
Dementia Detection from Speech Using Machine Learning and Deep Learning Architectures

 ,
,  , and
, and
Abstract
1. Introduction
- To explore significant speech features that are useful in early detection of dementia by training various ML and DL models.
- To study the statistical and temporal aspects of the speech features and analyse their performance along with various ML and DL models.
2. Related Works
3. Proposed Methodology
3.1. Dataset
3.2. Preprocessing
3.3. Feature Extraction
3.3.1. Time-Dependent Features
- MFCC: MFCC computes frequency analysis based on a set of mel-filter banks. The formula to convert from linear frequency scale to the mel-scale [16] is shown in Equation (1) where the variable ‘f’ denotes the frequency of the signal.
- Delta-coefficients: The delta coefficients represent the first-order derivative over time or the change in coefficients from one analysis window to another [38]. Since the simple difference in the coefficients from adjacent windows are a poor estimation of the derivative, the delta coefficients are computed as the least-square approximation to the local slope, as described in Equation (2). The delta coefficients are computed for both MFCC and GTCC. In Equation (2), ‘cn’ denotes the value of the coefficient at the nth time-step.
- Log-Energy: The log-energy describes the total energy content of the signal within a given duration in the log scale [38].
- Formants: The formants are the range of frequencies that are amplified by the shape of the speaker’s vocal tract and describe the distinct characteristics of the subject’s voice. The first four or five formants are the most significant as the higher formants are outside the human hearing range.
- Fundamental frequency: Fundamental frequency [38] describes the frequency of the audio signal within a given window.
3.3.2. Time-Independent Features
- Jitter and Shimmer: Jitter and shimmer provide information regarding the instability in the frequency and amplitude respectively [27].
- Pitch: Pitch is the relative highness or lowness of the tone as perceived by the ear, based on the number of vibrations per second produced by the vocal cord [39].
3.4. Classification
3.4.1. Machine Learning (ML)
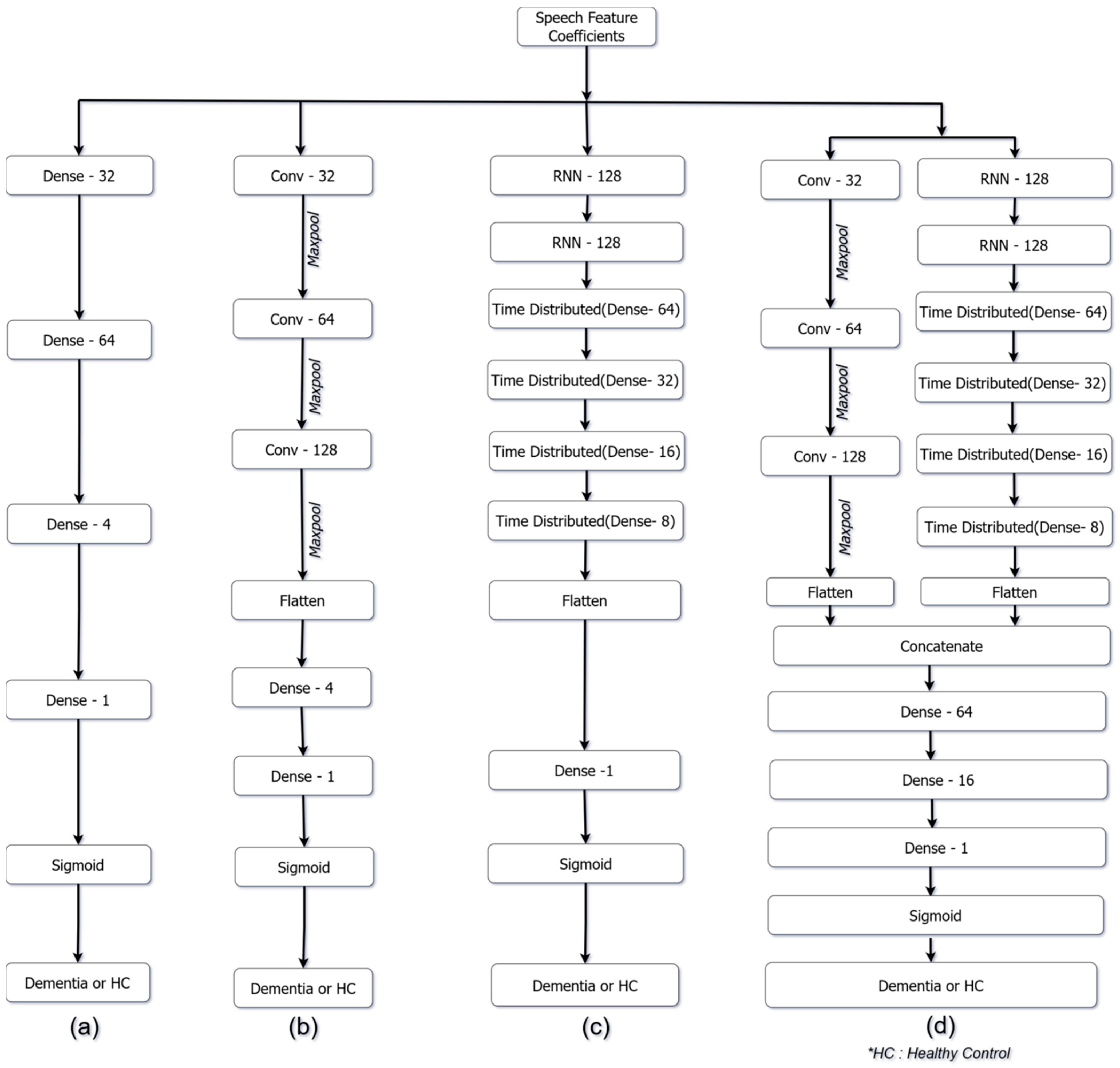
3.4.2. Deep Learning (DL)
- Artificial Neural Networks (ANN):
- Convolutional Neural Network (CNN):
- Recurrent neural network (RNN):
- Parallel Recurrent Convolutional Neural Network (PRCNN)
3.5. Performance Metrics
4. Experimental Results
4.1. Proposed Model for Dementia Recognition Using Machine Learning (ML) Methods
4.2. Proposed Model for Dementia Recognition Using DL Methods
5. Discussion
5.1. Comparative Analysis of the Proposed Approach Using ML and DL Models
5.2. Comparison of the Proposed Work to Other Research

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SL. NO | Research | Key Features/Number of Features | Number of Features | ML/DL Models | Accuracy | F-Score |
|---|---|---|---|---|---|---|
| 1 | Triapthi et al. [52] | EmoLarge Feature set | 6552 | BayesNet | - | 85.7% |
| 2 | Lui et al. [53] | Bottleneck features derived from MFCC | 512 (per frame) | CNN and BiLSTM based neural network | 82.59% | 82.94% |
| 3 | La Fuente Garcia [54] | eGeMAPS feature set and Active Data Representation (ADR) | 88 (per segment) | Random forest | 70.73% | - |
| 4 | F. Haider et al. [27] | Emobase feature set | 75 | Decision tree | 78.7% | - |
| ComParE feature set | 711 | |||||
| eGeMAPS feature set | 3899 | |||||
| MRCG feature set | 4688 | |||||
| 5 | L. Hernández-Domínguez, et al. [19] | 13 MFCC (mean, kurtosis, skewness, and variance) | 52 | Random forest | 67% | - |
| 6 | T. Warnita et al. [31] | Paralinguistic feature set | 76 (per frame) | GCNN | 73.6% | - |
| 7 | ML model (proposed) | MFCC, GTCC, formants, pitch, jitter and shimmer | 44 | Random forest | 87.6% | 87.5% |
| 8 | DL model (proposed) | MFCC, GTCC, formants, fundamental frequency, and log-energy | 62 (per frame) | PRCNN | 85% | 85.1% |
6. Conclusions and Future Scope
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Dementia. Available online: https://www.who.int/news-room/fact-sheets/detail/dementia (accessed on 20 September 2022).
- Casarella, J. Types of Dementia Explained. WebMD. Available online: https://www.webmd.com/alzheimers/guide/alzheimers-dementia (accessed on 20 September 2022).
- Deture, M.A.; Dickson, D.W. The Neuropathological Diagnosis of Alzheimer’s Disease. Mol. Neurodegener. 2019, 14, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Duboisa, B.; Padovanib, A.; Scheltensc, P.; Rossid, A.; Agnello, G.D. Timely Diagnosis for Alzheimer’s Disease: A Literature Review on Benefits and Challenges. J. Alzheimer’s Dis. 2015, 49, 617–631. [Google Scholar] [CrossRef] [PubMed]
- Balas, A.F.; Chircov, C.; Grumezescu, A.M. Body Fluid Biomarkers for Alzheimer’s Disease—An Up-To-Date Overview. Biomedicines 2020, 8, 11–13. [Google Scholar]
- Hane, F.T.; Robinson, M.; Lee, B.Y.; Bai, O.; Leonenko, Z.; Albert, M.S. Recent Progress in Alzheimer’s Disease Research, Part 3: Diagnosis and Treatment. J. Alzheimer’s Dis. 2017, 57, 645–665. [Google Scholar] [CrossRef] [PubMed]
- Jack, C.R.; Knopman, D.S.; Jagust, W.J.; Petersen, C.R.; Weiner, M.W.; Aisen, P.S.; Shaw, L.M.; Vemuri, P.; Wiste, H.J.; Weigand, S.D.; et al. Update on Hypothetical Model of Alzheimer’s Disease Biomarkers. Lancet Neurol. 2013, 12, 207–216. [Google Scholar] [CrossRef]
- Khatun, S.; Morshed, B.I.; Bidelman, G.M. A Single-Channel EEG-Based Approach to Detect Mild Cognitive Impairment via Speech-Evoked Brain Responses. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1063–1070. [Google Scholar] [CrossRef] [PubMed]
- Aoe, J.; Fukuma, R.; Yanagisawa, T.; Harada, T.; Tanaka, M.; Kobayashi, M.; Inoue, Y.; Yamamoto, S.; Ohnishi, Y.; Kishima, H. Automatic Diagnosis of Neurological Diseases Using MEG Signals with a Deep Neural Network. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef]
- Nair, J.J.; Mohan, N. Alzheimer’s Disease Diagnosis in MR Images Using Statistical Methods. In Proceedings of the 2017 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 6–8 April 2017; IEEE: Piscataway, NJ, USA, 2018; Volume 2018, pp. 1232–1235. [Google Scholar] [CrossRef]
- Pushpa, B.R.; Amal, P.S.; Kamal, N.P. Detection and Stagewise Classification of Alzheimer Disease Using Deep Learning Methods. Int. J. Recent Technol. Eng. 2019, 7, 206–212. [Google Scholar]
- Pasi, M.; Poggesi, A.; Pantoni, L. The Use of CT in Dementia. Int. Psychogeriatr. 2011, 23 (Suppl. S2), S6–S12. [Google Scholar] [CrossRef]
- Herholz, K.; Carter, S.F.; Jones, M. Positron Emission Tomography Imaging in Dementia. Br. J. Radiol. 2007, 80, 160–167. [Google Scholar] [CrossRef]
- Banovic, S.; Zunic, L.; Sinanovic, O. Communication Difficulties as a Result of Dementia. Mater. Socio Medica 2018, 30, 221. [Google Scholar] [CrossRef] [PubMed]
- Asgari, M.; Kaye, J.; Dodge, H. Predicting Mild Cognitive Impairment from Spontaneous Spoken Utterances. Alzheimer’s Dement. Transl. Res. Clin. Interv. 2017, 3, 219–228. [Google Scholar] [CrossRef]
- Lalitha, S.; Tripathi, S.; Gupta, D. Enhanced Speech Emotion Detection Using Deep Neural Networks. Int. J. Speech Technol. 2019, 22, 497–510. [Google Scholar] [CrossRef]
- Srimadhur, N.S.; Lalitha, S. An End-to-End Model for Detection and Assessment of Depression Levels Using Speech. Procedia Comput. Sci. 2020, 171, 12–21. [Google Scholar] [CrossRef]
- Ross, G.W.; Cummings, J.; Benson, D.F. Speech and Language Alterations in Dementia Syndromes: Characteristics and Treatment. Aphasiology 1990, 4, 339–352. [Google Scholar] [CrossRef]
- Hernández-Domínguez, L.; Ratté, S.; Sierra-Martínez, G.; Roche-Bergua, A. Computer-Based Evaluation of Alzheimer’s Disease and Mild Cognitive Impairment Patients during a Picture Description Task. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2018, 10, 260–268. [Google Scholar] [CrossRef]
- Ding, X.; Bucholc, M.; Wang, H.; Glass, D.H.; Wang, H.; Clarke, D.H.; Bjourson, A.J.; Dowey, L.R.C.; O’Kane, M.; Prasad, G.; et al. A Hybrid Computational Approach for Efficient Alzheimer’s Disease Classification Based on Heterogeneous Data. Sci. Rep. 2018, 8, 1–10. [Google Scholar] [CrossRef]
- Lalitha, S.; Geyasruti, D.; Narayanan, R.; Shravani, M. Emotion Detection Using MFCC and Cepstrum Features. Procedia Comput. Sci. 2015, 70, 29–35. [Google Scholar] [CrossRef]
- Liu, L.; Zhao, S.; Chen, H.; Wang, A. A New Machine Learning Method for Identifying Alzheimer’s Disease. Simul. Model. Pract. Theory 2020, 99, 102023. [Google Scholar] [CrossRef]
- Chen, J.; Zhu, J.; Ye, J. An Attention-Based Hybrid Network for Automatic Detection of Alzheimer’s Disease from Narrative Speech. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Graz, Austria, 15–19 September 2019; Volume 2019, pp. 4085–4089. [Google Scholar] [CrossRef]
- Weiner, J.; Engelbart, M.; Schultz, T. Manual and Automatic Transcriptions in Dementia Detection from Speech. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; Volume 2017, pp. 3117–3121. [Google Scholar] [CrossRef]
- Luz, S. Longitudinal Monitoring and Detection of Alzheimer’s Type Dementia from Spontaneous Speech Data. In Proceedings of the IEEE 30th International Symposium on Computer-Based Medical Systems (CBMS), Thessaloniki, Greece, 22–24 June 2017; Volume 2017, pp. 45–46. [Google Scholar] [CrossRef]
- Weiner, J.; Angrick, M.; Umesh, S.; Schultz, T. Investigating the Effect of Audio Duration on Dementia Detection Using Acoustic Features. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Hyderabad, India, 2–6 September 2018; Volume 2018, pp. 2324–2328. [Google Scholar] [CrossRef]
- Haider, F.; De La Fuente, S.; Luz, S. An Assessment of Paralinguistic Acoustic Features for Detection of Alzheimer’s Dementia in Spontaneous Speech. IEEE J. Sel. Top. Signal Process. 2020, 14, 272–281. [Google Scholar] [CrossRef]
- Sumali, B.; Mitsukura, Y.; Liang, K.C.; Yoshimura, M.; Kitazawa, M.; Takamiya, A.; Fujita, T.; Mimura, M.; Kishimoto, T. Speech Quality Feature Analysis for Classification of Depression and Dementia Patients. Sensors 2020, 20, 3599. [Google Scholar] [CrossRef] [PubMed]
- Vipperla, R.; Renals, S.; Frankel, J. Longitudinal Study of ASR Performance on Ageing Voices. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Brisbane, Australia, 22–26 September 2008; Volume 2008, pp. 2550–2553. [Google Scholar]
- Vekkot, S.; Gupta, D. Fusion of spectral and prosody modelling for multilingual speech emotion conversion. Knowl.-Based Syst. 2022, 242, 108360. [Google Scholar] [CrossRef]
- Warnita, T.; Inoue, N.; Shinoda, K. Detecting Alzheimer’s Disease Using Gated Convolutional Neural Network from Audio Data. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Hyderabad, India, 2–6 September 2018; Volume 2018, pp. 1706–1710. [Google Scholar] [CrossRef]
- Chien, Y.W.; Hong, S.Y.; Cheah, W.T.; Yao, L.H.; Chang, Y.L.; Fu, L.C. An Automatic Assessment System for Alzheimer’s Disease Based on Speech Using Feature Sequence Generator and Recurrent Neural Network. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef]
- Sadeghian, R.; Schaffer, D.J.; Zahorian, S.A. Using Automatic Speech Recognition to Identify Dementia in Early Stages. J. Acoust. Soc. Am. 2015, 138, 1782. [Google Scholar] [CrossRef]
- Petti, U.; Baker, S.; Korhonen, A. A Systematic Literature Review of Automatic Alzheimer’s Disease Detection from Speech and Language. J. Am. Med. Inform. Assoc. 2020, 27, 1784–1797. [Google Scholar] [CrossRef] [PubMed]
- Meghanani, A.; Anoop, C.S.; Ramakrishnan, A.G. An Exploration of Log-Mel Spectrogram and MFCC Features For Alzheimer’s Dementia Recognition from Spontaneous Speech. IEEE Spok. Lang. Technol. Work. 2021, 670–677. [Google Scholar] [CrossRef]
- Becker, J.T.; Boiler, F.; Lopez, O.L.; Saxton, J.; McGonigle, K.L. (DementiaBank English Pitt Corpus) The Natural History of Alzheimer’s Disease: Description Ofstudy Cohort and Accuracy of Diagnosis. Arch. Neurol. 1994, 51, 585–594. [Google Scholar] [CrossRef] [PubMed]
- The Audacity Team. Audacity®; The Audacity Team: Oak Park, MI, USA, 2021. [Google Scholar]
- Lauraitis, A.; Maskeliunas, R.; Damaševičius, R.; Krilavičius, T. Detection of Speech Impairments Using Cepstrum, Auditory Spectrogram and Wavelet Time Scattering Domain Features. IEEE Access 2020, 8, 96162–96172. [Google Scholar] [CrossRef]
- The Editors of Encyclopaedia Britannica. Available online: https://www.britannica.com/topic/pitch-speech (accessed on 20 September 2022).
- Jahnavi, B.S.; Supraja, B.S.; Lalitha, S. A Vital Neurodegenerative Disorder Detection Using Speech Cues. J. Intell. Fuzzy Syst. 2020, 38, 6337–6345. [Google Scholar] [CrossRef]
- DiPietro, R.; Hager, G.D. Deep Learning: RNNs and LSTM. In Handbook of Medical Image Computing and Computer Assisted Intervention; Academic Press: Cambridge, MA, USA, 2019; pp. 503–519. [Google Scholar] [CrossRef]
- Yang, R.; Feng, L.; Wang, H.; Yao, J.; Luo, S. Parallel Recurrent Convolutional Neural Networks-Based Music Genre Classification Method for Mobile Devices. IEEE Access 2020, 8, 19629–19637. [Google Scholar] [CrossRef]
- Frank, E.; Hall, M.; Holmes, G.; Kirkby, R.; Witten, I.H. Weka: A Machine Learning Workbench for Data Mining. In Data Mining and Knowledge Discovery Handbook: A Complete Guide for Practitioners and Researchers; Maimon, O., Rokach, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Lalitha, S.; Gupta, D.; Zakariah, M.; Alotaibi, Y.A. Investigation of Multilingual and Mixed-Lingual Emotion Recognition Using Enhanced Cues with Data Augmentation. Appl. Acoust. 2020, 170, 107519. [Google Scholar] [CrossRef]
- Vigo, I.; Coelho, L.; Reis, S. Speech- and Language-Based Classification of Alzheimer’s Disease: A Systematic Review. Bioengineering 2022, 9, 27. [Google Scholar] [CrossRef] [PubMed]
- Abbaszadeh Shahri, A.; Shan, C.; Zäll, E.; Larsson, S. Spatial Distribution Modeling of Subsurface Bedrock Using a Developed Automated Intelligence Deep Learning Procedure: A Case Study in Sweden. J. Rock Mech. Geotech. Eng. 2021, 13, 1300–1310. [Google Scholar] [CrossRef]
- Liu, D.; Lin, P.; Zhao, C.; Qiu, J. Mapping Horizontal Displacement of Soil Nail Walls Using Machine Learning Approaches. Acta Geotech. 2021, 16, 4027–4044. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, N.; Zheng, Q.; Xu, Y.S. Real-Time Prediction of Shield Moving Trajectory during Tunnelling Using GRU Deep Neural Network. Acta Geotech. 2022, 17, 1167–1182. [Google Scholar] [CrossRef]
- Tabarestani, S.; Aghili, M.; Shojaie, M.; Freytes, C.; Cabrerizo, M.; Barreto, A.; Rishe, N.; Curiel, R.E.; Loewenstein, D.; Duara, R.; et al. Longitudinal Prediction Modeling of Alzheimer Disease Using Recurrent Neural Networks. In Proceedings of the 2019 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Chicago, IL, USA, 19–22 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Dozat, T. Incorporating Nesterov Momentum into Adam. 2016. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwi4t6b5grf7AhUDNd4KHev8C5IQFnoECA0QAQ&url=https%3A%2F%2Fopenreview.net%2Fpdf%2FOM0jvwB8jIp57ZJjtNEZ.pdf&usg=AOvVaw0iYSzFfzEXwraAE8RXxVQS (accessed on 20 September 2022).
- Tensorflow-Keras. Nadam Optimizer. Available online: https://keras.io/api/optimizers/Nadam/ (accessed on 29 July 2022).
- Triapthi, A.; Chakraborty, R.; Kopparapu, S.K. Dementia Classification Using Acoustic Descriptors Derived from Subsampled Signals. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021; Volume 2021, pp. 91–95. [Google Scholar] [CrossRef]
- Liu, Z.; Guo, Z.; Ling, Z.; Li, Y. Detecting Alzheimer’s Disease from Speech Using Neural Networks with Bottleneck Features and Data Augmentation. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; Volume 2021, pp. 7323–7327. [Google Scholar] [CrossRef]
- La Fuente Garcia, S.; De Haider, F.; Luz, S. Cross-Corpus Feature Learning between Spontaneous Monologue and Dialogue for Automatic Classification of Alzheimer’s Dementia Speech. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; Volume 2020, pp. 5851–5855. [Google Scholar] [CrossRef]





| Model/Feature (No. of Features) | MFCC (14) | Delta MFCC (14) | GTCC (14) | Delta GTCC (14) | Log Energy (1) | Formants (4) | Pitch (1) | Fundamental Frequency (1) | Jitter (5) | Shimmer (5) | Total Number of Features |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Random forest | ✓ | - | ✓ | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 44 |
| Random tree | ✓ | - | ✓ | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 44 |
| REP tree | ✓ | - | ✓ | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 44 |
| SVM | ✓ | - | ✓ | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 44 |
| ANN | ✓ | - | ✓ | - | ✓ | ✓ | - | ✓ | - | - | 33 |
| CNN | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | ✓ | - | - | 62 |
| GRU | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | ✓ | - | - | 62 |
| LSTM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | ✓ | - | - | 62 |
| Bi-GRU | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | ✓ | - | - | 62 |
| Bi-LSTM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | ✓ | - | - | 62 |
| PRCNN | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | ✓ | - | - | 62 |
| Model | Class | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|---|
| Random forest | HC | 84.7 | 92.5 | 88.5 |
| Dementia | 91.2 | 82.2 | 86.5 | |
| Random tree | HC | 79.1 | 76.3 | 77.7 |
| Dementia | 75.7 | 78.5 | 77.1 | |
| REP tree | HC | 79.1 | 76.3 | 77.7 |
| Dementia | 85.9 | 76.6 | 81 | |
| SVM | HC | 73.3 | 97.4 | 83.6 |
| Dementia | 95.7 | 62.1 | 75.4 |
| Model | Class | Precision (%) | Recall (%) | F-Score (%) |
|---|---|---|---|---|
| ANN | HC | 81.3 | 88 | 84.5 |
| Dementia | 84.4 | 73.7 | 78.7 | |
| CNN | HC | 83.1 | 89.2 | 86 |
| Dementia | 85.4 | 77.5 | 81.3 | |
| GRU | HC | 84.1 | 88.5 | 86.2 |
| Dementia | 85.8 | 78.6 | 82 | |
| LSTM | HC | 82 | 87.9 | 84.9 |
| Dementia | 84.3 | 76 | 79.9 | |
| Bi-GRU | HC | 83.3 | 88.8 | 86 |
| Dementia | 85.4 | 77.5 | 81.3 | |
| Bi-LSTM | HC | 84.4 | 86 | 85.2 |
| Dementia | 83.3 | 80.3 | 81.8 | |
| PRCNN | HC | 85.9 | 87.2 | 86.6 |
| Dementia | 84.7 | 82.4 | 83.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, M.R.; Vekkot, S.; Lalitha, S.; Gupta, D.; Govindraj, V.J.; Shaukat, K.; Alotaibi, Y.A.; Zakariah, M. Dementia Detection from Speech Using Machine Learning and Deep Learning Architectures. Sensors 2022, 22, 9311. https://doi.org/10.3390/s22239311
Kumar MR, Vekkot S, Lalitha S, Gupta D, Govindraj VJ, Shaukat K, Alotaibi YA, Zakariah M. Dementia Detection from Speech Using Machine Learning and Deep Learning Architectures. Sensors. 2022; 22(23):9311. https://doi.org/10.3390/s22239311
Chicago/Turabian StyleKumar, M. Rupesh, Susmitha Vekkot, S. Lalitha, Deepa Gupta, Varasiddhi Jayasuryaa Govindraj, Kamran Shaukat, Yousef Ajami Alotaibi, and Mohammed Zakariah. 2022. "Dementia Detection from Speech Using Machine Learning and Deep Learning Architectures" Sensors 22, no. 23: 9311. https://doi.org/10.3390/s22239311
APA StyleKumar, M. R., Vekkot, S., Lalitha, S., Gupta, D., Govindraj, V. J., Shaukat, K., Alotaibi, Y. A., & Zakariah, M. (2022). Dementia Detection from Speech Using Machine Learning and Deep Learning Architectures. Sensors, 22(23), 9311. https://doi.org/10.3390/s22239311