
Visual Detection and Image Processing of Parking Space Based on Deep Learning

Abstract
:1. Introduction
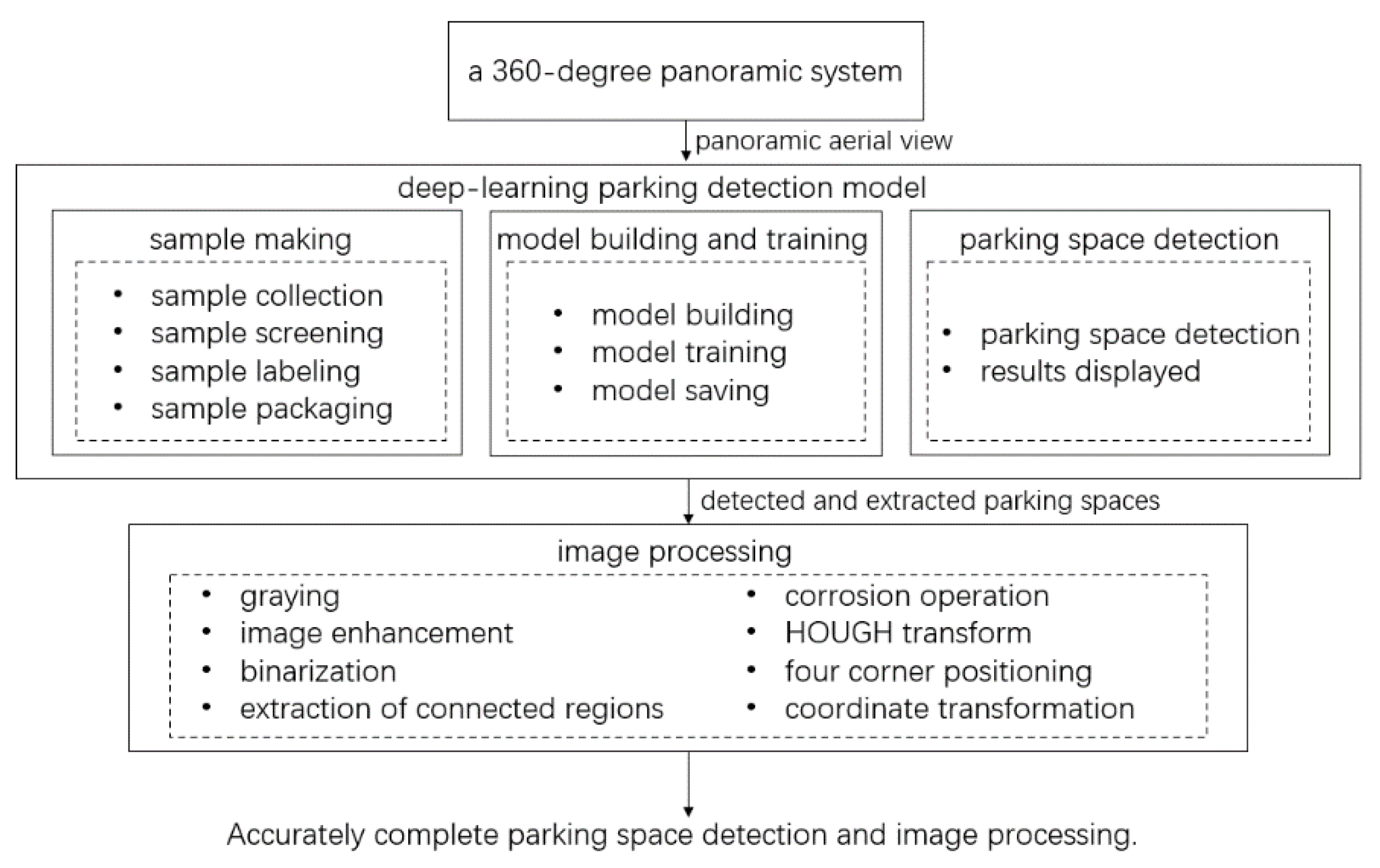
2. Models and Methods
2.1. Fish-Eye Camera Model
2.2. Deep-Learning Parking Detection Model
- (1)
- Firstly, a feature layer can be obtained by using the convolutional neural network to extract the features of the input original image;
- (2)
- Secondly, the RPN network replaces the traditional selective search algorithm to nominate candidate regions;
- (3)
- Thirdly, the nominated area is judged to contain the target. The location and size of the target box are adjusted as well;
- (4)
- Finally, further regression adjustment is carried out for the candidate area classification and target box position and size.
2.3. Image Processing
2.3.1. Graying
2.3.2. Image Enhancement
2.3.3. Binarization
2.3.4. Extraction of Connected Regions
2.3.5. Corrosion Operation
2.3.6. Hough Transform
2.3.7. Location Coordinate Transformation
3. Experiment and Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jeong, S.H.; Choi, C.G.; Oh, J.N.; Yoon, P.J.; Kim, B.S.; Kim, M.; Lee, K.H. Low cost design of parallel parking assist system based on an ultrasonic sensor. Int. J. Automot. Technol. 2010, 11, 409–416. [Google Scholar] [CrossRef]
- Reddy, V.; Laxmeshwar, S.R. Design and Development of Low Cost Automatic Parking Assistance System. Int. Conf. Inf. Commun. Technol. 2014, 975, 8887. [Google Scholar]
- Wang, W.; Song, Y.; Zhang, J.; Deng, H. Automatic parking of vehicles: A review of literatures. Int. J. Automot. Technol. 2014, 15, 967–978. [Google Scholar] [CrossRef]
- Khan, S.D.; Ullah, H. A survey of advances in vision-based vehicle re-identification. Comput. Vis. Image Underst. 2019, 182, 50–63. [Google Scholar] [CrossRef]
- Heimberger, M.; Horgan, J.; Hughes, C.; McDonald, J.; Yogamani, S. Computer vision in automated parking systems: Design, Implementation and challenges. Image Vis. Comput. 2017, 68, 88–101. [Google Scholar] [CrossRef]
- Forsyth, D. Object Detection with Discriminatively Trained Part-Based Models. Computer 2014, 47, 6–7. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Suhr, J.K.; Jung, H.G. End-to-End Trainable One-Stage Parking Slot Detection Integrating Global and Local Information. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4570–4582. [Google Scholar] [CrossRef]
- Nemec, D.; Hrubos, M.; Gregor, M.; Bubeníková, E. Visual Localization and Identification of Vehicles Inside a Parking House. Procedia Eng. 2017, 192, 632–637. [Google Scholar] [CrossRef]
- Ma, Y.; Liu, Y.; Shao, S.; Zhao, J.; Tang, J. Review of Research on Vision-Based Parking Space Detection Method. Int. J. Web Serv. Res. 2022, 19, 61. [Google Scholar] [CrossRef]
- Yu, Z.; Gao, Z.; Chen, H.; Huang, Y. SPFCN: Select and Prune the Fully Convolutional Networks for Real-time Parking Slot Detection. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020. [Google Scholar]
- Sairam, B.; Agrawal, A.; Krishna, G.; Sahu, S.P. Automated Vehicle Parking Slot Detection System Using Deep Learning. In Proceedings of the 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 11–13 March 2020. [Google Scholar]
- Zhang, L.; Lin, L.; Liang, X.; He, K. Is Faster R-CNN Doing Well for Pedestrian Detection. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Zhou, H.; Zhang, H.; Hasith, K.; Wang, H. Real-time Robust Multi-lane Detection and Tracking in Challenging Urban Scenarios. In Proceedings of the IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM), Toyonaka, Japan, 3–5 July 2019. [Google Scholar]
- Gopalan, R.; Hong, T.; Shneier, M.; Chellappa, R. A Learning Approach towards Detection and Tracking of Lane Markings. Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1088–1098. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Yang, M.; Wang, X.; Ye, L.; Guo, C. Automatic Parking Based on a Bird’s Eye View Vision System. Adv. Mech. Eng. 2014, 6, 847406. [Google Scholar] [CrossRef]
- Shen, Y.; Xiao, T.; Li, H.; Yi, S.; Wang, X. Learning Deep Neural Networks for Vehicle Re-ID with Visual-spatio-temporal Path Proposals. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; IEEE Computer Society: Piscataway, NJ, USA, 2017. [Google Scholar]
- Li, Y.; Li, Y.; Yan, H.; Liu, J. Deep joint discriminative learning for vehicle re-identification and retrieval. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017. [Google Scholar]
- Huang, F.; Wang, Y.; Shen, X.; Lin, C.; Chen, Y. Method for calibrating the fisheye distortion center. Appl. Opt. 2012, 51, 8169–8176. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Salvador, A.; Giro-I-Nieto, X.; Marques, F.; Satoh, S. Faster R-CNN Features for Instance Search. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; IEEE Computer Society: Piscataway, NJ, USA, 2016. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, H.; Hou, X. The Precise Location Algorithm of License Plate Based on Gray Image. In Proceedings of the International Conference on Computer Science & Service System, Nanjing, China, 11–13 August 2012; IEEE Computer Society: Piscataway, NJ, USA, 2012. [Google Scholar]
- Zhu, R.; Wang, Y. Application of Improved Median Filter on Image Processing. J. Comput. 2012, 7, 838–841. [Google Scholar] [CrossRef]
- Cheng, Y.; Yue, G. Application of Convolutional Neural Network Technology in Vehicle Parking Management. In Proceedings of the CSAE 2021: The 5th International Conference on Computer Science and Application Engineering, Sanya, China, 19–21 October 2021. [Google Scholar]
- Fu, Y.; Lu, S.; Li, K.; Liu, C.; Cheng, X.; Zhang, H. An experimental study on burning behaviors of 18650 lithium ion batteries using a cone calorimeter. J. Power Sources 2015, 273, 216–222. [Google Scholar] [CrossRef]
- Yao, L.; Liu, Z.; Wang, B. 2D-to-3D conversion using optical flow based depth generation and cross-scale hole filling algorithm. Multimedia Tools Appl. 2018, 78, 10543–10564. [Google Scholar] [CrossRef]
- Lopez, C.F. Characterization of Lithium-Ion Battery Thermal Abuse Behavior Using Experimental and Computational Analysis. J. Electrochem. Soc. 2015, 162, A2163–A2173. [Google Scholar] [CrossRef]
- Zhao, R.; Liu, J.; Gu, J. Simulation and experimental study on lithium ion battery short circuit. Appl. Energy 2016, 173, 29–39. [Google Scholar] [CrossRef]
- Vera, E.; Lucio, D.; Fernandes, L.; Velho, L. Hough Transform for real-time plane detection in depth images. Pattern Recognit. Lett. 2018, 103, 8–15. [Google Scholar] [CrossRef]
- Gonzalez, D.; Zimmermann, T.; Nagappan, N. The State of the ML-universe: 10 Years of Artificial Intelligence & Machine Learning Software Development on GitHub. In Proceedings of the MSR ’20: 17th International Conference on Mining Software Repositories, Seoul, Korea, 29–30 June 2020. [Google Scholar]
- Çiçek, E.; Gören, S. Fully automated roadside parking spot detection in real time with deep learning. Concurrency Computat Pract Exper. 2021, 33, e6006. [Google Scholar] [CrossRef]
- Bazzaza, T.; Chen, Z.; Prabha, S.; Tohidypour, H.R.; Wang, Y.; Pourazad, M.T.; Nasiopoulos, P.; Leung, V.C. Automatic Street Parking Space Detection Using Visual Information and Convolutional Neural Networks. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 7–9 January 2022; pp. 1–2. [Google Scholar] [CrossRef]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware Equipment | Model Specifications | Amount |
|---|---|---|
| graphics card | NVIDIA GeForce GTX 1060 (6G VRAM) | 1 |
| CPU processor | Intel Core i5-3470 | 1 |
| memory stick 1 | Kingston DDR3 (8G memory) | 1 |
| memory stick 2 | Kingston DDR3 (4G memory) | 1 |
| Parameter | Sensitive Interval |
|---|---|
| parking line clarity | 0–32% |
| the proportion of white area | 61–100% |
| the angle between the vehicle and the parking space | / |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.; Yang, S.; Luo, Y.; Wang, Y.; Liu, Z. Visual Detection and Image Processing of Parking Space Based on Deep Learning. Sensors 2022, 22, 6672. https://doi.org/10.3390/s22176672
Huang C, Yang S, Luo Y, Wang Y, Liu Z. Visual Detection and Image Processing of Parking Space Based on Deep Learning. Sensors. 2022; 22(17):6672. https://doi.org/10.3390/s22176672
Chicago/Turabian StyleHuang, Chen, Shiyue Yang, Yugong Luo, Yongsheng Wang, and Ze Liu. 2022. "Visual Detection and Image Processing of Parking Space Based on Deep Learning" Sensors 22, no. 17: 6672. https://doi.org/10.3390/s22176672