
Research on Lane Changing Game and Behavioral Decision Making Based on Driving Styles and Micro-Interaction Behaviors



Abstract
:1. Introduction
1.1. Introduction and Related Work
1.2. Contribution
1.3. Paper Organization
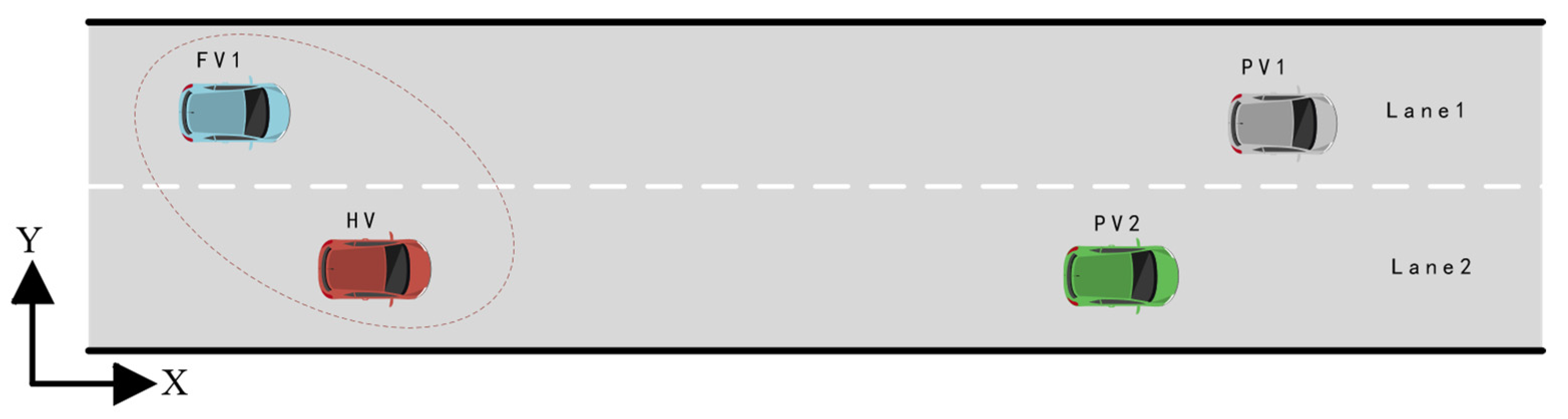
2. Problem Formulation and System Construction
- It is assumed that the vehicles studied in this paper are all AVs and have been equipped with complete onboard sensors and wireless communication modules (i.e., V2V and V2I technologies) to obtain rich information about the surrounding vehicles motion status and road environment.
- Only the acceleration and deceleration behaviors of surrounding vehicles are considered, and their lane-changing behaviors are not considered.
- The vehicles studied are all cars, excluding other types such as trucks and motorcycles.
3. Mathematical Modeling of Lane-Changing Decision
3.1. Game Formulation
3.2. Definition of Cost Function
3.3. Solution of the Game
4. Controller Design Based on Driving Risk Field
4.1. Vehicle Kinematic Modeling
4.2. Driving Risk Field Modeling
4.2.1. Risk Field of an Obstacle Vehicle
4.2.2. Risk Field of an Obstacle Vehicle
4.3. DRF-Based MPC Controller
5. Testing and Results Analysis
5.1. Parameters Setting
5.2. Test Scenario A
5.3. Test Scenario B
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, J.; Zheng, H.; Zong, C. Longitudinal and lateral dynamics control of automatic lane change system. Trans. Inst. Meas. Control 2019, 41, 4322–4338. [Google Scholar] [CrossRef]
- González, D.; Pérez, J.; Milanés, V.; Nashashibi, F. A review of motion planning techniques for automated vehicles. IEEE Trans. Intell. Transp. 2015, 17, 1135–1145. [Google Scholar] [CrossRef]
- Furda, A.; Vlacic, L. Enabling safe autonomous driving in real-world city traffic using multiple criteria decision making. IEEE Intel. Transp. Syst. 2011, 3, 4–17. [Google Scholar] [CrossRef]
- Bai, H.; Cai, S.; Ye, N.; Hsu, D.; Lee, W.S. Intention-aware online POMDP planning for autonomous driving in a crowd. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 454–460. [Google Scholar]
- Ulbrich, S.; Maurer, M. Situation assessment in tactical lane change behavior planning for automated vehicles. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 975–981. [Google Scholar]
- Li, L.; Ota, K.; Dong, M. Humanlike driving: Empirical decision-making system for autonomous vehicles. IEEE Tran. Veh. Technol. 2018, 67, 6814–6823. [Google Scholar] [CrossRef]
- You, C.; Lu, J.; Filev, D.; Tsiotras, P. Highway traffic modeling and decision making for autonomous vehicle using reinforcement learning. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1227–1232. [Google Scholar]
- Naranjo, J.E.; Gonzalez, C.; Garcia, R.; De Pedro, T. Lane-change fuzzy control in autonomous vehicles for the overtaking maneuver. IEEE Trans. Intell. Transp. 2008, 9, 438–450. [Google Scholar] [CrossRef]
- Vacek, S.; Gindele, T.; Zollner, J.M.; Dillmann, R. Using case-based reasoning for autonomous vehicle guidance. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, San Diego, CA, USA, 29 October–2 November 2007; pp. 4271–4276. [Google Scholar]
- Yang, Q.; Koutsopoulos, H.N. A microscopic traffic simulator for evaluation of dynamic traffic management systems. Transport. Res. C-EMER 1996, 4, 113–129. [Google Scholar] [CrossRef]
- Brand, M.; Oliver, N.; Pentland, A. Coupled hidden markov models for complex action recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition(CVPR), San Juan, PR, USA, 17–19 June 1997; pp. 994–999. [Google Scholar]
- Yu, H.; Tseng, H.E.; Langari, R. A human-like game theory-based controller for automatic lane changing. Transport. Res. C-EMER 2018, 88, 140–158. [Google Scholar] [CrossRef]
- Wang, M.; Hoogendoorn, S.P.; Daamen, W.; van Arem, B.; Happee, R. Game theoretic approach for predictive lane-changing and car-following control. Transport. Res. C-EMER 2015, 58, 73–92. [Google Scholar] [CrossRef]
- Yoo, J.H.; Langari, R. Stackelberg game based model of highway driving, Dynamic Systems and Control Conference. In Proceedings of the ASME Dynamic Systems and Control Conference joint with JSME Motion and Vibration Conference, Fort Lauderdale, FL, USA, 17–19 October 2012; pp. 499–508. [Google Scholar]
- Arbis, D.D.; Dixit, V.V. Game theoretic model for lane changing: Incorporating conflict risks. Accid. Anal. Prev. 2019, 125, 158–164. [Google Scholar] [CrossRef]
- Sun, D.J.; Kondyli, A. Modeling Vehicle Interactions during Lane-Changing Behavior on Arterial Streets. Comput. Civ. Infrastruct. Eng. 2010, 25, 557–571. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. Int. J. Rob. Res. 1986, 2, 396–404. [Google Scholar]
- Lin-heng, L.; Jing, G.; Xu, Q.; Pei-pei, M.; Bin, R. Car-following model based on safety potential field theory under connected and automated vehicle environment. China J. Highw. Transp. 2019, 32, 76. [Google Scholar]
- Ji, J.; Khajepour, A.; Melek, W.W.; Huang, Y. Path planning and tracking for vehicle collision avoidance based on model predictive control with multiconstraints. IEEE Trans. Veh. Technol. 2016, 66, 952–964. [Google Scholar] [CrossRef]
- Rasekhipour, Y.; Khajepour, A.; Chen, S.-K.; Litkouhi, B. A potential field-based model predictive path-planning controller for autonomous road vehicles. IEEE Trans. Intell. Transp. 2016, 18, 1255–1267. [Google Scholar] [CrossRef]
- Vanlaar, W.; Simpson, H.; Mayhew, D.; Robertson, R. Aggressive driving: A survey of attitudes, opinions and behaviors. J. Saf. Res. 2008, 39, 375–381. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Filev, D.; Tseng, H.E.; Szwabowski, S.; Langari, R. Addressing mandatory lane change problem with game theoretic model predictive control and fuzzy Markov chain. In Proceedings of the Annual American Control Conference (ACC), Milwaukee, WI, USA, 27–29 June 2018; pp. 4764–4771. [Google Scholar]
- Nash, J. Non-cooperative games. Ann. Math. 1951, 54, 286–295. [Google Scholar] [CrossRef]
- Hang, P.; Huang, C.; Hu, Z.; Lv, C. Driving Conflict Resolution of Autonomous Vehicles at Unsignalized Intersections: A Differential Game Approach. arXiv 2022, arXiv:2201.01424. [Google Scholar] [CrossRef]
- Von Stackelberg, H. Market Structure and Equilibrium; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Myerson, R.B. Nash equilibrium and the history of economic theory. J. Econ. Lit. 1999, 37, 1067–1082. [Google Scholar] [CrossRef]
- Papavassilopoulos, G.; Cruz, J. Nonclassical control problems and Stackelberg games. IEEE Trans. Auto. Contr. 1979, 24, 155–166. [Google Scholar] [CrossRef]
- Sinha, A.; Malo, P.; Deb, K.J. Efficient evolutionary algorithm for single-objective bilevel optimization. arXiv 2013, arXiv:1303.3901. [Google Scholar]
- Yang, S.; Wang, Z.; Zhang, H. Kinematic model based real-time path planning method with guide line for autonomous vehicle. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 990–994. [Google Scholar]
- Tu, Q.; Chen, H.; Li, J. A potential field based lateral planning method for autonomous vehicles. SAE Int. J. Passeng. Cars—Electron. Electr.Syst. 2017, 10, 24–35. [Google Scholar] [CrossRef]
- Li, H.; Wu, C.; Chu, D.; Lu, L.; Cheng, K. Combined trajectory planning and tracking for autonomous vehicle considering driving styles. IEEE Access 2021, 9, 9453–9463. [Google Scholar] [CrossRef]
- Li, B.-B.; Wang, L.; Liu, B. An effective PSO-based hybrid algorithm for multiobjective permutation flow shop scheduling. Trans.-SMCA 2008, 38, 818–831. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decision Making | HV | ||
|---|---|---|---|
| Change Lanes | Stay | ||
| FV | |||
| Stackelberg Game | DRF | ||||||
|---|---|---|---|---|---|---|---|
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| 0.2 | 1 × 10−5 | 2 | 1.7 | ||||
| 8 × 103 | 20 | 15 | 4.4 | ||||
| 0.2 | [−3,5] | 1 | 2.2 | ||||
| 8 × 103 | 30 | 1.8 | 0.5 | ||||
| 0.4 | - | - | 10 | 10 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, M.; Li, P.; Yang, Z.; Liu, Y. Research on Lane Changing Game and Behavioral Decision Making Based on Driving Styles and Micro-Interaction Behaviors. Sensors 2022, 22, 6729. https://doi.org/10.3390/s22186729
Ye M, Li P, Yang Z, Liu Y. Research on Lane Changing Game and Behavioral Decision Making Based on Driving Styles and Micro-Interaction Behaviors. Sensors. 2022; 22(18):6729. https://doi.org/10.3390/s22186729
Chicago/Turabian StyleYe, Ming, Pan Li, Zhou Yang, and Yonggang Liu. 2022. "Research on Lane Changing Game and Behavioral Decision Making Based on Driving Styles and Micro-Interaction Behaviors" Sensors 22, no. 18: 6729. https://doi.org/10.3390/s22186729
APA StyleYe, M., Li, P., Yang, Z., & Liu, Y. (2022). Research on Lane Changing Game and Behavioral Decision Making Based on Driving Styles and Micro-Interaction Behaviors. Sensors, 22(18), 6729. https://doi.org/10.3390/s22186729