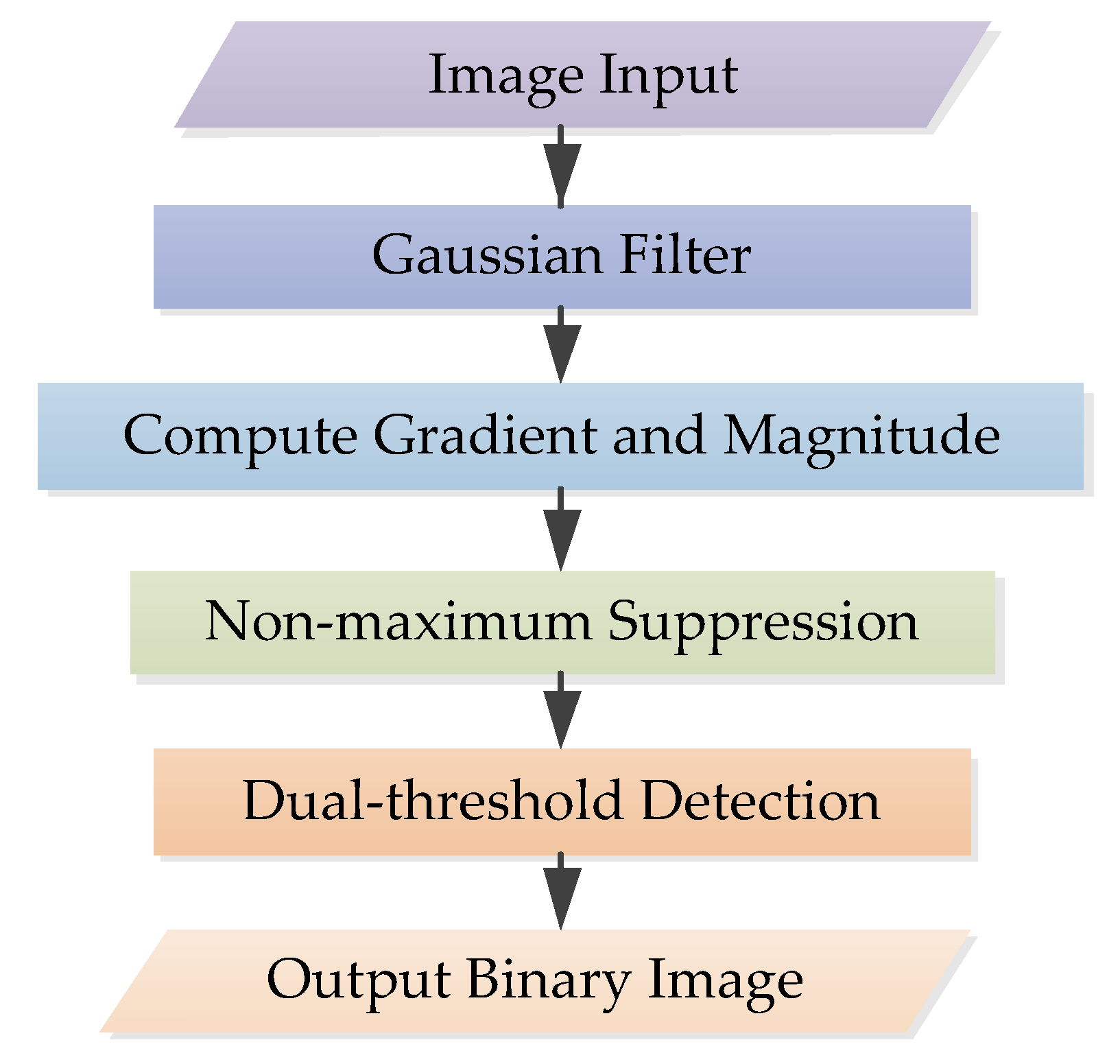
4.2. Evaluation of L-FAST Method
In order to study the performance of L-FAST, this section first analyzes the number and time values of point feature extraction. Then, it is applied to ORB-SLAM to replace the FAST module in the ORB, and other modules remain unchanged. It is compared with the traditional ORB to analyze and compare the performance of L-FAST.
This section describes the use of the KITTI dataset 00–10 sequences diagrams to conduct the experiment. The accelerated ORB-SLAM was used for comparative experiments. Taking the KITTI dataset 00 sequence as an example, the image sequence was introduced into FAST and L-FAST algorithms, respectively, and the time consumed in extraction and the number of successfully extracted feature relationships was recorded. The visual data are shown in
Figure 9.
We can see that the average extraction time of L-FAST was 3 ms, while the average extraction time of FAST was 15 ms. The average number of point features extracted by FAST and L-FAST was 1763 and 205, respectively. In terms of time, the extraction time of L-FAST was slightly better than that of FAST. While ensuring the success rate of frame matching, the number of point features was significantly reduced.
In order to deeply compare the effects of different sequence sets, the same method was used to run 01–10 sequence datasets, respectively. The average time and number results of each sequence are shown in
Figure 10.
The results of each sequence show that compared with FAST, L-FAST took less time to extract, and the number of extracts was relatively stable. In the case of less texture, L-FAST performed well. In order to deeply analyze the feasibility of specific applications in the system, the impact of FAST and L-FAST on the positioning performance of the simulation system was explored. The KITTI-05 dataset sequence was run to conduct the experiment. The images in the sequence were introduced into the simulation system using FAST and L-FAST, respectively, and their motion trajectories recorded. The absolute trajectory error was used to analyze the trajectory, and the root mean square error (RMSE) indexes of the two front ends were mainly compared. KITTI-05 sequence was composed of 2761 × 2 track photos, with a distance of about 3 km, tracking within 287.5 s, and the trajectory contained many loops.
The motion trajectories are shown in
Figure 11, including the trajectories of the simulation system using FAST and L-FAST, as well as the three-axis error comparison diagrams of different algorithms of sequence 05.
It can be seen from
Figure 11 that the trajectory of L-FAST had smaller deviations in some areas than FAST. Further analysis of
three-axis error shows that the trajectory of L-FAST was basically consistent with the real trajectory of the KITTI-05 sequence on the
axis, while the trajectory of L-FAST on the
axis had a slightly larger deviation than that of FAST.
In order to further analyze the performance of L-FAST, the quantitative analysis of each trajectory and the calculated absolute trajectory error (ATE) was carried out for each trajectory in the diagram, and the relevant indicators of error are given in
Table 3.
It can be seen from
Table 3 that compared with FAST, the ATE of L-FAST decreased on the whole, but the improvement was not great. According to preliminary judgment, in the scene with many online features, L-FAST was better than FAST locally. Considering the conclusion drawn in
Figure 11, L-FAST was obviously not good at the
axis calculations, which related to pitch angle, and the overall positioning accuracy of L-FAST on the
axis was slightly better than that of FAST. In order to further analyze the reasons for the poor performance of the L-FAST algorithm on the
axis, the images of KITTI-00 to KITTI-10 sequences were run for comparison and analysis with FAST, and the time spent on each sequence was recorded to explore its time complexity.
Table 4 shows the RMSE, min and max errors of ATE for sequence from 00 to 10, respectively.
Table 5 shows the running time of each frame of the corresponding sequences, and the cumulative distribution functions (CDFs) of each sequence are shown respectively in
Figure 12.
It can be seen from the error results of ATE and the CDFs that there was little difference between the two algorithms on 01, 02, 03, 05 and 09 sequences. The L-FAST algorithm performed better on 00, 04 and 08 sequences, but the performance of 07 and 10 sequences was far worse than that of FAST, which made a large error in some frames. By viewing the picture streams of each sequence in KITTI datasets, the car-following phenomenon occurred many times in the 07 sequence, and the white vehicle appeared for a long time in the 10 sequence. We judged that the quality of corners extracted by L-FAST was far less than that of FAST in these two sequences, due to it being easily detected as the intersection of the two lines from vehicles, which undoubtedly leads to a huge drift of some frames. In addition, for 01, 02, 05, 07, 09 and 10 sequences, it can be seen that the acquisition vehicles had a gentle slope process up and down. Among them, 01, 02, 07 and 10 sequences had a large slope change, while 05 and 09 sequences had a small slope change. The CDF images show that L-FAST was slightly less robust than FAST; this may be due to L-FAST using fewer corners. Therefore, we can conclude that L-FAST does not perform well on the axis, and has certain robustness for small slopes. For 04 and 08 sequences images, the left-right motion of the camera caused by vehicle lane changes occurred many times during operation, but L-FAST still performed well. Therefore, we can conclude that L-FAST has strong robustness to parallel motion.
In terms of time, the matching time of each frame of L-FAST was about twice that of FAST. For 01, 03 and 06 sequences, it can be seen that their textures are relatively few, their brightness is uniform, and most of them are roads, so it took less time to extract edges. For 08 and 10 sequences, white vehicles exist in the image for a long time, resulting in uneven image brightness and increasing the time of edge extraction.
To sum up, L-FAST achieved similar performance to FAST in a general environment by using a small number of feature points. The proposed algorithm greatly improves the quality of feature points. The performance of L-FAST was poor in the environment with slope and abnormal car-following. L-FAST was robust in the left-right moving environments.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}