
Alpine Skiing Activity Recognition Using Smartphone’s IMUs

 ,
,  , and
, and
Abstract
:1. Introduction
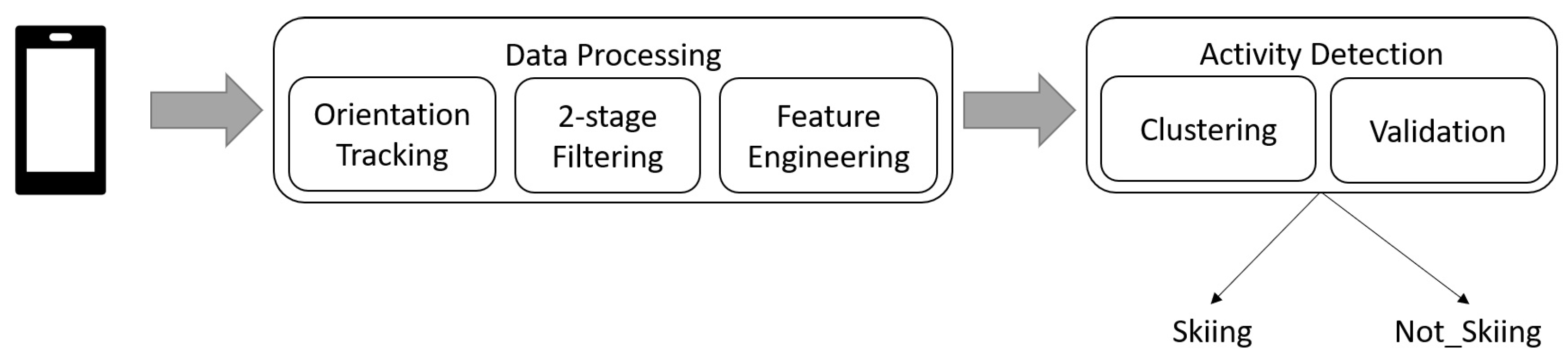
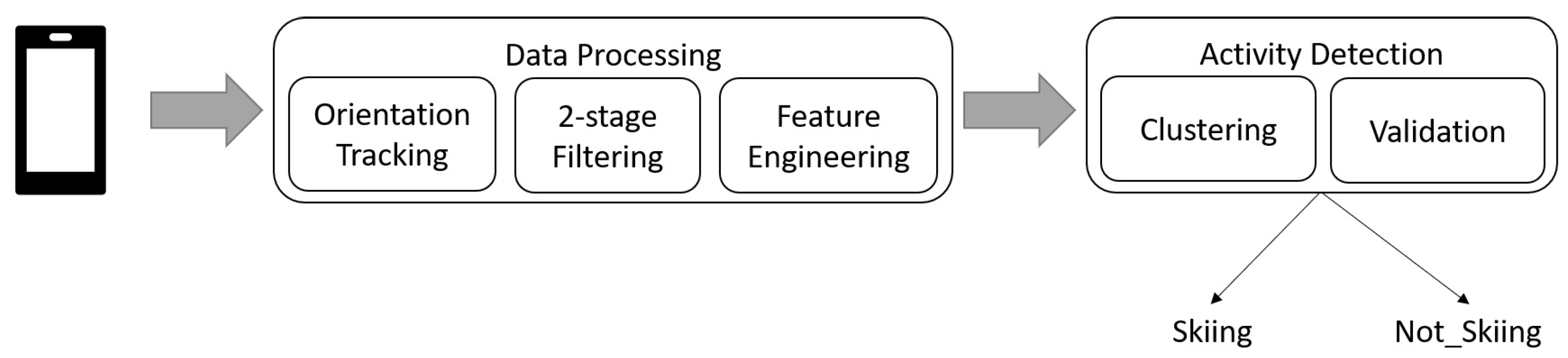
2. Materials and Methods
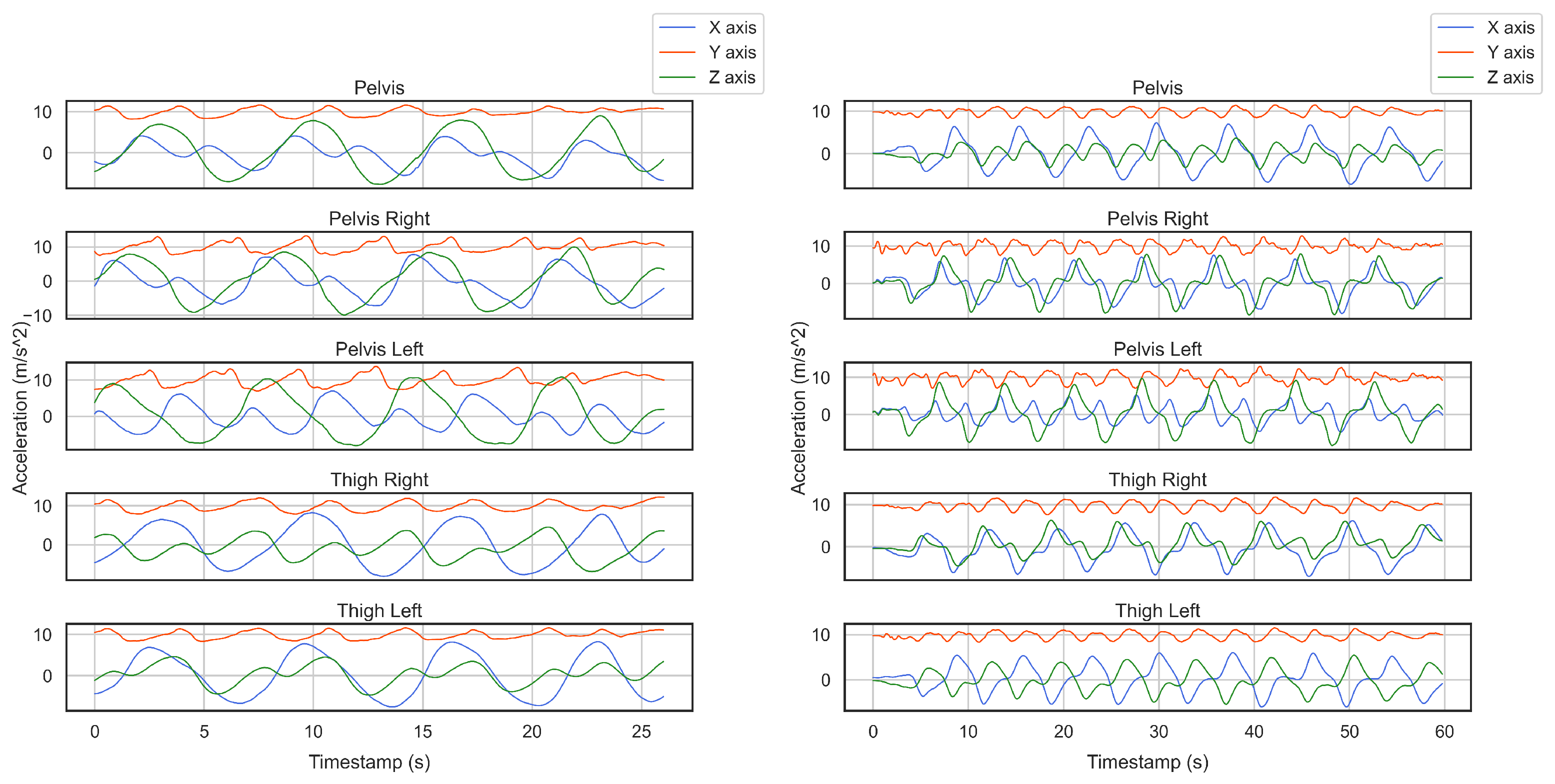
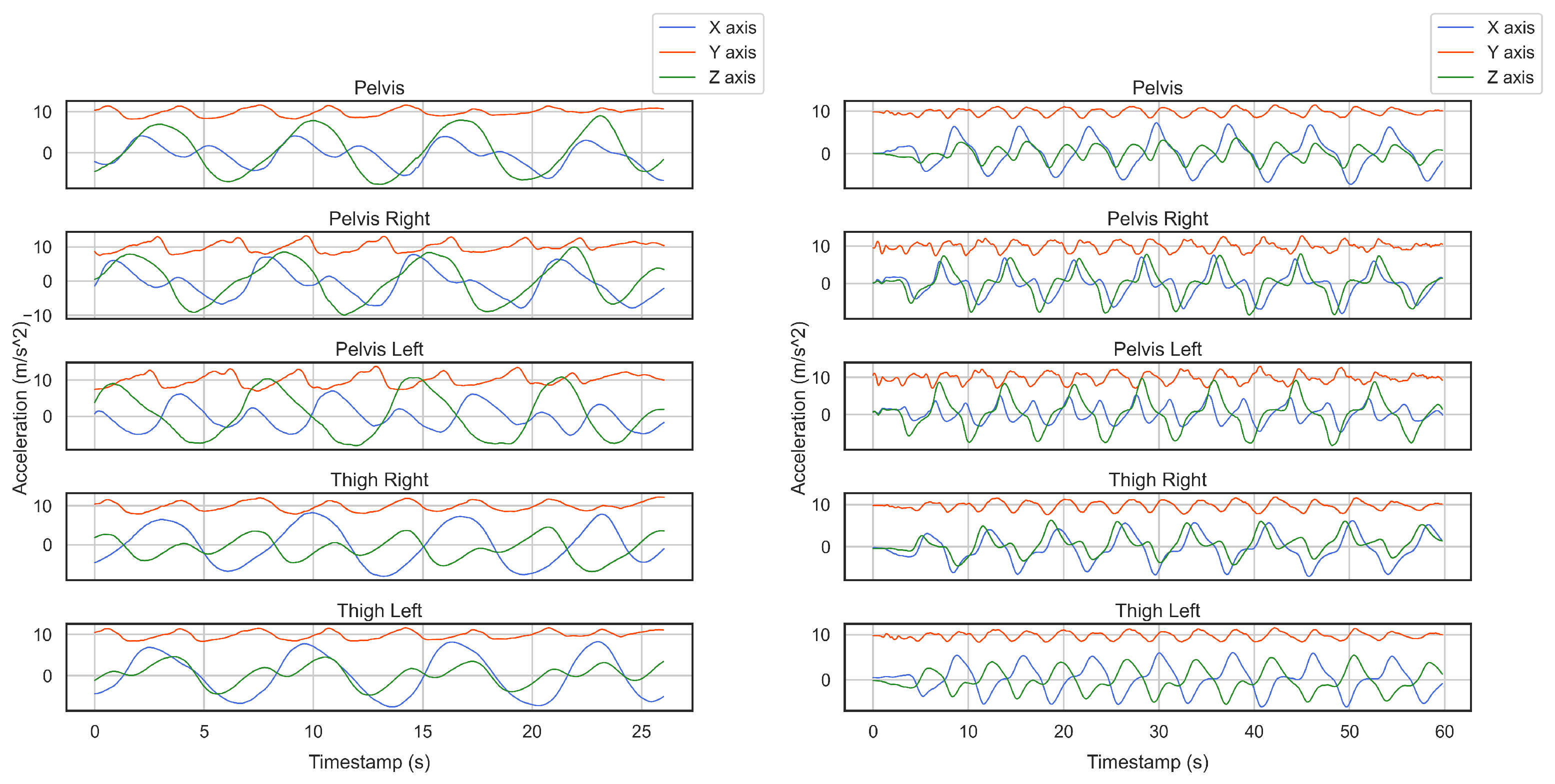
2.1. Data Collection
2.2. Experimental Design
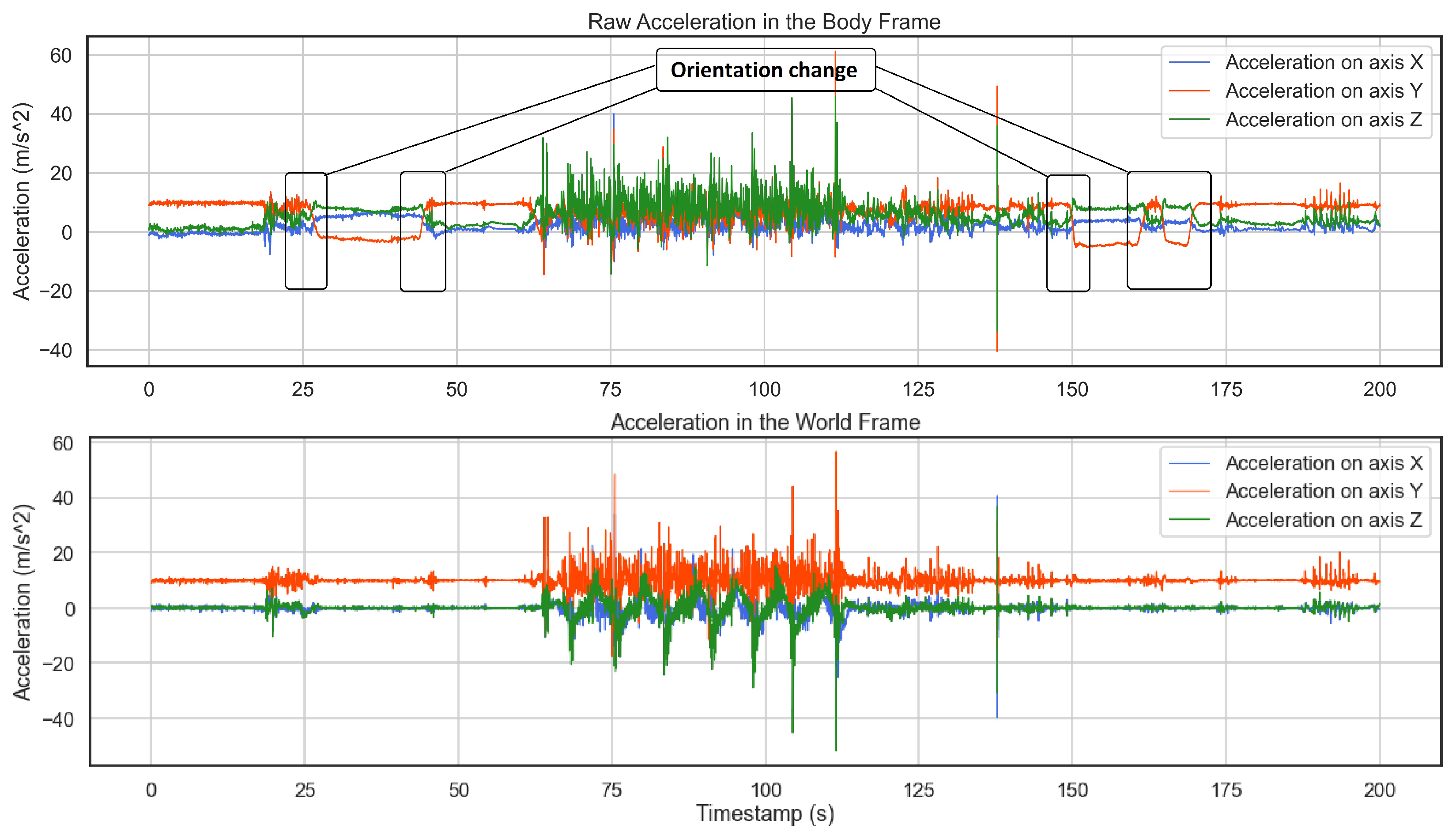
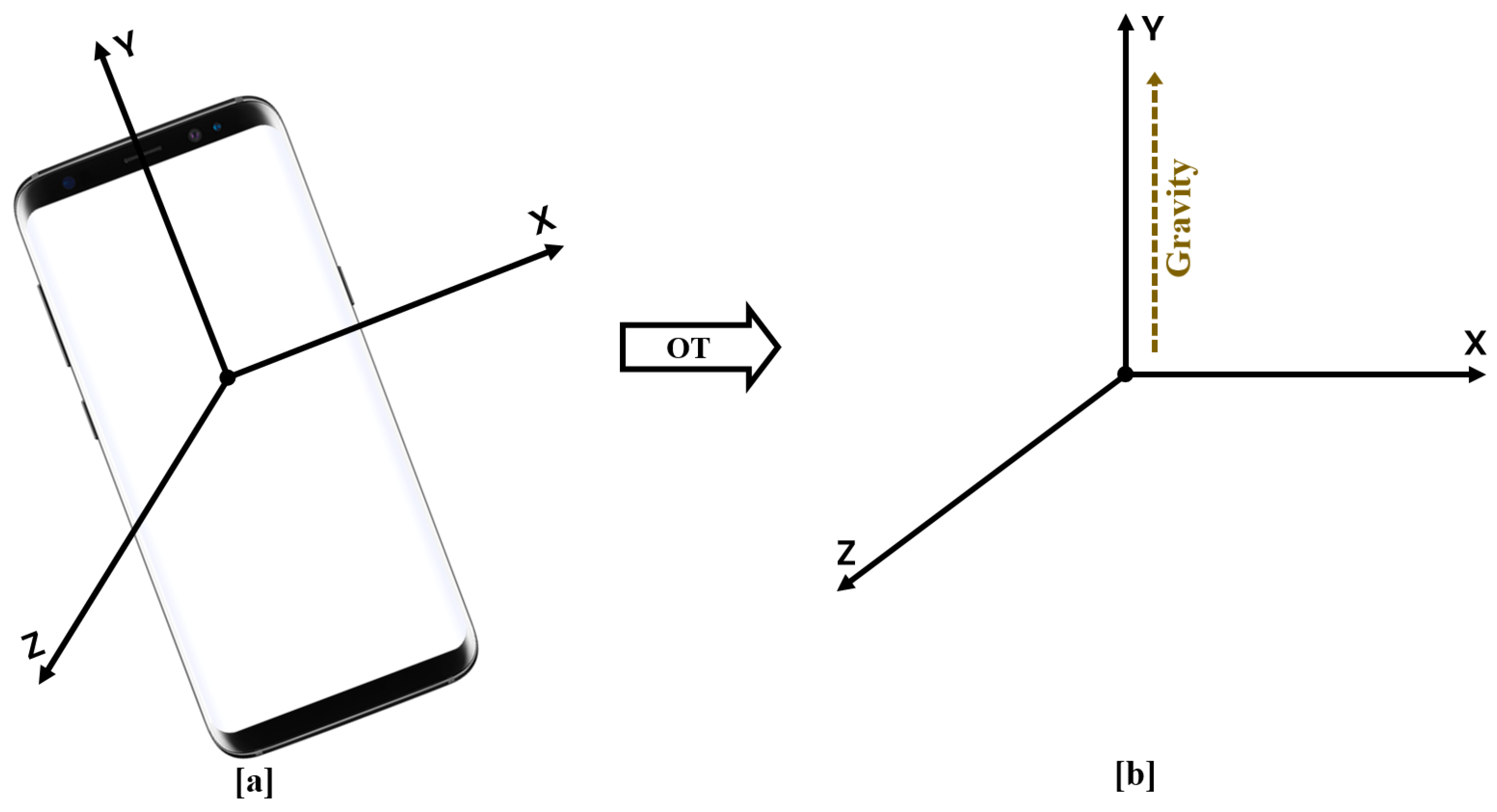
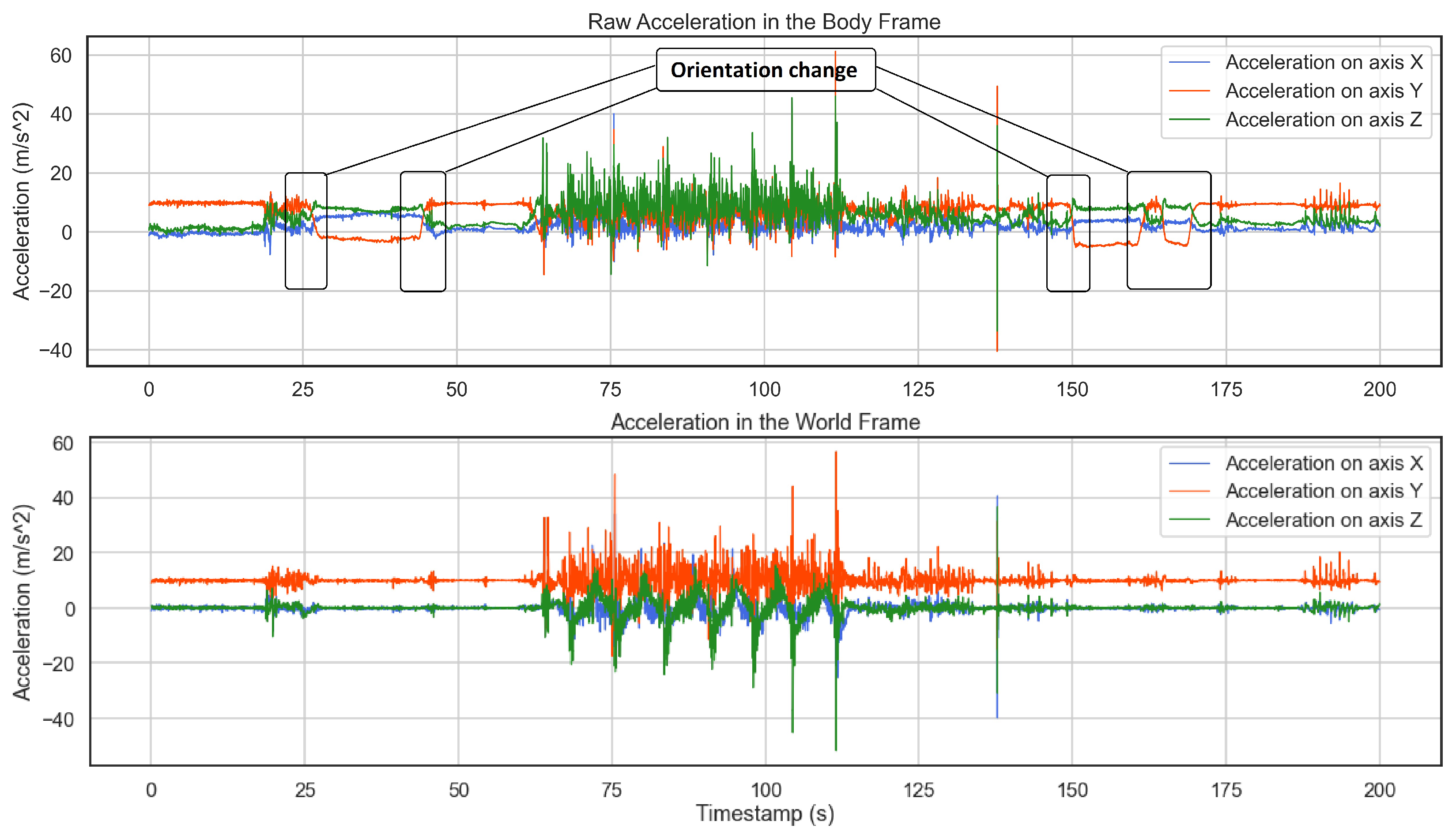
2.2.1. Orientation Tracking
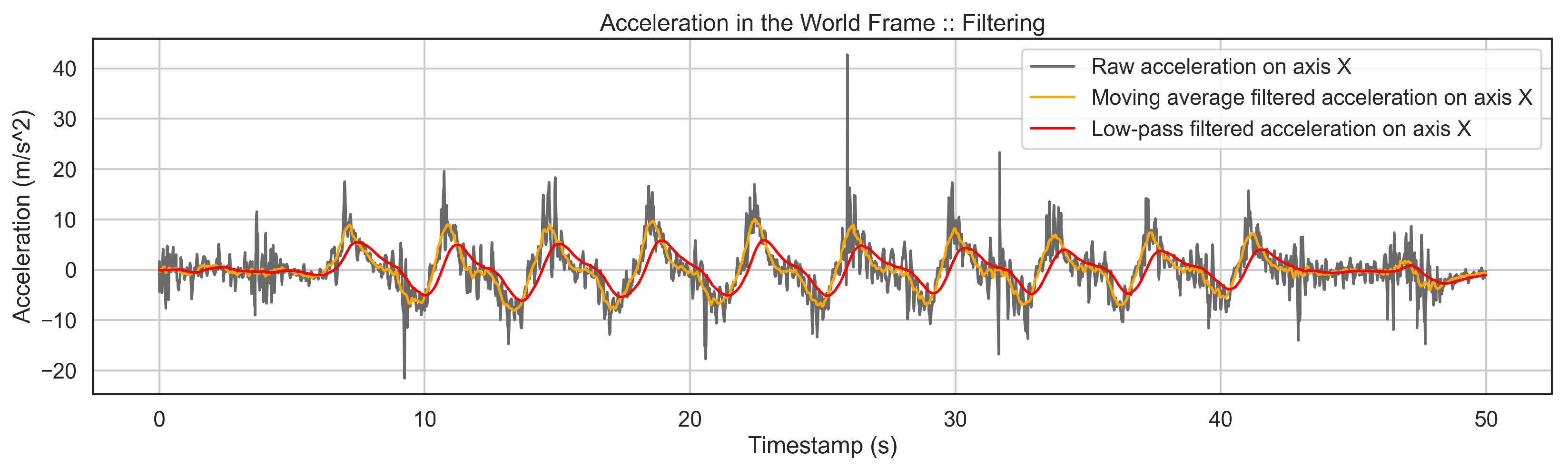
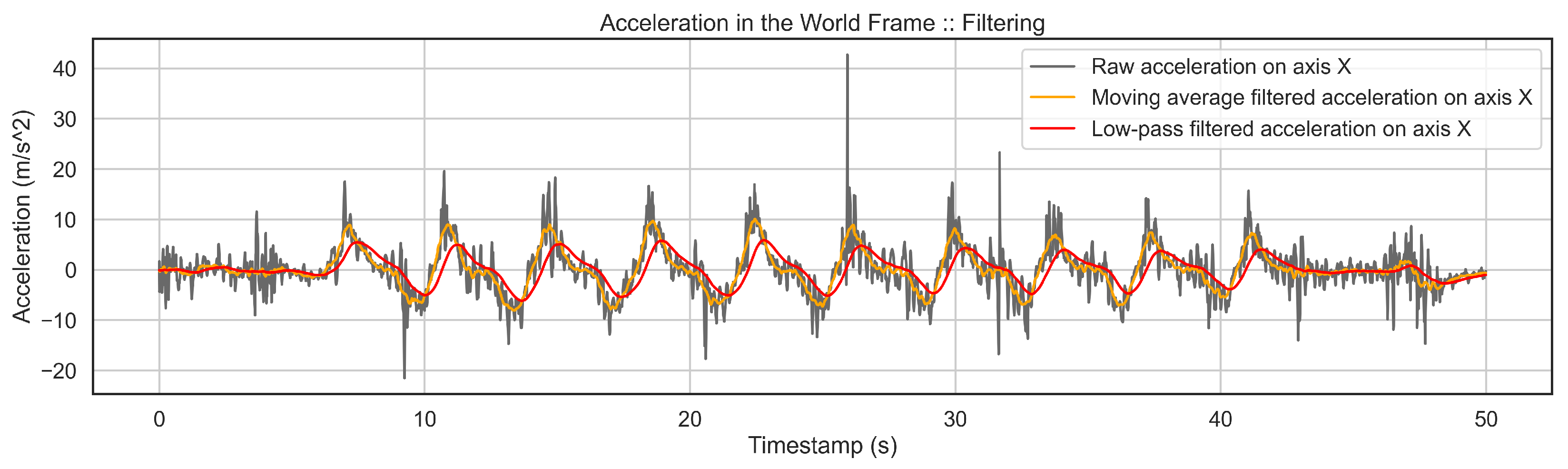
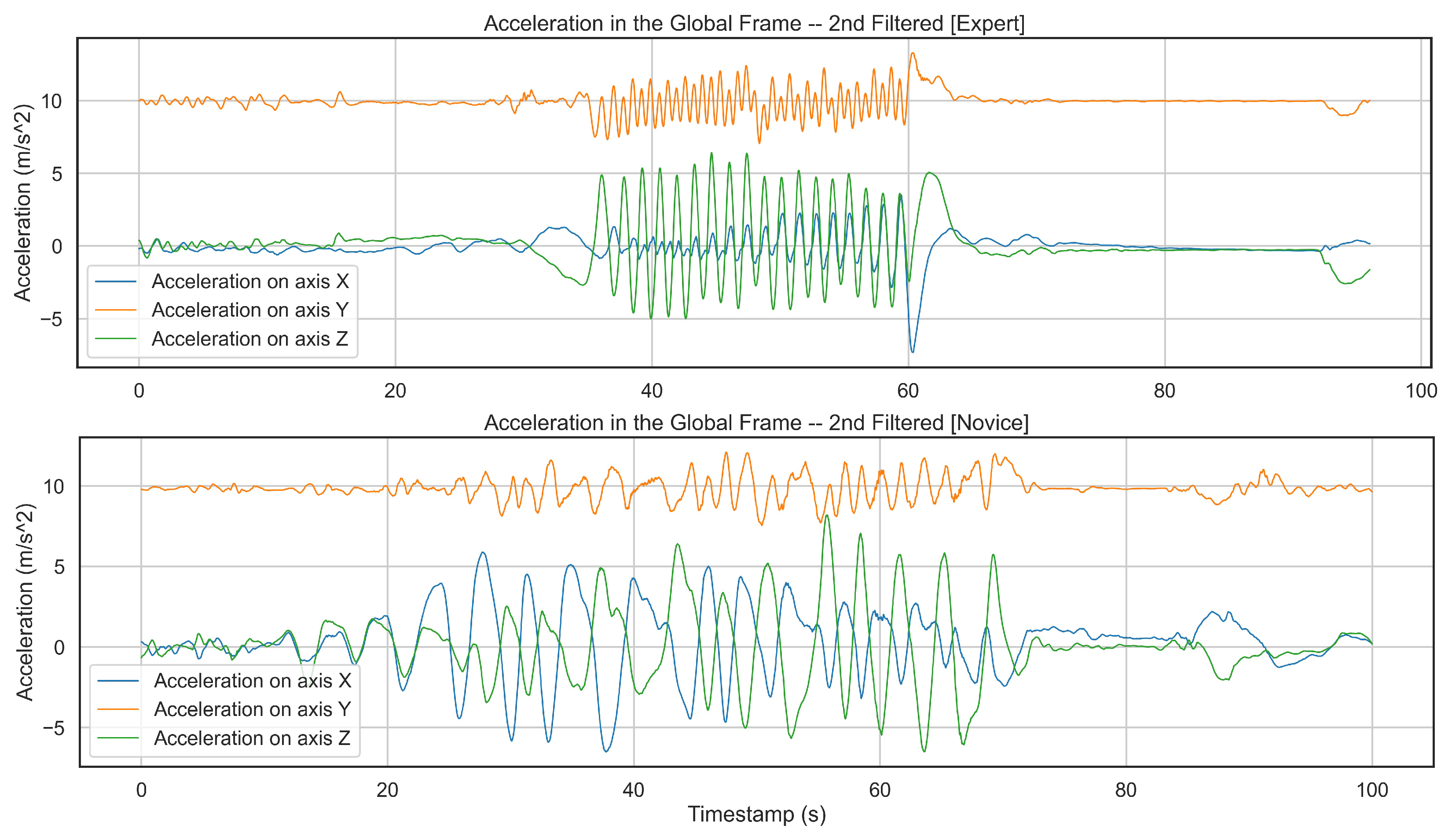
2.2.2. 2-Stage Filtering
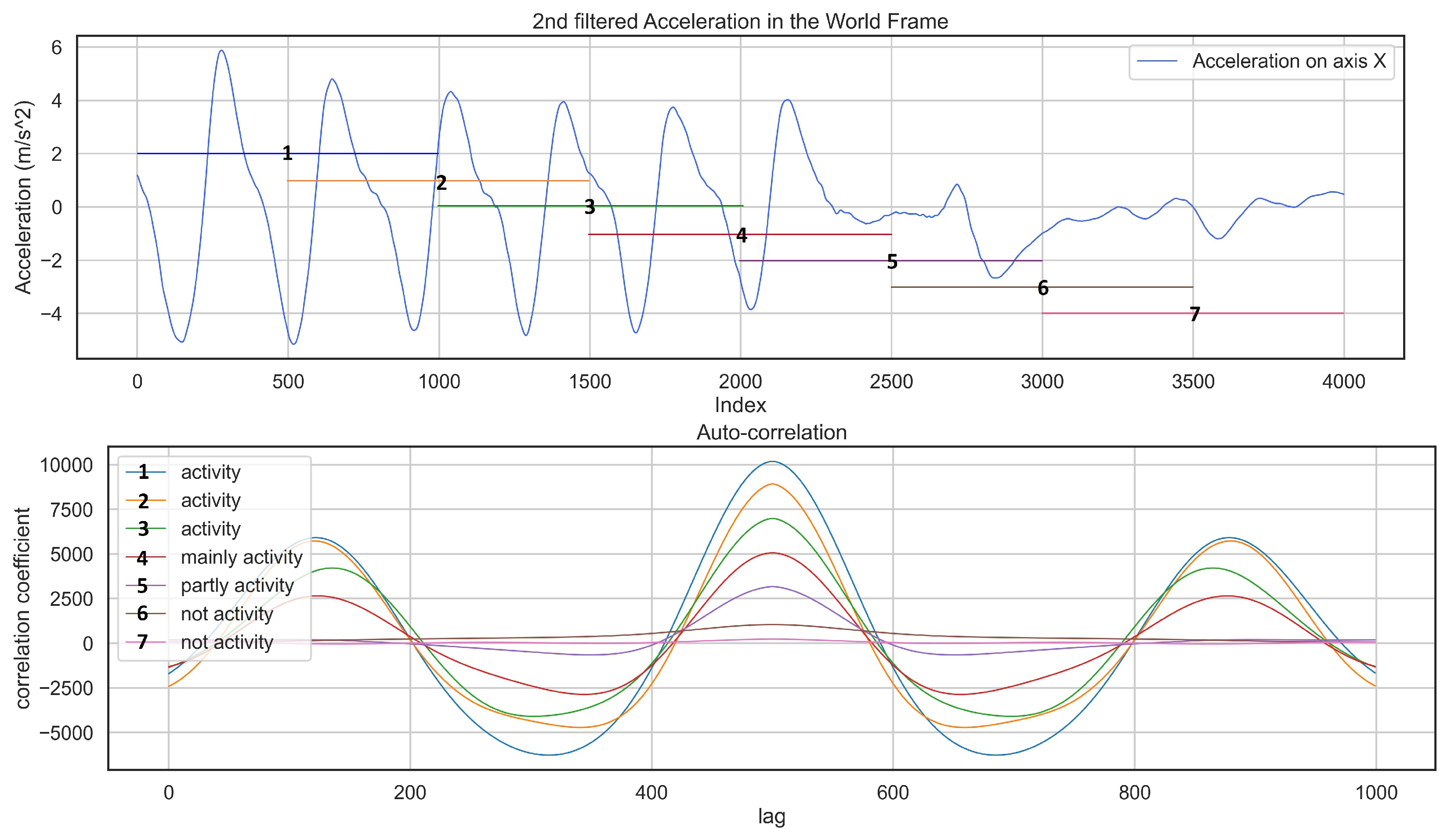
2.2.3. Feature Engineering
- mean, standard deviation, root mean square, minimum, maximum, median, variance, median absolute deviation, the energy of the window and its auto-correlation
- mean crossing, 50 percent crossing, 25 percent crossing, 75 percent crossing of the window and its auto-correlation
- mean, the median of Power Spectrum of the window
- SMA: Signal Magnitude Area
2.2.4. Clustering
2.2.5. Validation
2.3. Data Analysis
3. Results
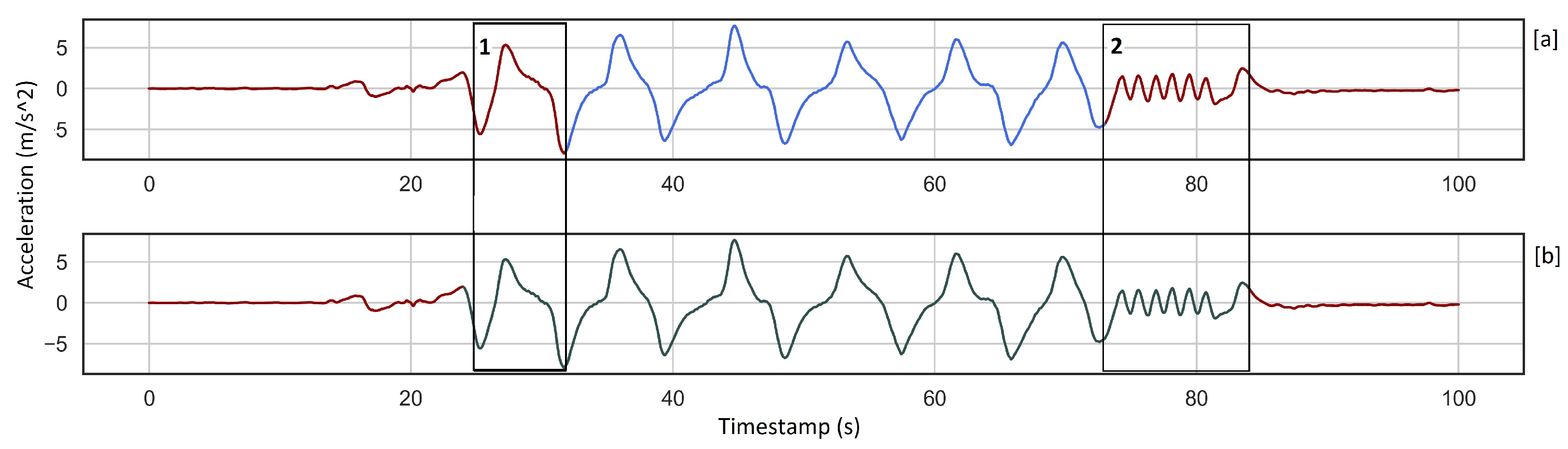
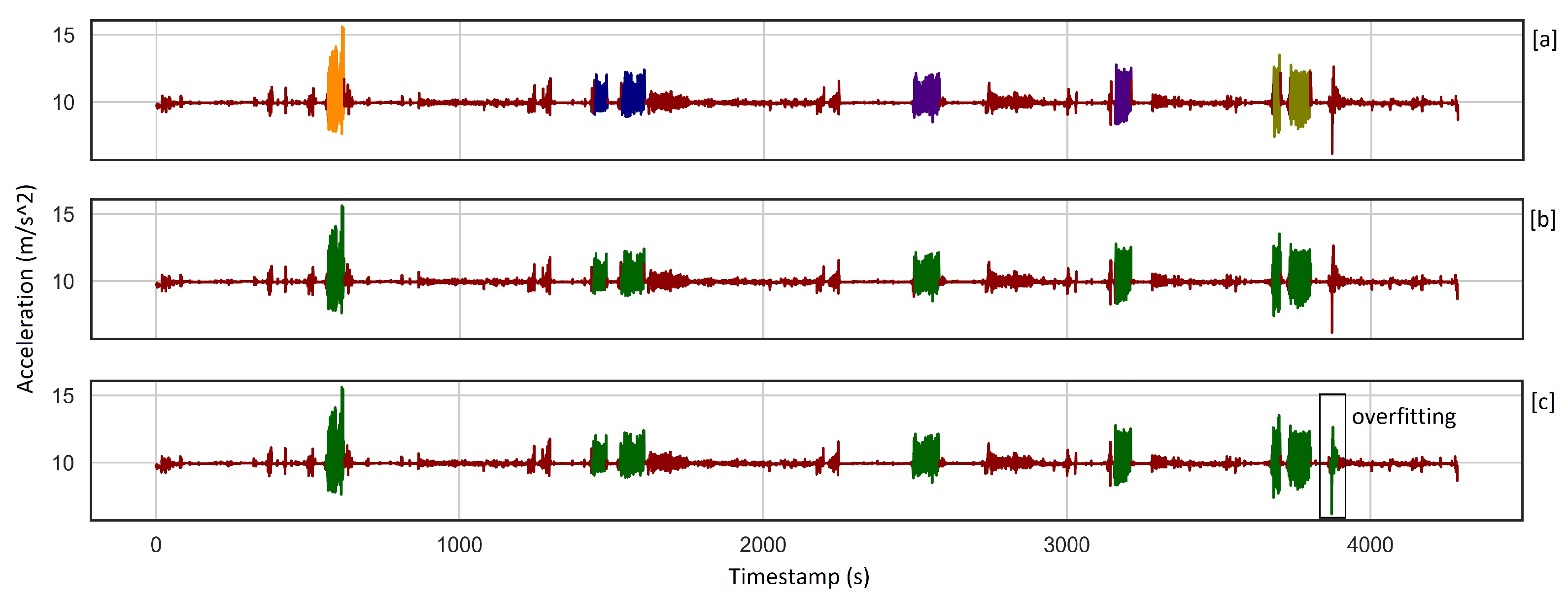
3.1. Analysis Result: Phase One
3.2. Analysis Result: Phase Two
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Supej, M.; Holmberg, H.C. Recent kinematic and kinetic advances in olympic alpine skiing: Pyeongchang and beyond. Front. Physiol. 2019, 10, 111. [Google Scholar] [CrossRef] [PubMed]
- Hébert-Losier, K.; Supej, M.; Holmberg, H.C. Biomechanical factors influencing the performance of elite alpine ski racers. Sport. Med. 2014, 44, 519–533. [Google Scholar] [CrossRef] [PubMed]
- Supej, M.; Senner, V.; Petrone, N.; Holmberg, H.C. Reducing the risks for traumatic and overuse injury among competitive alpine skiers. Br. J. Sport. Med. 2017, 51, 1–2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spörri, J.; Kröll, J.; Schwameder, H.; Schiefermüller, C.; Müller, E. Course setting and selected biomechanical variables related to injury risk in alpine ski racing: An explorative case study. Br. J. Sport. Med. 2012, 46, 1072–1077. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Spörri, J.; Kröll, J.; Gilgien, M.; Müller, E. Sidecut radius and the mechanics of turning—Equipment designed to reduce risk of severe traumatic knee injuries in alpine giant slalom ski racing. Br. J. Sport. Med. 2016, 50, 14–19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fasel, B.; Spörri, J.; Gilgien, M.; Gerber, N.; Falbriard, M.; Müller, E.; Aminian, K. IMU and GNSS-based turn switch detection in alpine ski racing. In Proceedings of the Book of Abstracts of the 7th International Congress on Science and Skiing, St. Christopher/Arlberg, Austria, 10–15 December 2016. [Google Scholar]
- Martínez, A.; Jahnel, R.; Buchecker, M.; Snyder, C.; Brunauer, R.; Stöggl, T. Development of an automatic alpine skiing turn detection algorithm based on a simple sensor setup. Sensors 2019, 19, 902. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dang, L.M.; Min, K.; Wang, H.; Piran, M.J.; Lee, C.H.; Moon, H. Sensor-based and vision-based human activity recognition: A comprehensive survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Reich, O.; Hübner, E.; Ghita, B.; Wagner, M.F.; Schäfer, J. A Survey Investigating the Combination and Number of IMUs on the Human Body Used for Detecting Activities and Human Tracking. In Proceedings of the 2020 World Conference on Computing and Communication Technologies (WCCCT), Warsaw, Poland, 13–15 May 2020; pp. 20–27. [Google Scholar]
- Yu, G.; Jang, Y.J.; Kim, J.; Kim, J.H.; Kim, H.Y.; Kim, K.; Panday, S.B. Potential of IMU sensors in performance analysis of professional alpine skiers. Sensors 2016, 16, 463. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martínez, A.; Brunauer, R.; Venek, V.; Snyder, C.; Jahnel, R.; Buchecker, M.; Thorwartl, C.; Stöggl, T. Development and validation of a gyroscope-based turn detection algorithm for alpine skiing in the field. Front. Sport. Act. Living 2019, 1, 18. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neuwirth, C.; Snyder, C.; Kremser, W.; Brunauer, R.; Holzer, H.; Stöggl, T. Classification of Alpine Skiing Styles Using GNSS and Inertial Measurement Units. Sensors 2020, 20, 4232. [Google Scholar] [CrossRef] [PubMed]
- Han, B.K.; Ryu, J.K.; Kim, S.C. Context-Aware winter sports based on multivariate sequence learning. Sensors 2019, 19, 3296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pawlyta, M.; Hermansa, M.; Szczęsna, A.; Janiak, M.; Wojciechowski, K. Deep recurrent neural networks for human activity recognition during skiing. In International Conference on Man–Machine Interactions; Springer: New York, NY, USA, 2019; pp. 136–145. [Google Scholar]
- Hassan, M.M.; Uddin, M.Z.; Mohamed, A.; Almogren, A. A robust human activity recognition system using smartphone sensors and deep learning. Future Gener. Comput. Syst. 2018, 81, 307–313. [Google Scholar] [CrossRef]
- Altun, K.; Barshan, B. Human activity recognition using inertial/magnetic sensor units. In International Workshop on Human Behavior Understanding; Springer: New York, NY, USA, 2010; pp. 38–51. [Google Scholar]
- Zhou, Z.H. A brief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Wetzstein, G. EE 267 Virtual Reality Course Notes: 3-DOF Orientation Tracking with IMUs. Available online: https://stanford.edu/class/ee267/notes/ee267_notes_imu.pdf (accessed on 3 July 2022).
- LaValle, S.M.; Yershova, A.; Katsev, M.; Antonov, M. Head tracking for the Oculus Rift. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 187–194. [Google Scholar]
- LaValle, S. Virtual Reality; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M. Preprocessing techniques for context recognition from accelerometer data. Pers. Ubiquitous Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Maekawa, T.; Nakai, D.; Ohara, K.; Namioka, Y. Toward practical factory activity recognition: Unsupervised understanding of repetitive assembly work in a factory. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 1088–1099. [Google Scholar]
- Azadi, B.; Haslgrübler, M.; Sopidis, G.; Murauer, M.; Anzengruber, B.; Ferscha, A. Feasibility analysis of unsupervised industrial activity recognition based on a frequent micro action. In Proceedings of the 12th ACM International Conference on Pervasive Technologies Related to Assistive Environments, Rhodes, Greece, 5–7 June 2019; pp. 368–375. [Google Scholar]
- Trebuňa, P.; Halčinová, J.; Fil’o, M.; Markovič, J. The importance of normalization and standardization in the process of clustering. In Proceedings of the 2014 IEEE 12th International Symposium on Applied Machine Intelligence and Informatics (SAMI), Herl’any, Slovakia, 23–25 January 2014; pp. 381–385. [Google Scholar]
- Demrozi, F.; Pravadelli, G.; Bihorac, A.; Rashidi, P. Human activity recognition using inertial, physiological and environmental sensors: A comprehensive survey. IEEE Access 2020, 8, 210816–210836. [Google Scholar] [CrossRef] [PubMed]
- Kwon, Y.; Kang, K.; Bae, C. Unsupervised learning for human activity recognition using smartphone sensors. Expert Syst. Appl. 2014, 41, 6067–6074. [Google Scholar] [CrossRef]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Yan, Z.; Subbaraju, V.; Chakraborty, D.; Misra, A.; Aberer, K. Energy-efficient continuous activity recognition on mobile phones: An activity-adaptive approach. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle Upon Tyne, UK, 18–22 June 2012; pp. 17–24. [Google Scholar]
- Shoaib, M.; Bosch, S.; Incel, O.D.; Scholten, H.; Havinga, P.J. Complex human activity recognition using smartphone and wrist-worn motion sensors. Sensors 2016, 16, 426. [Google Scholar] [CrossRef] [PubMed]
- Sousa, W.; Souto, E.; Rodrigres, J.; Sadarc, P.; Jalali, R.; El-Khatib, K. A comparative analysis of the impact of features on human activity recognition with smartphone sensors. In Proceedings of the 23rd Brazillian Symposium on Multimedia and the Web, Gramado, Brazil, 17–20 October 2017; pp. 397–404. [Google Scholar]
- Abbas, O.A. Comparisons between data clustering algorithms. Int. Arab. J. Inf. Technol. 2008, 5, 320–325. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Session | Where | When | Subjects | Skill * | Techniques | Self-Recorded | Glacier | Duration + |
|---|---|---|---|---|---|---|---|---|
| 1 | Hintertux | June 2019 | 4 | AAII | 3 | No | Yes | 50 |
| 2 | Dachstein | November 2019 | 1 | N | 5 | No | Yes | 28 |
| 3 | Galterbergalm | February 2020 | 1 | E | 6 | No | No | 151 |
| 4 | Hintertux | July 2020 | 1 | E | 6 | Partially | Yes | 71 |
| 5 | Ramsau | February 2021 | 4 | EEAN | 6 | Yes | No | 728 |
| Algorithm | FST | Accuracy [%] | NMI | ARI | Accuracy [] | NMI [] | ARI [] |
|---|---|---|---|---|---|---|---|
| Kmeans | NFS | 96.56 | 0.68 | 0.80 | 1.85 | 0.12 | 0.14 |
| Kmeans | PCA | 96.53 | 0.68 | 0.80 | 1.87 | 0.12 | 0.14 |
| GMM | NFS | 96.02 | 0.67 | 0.79 | 4.99 | 0.12 | 0.14 |
| Ward | NFS | 95.49 | 0.64 | 0.75 | 3.17 | 0.17 | 0.16 |
| Ward | PCA | 95.12 | 0.62 | 0.73 | 3.13 | 0.18 | 0.17 |
| GMM | PCA | 92.88 | 0.58 | 0.67 | 3.39 | 0.12 | 0.11 |
| Baseline | – | 88.7 | 0.0 | 0.0 | 0.45 | 0.0 | 0.0 |
| Window Size [s] | Sliding Rate | Accuracy [%] | NMI | ARI | Accuracy [] | NMI [] | ARI [] |
|---|---|---|---|---|---|---|---|
| 6 | 1 | 96.07 | 0.68 | 0.79 | 2.81 | 0.12 | 0.12 |
| 7 | 0.2 | 95.81 | 0.68 | 0.78 | 2.84 | 0.12 | 0.12 |
| 9 | 0.2 | 95.75 | 0.68 | 0.78 | 2.89 | 0.12 | 0.13 |
| 6 | 0.5 | 95.76 | 0.67 | 0.78 | 3.41 | 0.17 | 0.16 |
| 8 | 0.2 | 95.53 | 0.67 | 0.78 | 3.39 | 0.13 | 0.12 |
| Algorithm | FST | Window Size [s] | Sliding Rate | Accuracy [%] | NMI | ARI | Accuracy [] | NMI [] | ARI [] |
|---|---|---|---|---|---|---|---|---|---|
| GMM | NFS | 6 | 0.5 | 97.43 | 0.74 | 0.85 | 1.33 | 0.08 | 0.11 |
| KMeans | PCA | 6 | 0.5 | 97.41 | 0.73 | 0.85 | 1.32 | 0.08 | 0.11 |
| KMeans | NFS | 9 | 0.2 | 97.01 | 0.73 | 0.84 | 1.41 | 0.07 | 0.10 |
| KMeans | NFS | 6 | 0.5 | 97.32 | 0.72 | 0.84 | 1.26 | 0.07 | 0.10 |
| KMeans | NFS | 6 | 1 | 97.14 | 0.72 | 0.84 | 1.10 | 0.05 | 0.07 |
| Algorithm | FST | Window Size [s] | Sliding Rate | Accuracy [%] | NMI | ARI | Accuracy [] | NMI [] | ARI [] |
|---|---|---|---|---|---|---|---|---|---|
| KMeans | NFS | 6 | 0.2 | 99.28 | 0.87 | 0.95 | 0.09 | 0.01 | 0.01 |
| KMeans | PCA | 6 | 0.2 | 99.27 | 0.87 | 0.95 | 0.09 | 0.01 | 0.01 |
| KMeans | PCA | 7 | 0.2 | 99.25 | 0.87 | 0.94 | 0.12 | 0.02 | 0.01 |
| KMeans | PCA | 8 | 0.5 | 99.25 | 0.87 | 0.94 | 0.10 | 0.02 | 0.01 |
| KMeans | NFS | 7 | 0.2 | 99.23 | 0.87 | 0.94 | 0.13 | 0.02 | 0.01 |
| Algorithm | FST | Window Size [s] | Sliding Rate | Accuracy [%] | NMI | ARI | Detected Activities |
|---|---|---|---|---|---|---|---|
| KMeans | PCA | 8 | 0.5 | 99.17 | 0.86 | 0.94 | 7 |
| GMM | PCA | 8 | 0.5 | 98.12 | 0.77 | 0.87 | 8 |
| Baseline | - | - | - | 90.76 | 0 | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azadi, B.; Haslgrübler, M.; Anzengruber-Tanase, B.; Grünberger, S.; Ferscha, A. Alpine Skiing Activity Recognition Using Smartphone’s IMUs. Sensors 2022, 22, 5922. https://doi.org/10.3390/s22155922
Azadi B, Haslgrübler M, Anzengruber-Tanase B, Grünberger S, Ferscha A. Alpine Skiing Activity Recognition Using Smartphone’s IMUs. Sensors. 2022; 22(15):5922. https://doi.org/10.3390/s22155922
Chicago/Turabian StyleAzadi, Behrooz, Michael Haslgrübler, Bernhard Anzengruber-Tanase, Stefan Grünberger, and Alois Ferscha. 2022. "Alpine Skiing Activity Recognition Using Smartphone’s IMUs" Sensors 22, no. 15: 5922. https://doi.org/10.3390/s22155922
APA StyleAzadi, B., Haslgrübler, M., Anzengruber-Tanase, B., Grünberger, S., & Ferscha, A. (2022). Alpine Skiing Activity Recognition Using Smartphone’s IMUs. Sensors, 22(15), 5922. https://doi.org/10.3390/s22155922