

Low-Light Image Enhancement Using Hybrid Deep-Learning and Mixed-Norm Loss Functions
Abstract
:1. Introduction
2. Proposed Method
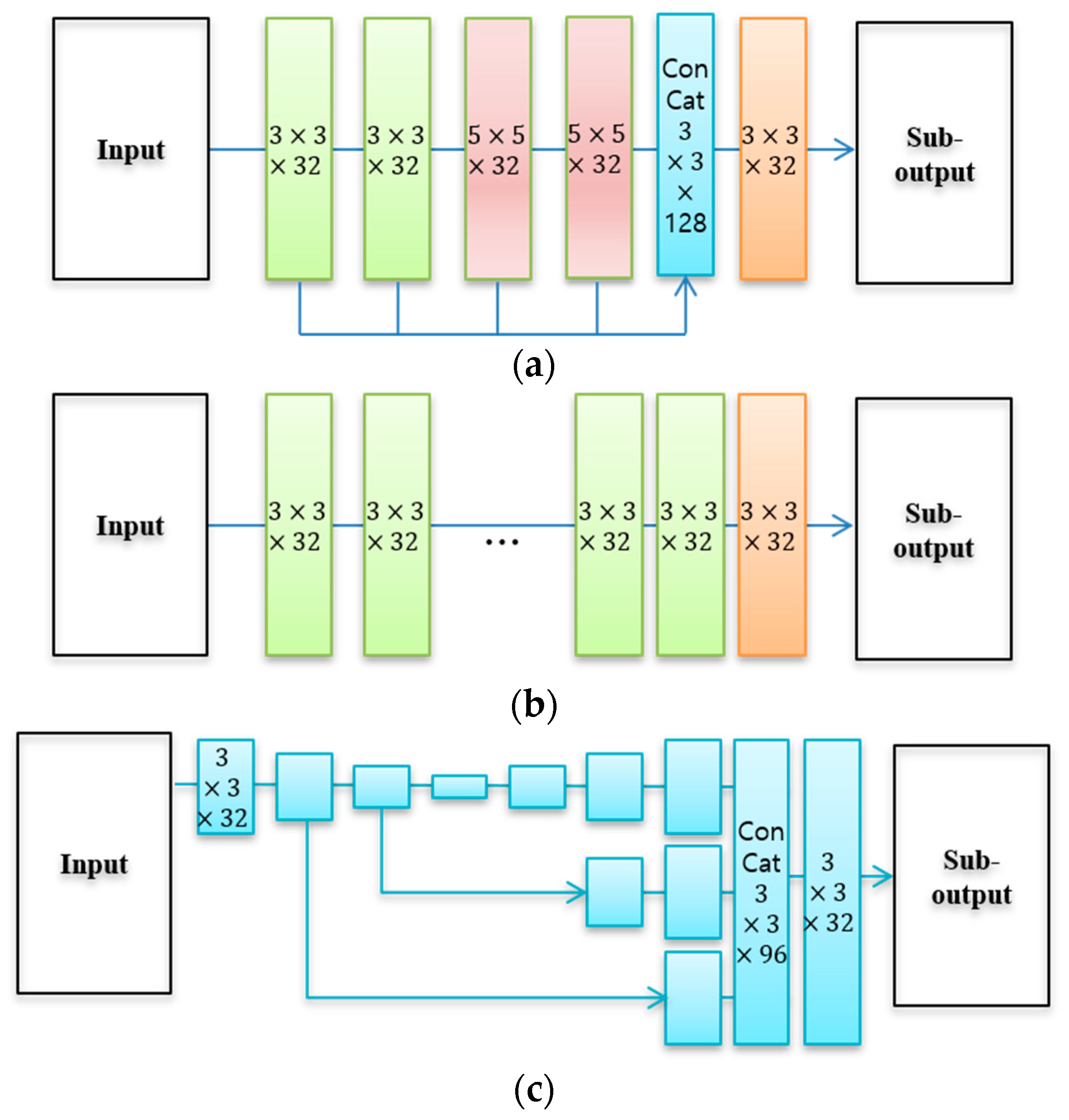
2.1. Hybrid Deep-Learning Structure
2.2. Mixed Norm-Based Loss Function
3. Experimental Results
3.1. Experimental Setup
- (1)
- gamma correction: ,
- (2)
- random spray Gaussian noise: random spray ratio (0.01%) and Gaussian std. .
3.2. Analyses of Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chien, J.-C.; Chen, Y.-S.; Lee, J.-D. Improving night time driving safety using vision-based classification techniques. Sensors 2017, 17, 10. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Wu, X.; Yuan, X.; Gao, Z. An experimental-based review of low-light image enhancement methods. IEEE Access 2020, 8, 87884–87917. [Google Scholar] [CrossRef]
- Land, E.; McCann, J. Lightness and retinex theory. J. Opt. Soc. Am. 1971, 61, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Jobson, D.; Woodell, G. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Rahman, Z.; Jobson, D.; Woodell, G. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 16–19 September 1996; pp. 1003–1006. [Google Scholar]
- Jobson, D.; Rahman, Z.; Woodell, G. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Provenzi, E.; Fierro, M.; Rizzi, A.; Carli, L.D.; Gadia, D.; Marini, D. Random spray retinex: A new retinex implementation to investigate the local properties of the model. IEEE Trans. Image Process. 2007, 16, 162–171. [Google Scholar] [CrossRef]
- Banic, N.; Loncaric, S. Light random spray retinex: Exploiting the noisy illumination estimation. IEEE Signal Process. Lett. 2013, 20, 1240–1243. [Google Scholar] [CrossRef]
- Celik, T. Spatial Entropy-Based Global and Local Image Contrast Enhancement. IEEE Trans. Image Process. 2014, 23, 5209–5308. [Google Scholar] [CrossRef]
- Shin, Y.; Jeong, S.; Lee, S. Efficient naturalness restoration for non-uniform illuminance images. IET Image Process. 2015, 9, 662–671. [Google Scholar] [CrossRef]
- Lecca, M.; Rizzi, A.; Serapioni, R.P. GRASS: A gradient-based random sampling scheme for Milano retinex. IEEE Trans. Image Process. 2017, 26, 2767–2780. [Google Scholar] [CrossRef] [Green Version]
- Simone, G.; Audino, G.; Farup, I.; Albregtsen, F.; Rizzi, A. Termite retinex: A new implementation based on a colony of intelligent agents. J. Electron. Imaging 2014, 23, 013006. [Google Scholar] [CrossRef]
- Dou, Z.; Gao, K.; Zhang, B.; Yu, X.; Han, L.; Zhu, Z. Realistic image rendition using a variable exponent functional model for retinex. Sensors 2017, 16, 832. [Google Scholar] [CrossRef]
- Kimmel, R.; Elad, M.; Sobel, I. A variational framework for retinex. Int. J. Comput. Vis. 2003, 52, 7–23. [Google Scholar] [CrossRef]
- Zosso, D.; Tran, G.; Osher, S.J. Non-local retinex-A unifying framework and beyond. SIAM J. Imaging Sci. 2015, 8, 787–826. [Google Scholar] [CrossRef]
- Park, S.; Yu, S.; Moon, B.; Ko, S.; Paik, J. Low-light image enhancement using variational optimization-based retinex model. IEEE Trans. Consum. Electron. 2017, 63, 178–184. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. MSR-net: Low-light image enhancement using deep convolutional network. arXiv 2017, arXiv:171102488. [Google Scholar]
- Guo, C.; Li, Y.; Ling, H. Lime: Low-light image enhancement via illuminance map estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:180804560. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-light image/video enhancement using CNNs. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; pp. 1–13. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 15 October 2019; pp. 1632–1640. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Kim, B.; Lee, S.; Kim, N.; Jang, D.; Kim, D.-S. Learning color representation for low-light image enhancement. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1455–1463. [Google Scholar]
- Oh, J.-G.; Hong, M.-C. Adaptive image rendering using a nonlinear mapping-function-based retinex model. Sensors 2019, 19, 969. [Google Scholar] [CrossRef]
- Kinoshita, Y.; Kiya, H. Convolutional neural networks considering local and global features for image enhancement. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar] [CrossRef] [Green Version]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Shahbaz, F.; Yang, M.-H.; Shao, L. Learning enriched features for real image restoration and enhancement. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 492–511. [Google Scholar]
- Anwar, S.; Barnes, N.; Petersson, L. Attention-based real image restoration. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2016, 26, 3142–3155. [Google Scholar] [CrossRef]
- Kingman, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:14126980v9. [Google Scholar]
- Sheikh, H.R.; Wang, Z.; Cormack, L.; Bovik, A.C. Live Image Quality Assessment Database Release 2. The Univ. of Texas at Austin. 2005. Available online: https://live.ece.utexas.edu/research/Quality/subjective.htm (accessed on 23 March 2022).
- Stanford Vision Lab. ImageNet. 2016. Available online: http://image-net.org (accessed on 18 May 2022).
- NASA Langley Research Center. Available online: https://dragon.larc.nasa.gov (accessed on 17 November 2021).
- Arbelaez, P.; Fowlkes, C.; Martin, D. The Berkeley Segmentation Dataset and Benchmark. 2007. Available online: https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/bsds/ (accessed on 7 February 2022).
- Wang, S.; Zheng, J.; Hu, H.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef]
- Venkatanath, N.; Praneeth, D.; Chandrasekhar, B.H.; Channappayya, S.S.; Medasani, S.S. Blind image quality evaluation using perception based features. In Proceedings of the 21st National Conference on Communications (NCC), Mumbai, India, 27 February–1 March 2015. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Peli, E. Contrast in complex images. J. Opt. Soc. Am. A 1990, 7, 2032–2040. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluator | Ground Truth | Degraded Image | MSR- Net [18] | Retinex- Net [20] | MBLLEN [21] | KinD [22] | Proposed Method | |
|---|---|---|---|---|---|---|---|---|
| with reference | N/A | 8.69 | 15.88 | 17.64 | 19.60 | 20.14 | 22.01 | |
| N/A | 0.547 | 0.800 | 0.766 | 0.823 | 0.873 | 0.897 | ||
| N/A | 282.90 | 210.94 | 374.09 | 202.57 | 327.84 | 208.04 | ||
| N/A | 0.366 | 0.508 | 0.451 | 0.556 | 0.613 | 0.656 | ||
| 36.94 | 39.83 | 37.60 | 47.47 | 47.41 | 51.17 | 30.96 | ||
| CPP | 35.98 | 15.07 | 29.36 | 47.50 | 25.82 | 30.03 | 31.27 | |
| without reference | N/A | 33.25 | 31.06 | 39.25 | 52.65 | 46.17 | 24.02 | |
| CPP | N/A | 13.93 | 19.64 | 35.66 | 14.44 | 20.01 | 20.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, J.; Hong, M.-C. Low-Light Image Enhancement Using Hybrid Deep-Learning and Mixed-Norm Loss Functions. Sensors 2022, 22, 6904. https://doi.org/10.3390/s22186904
Oh J, Hong M-C. Low-Light Image Enhancement Using Hybrid Deep-Learning and Mixed-Norm Loss Functions. Sensors. 2022; 22(18):6904. https://doi.org/10.3390/s22186904
Chicago/Turabian StyleOh, JongGeun, and Min-Cheol Hong. 2022. "Low-Light Image Enhancement Using Hybrid Deep-Learning and Mixed-Norm Loss Functions" Sensors 22, no. 18: 6904. https://doi.org/10.3390/s22186904
APA StyleOh, J., & Hong, M.-C. (2022). Low-Light Image Enhancement Using Hybrid Deep-Learning and Mixed-Norm Loss Functions. Sensors, 22(18), 6904. https://doi.org/10.3390/s22186904