
Acne Detection by Ensemble Neural Networks


Abstract
:1. Introduction
2. Related Work
2.1. Acne Grading
2.2. Acne Detection
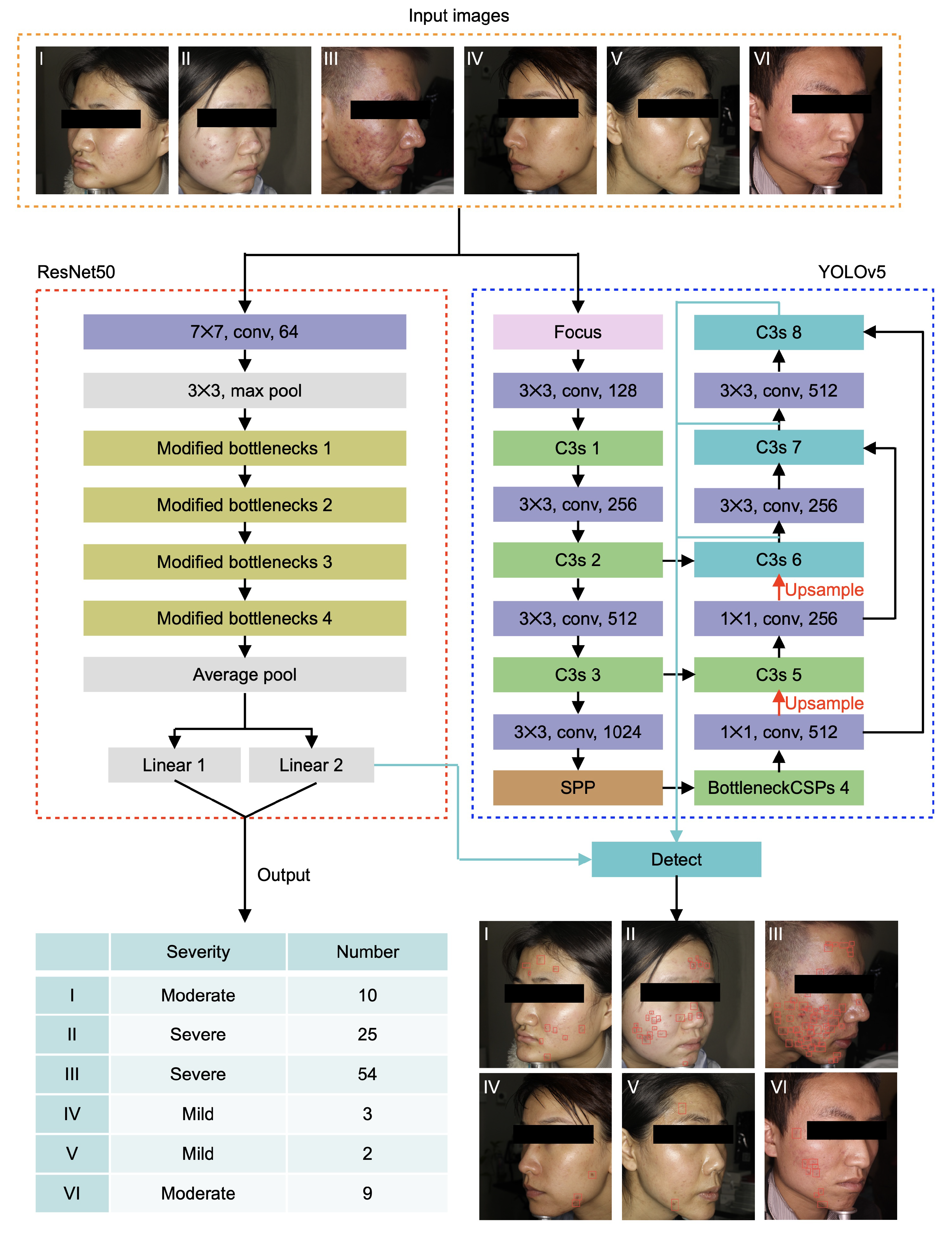
3. Materials and Methods
3.1. Data Preparation
3.2. Classification Module
- (1)
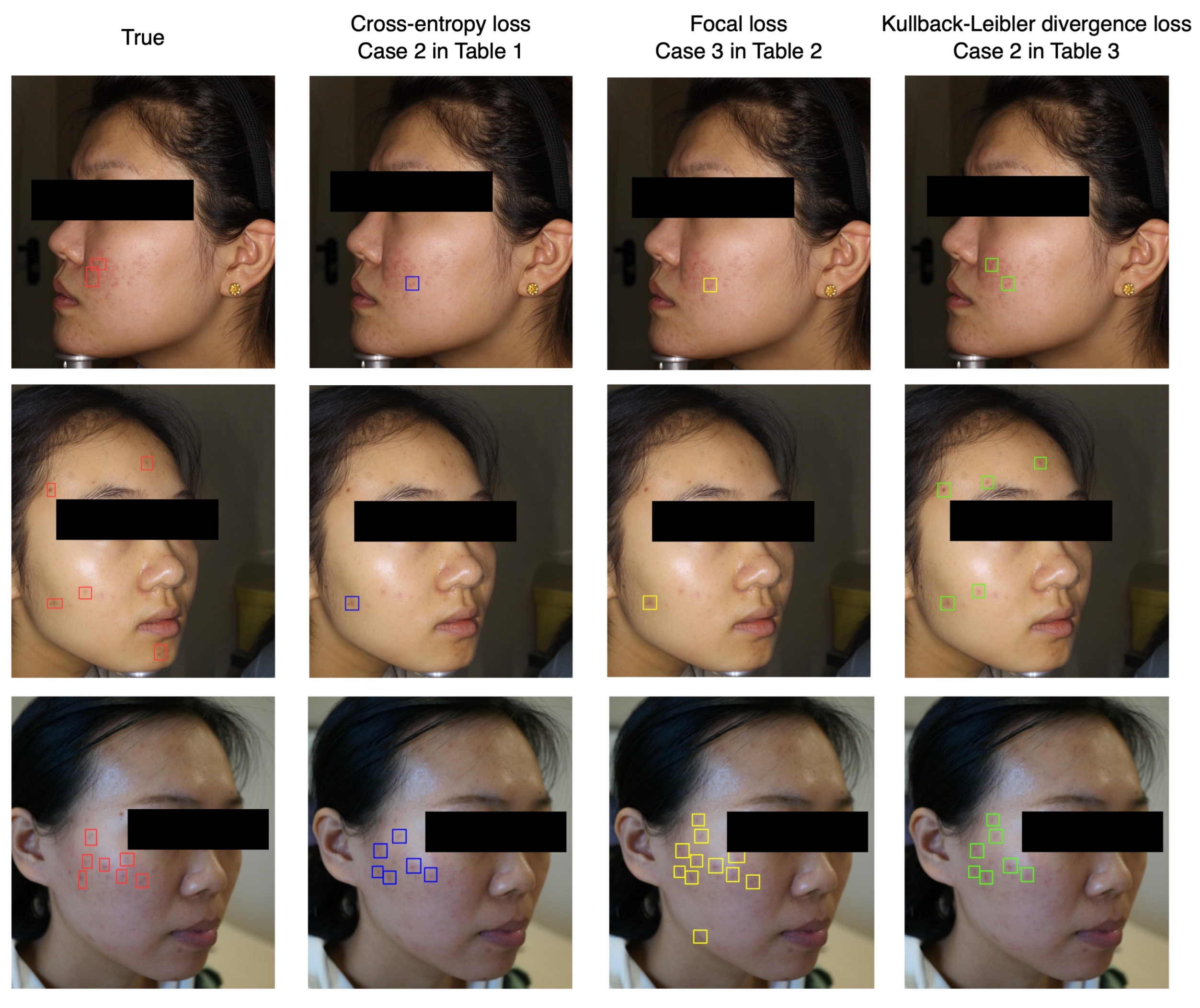
- Considering that the main task here is to calculate the acne severity and number, we adopt a cross-entropy loss function, which is very useful when training a classification problem with several classes. The loss function can be written as:where N denotes the total image numbers and M denotes the total class numbers (i.e., 4 and 65 for severity and number, respectively). Coefficient is a rescaling weight given to each category and is particularly useful when the data distribution is very uneven. Characters and denote the calculated and true probability that the image i belongs to category j, respectively. Typically, is a Kronecker-like function and can be written as:
- (2)
- Although the number of images in different severity classes is similar, the sample size varies widely in the categories with different acne numbers. Focal loss [53], a loss function aiming to handle the problem of category imbalance, would be helpful for the prediction of acne numbers. Similar to the cross-entropy loss, focal loss tries to make the model pay more attention to the samples, which are hard to classify by changing the sample weights. Furthermore, the function expression can be written as:where is a manual parameter named the focusing parameter, which is not smaller than 0. Different from the cross-entropy loss, the additional coefficient , named the modulating factor, could effectively reduce the loss contribution from the samples which are easy to classify. Note that when is equal to zero, the focal loss will degenerate to the cross-entropy loss. Specifically, when image i does not belong to categories j, would be small while the modulating factor is close to 1, showing little influence on the loss. On the contrary, if the image is well classified, would be close to 1, and the modulating factor becomes very small. By tuning the hyperparameters and , we can optimize the training process of the model.
- (3)
- Another common strategy is to transform this classification problem into a regression problem. Inspired by label distribution learning [54,55,56,57,58,59,60,61,62], Wu et al. introduced Kullback–Leibler divergence loss to train the ResNet50 [47]. The general expression of the loss function can be written as:where and are calculated and predicted continuous probability distribution of the image category. Note that the Kullback–Leibler divergence loss can be taken as a variant of the traditional cross-entropy loss. For example, if the probability is strictly set to zero when image i does not belong to category j, probability distribution would become a one-hot vector. We adopt the Normal distribution to generate the label distribution, and the expression can be written as:where the expectation is the true category number and the standard deviation is set to 3.
3.3. Localization Module
4. Results
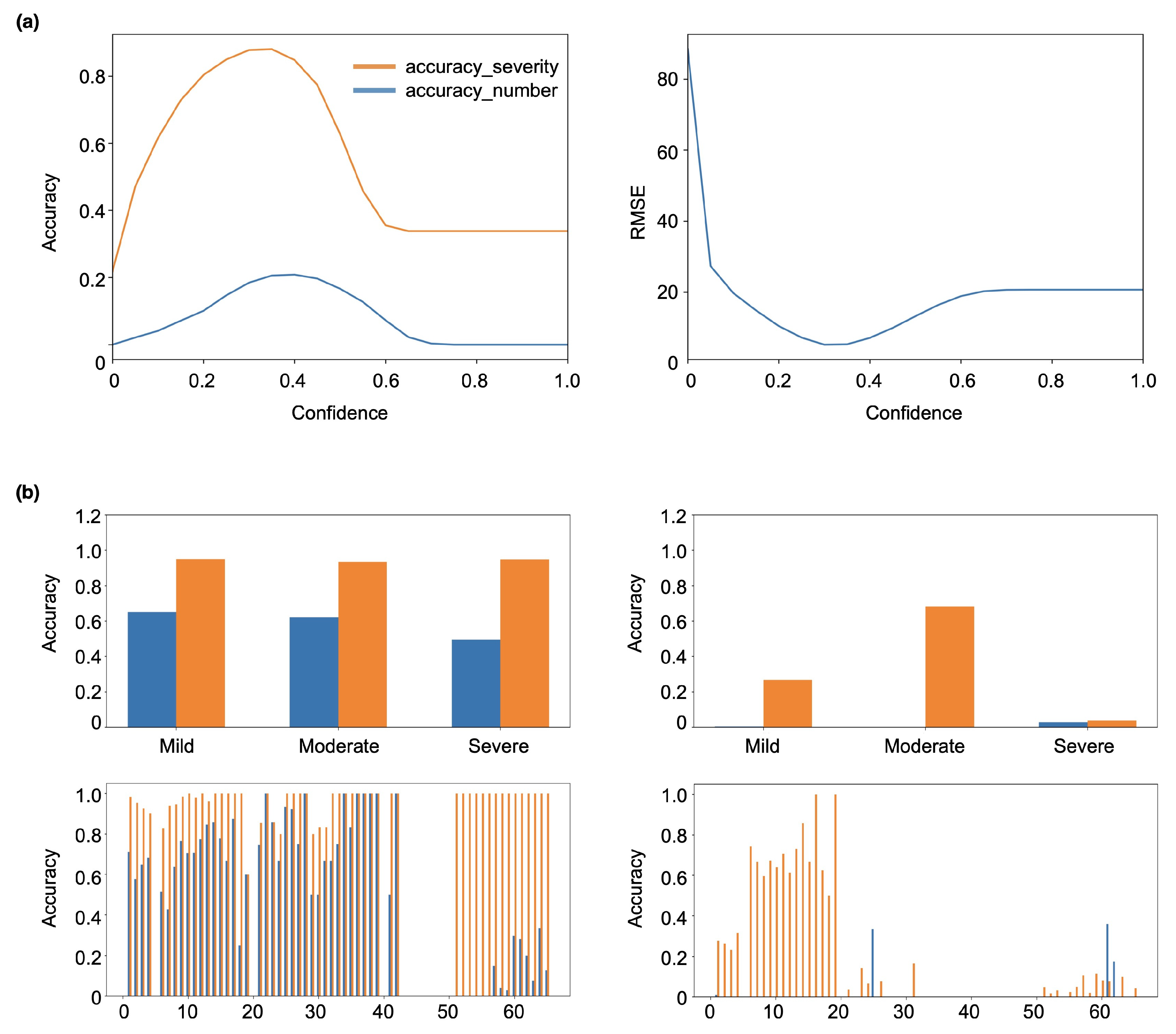
4.1. Training and Evaluation
4.2. Analyses of Classification and Localization Modules
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W.T. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pritt, M.; Chern, G. Satellite image classification with deep learning. In Proceedings of the 2017 IEEE Applied Imagery Pattern Recognition Workshop, Washington, DC, USA, 10–12 October 2017; pp. 1–7. [Google Scholar]
- Al-Saffar, A.A.M.; Tao, H.; Talab, M.A. Review of deep convolution neural network in image classification. In Proceedings of the 2017 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications, Jakarta, Indonesia, 23–24 October 2017; pp. 26–31. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Affonso, C.; Rossi, A.L.D.; Vieira, F.H.A.; de Leon Ferreira, A.C.P. Deep learning for biological image classification. Expert Syst. Appl. 2017, 85, 114–122. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Algan, G.; Ulusoy, I. Image classification with deep learning in the presence of noisy labels: A survey. Knowl.-Based Syst. 2021, 215, 106771. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE international conference on computer vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.-B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In Proceedings of the Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; pp. 2802–2810. [Google Scholar]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep cnn denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3929–3938. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4539–4547. [Google Scholar]
- Hoang, V.-D.; Tran, D.-P.; Nhu, N.G.; Pham, T.-A.; Pham, V.-H. Deep feature extraction for panoramic image stitching. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Phuket, Thailand, 23–26 March 2020; pp. 141–151. [Google Scholar]
- Zhao, Q.; Ma, Y.; Zhu, C.; Yao, C.; Feng, B.; Dai, F. Image stitching via deep homography estimation. Neurocomputing 2021, 450, 219–229. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, M. Panoramic image stitching using double encoder–decoders. Comput. Sci. 2021, 2, 81. [Google Scholar] [CrossRef]
- Hu, G.; Yang, Y.; Yi, D.; Kittler, J.; Christmas, W.; Li, S.Z.; Hospedales, T. When face recognition meets with deep learning: An rvaluation of convolutional neural networks for face recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Association, Singleton, Australia, 7–11 September 2015. [Google Scholar]
- Ge, M.; Su, F.; Zhao, Z.; Su, D. Deep learning analysis on microscopic imaging in materials science. Mater. Today Nano 2020, 11, 100087. [Google Scholar] [CrossRef]
- Ziletti, A.; Kumar, D.; Scheffler, M.; Ghiringhelli, L.M. Insightful classification of crystal structures using deep learning. Nat. Commun. 2018, 9, 2775. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, H.; Xiang, X.; Wang, X. Layer thickness measurement of the TRISO-coated particle based on U-Net. NDT E Int. 2021, 121, 102468. [Google Scholar] [CrossRef]
- Bhuvaneswari, V.; Priyadharshini, M.; Deepa, C.; Balaji, D.; Rajeshkumar, L.; Ramesh, M. Deep learning for material synthesis and manufacturing systems: A review. Mater. Today Proc. 2021, 46, 3263–3269. [Google Scholar] [CrossRef]
- Ramasamy, J.; Pundhir, S.; Narayanan, S.; Ramadass, S.; Aswin, S.; Suresh, A. Deep learning for material synthesis and pose estimation material systems: A review. Mater. Today Proc. 2021; in press. [Google Scholar] [CrossRef]
- Chun, S.; Roy, S.; Nguyen, Y.T.; Choi, J.B.; Udaykumar, H.S.; Baek, S.S. Deep learning for synthetic microstructure generation in a materials-by-design framework for heterogeneous energetic materials. Sci. Rep. 2020, 10, 13307. [Google Scholar] [CrossRef]
- Ma, W.; Cheng, F.; Liu, Y. Deep-learning-enabled on-demand design of chiral metamaterials. ACS Nano 2018, 12, 6326–6334. [Google Scholar] [CrossRef]
- Kollmann, H.T.; Abueidda, D.W.; Koric, S.; Guleryuz, E.; Sobh, N.A. Deep learning for topology optimization of 2D metamaterials. Mater. Des. 2020, 196, 109098. [Google Scholar] [CrossRef]
- Hou, Z.; Zhang, P.; Ge, M.; Li, J.; Tang, T.; Shen, J.; Li, C. Metamaterial reverse multiple prediction method based on deep learning. Nanomaterials 2021, 11, 2672. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Zhou, X.; Luo, Y.; Zhang, H.; Yang, H.; Ma, J.; Ma, L. Opportunities and challenges: Classification of skin disease based on deep learning. Chin. J. Mech. Eng. 2021, 34, 112. [Google Scholar] [CrossRef]
- Li, L.-F.; Wang, X.; Hu, W.-J.; Xiong, N.N.; Du, Y.-X.; Li, B.-S. Deep learning in skin disease image recognition: A review. IEEE Access 2020, 8, 208264–208280. [Google Scholar] [CrossRef]
- Liu, Y.; Jain, A.; Eng, C.; Way, D.H.; Lee, K.; Bui, P.; Kanada, K.; de Oliveira Marinho, G.; Gallegos, J.; Gabriele, S.; et al. A deep learning system for differential diagnosis of skin diseases. Nat. Med. 2020, 26, 900–908. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Pan, Y.; Zhao, J.; Zhang, L. Skin disease diagnosis with deep learning: A review. Neurocomputing 2021, 464, 364–393. [Google Scholar] [CrossRef]
- Srinivasu, P.N.; SivaSai, J.G.; Ijaz, M.F.; Bhoi, A.K.; Kim, W.; Kang, J.J. Classification of skin disease using deep learning neural networks with mobilenet v2 and lstm. Sensors 2021, 21, 2852. [Google Scholar] [CrossRef]
- Goceri, E. Skin disease diagnosis from photographs using deep learning. In Proceedings of the ECCOMAS Thematic Conference on Computational Vision and Medical Image Processing, Porto, Portugal, 16–18 October 2019; pp. 239–246. [Google Scholar]
- Rashataprucksa, K.; Chuangchaichatchavarn, C.; Triukose, S.; Nitinawarat, S.; Pongprutthipan, M.; Piromsopa, K. Acne detection with deep neural networks. In Proceedings of the 2020 2nd International Conference on Image Processing and Machine Vision, Chongqing, China, 10–12 July 2020; pp. 53–56. [Google Scholar]
- Yang, Y.; Guo, L.; Wu, Q.; Zhang, M.; Zeng, R.; Ding, H.; Zheng, H.; Xie, J.; Li, Y.; Ge, Y.; et al. Construction and evaluation of a deep learning model for assessing acne vulgaris using clinical images. Dermatol. Ther. 2021, 11, 1239–1248. [Google Scholar] [CrossRef]
- Seité, S.; Khammari, A.; Benzaquen, M.; Moyal, D.; Dréno, B. Development and accuracy of an artificial intelligence algorithm for acne grading from smartphone photographs. Exp. Dermatol. 2019, 2, 1252–1257. [Google Scholar] [CrossRef]
- Wu, X.; Wen, N.; Liang, J.; Lai, Y.-K.; She, D.; Cheng, M.-M.; Yang, J. Joint acne image grading and counting via label distribution learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10642–10651. [Google Scholar]
- Shen, X.; Zhang, J.; Yan, C.; Zhou, H. An automatic diagnosis method of facial acne vulgaris based on convolutional neural network. Sci. Rep. 2018, 8, 5839. [Google Scholar] [CrossRef]
- Lim, Z.V.; Akram, F.; Ngo, C.P.; Winarto, A.A.; Lee, H.K. Automated grading of acne vulgaris by deep learning with convolutional neural networks. Ski. Res. Technol. 2019, 26, 187–192. [Google Scholar] [CrossRef] [PubMed]
- Min, K.; Lee, G.-H.; Lee, S.-W. Acnet: Mask-aware attention with dynamic context enhancement for robust acne detection. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics, Melbourne, Australia, 17–20 October 2021; pp. 2724–2729. [Google Scholar]
- Hayashi, N.; Akamatsu, H.; Kawashima, M.; Acne Study Group. Establishment of grading criteria for acne severity. J. Dermatol. 2008, 35, 255–260. [Google Scholar] [PubMed]
- Liu, S.; Fan, Y.; Duan, M.; Wang, Y.; Su, G.; Ren, Y.; Huang, L.; Zhou, F. AcneGrader: An ensemble pruning of the deep learning base models to grade acne. Ski. Res. Technol. 2022. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Geng, X.; Wang, Q.; Xia, Y. Facial age estimation by adaptive label distribution learning. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 4465–4470. [Google Scholar]
- Gao, B.-B.; Xing, C.; Xie, C.-W.; Wu, J.; Geng, X. Deep label distribution learning with label ambiguity. IEEE Trans. Image Process. 2017, 26, 2825–2838. [Google Scholar] [CrossRef]
- Geng, X. Label distribution learning. IEEE Trans. Knowl. Data Eng. 2016, 28, 1734–1748. [Google Scholar] [CrossRef]
- Wang, J.; Geng, X.; Xue, H. Re-weighting large margin label distribution learning for classification. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5445–5459. [Google Scholar] [CrossRef]
- Luo, J.; He, B.; Ou, Y.; Li, B.; Wang, K. Topic-based label distribution learning to exploit label ambiguity for scene classification. Neural Comput. Appl. 2021, 33, 16181–16196. [Google Scholar] [CrossRef]
- Wang, J.; Geng, X. Label distribution learning machine. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 10749–10759. [Google Scholar]
- Chen, S.; Wang, J.; Chen, Y.; Shi, Z.; Geng, X.; Rui, Y. Label distribution learning on auxiliary label space graphs for facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Luo, J.; Wang, Y.; Ou, Y.; He, B.; Li, B. Neighbor-based label distribution learning to model label ambiguity for aerial scene classification. Remote. Sens. 2021, 13, 755. [Google Scholar] [CrossRef]
- Jing, W.; Geng, X. Classification with label distribution learning. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3712–3718. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy_Severity | Accuracy_Number | RMSE_Count | |
|---|---|---|---|
| Case 1 | 90.67% | 6.18% | 10.54 |
| Case 2 | 95.06% | 21.48% | 9.07 |
| Accuracy_Severity | Accuracy_Number | RMSE_Count | |
|---|---|---|---|
| Case 1 | 99.45% | 25.88% | 11.70 |
| Case 2 | 43.44% | 11.81% | 19.91 |
| Case 3 | 99.45% | 16.00% | 7.93 |
| Case 4 | 21.35% | 0% | 34.90 |
| Case 5 | 99.45% | 14.76% | 8.42 |
| Accuracy_Severity | Accuracy_Number | RMSE_Count | |
|---|---|---|---|
| Case 1 | 99.31% | 84.60% | 2.74 |
| Case 2 | 99.17% | 84.17% | 2.17 |
| F-RCNN | 73.97% | 3.39 | |
| YOLOv3 | 63.70% | 3.37 | |
| Wu et al. | 84.11% | 2.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Ma, T. Acne Detection by Ensemble Neural Networks. Sensors 2022, 22, 6828. https://doi.org/10.3390/s22186828
Zhang H, Ma T. Acne Detection by Ensemble Neural Networks. Sensors. 2022; 22(18):6828. https://doi.org/10.3390/s22186828
Chicago/Turabian StyleZhang, Hang, and Tianyi Ma. 2022. "Acne Detection by Ensemble Neural Networks" Sensors 22, no. 18: 6828. https://doi.org/10.3390/s22186828
APA StyleZhang, H., & Ma, T. (2022). Acne Detection by Ensemble Neural Networks. Sensors, 22(18), 6828. https://doi.org/10.3390/s22186828