
SMaTE: A Segment-Level Feature Mixing and Temporal Encoding Framework for Facial Expression Recognition


Abstract
:1. Introduction
- A new framework referred to as SMaTE is proposed for facial expression recognition based on the video vision transformer model.
- Data augmentation and feature extraction were performed, with the aim being for the model to learn useful representations of FER more effectively. Various data enhancements were decomposed into patch units and converted into token sequence through linear projection. Subsequently, these were randomly aggregated into one token architecture and thus improved the modeling of FER.
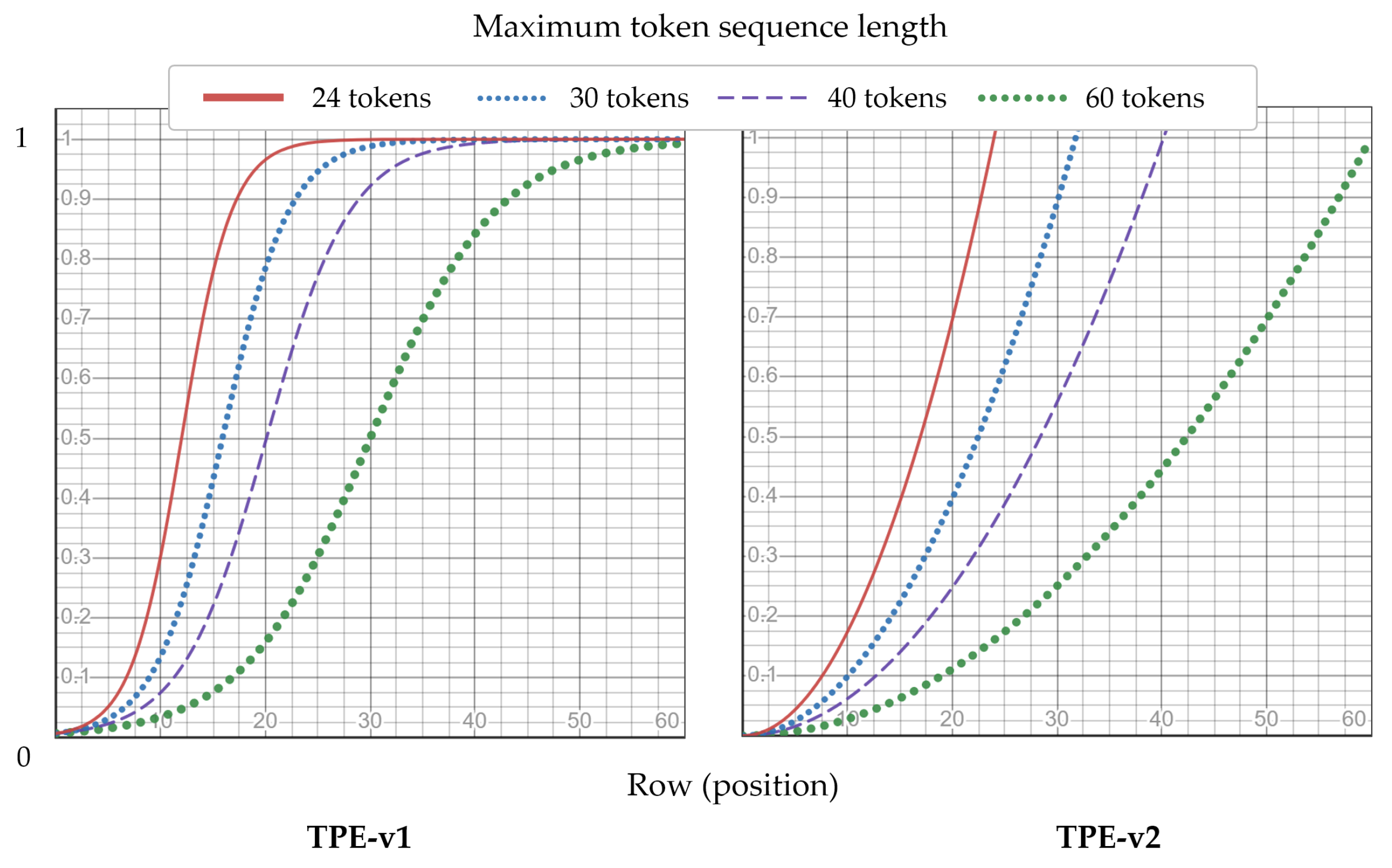
- Temporal position encoding is proposed for FER instead of the learned position embedding used in the existing work [42]. This encourages increase in the interaction between data and position encoding in temporal transformer encoder. This study shows that the proposed encoding methods outperform existing position embeddings on the Extended Cohn–Kanade (CK+) and AFEW.
- The proposed framework was demonstrated to be the best choice for improving FER performance with only a few adjustments of pure-transformer architectures [42] through ablation analysis of the position encodings, data augmentation and feature extraction methods, tokenization strategies, and a model architecture.
2. Related Works
3. Proposed Methods
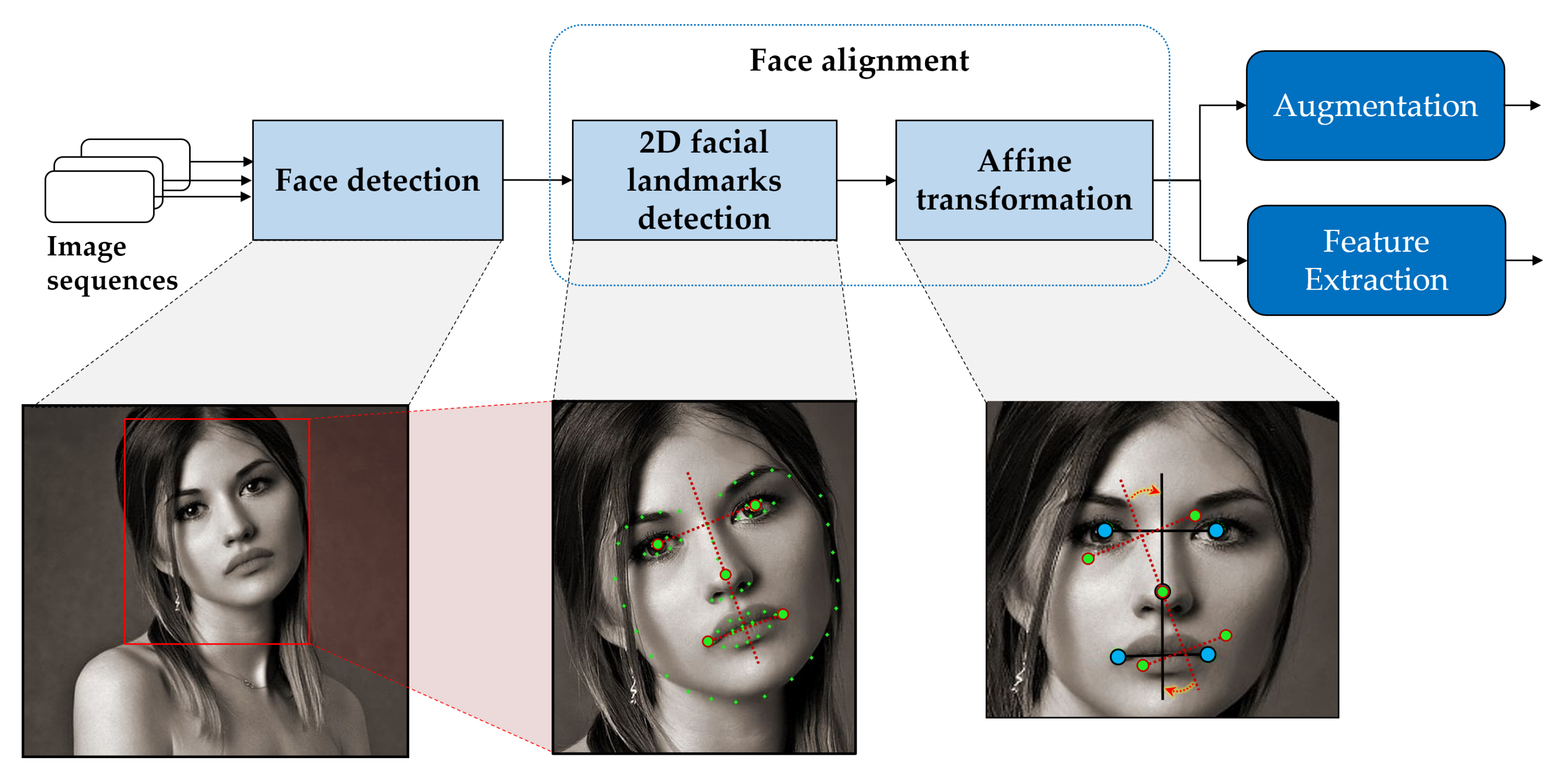
3.1. Preprocessing for FER
3.1.1. Face Preprocessing
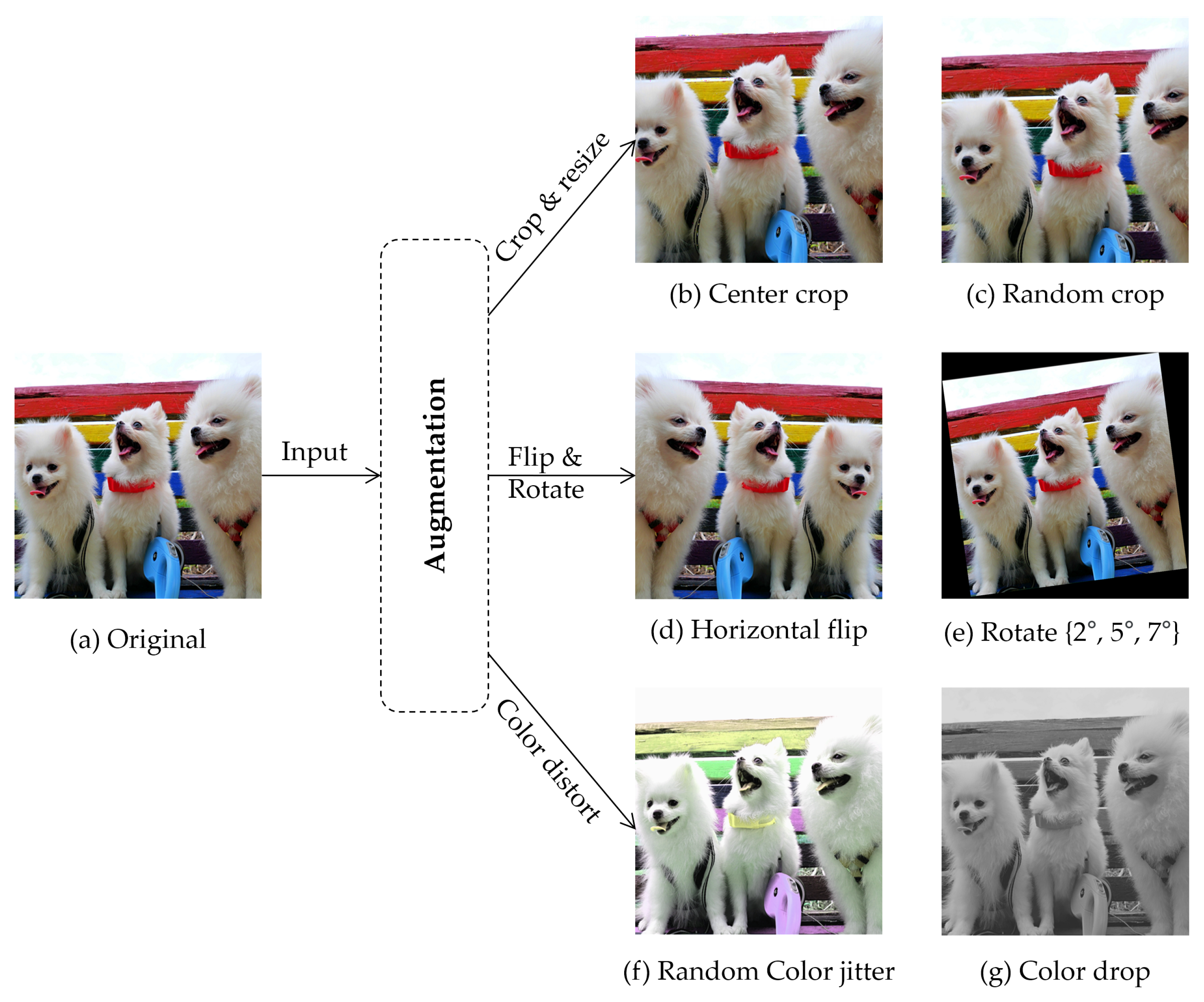
3.1.2. Data Augmentation
3.1.3. Feature Extraction
3.2. Model for Facial Expression Recognition
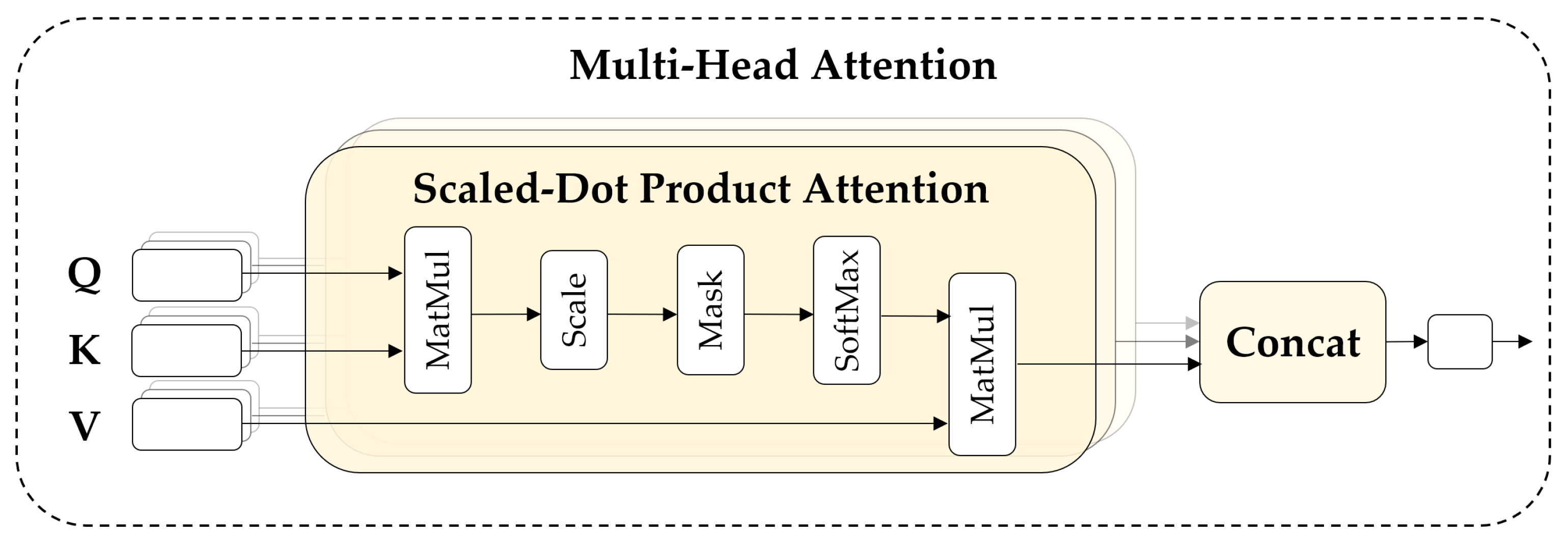
3.2.1. Overview of Vision Transformer
3.2.2. Token Embeddings
3.2.3. Positional Embeddings
3.2.4. Model Architecture
4. Results
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Performance Metrics
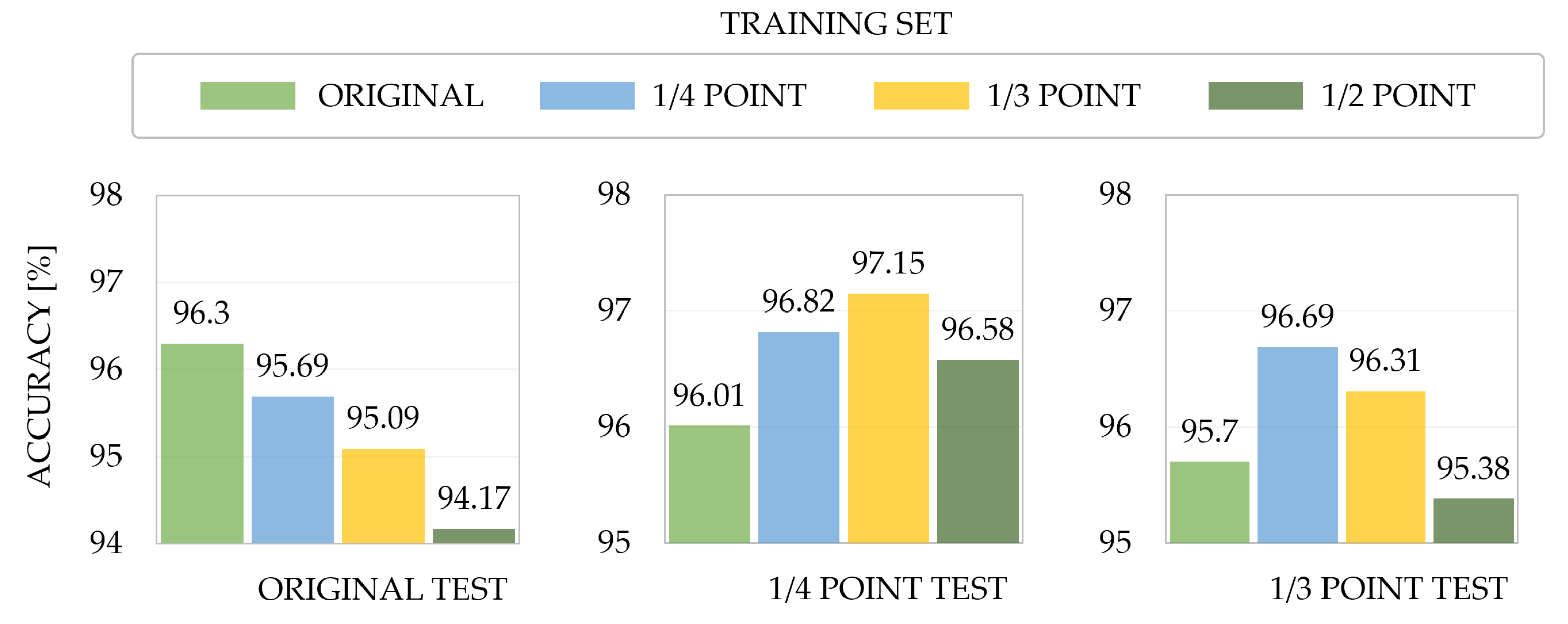
4.2. Ablation Study
4.3. Comparison with State-of-the-Art
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AFEW | Acted Facial Expressions in the Wild |
| BERT | Bidirectional encoder representations from transformers |
| CK+ | Extended Cohn–Kanade |
| CNN | Convolutional neural networks |
| FE | Factorized encoder |
| FER | Facial expression recognition |
| HCI | Human–computer interactions |
| LBP | Local binary patterns |
| RNN | Recurrent neural networks |
| SER | Speech emotion recognition |
| SMaTE | Segment-level feature mixing and temporal encoding |
| STE | Spatial transformer encoder |
| TPE | Temporal positional encoding |
| TTE | Temporal transformer encoder |
| ViT | Vision transformer |
| ViViT | Video vision transformer |
References
- Ekman, P. Basic emotions. Handb. Cogn. Emot. 1999, 98, 16. [Google Scholar]
- Cohen, I.; Sebe, N.; Garg, A.; Chen, L.S.; Huang, T.S. Facial expression recognition from video sequences: Temporal and static modeling. Comput. Vis. Image Underst. 2003, 91, 160–187. [Google Scholar] [CrossRef] [Green Version]
- Chibelushi, C.C.; Bourel, F. Facial Expression Recognition: A Brief Tutorial Overview. CVonline: On-Line Compendium of Computer Vision. 2003, Volume 9. Available online: https://s2.smu.edu/~mhd/8331f06/CCC.pdf (accessed on 2 May 2022).
- Den Uyl, M.; Van Kuilenburg, H. The FaceReader: Online facial expression recognition. In Proceedings of the Measuring Behavior, Wageningen, The Netherlands, 30 August–2 September 2005; Volume 30, pp. 589–590. [Google Scholar]
- Liu, S.S.; Tian, Y.T.; Li, D. New research advances of facial expression recognition. In Proceedings of the 2009 International Conference on Machine Learning and Cybernetics, Baoding, China, 12–15 July 2009; Volume 2, pp. 1150–1155. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef] [Green Version]
- Sarode, N.; Bhatia, S. Facial expression recognition. Int. J. Comput. Sci. Eng. 2010, 2, 1552–1557. [Google Scholar]
- Insaf, A.; Ouahabi, A.; Benzaoui, A.; Taleb Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Schuller, B.; Rigoll, G.; Lang, M. Hidden Markov model-based speech emotion recognition. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Baltimore, MD, USA, 6–9 July 2003; Volume 2, p. II-1. [Google Scholar]
- Nwe, T.L.; Foo, S.W.; De Silva, L.C. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar] [CrossRef]
- Schuller, B.; Rigoll, G.; Lang, M. Speech emotion recognition combining acoustic features and linguistic information in a hybrid support vector machine-belief network architecture. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, p. I-577. [Google Scholar]
- Lin, Y.L.; Wei, G. Speech emotion recognition based on HMM and SVM. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 8, pp. 4898–4901. [Google Scholar]
- Hu, H.; Xu, M.X.; Wu, W. GMM supervector based SVM with spectral features for speech emotion recognition. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 4, p. IV-413. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Happy, S.; Routray, A. Automatic facial expression recognition using features of salient facial patches. IEEE Trans. Affect. Comput. 2014, 6, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Yu, Z.; Zhang, C. Image based static facial expression recognition with multiple deep network learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 435–442. [Google Scholar]
- Lee, J.R.; Wang, L.; Wong, A. Emotionnet nano: An efficient deep convolutional neural network design for real-time facial expression recognition. Front. Artif. Intell. 2021, 3, 609673. [Google Scholar] [CrossRef] [PubMed]
- El Morabit, S.; Rivenq, A.; Zighem, M.E.n.; Hadid, A.; Ouahabi, A.; Taleb-Ahmed, A. Automatic Pain Estimation from Facial Expressions: A Comparative Analysis Using Off-the-Shelf CNN Architectures. Electronics 2021, 10, 1926. [Google Scholar] [CrossRef]
- Khalil, R.A.; Jones, E.; Babar, M.I.; Jan, T.; Zafar, M.H.; Alhussain, T. Speech emotion recognition using deep learning techniques: A review. IEEE Access 2019, 7, 117327–117345. [Google Scholar] [CrossRef]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar]
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; PietikäInen, M. Facial expression recognition from near-infrared videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Z.; Chi, Z.; Fu, H. Facial expression recognition in video with multiple feature fusion. IEEE Trans. Affect. Comput. 2016, 9, 38–50. [Google Scholar] [CrossRef]
- Sun, M.; Li, J.; Feng, H.; Gou, W.; Shen, H.; Tang, J.; Yang, Y.; Ye, J. Multi-Modal Fusion Using Spatio-Temporal and Static Features for Group Emotion Recognition. In Proceedings of the 2020 International Conference on Multimodal Interaction, Virtual Event, 25–29 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 835–840. [Google Scholar]
- Dhall, A.; Sharma, G.; Goecke, R.; Gedeon, T. Emotiw 2020: Driver gaze, group emotion, student engagement and physiological signal based challenges. In Proceedings of the 2020 International Conference on Multimodal Interaction, New York, NY, USA, 25–29 October 2020; pp. 784–789. [Google Scholar]
- Liu, C.; Jiang, W.; Wang, M.; Tang, T. Group Level Audio-Video Emotion Recognition Using Hybrid Networks. In Group Level Audio-Video Emotion Recognition Using Hybrid Networks; Association for Computing Machinery: New York, NY, USA, 2020; pp. 807–812. [Google Scholar]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar]
- Dhall, A.; Goecke, R.; Joshi, J.; Hoey, J.; Gedeon, T. Emotiw 2016: Video and group-level emotion recognition challenges. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 427–432. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Acted Facial Expressions in the Wild Database; Technical Report TR-CS-11; Australian National University: Canberra, Australia, 2011; Volume 2, p. 1. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting large, richly annotated facial-expression databases from movies. IEEE Multimed. 2012, 19, 34–41. [Google Scholar] [CrossRef] [Green Version]
- Bargal, S.A.; Barsoum, E.; Ferrer, C.C.; Zhang, C. Emotion recognition in the wild from videos using images. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 433–436. [Google Scholar]
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial expression recognition: A survey. Symmetry 2019, 11, 1189. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://dl.acm.org/doi/10.5555/3295222.3295349 (accessed on 27 July 2022).
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6836–6846. [Google Scholar]
- Kanade, T.; Cohn, J.F.; Tian, Y. Comprehensive database for facial expression analysis. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat. No. PR00580), Grenoble, France, 28–30 March 2000; pp. 46–53. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Saba, T. Computer vision for microscopic skin cancer diagnosis using handcrafted and non-handcrafted features. Microsc. Res. Tech. 2021, 84, 1272–1283. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, S. Dermatoscopy using multi-layer perceptron, convolution neural network, and capsule network to differentiate malignant melanoma from benign nevus. Int. J. Healthc. Inf. Syst. Inform. (IJHISI) 2021, 16, 58–73. [Google Scholar] [CrossRef]
- Zheng, H.; Geng, X.; Tao, D.; Jin, Z. A multi-task model for simultaneous face identification and facial expression recognition. Neurocomputing 2016, 171, 515–523. [Google Scholar] [CrossRef]
- Rassadin, A.; Gruzdev, A.; Savchenko, A. Group-level emotion recognition using transfer learning from face identification. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 544–548. [Google Scholar]
- Vu, M.T.; Beurton-Aimar, M.; Marchand, S. Multitask multi-database emotion recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3637–3644. [Google Scholar]
- Chang, X.; Skarbek, W. From face identification to emotion recognition. In Proceedings of the Photonics Applications in Astronomy, Communications, Industry, and High-Energy Physics Experiments 2019, International Society for Optics and Photonics, Wilga, Poland, 25 May–2 June 2019; Volume 11176, p. 111760K. [Google Scholar]
- Lee, J.; Kim, S.; Kim, S.; Park, J.; Sohn, K. Context-Aware Emotion Recognition Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Mittal, T.; Guhan, P.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. EmotiCon: Context-Aware Multimodal Emotion Recognition Using Frege’s Principle. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yu, Z.; Liu, G.; Liu, Q.; Deng, J. Spatio-temporal convolutional features with nested LSTM for facial expression recognition. Neurocomputing 2018, 317, 50–57. [Google Scholar] [CrossRef]
- Breuer, R.; Kimmel, R. A deep learning perspective on the origin of facial expressions. arXiv 2017, arXiv:1705.01842. [Google Scholar]
- Ko, B.C. A brief review of facial emotion recognition based on visual information. Sensors 2018, 18, 401. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Lam, J.C.; Li, V.O. Multi-region ensemble convolutional neural network for facial expression recognition. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 84–94. [Google Scholar]
- Kayhan, O.S.; Gemert, J.C.V. On translation invariance in cnns: Convolutional layers can exploit absolute spatial location. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14274–14285. [Google Scholar]
- Kondor, R.; Trivedi, S. On the generalization of equivariance and convolution in neural networks to the action of compact groups. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2747–2755. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Gendron, M.; Roberson, D.; van der Vyver, J.M.; Barrett, L.F. Perceptions of emotion from facial expressions are not culturally universal: Evidence from a remote culture. Emotion 2014, 14, 251. [Google Scholar] [CrossRef] [PubMed]
- Matsumoto, D. Cultural influences on facial expressions of emotion. South. J. Commun. 1991, 56, 128–137. [Google Scholar] [CrossRef]
- Mühlenbeck, C.; Pritsch, C.; Wartenburger, I.; Telkemeyer, S.; Liebal, K. Attentional Bias to Facial Expressions of Different Emotions—A Cross-Cultural Comparison of ≠Akhoe Hai||om and German Children and Adolescents. Front. Psychol. 2020, 11, 795. [Google Scholar] [CrossRef] [PubMed]
- Savchenko, A.V. Facial expression and attributes recognition based on multi-task learning of lightweight neural networks. In Proceedings of the 2021 IEEE 19th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 16–18 September 2021; pp. 119–124. [Google Scholar]
- He, Y.; Xu, D.; Wu, L.; Jian, M.; Xiang, S.; Pan, C. Lffd: A light and fast face detector for edge devices. arXiv 2019, arXiv:1904.10633. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. Wider face: A face detection benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5525–5533. [Google Scholar]
- Chen, C. PyTorch Face Landmark: A Fast and Accurate Facial Landmark Detector. 2021.
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual Event, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Park, S.J.; Kim, B.G.; Chilamkurti, N. A Robust Facial Expression Recognition Algorithm Based on Multi-Rate Feature Fusion Scheme. Sensors 2021, 21, 6954. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikäinen, M. Face recognition with local binary patterns. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 469–481. [Google Scholar]
- Liu, L.; Fieguth, P.; Zhao, G.; Pietikäinen, M.; Hu, D. Extended local binary patterns for face recognition. Inf. Sci. 2016, 358–359, 56–72. [Google Scholar] [CrossRef]
- Sun, B.; Li, L.; Zhou, G.; He, J. Facial expression recognition in the wild based on multimodal texture features. J. Electron. Imaging 2016, 25, 061407. [Google Scholar] [CrossRef] [Green Version]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef]
- Pourmirzaei, M.; Montazer, G.A.; Esmaili, F. Using Self-Supervised Auxiliary Tasks to Improve Fine-Grained Facial Representation. arXiv 2021, arXiv:2105.06421. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CK+ | AFEW | FLOPs () | Params () |
|---|---|---|---|---|
| ViViT-B/16 × 2 FE | 42.42 | 37.22 | 213.93 | 171.45 |
| Initialization | CK+ | AFEW |
|---|---|---|
| BERT | 42.42 | 34.99 |
| TPE-V1 | 43.18 | 36.66 |
| TPE-V2 | 43.93 | 39.44 |
| CK+ | AFEW | |
|---|---|---|
| Original | 42.42 | 34.99 |
| LBP | 54.95 | 37.22 |
| Crop, flip, rotate, color jitter | 91.97 | 38.33 |
| Mixed-token embedding | 98.39 | 38.88 |
| CK+ | AFEW | |
|---|---|---|
| Original | 43.93 | 37.22 |
| LBP | 63.35 | 39.71 |
| Crop, flip, rotate, color jitter | 95.38 | 40.83 |
| Mixed-token embedding | 99.19 | 41.38 |
| Crop Size | 64 | 128 | 224 | 320 |
|---|---|---|---|---|
| GFLOPs | 12.5 | 46.3 | 142.6 | 301.8 |
| Training speeds | 23.5 | 22.6 | 20.3 | 17.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, N.; Cho, S.; Bae, B. SMaTE: A Segment-Level Feature Mixing and Temporal Encoding Framework for Facial Expression Recognition. Sensors 2022, 22, 5753. https://doi.org/10.3390/s22155753
Kim N, Cho S, Bae B. SMaTE: A Segment-Level Feature Mixing and Temporal Encoding Framework for Facial Expression Recognition. Sensors. 2022; 22(15):5753. https://doi.org/10.3390/s22155753
Chicago/Turabian StyleKim, Nayeon, Sukhee Cho, and Byungjun Bae. 2022. "SMaTE: A Segment-Level Feature Mixing and Temporal Encoding Framework for Facial Expression Recognition" Sensors 22, no. 15: 5753. https://doi.org/10.3390/s22155753
APA StyleKim, N., Cho, S., & Bae, B. (2022). SMaTE: A Segment-Level Feature Mixing and Temporal Encoding Framework for Facial Expression Recognition. Sensors, 22(15), 5753. https://doi.org/10.3390/s22155753