


Automatic Recognition of Giant Panda Attributes from Their Vocalizations Based on Squeeze-and-Excitation Network


 ,
,
Abstract
:1. Introduction
1.1. Acoustic Recognition of Animals
1.2. Content of This Study
2. Materials and Methods
2.1. Materials
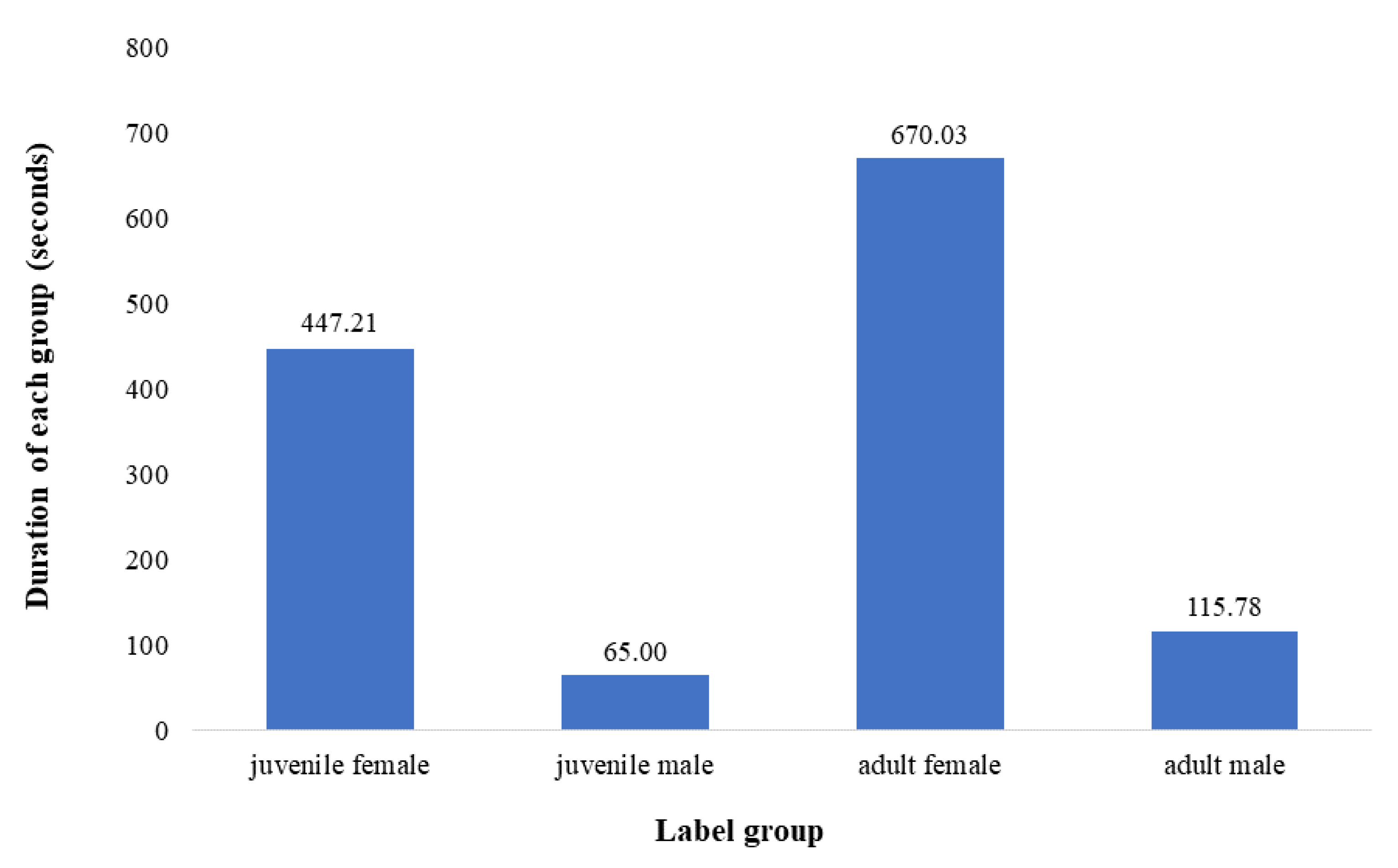
2.1.1. Dataset
2.1.2. Data Preprocessing
2.1.3. MFCC
2.2. Methods
2.2.1. Model Architecture
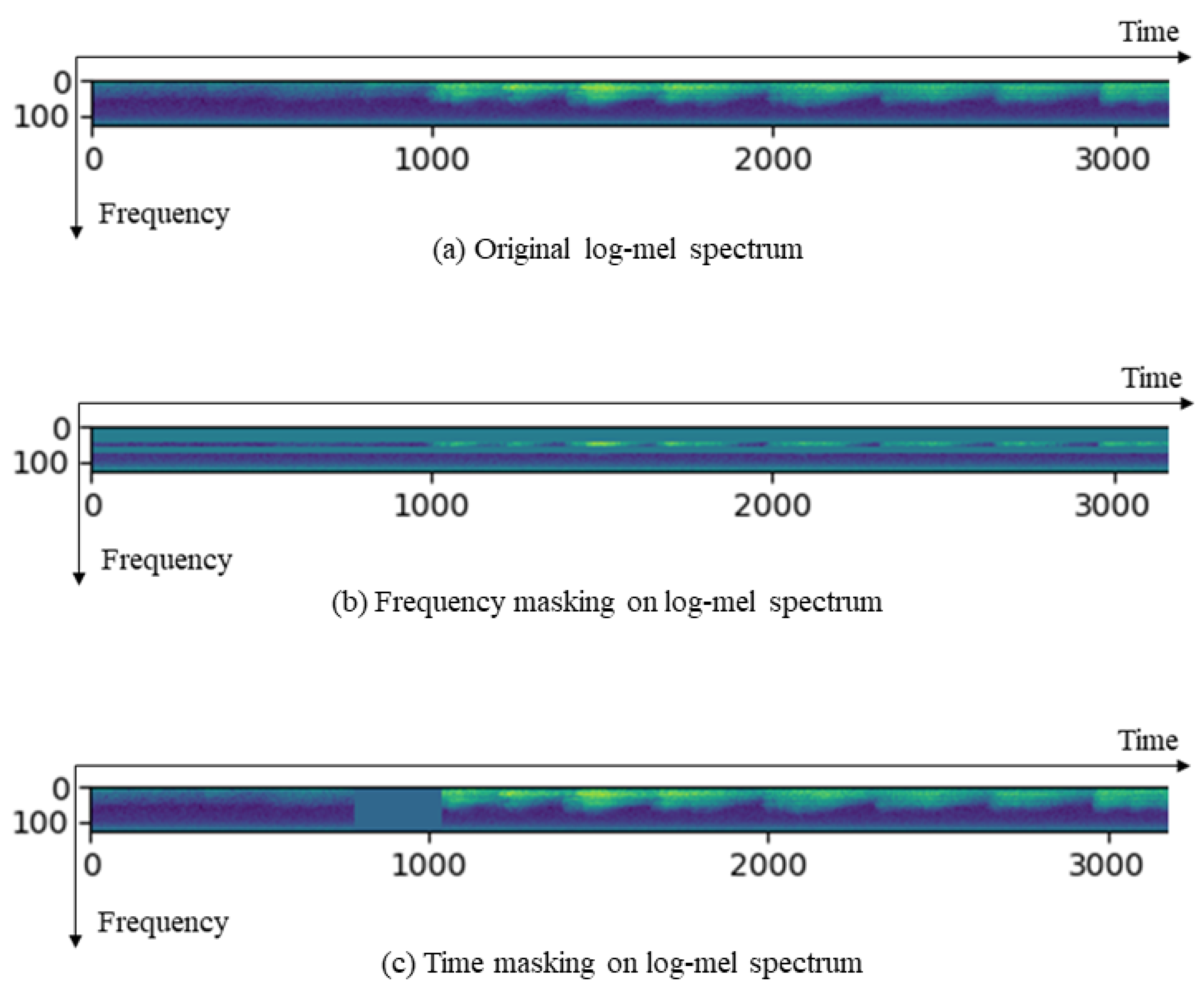
2.2.2. Data Augmentation
2.2.3. Focal Loss
2.3. Implementation Detail
3. Results and Discussions
3.1. Model Evaluation
3.2. Age Group Recognition Results
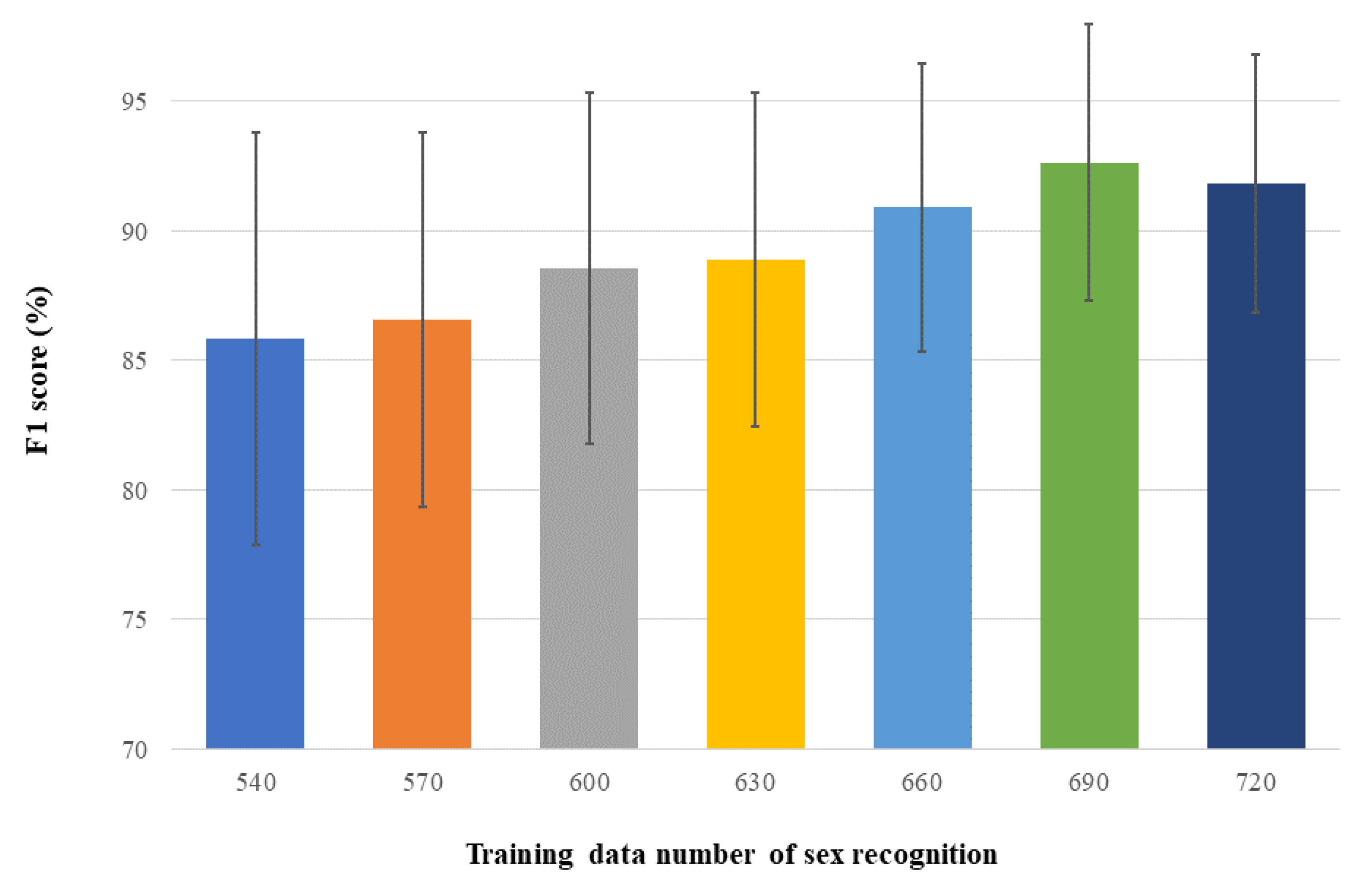
3.3. Sex Recognition Results
3.4. Discussions
4. Conclusions
5. Patents
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, P.; Swarup, P.; Matkowski, W.M.; Kong, A.; Han, S.; Zhang, Z.; Hou, R. A study on giant panda recognition based on images of a large proportion of captive pandas. Ecol. Evol. 2020, 10, 3561–3573. [Google Scholar] [CrossRef] [PubMed]
- McNeely, J.A.; Miller, K.R.; Reid, W.V.; Mittermeier, R.A.; Werner, T.B. Conserving the World’s Biological Diversity; International Union for Conservation of Nature and Natural Resources: Gland, Switzerland, 1990; pp. 1–192. [Google Scholar]
- Miller, C.R.; Joyce, P.; Waits, L.P. A new method for estimating the size of small populations from genetic mark-recapture data. Mol. Ecol. 2005, 14, 1991–2005. [Google Scholar] [CrossRef] [PubMed]
- Zhan, X.; Li, M.; Zhang, Z.; Goossens, B.; Chen, Y.; Wang, H.; Wei, F. Molecular censusing doubles giant panda population estimate in a key nature reserve. Curr. Biol. 2006, 16, R451–R452. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, D.; Zhang, G.; Wei, R.; Zhang, H.; Fang, J.; Sun, R. Effects of sex and age on the behavior of captive giant pandas (Ailuropoda melanoleuca). Dong Wu Xue Bao [Acta Zool. Sin.] 2002, 48, 585–590. [Google Scholar]
- Han, C.L.; Cao, Y.B.; Tang, C.X.; Zhang, G.Q.; Li, D.S. Application of Quantitative Method I and the Relation between Giant Panda’s (Ailuropoda melanoleuca) outdoor Activities and the Sex, Age, and Surroundings. J. Biomath. 2001, 16, 462–467. [Google Scholar]
- Hu, J.C. A study on the age and population composition of the giant panda by judging droppings in the wild. Acta Theriol. Sin. 1987, 7, 81–84. [Google Scholar]
- Moorhouse, T.P.; MacDonald, D.W. Indirect negative impacts of radio-collaring: Sex ratio variation in water voles. J. Appl. Ecol. 2005, 42, 91–98. [Google Scholar] [CrossRef]
- Zhan, X.J.; Tao, Y.; Li, M.; Zhang, Z.J.; Goossens, B.; Chen, Y.P.; Wang, H.J.; Bruford, M.; Wei, F.W. Accurate population size estimates are vital parameters for conserving the giant panda. Ursus 2009, 20, 56–62. [Google Scholar] [CrossRef]
- Swarup, P.; Chen, P.; Hou, R.; Que, P.; Kong, A. Giant panda behaviour recognition using images. Glob. Ecol. Conserv. 2021, 26, e01510. [Google Scholar] [CrossRef]
- Zhan, X.J.; Zhang, Z.J.; Wu, H.; Goossens, B.; Li, M.; Jiang, S.W.; Bruford, M.W.; Wei, F.W. Molecular analysis of dispersal in giant pandas. Mol. Ecol. 2007, 16, 3792–3800. [Google Scholar] [CrossRef]
- Marco, L.; Luc, A.; Louise, B.; Lou, S.; Jean-Julien, A. Angus: Real-time manipulation of vocal roughness for emotional speech transformations. arXiv 2020, arXiv:2008.11241. [Google Scholar]
- Charlton, B.D.; Zhang, Z.; Snyder, R.J. The information content of giant panda, ailuropoda melanoleuca, bleats: Acoustic cues to sex, age and size. Anim. Behav. 2009, 78, 893–898. [Google Scholar] [CrossRef]
- Oikarinen, T.; Srinivasan, K.; Meisner, O.; Hyman, J.B.; Parmar, S.; Fanucci-Kiss, A.; Desimone, R.; Landman, R.; Feng, G. Erratum: Deep convolutional network for animal sound classification and source attribution using dual audio recordings [J. Acoust. Soc. Am. 145, 654 (2019)]. J. Acoust. Soc. Am. 2019, 145, 2209. [Google Scholar] [CrossRef]
- Schroter, H.; Noth, E.; Maier, A.; Cheng, R.; Bergler, C. Segmentation, Classification, and Visualization of Orca Calls Using Deep Learning. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 8231–8235. [Google Scholar] [CrossRef]
- Alexandru, S.; Dan, S. Efficient Bird Sound Detection on the Bela Embedded System. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; Volume 2, pp. 746–750. [Google Scholar] [CrossRef]
- Nolasco, I.; Terenzi, A.; Cecchi, S.; Orcioni, S.; Bear, H.L.; Benetos, E. Audio-based identification of beehive states. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 8256–8260. [Google Scholar] [CrossRef]
- Kiskin, I.; Cobb, A.D.; Wang, L.; Roberts, S. Humbug zooniverse: A crowd-sourced acoustic mosquito dataset. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 916–920. [Google Scholar] [CrossRef] [Green Version]
- Analysis and Research of Giant Panda Individual Identification System Based on Voiceprint. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2019.
- Yan, W.R.; Tang, M.L.; Zhao, Q.J.; Chen, P.; Qi, D.W.; Hou, R.; Zhang, Z.H. Automatically predicting giant panda mating success based on acoustic features. Glob. Ecol. Conserv. 2020, 24, e01301. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Hou, R.; Guo, L.Y.; Liu, P.; Zhao, Q.J.; Chen, P. Automatically Distinguishing Adult from Young Giant Pandas Based on Their Call. In Proceedings of the Chinese Conference on Biometric Recognition, Online, 10–12 September 2021; pp. 92–101. [Google Scholar] [CrossRef]
- Nagamanoj, K.; Arti, A. A Scalable Hybrid Classifier for Music Genre Classification using Machine Learning Concepts and Spark. In Proceedings of the 2018 International Conference on Intelligent Autonomous Systems (ICoIAS), Singapore, 1–3 March 2018; pp. 128–135. [Google Scholar] [CrossRef]
- Józef, B.; Janusz, M. LIDFT method with classic data windows and zero padding in multifrequency signal analysis. Measurement 2010, 43, 1595–1602. [Google Scholar] [CrossRef]
- Seyedamiryousef, H.; Mahdieh, G.; Sajad, H. A Wavelet Transform Based Scheme to Extract Speech Pitch and Formant Frequencies. arXiv 2022, arXiv:2209.00733. [Google Scholar]
- Darch, J.; Milner, B.; Shao, X.; Vaseghi, S.; Yan, Q. Predicting formant frequencies from mfcc vectors. In Proceedings of the ICASSP 2005—2005 IEEE International Conference on Acoustics, Speech and Signal Processing, Philadelphia, PA, USA, 23 March 2005; p. I-941. [Google Scholar] [CrossRef] [Green Version]
- Peters, G. A comparative survey of vocalization in the giant panda. Ailuropoda Melanoleuca 1985, 36, 197–208. [Google Scholar]
- Zhao, C.; Wang, P. The sound spectrum analysis of calls in the baby giant panda. Discov. Nat. 1988, 2, 99–102. [Google Scholar]
- Jie, H.; Li, S.; Samuel, A.; Gang, S.; Enhua, W. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 99. [Google Scholar] [CrossRef] [Green Version]
- Technicolor, T.; Related, S.; Technicolor, T.; Related, S. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Training Data | Mutually Exclusive | Augmentation | Loss |
|---|---|---|---|---|
| 1 | 540 | No | No | Cross entropy |
| 2A | 540 | Yes | No | Cross entropy |
| 2B | 540 | Yes | Yes | Cross entropy |
| 2C | 540 | Yes | Yes | Focal loss |
| 3 | 540~720 (30 clips up) | Yes | Yes | Focal loss |
| Experiment | Training Time |
|---|---|
| 1 | about 1.5 h |
| 2A | about 1.5 h |
| 2B | about 2 h |
| 2C | about 2 h |
| 3 | about 13.5 h |
| Mutually Exclusive | Augmentation | Loss | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| No | No | Cross entropy | 99.35% ± 0.56% | 97.23% ± 2.34% | 98.28% ± 1.27% |
| Yes | No | Cross entropy | 82.96% ± 10.43% | 83.50% ± 15.03% | 83.23% ± 13.21% |
| Yes | Yes | Cross entropy | 92.58% ± 6.66% | 85.43% ± 11.80% | 88.86% ± 7.14% |
| Yes | Yes | Focal loss | 97.43% ± 4.65% | 95.51% ± 7.98% | 96.46% ± 5.71% |
| Training Data | F1 Score |
|---|---|
| 540 | 96.46% ± 5.71% |
| 570 | 97.50% ± 4.20% |
| 600 | 98.73% ± 2.77% |
| 630 | 99.75% ± 2.05% |
| 660 | 99.13% ± 1.56% |
| 690 | 99.91% ± 1.25% |
| 720 | 99.98% ± 0.77% |
| Mutually Exclusive | Augmentation | Loss | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
| No | No | Cross entropy | 96.75% ± 0.94% | 92.24% ± 3.12% | 94.44% ± 1.56% |
| Yes | No | Cross entropy | 84.19% ± 12.84% | 76.98% ± 19.42% | 80.42% ± 15.64% |
| Yes | Yes | Cross entropy | 86.63% ± 7.14% | 77.43% ± 12.38% | 81.77% ± 10.96% |
| Yes | Yes | Focal loss | 91.93% ± 5.97% | 80.52% ± 9.28% | 85.85% ± 7.99% |
| Training Data | F1 Score |
|---|---|
| 540 | 85.85% ± 7.99% |
| 570 | 86.58% ± 7.23% |
| 600 | 88.57% ± 6.79% |
| 630 | 88.89% ± 6.44% |
| 660 | 90.91% ± 5.58% |
| 690 | 92.65% ± 5.34% |
| 720 | 91.85% ± 4.98% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Q.; Zhang, Y.; Hou, R.; He, M.; Liu, P.; Xu, P.; Zhang, Z.; Chen, P. Automatic Recognition of Giant Panda Attributes from Their Vocalizations Based on Squeeze-and-Excitation Network. Sensors 2022, 22, 8015. https://doi.org/10.3390/s22208015
Zhao Q, Zhang Y, Hou R, He M, Liu P, Xu P, Zhang Z, Chen P. Automatic Recognition of Giant Panda Attributes from Their Vocalizations Based on Squeeze-and-Excitation Network. Sensors. 2022; 22(20):8015. https://doi.org/10.3390/s22208015
Chicago/Turabian StyleZhao, Qijun, Yanqiu Zhang, Rong Hou, Mengnan He, Peng Liu, Ping Xu, Zhihe Zhang, and Peng Chen. 2022. "Automatic Recognition of Giant Panda Attributes from Their Vocalizations Based on Squeeze-and-Excitation Network" Sensors 22, no. 20: 8015. https://doi.org/10.3390/s22208015
APA StyleZhao, Q., Zhang, Y., Hou, R., He, M., Liu, P., Xu, P., Zhang, Z., & Chen, P. (2022). Automatic Recognition of Giant Panda Attributes from Their Vocalizations Based on Squeeze-and-Excitation Network. Sensors, 22(20), 8015. https://doi.org/10.3390/s22208015