation, and an area metric-based method, which compares prior and posterior distributions. Mullins et al. [
22] built on this work and suggested a weighted evaluation of the different epistemic uncertainty estimates using a Gaussian Process (GP) as surrogate model.
Even though UQ methods for ML architectures have not gained a lot of attention in the area of MEMS production and testing as of yet, their use has been successfully demonstrated in other safety and time-critical applications. Auspicious examples are the application of MDNs in autonomous driving [
23] and the use of bootstrapping and Monte-Carlo dropout for collision avoidance in robotics by controlling the movement speed according to uncertainty estimates [
24]. Furthermore, BayesFlow was shown to reach encouraging accuracy in the parameter recovering on a macroeconomic agent-based model [
25] and its use to infer spreading dynamics of diseases via Bayesian inference has been demonstrated [
26].
3. Methods for Uncertainty Quantification
There are three categories of tasks which can be addressed by different methods for uncertainty quantification, summarized by Lust et al. [
27]; First, in the setup of predictive uncertainty, mainly samples within the training distribution and thus within the generalization envelope of a deep neural network (DNN) are taken into account. Samples with larger uncertainty scores assigned are associated with a more error-prone output. The second objective is anomaly or OOD detection, i.e., the identification of whether an input sample belongs to the training distribution. The third objective is the security of the system by aiming to detect synthetically generated or manipulated inputs, which might be used to deliberately provoke wrong outputs, called adversarial examples.
In this work, the focus is on the first two tasks, where the distinction between them is based on the fact that the overall predictive variance or uncertainty of a prediction arises from two components, namely epistemic uncertainty and aleatoric uncertainty [
28,
29,
30,
31]. Epistemic uncertainty
is associated with the uncertainty which arises from the choice of network parameters and is due to phenomena unexplained by the ML model [
28], and thus also called model uncertainty. The aleatoric uncertainty component
originates from noise in data, e.g., due to the measurement error of a test bench. The ML model cannot compensate for measurement error, thus this contribution cannot be reduced for example by gathering more data. The aleatoric component can be either homoscedastic if all samples are subjected to the same systematic noise, or heteroscedastic if the noise is input dependent [
32]. Thus, for a dataset
the total predictive variance results from the sum of the two uncertainty components [
23,
33]:
For further information on the basics of decision making under uncertainty, and a background on Bayesian inference, the reader is referred to [
23,
29,
34].
Gaussian Processes and Markov Chain Monte-Carlo (MCMC) algorithms are designed to capture the uncertainty of their predictions. However, their computational expense usually disqualifies them for near real-time applications for complex systems [
5,
29,
35]. For uncertainty quantification (UQ) with DNNs, variational inference (VI)-based approaches are widely used to approximate the posterior probability distribution. Since DNNs do not contain any confidence representation, variability has to be introduced by either creating a distribution over networks or over their parameters. An example for VI is the ensembling of multiple trained models [
29,
33,
36,
37]. If the different models return similar outputs for an input sample, it is more likely that the input lies within the generalization area of the models. However, a distinction of the uncertainty source is not possible with this method [
29]. Another VI-based approach is the application of Monte-Carlo Dropout during inference [
38], i.e., passing the same input sample through the same DNN multiple times while randomly setting weights to zero, and thus creating a distribution over several predictions.
3.1. Network Architectures of BNN, MDN, PBNN and BayesFlow
3.1.1. Bayesian Neural Networks
Instead of the deterministic weights, which are used in common DNNs, Bayesian neural networks (BNNs) learn probability distributions over their weights starting from given priors. However, there exists no universally valid approach on the choice of the priors even though Gaussian distributions with zero mean are often assumed.
As in all VI-based approaches, the posterior distribution for an input
needs to be approximated as it cannot be determined analytically [
29,
38]. In BNNs, this is done by minimizing the Kullback–Leibler (KL) divergence
[
39] between the true and estimated posterior distribution, here denoted as
and
with
This is equivalent to minimizing the negative log-likelihood (NLL), i.e., performing maximum likelihood estimation (MLE) [
28,
40]. Although the true posterior distribution is unknown, minimizing the KL divergence enables the definition of the evidence lower bound (ELBO), which is a lower bound of the log marginal likelihood [
28,
41]. The ELBO can be maximized via stochastic variational inference (SVI), which enables the optimization via deep learning methods. During inference, multiple predictions of one input through network are conducted, sampling from the weight distributions multiple times. Thus, a non-parametric distribution is obtained [
42]. The cost function is composed of a weighted sum of a term measuring how well the network fits the data
and the KL divergence for comparing the difference between the true and estimated posterior, which is multiplied by the KL weight
:
Within the training procedure, SVI can be implemented via the “Bayes-by-backpropagation” algorithm [
42].
The computational effort can be reduced by using distributions over weights only in the last layer(s) [
43]. However, a BNN constructed in the described way can only provide information regarding its epistemic uncertainty [
42].
3.1.2. Mixture Density Networks
An architecture which enables the prediction of parametric distributions and does not use sampling or probability distributions within the network is the mixture density network (MDN) [
35]. It is trained to estimate the parameters of the posterior distribution, e.g., in the form of a Gaussian mixture model (GMM) within one prediction pass. Thus, in the case of a mixture of Gaussian distributions,
with mean or expected value
, standard deviation
, and weight coefficients
,
, for a predefined number of mixture components
K [
5]. In the case of a unimodal output, the weight coefficients are discarded. The total expectation
and variance
of a Gaussian mixture are given by the following equations [
23,
35,
44]:
Although any posterior can be approximated by a mixture of sufficient components, the MDN architecture is only able to capture aleatoric uncertainty as it does not provide variability within an individual prediction. Choi et al. [
23] argued that when using more than one component, such a variability can though again be introduced. Additionally, the known difficulty of mode collapse in this architecture can lead to the disregard of modes in multimodal distributions [
45].
3.1.3. Probabilistic Bayesian Neural Networks
Probabilistic Bayesian neural networks (PBNN) are built up with the two network architectures described above, i.e., network weights are defined as distributions and a MDN output layer is attached to the network. Thus, each of
T repeated prediction passes of an unchanged input vector leads to a slightly different parameterized posterior. In case of a mixture of Gaussian distributions, the total variance is calculated by applying Equation (
6) with equal weights for each distribution. Furthermore, the mean over the standard deviations represents the data uncertainty
[
23]. Thus, with
as residual, PBNNs are able to capture both aleatoric and epistemic uncertainty.
3.1.4. BayesFlow
BayesFlow [
46] is a Bayesian inference method in use of an invertible neural network. The invertible neural network is based on normalizing flows, which allow for inference from a simple probability density to a complex distribution through a series of invertible mappings [
47]. The distribution inference with implicit form is directly obtained from the neural network, and thus can be very exact. The network is trained to learn a global estimator for the probabilistic mapping from observed data to underlying physical parameters, then the well-trained network can directly infer the posterior of physical parameters from the same physical model family.
The architecture of BayesFlow (shown in
Figure 1) consists of a summary network to reduce the dimensionality of the observed data
and a conditional invertible neural network (cINN) to transform the distributions implicitly between the physical parameters
and latent variables
. The network parameters of the summary network and cINN are denoted as
ψ and
ϕ, respectively. Both parts can be optimized jointly via back propagation by minimizing the KL divergence between the true and the model induced posterior of
. Then, the objective function can be written as follows:
The summary network
is supposed to be adjusted to the observed data
. For example, a long short-term memory network (LSTM) [
48] is a typical architecture for time-series data. In this way, the compressed data
with informative statistics can be passed through the cINN and taken as the condition while inducing the posterior of physical parameters
, namely
.
The cINN, assumed as an invertible function
, is built up from a chain of conditional affine coupling blocks [
49], the structure of which ensures the neural network to be invertible, bijective and to have easily calculable Jacobian determinant
[
50]. In the forward direction, the input is the physical parameters
, while the output is the latent variables
, which follow a standard normal distribution
. Via the change-of-variables formula of probability, the posterior can be reformulated as
For a batch of dataset
, the objective function becomes
In the inverse direction, the physical parameters
can be obtained by calculating the mean of the posterior
with the well-trained network and sampled variables
. For an observation of test
with sampling a latent variable
T times, this process can be formulated as follows:
3.2. Metrics
To evaluate the quality of Bayesian inference, on the one hand, the accuracy, precision, and reliability of the estimation of model parameters are taken into consideration. On the other hand, the posterior distribution of model parameters is investigated, regarding uncertainty, consistency with the prior distribution, and multicollinearity between model parameters.
- 1.
In terms of the regression accuracy between the estimation and the ground truth of the model parameters, normalized root mean squared error (NRMSE) and coefficient of determination (
) are two standard metrics. Moreover, in practice it is also important to have information about the maximum absolute error (MAXAE) and mean absolute error (MAE). For a group of estimated
and true parameters
with the mean of the true parameters
, these metrics can be calculated as follows:
- 2.
In terms of the precision and reliability of the estimation, the normalized mean confidence interval width (NMCIW) and confidence interval coverage probability (CICP) at the 95% confidence level are assessed. The higher the CICP is, the more reliable the estimation could be. Whereas the smaller the NMCIW is, the more precise the estimation could be. For the
m-th parameter by sampling it
T times, the standard deviation is
, the 95% confidence interval (CI) with lower limit
and upper limit
is
Then, the NMCIW and CICP for the entire group of parameters are
- 3.
In terms of the uncertainty of posterior distribution, the negative log-likelihood (NLL) is calculated by assuming the posterior to be Gaussian distributed, which is guaranteed for MDN and PBNN. When the mean is taken to be the Gaussian NLL of the
M data samples, the NLL is
6. Discussion
All uncertainty expressing methods showed an increase in the overall performance compared to a pure ResNet architecture. This effect was reported by other works as well, e.g., [
56,
57], especially for OOD samples and small datasets. By taking the probabilistic perspective, averaging predictions drawn from continuous distributions resembles the usage of an infinite ensemble, which explains the improvement in performance.
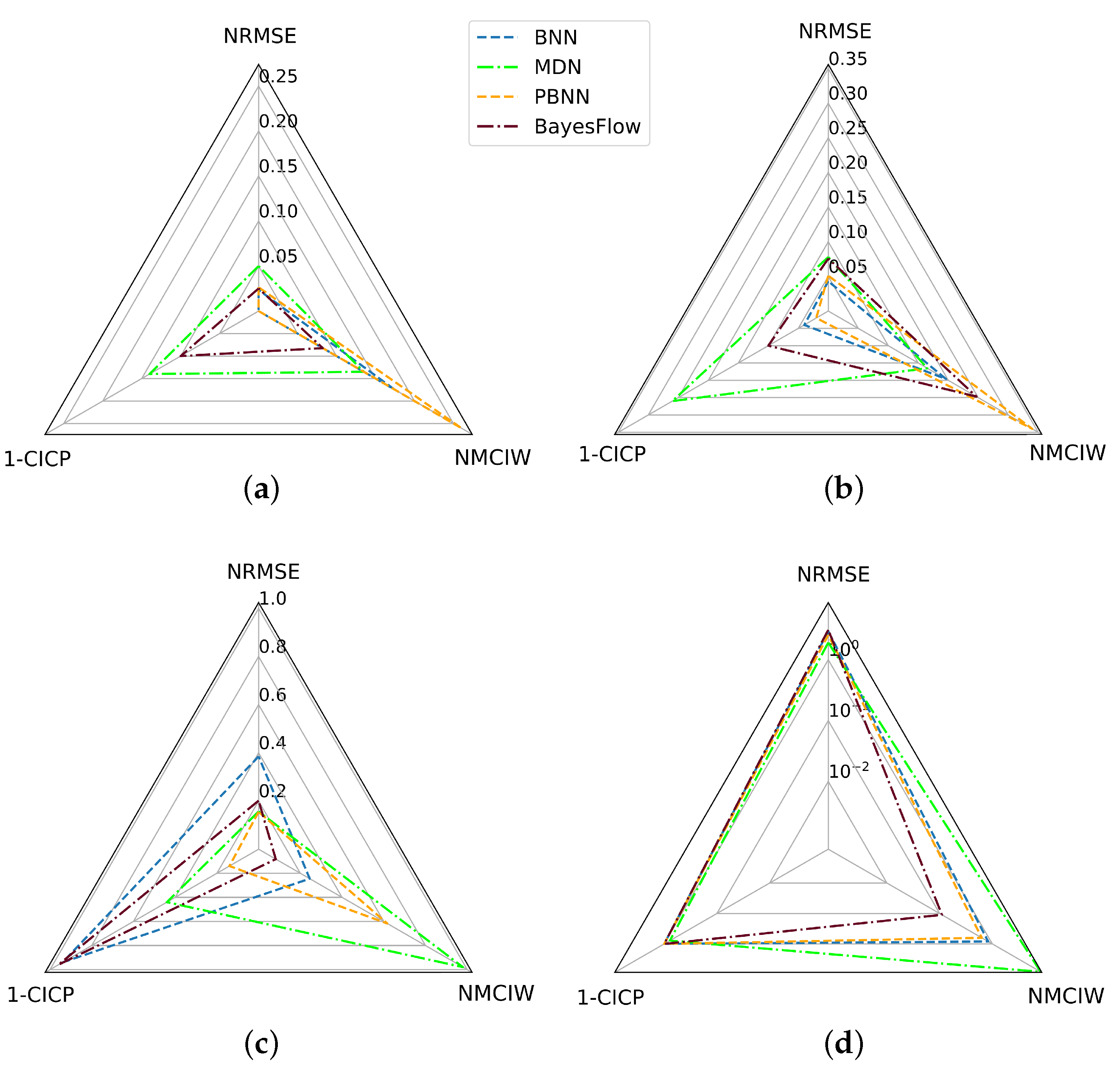
The predictive performance of the BayesFlow architecture, however, was considerably higher than that of BNN, MDN, and PBNN on the same amount of training data. After doubling the training set size, the performance of the latter three architectures, however, improved, but they still did not outperform the BayesFlow network on average. The reason for this is twofold: First, the separate summary network of the BayesFlow architecture, which focuses on learning the representation of observed data, is optimized jointly with the inference network, which learns the posterior distribution of physical parameters. This separation of architecture encourages the learned representation to be as improving as possible for the inference of parameters’ distribution. Second, BayesFlow generates samples of posterior distribution of physical parameters according to the well-trained network without assuming its shape. This implicit network-induced posterior contributes to the more precise estimation of physical parameters. Another difference between the architectures was the quality of their uncertainty scores. In BayesFlow and PBNN, parameters with small predictive errors such as were predicted with smaller intervals. For BNN and MDN this was not the case, thus, the latter two architectures require the definition of a parameter individual threshold for OOD detection.
Furthermore, in all experiments, BayesFlow gave the narrowest intervals and, associated therewith, the lowest CICP values, thus overestimating its predictive performance or underestimating the underlying uncertainties. On the contrary, the NMCIW of the MDN was often the largest. Despite that, the CICP of the MDN was often smaller than 0.95, even on the unperturbed test set. This can be explained by the general lower performance of the MDN compared to BNN, BayesFlow, and BPNN with at the same time underestimated uncertainty. Overall, the PBNN led to the best CICP scores, which might be due to its capability of capturing both aleatoric and epistemic uncertainty components. For the remaining architectures, calibration of the uncertainty scores on a separate calibration dataset might prove useful [
58,
59].
The influence analysis of the number of evaluations for one input signal showed that for a sound statement on the predictive uncertainty at least 25, or better still, 50 to 200 evaluations were required. The NRMSE also benefited from an increased number of evaluations, analogous to ensemble methods. This should be considered when assessing the suitability of the models for deployment.
For the BNN, another adjusting option for performance improvement was provided by the KL weight
. At a weight of
, the BNN even outperformed BayesFlow regarding the NRMSE, however, the NMCIW did not reliably reflect the uncertainty anymore as the share of the KL loss in the cost function then becomes negligible. However, decreasing
led to a further drop in performance as the training stimulus to optimize the distributions over weights vanishes. In other works,
was also found to be optimal [
60]. Thus, a trade-off has to be accepted between predictive performance and quality of uncertainty score.
This becomes even more relevant when investigating the influence of the KL weight on the distinction between aleatoric and epistemic uncertainty in PBNNs, as shown in
Figure 7. As expected, the epistemic uncertainty decreased with the doubling of the training set size. Counterintuitively, especially for low KL weights, the aleatoric uncertainty also decreased with larger training set sizes. This might be explained by the poor generalization of the model trained on a too small dataset reflected by the comparatively high epistemic uncertainty. The effect is therefore expected to vanish for larger datasets. Huseljic et al. postulated that high epistemic uncertainty entails high aleatoric uncertainty [
61]. Thus, even for a KL weight of 0.1, the difference in the aleatoric uncertainties between the model trained on 100 samples compared to the ones trained on 200 and 400 samples remained visible even if the difference between the latter two equalized as expected. In practice, if very few training samples are available and the model uncertainty is high, the distinction between the two uncertainty components therefore has to be regarded with special caution.
Furthermore, a relation between KL weight and returned aleatoric uncertainty appeared for 100 and 200 training samples. For 400 training samples, the KL weight did not influence the aleatoric uncertainty anymore, indicating that here the number of training samples was sufficient to reduce both loss terms irrespective of their weighting.
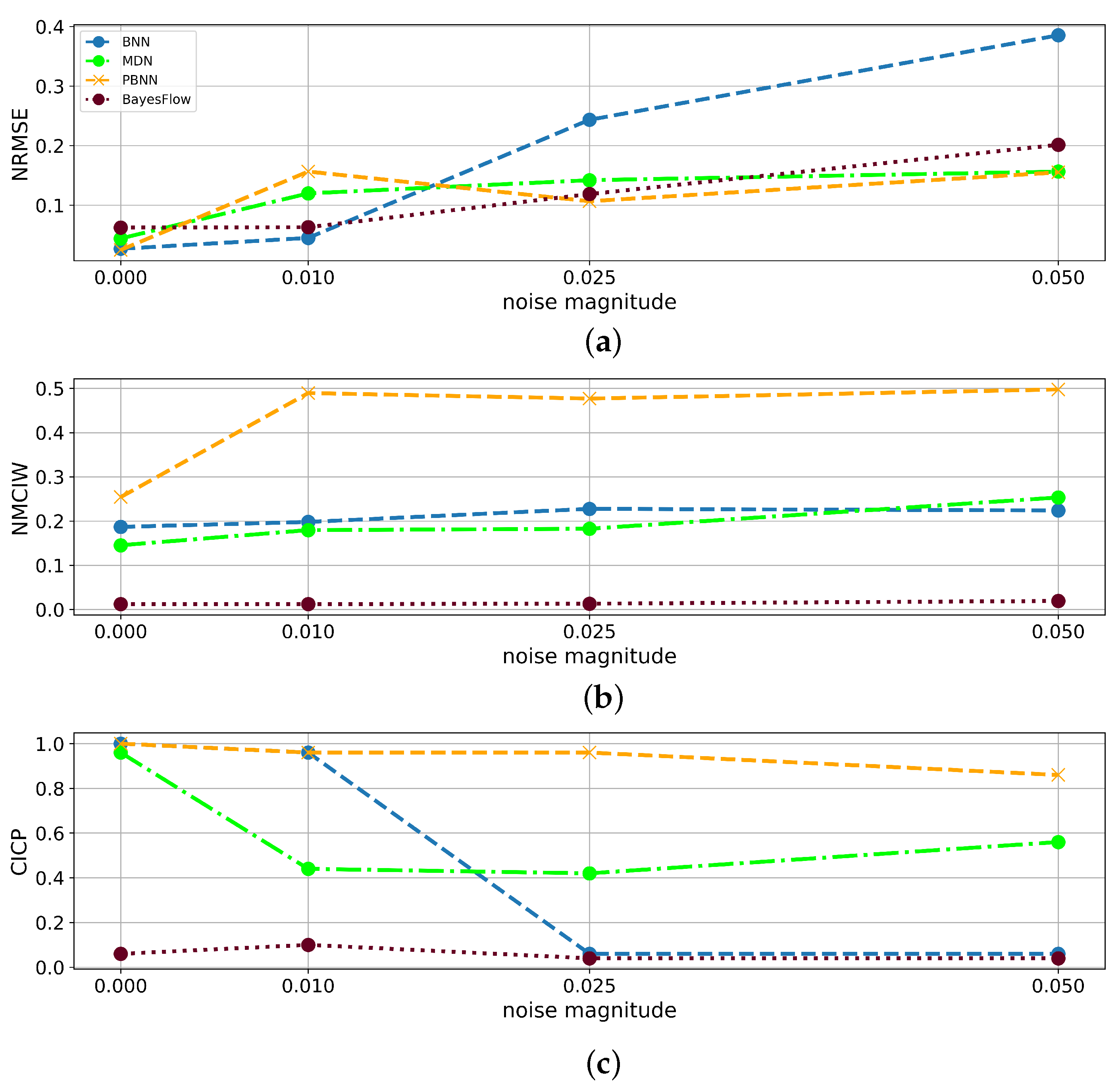
In the presence of noisy inputs, as expected, the epistemic uncertainty given by the PBNN remained on a constant level, as noisy time series were already contained in the training dataset, and the aleatoric uncertainty sharply rose for disturbed inputs. This matches the observation that the NMICW of the MDN increased strictly monotonously with the noise amplitude whereas BNN and BayesFlow, unable to capture aleatoric uncertainty, did not show an increase of the NMICW resulting in low CICP values. For the PBNN, a notable step between clean and noisy data was visible, making it the only model with a high CICP even for noisy inputs. The increased epistemic uncertainty when trained on samples with varying noise levels compared to clean data is plausible as the model thereby was trained on less data for each individual noise domain. During all experiments, only homoscedastic noise has been applied, which might in practice not always be the case, e.g., due to influences from measurement equipment or ASIC. Additionally, it might be interesting for the application in FT to further split the detected data uncertainty into the individual sources described in
Section 1.2.
It is well-known from the literature that purely data-driven models usually do not perform well outside of their training distribution. Thus, as expected, the NRMSE in the prediction of from the test set containing DUTs with higher damping factors than the training set decreased compared to models trained on samples from all three distributions, e.g., from 0.0391 to 1.82 for and 1.91 for for the BNN. Process drifts and defects, however, are commonly observed from productive data, which makes it important to closely evaluate how the confidence interval widths of the individual architectures reflect their uncertainty. From the OOD-experiments with DUTs with damping factors outside of the training distribution, it became visible, that the uncertainty intervals of BNN, MDN, and PBNN increased steeply for these test samples. However, similar to the observations for the incremental noise magnitudes, the predictive error of the BayesFlow model, which by far outperformed the other architectures on samples within the training distribution, heavily increased for DUTs with higher damping factors, but the interval widths did not reflect this behavior as distinctly as the other architectures. As the BayesFlow network also showed the worst generalization performance for the prediction of the resonance frequency for DUTs with previously unseen damping factors and gave low CICP scores for the other experiments, one might conclude that the BayesFlow model constituting the most complex one of the evaluated network architectures, slightly overfitted during the training process. This hypothesis is supported by the tremendous influence of the training set size on the NMCIW and CICP of BayesFlow. It could be interesting to investigate whether countermeasures to overfitting might also increase the CICP of BayesFlow models, for samples outside of the training distribution. To increase the confidence interval and improve the robustness of BayesFlow, some stochastic components should be extended in the future work.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










