
DAG-Based Blockchain Sharding for Secure Federated Learning with Non-IID Data


Abstract
:1. Introduction
- This is the first blockchain study on model protection from a poisoning attack during federated learning with non-IID train and test datasets.
- A novel secure update mechanism of the global model is proposed from the asynchronously operating distributed DAG shards.
- This is an empirical study conducted on a real testbed for investigating the feasibility of the proposed system using a convolutional neural network (CNN) and the MNIST dataset.
2. Federated Learning
2.1. Federated Model Averaging
2.2. Asynchronous Federated Learning
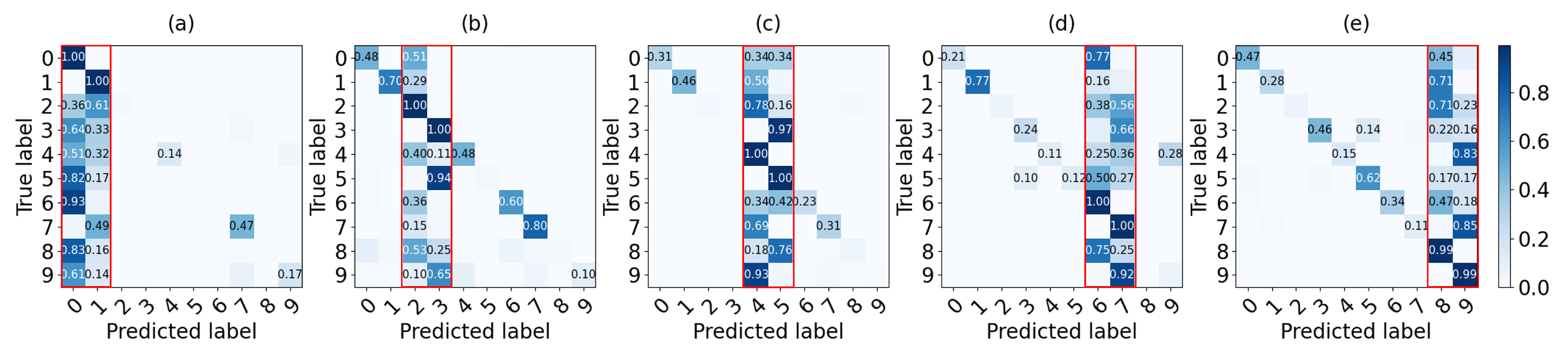
2.3. Training with Non-IID Data
3. Blockchain for Federated Learning
3.1. Blockchain Overview
3.2. Blockchain Scalability
3.3. Blockchain for Federated Learning
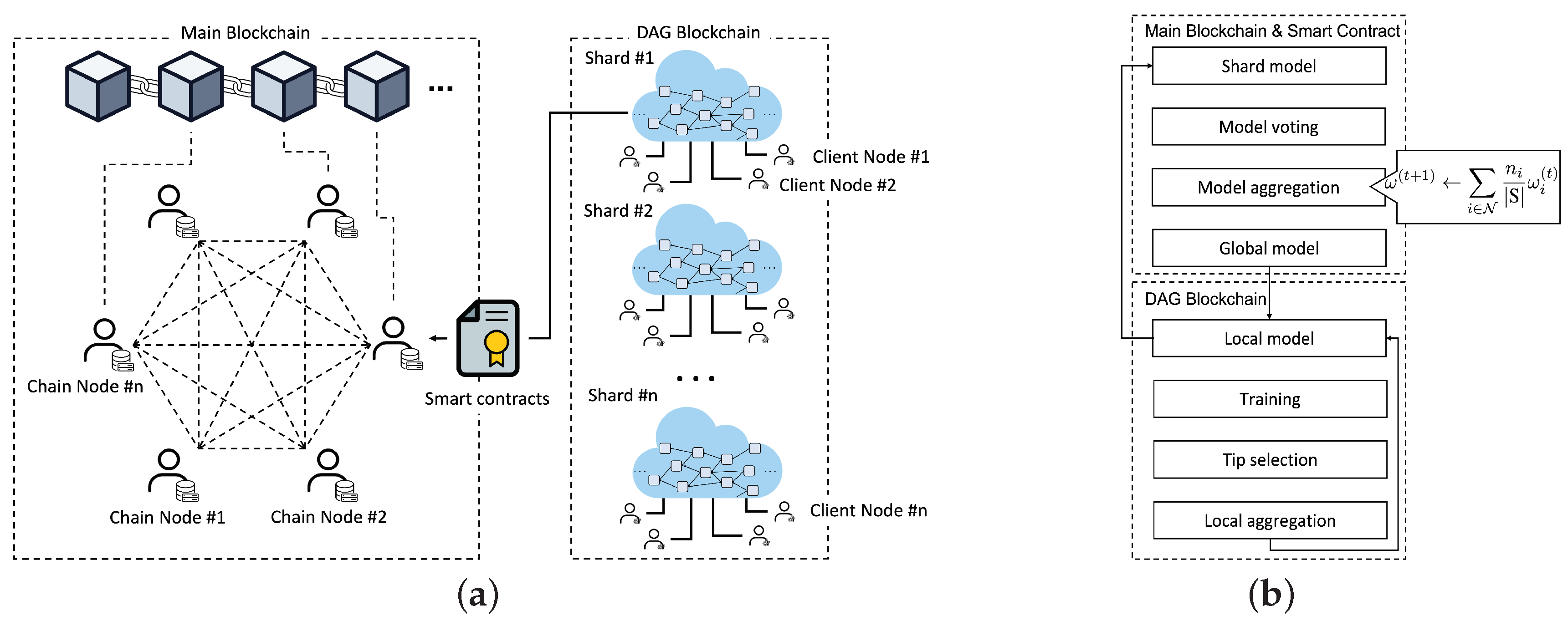
4. DAG-Based Sharding for Secure Federated Learning
- Each node has a non-IID dataset for training and testing with a different distribution probability.
- The computing capability of a node varies according to the device type.
- Open accessibility allows Sybil-based poisoning attacks on local or global models.
4.1. Hierarchical Blockchain Architecture for Federated Learning
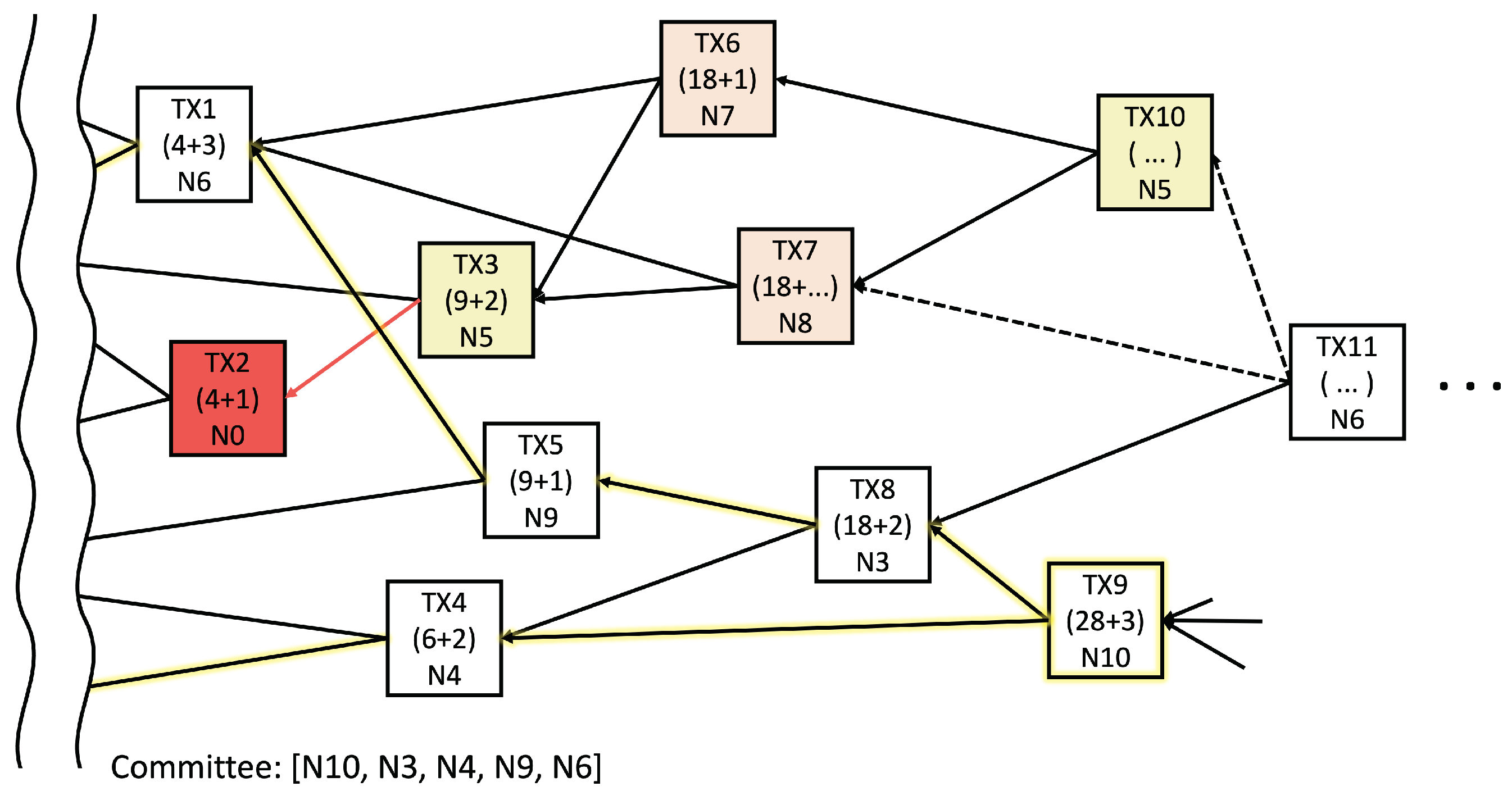
4.2. DAG-Based Shard Formation
| Algorithm 1 Shard initiation algorithm. |
| Input: |
|
4.3. Local Model Aggregation
| Algorithm 2 Local model aggregation algorithm. |
| Input: node has participated in |
|
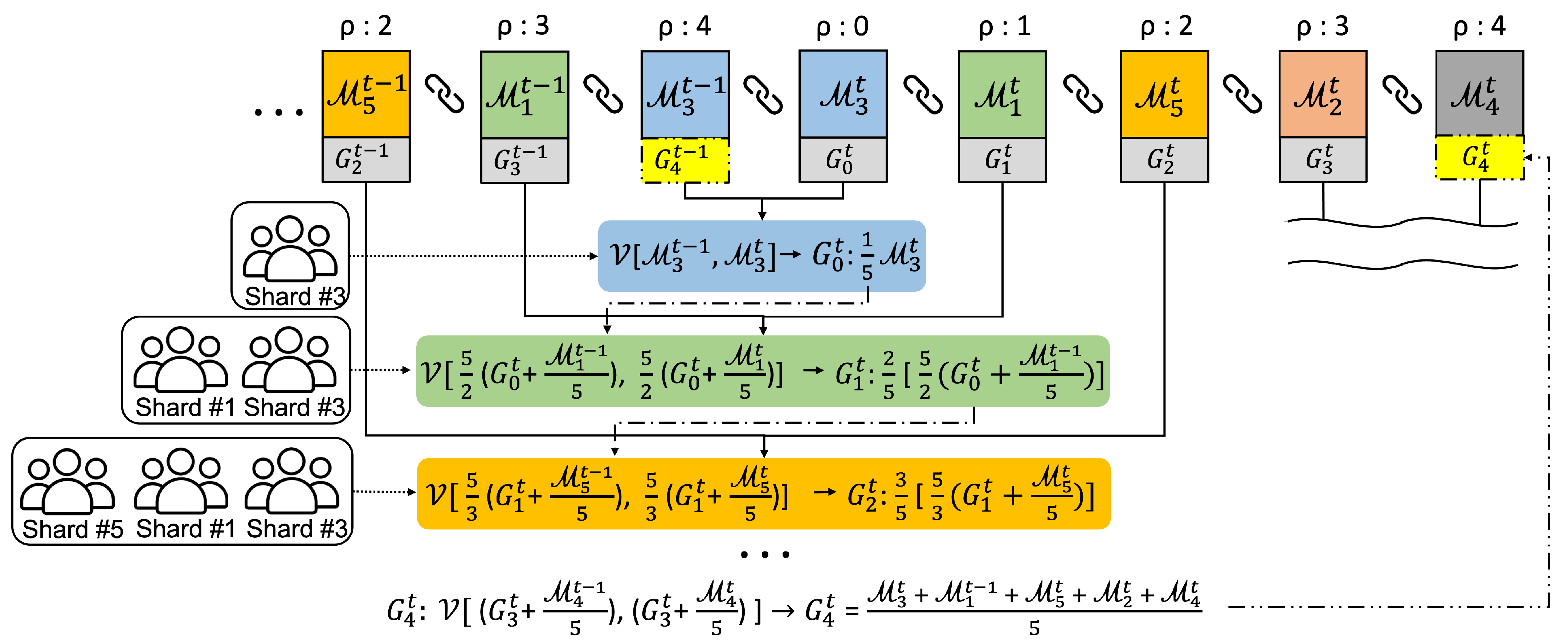
4.4. Global Model Aggregation
| Algorithm 3 Global model aggregation algorithm. |
|
5. Experiment
5.1. Experimental Setup
Attack Scenarios
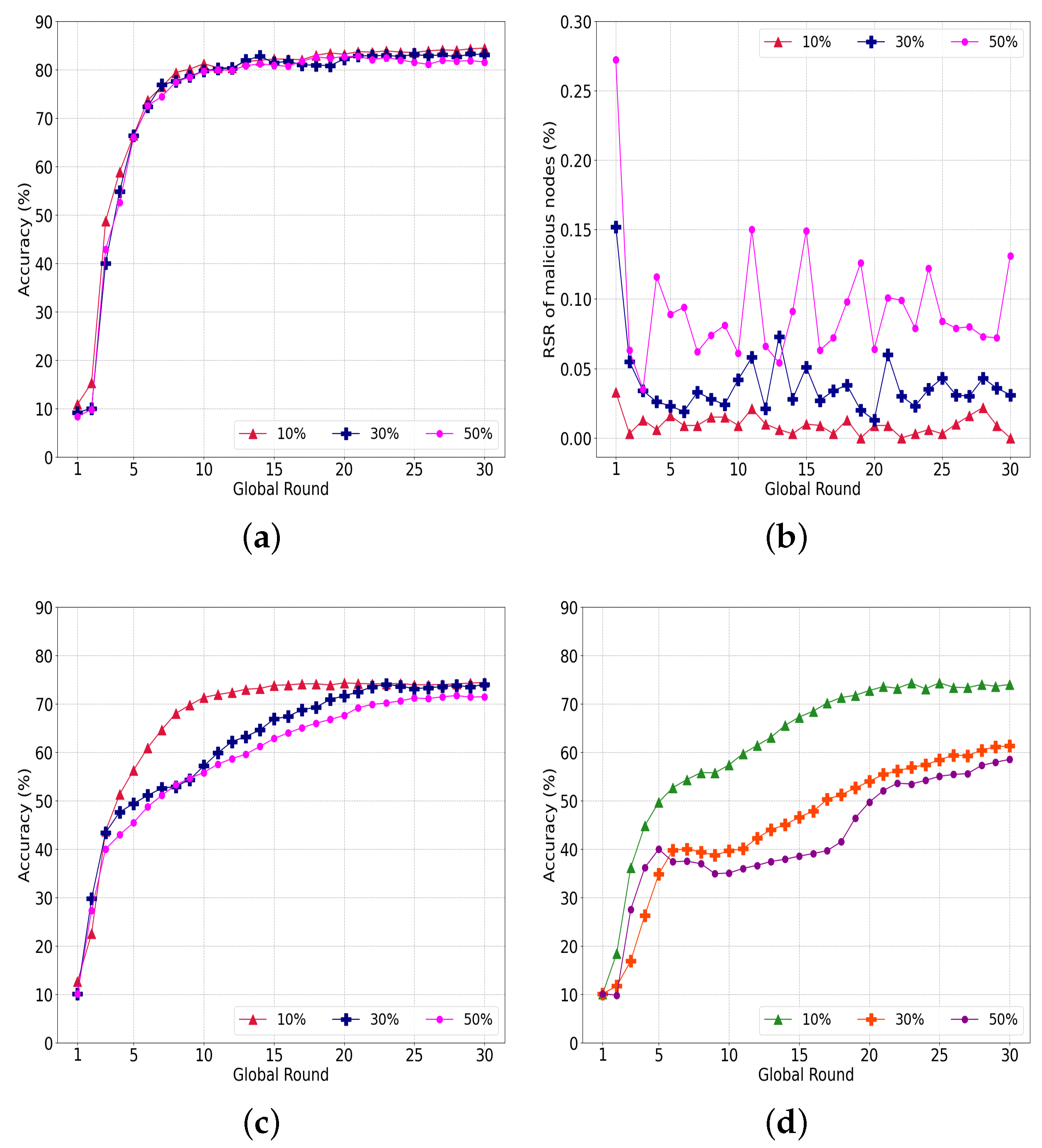
- Model-poisoning attack: The purpose of a model-poisoning attack is to upload an arbitrarily altered model to deviate the global model from a target model. In our experiments, a malicious node generated additive Gaussian noise with . As many noise vectors as the number of model parameters were extracted and added to them.
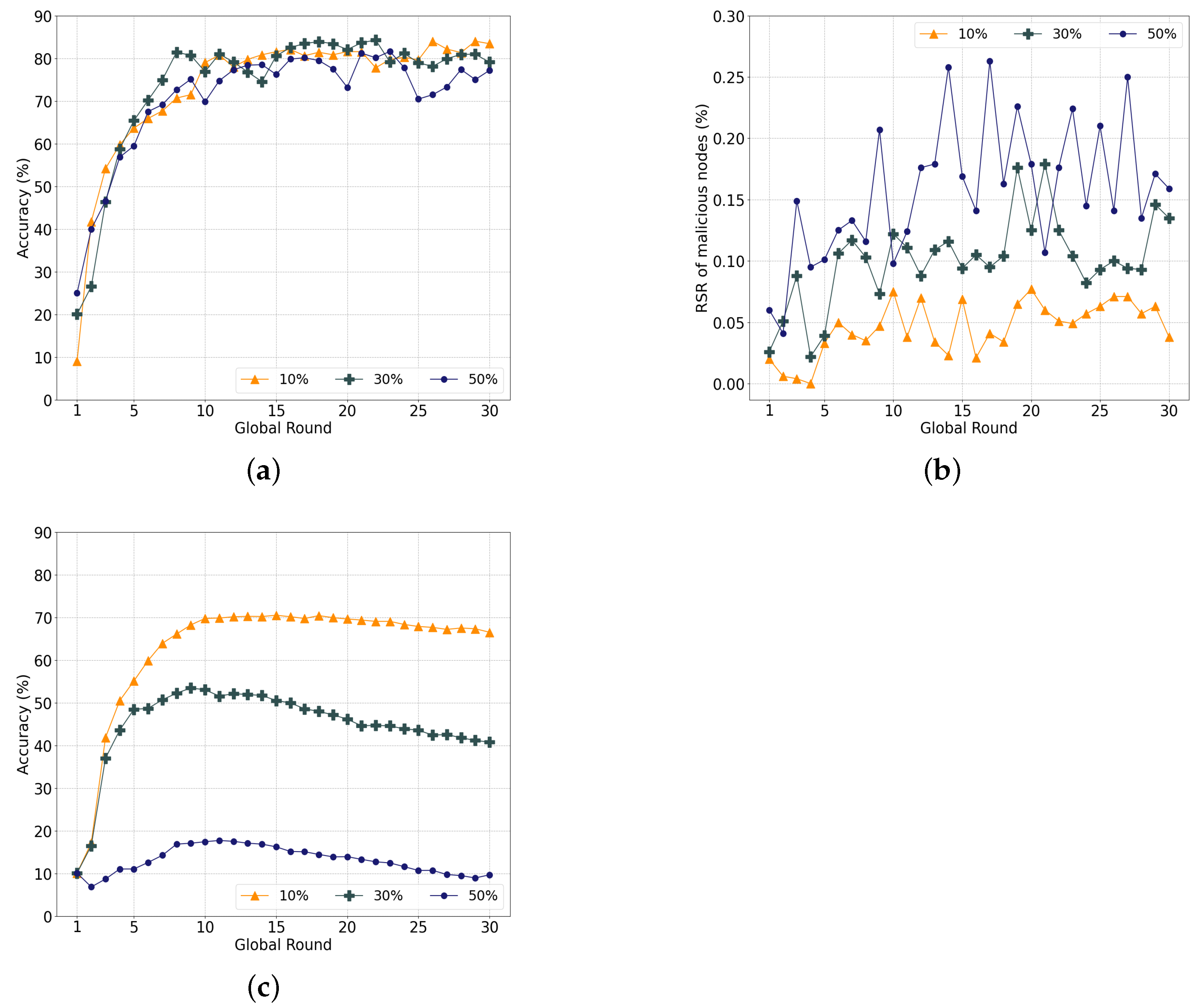
- Data-poisoning attack: A data-poisoning attack is a type of interference in learning using poisoned data and is known to be less effective than a model-poisoning attack. To evaluate the vulnerability of our system against a data-poisoning attack, the MNIST training data were manipulated by randomly generated additive noise with a Gaussian distribution . We generated a random 28 × 28 noise image and added it to each MNIST training image.
- Label-swapping attack: A label-swapping attack, similar to a data-poisoning attack, is an efficient attack without directly damaging the model or training data. It proceeds simply by swapping the input labels for the corresponding data. For example, an attacker trains a model using 2 and 3 data, which are tagged by the swapped labels `3’ and `2’, respectively.
5.2. Shard Layer Review
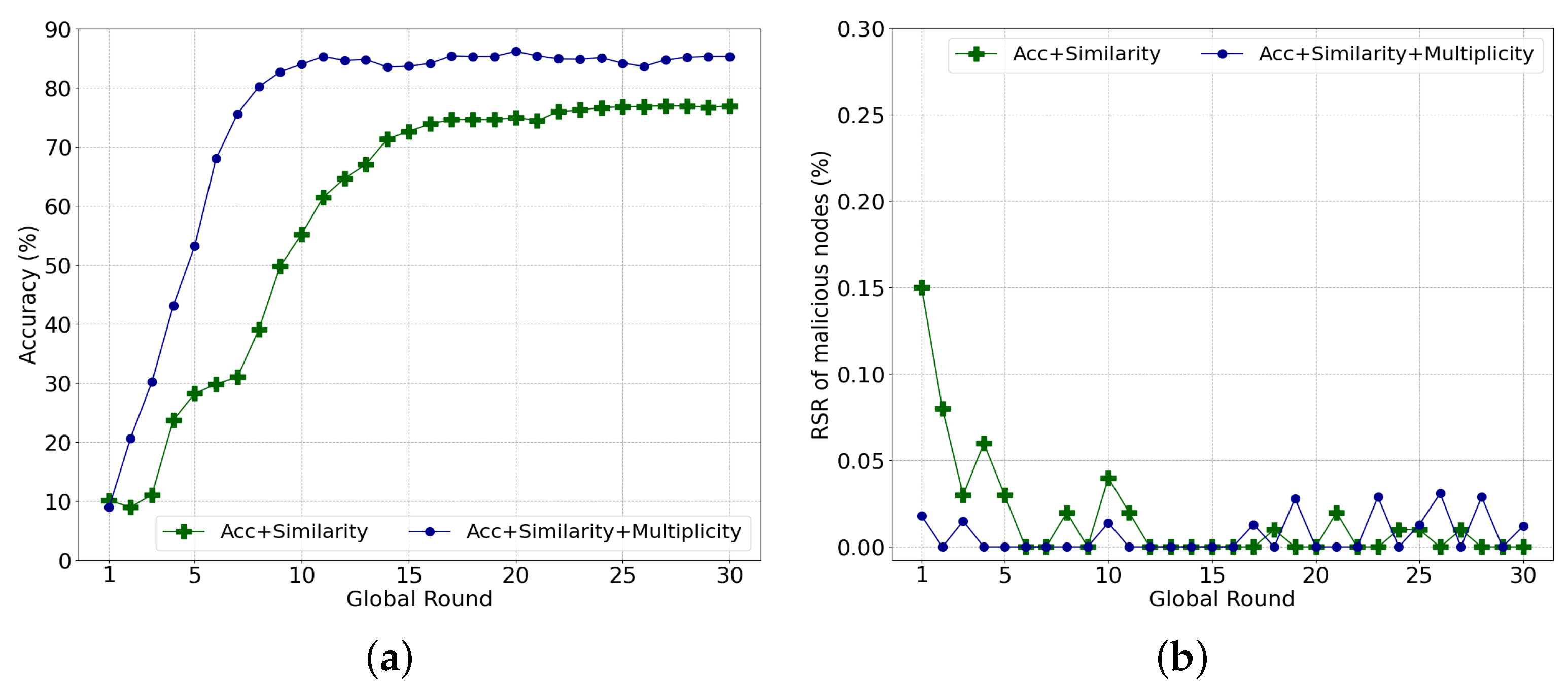
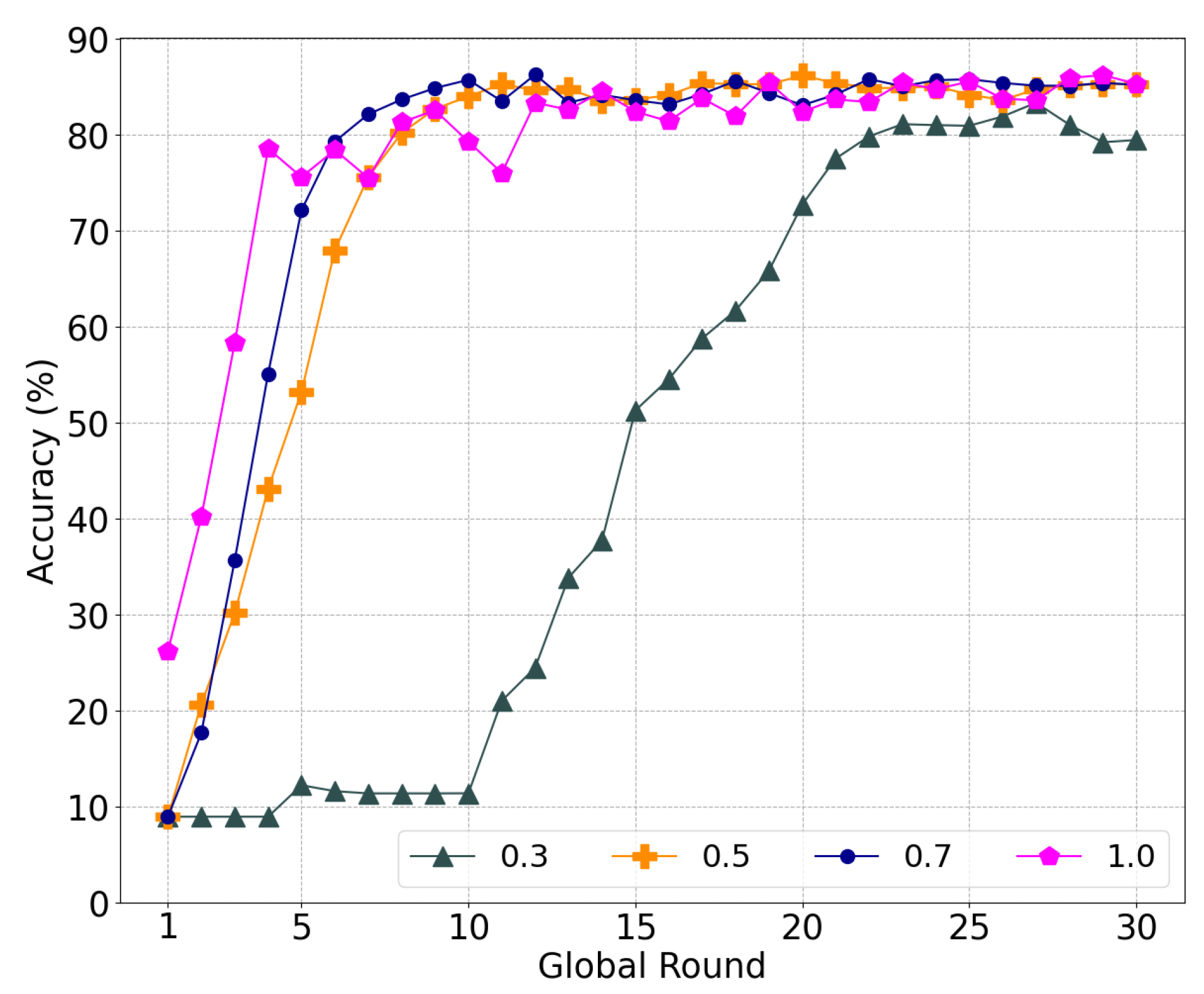
5.2.1. Performance According to Similarity Parameter
5.2.2. Multiplicity Effect on Performance
5.3. Main Blockchain Layer Review
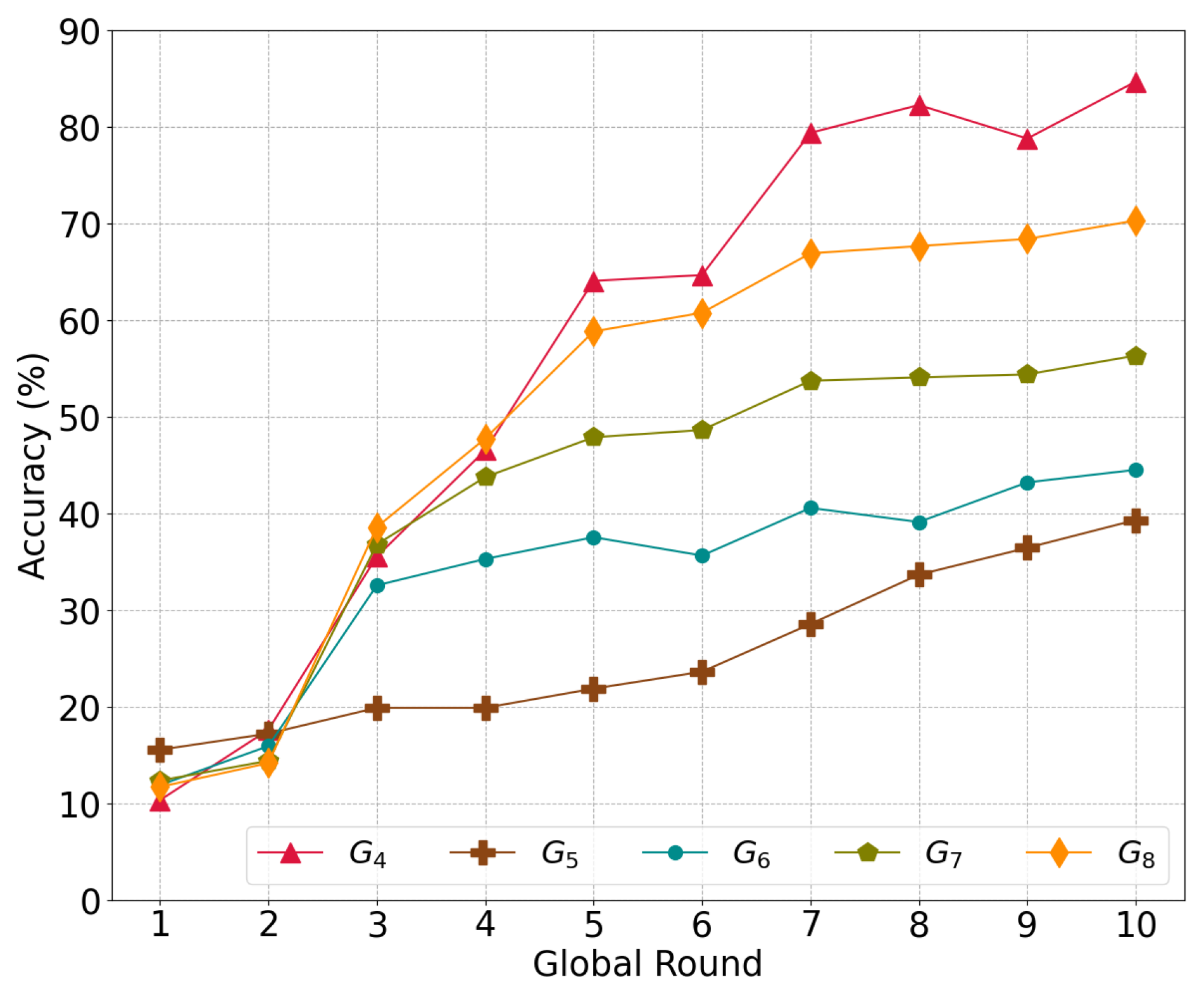
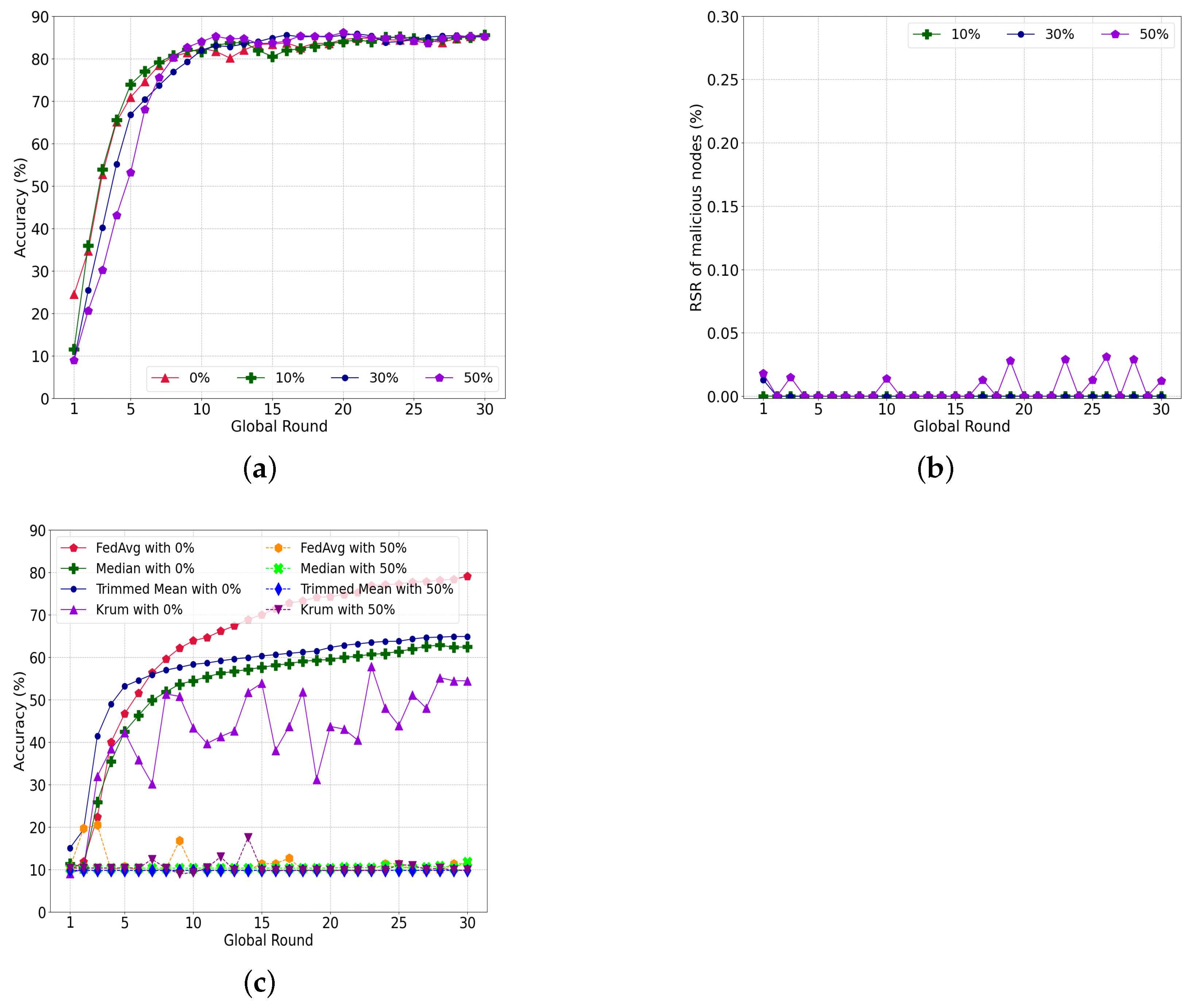
5.3.1. Performance Depending on the Local Model Proportion to the Global Model
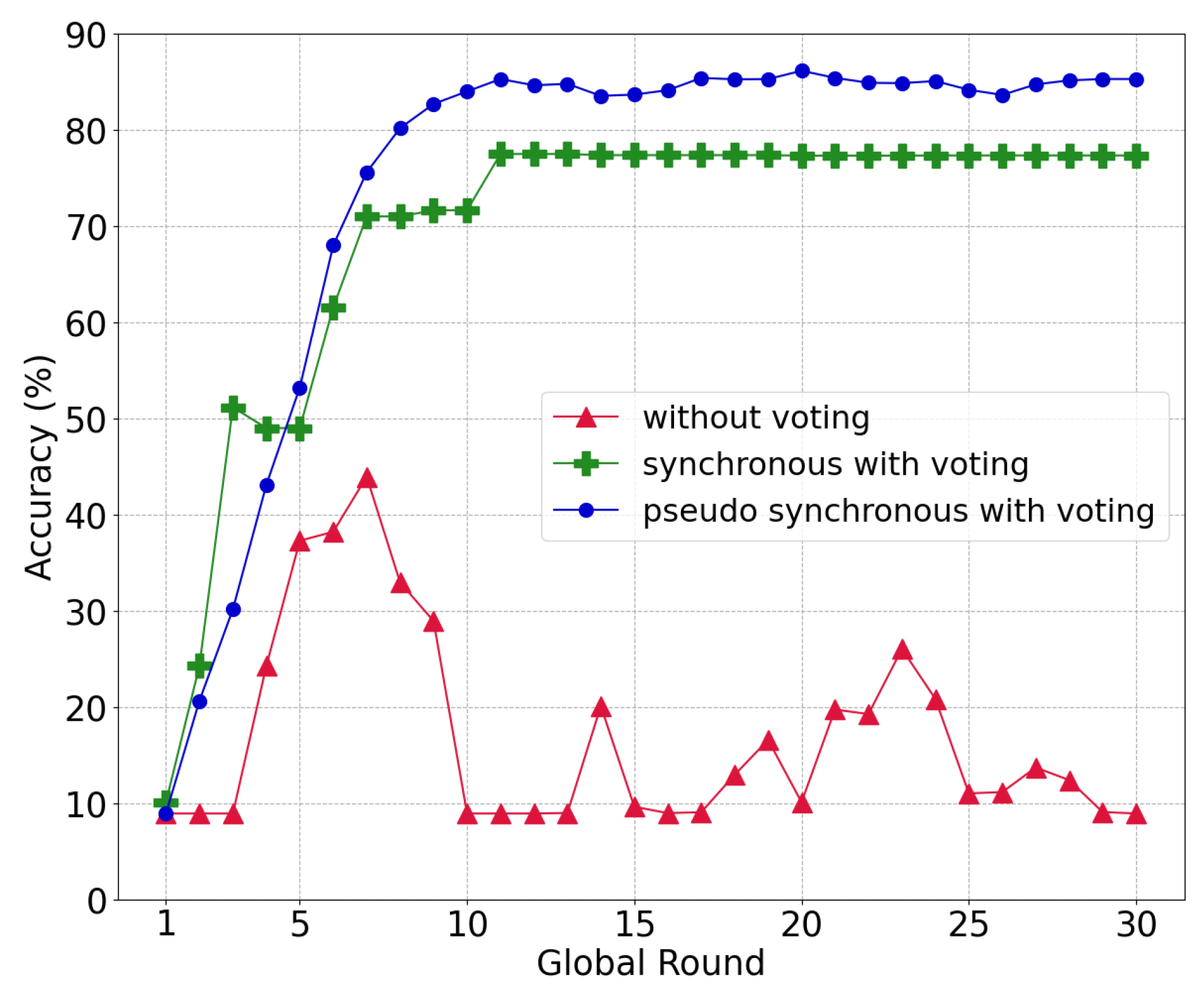
5.3.2. Compare the Various Voting Systems
5.3.3. Global Model Update Speed
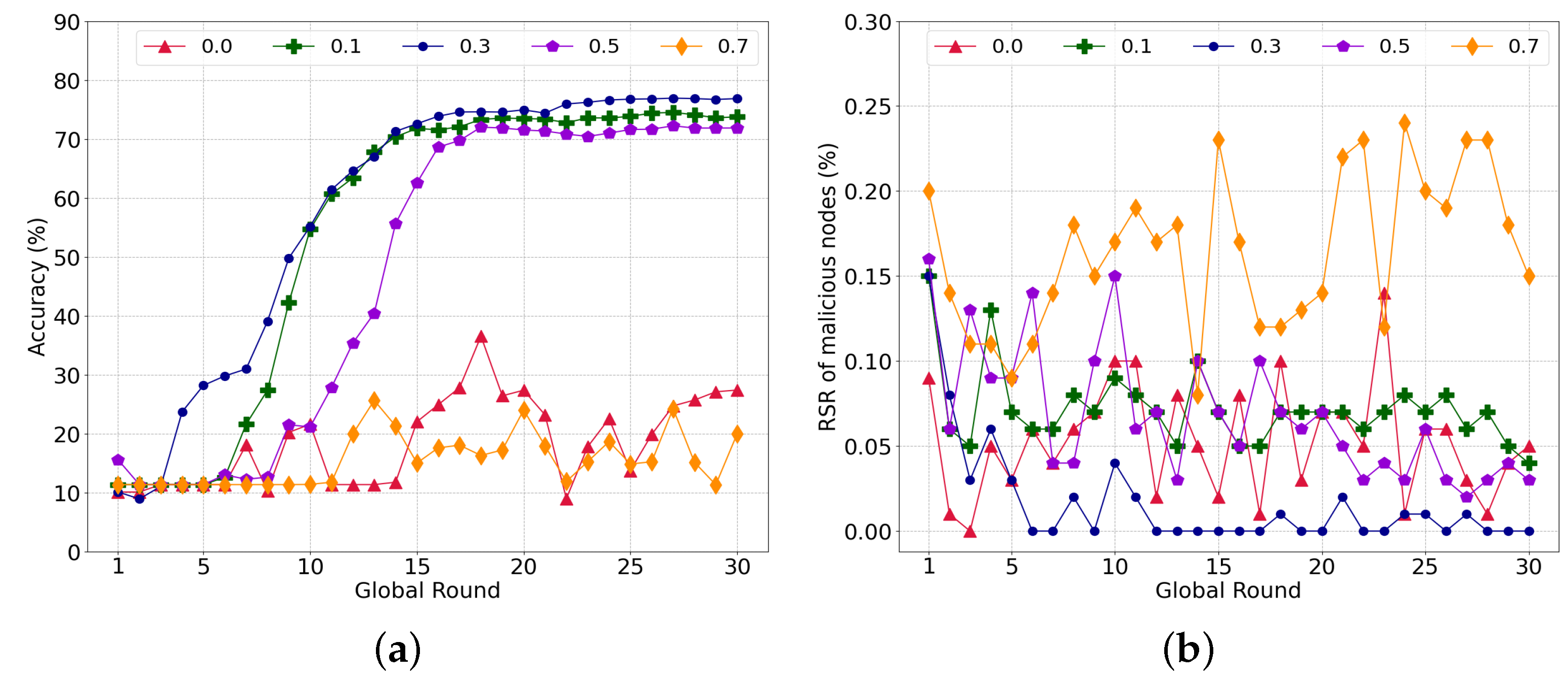
5.4. Performance for the Various Attack Scenarios
5.4.1. Model-Poisoning Attacks
5.4.2. Data-Poisoning Attacks
5.4.3. Label-Swapping Attacks
6. Conclusions
7. Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Regulation, G.D.P. General data protection regulation (GDPR). Intersoft Consult. 2018, 1, 1–9. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Nguyen, D.C.; Ding, M.; Pham, Q.V.; Pathirana, P.N.; Le, L.B.; Seneviratne, A.; Li, J.; Niyato, D.; Poor, H.V. Federated learning meets blockchain in edge computing: Opportunities and challenges. IEEE Internet Things J. 2021, 8, 12806–12825. [Google Scholar] [CrossRef]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Model poisoning attacks in federated learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1–23. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local Model Poisoning Attacks to {Byzantine-Robust} Federated Learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Online, 7–11 August 2020; pp. 1605–1622. [Google Scholar]
- Lyu, L.; Yu, H.; Yang, Q. Threats to federated learning: A survey. arXiv 2020, arXiv:2003.02133. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Sattler, F.; Müller, K.R.; Wiegand, T.; Samek, W. On the byzantine robustness of clustered federated learning. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8861–8865. [Google Scholar]
- Yadav, K.; Gupta, B. Clustering Algorithm to Detect Adversaries in Federated Learning. arXiv 2021, arXiv:2102.10799. [Google Scholar]
- Li, S.; Cheng, Y.; Wang, W.; Liu, Y.; Chen, T. Learning to detect malicious clients for robust federated learning. arXiv 2020, arXiv:2002.00211. [Google Scholar]
- Che, C.; Li, X.; Chen, C.; He, X.; Zheng, Z. A decentralized federated learning framework via committee mechanism with convergence guarantee. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 4783–4800. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Decentralized Bus. Rev. 2008, 21260. [Google Scholar]
- Wood, G. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Schwartz, D.; Youngs, N.; Britto, A. Ripple. 2014. Available online: https://ripple.com/files/ripple-consensus-whitepaper.pdf (accessed on 25 September 2022).
- Mazieres, D. The stellar consensus protocol: A federated model for internet-level consensus. Stellar Dev. Found. 2015, 32, 1–45. [Google Scholar]
- Pokhrel, S.R.; Choi, J. Federated learning with blockchain for autonomous vehicles: Analysis and design challenges. IEEE Trans. Commun. 2020, 68, 4734–4746. [Google Scholar] [CrossRef]
- Bao, X.; Su, C.; Xiong, Y.; Huang, W.; Hu, Y. Flchain: A blockchain for auditable federated learning with trust and incentive. In Proceedings of the 2019 5th International Conference on Big Data Computing and Communications (BIGCOM), Qingdao, China, 9–11 August 2019; pp. 151–159. [Google Scholar]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. On-device federated learning via blockchain and its latency analysis. arXiv 2018, arXiv:1808.03949. [Google Scholar]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain empowered asynchronous federated learning for secure data sharing in internet of vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Communication-efficient federated learning and permissioned blockchain for digital twin edge networks. IEEE Internet Things J. 2020, 8, 2276–2288. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Low-latency federated learning and blockchain for edge association in digital twin empowered 6G networks. IEEE Trans. Ind. Inf. 2020, 17, 5098–5107. [Google Scholar] [CrossRef]
- Desai, H.B.; Ozdayi, M.S.; Kantarcioglu, M. Blockfla: Accountable federated learning via hybrid blockchain architecture. In Proceedings of the Eleventh ACM Conference on Data and Application Security and Privacy, Virtual Event, 26–28 April 2021; pp. 101–112. [Google Scholar]
- Weng, J.; Weng, J.; Zhang, J.; Li, M.; Zhang, Y.; Luo, W. Deepchain: Auditable and privacy-preserving deep learning with blockchain-based incentive. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2438–2455. [Google Scholar] [CrossRef]
- Qu, Y.; Gao, L.; Luan, T.H.; Xiang, Y.; Yu, S.; Li, B.; Zheng, G. Decentralized privacy using blockchain-enabled federated learning in fog computing. IEEE Internet Things J. 2020, 7, 5171–5183. [Google Scholar] [CrossRef]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated learning on non-IID data: A survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Wang, H.; Kaplan, Z.; Niu, D.; Li, B. Optimizing federated learning on non-iid data with reinforcement learning. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1698–1707. [Google Scholar]
- Li, Y.; Chen, C.; Liu, N.; Huang, H.; Zheng, Z.; Yan, Q. A blockchain-based decentralized federated learning framework with committee consensus. IEEE Netw. 2020, 35, 234–241. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics (AISTATS 2017), Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Xie, C.; Koyejo, S.; Gupta, I. Asynchronous federated optimization. arXiv 2019, arXiv:1903.03934. [Google Scholar]
- Chai, Z.; Chen, Y.; Zhao, L.; Cheng, Y.; Rangwala, H. Fedat: A communication-efficient federated learning method with asynchronous tiers under non-iid data. ArXivorg 2020, 60, 1–16. [Google Scholar]
- Chen, Y.; Ning, Y.; Slawski, M.; Rangwala, H. Asynchronous online federated learning for edge devices with non-iid data. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 15–24. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the convergence of fedavg on non-iid data. arXiv 2019, arXiv:1907.02189. [Google Scholar]
- King, S.; Nadal, S. 2017. Available online: https://peercoin.net/assets/paper/peercoin-paper.pdf (accessed on 25 September 2022).
- Vasin, P. BlackCoin’s Proof-of-Stake Protocol v2. 2016. Available online: https://blackcoin.org/blackcoin-pos-protocol-v2-whitepaper.pdf (accessed on 25 September 2022).
- Nxt Wiki. 2016. Available online: https://nxtplatform.org/ (accessed on 25 September 2022).
- Bentov, I.; Gabizon, A.; Mizrahi, A. Cryptocurrencies without proof of work. In Proceedings of the International Conference on Financial Cryptography and Data Security, Christ Church, Barbados, 22–26 February 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 142–157. [Google Scholar]
- BitShare. 2016. Available online: https://bitshares.org/technology/delegated-proof-of-stake-consensus/ (accessed on 25 September 2022).
- P4Titan. 2014. Slimcoin: A Peer-to-Peer Crypto-currency with Proof-of-Burn. Available online: https://slimcoin.info/whitepaperSLM.pdf (accessed on 25 September 2022).
- Tendermint. 2018. Available online: https://tendermint.com/ (accessed on 25 September 2022).
- Park, S.; Pietrzak, K.; Alwen, J.; Fuchsbauer, G.; Gazi, P. Spacecoin: A Cryptocurrency Based on Proofs of Space; Technical Report, IACR Cryptology ePrint Archive 2015. 2015. Available online: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwiKx7u_h4L7AhWjmVYBHWoVDK0QFnoECA4QAQ&url=https%3A%2F%2Fwww.allcryptowhitepapers.com%2Fwp-content%2Fuploads%2F2018%2F05%2FSpacecoin.pdf&usg=AOvVaw3X70G1HG_AxQq6hcXs3iMG (accessed on 25 September 2022).
- BurstCoin. 2018. Available online: https://burstcoin.info/ (accessed on 25 September 2022).
- Luu, L.; Narayanan, V.; Zheng, C.; Baweja, K.; Gilbert, S.; Saxena, P. A secure sharding protocol for open blockchains. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 17–30. [Google Scholar]
- Vukolić, M. The quest for scalable blockchain fabric: Proof-of-work vs. BFT replication. In Proceedings of the International Workshop on Open Problems in Network Security, Zurich, Switzerland, 29 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 112–125. [Google Scholar]
- Zamani, M.; Movahedi, M.; Raykova, M. RapidChain: Scaling blockchain via full sharding. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 931–948. [Google Scholar]
- Eyal, I.; Gencer, A.E.; Sirer, E.G.; Van Renesse, R. Bitcoin-NG: A Scalable Blockchain Protocol. In Proceedings of the NSDI, Santa Clara, CA, USA, 16–18 March 2016; pp. 45–59. [Google Scholar]
- Raiden Network. 2018. Available online: https://raiden.network/ (accessed on 25 September 2022).
- Plasma. 2017. Available online: https://plasma.io/ (accessed on 25 September 2022).
- Herrera-Joancomartí, J.; Pérez-Solà, C. Privacy in bitcoin transactions: New challenges from blockchain scalability solutions. In Proceedings of the Modeling Decisions for Artificial Intelligence, Sant Julià de Lòria, Andorra, 19–21 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 26–44. [Google Scholar]
- Danezis, G.; Meiklejohn, S. Centrally banked cryptocurrencies. arXiv 2015, arXiv:1505.06895. [Google Scholar]
- Kokoris-Kogias, E.; Jovanovic, P.; Gasser, L.; Gailly, N.; Syta, E.; Ford, B. Omniledger: A secure, scale-out, decentralized ledger via sharding. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 583–598. [Google Scholar]
- Pervez, H.; Muneeb, M.; Irfan, M.U.; Haq, I.U. A comparative analysis of DAG-based blockchain architectures. In Proceedings of the 2018 12th International Conference on Open Source Systems and Technologies (ICOSST), Lahore, Pakistan, 19–21 December 2018; pp. 27–34. [Google Scholar]
- Conti, M.; Kumar, G.; Nerurkar, P.; Saha, R.; Vigneri, L. A survey on security challenges and solutions in the IOTA. J. Netw. Comput. Appl. 2022, 203, 103383. [Google Scholar] [CrossRef]
- dagCoin. 2022. Available online: https://dagcoin.org/ (accessed on 25 September 2022).
- Feng, L.; Zhao, Y.; Guo, S.; Qiu, X.; Li, W.; Yu, P. BAFL: A Blockchain-Based Asynchronous Federated Learning Framework. IEEE Trans. Comput. 2022, 71, 1092–1103. [Google Scholar] [CrossRef]
- Shayan, M.; Fung, C.; Yoon, C.J.; Beschastnikh, I. Biscotti: A blockchain system for private and secure federated learning. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1513–1525. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y. Asynchronous Hierarchical Federated Learning. arXiv 2022, arXiv:2206.00054. [Google Scholar]
- Kang, J.; Xiong, Z.; Niyato, D.; Zou, Y.; Zhang, Y.; Guizani, M. Reliable federated learning for mobile networks. IEEE Wirel. Commun. 2020, 27, 72–80. [Google Scholar] [CrossRef] [Green Version]
- Ferraro, P.; King, C.; Shorten, R. On the stability of unverified transactions in a DAG-based distributed ledger. IEEE Trans. Autom. Control 2019, 65, 3772–3783. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Set of client nodes in a federated learning network. | |
| i | A client node that conducts local training in the network. |
| Set of local data samples that each node i owns. | |
| Learning rate. | |
| w | The weight of model. |
| The cumulative reference score (CRS) of the transaction. | |
| S | Set of shards in the network. |
| A shard where the index is k. | |
| The local model for the maximum reference score within a specific range in each shard. | |
| A global model. | |
| The integer value starting from 0 to as the order of the shard models uploaded to the main blockchain. | |
| Voting function: nodes belonging to the committee select one model based on the accuracy of the two models. | |
| r | Global round |
| B | The local batch size |
| E | The number of local epochs |
| A transaction in the DAG blockchain. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Kim, W. DAG-Based Blockchain Sharding for Secure Federated Learning with Non-IID Data. Sensors 2022, 22, 8263. https://doi.org/10.3390/s22218263
Lee J, Kim W. DAG-Based Blockchain Sharding for Secure Federated Learning with Non-IID Data. Sensors. 2022; 22(21):8263. https://doi.org/10.3390/s22218263
Chicago/Turabian StyleLee, Jungjae, and Wooseong Kim. 2022. "DAG-Based Blockchain Sharding for Secure Federated Learning with Non-IID Data" Sensors 22, no. 21: 8263. https://doi.org/10.3390/s22218263
APA StyleLee, J., & Kim, W. (2022). DAG-Based Blockchain Sharding for Secure Federated Learning with Non-IID Data. Sensors, 22(21), 8263. https://doi.org/10.3390/s22218263