Abstract
Amyotrophic lateral sclerosis (ALS) causes people to have difficulty communicating with others or devices. In this paper, multi-task learning with denoising and classification tasks is used to develop a robust steady-state visual evoked potential-based brain–computer interface (SSVEP-based BCI), which can help people communicate with others. To ease the operation of the input interface, a single channel-based SSVEP-based BCI is selected. To increase the practicality of SSVEP-based BCI, multi-task learning is adopted to develop the neural network-based intelligent system, which can suppress the noise components and obtain a high level of accuracy of classification. Thus, denoising and classification tasks are selected in multi-task learning. The experimental results show that the proposed multi-task learning can effectively integrate the advantages of denoising and discriminative characteristics and outperform other approaches. Therefore, multi-task learning with denoising and classification tasks is very suitable for developing an SSVEP-based BCI for practical applications. In the future, an augmentative and alternative communication interface can be implemented and examined for helping people with ALS communicate with others in their daily lives.
1. Introduction
People with amyotrophic lateral sclerosis (ALS) normally have difficulty communicating with others or devices [1,2,3,4]. A brain–computer interface (BCI) can effectively help people with ALS communicate with others or give commands to external devices without using muscles [4,5,6,7,8,9,10,11]. Compared with other BCIs, steady-state visual evoked potentials-based (SSVEP-based) BCI is one of the most successful interfaces for people with ALS since it has a high signal-to-noise ratio (SNR) [4]. However, in practical applications, the noise of the usage environment greatly reduces the performance of SSVEP-based BCIs. Moreover, for people with ALS, an easy-to-use interface, which can select a predefined vocabulary or phrase by using visual stimuli, would increase users’ acceptance. Therefore, developing a robust SSVEP-based BCI can help people with ALS to effectively communicate with others or devices.
ALS hinders the normal functioning of the motor neurons that control voluntary muscles, causing progressive weakness, muscle twitching, and stiff muscles [9,10,11,12,13]. The abilities to swallow, walk, move hands, and speak are severely degraded. Moreover, the nervous system of affected people is still intact and therefore people with ALS feel pain. Thus, developing a suitable assistive communication interface can effectively help people with ALS.
For BCI applications, the SSVEP-based technologies utilize visual stimuli to induce human brain activity in the central nervous system and then trigger brain potentials [6,7,14]. Via the brain potentials, the SSVEP-based BCIs can easily detect the selected visual stimulus, which represents a predefined vocabulary or phrase. Then, a user can communicate with others or devices without using muscles. Therefore, SSVEP-based BCI is one of the most successful assistive communication interfaces for subjects with ALS [14,15,16,17]. However, the quality of the SSVEP signal is degraded since the SSVEP signals always mix with normal brain activity and background noise. Several researchers have proposed an EEG device with multi-channels and multi-channel-based signal processing to improve the quality of acquired EEG signals [15,16,17]. However, the cost of the SSVEP-based BCIs is increasing and it is uncomfortable for a user having to place a number of electrodes. Thus, developing a robust SSVEP-based BCI using a single channel to operate the BCI is very useful for users.
SSVEP-based BCIs with a single channel have been developed and used to help people with ALS [6,12,15]. However, the performance of these systems is always degraded in practical applications due to the noisy SSVEP signal. Maye et al. proposed an averaging approach to reduce the effects of noise [6]. However, the noise in practical applications is not stable, and therefore the averaging approach cannot effectively remove the noise components. Chen et al. proposed a denoising autoencoder-based SSVEP signal enhancement to deal with the noisy SSVEP signal [12]. For this approach, a denoising autoencoder (DAE) is adopted to learn the characteristics of noise, and then a robust feature is extracted to represent a noisy SSVEP signal. However, the robust feature is used to represent a clean SSVEP signal, not a discriminative feature for a classification task. Therefore, it still has to design a complex neural network structure to achieve an acceptable performance of classification approaches. Generating a robust feature, which can effectively reduce the noisy components of a SSVEP signal and exactly represent the characteristic of a SSVEP signal for the classification tasks, can increase the values of SSVEP-based BCIs for practical applications.
Recently, multi-task learning (MTL) has been proposed to exploit commonalities across tasks to improve generalization by using domain information contained in the training signals [16,18,19,20]. Moreover, MTL uses a shared representation, which is learned for each task, to integrate the different information for each task. For clinical practical applications, MTL can obtain representations that can achieve an acceptable performance of classification and reduce the effects of noise in the SSVEP signal. Thus, MTL is very suitable for developing robust SSVEP-based BCIs.
In this paper, we present a study to develop an SSVEP-based BCI with MTL to help people communicate with others. To assist people in operating the input interface, the visual stimuli with specific frequencies displayed on an LCD monitor are selected as the input interface. To reduce the cost and increase comfort, a single channel is adopted as the input interface of the SSVEP-based BCI. To increase the accuracy of the SSVEP-based BCI in practical applications, MTL is developed to extract the features with denoising and discriminative characteristics.
2. An SSVEP-Based BCI with Multi-Task Learning
The flowchart of the proposed SSVEP-based BCI with MTL is shown in Figure 1. Firstly, an LCD monitor is used to display the visual stimuli with different flicking frequencies, and then the elicited EEG signal can be acquired. Secondly, a deep neural network with a multi-task framework is applied to encode the SSVEP signal and to find the designed commands or messages. These procedures are detailed in the following subsections.

Figure 1.
The flowchart of the proposed SSVEP-based BCI with MTL includes a visual stimulation procedure, SSVEP signal acquisition, and neural network with MTL.
2.1. SSVEP Signal Acquisition
In this study, a 20” LCD monitor is used to display the visual stimuli, which are five blinking boxes. The five blinking boxes are adopted to represent five commands/messages and are arranged in a regular pentagon for reducing the interference between each visual stimulus. All stimuli are set to a size of 5 × 5 cm with equalized mean pixel luminance and contrast during the presentation. Since the refresh rate of the LCD monitor is 60 Hz, to ensure that the refresh rate is an integer multiple of the presentation frequencies, the blinking frequencies for the five blinking boxes are 6.00 Hz, 6.67 Hz, 7.50 Hz, 8.57 Hz, and 10.00 Hz [7]. Some selected blinking frequencies are not perfect multiples, but it can work as the residual is very small.
The subjects are asked to sit at a viewing distance of 55 cm from an LCD monitor. The elicited SSVEP signal is acquired using a Neuroscan Quickcap electrode cap with 40 channels and a Neuroscan NuAmps™ EEG amplifier. Since the visual stimulation elicits an SSVEP signal in the visual cortex of the brain, only the Oz channel is used to acquire the EEG signal. The reference and ground electrodes are placed at A1 and A2. The sampling rate of the EEG signal acquisition system is 1 kHz. To reduce the computational complexity, the sampling rate of the SSVEP signal is converted to 100 Hz using an anti-aliasing lowpass filter, which is a 19-order Butterworth lowpass filter with a 50 Hz cut-off frequency.
In this study, a visual stimulation procedure with 5 sequences of target stimuli is designed to elicit the SSVEP signal. Each sequence has 3 target stimuli with different stimulation frequencies, which are randomly selected from the given 5 frequencies. Moreover, each visual stimulus with different blinking frequencies is strictly limited to 3 occurrences in a testing procedure. For a testing procedure, the participant is asked to sequentially look at a blinking box by using a speech cue, which refers to the target stimuli in the sequence. The testing procedure is designed as follows.
Step 1: A 5 s countdown delay is designed at the beginning of the testing procedure. For the countdown period, a speech cue is used to ask the participant to look at the corresponding blinking box. Since five blinking boxes are displayed on the LCD monitor, the position of the corresponding target stimulus is also provided to the participant.
Step 2: The participant is asked to look at the target blinking box, and then a series of 10 s of the elicited SSVEP signal is recorded.
Step 3: The participant can rest for 10 s.
Step 4: Step 1 is repeated three times.
Step 5. One minute of compulsory rest is provided for the participant if he/she wants to continue an experiment by using another sequence.
Once the participant finishes a visual stimulation procedure, 3 trials for each stimulus can be obtained. To increase the data size, a trial is then blocked into 10 non-overlapping blocks, with a duration of one second. Hence, for the participant, there are 30 blocks consisting of 100 EEG samples for each target stimulation frequency.
2.2. Neural Network with Multi-Task Learning
The framework of the proposed neural network with MTL is shown in Figure 2. In this study, the DAE and SSVEP classification tasks are selected to develop the neural network with MTL. The DAE task is used for SSVEP signal enhancement and reduces the effects of noise in practical applications. The SSVEP classification task is then used to recognize the commands/messages according to the elicited SSVEP signal. By integrating these tasks, the feature encoder can extract the robust feature, which has denoising and discriminative characteristics. The process is introduced in greater detail in the following section.
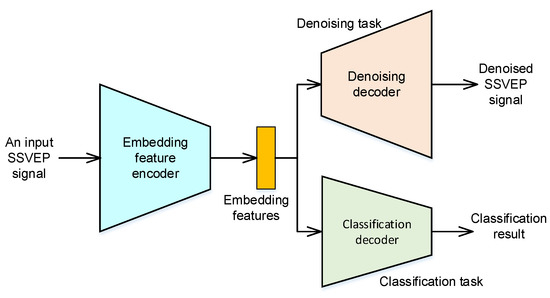
Figure 2.
The framework of the proposed multi-task based neural network.
2.2.1. Embedding Feature Encoder
The neural network structure of the embedding feature encoder is shown in Figure 3. For the embedding feature encoder, an SSVEP signal in the time domain is fed into the input layer. Then, a sequence of convolutional layers, activation functions, and max pooling layers is applied to extract a representation of the input SSVEP signal.
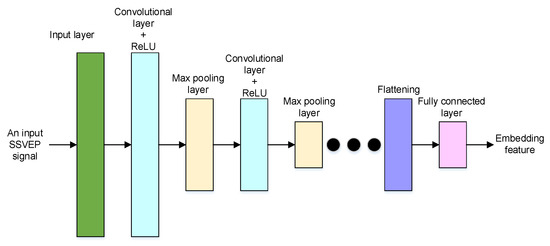
Figure 3.
The neural network structure of the embedding feature encoder.
Generally, the following convolutional layer is adopted to perform convolution to the outputs of previous layers, and the weights of previous inputs can be learned. The rectified linear unit (ReLU) is selected as the activation function and used to prevent the exponential growth in the computation required to operate the neural network. The max pooling layer is a pooling operation that calculates the maximum value for patches of a feature map. Then, the computational complexity can be effectively reduced by using downsampling features.
Finally, a fully connected layer is adopted to extract the embedding features, which are the bottleneck features of the network. The fully connected layer applies a linear transformation to the input vector through a weights matrix, and then a bottleneck feature can be obtained. The bottleneck feature is also called the embedding feature and is used to represent the input SSVEP signal. Moreover, using MTL, the embedding features will contain denoising and discriminative characteristics.
2.2.2. Denoising Task
The neural network structure of the denoising task is shown in Figure 4. Firstly, a fully connected layer is applied to decode the encoding features. Secondly, decoded features are reshaped to a set of features and the size is the same as the kernel of the convolution layer in the encoder. Finally, a sequence of deconvolutional layers and up-pooling layers is applied to reconstruct the SSVEP signal.
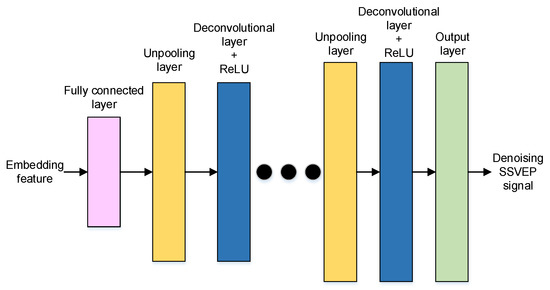
Figure 4.
The neural network structure of the denoising decoder.
In this study, a DAE can be developed by combining the structures of the embedding feature encoding and the denoising decoder. For practical SSVEP-based BCIs, the elicited SSVEP signal always contains different degrees of noise, which are defined as non-target frequency components. Thus, an acquired SSVEP signal, x(t), is defined as
where s(t) and n(t) are an ideal SSVEP signal and a noise signal, respectively. Since the ideal SSVEP signal cannot be obtained, the ideal SSVEP signal of different visual stimuli is assumed as a sine wave and defined as
where i is the i-th visual stimulus. A, fi, and φi are the amplitude, ordinary frequency, and phase, respectively.
x(t) = s(t) + n(t),
In the training stage, fi can be obtained via the frequency of the corresponding visual stimulus. Generally, there is a phase shift, φi, between the acquired SSVEP signal and an ideal SSVEP signal. Therefore, the cross-correlation is applied to find the φi between the input SSVEP signal and a sine wave, the phase of which is zero. According to the estimated phase shift, an ideal SSVEP signal, the phase of which is equal to the input SSVEP signal, can be generated. The mean square error is used as the loss function of the denoising decoder, LD.
2.2.3. Classification Task
The neural network structure of the classification task is shown in Figure 5. Firstly, a fully connected layer is applied to decode the embedding feature. Secondly, the decoded feature is reshaped to a set of features and the size is the same as the kernel size of the convolution layer in the encoder. Thirdly, a sequence of convolution layers, activation functions, and max pooling layers is adopted to extract reasonable features for classification. Finally, a sequence of fully connected layers is used to find the recognition results.
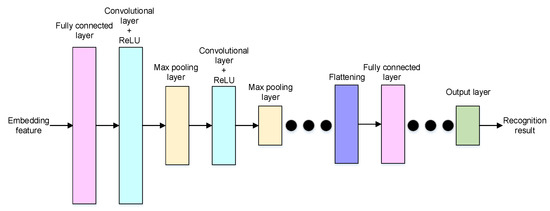
Figure 5.
The neural network structure of the classification decoder.
In the training stage, the cross-entropy function is selected as the loss function of the classification task and denoted as LC. To estimate the parameters of the proposed neural network, as shown in Figure 1, a loss function by weighting LD and LC is used and defined as
where α is a weighting factor. The α is used to balance the effects of loss for DAE and classification tasks. The effects of the DAE and classification tasks are assumed to be equal, and then it is set by referring to the distributions of the loss score for DAE and classification tasks.
L(x) = LC(x) + αLD(x),
2.3. The Selected Hyperparameters of the Proposed Neural Networks
Moreover, the hyperparameters of the proposed neural network with MTL are shown in Table 1. The Adam algorithm, which is an adaptive learning rate optimization technique, is selected as the optimizer for training neural networks. The learning rate, number of iterations, and batch size are 0.001, 200, and 32, respectively. Furthermore, α, which refers to the distributions of the loss score for denoising and classifying decoders, is 0.08 in this study.

Table 1.
The hyperparameters of the proposed neural network with MTL (I: input layer, C: convolutional layer, M: max pooling layer, F: fully connected layer, U: up pooling layer, DC: deconvolutional layer, S: sigmoid layer, NS: the number of nodes, FS: filter size, KS: kernel size).
3. Experimental Results and Discussions
The performance of the proposed SSVEP-based BCI with MTL is evaluated in the following section.
3.1. Experimental Environment
In this study, 24 health participants (18 males and 6 females) aged between 21 and 23 were asked to participate in the experiment. The participants gave informed consent to the study conditions and were able to abort the experiment if they felt uncomfortable. The participants did not have epilepsy or previous experience using the SSVEP-based BCIs. For a user, it is very useful and convenient to use a system without any adaptation/training process. To find an embedding feature, which is user-invariant, a user-independent SSVEP-based BCI can be developed. Therefore, leaving-one-participant-out cross-validation, where the number of folds equals the number of participants in the data set, was adopted to evaluate the proposed approaches. Thus, the learning algorithm of the proposed approach was applied once for each participant, using all other participants as a training set and using the selected participant as a single-item test set.
3.2. Experimental Results of Denoising Task
In this sub-section, the SNR is applied to evaluate the performance of the denoising task. For each input SSVEP signal, the sine wave, the phase of which is equal to the input SSVEP signal, is selected as the ideal SSVEP signal. To compare the performance of the MTL approach, the DAE, which has the same hyperparameters of the neural networks used for embedding the features encoder and denoising decoder, is adopted as the baseline system, and the experimental results are shown in Table 2. The average SNR for original SSVEP signal, DAE without MTL, and DAE with MTL are 2.50 dB, 6.23 dB, and 6.86 dB, respectively. It is clear that the noise components increase with frequency in this dataset. The DAE can effectively reduce the noise components. Moreover, the SNR of DAE can be improved again by integrating the classification task. The embedding feature of DAE with MTL will preserve the properties of classification results. Therefore, the proposed DAE with MTL can suppress the noise components for practical applications.
Table 2.
The average SNR (dB) for original SSVEP signal, DAE without MTL, and DAE with MTL.
To examine the effects of noise components for practical applications, the canonical correlation analysis (CCA), which has been widely used in SSVEP-based BCIs [21], is adopted in this experiment. The number of harmonics for CCA was set to be 4, and the experimental results are shown in Table 3. The average accuracy and standard deviation for original SSVEP signal, DAE without MTL, and DAE with MTL are 87.45% ± 1.86%, 90.14% ± 1.19%, and 90.70% ± 1.24%, respectively. The Wilcoxon signed-rank test is then selected to test whether or not there is a significant difference between two population means. The p-values for comparing DAE with MTL vs. DAE and DAE with MTL vs. original SSVEP signal are 0.03662 and 0.00138, respectively. The statistical results are significant at p < 0.05, meaning that the proposed approach outperforms other approaches. Referring to Table 2, it is clear that the recognition rate increases with SNR. Hence, suppressing noise components can effectively increase the recognition rate of an SSVEP-based BCI.
Table 3.
The accuracy (μ ± σ%) of CCA for original SSVEP signal, DAE without MTL, and DAE with MTL.
3.3. Experimental Results of Classification Task
In this sub-section, the performance of the classification task by using the proposed neural networks with MTL is evaluated. A neural network, which has the same hyperparameters of the neural network used for embedding the feature encoder and classification decoder, is selected as the baseline system. The experimental results are shown in Table 4. The average accuracies and standard deviation for baseline system and neural network with MTL are 89.70% ± 1.63% and 93.44% ± 1.14%, respectively. The Wilcoxon signed-rank test is also selected to test the results of the classification approach by using neural networks with and without MTL. The p-value is 0.02088 and is significant at p < 0.05. Therefore, the neural network with MTL can effectively improve the performance of neural network-based classification. Referring to Table 3, the accuracy of the baseline system is greatly affected by the noise. However, the accuracy of the neural network with MTL can effectively reduce the effects of noise. This demonstrates that the embedding feature with denoising characteristics is highly effective for suppressing noise.
Table 4.
The accuracy (μ ± σ%) of SSVEP-based BCI using neural network-based classification with and without MTL.
To detail the characteristics of the proposed SSVEP-based BCI with MTL, the architecture of the DAE approach [12] is selected. In this approach, the encoder and decoder networks are trained, and then the weights of the encoder network are fixed. Then, the neural networks for the classification task, including four convolution layers and two fully connected layers, are used to connect the encoder network. In the training stage, we only update the weights of the neural network for the classification decoder. This approach is denoted as DAE_baseline.
To objectively compare the denoising approach, a two-stage training approach is also used. In the first training stage, the whole weights of the neural network with MTL are updated. In the second training stage, the weights of the embedding feature encoder are fixed and we only update the weights of the neural network of the classification decoder. This approach is denoted as the updated neural network with MTL.
The accuracy and standard deviation for the denoising approach, DAE_baseline, the neural network with MTL, and the updated neural network with MTL approach are 92.92% ± 1.05%, 93.44% ± 1.19%, and 94.64% ± 1.59%, respectively. The result of the neural network with MTL is similar to that of the DAE_baseline, and the effects of noise components can be effectively reduced. Moreover, to achieve an acceptable performance for practical applications, a two-stage training approach is very useful to increase the accuracy of MTL for SSVEP-based BCIs.
Comparing the results in Table 3 and Table 4, the accuracy of CCA with SSVEP signal enhancement by using DAE with MTL and neural network-based classification by using DAE with MTL are 90.70% and 93.44%, respectively. The results show that the proposed approach outperforms CCA, and can achieve an acceptable performance for practical applications. Moreover, the embedding feature of DAE is forced to find a common stimulus representation that works for all participants, and the classification network is optimized for the current participant only. Therefore, MTL with DAE and SSVEP classification tasks can successfully improve the performance of the SSVEP-based BCIs. With the acceptable performance, an augmentative and alternative communication interface can be designed to express some intents that are selected from a predefined set, including specified vocabularies or phrases. Therefore, people with ALS can use the predefined vocabularies or phrases to communicate with others in their daily lives.
4. Conclusions
In this study, a robust SSVEP-based BCI is successfully developed to help people with ALS communicate with others by using visual stimulation. MTL can integrate the advantages of denoising and classification tasks. The denoising task can effectively suppress the noise components in SSVEP signals and then robust embedding features can be extracted to improve the performance of classification. The classification task is adopted not only to find a suitable recognition result of SSVEP-based BCI but also to provide classification information for improving the performance of the denoising task. The experimental results show that the proposed neural networks with MTL outperform other approaches. Thus, the denoising and the classification tasks have complementary effects on the recognition rate of an SSVEP-based BCI. Therefore, MTL with denoising and classification tasks is suitable for developing an SSVEP-based BCI for practical applications. In this study, the convolutional layers are adopted as the basic units of MTL. Recently, many novel neural network structures, such as Inception, DenseNet, and SENet, are proposed, and these novel neural networks can be easily adopted as the basic units of our approach. The proposed approaches can also be used to implement an augmentative and alternative communication interface so that people with ALS can evaluate the suitability of the proposed SSVEP-based BCI.
Author Contributions
These authors contributed equally: C.-C.C. and C.-C.L. Conceptualization, C.-C.C., C.-C.L. and Y.-J.C.; methodology, C.-C.C. and C.-C.L.; software and validation, E.-C.S.; formal analysis and investigation, C.-C.C. and C.-C.L.; resources and data curation, C.-H.Y. and E.-C.S.; writing—original draft preparation, C.-C.C. and C.-C.L.; writing—review and editing, Y.-J.C.; visualization, E.-C.S.; supervision, project administration and funding acquisition, C.-C.C. and C.-C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partly supported by one research fund (ANHRF111-26) from An Nan Hospital, China Medical University, granted to Chia-Chun Chuang and another research fund (ANHRF110-22) from An Nan Hospital, China Medical University, granted to Chien-Ching Lee.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank the support of the MOST 110-2221-E-218-004 from the Ministry of Science and Technology, Taiwan, and the Higher Education Sprout of the Ministry of Education, Taiwan.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Edughele, H.O.; Zhang, Y.; Muhammad-Sukki, F.; Vien, Q.-T.; Morris-Cafiero, H.; Opoku Agyeman, M. Eye-Tracking Assistive Technologies for Individuals with Amyotrophic Lateral Sclerosis. IEEE Access 2022, 10, 41952–41972. [Google Scholar] [CrossRef]
- Roberts, B.; Theunissen, F.; Mastaglia, F.L.; Akkari, P.A.; Flynn, L.L. Synucleinopathy in Amyotrophic Lateral Sclerosis: A Potential Avenue for Antisense Therapeutics. Int. J. Mol. Sci. 2022, 23, 9364. [Google Scholar] [CrossRef] [PubMed]
- Borgheai, S.B.; McLinden, J.; Zisk, A.H.; Hosni, S.I.; Deligani, R.J.; Abtahi, M.; Mankodiya, K.; Shahriari, Y. Enhancing Communication for People in Late-Stage ALS Using an fNIRS-Based BCI System. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1198–1207. [Google Scholar] [CrossRef] [PubMed]
- Nicolas-Alonso, L.F.; Gomez-Gil, J. Brain Computer Interfaces, a Review. Sensors 2012, 12, 1211–1279. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.J.; Chen, S.C.; Zaeni, I.A.E.; Wu, C.M. Fuzzy Tracking and Control Algorithm for an SSVEP-Based BCI System. Appl. Sci. 2016, 6, 270. [Google Scholar] [CrossRef]
- Maye, A.; Zhang, D.; Engel, A.K. Utilizing Retinotopic Mapping for a Multi-Target SSVEP BCI with a Single Flicker Frequency. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1026–1036. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.C.; Chen, Y.J.; Zaeni, I.A.E.; Wu, C.M. A Single Channel SSVEP based BCI with a Fuzzy Feature Threshold Algorithm in a Maze Game. Int. J. Fuzzy Syst. 2017, 19, 553–565. [Google Scholar] [CrossRef]
- Young, S.J.; Lin, Z.D. High On/Off Ratio Field-Effect Transistor Based on Semiconducting Single-Walled Carbon Nanotubes by Selective Separation. ECS J. Solid State Sci. Technol. 2017, 6, M1–M4. [Google Scholar] [CrossRef]
- Feng, J.; Yin, E.; Jin, J.; Saab, R.; Daly, L.; Wang, X.; Hu, D.; Cichocki, A. Towards correlation-based time window selection method for motor imagery BCIs. Neural Netw. 2018, 102, 87–95. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, P.L.C.; Jutten, C.; Congedo, M. Riemannian Procrustes Analysis: Transfer Learning for Brain–Computer Interfaces. IEEE Trans. Biomed. Eng. 2019, 66, 2390–2401. [Google Scholar] [CrossRef] [PubMed]
- Hua, X.; Ono, Y.; Peng, L.; Xu, Y. Unsupervised Learning Discriminative MIG Detectors in Nonhomogeneous Clutter. IEEE Trans. Commun. 2022, 70, 4107–4120. [Google Scholar] [CrossRef]
- Chuang, C.C.; Lee, C.C.; Yeng, C.H.; So, E.C.; Lin, B.S.; Chen, Y.J. Convolutional Denoising Autoencoder based SSVEP Signal Enhancement to SSVEP-based BCIs. Microsyst. Technol. 2022, 28, 237–244. [Google Scholar] [CrossRef]
- Kiernan, M.C.; Vucic, S.; Cheah, B.C.; Turner, M.R.; Eisen, A.; Hardiman, O.; Burrell, J.B.; Zoing, M.C. Amyotrophic lateral sclerosis. Lancet 2011, 377, 942–955. [Google Scholar] [CrossRef]
- Muller, S.M.T.; Celeste, W.C.; Bastos, T.F.; Sarcinelli, M. Brain-computer Interface Based on Visual Evoked Potentials to Command Autonomous Robotic Wheelchair. J. Med. Biol. Eng. 2010, 30, 407–415. [Google Scholar] [CrossRef]
- Peters, B.; Bedrick, S.; Dudy, S.; Eddy, B.; Higger, M.; Kinsella, M.; McLaughlin, D.; Memmott, T.; Oken, B.; Quivira, F.; et al. SSVEP BCI and Eye Tracking Use by Individuals with Late-Stage ALS and Visual Impairments. Front. Hum. Neurosci. 2020, 20, 595890. [Google Scholar] [CrossRef] [PubMed]
- Khok, H.J.; Koh, V.T.C.; Guan, C. Deep Multi-Task Learning for SSVEP Detection and Visual Response Mapping. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics, Toronto, ON, Canada, 11–14 October 2020; IEEE: Geneva, Sitzerland, 2020; pp. 1280–1285. [Google Scholar]
- Hsu, H.T.; Lee, I.H.; Tsai, H.T.; Chang, H.C.; Shyu, K.K.; Hsu, C.C.; Chang, H.H.; Yeh, T.K.; Chang, C.Y.; Lee, P.L. Evaluate the Feasibility of Using Frontal SSVEP to Implement an SSVEP-Based BCI in Young, Elderly and ALS Groups. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 603–615. [Google Scholar] [CrossRef] [PubMed]
- Cheng, M.; Jiao, L.; Yan, P.; Gu, H.; Sun, J.; Qiu, T.; Wang, X. A Novel Multi-Task Learning Model with PSAE Network for Simultaneous Estimation of Surface Quality and Tool Wear in Milling of Nickel-Based Superalloy Haynes 230. Sensors 2022, 22, 4943. [Google Scholar] [CrossRef] [PubMed]
- Cerviño, J.; Bazerque, J.A.; Calvo-Fullana, M.; Ribeiro, A. Multi-Task Reinforcement Learning in Reproducing Kernel Hilbert Spaces via Cross-Learning. IEEE Trans. Signal Process. 2021, 69, 5947–5962. [Google Scholar] [CrossRef]
- Ranjan, R.; Patel, V.M.; Chellappa, R. HyperFace: A Deep Multi-Task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 121–135. [Google Scholar] [CrossRef] [PubMed]
- Yin, E.; Zhou, Z.; Jiang, J.; Yu, Y.; Hu, D. A dynamically optimized SSVEP Brain-computer interface (BCI) Speller. IEEE Trans. Biomed. Eng. 2015, 62, 1447–1456. [Google Scholar] [CrossRef] [PubMed]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).