
A Reconfigurable Visual–Inertial Odometry Accelerated Core with High Area and Energy Efficiency for Autonomous Mobile Robots

 ,
,
Abstract
1. Introduction
2. Algorithms
2.1. Overall Procedure of the Visual–Inertial Odometry
2.2. IMU Pre-Integration
2.3. Algorithm of Feature Extraction
2.3.1. FAST-9 Feature Detection
2.3.2. Gradient-Based Score Calculation
2.4. Algorithm of Feature Coordinates Alignment
2.5. Supported Operations in SLAM Algorithms
3. Hardware Design
3.1. Overall Hardware Architecture
3.2. Fixed-Point Vision Pipeline
3.3. Programmable Computation Core
3.4. Feature Processing Engine
4. Implementation Results
4.1. Accuracy of Datasets Compared with Software Platform
4.2. Evaluation Platform and Experiments
4.3. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
References
- Silveira, G.; Malis, E.; Rives, P. An Efficient Direct Approach to Visual SLAM. IEEE Trans. Robot. 2008, 24, 969–979. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Engel, J.; Stuckler, J.; Cremers, D. Large-scale direct SLAM with stereo cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Herbert, B.; Andreas, E.; Tinne, T.; LucVan, G. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar]
- Rosten, E.; Porter, R.; Drummond, T. Faster and better: A machine learning approach to corner detection. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 105–119. [Google Scholar] [CrossRef]
- Castellanos, J.A.; Montiel, J.; Neira, J.; Tardós, J.D. The SPmap: A probabilistic framework for simultaneous localization and map building. IEEE Trans. Robot. Autom. 1999, 15, 948–952. [Google Scholar] [CrossRef]
- Huang, G.P.; Mourikis, A.I.; Roumeliotis, S.I. Analysis and improvement of the consistency of extended Kalman filter based SLAM. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008. [Google Scholar]
- Eustice, R.M.; Singh, H.; Leonard, J.J. Exactly Sparse Delayed-State Filters for View-Based SLAM. IEEE Trans. Robot. 2007, 22, 1100–1114. [Google Scholar] [CrossRef]
- Thrun, S.; Liu, Y.; Koller, D.; Ng, A.Y.; Ghahramani, Z.; Durrant-Whyte, H. Simultaneous Localization and Mapping With Sparse Extended Information Filters. Int. J. Robot. Res. 2004, 23, 693–716. [Google Scholar] [CrossRef]
- Montemarlo, M. FastSLAM: A Factored Solution to the Simultaneous Localization and Mapping Problem. In Proceedings of the Theaaai National Conference on Artificial Intelligence, Edmonton, AB, Canada, 28 July–1 August 2002. [Google Scholar]
- Hähnel, D.; Burgard, W.; Fox, D.; Thrun, S. An Efficient {FastSLAM} Algorithm for Generating Maps of Large-Scale Cyclic Environments from Raw Laser Range Measurements. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2003, Las Vegas, NV, USA, 27–31 October 2003. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping with Rao-Blackwellized Particle Filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Di, K.; Zhao, Q.; Wan, W.; Wang, Y.; Gao, Y. RGB-D SLAM Based on Extended Bundle Adjustment with 2D and 3D Information. Sensors 2016, 16, 1285. [Google Scholar] [CrossRef] [PubMed]
- Alismail, H.; Browning, B.; Lucey, S. Photometric Bundle Adjustment for Vision-Based SLAM. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016. [Google Scholar]
- Liu, H.; Chen, M.; Zhang, G.; Bao, H.; Bao, Y. ICE-BA: Incremental, Consistent and Efficient Bundle Adjustment for Visual-Inertial SLAM. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chao, J.; Geng, Z.X.; Wei, X.F.; Shen, C. SIFT implementation based on GPU. In Proceedings of the ISPDI 2013—Fifth International Symposium on Photoelectronic Detection and Imaging, Beijing, China, 25–27 June 2013. [Google Scholar]
- Cornelis, N.; Gool, L.V. Fast scale invariant feature detection and matching on programmable graphics hardware. In Proceedings of the IEEE International Conference on Technologies for Practical Robot Applications, Woburn, MA, USA, 9–10 November 2009. [Google Scholar]
- Yum, J.; Lee, C.H.; Kim, J.S.; Lee, H.J. A Novel Hardware Architecture with Reduced Internal Memory for Real-Time Extraction of SIFT in an HD Video. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 1. [Google Scholar] [CrossRef]
- Wilson, C.; Zicari, P.; Craciun, S.; Gauvin, P.; Lam, H. A power-efficient real-time architecture for SURF feature extraction. In Proceedings of the International Conference on ReConFigurable mputing and FPGAs (ReConFig14), Riviera Maya, Mexico, 7–9 December 2015. [Google Scholar]
- Ulusel, O.; Picardo, C.; Harris, C.B.; Reda, S.; Bahar, R.I. Hardware acceleration of feature detection and description algorithms on low-power embedded platforms. In Proceedings of the International Conference on Field Programmable Logic & Applications, FPL 2016, Lausanne, Switzerland, 29 August–2 September 2016. [Google Scholar]
- Tertei, D.T.R.; Piat, J.; Devy, M. FPGA design of EKF block accelerator for 3D visual SLAM. Comput. Electr. Eng. 2016, 55, 123–137. [Google Scholar] [CrossRef]
- Wang, J.; Zhan, Y.; Wang, Z.; Peng, Z.; Xu, J.; Liu, B.; Yu, G.; An, F.; Wang, C.; Zou, X. A Reconfigurable Matrix Multiplication Coprocessor with High Area and Energy Efficiency for Visual Intelligent and Autonomous Mobile Robots. In Proceedings of the 2021 IEEE Asian Solid-State Circuits Conference, A-SSCC 2021, Busan, Korea, 7–10 November 2021. [Google Scholar]
- Liu, R.; Yang, J.; Chen, Y.; Zhao, W. eSLAM: An Energy-Efficient Accelerator for Real-Time ORB-SLAM on FPGA Platform. In Proceedings of the 56th Annual Design Automation Conference, Las Vegas, NV, USA, 2–6 June 2019. [Google Scholar]
- Li, Z.; Chen, Y.; Gong, L.; Liu, L.; Kim, H.S. An 879GOPS 243mW 80fps VGA Fully Visual CNN-SLAM Processor for Wide-Range Autonomous Exploration. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 17–21 February 2019. [Google Scholar]
- Suleiman, A.; Zhengdong, Z.; Carlone, L.; Karaman, S.; Sze, V. Navion: A 2-mW Fully Integrated Real-Time Visual-Inertial Odometry Accelerator for Autonomous Navigation of Nano Drones. IEEE J. Solid-State Circuits 2019, 54, 1106–1119. [Google Scholar] [CrossRef]
- Zhang, Z.; Suleiman, A.Z.; Carlone, L.; Sze, V.; Karaman, S. Visual-Inertial Odometry on Chip: An Algorithm-and-Hardware Co-design Approach. In Proceedings of the Robotics: Science and Systems, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar]
- Wang, C.; Liu, Y.; Zuo, K.; Tong, J.; Ding, Y.; Ren, P. ac2SLAM: FPGA Accelerated High-Accuracy SLAM with Heapsort and Parallel Keypoint Extractor. In Proceedings of the 2021 International Conference on Field-Programmable Technology (ICFPT), Auckland, New Zealand, 6–10 December 2021. [Google Scholar]
- Lupton, T.; Sukkarieh, S. Visual-Inertial-Aided Navigation for High-Dynamic Motion in Built Environments Without Initial Conditions. IEEE Trans. Robot. 2012, 28, 61–76. [Google Scholar] [CrossRef]
- Forster, C.; Carlone, L.; Dellaert, F.; Scaramuzza, D. IMU Preintegration on Manifold for Efficient Visual-Inertial Maximum-a-Posteriori Estimation. In Proceedings of the Robotics: Science and Systems XI, Rome, Italy, 13–17 July 2015. [Google Scholar]
- Tong, Q.; Li, P.; Shen, S. VINS-Mono: A Robust and Versatile Monocular Visual-Inertial State Estimator. IEEE Trans. Robot. 2017, 34, 1–17. [Google Scholar]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Tan, Y.; Deng, H.; Sun, M.; Zhou, M.; Chen, Y.; Chen, L.; Wang, C.; An, F. A Reconfigurable Coprocessor for Simultaneous Localization and Mapping Algorithms in FPGA. IEEE Trans. Circuits Syst. II Express Briefs, 2022; in press. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
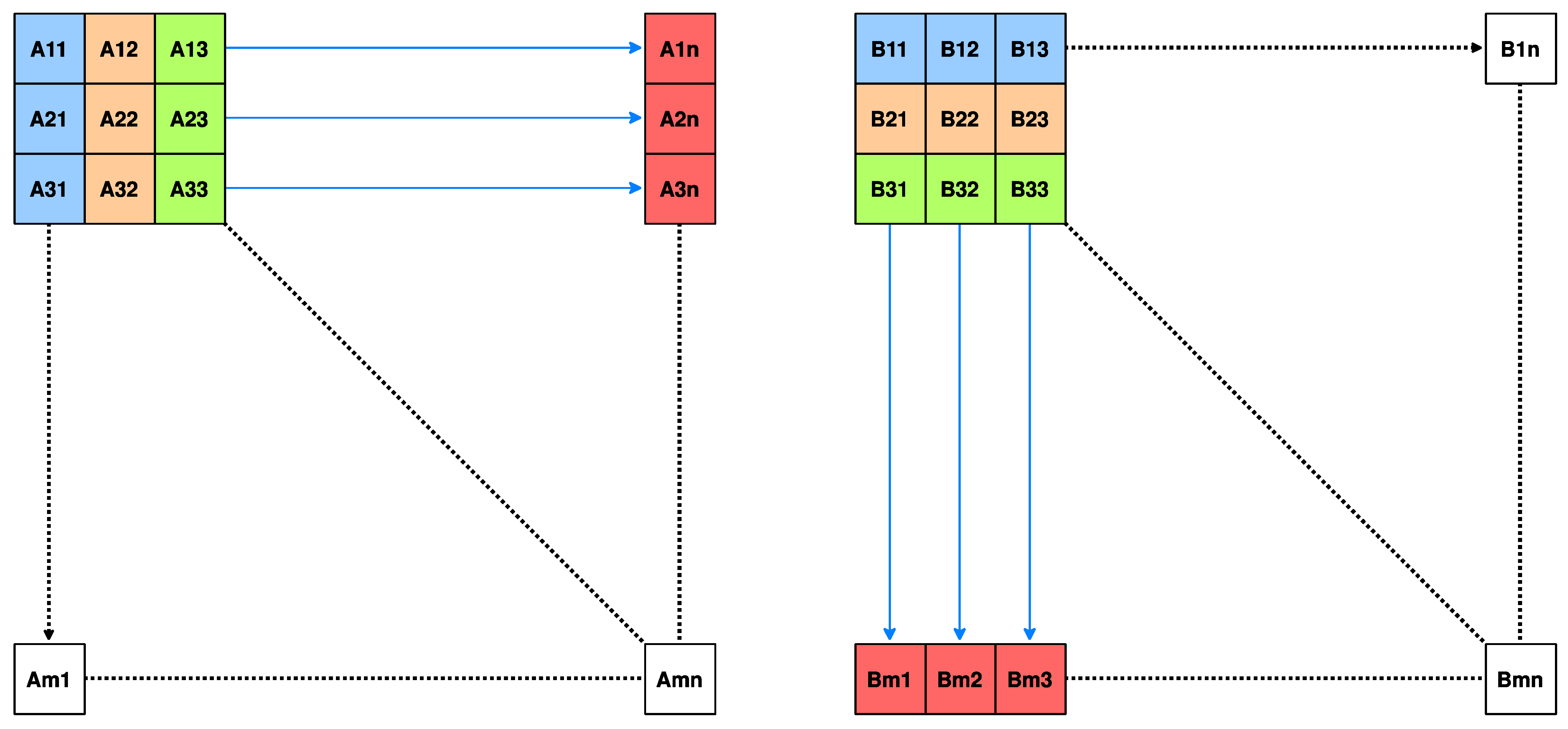{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation | Description | Time Consumption |
|---|---|---|
| Scalar add/sub | Scalar addition/subtraction | 5 clock cycles |
| Scalar mul | Scalar multiplication | 2 clock cycles |
| Scalar reci | Scalar reciprocal | 10 clock cycles |
| Scalar sqrt_slow | Scalar square root with high accuracy | 27 clock cycles |
| Scalar sqrt_fast | Scalar square root with low latency | 10 clock cycles |
| Sin_Cos | Sine and cosine function for input in radians | 52 clock cycles |
| M_inv | Matrix inversion | 31 clock cycles |
| Li2R | Transform lie algebra to a rotation matrix | 73 clock cycles |
| Li2Q | Transform lie algebra to quaternion | 65 clock cycles |
| R2Q | Transform rotation matrix to quaternion | 53 clock cycles |
| Q2R | Transform quaternion to a rotation matrix | 14 clock cycles |
| Q_q | Quaternion multiplication | 14 clock cycles |
| Operation | Description | Time Consumption |
|---|---|---|
| Scalar add/sub | Scalar addition/subtraction | 5 clock cycles |
| Scalar mul | Scalar multiplication | 2 clock cycles |
| Scalar reci | Scalar reciprocal | 10 clock cycles |
| Scalar sqrt_slow | Scalar square root with high accuracy | 27 clock cycles |
| Scalar sqrt_fast | Scalar square root with low latency | 10 clock cycles |
| Sin_Cos | Sine and cosine function for input in radians | 52 clock cycles |
| M_inv | Matrix inversion | 31 clock cycles |
| Li2R | Transform lie algebra to a rotation matrix | 73 clock cycles |
| Li2Q | Transform lie algebra to quaternion | 65 clock cycles |
| R2Q | Transform rotation matrix to quaternion | 53 clock cycles |
| Q2R | Transform quaternion to a rotation matrix | 14 clock cycles |
| Q_q | Quaternion multiplication | 14 clock cycles |
| Dataset | ROVIO (Software) | The Proposed Core |
|---|---|---|
| MH_1 | 0.19% | 0.19% |
| MH_2 | 0.23% | 0.23% |
| MH_3 | 0.47% | 0.49% |
| MH_4 | 0.55% | 0.52% |
| MH_5 | 0.78% | 0.79% |
| V1_1 | 0.28% | 0.26% |
| V1_2 | 0.35% | 0.34% |
| V1_3 | 0.27% | 0.25% |
| V2_1 | 0.26% | 0.26% |
| V2_2 | 0.37% | 0.40% |
| V2_3 | 0.61% | 0.61% |
| MIT 2017 [28] | ICFPT 2021 [29] | JSSC 2019 [27] | ISSCC 2019 [26] | This Work | |
|---|---|---|---|---|---|
| Type | VIO | SLAM | VIO | SLAM | VIO |
| Odometry | IMU | Visual | IMU | Visual | IMU |
| FPGA Platform | Kintex-7 XC7K355T | UltraScale + XCZU7EV | N/A | N/A | UltraScale + XCVU440 |
| Technology | N/A | N/A | 65 nm | 28 nm | 28 nm * |
| Resolution | N/A | 640 × 480 | 752 × 480 | 640 × 480 | 640 × 480 |
| Speed | 20 fps | 15.5 fps | 171 fps | 80 fps | 160 fps |
| Frequency | 100 MHz | 100 MHz | 62.5 MHz/ 83.3 MHz | 240 MHz | 160 MHz (250 MHz *) |
| SoC | No | Yes | No | No | No |
| On-chip Memory | 2048 KB | 61 KB | 854 KB | 1126 KB | 70 KB |
| LUTs | 192,000 | 146,572 | N/A | N/A | 91,802 |
| FFs | 144,000 | 74,166 | N/A | N/A | 61,107 |
| DSPs | 771 | 173 | N/A | N/A | 96 |
| Power | 1.46 W | Not Given | 24 mW | 243.6 mW | 0.683 W (179.52 mW) |
| Area | N/A | N/A | 20 mm2 | 10.92 mm2 | 3 mm2 |
| Reconfigurable | No | No | No | No | Yes |
| Application | Nano and pico robots | Autonomous navigation | AR, VR and UAVs | AMRs | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, Y.; Sun, M.; Deng, H.; Wu, H.; Zhou, M.; Chen, Y.; Yu, Z.; Zeng, Q.; Li, P.; Chen, L.; et al. A Reconfigurable Visual–Inertial Odometry Accelerated Core with High Area and Energy Efficiency for Autonomous Mobile Robots. Sensors 2022, 22, 7669. https://doi.org/10.3390/s22197669
Tan Y, Sun M, Deng H, Wu H, Zhou M, Chen Y, Yu Z, Zeng Q, Li P, Chen L, et al. A Reconfigurable Visual–Inertial Odometry Accelerated Core with High Area and Energy Efficiency for Autonomous Mobile Robots. Sensors. 2022; 22(19):7669. https://doi.org/10.3390/s22197669
Chicago/Turabian StyleTan, Yonghao, Mengying Sun, Huanshihong Deng, Haihan Wu, Minghao Zhou, Yifei Chen, Zhuo Yu, Qinghan Zeng, Ping Li, Lei Chen, and et al. 2022. "A Reconfigurable Visual–Inertial Odometry Accelerated Core with High Area and Energy Efficiency for Autonomous Mobile Robots" Sensors 22, no. 19: 7669. https://doi.org/10.3390/s22197669
APA StyleTan, Y., Sun, M., Deng, H., Wu, H., Zhou, M., Chen, Y., Yu, Z., Zeng, Q., Li, P., Chen, L., & An, F. (2022). A Reconfigurable Visual–Inertial Odometry Accelerated Core with High Area and Energy Efficiency for Autonomous Mobile Robots. Sensors, 22(19), 7669. https://doi.org/10.3390/s22197669