
An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images



Abstract
:1. Introduction
2. Related Works
2.1. Semantic Point Cloud Segmentation with Point-Based Methods
2.2. Semantic Point Cloud Segmentation with Voxel-Based Methods
2.3. Semantic Point Cloud Segmentation with Projection-Based Methods
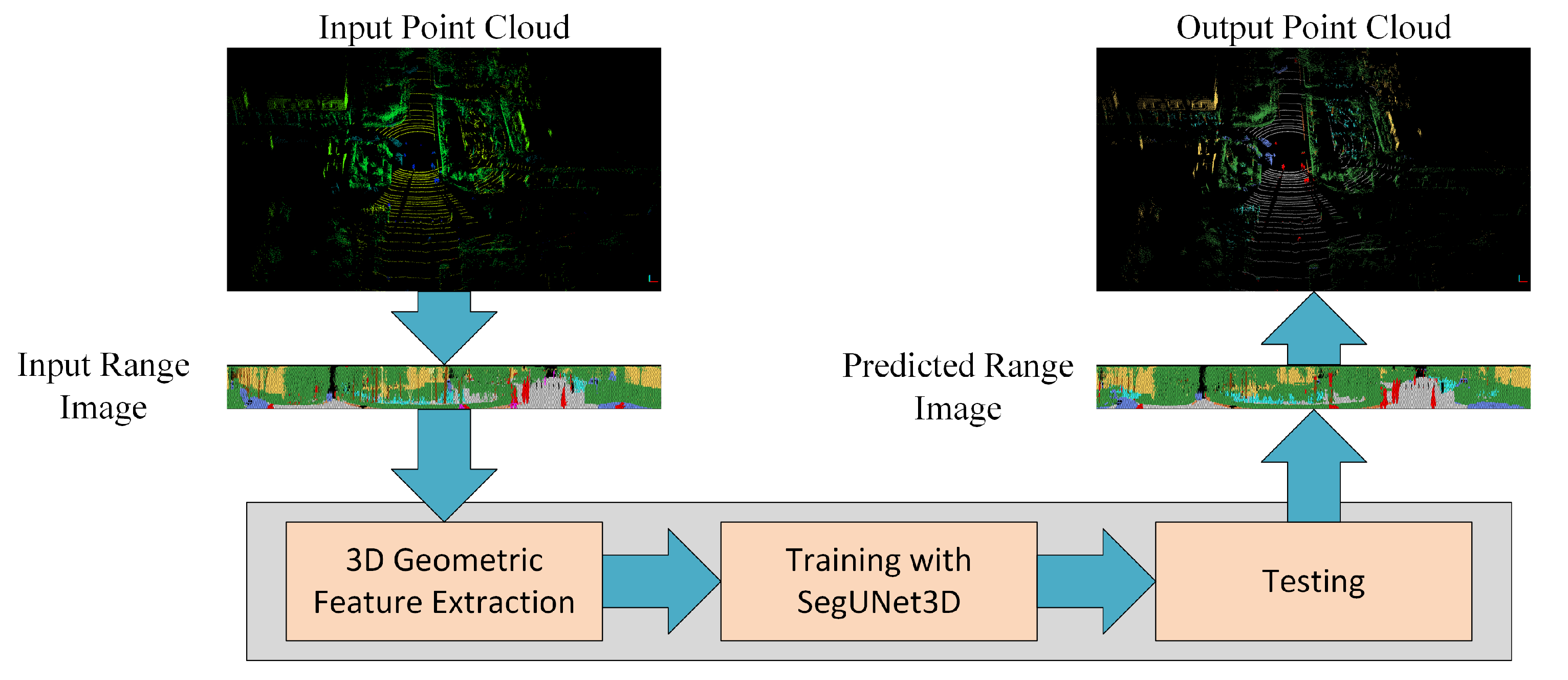
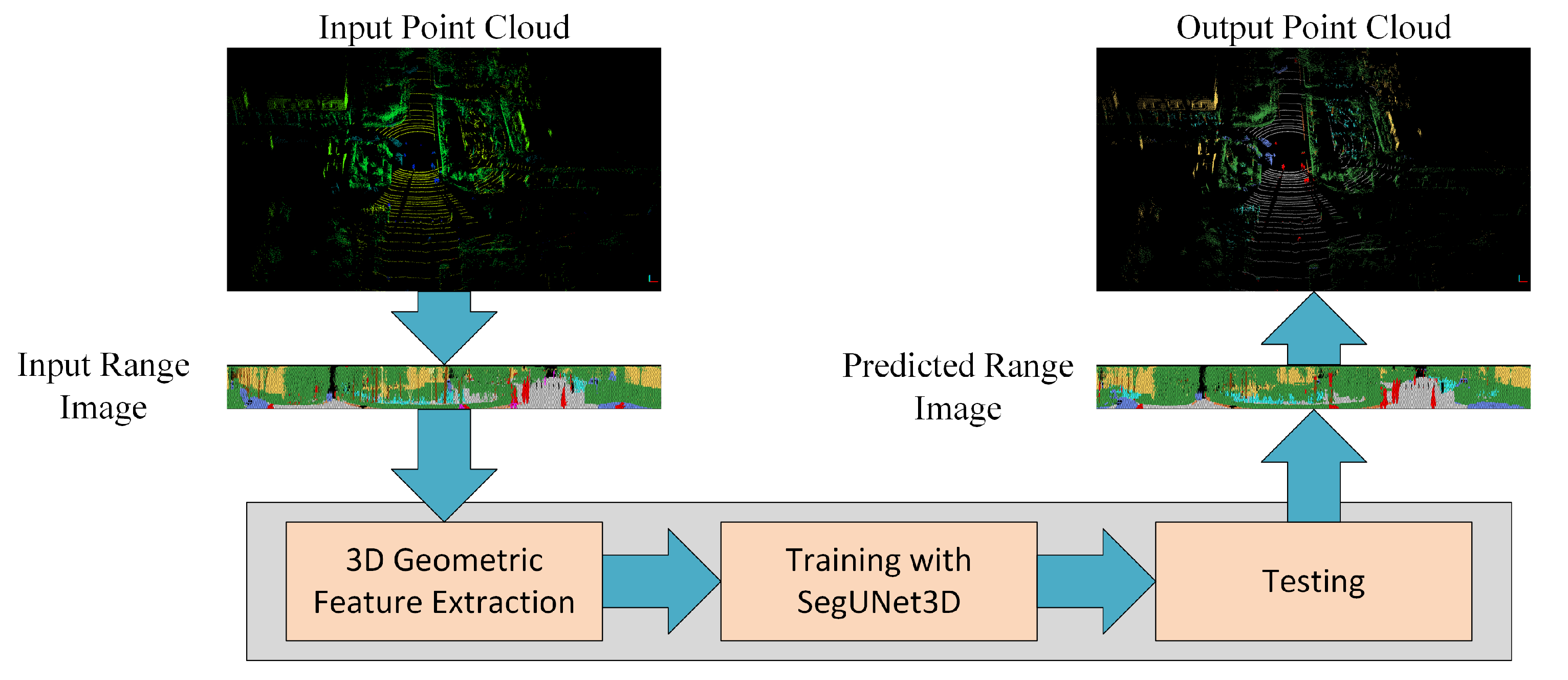
3. Materials and Methods
3.1. Datasets
3.1.1. RELLIS-3D
3.1.2. SemanticPOSS
3.2. Proposed Approach: SegUNet3D
3.2.1. Producing Network Input: Range Images
3.2.2. Extraction of Geometric Features
3.2.3. Review of U-Net
3.2.4. Review of SegNet
3.2.5. Architecture
4. Results and Discussion
4.1. Comparative Experiment Analysis
4.1.1. Effect of Input Image Resolution
4.1.2. Effect of Segment Size
4.1.3. Effect of 3D Geometric Features
4.2. Comparison with State-of-the-Art Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. SqueezeSegV2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a LiDAR point cloud. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar] [CrossRef]
- Biasutti, P.; Lepetit, V.; Aujol, J.F.; Bredif, M.; Bugeau, A. LU-net: An efficient network for 3D LiDAR point cloud semantic segmentation based on end-to-end-learned 3D features and U-net. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Li, S.; Liu, Y.; Gall, J. Rethinking 3-D LiDAR Point Cloud Segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3412–3432. [Google Scholar] [CrossRef] [PubMed]
- Nagy, B.; Benedek, C. 3D CNN-based semantic labeling approach for mobile laser scanning data. IEEE Sens. J. 2019, 19, 10034–10045. [Google Scholar] [CrossRef]
- Atik, M.E.; Duran, Z.; Seker, D.Z. Machine learning-based supervised classification of point clouds using multiscale geometric features. ISPRS Int. J. Geo-Inf. 2021, 10, 187. [Google Scholar] [CrossRef]
- Atik, M.E.; Duran, Z. Classification of Aerial Photogrammetric Point Cloud Using Recurrent Neural Networks. Fresenius Environ. Bull. 2021, 30, 4270–4275. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Griffiths, D.; Boehm, J. A Review on deep learning techniques for 3D sensed data classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Engelmann, F.; Kontogianni, T.; Schult, J.; Leibe, B. Know what your neighbors do: 3D semantic segmentation of point clouds. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2019; Lecture Notes in Computer Science. Volume 11131. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-Net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution on X-transformed points. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing local neighborhood features for point cloud processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2019. [Google Scholar] [CrossRef]
- Zhang, Z.; Hua, B.S.; Yeung, S.K. ShellNet: Efficient point cloud convolutional neural networks using concentric shells statistics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. KPConv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar] [CrossRef]
- Wen, C.; Yang, L.; Li, X.; Peng, L.; Chi, T. Directionally constrained fully convolutional neural network for airborne LiDAR point cloud classification. ISPRS J. Photogramm. Remote Sens. 2020, 162, 50–62. [Google Scholar] [CrossRef]
- Yousefhussien, M.; Kelbe, D.J.; Ientilucci, E.J.; Salvaggio, C. A multi-scale fully convolutional network for semantic labeling of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 191–204. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Wang, Y.; Shi, T.; Yun, P.; Tai, L.; Liu, M. Pointseg: Real-time semantic segmentation based on 3d lidar point cloud. arXiv 2018, arXiv:1807.06288. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), Macau, China, 3–8 November 2019. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-Aware Semantic Segmentation of LiDAR Point Clouds. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020; Lecture Notes in Computer Science. Volume 12510. [Google Scholar] [CrossRef]
- Jiang, P.; Osteen, P.; Wigness, M.; Saripalli, S. RELLIS-3D Dataset: Data, Benchmarks and Analysis. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021. [Google Scholar] [CrossRef]
- Pan, Y.; Gao, B.; Mei, J.; Geng, S.; Li, C.; Zhao, H. SemanticPOSS: A Point Cloud Dataset with Large Quantity of Dynamic Instances. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020. [Google Scholar] [CrossRef]
- Duran, Z.; Ozcan, K.; Atik, M.E. Classification of Photogrammetric and Airborne LiDAR Point Clouds Using Machine Learning Algorithms. Drones 2021, 5, 104. [Google Scholar] [CrossRef]
- West, K.F.; Webb, B.N.; Lersch, J.R.; Pothier, S.; Triscari, J.M.; Iverson, A.E. Context-driven automated target detection in 3D data. In Proceedings of the Automatic Target Recognition XIV, Orlando, FL, USA, 12–16 April 2004; Volume 5426. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Volume 9351. [Google Scholar] [CrossRef]
- Atik, S.O.; Ipbuker, C. Integrating convolutional neural network and multiresolution segmentation for land cover and land use mapping using satellite imagery. Appl. Sci. 2021, 11, 5551. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resolution | U-Net | SegNet | SqueezeSegV2 | PointSeg | SalsaNext | SegUnet3D |
|---|---|---|---|---|---|---|
| 64 × 512 | 29.1 | 34.4 | 25.9 | 25.5 | 21.8 | 35.2 |
| 64 × 1024 | 35.6 | 41.6 | 35.5 | 28.8 | 43.8 | 44.7 |
| 64 × 2048 | 42.7 | 45.0 | 42.4 | 33.2 | 42.0 | 45.7 |
| Resolution | U-Net | SegNet | SqueezeSegV2 | PointSeg | SalsaNext | SegUnet3D |
|---|---|---|---|---|---|---|
| 64 × 512 | 18.5 | 28.5 | 26.5 | 26.0 | 31.3 | 33.3 |
| 64 × 1024 | 23.9 | 29.9 | 29.1 | 29.6 | 32.0 | 30.6 |
| 64 × 2048 | 28.8 | 28.7 | 26.3 | 24.8 | 31.6 | 29.8 |
| Minimum Points | U-Net | SegNet | SqueezeSegV2 | PointSeg | SalsaNext | SegUnet3D |
|---|---|---|---|---|---|---|
| 30 | 35.4 | 40.7 | 35.9 | 29.7 | 38.3 | 42.3 |
| 50 | 35.6 | 41.6 | 35.5 | 28.8 | 43.8 | 44.7 |
| 70 | 33.4 | 41.8 | 35.8 | 30.1 | 39.6 | 41.6 |
| Minimum Points | U-Net | SegNet | SqueezeSegV2 | PointSeg | SalsaNext | SegUnet3D |
|---|---|---|---|---|---|---|
| 30 | 32.9 | 28.8 | 27.8 | 26.7 | 31.0 | 30.0 |
| 50 | 18.5 | 28.5 | 26.5 | 26.0 | 31.3 | 33.3 |
| 70 | 30.9 | 29.5 | 28.4 | 27.9 | 25.2 | 30.3 |
| Feature | U-Net | SegNet | SqueezeSegV2 | PointSeg | SalsaNext | SegUnet3D |
|---|---|---|---|---|---|---|
| Without 3D Geometric Features | 38.1 | 38.6 | 33.3 | 28.5 | 38.6 | 41.4 |
| With 3D Geometric Features | 35.6 | 41.6 | 35.5 | 28.8 | 43.8 | 44.7 |
| Feature | U-Net | SegNet | SqueezeSegV2 | PointSeg | SalsaNext | SegUnet3D |
|---|---|---|---|---|---|---|
| Without 3D Geometric Features | 32.4 | 24.4 | 24.0 | 24.5 | 24.9 | 26.6 |
| With 3D Geometric Features | 18.5 | 28.5 | 26.5 | 26.0 | 31.3 | 33.3 |
| Method | People | Rider | Car | Trunk | Plants | Traffic Sign | Pole | Building | Fence | Bike | Road | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SegNet [34] | 42.6 | 14.8 | 50.3 | 24.5 | 68.2 | 22.3 | 12.4 | 65.9 | 37.0 | 43.6 | 75.7 | 41.6 |
| U-Net [32] | 37.5 | 1.4 | 42.1 | 23.2 | 62.7 | 16.4 | 9.6 | 62.4 | 24.3 | 37.4 | 74.9 | 35.6 |
| SqueezeSegV2 [1] | 28.3 | 2.2 | 42.3 | 13.3 | 67.0 | 13.0 | 10.4 | 63.1 | 32.3 | 40.8 | 77.7 | 35.5 |
| PointSeg [23] | 22.5 | 4.7 | 21.9 | 15.1 | 55.9 | 13.0 | 10.0 | 54.1 | 17.5 | 30.0 | 72.3 | 28.8 |
| SalsaNext [26] | 47.7 | 6.2 | 47.1 | 24.6 | 69.3 | 29.3 | 19.1 | 64.9 | 46.9 | 49.0 | 78.1 | 43.8 |
| SegUnet3D (Ours) | 44.7 | 26.4 | 50.7 | 24.2 | 69.2 | 21.9 | 17.3 | 68.4 | 45.8 | 46.5 | 76.3 | 44.7 |
| Method | Grass | Tree | Pole | Water | Vehicle | Log | Person | Fence | Bush | Concrete | Barrirer | Puddle | Mud | Rubble | mIoU |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SegNet [34] | 67.3 | 74.4 | 0.0 | 0.0 | 4.7 | 0.0 | 78.1 | 0.5 | 75.3 | 58.7 | 43.1 | 2.8 | 2.9 | 0.6 | 29.2 |
| U-Net [32] | 67.6 | 76.4 | 1.4 | 20.0 | 7.6 | 0.1 | 77.5 | 0.6 | 76.3 | 62.0 | 40.6 | 2.5 | 2.1 | 8.5 | 30.2 |
| SqueezeSegV2 [1] | 66.7 | 73.0 | 0.0 | 0.0 | 3.0 | 0.0 | 71.8 | 0.0 | 73.4 | 62.7 | 39.4 | 2.7 | 3.7 | 0.4 | 28.4 |
| PointSeg [23] | 64.1 | 67.2 | 16.0 | 0.0 | 12.3 | 1.1 | 61.3 | 6.0 | 72.2 | 54.9 | 24.9 | 4.4 | 6.6 | 0.0 | 27.9 |
| SalsaNext [26] | 67.3 | 75.5 | 0.0 | 0.0 | 4.1 | 0.0 | 82.6 | 0.2 | 75.3 | 66.8 | 53.3 | 3.8 | 3.8 | 4.7 | 31.3 |
| SegUnet3D (Ours) | 67.6 | 73.9 | 39.8 | 0.0 | 9.3 | 0.0 | 77.5 | 1.1 | 75.5 | 62.2 | 50.5 | 3.1 | 4.7 | 1.4 | 33.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atik, M.E.; Duran, Z. An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images. Sensors 2022, 22, 6210. https://doi.org/10.3390/s22166210
Atik ME, Duran Z. An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images. Sensors. 2022; 22(16):6210. https://doi.org/10.3390/s22166210
Chicago/Turabian StyleAtik, Muhammed Enes, and Zaide Duran. 2022. "An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images" Sensors 22, no. 16: 6210. https://doi.org/10.3390/s22166210