
Methodology for Large-Scale Camera Positioning to Enable Intelligent Self-Configuration

Abstract
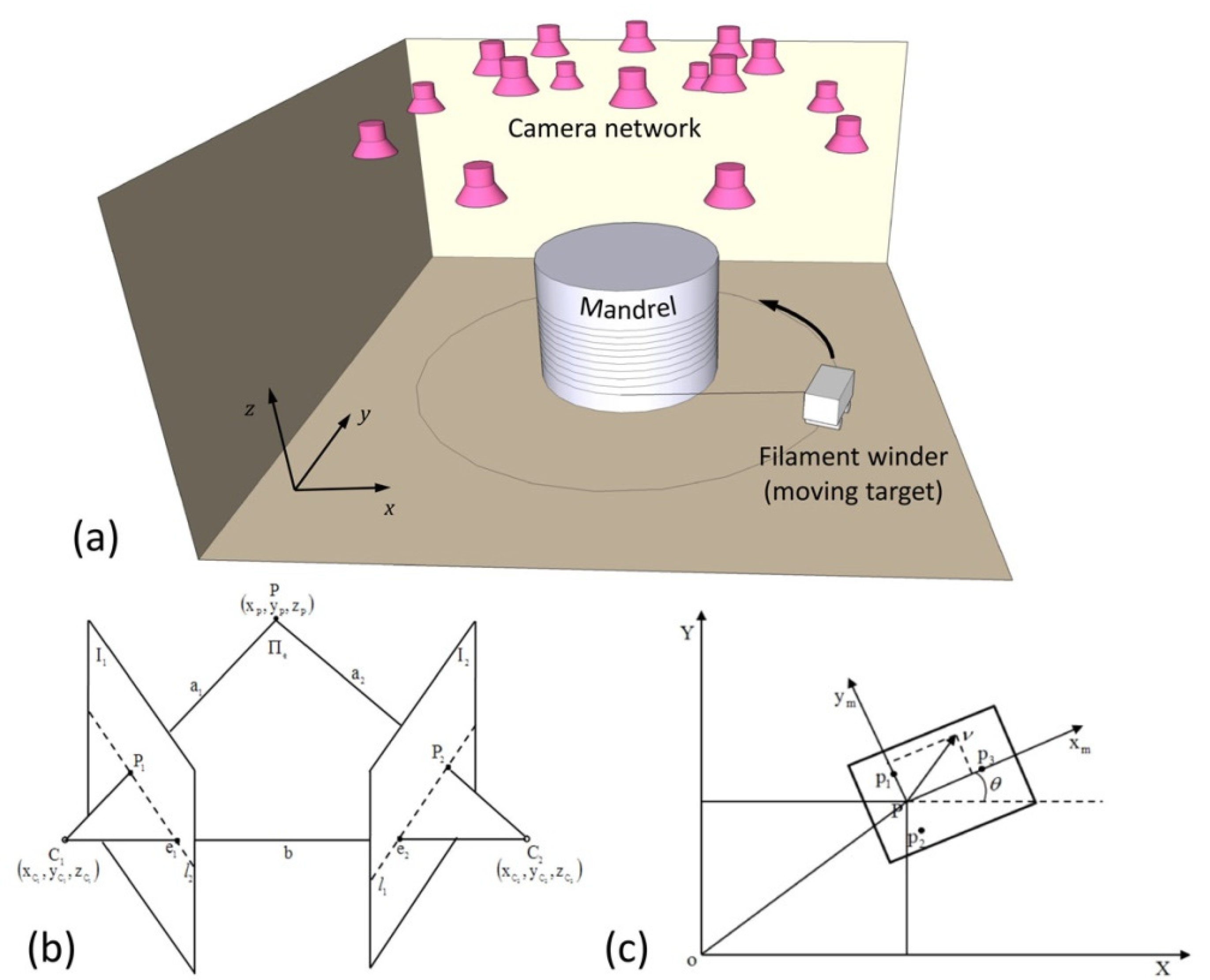
:1. Introduction
2. Methodology
2.1. Positioning System
2.1.1. Stereo Vision
2.1.2. Methodology of Locating the Moving Target (the Filament Winder)
2.2. Data Processing Using Extended Kalman Filter
3. Experimental Approaches
3.1. Calibration of Cameras
3.2. Algorithm for Automatically Selecting Cameras
3.3. Self-Configuration for Camera Network
4. Results
4.1. Experimental Observations
4.2. Error Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bae, H.J.; Choi, L. Large-Scale Indoor Positioning using Geomagnetic Field with Deep Neural Networks. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Chang, L.; Wang, J.; Meng, H.; Chen, X.; Fang, D.; Tang, Z.; Wang, Z. Towards Large-Scale RFID Positioning: A Low-cost, High-precision Solution Based on Compressive Sensing. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom), Athens, Greece, 19–23 March 2018; pp. 1–10. [Google Scholar] [CrossRef] [Green Version]
- Lu, Y.; Liu, W.; Zhang, Y.; Xing, H.; Li, J.; Liu, S.; Zhang, L. An Accurate Calibration Method of Large-Scale Reference System. IEEE Trans. Instrum. Meas. 2020, 69, 6957–6967. [Google Scholar] [CrossRef]
- Maisano, D.A.; Jamshidi, J.; Franceschini, F.; Maropoulos, P.G.; Mastrogiacomo, L.; Mileham, A.R.; Owen, G.W. A comparison of two distributed large-volume measurement systems: The mobile spatial co-ordinate measuring system and the indoor global positioning system. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2009, 223, 511–521. [Google Scholar] [CrossRef]
- Liu, Z.G.; Xu, Y.Z.; Liu, Z.Z.; Wu, J.W. A large scale 3D positioning method based on a network of rotating laser automatic theodolites. In Proceedings of the IEEE International Conference on Information and Automation (ICIA), Harbin, China, 20–23 June 2010; pp. 513–518. [Google Scholar]
- Cuypers, W.; van Gestel, N.; Voet, A.; Kruth, J.-P.; Mingneau, J.; VanGestel, P.B.N.; Voet, A.; Kruth, J.-P.; Mingneau, J.; Bleys, P. Optical measurement techniques for mobile and large-scale dimensional metrology. Opt. Lasers Eng. 2009, 47, 292–300. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, Z.; Siegwart, R.; Chung, J.J. Distributed PDOP Coverage Control: Providing Large-Scale Positioning Service Using a Multi-Robot System. IEEE Robot. Autom. Lett. 2021, 6, 2217–2224. [Google Scholar] [CrossRef]
- Yen, H.H. Novel visual sensor deployment algorithm in PTZ wireless visual sensor networks. In Proceedings of the Asia Pacific Conference on Wireless and Mobile, Bali, Indonesia, 28–30 August 2014; pp. 214–218. [Google Scholar]
- Liang, X.F.; Sumi, Y.; Kim, B.K.; Do, H.M.; Kim, Y.S.; Tomizawa, T.; Ohara, K.; Tanikawa, T.; Ohba, K. A large planar camera array for multiple automated guided vehicles localization. In Proceedings of the International Conference on Advanced Intelligent Mechatronics, Xi’an, China, 2–5 July 2008; pp. 608–613. [Google Scholar]
- Galetto, M.; Mastrogiacomo, L.; Pralio, B. MScMS-II an innovative IR-based indoor coordinate measuring system for large-scale metrology applications. Int. J. Adv. Manuf. Technol. 2011, 52, 291–302. [Google Scholar] [CrossRef] [Green Version]
- Dixon, M.; Jacobs, N.; Pless, R. An Efficient System for Vehicle Tracking in Multi-Camera Networks. In Proceedings of the Third ACM/IEEE International Conference on Distributed Smart Cameras, Como, Italy, 30 August–2 September 2009; pp. 1–8. [Google Scholar]
- Wei, G.; Petrushin, V.; Gershman, A. Multiple-camera people localization in a cluttered environment. In Proceedings of the 5th International Workshop on Multimedia Data Mining, Brighton, UK, 1–4 November 2004; pp. 9–12. [Google Scholar]
- Kuo, T.; Ni, Z.; De Leo, C.; Manjunath, B.S. Design and Implementation of a Wide Area, Large-Scale Camera Network. In Proceedings of the Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 25–32. [Google Scholar]
- Lin, J.; Chen, J.; Yang, L.; Ren, Y.; Wang, Z.; Keogh, P.; Zhu, J. Design and development of a ceiling-mounted workshop measurement positioning system for large-scale metrology. Opt. Lasers Eng. 2020, 124, 105814. [Google Scholar] [CrossRef]
- Puerto, P.; Heißelmann, D.; Müller, S.; Mendikute, A. Methodology to Evaluate the Performance of Portable Photogrammetry for Large-Volume Metrology. Metrology 2022, 2, 320–334. [Google Scholar] [CrossRef]
- Maisano, D.A.; Mastrogiacomo, L. Cooperative diagnostics for combinations of large volume metrology systems. Int. J. Manuf. Res. 2019, 14, 15–42. [Google Scholar] [CrossRef]
- Soro, S.; Heinzelman, W. Camera Selection in Visual Sensor Networks. In Proceedings of the IEEE Conference on Advanced Video and Signal Based Surveillance, London, UK, 5–7 September 2007; pp. 81–86. [Google Scholar]
- Liu, L.; Zhang, X.; Ma, H.D. Dynamic Node Collaboration for Mobile Target Tracking in Wireless Camera Sensor Networks. In Proceedings of the INFOCOM, Rio de Janeiro, Brazil, 24 April 2009; pp. 1188–1196. [Google Scholar]
- Wu, Y.F.; Li, G.Y.; Yan, H. Optimal Camera Placement of Large Scale Volume Localization System for Mobile Robot. In Proceedings of the ICMSE, Shanghai, China, 14–16 April 2014; pp. 1390–1395. [Google Scholar]
- Tian, H.F.; Yan, H.; Wu, Y.F. Relative Position Algorithm for Optimal Camera Placement of Large Scale Volume Localization System. In Proceedings of the ICFMD, Hong Kong, China, September 2014; pp. 1442–1446. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004; Part I. [Google Scholar]
- Corke, P. Robotics Vision & Contro, 1st ed.; Springer: Berlin/Heidelberg, Germany; GmbH & Co. K: Berlin, Germany, 2011; Chapter 2. [Google Scholar]
- Kim, G.W.; Nam, K.T.; Lee, S.M. Visual Servoing of a Wheeled Mobile Robot using Unconstrained Optimization with a Ceiling Mounted Camera. In Proceedings of the 16th IEEE International Conference on Robot and Human interactive Communication, Jeju, Korea, 8–12 August 2007; pp. 212–217. [Google Scholar]
- Dutkiewicz, P.; Kiełczewski, M.; Kozłowski, K. Vision localization system for mobile robot with velocities and acceleration estimator. Bull. Pol. Acad. Sci. Tech. Sci. 2010, 58, 29–41. [Google Scholar] [CrossRef] [Green Version]
- Wan, E. Sigma-Point Filters: An Overview with Applications to Integrated Navigation and Vision Assisted Control. In Proceedings of the 2006 IEEE Nonlinear Statistical Signal Processing Workshop, Cambridge, UK, 13–15 September 2006; pp. 201–202, ISBN 978-1-4244-0579-4. [Google Scholar] [CrossRef]
- Pelka, M.; Hellbruck, H. Introduction discussion and evaluation of recursive Bayesian filters for linear and nonlinear filtering problems in indoor localization. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcala de Henares, Spain, 4–7 October 2016; pp. 1–8. [Google Scholar]
- Haifeng, Z.; Huabo, W.; Min, W.; Huizhu, Z.; Yu, L. A Vision Based UAV Pesticide Mission System. In Proceedings of the 2018 IEEE CSAA Guidance, Navigation and Control Conference (CGNCC), Xiamen, China, 10–12 August 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Svoboda, T.; Martinec, D.; Pajdla, T. A convenient multi-camera self-calibration for virtual environments. Teleoperators Virtual Environ. 2005, 14, 407–422. [Google Scholar] [CrossRef]
- Zhao, W.; Shi, Z.; Chen, X.; Yang, G.; Lenardi, C.; Liu, C. Microstructural and Mechanical Characteristics of PHEMA-based Nanofibre-reinforced Hydrogel under Compression. Compos. Part B Eng. 2015, 76, 292–299. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Li, X.; Gao, S.; Feng, Y.; Huang, J. Understanding Mechanical Characteristics of Cellulose Nanocrystals Reinforced PHEMA Nanocomposite Hydrogel: In Aqueous Cyclic Test. Cellulose 2017, 24, 2095–2110. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x | y | θ | vx | vy | w | |
|---|---|---|---|---|---|---|
| F * | 2.31 × 10−6 | 1.69 × 10−6 | 2.16 × 10−4 | 5.23 × 10−6 | 4.14 × 10−4 | 9.72 |
| FCV * | 6.69 | 6.69 | 6.69 | 6.69 | 6.69 | 6.69 |
| Interpretation | F < FCV | F < FCV | F < FCV | F < FCV | F < FCV | F > FCV |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Zhao, W.; Zhang, J. Methodology for Large-Scale Camera Positioning to Enable Intelligent Self-Configuration. Sensors 2022, 22, 5806. https://doi.org/10.3390/s22155806
Wu Y, Zhao W, Zhang J. Methodology for Large-Scale Camera Positioning to Enable Intelligent Self-Configuration. Sensors. 2022; 22(15):5806. https://doi.org/10.3390/s22155806
Chicago/Turabian StyleWu, Yingfeng, Weiwei Zhao, and Jifa Zhang. 2022. "Methodology for Large-Scale Camera Positioning to Enable Intelligent Self-Configuration" Sensors 22, no. 15: 5806. https://doi.org/10.3390/s22155806