
TNT Loss: A Technical and Nontechnical Generative Cooperative Energy Loss Detection System
Abstract
:1. Introduction
2. Materials and Methods
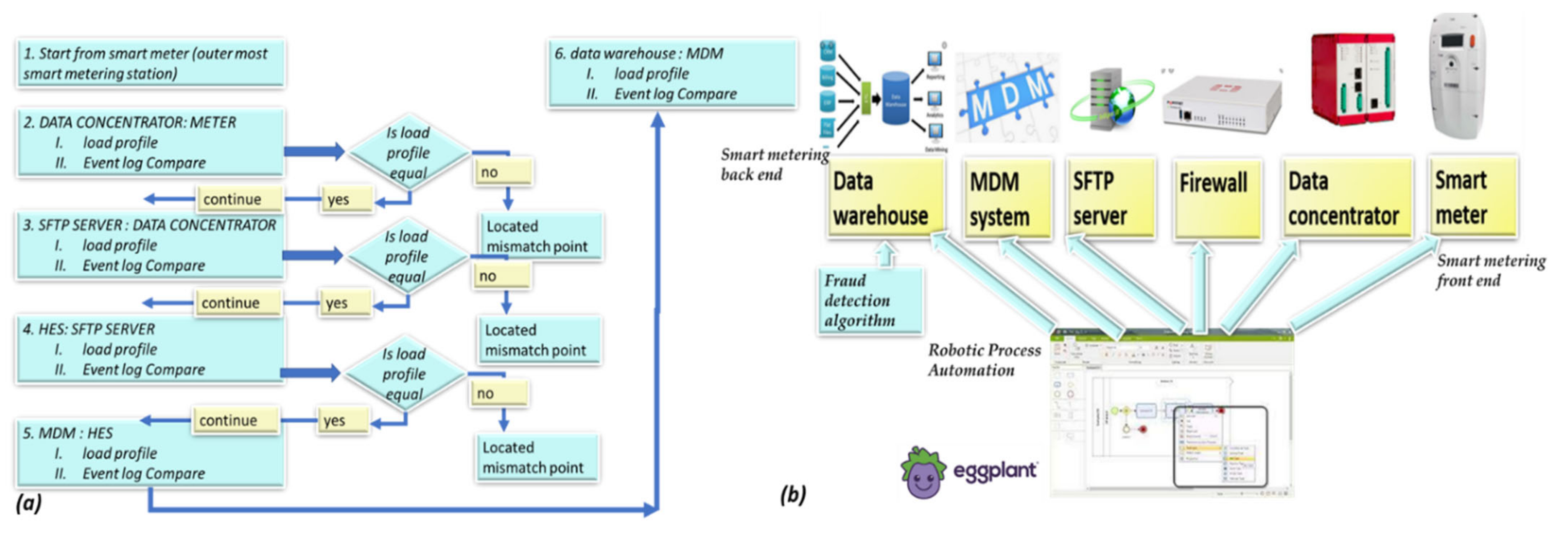
2.1. An Introduction to the System’s Architecture
2.2. A Variable Algorithm Suitable for Various Local Dataset Sizes
2.3. A Holistic Multi Loss Type—An Algorithm System Instead of an Algorithm: Generative Cooperative Modules
2.4. Module 4: Decision Making, Probability Computation Prior to Sending a Technical/Nontechnical Loss Detection Team to the Field
- denotes a specific meter event or assertion rule set at Module 1, the “generator”
- denotes any of the meter events or assertion rules is set
- denotes a decision to send the team to the field for inspection
- = denotes the TNT loss event
- denotes the probability decision that it is a TNT loss
- —a logical operator and not being an event type from the following types:
- —“not a data mismatch anomaly” ∩
- —“not a preventive maintenance anomaly” (part of technical losses) ∩ ”
- —“not a cyberattack anomaly” ∩ customer information: “customer is not from high socioeconomic status” ∩ “customer is not abroad” ∩ “customer is not from town with a low fraud rate” ∩ “not super-consumption” ∩
- “events from the smart meter included”—magnetic tampering and front-panel opening.
- where the count of no events is from the total anomaly count and not from the entire specific customer count.
- —event in which a customer with a “specific TNT loss type signature” from ∪ groups (i), i = 1,2..., N.
2.5. A Holistic Technical/Nontechnical Loss Detection System—An Ever-Learning Algorithm—GCN-like Architecture
2.6. A Robotic Process Automation (RPA) System to ASSIST in Information Loss that Looks Similar to Energy Loss Detection
2.7. Data Augmentation of Verified Frauds to Fill in the AI Requirement of Scenarios
2.8. The Pooling Mechanism—Second Top Architecture after GCN to Enable Loss Classification
2.9. Consumption or Universal Expert Knowledge-Based Generated Features
2.9.1. Expert Feature 1: Energetic Distribution from the Load Profile
- is the number of load-profile periods counted with energy that is inside the bin [.
- is the entire load-profile period count, which is a summation over all bins of period counts. It is not the entire energy, is.
- is a limit continuous function of the series at the point when the periods count N becomes infinite and the bins split, becomes zero.
- is the continuous version of the distribution function according to the energy parameter.

2.9.2. Expert Feature 2: Daily Spectral Energy Distribution
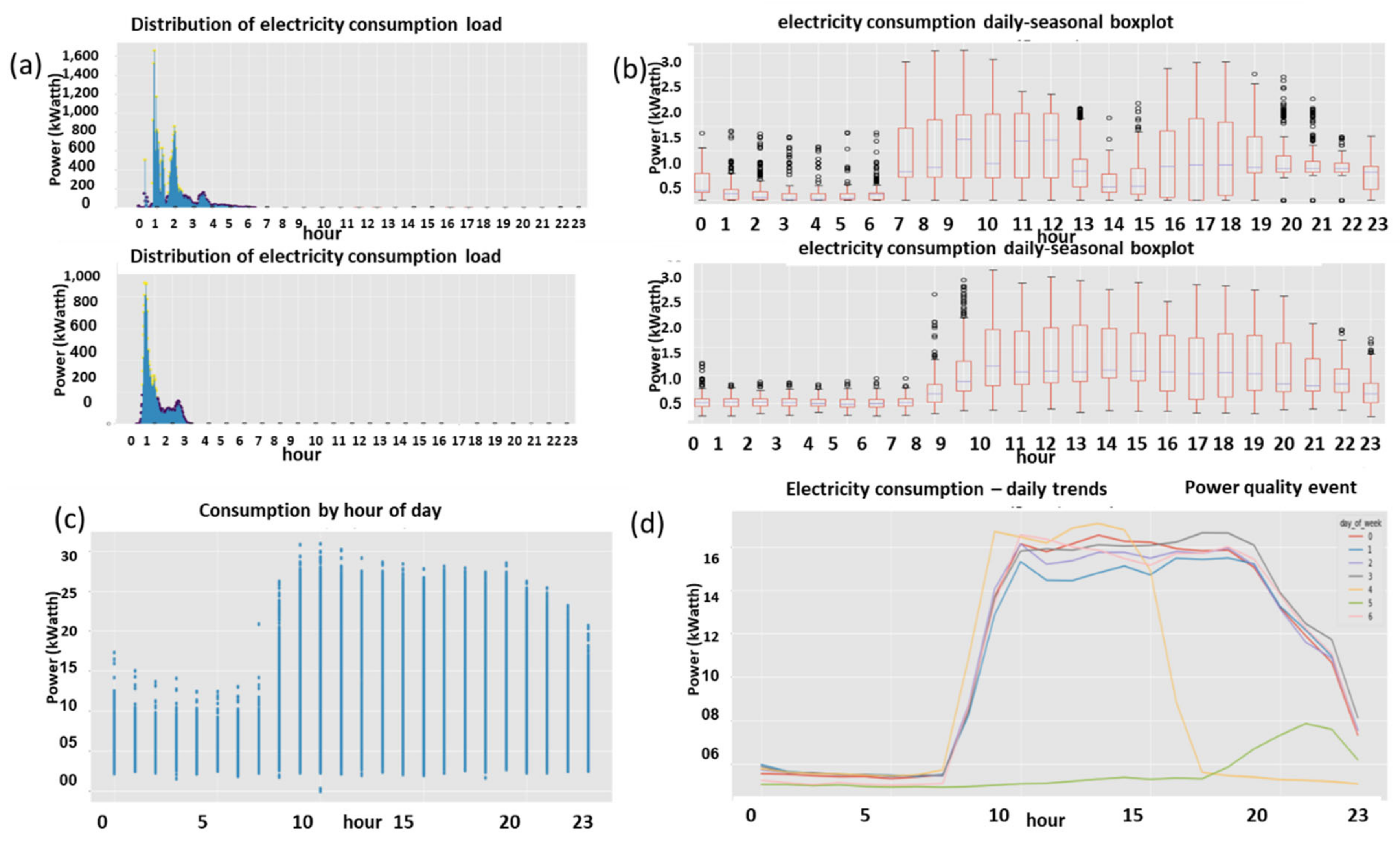
2.9.3. Expert Feature 3: Daily-Hourly Trend Graphs:
2.9.4. Expert Feature 4: Boxplot Hourly Seasonal Trends Acting as a 2D Object Identification System
2.10. Insertion of the Reactive Load Profile to the Learning Space and Comparison to the Active Load Profile
2.10.1. Expert Features: Reactive Load Profile vs. Active Load Profile for Distribution of a High-Order Dimensional and PCA 3D Space
2.10.2. Expert Feature 5: A “Six-Dimensional” Energy Distribution Space—Reactive vs. Active Energy
- is the peak amplitude parameter, is the central frequency,
- is the width, K is the Gaussian count, and is the normal distribution
2.10.3. Expert Feature 6: Active vs. Reactive Daily-Hourly Trends
- denotes collaborative distance measurements between two daily curves ,
- denotes energetic daily-hourly curves illustrated in Section 2.9.3.
- —for Christian-based weeks {Monday-Friday} for Muslim-based weeks {Saturday-Wednesday} and for Jewish-based weeks {Sunday-Thursday}. In general, not including weekends.
- denotes max-pooling over all combinations of daily trends.
2.10.4. Expert Feature 7: Active vs. Reactive Boxplot “Hourly Seasonal” Trends
2.10.5. Expert Feature 8: Active vs. Reactive Pearson Correlation Heatmap
2.10.6. Expert Feature 9: Reactive vs. Active PCA 3D of All Collaborative Features
2.11. A Computational Study on the Effect of Features Space on Training Effort and Accuracy
2.11.1. Forward
2.11.2. Computation of the Mix-Up Probability of Two Event Clusters
- denotes the standard deviation of
- denotes the forecast object instance
- denotes the actual object instance
2.11.3. The Probability of Mix-Up when Classification or Clustering Goes to N Object Types
2.12. Generative Cooperative Modules Theory
2.13. Generative Cooperative Module Theory Applied to Technical Nontechnical Loss Detection—A Classification Problem with a Generator and Discriminator
- denotes the normalization constant to reflect the distribution function.
- is the reference distribution common to all loss types.
- denotes the scoring function for a class Y of {loss type, loss location} conditioned with unknown parameters to be learned
- D denotes the dimensionality of {loss type, loss location}.
- denotes the distribution variance.
- is the vector of the loss type, such as “phase disconnect”.
3. Results
3.1. A Comparative Experimental Study of the Proposed Expert Knowledge Preprocessor with Various Clustering Algorithms Compared to Other Works
3.2. Detection of Ten Technical/Nontechnical Losses and Faults Using TNT
3.3. Test Case 1: Power Quality Events
3.4. Test Case 2: Magnetic Tampering
3.5. Test Case 3: A Single Phase Disconnects
3.6. Test Case 4: Smart Metering Data Chain Failure—Load Profile with Gaps
3.7. Test Case 5: A Meter Internal Multiplication Factor Attenuation
3.8. Demonstration of the Robustness of Expert Features to TNT Loss Determination
3.9. A comparative Study of Smart Metering Failures and Technical/Nontechnical Loss Events—Can They Be Differentiated
- (i)
- Recognition-like AI of the graphs. Two failures occurring in the field out of many in a stable smart metering system are compared to fraud and non-fraud to determine whether separability between anomaly types is possible. Figure 26 shows characteristic signature graphs. It may be understood that non-fraud and no anomaly are separable. Data mismatch failure (i. 1). The daily-hourly trends (1-a) look much messier than the remaining cases. (i. 2) The seasonal-hourly trends (1-c to 1-f)—if the boxplots are considered without outliers, then the “wavy” nature is broken into a discontinuous shape in Q1, Q2, and Q4. This is unique to anomaly (1). (i. 3) The outliers indicate anomalies for cases (1)–(3).
- (ii)
- Observing case (2)—meter internal attenuated due to a firmware bug during the daily time sync by the server network time protocol (SNTP). (ii. 1) The daily-hourly patterns (2-a) are not ordered, but they are the tidiest among all anomalies. Because the consumption pattern is not violated, (ii. 2) the outliers (2-c to 2-f indicate an anomaly, (ii. 3) the energy consumption distribution (2-b) is smaller than the fraud, (ii. 4.) the variance between quadrants Q1–Q4 (2-c to2-f) is much sharper than in the fraud case. There are sub-consumption outliers below the boxplots similar to regular consumption (2-c to 2-f), unique to case (2).
- (iii)
- Observing the fraud in case (3) is easily separable from cases (1) and (2).
- (iv)
- Finally, in case (3), the daily-hourly trends (3-a) are messier than (4-a, 2-a). The outliers (3-c to 3-f) indicate anomalies and are much more intense than in case (2). The energy consumption (3-b) is larger in the case of fraud than in case (2). The quadrants Q2, Q4, and Q3 boxplots (3-c to 3-f) look similar. The boxplot wave is smooth and not wavy. There is no need to implement all these rules using the software. The classifier and feature space should use them.
3.10. Techno-Economic Impact Analysis and Its Implied Future Research
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RPA | Robotic process automation |
| GCN | Generative cooperative networks |
| GCM | Generative cooperative (AI) modules (classical not deep neural networks) |
| GAN | Generative adversarial network |
| TNT losses | Technical nontechnical losses |
| NEW_FL | Tagging a group of new untagged failures |
| Word2Vec | an NLP library converting from text to vector |
| SAP ERP | Systems applications and products in data processing, enterprise resource planning |
| a universal billing system | |
| EUT | Equipment under test |
| RDP | Remote desktop protocol |
| OCR | Optical character recognition |
| MDM | Meter data management system |
| WFM | Workforce management system |
| NLP | Natural language processing |
| HES | Head end system |
| PLC | Power line carrier communication method |
| PCA | Principal component analysis |
| DWH | Data warehouse |
| TALEND | “Data integrity and governance” system |
References
- Calamaro, N.; Beck, Y.; Ben Melech, R.; Shmilovitz, D. An Energy-Fraud Detection-System Capable of Distinguishing Frauds from Other Energy Flow Anomalies in an Urban Environment. Sustainability 2021, 13, 10696. [Google Scholar] [CrossRef]
- Li, J.; Wang, F. Non-Technical Loss Detection in Power Grids with Statistical Profile Images Based on Semi-Supervised Learning. Sensors 2020, 20, 236. [Google Scholar] [CrossRef] [PubMed]
- Jin, W.; Zhang, S.; Sun, B.; Jin, P.; Li, Z. An Analytical Investigation of Anomaly Detection Methods Based on Sequence to Sequence Model in Satellite Power Subsystem. Sensors 2022, 22, 1819. [Google Scholar] [CrossRef] [PubMed]
- Utomo, D.; Hsiung, P.-A. A Multitiered Solution for Anomaly Detection in Edge Computing for Smart Meters. Sensors 2020, 20, 5159. [Google Scholar] [CrossRef] [PubMed]
- Smart Meter Reading Method. European Union Document by Regulatory Organization. European Forum for Energy, Business Information eXchange; ebIX: Atlanta, GA, USA, 2017. [Google Scholar]
- Emanuel, A.E. Power Definitions and the Physical Mechanism of Power Flow, 1st ed.; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- De Souza, M.A.; Pereira, J.L.R.; De Alves, G.O.; De Oliveira, B.C.; Melo, I.D.; Garcia, P.A.N. Detection and identification of energy theft in advanced metering infrastructures. Electr. Power Syst. Res. 2020, 182, 106258. [Google Scholar] [CrossRef]
- Cárdenas, A.A.; Amin, S.; Schwartz, G.; Dong, R.; Sastry, S. A game theory model for electricity theft detection and privacy-aware control in AMI systems. In Proceedings of the 50th Annual Allerton Conference on Community Control and Computers (Allerton), Monticello, IL, USA, 1–5 October 2012; pp. 1830–1837. [Google Scholar]
- Yan, Z.; Wen, H. Performance Analysis of Electricity Theft Detection for the Smart Grid: An Overview. IEEE Trans. Instrum. Meas. 2021, 71, 2502928. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Processing Syst. 2014, 27. [Google Scholar]
- Aslam, Z.; Ahmed, F.; Almogren, A.; Shafiq, M.; Zuair, M.; Javaid, N. An Attention Guided Semi-Supervised Learning Mechanism to Detect Electricity Frauds in the Distribution Systems. IEEE Access 2020, 8, 221767–221782. [Google Scholar] [CrossRef]
- Gong, X.; Tang, B.; Zhu, R.; Liao, W.; Song, L. Data Augmentation for Electricity Theft Detection Using Conditional Variational Auto-Encoder. Energies 2020, 13, 4291. [Google Scholar] [CrossRef]
- Xie, J.; Lu, Y.; Gao, R.; Zhu, S.-C.; Wu, Y.N. Cooperative training of descriptor and generator networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 27–45. [Google Scholar] [CrossRef]
- Dai, J.; Lu, Y.; Wu, Y.N. Generative modeling of convolutional neural networks. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Otuoze, A.O.; Mustafa, M.W.; Abioye, A.E.; Sultana, U.; Usman, A.M.; Ibrahim, O.; Omeiza, I.O.A.; Abu-Saeed, A. A rule-based model for electricity theft prevention in advanced metering infrastructure. J. Electr. Syst. Inf. Technol. 2022, 9, 1–17. [Google Scholar] [CrossRef]
- Mahabadi, R.K.; Ruder, S.; Dehghani, M.; Henderson, J. Parameter efficient multi-task fine-tuning for transformers via shared hypernetworks. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 October 2021;: Long Papers; Volume 1, pp. 565–576. [Google Scholar]
- Alaton, C.; Tounquet, F. Benchmarking Smart Metering Deployment in the EU-28; Final Report; Directorate-General for Energy, European Commission, Tractebel Impact: Brussels, Belgium, 2020. [Google Scholar]
- Gianniou, P.; Liu, X.; Heller, A.; Nielsen, P.S.; Rode, C. Clustering-based analysis for residential district heating data. Energy Convers Manag. 2018, 165, 840–850. [Google Scholar] [CrossRef]
- Calamaro, N.; Ofir, A.; Shmilovitz, D. Application of Enhanced CPC for Load Identification, Preventive Maintenance and Grid Interpretation. Energies 2021, 14, 3275. [Google Scholar] [CrossRef]
- Devine, S. The Insights of Algorithmic Entropy. Entropy 2009, 11, 85–110. [Google Scholar] [CrossRef]
- Wigderson, A. Mathematics and Computation; Princeton University Press: Princeton, NJ, USA, 2019. [Google Scholar]
- Burgisser, P.; Goldreich, O.; Sudan, M.; Vadhan, S. Complexity theory. Oberwolfach Rep. 2016, 12, 3049–3099. [Google Scholar] [CrossRef]
- Goldreich, O.; Vadhan, S.P. On the complexity of computational problems regarding distributions (A survey). Electron. Colloq. Comput. Complex. 2011, 18, 4. [Google Scholar]
- Yadav, N.; Sardina, S.; Murawski, C.; Bossaerts, P. Phase transition in the knapsack problem. arXiv 2018, arXiv:1806.10244. [Google Scholar]
- Arora, S.; Barak, B. Computational Complexity: A Modern Approach; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Levine, Y.; Sharir, O.; Cohen, N.; Shashua, A. Quantum entanglement in deep learning architectures. Phys. Rev. Lett. 2019, 122, 065301. [Google Scholar] [CrossRef]
- Levine, Y.; Yakira, D.; Cohen, N.; Shashua, A. Deep learning and quantum entanglement: Fundamental connections with implications to network design. arXiv 2017, arXiv:1704.01552. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999. [Google Scholar]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Ghojogh, B.; Ghodsi, A.; Karray, F.; Crowley, M. Restricted Boltzmann machine and deep belief network: Tutorial and survey. arXiv 2021, arXiv:2107.12521. [Google Scholar]
- Cernat, M.; Staicu, A.-N.; Stefanescu, A. Improving UI Test Automation using Robotic Process Automation. In Proceedings of the 15th International Conference on Software Technologies (ICSOFT’20), SciTePress, Online, 7–9 July 2020; pp. 260–267. [Google Scholar]
- Tripathi, A.M. Learning Robotic Process Automation: Create Software Robots and Automate Business Processes with the Leading RPA Tool-UiPath; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Yung-Pin, C.; Ching-Wei, L.; Yi-Cheng, C. Apply computer vision in GUI automation for industrial applications. Math. Biosci. Eng. 2019, 16, 7526–7545. [Google Scholar]
- Singer, S.; Ozeri, S.; Shmilovitz, D. A pure realization of Loss-Free Resistor. IEEE Trans. Circuits Syst. Part I 2004, 51, 1639–1647. [Google Scholar] [CrossRef]
- Shmilovitz, D. Gyrator realization based on a capacitive switched cell. IEEE Trans. Circuits Syst. II 2006, 53, 1418–1422. [Google Scholar] [CrossRef]
- Messinis, G.M.; Hatziargyriou, N.D. Review of non-technical loss detection methods. Electr. Power Syst. Res. 2018, 158, 250–266. [Google Scholar] [CrossRef]
- Irish Social Science Data Archive. Available online: https://www.ucd.ie/issda/data/commissionforenergyregulationcer/ (accessed on 31 March 2020).
- NREL. Eastern Wind Data Set. Available online: https://www.nrel.gov/grid/eastern-wind-data.html (accessed on 31 March 2010).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Processing Syst. 2013, 26. [Google Scholar]
- Mikolov, T.; Grave, E.; Bojanowski, P.; Puhrsch, C.; Joulin, A. Advances in pre-training distributed word representations. arXiv 2017, arXiv:1712.09405. [Google Scholar]
- Jain, M.; Mathew, M.; Jawahar, C.V. Unconstrained OCR for Urdu using deep CNN-RNN hybrid networks. In Proceedings of the 4th Asian Conference on Pattern Recognition (ACPR), Nanjing, China, 26–29 November 2017. [Google Scholar]
- Feng, Z.; Fang, J.; Cai, B.; Zhang, Y. GUIS2Code: A Computer Vision Tool to Generate Code Automatically from Graphical User Interface Sketches. In Proceedings of the International Conference on Artificial Neural Networks, Bratislava, Slovakia, 15–18 September 2021; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Ketkar, N. Deep Learning with Python; Springer: New York, NY, USA, 2017. [Google Scholar]
- Goodfellow, I. Nips 2016 tutorial: Generative adversarial networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Van Houdt, G.; Mosquera, C.; Nápoles, G. A review on the long short-term memory model. Artif. Intell. Rev. 2020, 53, 5929–5955. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Zhao, Y.; Wang, J. Analytical investigation of autoencoder-based methods for unsupervised anomaly detection in building energy data. Appl. Energy 2018, 211, 1123–1135. [Google Scholar] [CrossRef]
- Ryu, H.; Shin, H.; Park, J. Multi-agent actor-critic with generative cooperative policy network. arXiv 2018, arXiv:1810.09206. [Google Scholar]
- Zhang, J.; Xie, J.; Zheng, Z.; Barnes, N. Energy-based generative cooperative saliency prediction. arXiv 2021, arXiv:2106.13389. [Google Scholar] [CrossRef]
- Spear, M.E. Charting Statistics; McGraw Hill: New York, NY, USA, 1952; p. 166. [Google Scholar]
- Spear, M.E. Practical Charting Techniques; McGraw-Hill: New York, NY, USA, 1969; ISBN 0070600104. [Google Scholar]
- Wickham, H.; Stryjewski, L. 40 Years of Boxplots; Technical Report; Taylor and Francis Ltd.: Abingdon, UK, 2011. [Google Scholar]
- Reynolds, D. Gaussian Mixture Models. In Encyclopedia of Biometrics; Springer Science + Business Media: New York, NY, USA, 2009; pp. 659–663. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001; Volume 1. [Google Scholar]
- Smith, L.I.A. Tutorial on Principal Components Analysis; Cornell University: Ithaca, NY, USA, 2002; Volume 51, pp. 52–54. [Google Scholar]
- Matej, K.; Aleš, L. Multivariate online kernel density estimation. In Proceedings of the Computer Vision Winter Workshop, Nove Hrady, Czech Republic, 3–5 February 2010; pp. 77–86. [Google Scholar]
- Smith, T.B. Electricity theft: A comparative analysis. J. Energy Policy 2004, 32, 2067–2076. [Google Scholar] [CrossRef]
- World Fraud Report 2014. Available online: https://www.prnewswire.com/news-releases/world-loses-893-billion-to-electricity-theft-annually-587-billion-in-emerging-markets-300006515.html (accessed on 31 March 2022).
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Khan, Z.A.; Adil, M.; Javaid, N.; Saqib, M.N.; Shafiq, M.; Choi, J.-G. Electricity Theft Detection Using Supervised Learning Techniques on Smart Meter Data. Sustainability 2020, 12, 8023. [Google Scholar] [CrossRef]
- Labate, D.; Giubbini, P.; Chicco, G.; Piglione, F. Shape: The load prediction and non-technical losses modules. In Proceedings of the 23rd International Conference on Electricity Distribution, Lyon, France, 15–18 June 2015. [Google Scholar]
- Huang, S.-C.; Lo, Y.-L.; Lu, C.-N. Non-technical loss detection using state estimation and analysis of variance. IEEE Trans. Power Syst. 2013, 28, 2959–2966. [Google Scholar] [CrossRef]
- Fragkioudaki, A.; Cruz-Romero, P.; Gómez-Expósito, A.; Biscarri, J.; Tellechea, M.J.D.; Arcos, Á. Detection of non-technical losses in smart distribution networks: A review. In Proceedings of the International Conference on Practical Applications of Agents and Multi-Agent Systems, Sevilla, Spain, 1–3 June 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Calamaro, N.; Donko, M.; Shmilovitz, D. A Highly Accurate NILM: With an Electro-Spectral Space That Best Fits Algorithm’s National Deployment Requirements. Energies 2021, 14, 7410. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fraud | Non-Fraud | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Accuracy Macro, Weighted | Precision | F1-Score | Recall | Accuracy | Precision | F1-Score | Recall |
| Proposed SVM + HDS2 | 0.81 | 0.81 | 0.5 | 0.33 | 0.81 | 0.62 | 0.77 | 1 |
| Proposed Ridge + HDS | 0.81 0.8 | 1 | 0.55 | 0.33 | 0.81 0.8 | 0.81 | 0.77 | 1 |
| Proposed KNN + HDS | 0.88 | 1 | 0.800 | 0.67 | 0.88 | 0.77 | 0.67 | 1 |
| Proposed RF + HDS | 0.92 0.91 | 1 | 0.88 | 0.78 | 0.92 0.91 | 0.83 | 0.91 | 1 |
| Proposed DT + HDS | 0.95 0.95 | 1 | 0.94 | 0.89 | 0.95 0.95 | 0.91 | 0.95 | 1 |
| Proposed LR + HDS | 1 1 | 1 | 1 | 1 | 1 1 | 1 | 1 | 1 |
| Wide & deep CNN [24] | 0.9503 | 0.9503 | 0.9093 | -- | -- | -- | -- | -- |
| Work | ||||||||
| SVM w/o preprocess | 0.772 | 0.765 | 0.863 | -- | -- | -- | -- | -- |
| LR without preprocess | 0.676 | 0.645 | 0.937 | -- | -- | -- | -- | -- |
| CNN | 0.812 | 0.805 | 0.845 | -- | -- | -- | -- | -- |
| RUSBoost | 0.869 | 0.85 | 0.871 | -- | -- | -- | -- | -- |
| Work with [59] preprocessing and supervised learning | 0.95 | 0.93 | 0.937 | -- | -- | -- | -- | -- |
| Fraud | Non-Fraud | |||||||
|---|---|---|---|---|---|---|---|---|
| No. | Loss Type | Initially, Raised by Module | Currently Identified by Module | Was Verified Yes/No | Unique Signature Yes/No | Reason, Details | Final System Decision | Comment |
| 1 | Magnetic tampering | Module 2: events | Module 2: events Module 1: AI | yes | no | It is a false event by sensor, there is no real nontechnical loss | For the specific model type tag this is not a fault | It is not a tampering loss, it is a meter false alert |
| 2 | Disconnected phase | Module 2 events | Module 2: events Module 1: AI | yes | yes | Three mechanisms alert this now: (i) Meter event, (ii) expert knowledge rule: voltage while current = 0, (iii) AI signature | Tag this as a true TNT Loss | A true event 14 m out of 50,000 identified |
| 3 | Reversed-phase | Module 2 events: assertion rule | Module 2: events Module 1: AI | yes | Three mechanisms alert this now: (i) Meter event, (ii) expert knowledge rule: active export , (iii) AI signature and (iv) must not be PV | Tag this as a true TNT loss | A true event two meters out of 50,000 identified | |
| 4 | Repeated meter restart | Module 2 events | Module 2: events Module 1: AI | yes | yes | Due to hardware failure causing repeated restarts, energy stored in temporary registers is lost, and energy not measured during restart time is lost—metrological damage | Tag this as a true TNT loss | A true event five meters out of 50,000 identified |
| 5 | Meter turn-off/not measured | Module 2 events, assertion rule | Module 2: events Module 1: AI | yes | yes | Due to hardware failure the meter stops measuring | Tag this as a true TNT loss | A true event 14 m out of 50,000 identified |
| 6 | Meter abruptly low consumption | Module 1 AI, Module 2 events—assertion rule | Module 1: AI | yes | yes | Firmware defect: during daily midnight clock synch with SNTP an internal multiplication factor is reduced to close to zero but not zero | Tag this as a true TNT loss | A true event 5 m out of 50,000 identified |
| 7 | Holes/gaps in load profile | Module 1: AI | Module 2 events—assertion rule | yes | yes | Due to architecture flaw—lack of handshaking at load profile transfer from MDM to DWH1, 50% of the data gaps were generated. Insertion of a handshaking system TALEND resolved the problem completely | Tag this as a true TNT loss | A true event occurring at 100% of meters out of 50,000 identified |
| 8 | A random value of 20,000–2,000,000 kWh is exerted at one of three phases as export. From there, meter counts are precise | Module 2 events, assertion rule | Module 2: events Module 1: AI | yes | yes | Root cause analyzed this occurs at the factory. It is missed at the acceptance test by pulse counting and detected by electronic meter reading | Tag this as a true TNT loss | A true event occurring at 0.05% of meters out of 50,000 identified |
| 9 | Memory access fault events | Module 2 events, assertion rule | Module 2: events Module 1: AI | yes | yes | Might cause energy loss due to miss storage of energy | Tag this as a true TNT Loss | A true event occurring at 0.05% of meters out of 50,000 identified |
| 10 | Meter abruptly low consumption at a distribution transformer and data concentrator CT connected meter | Module 1 AI, Module 2 events—assertion rule | Module 1: AI | yes | yes | At distribution transformer level this fault causes energy balance mismatch—energy, which is more severe than a single faulty meter | Tag this as a true TNT Loss | A true event occurring at 0.05% of meters out of 50,000 identified |
| 11 | Signal quality | Module 2 events | Module 2 events | no | no | Power quality events. This is nota fault | Tag this as a false TNT Loss | A false event occurring at = ~0.05% of meters out of 50,000 identified |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Calamaro, N.; Levy, M.; Ben-Melech, R.; Shmilovitz, D. TNT Loss: A Technical and Nontechnical Generative Cooperative Energy Loss Detection System. Sensors 2022, 22, 7003. https://doi.org/10.3390/s22187003
Calamaro N, Levy M, Ben-Melech R, Shmilovitz D. TNT Loss: A Technical and Nontechnical Generative Cooperative Energy Loss Detection System. Sensors. 2022; 22(18):7003. https://doi.org/10.3390/s22187003
Chicago/Turabian StyleCalamaro, Netzah, Michael Levy, Ran Ben-Melech, and Doron Shmilovitz. 2022. "TNT Loss: A Technical and Nontechnical Generative Cooperative Energy Loss Detection System" Sensors 22, no. 18: 7003. https://doi.org/10.3390/s22187003