

A Novel Computer-Vision Approach Assisted by 2D-Wavelet Transform and Locality Sensitive Discriminant Analysis for Concrete Crack Detection

 ,
,  ,
, 
 and
and 
Abstract
:1. Introduction
- Enhancing the performance of crack classification compared to pre-trained CNNs.
- Stable in terms of model parameter uncertainty.
- Keeping a high level of robustness in unfavorable imaging situations.
- Potential to adapt adjustments in the quantity of training images and image size.
- Benefit from high speed to lower the time of computation.
2. Materials and Methods
2.1. Step One: Image Transformation Using Wavelet
- LL: low-frequency components oriented horizontally and vertically.
- LH: low-frequency components oriented horizontally and vertically.
- HL: both the horizontal and vertical directions include components with a high frequency.
- HH: both the horizontal and vertical directions include components with a high frequency.
2.2. Step Two: Feature Reduction
2.3. Step Three: Classification
2.4. Reference Image Classification Models
2.5. Indices of Evaluation
2.6. Concrete Image Dataset
3. Related Studies
4. Results and Discussion
4.1. Efficiency Evaluation
- AMD Ryzen 5 3500U Processor (4M Cache, 2.1 GHz up to 3.7 GHz);
- 24 GB DDR4 RAM & 512 GB SSD;
- Nvidia GTX 1050 4 GB Graphics.Nvidia GTX 1050 4 GB Graphics.
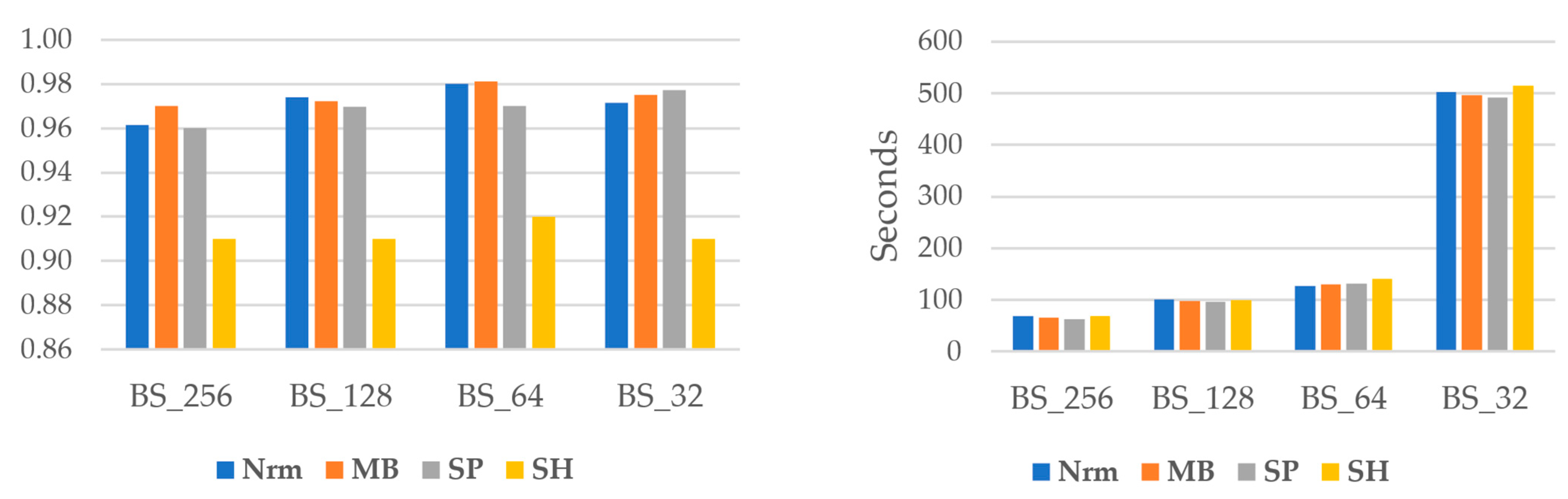
4.2. Finding Time-Saving Approach
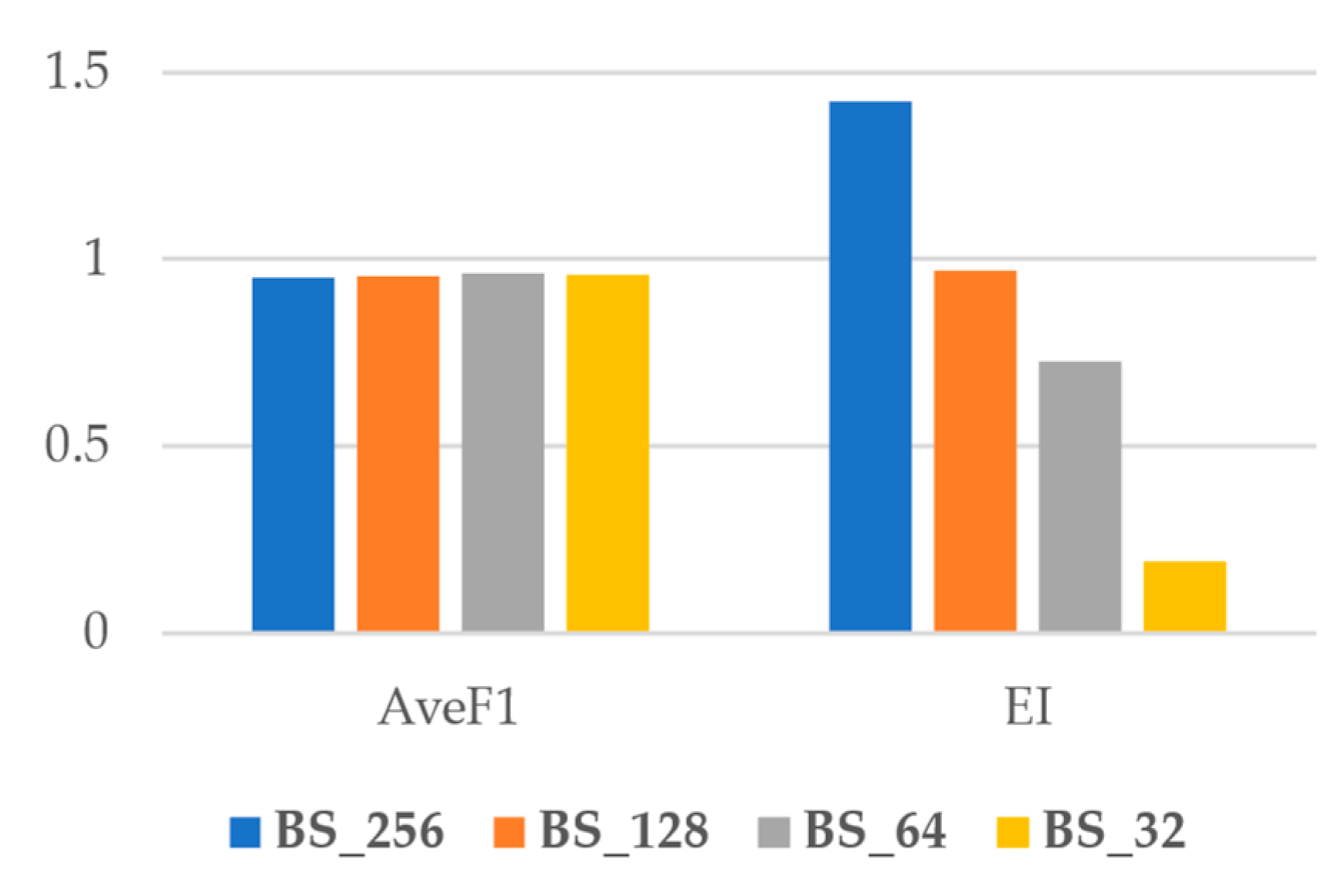
5. Stability Assessment
5.1. Batch Size Impact
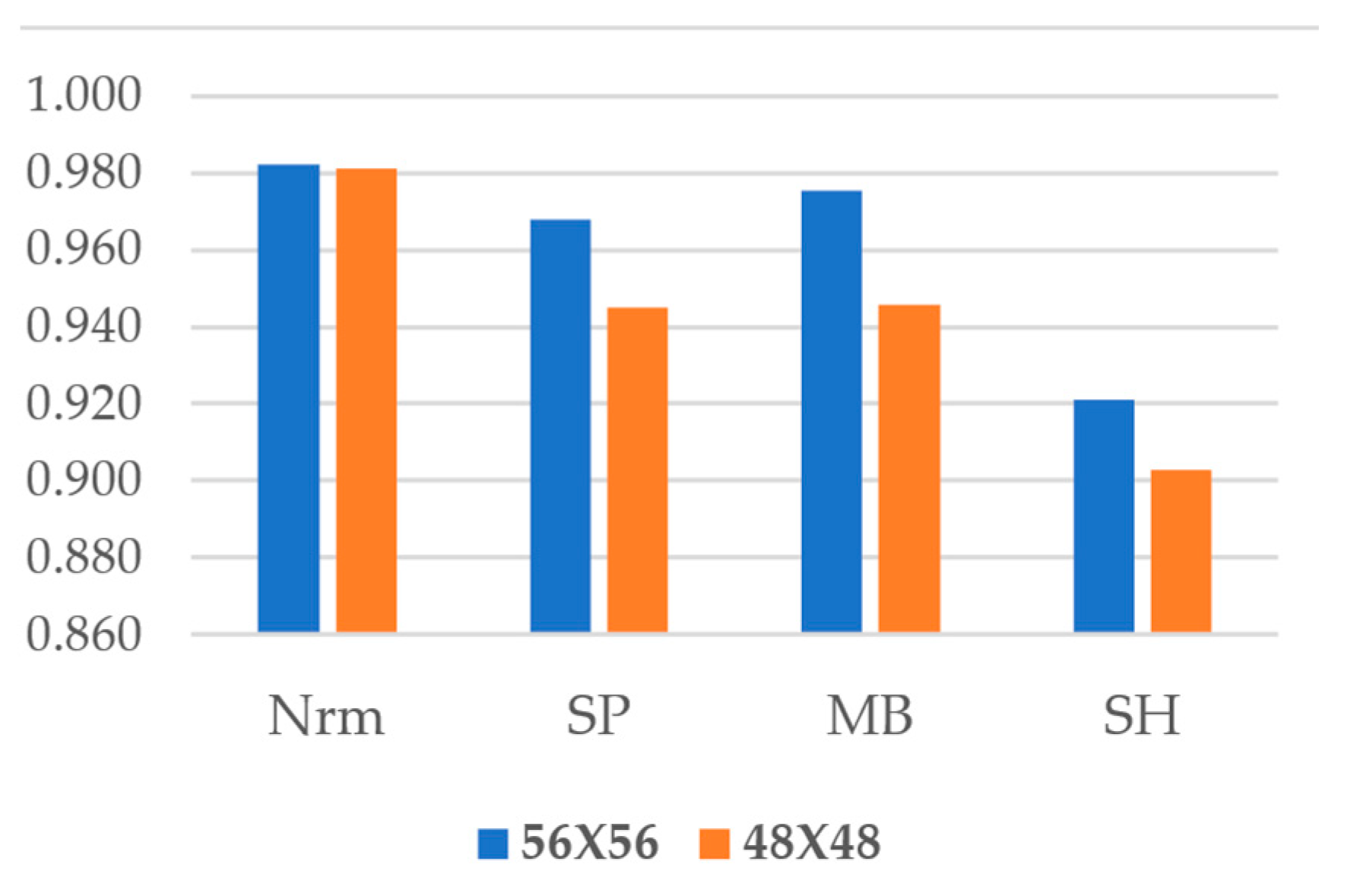
5.2. Image Size Impact
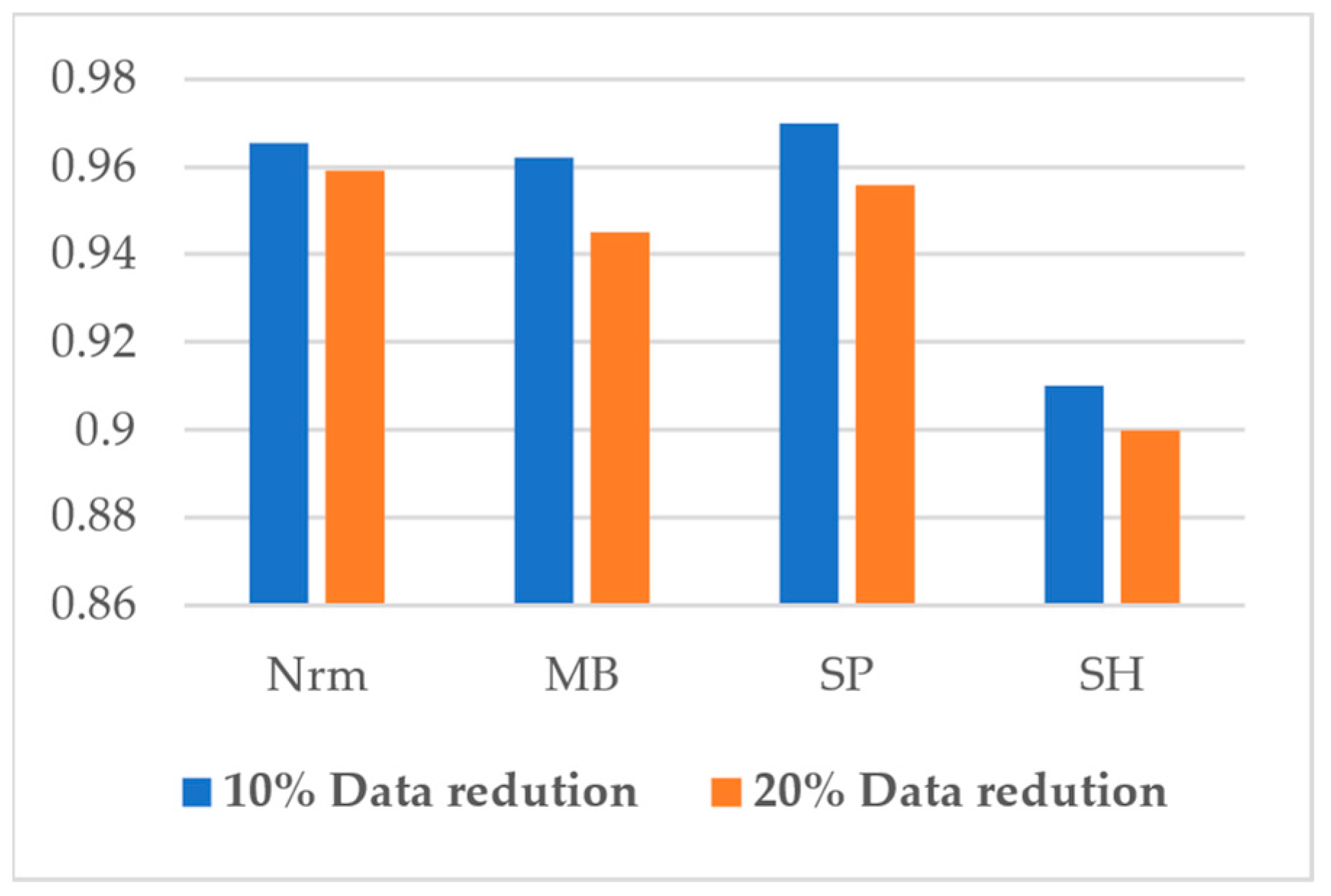
5.3. Impact of Number of Samples
5.4. Generalization
6. Conclusions
- FastCrackNet outperforms the traditional CNNs in terms of the accuracy of concrete crack classifications.
- FastCrackNet does not degrade due to adverse environmental conditions.
- FastCrackNet is significantly faster than the pre-trained CNNs.
- The batch size and uncertainties do not affect the performance of FastCrackNet significantly.
- The proposed approach encounters no over-fitting issues.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Affonso, C.; Rossi, A.L.D.; Vieira, F.H.A.; de Leon Ferreira, A.C.P. Deep learning for biological image classification. Expert Syst. Appl. 2017, 85, 114–122. [Google Scholar] [CrossRef] [Green Version]
- Hao, S. I-35W bridge collapse. J. Bridge Eng. 2010, 15, 608–614. [Google Scholar] [CrossRef]
- Behnam, B. Fire structural response of the plasco building: A preliminary investigation report. Int. J. Civ. Eng. 2019, 17, 563–580. [Google Scholar] [CrossRef]
- Gharehbaghi, V.R.; Noroozinejad Farsangi, E.; Noori, M.; Yang, T.; Li, S.; Nguyen, A.; Málaga-Chuquitaype, C.; Gardoni, P.; Mirjalili, S. A critical review on structural health monitoring: Definitions, methods, and perspectives. Arch. Comput. Methods Eng. 2021, 1–27. [Google Scholar] [CrossRef]
- Spencer, B.F., Jr.; Hoskere, V.; Narazaki, Y. Advances in computer vision-based civil infrastructure inspection and monitoring. Engineering. 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Graves, A. Long short-term memory. Supervised Seq. Label. Recurr. Neural Netw. 2012, 385, 37–45. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international Conference on Machine learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Medsker, L.R.; Jain, L. Recurrent neural networks. Des. Appl. 2001, 5, 64–67. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Fujita, Y.; Hamamoto, Y. A robust automatic crack detection method from noisy concrete surfaces. Mach. Vis. Appl. 2011, 22, 245–254. [Google Scholar] [CrossRef]
- Du, G.; Cao, X.; Liang, J.; Chen, X.; Zhan, Y. Medical image segmentation based on u-net: A review. J. Imaging Sci. Technol. 2020, 64, 1–12. [Google Scholar] [CrossRef]
- Jenkins, M.D.; Carr, T.A.; Iglesias, M.I.; Buggy, T.; Morison, G. A deep convolutional neural network for semantic pixel-wise segmentation of road and pavement surface cracks. In Proceedings of the 2018 26th European signal processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Galvez, R.L.; Bandala, A.A.; Dadios, E.P.; Vicerra, R.R.P.; Maningo, J.M.Z. Object detection using convolutional neural networks. In Proceedings of the TENCON 2018-2018 IEEE Region 10 Conference, Jeju, Republic of Korea, 28–31 October 2018; pp. 2023–2027. [Google Scholar]
- Wu, X.; Sahoo, D.; Hoi, S.C. Recent advances in deep learning for object detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, J.; Song, J. An intelligent classification model for surface defects on cement concrete bridges. Appl. Sci. 2020, 10, 972. [Google Scholar] [CrossRef] [Green Version]
- Hossain, M.Z.; Sohel, F.; Shiratuddin, M.F.; Laga, H. A comprehensive survey of deep learning for image captioning. ACM Comput. Surv. (CsUR) 2019, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Yang, H.; Bartz, C.; Meinel, C. Image captioning with deep bidirectional LSTMs. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 988–997. [Google Scholar]
- Dung, C.V. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Islam, M.M.; Hossain, M.B.; Akhtar, M.N.; Moni, M.A.; Hasan, K.F. CNN Based on Transfer Learning Models Using Data Augmentation and Transformation for Detection of Concrete Crack. Algorithms 2022, 15, 287. [Google Scholar] [CrossRef]
- Ma, D.; Fang, H.; Wang, N.; Xue, B.; Dong, J.; Wang, F. A real-time crack detection algorithm for pavement based on CNN with multiple feature layers. Road Mater. Pavement Des. 2022, 23, 2115–2131. [Google Scholar] [CrossRef]
- Zhang, C.; Nateghinia, E.; Miranda-Moreno, L.F.; Sun, L. Pavement distress detection using convolutional neural network (CNN): A case study in Montreal, Canada. Int. J. Transp. Sci. Technol. 2022, 11, 298–309. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Lin, X.; Chen, Z.; Lin, P.; Cheng, S. Surface crack detection based on image stitching and transfer learning with pretrained convolutional neural network. Struct. Control. Health Monit. 2021, 28, e2766. [Google Scholar] [CrossRef]
- Chianese, R.; Nguyen, A.; Gharehbaghi, V.; Aravinthan, T.; Noori, M. Influence of image noise on crack detection performance of deep convolutional neural networks. arXiv 2021, arXiv:2111.02079. Available online: https://arxiv.org/abs/2111.02079 (accessed on 3 November 2021).
- Rader, C.; Brenner, N. A new principle for fast Fourier transformation. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 264–266. [Google Scholar] [CrossRef]
- Griffin, D.; Lim, J. Signal estimation from modified short-time Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Johansson, M.; The Hilbert Transform. Master’s Thesis. Växjö University, Suecia. Available online: http://w3.msi.vxu.se/exarb/mj_ex.pdf (accessed on 31 December 2011).
- Gharehbaghi, V.R.; Kalbkhani, H.; Noroozinejad Farsangi, E.; Yang, T.; Nguyen, A.; Mirjalili, S.; Málaga-Chuquitaype, C. A novel approach for deterioration and damage identification in building structures based on Stockwell-Transform and deep convolutional neural network. J. Struct. Integr. Maint. 2022, 7, 136–150. [Google Scholar] [CrossRef]
- Sutha, S.; Leavline, E.J.; Singh, D. A comprehensive study on wavelet based shrinkage methods for denoising natural images. WSEAS Trans. Signal Process. 2013, 9, 203–215. [Google Scholar]
- Parida, P.; Bhoi, N. Wavelet based transition region extraction for image segmentation. Future Comput. Inform. J. 2017, 2, 65–78. [Google Scholar] [CrossRef]
- Rinky, B.; Mondal, P.; Manikantan, K.; Ramachandran, S. DWT based feature extraction using edge tracked scale normalization for enhanced face recognition. Procedia Technol. 2012, 6, 344–353. [Google Scholar] [CrossRef] [Green Version]
- Yelampalli, P.K.R.; Nayak, J.; Gaidhane, V.H. Daubechies wavelet-based local feature descriptor for multimodal medical image registration. IET Image Process. 2018, 12, 1692–1702. [Google Scholar] [CrossRef]
- Cai, D.; He, X.; Zhou, K.; Han, J.; Bao, H. Locality sensitive discriminant analysis. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; pp. 1713–1726. [Google Scholar]
- Attoui, I.; Fergani, N.; Boutasseta, N.; Oudjani, B.; Deliou, A. A new time–frequency method for identification and classification of ball bearing faults. J. Sound Vib. 2017, 397, 241–265. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Nguyen, A.; Chianese, R.R.; Gharehbaghi, V.R.; Perera, R.; Low, T.; Aravinthan, T.; Yu, Y.; Samali, B.; Guan, H.; Khuc, T.; et al. Robustness of Deep Transfer Learning-Based Crack Detection against Uncertainty in Hyperparameter Tuning and Input Data. In Recent Advances in Structural Health Monitoring Research in Australia; Guan, H., Chan, T.H.T., Eds.; Civil Engineering and Architecture; Nova Science Publishers: New York, NY, USA, 2022; pp. 215–243. ISBN 9781685077419. [Google Scholar] [CrossRef]
- 3000_ImageData_for_Crack_Detection; Kaggle. 2021. Available online: https://www.kaggle.com/datasets/nguyen49/3000-imagedata-for-crack-detection (accessed on 18 October 2022). [CrossRef]
- Rafiei, M.H.; Adeli, H. A novel unsupervised deep learning model for global and local health condition assessment of structures. Eng. Struct. 2018, 156, 598–607. [Google Scholar] [CrossRef]
- Ai, L.; Soltangharaei, V.; Ziehl, P. Evaluation of ASR in concrete using acoustic emission and deep learning. Nucl. Eng. Des. 2021, 380, 111328. [Google Scholar] [CrossRef]
- Gharehbaghi, V.R.; Farsangi, E.N.; Yang, T.; Hajirasouliha, I. Deterioration and damage identification in building structures using a novel feature selection method. Structures 2021, 29, 458–470. [Google Scholar] [CrossRef]
- Dixit, A.; Wagatsuma, H. Comparison of effectiveness of dual tree complex wavelet transform and anisotropic diffusion in MCA for concrete crack detection. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 2681–2686. [Google Scholar]
- Ranjbar, S.; Nejad, F.M.; Zakeri, H. An image-based system for pavement crack evaluation using transfer learning and wavelet transform. Int. J. Pavement Res. Technol. 2021, 14, 437–449. [Google Scholar] [CrossRef]
- Arbaoui, A.; Ouahabi, A.; Jacques, S.; Hamiane, M. Wavelet-based multiresolution analysis coupled with deep learning to efficiently monitor cracks in concrete. Frat. Ed Integrità Strutt. 2021, 15, 33–47. [Google Scholar] [CrossRef]
- Arbaoui, A.; Ouahabi, A.; Jacques, S.; Hamiane, M. Concrete cracks detection and monitoring using deep learning-based multiresolution analysis. Electronics 2021, 10, 1772. [Google Scholar] [CrossRef]
- Yang, G.; Geng, P.; Ma, H.; Liu, J.; Luo, J. DWTA-Unet: Concrete Crack Segmentation Based on Discrete Wavelet Transform and Unet. In Proceedings of the 2021 Chinese Intelligent Automation Conference, Zhanjiang, China, 5–7 November 2021; pp. 702–710. [Google Scholar]
- Kandel, I.; Castelli, M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Layers | Size (MB) | Parameters | Input Image Size |
|---|---|---|---|---|
| GoogleNet | 22 | 27 | 7.0 | 224 × 224 |
| Xception | 71 | 85 | 22.9 | 229 × 229 |
| Parameter | Value |
|---|---|
| Optimization method | SGDM |
| Initial learning rate | |
| L2 Regularization | |
| Epochs | 300 |
| Iterations | 2700 |
| Model | Image Type | Overall F1-Score | Time (s) |
|---|---|---|---|
| GoogleNet | Nrm | 0.95 | 8635 |
| SP | 0.93 | 8203 | |
| MB | 0.92 | 8191 | |
| SH | 0.86 | 8251 | |
| Xception | Nrm | 0.97 | 11,235 |
| SP | 0.93 | 10,662 | |
| MB | 0.92 | 10,591 | |
| SH | 0.84 | 11,657 | |
| FastCrackNet | Nrm | 0.98 | 127 |
| SP | 0.98 | 130 | |
| MB | 0.97 | 132 | |
| SH | 0.92 | 141 |
| Model | Image Type | Average of Overall F1-Score |
|---|---|---|
| FastCrackNet | Nrm | 0.95 |
| SP | 0.94 | |
| MB | 0.95 | |
| SH | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gharehbaghi, V.; Noroozinejad Farsangi, E.; Yang, T.Y.; Noori, M.; Kontoni, D.-P.N. A Novel Computer-Vision Approach Assisted by 2D-Wavelet Transform and Locality Sensitive Discriminant Analysis for Concrete Crack Detection. Sensors 2022, 22, 8986. https://doi.org/10.3390/s22228986
Gharehbaghi V, Noroozinejad Farsangi E, Yang TY, Noori M, Kontoni D-PN. A Novel Computer-Vision Approach Assisted by 2D-Wavelet Transform and Locality Sensitive Discriminant Analysis for Concrete Crack Detection. Sensors. 2022; 22(22):8986. https://doi.org/10.3390/s22228986
Chicago/Turabian StyleGharehbaghi, Vahidreza, Ehsan Noroozinejad Farsangi, T. Y. Yang, Mohammad Noori, and Denise-Penelope N. Kontoni. 2022. "A Novel Computer-Vision Approach Assisted by 2D-Wavelet Transform and Locality Sensitive Discriminant Analysis for Concrete Crack Detection" Sensors 22, no. 22: 8986. https://doi.org/10.3390/s22228986
APA StyleGharehbaghi, V., Noroozinejad Farsangi, E., Yang, T. Y., Noori, M., & Kontoni, D.-P. N. (2022). A Novel Computer-Vision Approach Assisted by 2D-Wavelet Transform and Locality Sensitive Discriminant Analysis for Concrete Crack Detection. Sensors, 22(22), 8986. https://doi.org/10.3390/s22228986