
An Explainable Evolving Fuzzy Neural Network to Predict the k Barriers for Intrusion Detection Using a Wireless Sensor Network




Abstract
:1. Introduction
2. k Barriers for Intrusion Detection in Wireless Sensor Networks—State-of-the-Art Approaches
3. Evolving Fuzzy Systems and Interpretability
3.1. Evolving Fuzzy Systems
3.2. On-Line Criteria of Interpretability
- Distinguishability and simplicity: Simplicity requires models with a trade off between low complexity and high accuracy in order to avoid over-fitting effects [30]. In contrast, distinguishability requires the use of structural components (rules, fuzzy sets) in a separable way (avoiding significant overlaps and redundancies [31]).
- Consistency: Consistency in a rule base is given when there are no conflicting, contradictory rules [32], e.g., when no rules overlap in their antecedents and consequents or when there is a significant overlap between two or more rules in their antecedents, then their consequents are also similar (overlapping). A fuzzy rule is consistent with another one if the similarity of their antecedents is lower than the similarity of their consequents [12].
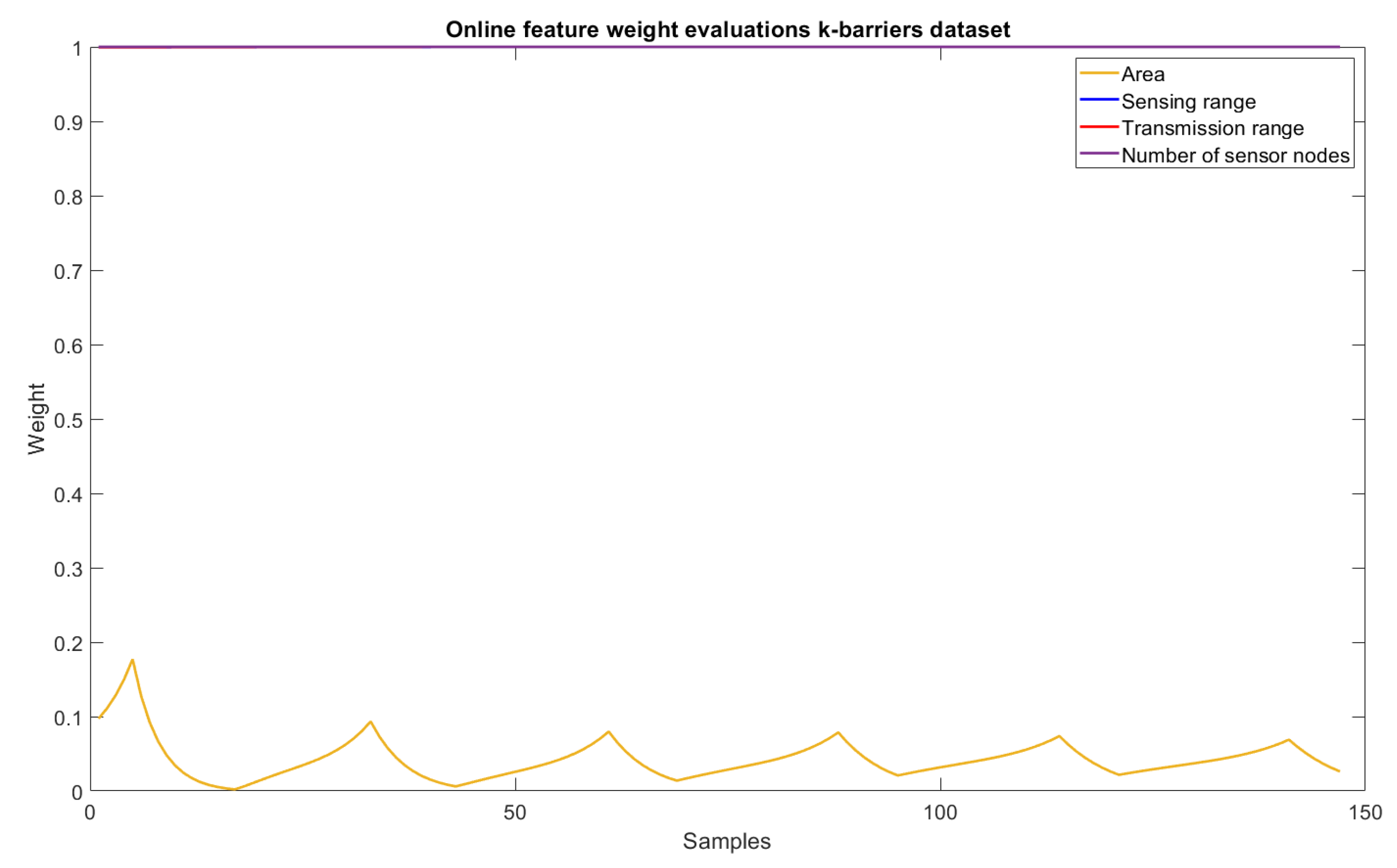
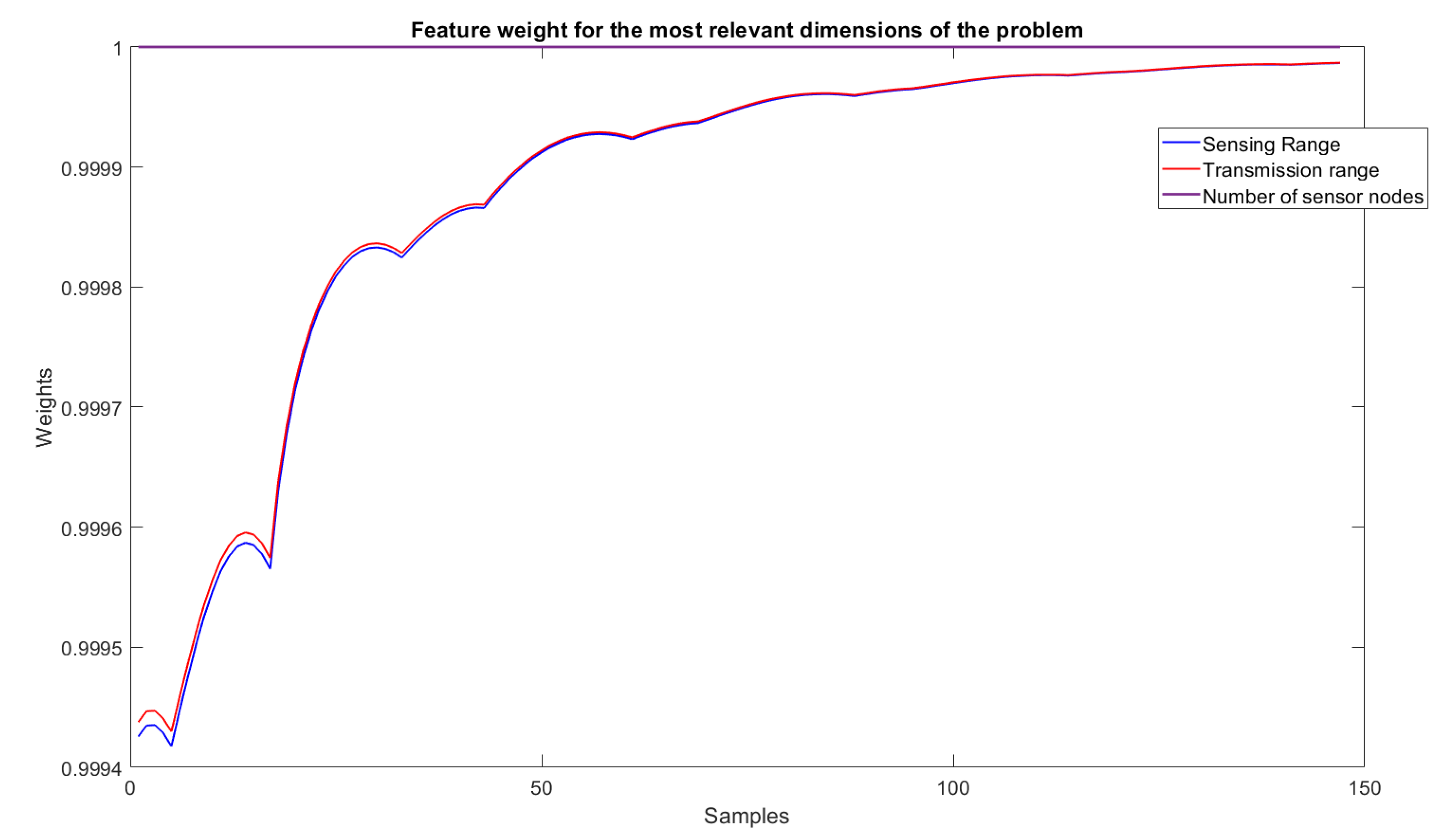
- Feature importance levels: This capability evaluates the importance of features in the final output of the model. It allows evaluation of their impact to explain the knowledge contained in the data (input–output relations) and also may serve for the possibility to reduce the rules’ length, which, in turn, increases their transparency and understandability (see the Results section for a concrete example).
- Rule importance levels: estimations of the significance levels of the rules are defined by numerical values (weight or consequents of the rules) to assess the relevance of the rule for the analyzed context and, thus, its importance to the prediction capabilities of the model.
- Interpretation of consequents: The consequents should not be too complex (e.g., higher order polynomials or wavelet functions), but represent the essential rule output statement for the local region it represents—for instance, in classification problems, a class confidence vector indicating the confidences in the different classes for the respective local regions leads (in combination with the rules’ antecedent parts) to a direct interpretation where classes are located in the feature space and overlap. In our case of regression problems, we deal with singleton numerical output values whose direct interpretation is the number of barriers in the associated region of the rule models. Another interpretation facet is how the consequents may change during stream learning and, thus, how rules may change their ’opinion’ in their output (we provide an example in the Results section).
- Knowledge expansion: Evaluation of results beyond accuracy. The criteria for incorporating new knowledge, assessments, and operations with the rules fit as parameters for this measure. The rules evolution criteria also make it possible to identify an evaluation of the knowledge obtained from the model.
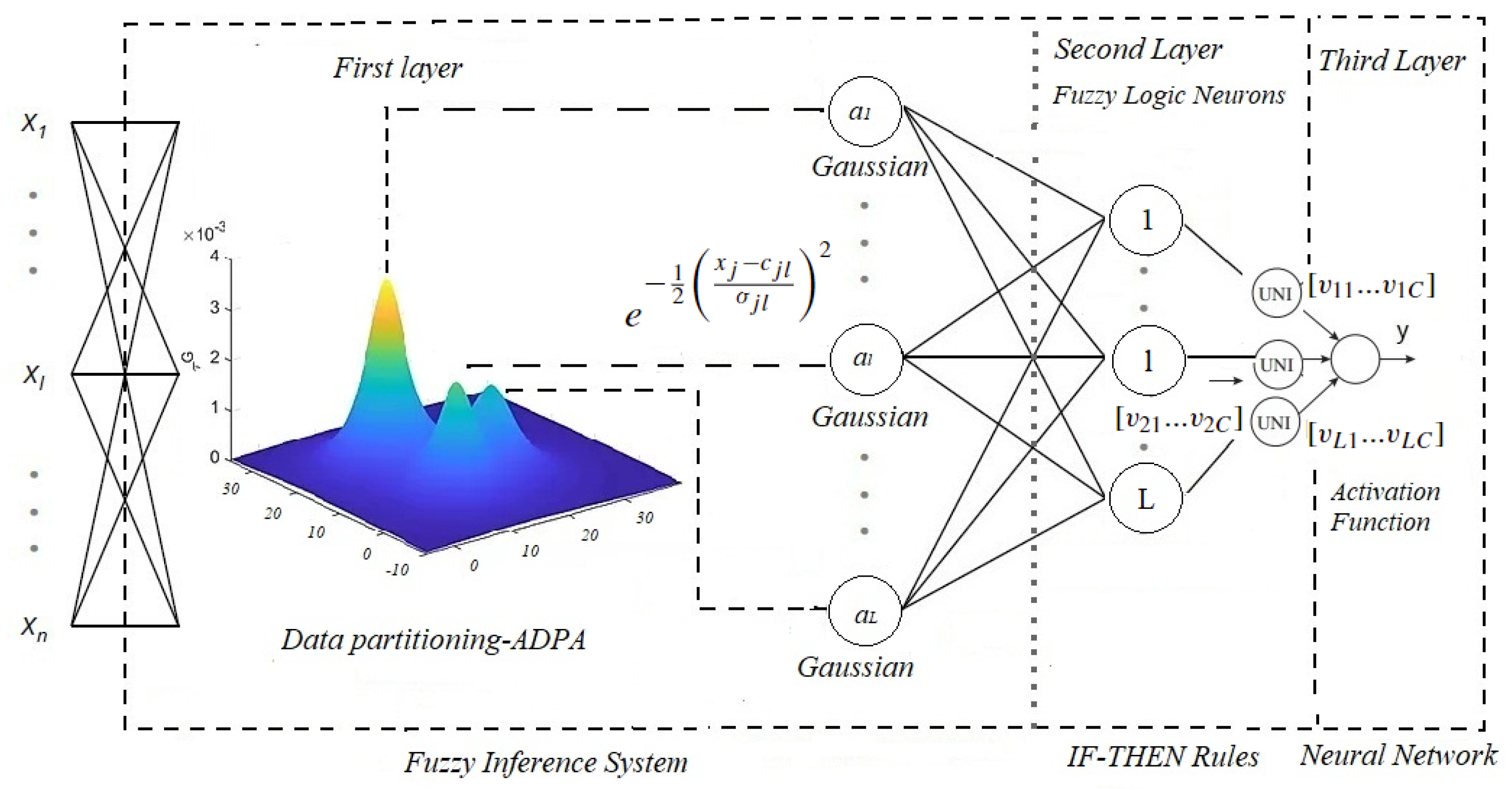
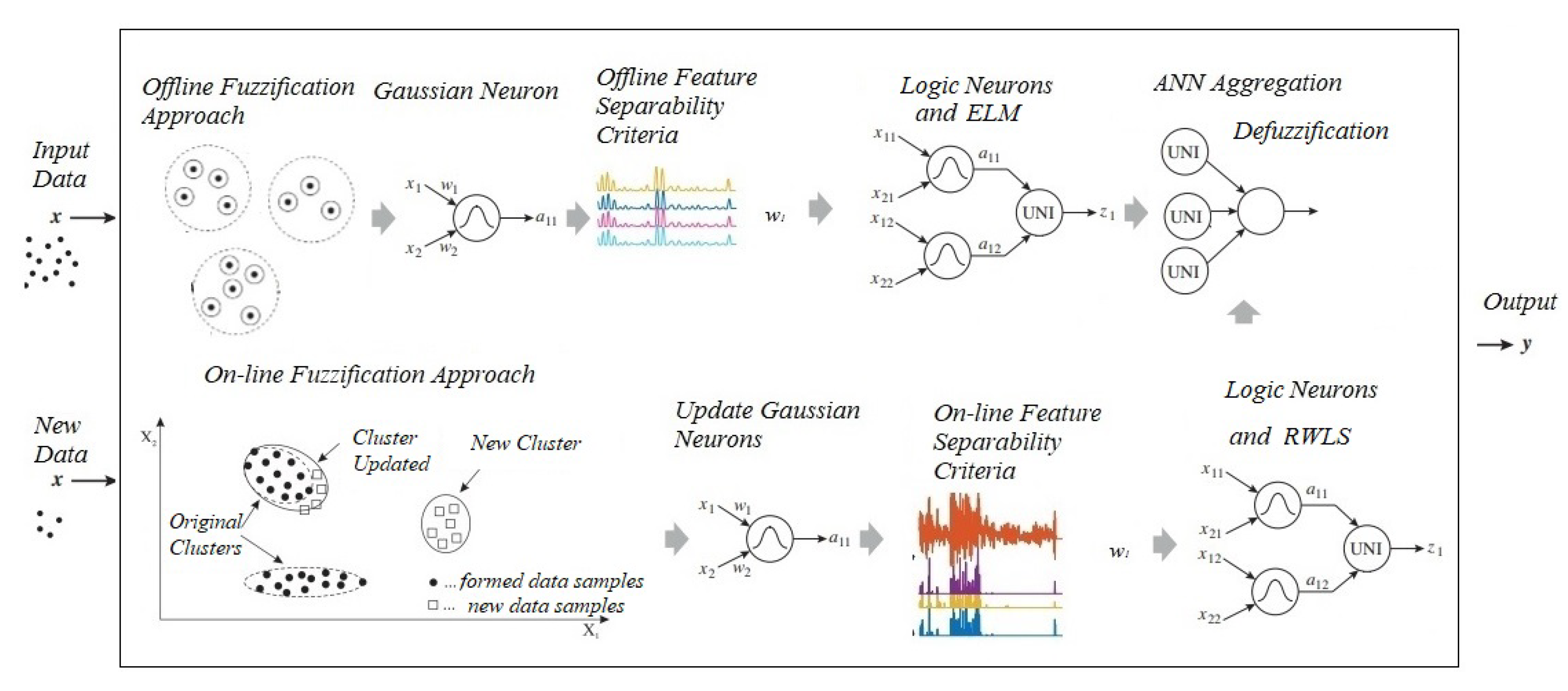
4. Evolving Fuzzy Neural Network for Regression Problems—ENFS-Uni0-reg
- Stage 1: Ranking of the samples regarding the distance to the global mode.
- Stage 2: Detecting local maxima (local modes).
- Stage 3: Forming data clouds.
- Stage 4: Filtering local modes.
- Stage 5: Selection of the first data sample within the data stream as the first local mode.
- Stage 6: System structure and meta-parameters update.
- Stage 7: Forming data clouds from the updated structure and parameters.
- Stage 8: Handling the outliers.
Feature Weight Separability Criteria for Regression Problems (FWSCR)
| Algorithm 1 ENFS-Uni0-reg Training and Update Algorithm |
Initial Batch Learning Phase (Input: data matrixwithsamples):
|
5. Experiments
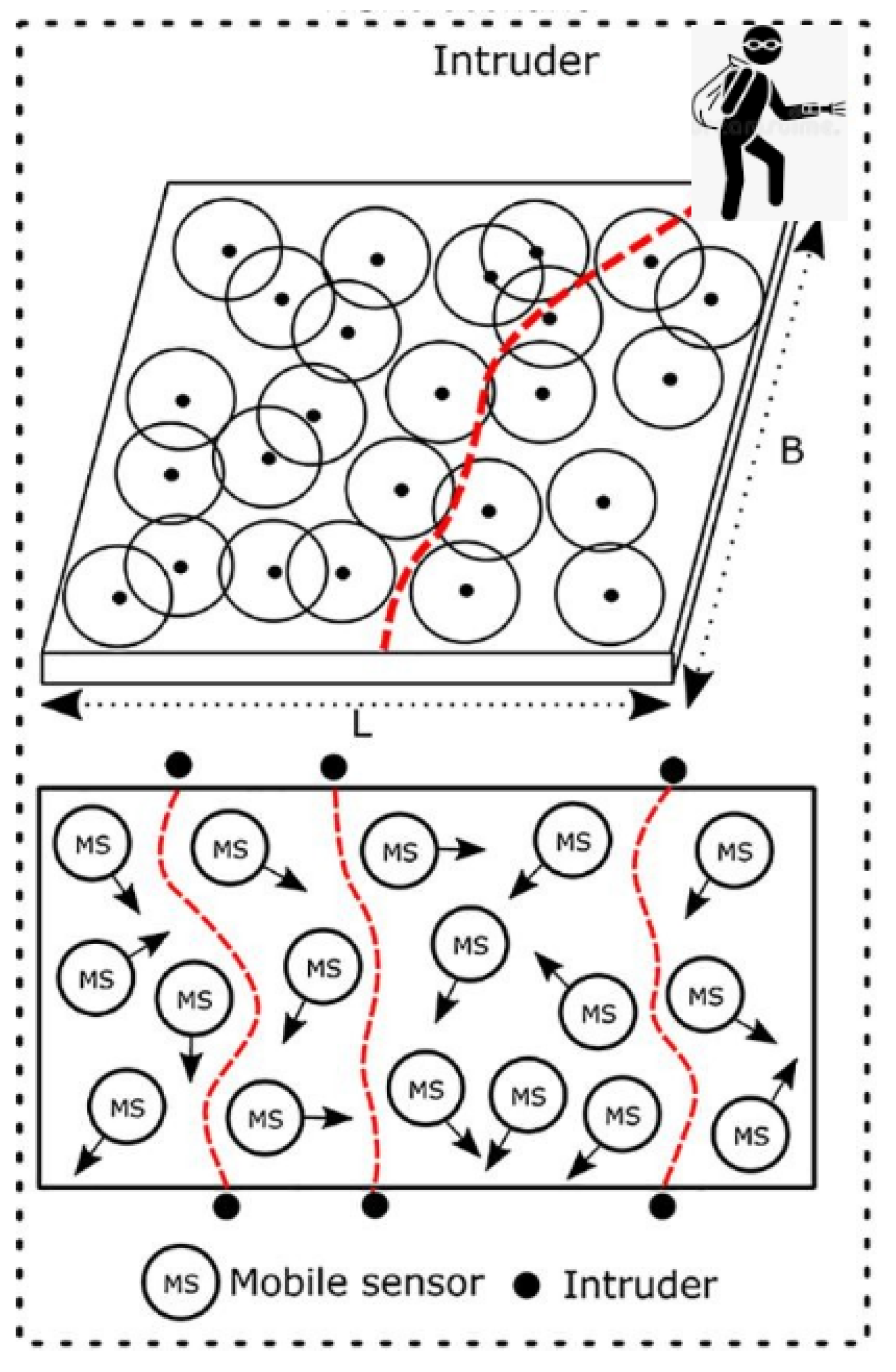
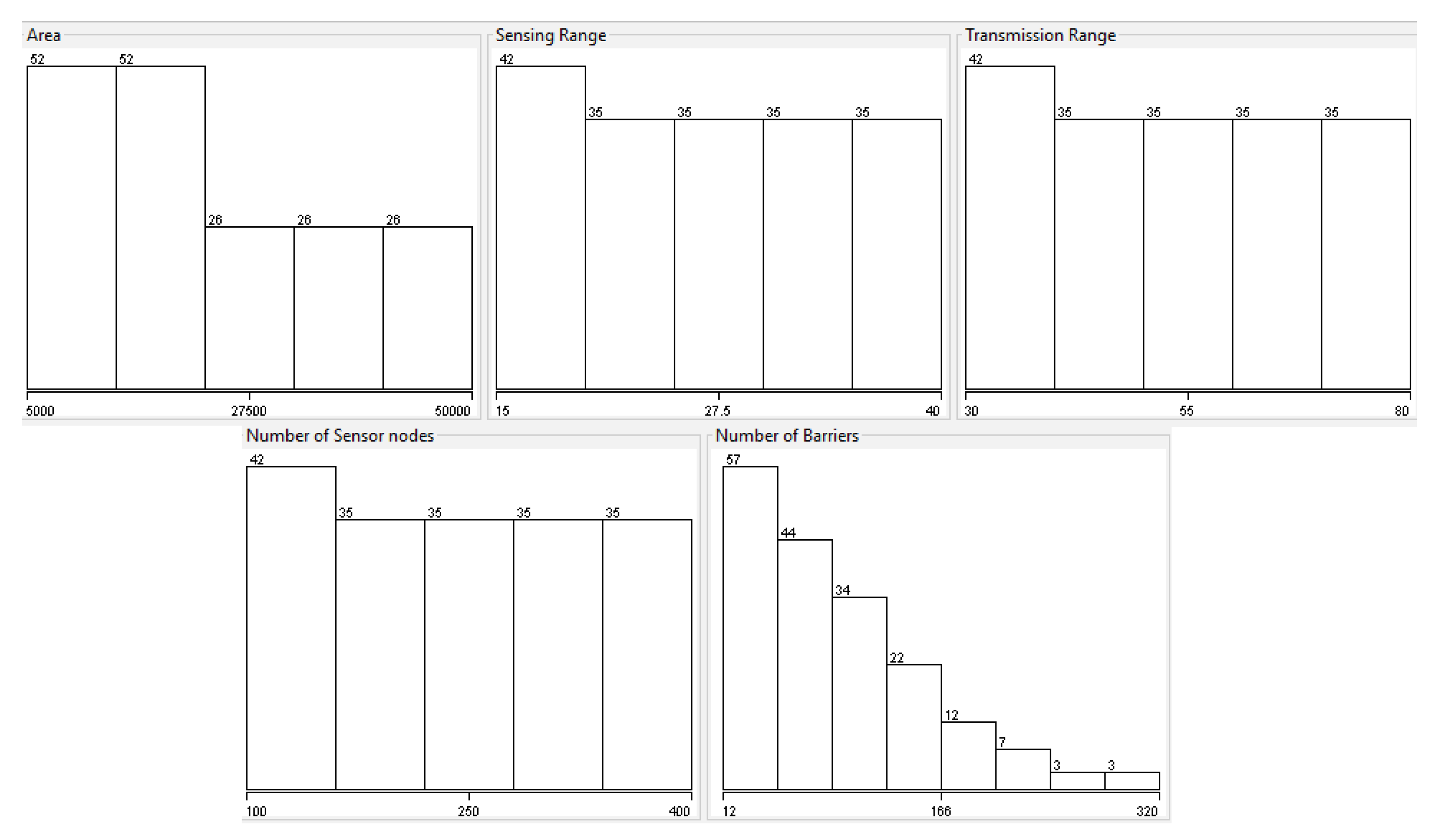
5.1. Intrusion Detection Using a Wireless-Sensor-Network Dataset
5.2. Models Used in the Experiments
6. Discussions
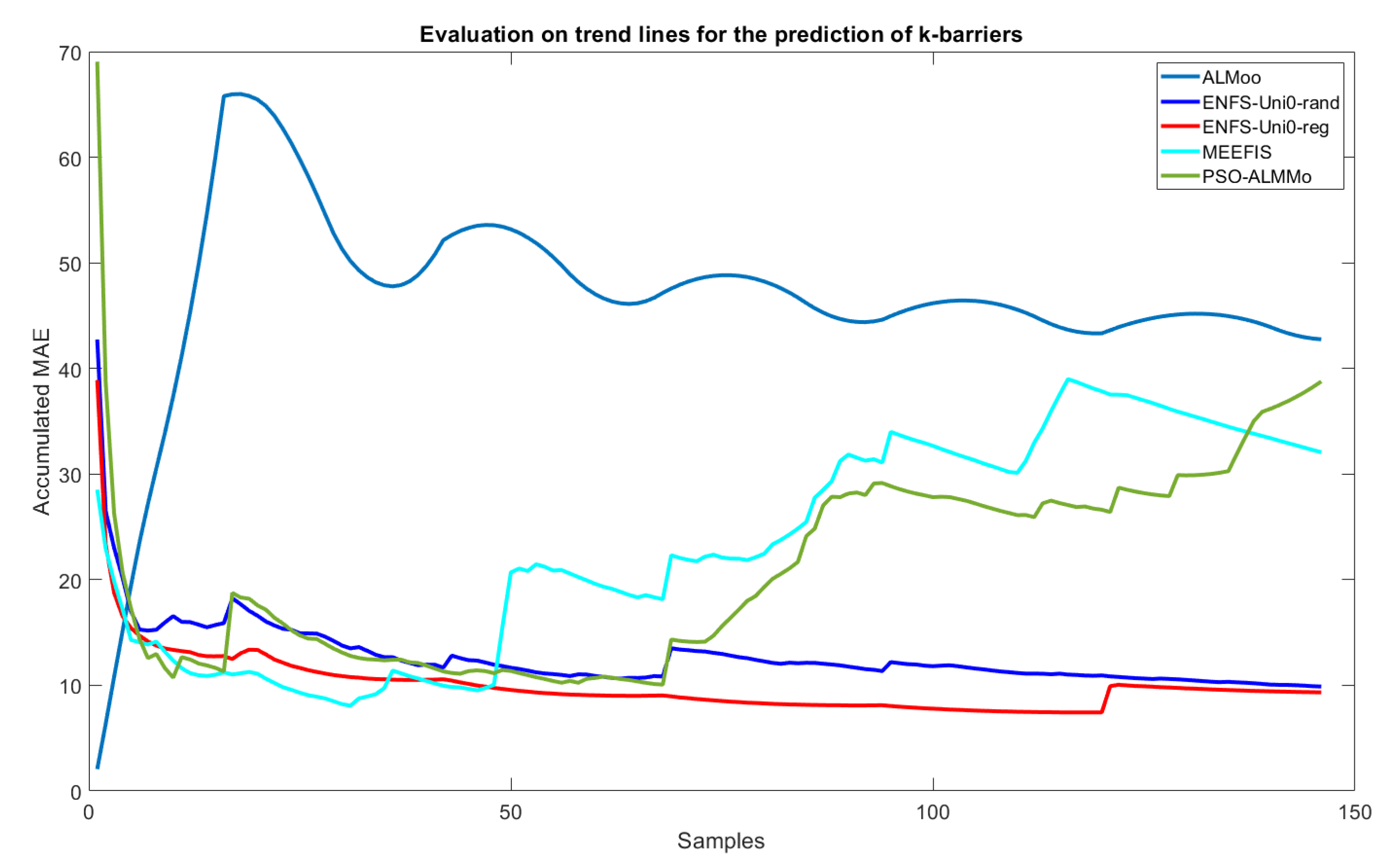
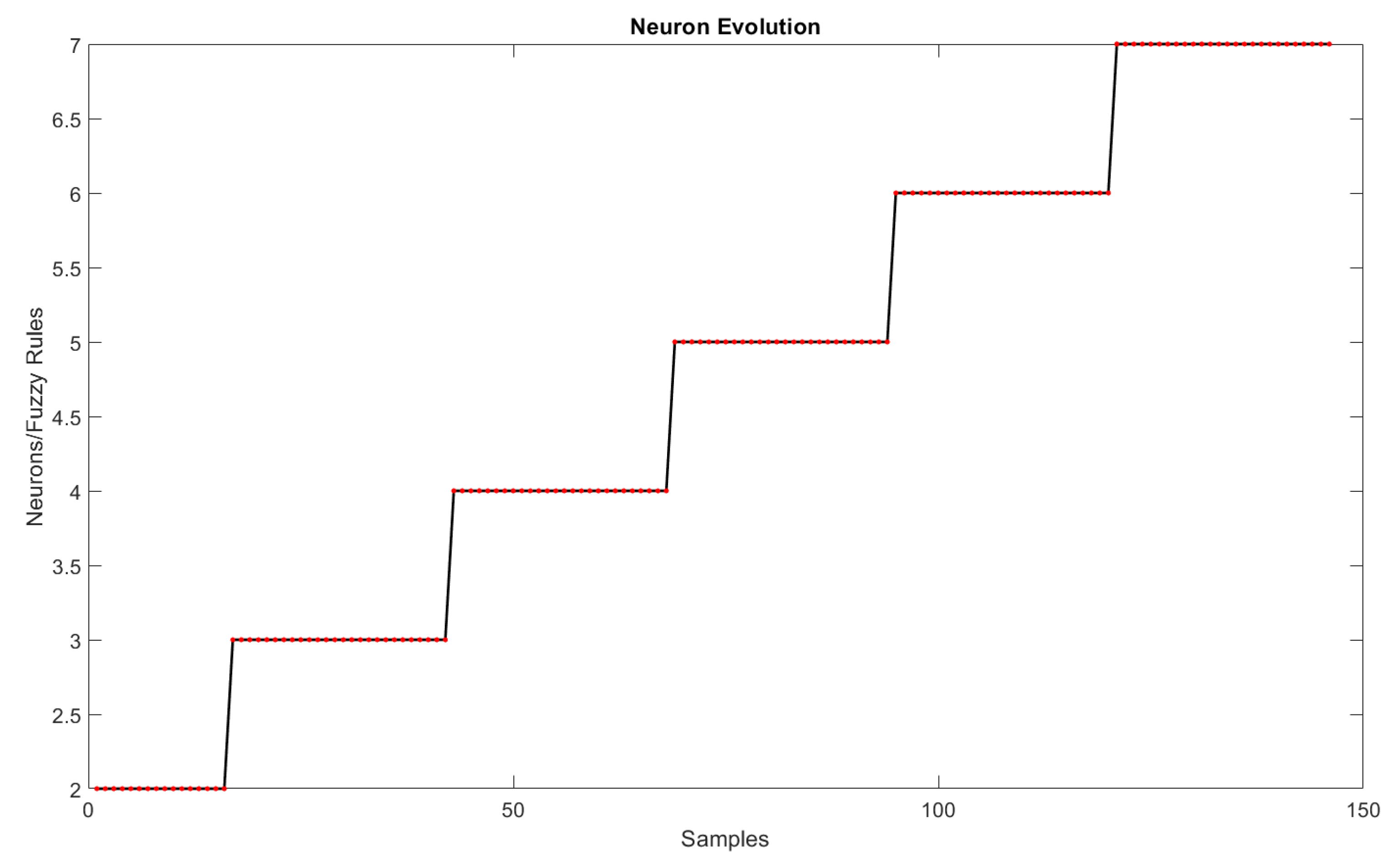
6.1. Model Efficiency
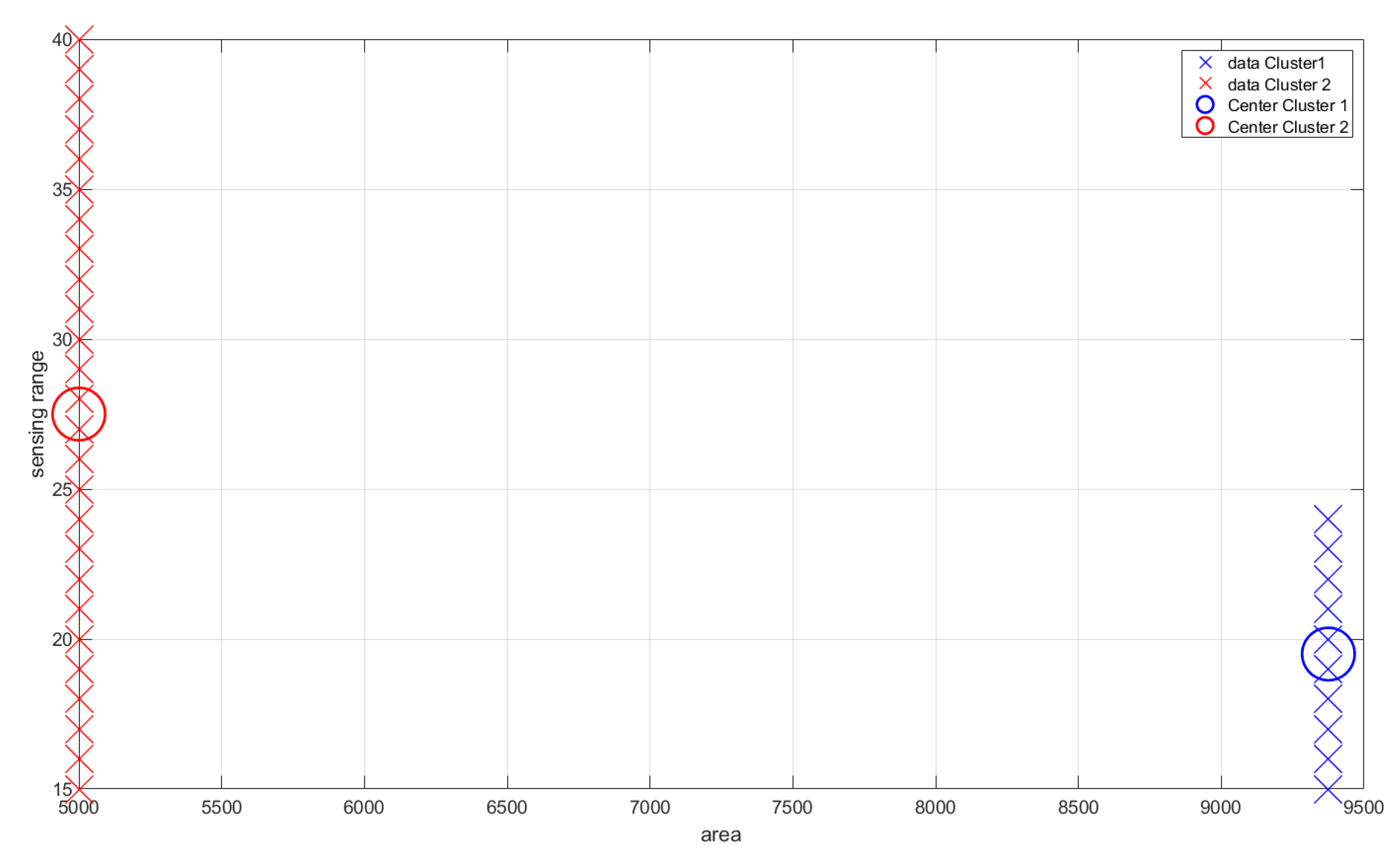
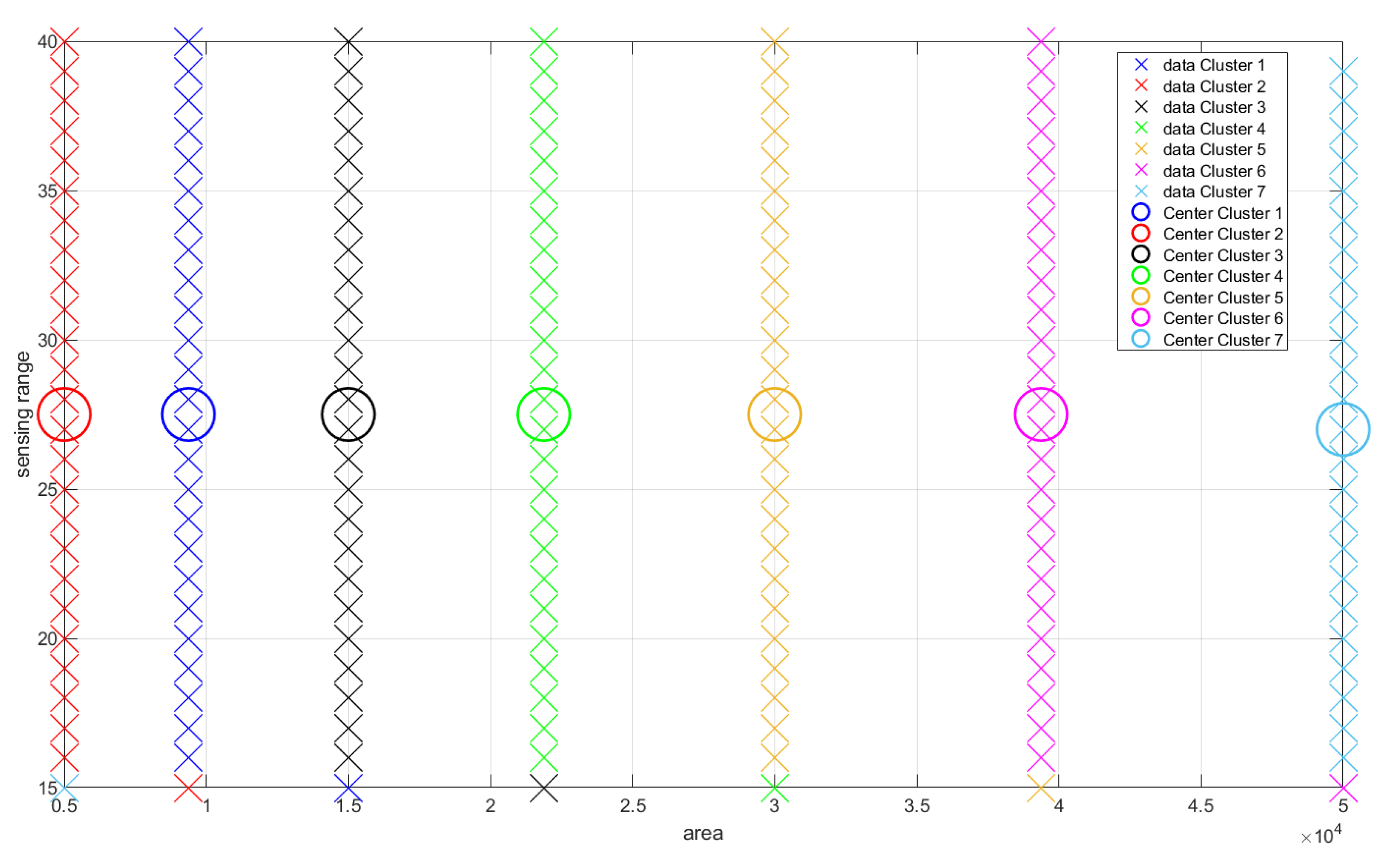
6.2. Distinguishability and Simplicity
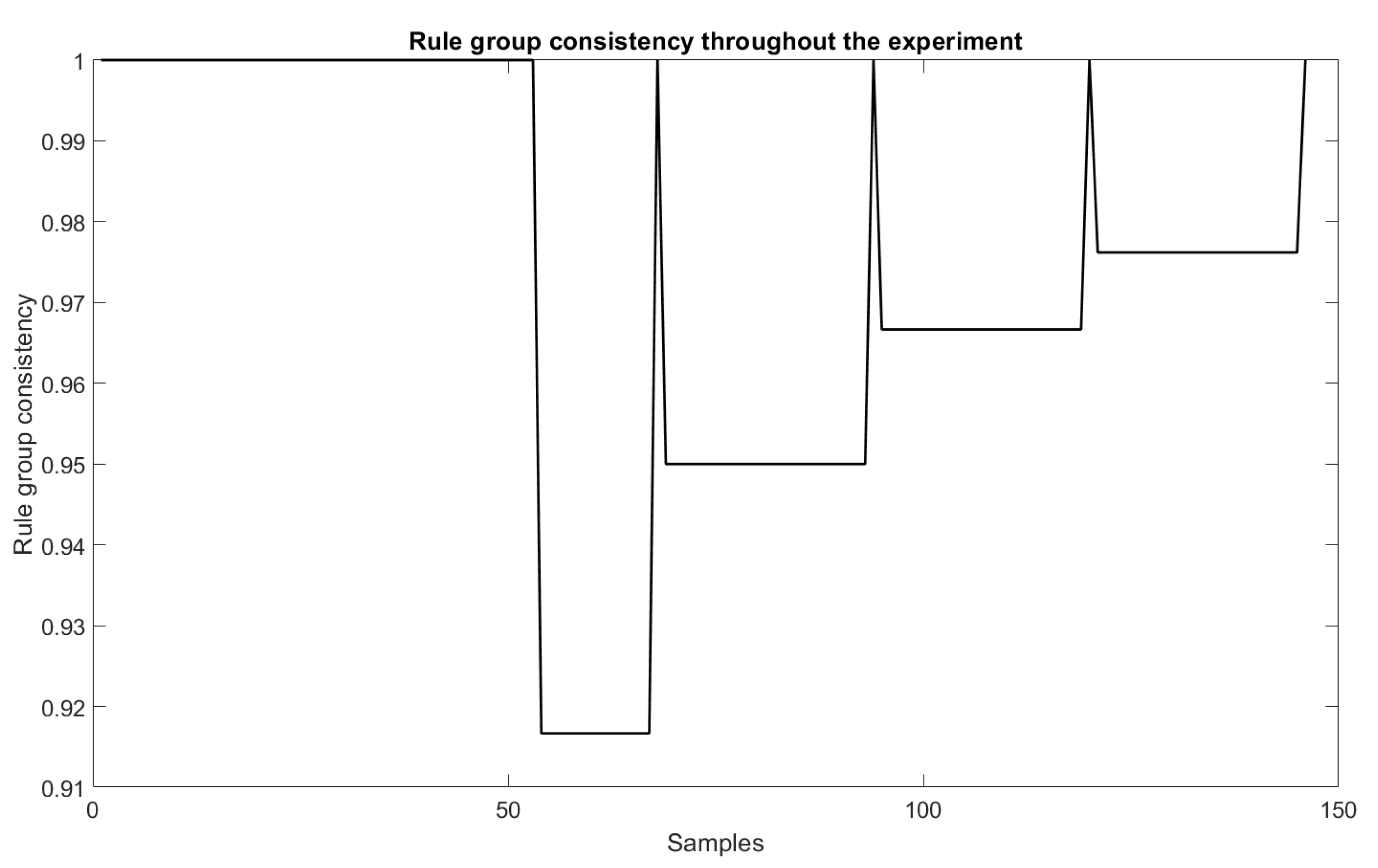
6.3. Consistency
6.4. Feature Importance Levels
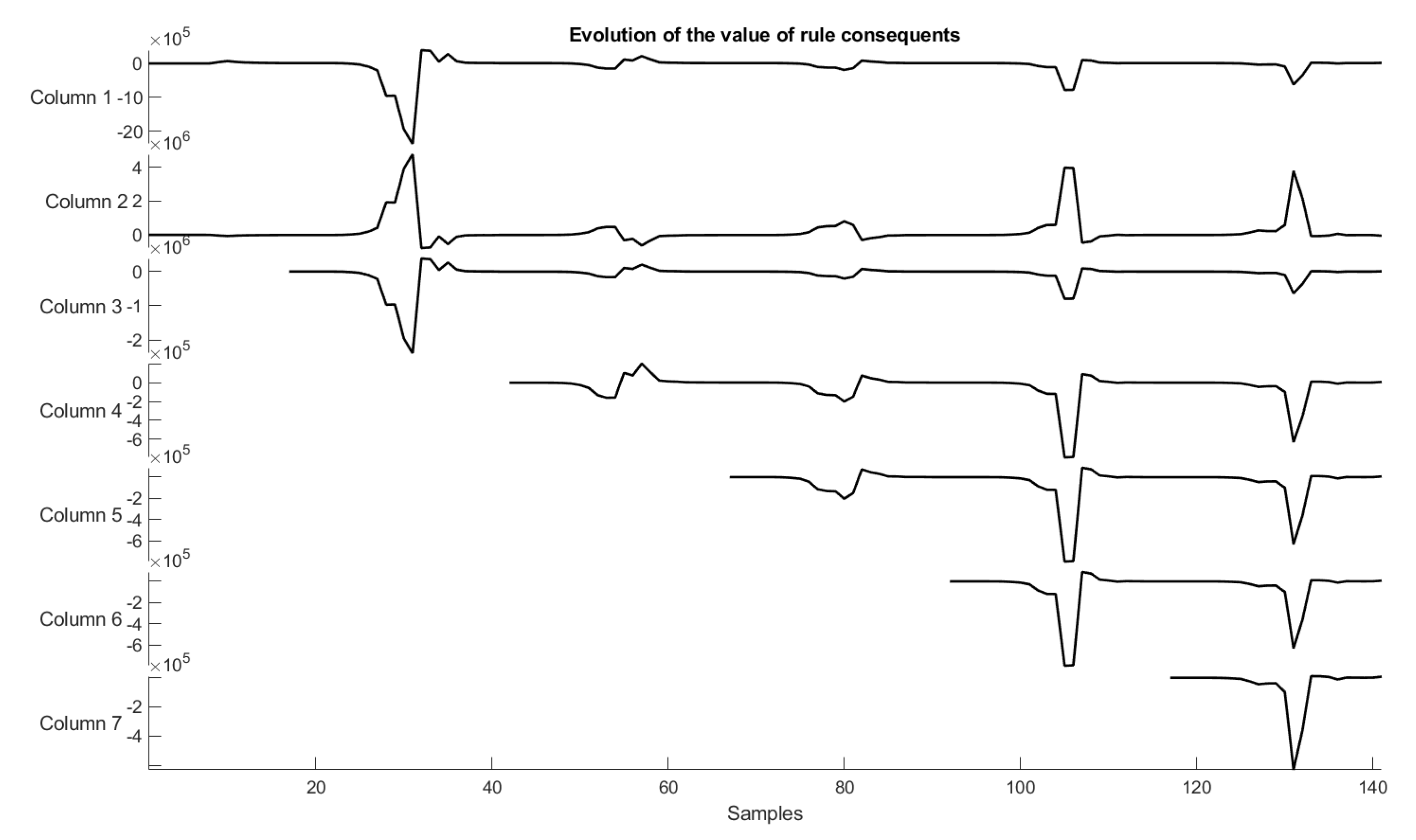
6.5. Interpretation of Consequents
6.6. Knowledge Expansion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ENFS-Uni0-reg | Evolving neuro-fuzzy system based on logic neurons for regression problems. |
| ENFS-Uni0 | Evolving neuro-fuzzy system based on logic neurons. |
| EFNNs | Evolving fuzzy neural networks |
| EFS | Evolving fuzzy systems |
| FWSCR | Feature weight separability criteria for regression problems. |
| RMSE | Root mean square error. |
| MAE | Mean absolute error. |
| MEEFIS | Multilayer ensemble evolving fuzzy inference system. |
| EFISs | Evolving fuzzy inference systems. |
| ALMMo | Autonomous zero-order multiple learning. |
| PSO-ALMMo | Version of autonomous zero-order multiple learning with particle |
| swarm optimization. | |
| PSO | Particle swarm optimization. |
| RWLS | Recursive weight least squares. |
| AutoML | Automated machine learning. |
| LOFO | Leave-one-feature-out. |
Appendix A

References
- Lin, C.T.; Lee, C.G.; Lin, C.T.; Lin, C. Neural Fuzzy Systems: A Neuro-Fuzzy Synergism to Intelligent Systems; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1996; Volume 205. [Google Scholar]
- De Campos Souza, P.V. Fuzzy neural networks and neuro-fuzzy networks: A review the main techniques and applications used in the literature. Appl. Soft Comput. 2020, 92, 106275. [Google Scholar] [CrossRef]
- Škrjanc, I.; Iglesias, J.A.; Sanchis, A.; Leite, D.; Lughofer, E.; Gomide, F. Evolving fuzzy and neuro-fuzzy approaches in clustering, regression, identification, and classification: A Survey. Inf. Sci. 2019, 490, 344–368. [Google Scholar] [CrossRef]
- Pedrycz, W.; Gomide, F. Fuzzy Systems Engineering: Toward Human-Centric Computing; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Lughofer, E. Evolving Fuzzy Systems—Fundamentals, Reliability, Interpretability and Useability. In Handbook of Computational Intelligence; Angelov, P., Ed.; World Scientific: New York, NY, USA, 2016; pp. 67–135. [Google Scholar]
- Mostafaei, H.; Chowdhury, M.U.; Obaidat, M.S. Border surveillance with WSN systems in a distributed manner. IEEE Syst. J. 2018, 12, 3703–3712. [Google Scholar] [CrossRef]
- Mostafaei, H.; Menth, M. Software-defined wireless sensor networks: A survey. J. Netw. Comput. Appl. 2018, 119, 42–56. [Google Scholar] [CrossRef]
- De Campos Souza, P.V.; Lughofer, E. An evolving neuro-fuzzy system based on uni-nullneurons with advanced interpretability capabilities. Neurocomputing 2021, 451, 231–251. [Google Scholar] [CrossRef]
- Souza, P.; Ponce, H.; Lughofer, E. Evolving fuzzy neural hydrocarbon networks: A model based on organic compounds. Knowl.-Based Syst. 2020, 203, 106099. [Google Scholar] [CrossRef]
- Leite, D.; Costa, P.; Gomide, F. Evolving granular neural networks from fuzzy data streams. Neural Netw. 2013, 38, 1–16. [Google Scholar] [CrossRef]
- Silva, A.M.; Caminhas, W.; Lemos, A.; Gomide, F. A fast learning algorithm for evolving neo-fuzzy neuron. Appl. Soft Comput. 2014, 14, 194–209. [Google Scholar] [CrossRef]
- Lughofer, E. On-line assurance of interpretability criteria in evolving fuzzy systems—Achievements, new concepts and open issues. Inf. Sci. 2013, 251, 22–46. [Google Scholar] [CrossRef]
- Anders, T. Territorial control in civil wars: Theory and measurement using machine learning. J. Peace Res. 2020, 57, 701–714. [Google Scholar] [CrossRef]
- Singh, A.; Amutha, J.; Nagar, J.; Sharma, S.; Lee, C.C. AutoML-ID: Automated machine learning model for intrusion detection using wireless sensor network. Sci. Rep. 2022, 12, 9074. [Google Scholar] [CrossRef] [PubMed]
- Xu, P.; Wu, J.; Shang, C.; Chang, C.Y. GSMS: A Barrier Coverage Algorithm for Joint Surveillance Quality and Network Lifetime in WSNs. IEEE Access 2019, 7, 159608–159621. [Google Scholar] [CrossRef]
- Fan, F.; Ji, Q.; Wu, G.; Wang, M.; Ye, X.; Mei, Q. Dynamic barrier coverage in a wireless sensor network for smart grids. Sensors 2018, 19, 41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amutha, J.; Sharma, S.; Nagar, J. WSN strategies based on sensors, deployment, sensing models, coverage and energy efficiency: Review, approaches and open issues. Wirel. Pers. Commun. 2020, 111, 1089–1115. [Google Scholar] [CrossRef]
- Singh, A.; Nagar, J.; Sharma, S.; Kotiyal, V. A Gaussian process regression approach to predict the k-barrier coverage probability for intrusion detection in wireless sensor networks. Expert Syst. Appl. 2021, 172, 114603. [Google Scholar] [CrossRef]
- Nagar, J.; Sharma, S. k-Barrier coverage-based intrusion detection for wireless sensor networks. In Cyber Security; Springer: Berlin/Heidelberg, Germany, 2018; pp. 373–385. [Google Scholar]
- Sharma, S.; Nagar, J. Intrusion detection in mobile sensor networks: A case study for different intrusion paths. Wirel. Pers. Commun. 2020, 115, 2569–2589. [Google Scholar] [CrossRef]
- Rajesh, S.; Sangeetha, M. Intrusion Detection In Wsn Using Modified AODV Algorithm. In Proceedings of the I3CAC 2021: Proceedings of the First International Conference on Computing, Communication and Control System, I3CAC 2021, Chennai, India, 7–8 June 2021; European Alliance for Innovation: Ghent, Belgium, 2021; p. 182. [Google Scholar]
- Lughofer, E. Evolving Fuzzy Systems—Methodologies, Advanced Concepts and Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Bordignon, F.; Gomide, F. Uninorm based evolving neural networks and approximation capabilities. Neurocomputing 2014, 127, 13–20. [Google Scholar] [CrossRef]
- Kasabov, N.K. On-line learning, reasoning, rule extraction and aggregation in locally optimized evolving fuzzy neural networks. Neurocomputing 2001, 41, 25–45. [Google Scholar] [CrossRef]
- Kasabov, N. Evolving fuzzy neural networks for supervised/unsupervised online knowledge-based learning. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2001, 31, 902–918. [Google Scholar] [CrossRef]
- Malcangi, M.; Nano, G. Biofeedback: E-health prediction based on evolving fuzzy neural network and wearable technologies. Evol. Syst. 2021, 12, 645–653. [Google Scholar] [CrossRef]
- Tang, J.; Zou, Y.; Ash, J.; Zhang, S.; Liu, F.; Wang, Y. Travel time estimation using freeway point detector data based on evolving fuzzy neural inference system. PLoS ONE 2016, 11, e0147263. [Google Scholar] [CrossRef] [PubMed]
- Hernández, J.A.M.; Castaneda, F.G.; Cadenas, J.A.M. An evolving fuzzy neural network based on the mapping of similarities. IEEE Trans. Fuzzy Syst. 2009, 17, 1379–1396. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning. 2020. Available online: https://christophm.github.io/interpretable-ml-book (accessed on 28 June 2022).
- Schaffer, C. Overfitting Avoidance as Bias. Mach. Learn. 1993, 10, 153–178. [Google Scholar] [CrossRef] [Green Version]
- Lughofer, E.; Bouchot, J.L.; Shaker, A. On-line Elimination of Local Redundancies in Evolving Fuzzy Systems. Evol. Syst. 2011, 2, 165–187. [Google Scholar] [CrossRef]
- Gacto, M.; Alcala, R.; Herrera, F. Interpretability of Linguistic Fuzzy Rule-Based Systems: An Overview of Interpretability Measures. Inf. Sci. 2011, 181, 4340–4360. [Google Scholar] [CrossRef]
- Gu, X.; Angelov, P.P.; Príncipe, J.C. A method for autonomous data partitioning. Inf. Sci. 2018, 460, 65–82. [Google Scholar] [CrossRef] [Green Version]
- Angelov, P.; Gu, X.; Kangin, D. Empirical data analytics. Int. J. Intell. Syst. 2017, 32, 1261–1284. [Google Scholar] [CrossRef]
- De Campos Souza, P.V.; Lughofer, E.; Guimaraes, A.J. An interpretable evolving fuzzy neural network based on self-organized direction-aware data partitioning and fuzzy logic neurons. Appl. Soft Comput. 2021, 112, 107829. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Albert, A. Regression and the Moore-Penrose Pseudoinverse; Elsevier: Amsterdam, The Netherlands, 1972. [Google Scholar]
- Huang, G.B.; Chen, L.; Siew, C.K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef] [Green Version]
- Ludl, M.C.; Widmer, G. Relative unsupervised discretization for regression problems. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2000; pp. 246–254. [Google Scholar]
- Salman, R.; Kecman, V. Regression as classification. In Proceedings of the 2012 Proceedings of IEEE Southeastcon, Orlando, FL, USA, 15–18 March 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Torgo, L.; Gama, J. Regression by classification. In Brazilian Symposium on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 1996; pp. 51–60. [Google Scholar]
- Lughofer, E. On-line incremental feature weighting in evolving fuzzy classifiers. Fuzzy Sets Syst. 2011, 163, 1–23. [Google Scholar] [CrossRef]
- Finch, T. Incremental calculation of weighted mean and variance. Univ. Camb. 2009, 4, 41–42. [Google Scholar]
- Qin, S.; Li, W.; Yue, H. Recursive PCA for Adaptive Process Monitoring. J. Process Control 2000, 10, 471–486. [Google Scholar]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive Online Analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]
- Singh, A.; Amutha, J.; Nagar, J.; Sharma, S.; Lee, C.C. LT-FS-ID: Log-Transformed Feature Learning and Feature-Scaling-Based Machine Learning Algorithms to Predict the k-Barriers for Intrusion Detection Using Wireless Sensor Network. Sensors 2022, 22, 1070. [Google Scholar] [CrossRef]
- Gu, X. Multilayer Ensemble Evolving Fuzzy Inference System. IEEE Trans. Fuzzy Syst. 2021, 29, 2425–2431. [Google Scholar] [CrossRef]
- Angelov, P.P.; Gu, X.; Príncipe, J.C. Autonomous Learning Multimodel Systems From Data Streams. IEEE Trans. Fuzzy Syst. 2018, 26, 2213–2224. [Google Scholar] [CrossRef] [Green Version]
- Gu, X.; Shen, Q.; Angelov, P.P. Particle Swarm Optimized Autonomous Learning Fuzzy System. IEEE Trans. Cybern. 2021, 51, 5352–5363. [Google Scholar] [CrossRef] [PubMed] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Mean | Standard Deviation | Maximum | Minimum |
|---|---|---|---|---|
| area | 24,375.00 | 15,197.25 | 50,000.00 | 5000.00 |
| sensing range | 27.50 | 7.52 | 40.00 | 15.00 |
| transmission range | 55.00 | 15.04 | 80.00 | 30.00 |
| number of sensor nodes | 250.00 | 90.24 | 400.00 | 100.00 |
| number of barriers | 94.07 | 65.17 | 320.00 | 12.00 |
| Model | RMSE. |
|---|---|
| ENFS-Uni0-reg | 11.16 (2.21) |
| ENFS-Uni0 | 12.29 (4.81) |
| MEEFIS | 13.60 (3.91) |
| ALMMo | 27.05 (1.67) |
| PSO-ALMMo | 24.27 (5.07) |
| Fuzzy Rule | v | v Standardized |
|---|---|---|
| 1 | 15,937.14 | 0.6996 |
| 2 | −51,137.92 | −2.2412 |
| 3 | 5260.04 | 0.2314 |
| 4 | 8603.60 | 0.3780 |
| 5 | 6352.77 | 0.2794 |
| 6 | 7258.79 | 0.3191 |
| 7 | 7593.08 | 0.3337 |
| Rule 1 did not change. |
| Rule 2 did not change. |
| Rule 3 changed with one membership function, changing the rule consequent from positive to negative. |
| Rule 4 changed with one membership function, changing the rule consequent from positive to negative. |
| Rule 5 changed with one membership function, changing the rule consequent from positive to negative. |
| Rule 6 changed with one membership function, changing the rule consequent from negative to positive. |
| Rule 7 changed with one membership function, changing the rule consequent from positive to negative. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Campos Souza, P.V.; Lughofer, E.; Rodrigues Batista, H. An Explainable Evolving Fuzzy Neural Network to Predict the k Barriers for Intrusion Detection Using a Wireless Sensor Network. Sensors 2022, 22, 5446. https://doi.org/10.3390/s22145446
de Campos Souza PV, Lughofer E, Rodrigues Batista H. An Explainable Evolving Fuzzy Neural Network to Predict the k Barriers for Intrusion Detection Using a Wireless Sensor Network. Sensors. 2022; 22(14):5446. https://doi.org/10.3390/s22145446
Chicago/Turabian Stylede Campos Souza, Paulo Vitor, Edwin Lughofer, and Huoston Rodrigues Batista. 2022. "An Explainable Evolving Fuzzy Neural Network to Predict the k Barriers for Intrusion Detection Using a Wireless Sensor Network" Sensors 22, no. 14: 5446. https://doi.org/10.3390/s22145446
APA Stylede Campos Souza, P. V., Lughofer, E., & Rodrigues Batista, H. (2022). An Explainable Evolving Fuzzy Neural Network to Predict the k Barriers for Intrusion Detection Using a Wireless Sensor Network. Sensors, 22(14), 5446. https://doi.org/10.3390/s22145446