Abstract
Text document clustering is one of the data mining techniques used in many real-world applications such as information retrieval from IoT Sensors data, duplicate content detection, and document organization. Swarm intelligence (SI) algorithms are suitable for solving complex text document clustering problems compared to traditional clustering algorithms. The previous studies show that in SI algorithms, particle swarm optimization (PSO) provides an effective solution to text document clustering problems. This PSO still needs to be improved to avoid the problems such as premature convergence to local optima. In this paper, an approach called dynamic sub-swarm of PSO (subswarm-PSO) is proposed to improve the results of PSO for text document clustering problems and avoid the local optimum by improving the global search capabilities of PSO. The results of this proposed approach were compared with the standard PSO algorithm and K-means algorithm. As for performance assurance, the evaluation metric purity is used with six benchmark data sets. The experimental results of this study show that our proposed subswarm-PSO algorithm performs best with high purity comparing the standard PSO and K-means traditional algorithms and also the execution time of subswarm-PSO comparatively takes a little less than the standard PSO algorithm.
1. Introduction
In recent years, there has been a tremendous increase in the volume of text documents on the Internet and modern applications which affect the text analysis process (i.e., text feature selection, text document clustering, text categorization, etc.) [1,2]. Text document clustering is an unsupervised classification of textual documents into clusters based on content similarity [3]. The most popular algorithms for clustering are K-means and its variants, as the K-means algorithm is a simple and most used unsupervised partitioning algorithm [4]. Extracting relevant information from the data is a challenging task that needs fast and high-quality text document clustering algorithms. In this study, swarm intelligence (SI) algorithms have been applied to text document clustering and improved one of the best-performing swarm algorithms to improve the quality of results.
SI algorithms include simple unintelligent agents that follow some simple rules to accomplish very complex tasks. SI algorithms are suitable for resolving complex text document clustering problems compared with traditional clustering algorithms [5]. The PSO provides an effective solution to text document clustering [6]. However, the PSO algorithm usually suffers from falling into a premature convergence to local optimum [7]. This is because PSO initializes the particles in starting of the algorithm and the searching behavior includes that all the particles move towards the best solution and search around the local area. In this case, if the initialization does not explore the proper area including the global solution, there is no option to research the undiscovered area to globally search again in the middle of the algorithm. To improve the global searching capability of the PSO algorithm for text document clustering, in this paper, a dynamic subswarm-PSO algorithm is proposed [8]. This proposed algorithm will reinitialize the number of worst fitness particles in each iteration. Six different data sets, created from BBC sports news [9], 20 newsgroups [10], and scientific papers [11], were used in this study. Purity is used as an evaluation metric for this study. The experimental results show that our proposed subswarm-PSO algorithm performs best comparing the standard PSO and K-means traditional algorithms. Also, the average execution time of our proposed algorithm is a little less than the standard PSO algorithm.
The next section provides an overview of the research work focused on the improvements in the PSO algorithm. Section 3 shows the process of the text document clustering problem. Section 4 outlines the existing standard algorithms for text document clustering. Section 5 describes our proposed subswarm approach in the PSO algorithm. Section 7 shows the experimental conditions. Section 8 shows the experimental results and a detailed discussion of these results. Section 9 summarizes the present research work.
2. Related Work
This section shows the previous research works (Table 1) related to the PSO algorithm with different sub-swarm optimization techniques.

Table 1.
Related research work.
3. Text Document Clustering
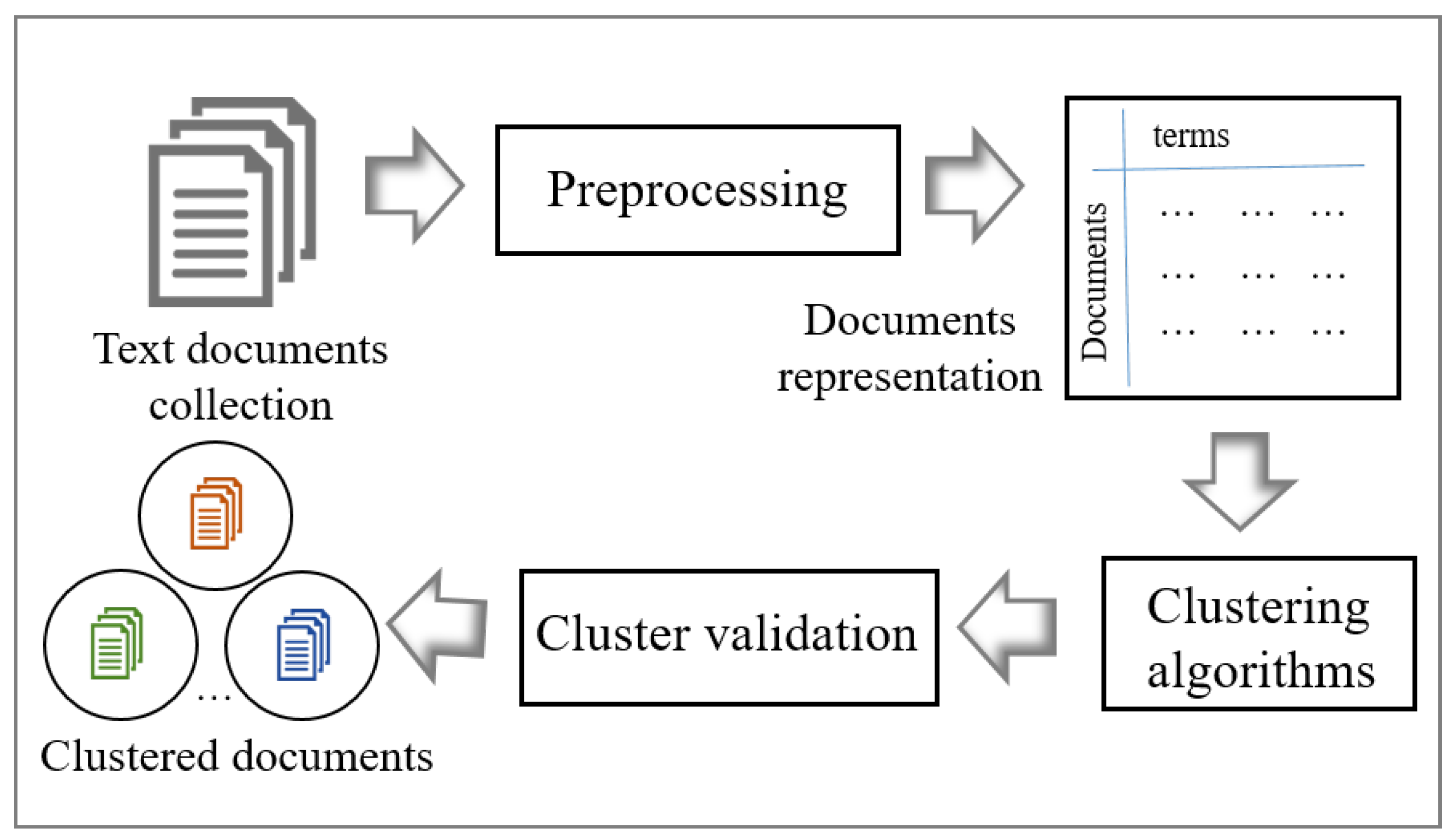
This section describes the main process of text document clustering. This process includes text document collection, pre-processing, document representation, clustering, and cluster validation as shown in Figure 1 [18].
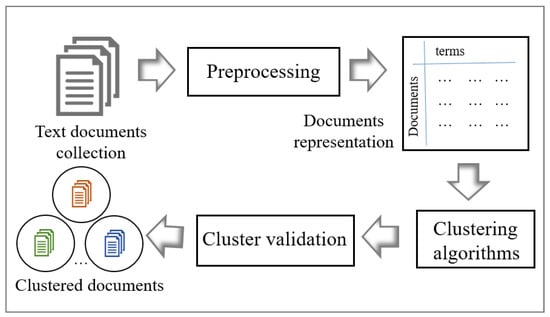
Figure 1.
The Process of Text Document Clustering [18].
Pre-processing is an important step to enhance the performance of the clustering algorithm. As shown in the Figure 1, after collecting the required raw text documents, text pre-processing is used to clean these text documents by applying natural language processing techniques such as tokenization, stop word removal, stemming, and term weighting to delete the unwanted data and manipulate the data. Then, pre-processing turns these clean documents into a term-document matrix. Here, t represents the number of unique terms in the document collection, and d represents the number of documents. The text document clustering algorithms (PSO and subswarm PSO) directly use this matrix to convert the document data sets into meaningful sub-collections.
As shown in Figure 1, to validate the quality of results from text document clustering algorithms, a few cluster evaluation metrics can be used. The next subsection explains the evaluation metrics in detail.
3.1. Evaluation Metrics
This subsection shows the evaluation metrics of text document clustering. Clusters can be evaluated using the metrics such as purity, homogeneity, accuracy, completeness, entropy, F-measure, V-measure, and adjusted rand index (ARI). In this study, we use purity to evaluate the quality of text document clustering algorithms.
Purity
Purity measures whether the clusters contain documents from a single category. The purity value ranges from 0 and 1. Purity is computed by dividing the number of properly assigned documents by N. The ideal clusters will get a purity value is 1. Equation (1) is used to compute the purity [19,20]:
where is the set of classes and is the set of clusters.
4. Algorithms for Text Document Clustering
This section shows the algorithms such as traditional K-means and standard PSO for the text document clustering problem. The standard PSO is a better performing algorithm than a few popular other standard SI algorithms such as bat and grey wolf optimization for text document clustering [18]. Therefore, in this study, we compare the performance of our proposed subswarm-PSO algorithms with these traditional K-means and standard PSO algorithms.
4.1. K-Means Algorithm for Text Document Clustering
The K-means is a popular traditional clustering algorithm that starts with the initialization of a number of clusters k and the random initialization of k cluster centers. After initialization, in the loop, the algorithm assigns each document to its closest centroid based on its similarity and updates the centroid of each cluster. This loop will execute again and again until meets the termination condition as shown in the Algorithm 1 [21].
| Algorithm 1: K-means text document clustering algorithm |
 |
4.2. PSO Algorithm for Text Document Clustering
The PSO algorithm is a population-based optimization algorithm developed based on the collective behavior of a flock of birds or fish schools, and aims to locate all the particles in the optimal position [21]. In this study, each particle in the PSO algorithm includes k cluster centroids of text document clusters. The initialization phase is used to initialize the n number of particles in the PSO algorithm and a few PSO parameters. The position of each particle will be initialized with k number of cluster centers randomly. After the initialization, k clusters are created by assigning each document to the closest center by calculating the distance to each centroid. Then, the fitness function purity (Equation (1)) evaluates the clusters, and the global best (gbest) and individual best (pbest) solutions are updated. Then, the new velocity (Equation (2)) and position (Equation (3)) are calculated for each particle. Until reaching the termination condition iterations will continue as shown in Algorithm 2. As a result, the algorithm finally returns the global best solution [22].
In Equations (2) and (3), and are the velocity and position of the particle i at iteration t. is the personal or individual best position of i. is the global best position of all particles. is the inertia weight to balance the global search and local search. and are positive constant values used to control the speed of the particle. and are random parameters within [0,1] [19,21].
| Algorithm 2: PSO text document clustering algorithm |
 |
5. Proposed Approach
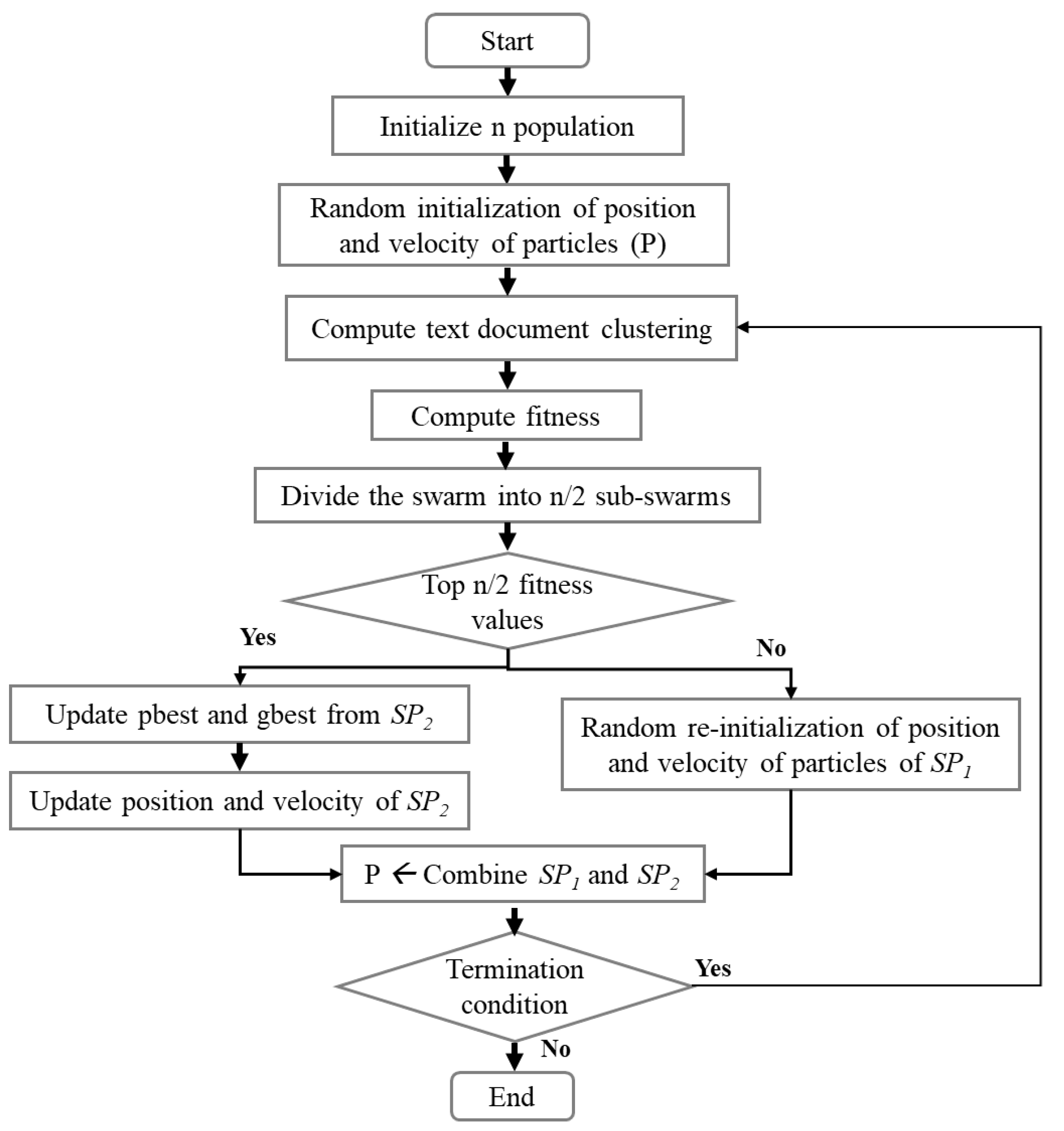
This section describes the proposed subswarm-PSO approach. The main focus of this study is to optimize the result of the PSO algorithm for the text document clustering (Algorithm 2) by applying dynamic sub-swarm techniques to the PSO algorithm as shown in Figure 2.
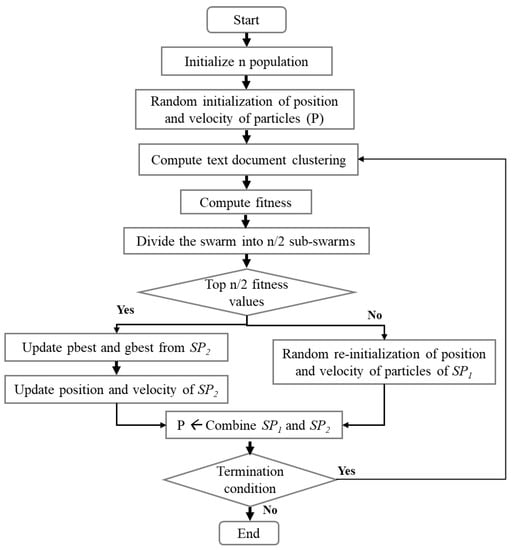
Figure 2.
The proposed dynamic sub-swarm for PSO algorithm.
The initialization section of the proposed subswarm-PSO algorithm is the same as the PSO algorithm and its starts with the initialization of populations (n) and other parameters of PSO. Each particle of the PSO algorithm is randomly initialized with the k cluster centers. Then the algorithm computes text document clustering around the cluster centers and executes the fitness function.
The proposed approach is implemented in the PSO algorithm while moving the position of the particles to the next position in the PSO algorithm. Here, based on the fitness solution, we dynamically divide the entire swarm population into two. That is the top n/2 best fitness particles are grouped into one sub-swarm () and the other n/2 particles with the remaining least fitness solutions are grouped into another sub-swarm (). As shown in Figure 2, the particles of sub-swarm will move to the next position and update the pbest and gbest solutions among them. The particle solutions from are abandoned and re-initialized randomly. Then, the sub-swarms and will be combined and moved to the next iteration until meets the termination condition.
In this proposed approach, to divide the two sub-swarms, the optimum number n/2 is chosen from the experiment with a different number of abandoned particles with the least solutions such as 1, , , , and as shown in the experiment and results section.
6. Proposed Dynamic Sub-Swarm Pso Algorithm for Text Document Clustering
As shown in the Algorithm 3, subswarm-PSO algorithm initialize n number of particles and other PSO parameters. Each particle in the PSO randomly initializes the k number of centroid points of the clusters. After initialization, the clusters are created by assigning each document to the closest centroid by calculating the distance to each centroid. Next, fitness values will be calculated for each particle. The pbest and gbest solutions will be updated as shown in the algorithm.
where particles of PSO , sorted particles , and .
Then, before updating the particles and moving to the next iteration in Algorithm 2, our proposed approaches are applied (from Equation (4) to (9)) in the PSO algorithm as shown in Algorithm 3. Here, Equation (4) and Algorithm 3 show that all particles P of PSO are sorted by fitness values using quicksort in ascending order and stored in SP. The total sorted swarm population is divided based on the fitness solution into two sub-swarms and as shown in Equations (5) and (6) respectively.
The sub-swarm includes particles with the least fitness solutions and includes particles with top fitness solutions. Here, we abandon the solutions of the sub-swarm particles and randomly reinitialized these particles as shown in Equation (7). As shown in Equation (8), the sub-swarm includes the particles of with updated new velocity (Equation (2)) and position (Equation (3)). The sub-swarms and will be combined as as shown in Equation (9) and assigned to particles P for the next iteration as shown in the Algorithm 3. The final result of the algorithm includes the global best solution.
| Algorithm 3: Dynamic Sub-Swarm Approach of PSO Algorithms for Text Document Clustering |
 |
7. Experiment
This section shows the details of benchmark data sets and experimental conditions that were used for this experiment.
7.1. Benchmark Data Sets
In this study, six different benchmark machine learning data sets were used that are constructed from BBC sports news [9], 20 newsgroups [10], and scientific papers [11]. These data sets are most commonly used for text document clustering and are publicly available for machine learning research [23,24]. Considering the computation time and our resources, we have used only six different data sets for this study.
As shown in Table 2, data set 1 includes 1427 documents and 23,057 terms and these documents belong to 2 clusters (alt.atheism and talk.religion.misc) from 20 newsgroups. Data set 2 consists of 737 documents and 4613 terms and belongs to 5 clusters (athletics, cricket, football, rugby, and tennis) from BBC sports news. Data set 3 includes 40 documents and 2596 terms and belongs to 5 clusters (athletics, cricket, football, rugby, and tennis) from BBC sports news. Data set 4 includes 200 documents and 8716 terms and these documents belong to 4 clusters (rec.motorcycles, rec.sport.hockey, sci.electronics, and talk.religion.misc) from 20 newsgroups. Data set 5 includes 100 documents and 5549 terms and these documents belong to 3 clusters (rec.motorcycles, rec.sport.hockey, and talk.religion.misc) from 20 newsgroups. Data set 6 includes scientific papers in the field of computer science. The data set contains 675 scientific papers and 27,416 terms under 4 classes including case-based reasoning (CBR), inductive logic programming (ILP), information retrieval (IR), and sonification (SON). Here, each paper is including the title, authors, abstract, and references.
Table 2.
Benchmark data sets.
7.2. Experimental Conditions
In this study, the population size of each SI algorithm is assigned as 10. Here, for each algorithm, we performed experiments for the iterations such as 10, 20, 30, …, 100. Five simulations are used for each iteration number to handle the stochastic results of algorithms. The performance of this algorithm is evaluated using the evaluation metric purity and these results were compared with the algorithms K-means and PSO.
In this experiment, our proposed approach is applied with a different number of abandoned particles with the least solutions such as 1, , , , and to find the optimal number of abandoned particles and with the optimal number, the comparative study is performed. To determine the optimum number of particles to be abandoned, we use experiments with 10 and 20 particles.
Here, to compare the performance of PSO and proposed subswarm-PSO, the same default parameters = 0.9, = 0.5, and = 0.3 of the PSO algorithm were used in both algorithms from the literature [18,25].
8. Results
This section shows the experimental results of finding the optimum number of abandoned least solutions of particles and the comparative results of the proposed subswarm-PSO algorithm with the optimum number of abandoned particles with the least solution for the text document clustering problem.
8.1. Different Number of Abandoned Particles with Least Solutions for Subswarm-PSO
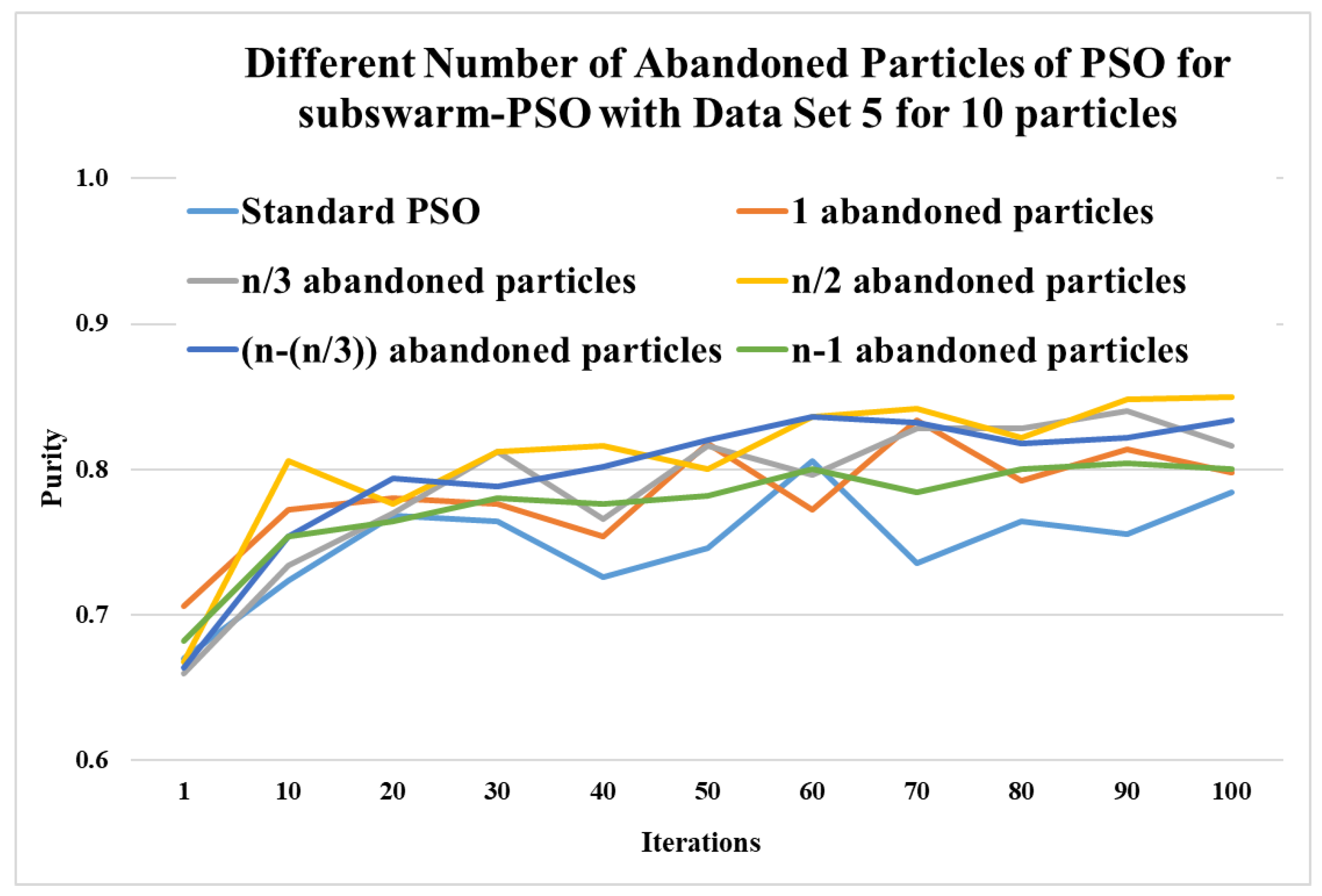
This section shows the experimental results of a different number of abandoned particles of PSO for the subswarm-PSO approach to find the optimum number of abandoned particles with the least solution. Here, we experiment and compare with 1, , , , and number of abandoned particles for subswarm-PSO with data set 5 for 10 and 20 particles.
This experiment includes the following.
- 1 particle with the least solution will be abandoned and reinitialized randomly. The remaining particles will move to the next position.
- particles with the least solution will be abandoned and reinitialized randomly. The remaining particles will move to the next position.
- particles with the least solution will be abandoned and reinitialized randomly. The remaining particles will move to the next position.
- particles with the least solution will be abandoned and reinitialized randomly. The remaining particles will move to the next position.
- particles with the least solution will be abandoned and reinitialized randomly. The remaining 1 particle will move to the next position.
Here, Table 3 and Figure 3 show the comparative experimental results for a number of abandoned particles with the least solutions such as 1, , , , and are compared with the standard PSO algorithm for 10 particles. This table shows the maximum, mean, and standard deviation of purity values for the iterations (1, 10, 20, 30, …, 100) and data set 5. This table also shows the average and ranks for all numbers of abandoned particles. Here, the results show that abandoned particles show the highest performance with the purity values 0.806, 0.812, 0.816, 0.836, 0.842, 0.848, and 0.850 for iterations 10, 30, 40, 60, 70, 90, and 100, respectively. The next level performance is shown for and with an average of 0.797 and 0.788.
Table 3.
Different number of abandoned particles with least solutions of subswarm-PSO for 10 particles.
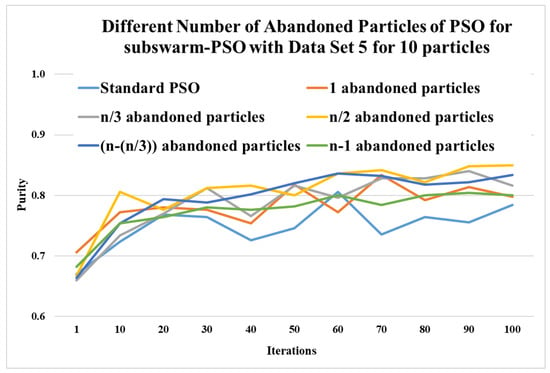
Figure 3.
Comparison of different numbers of abandoned particles of subswarm-PSO for data set 5 with 10 particles.
Figure 3 shows that comparing the standard PSO algorithm with other compared methods shows better performance and half-abandoned particles show the best performance.
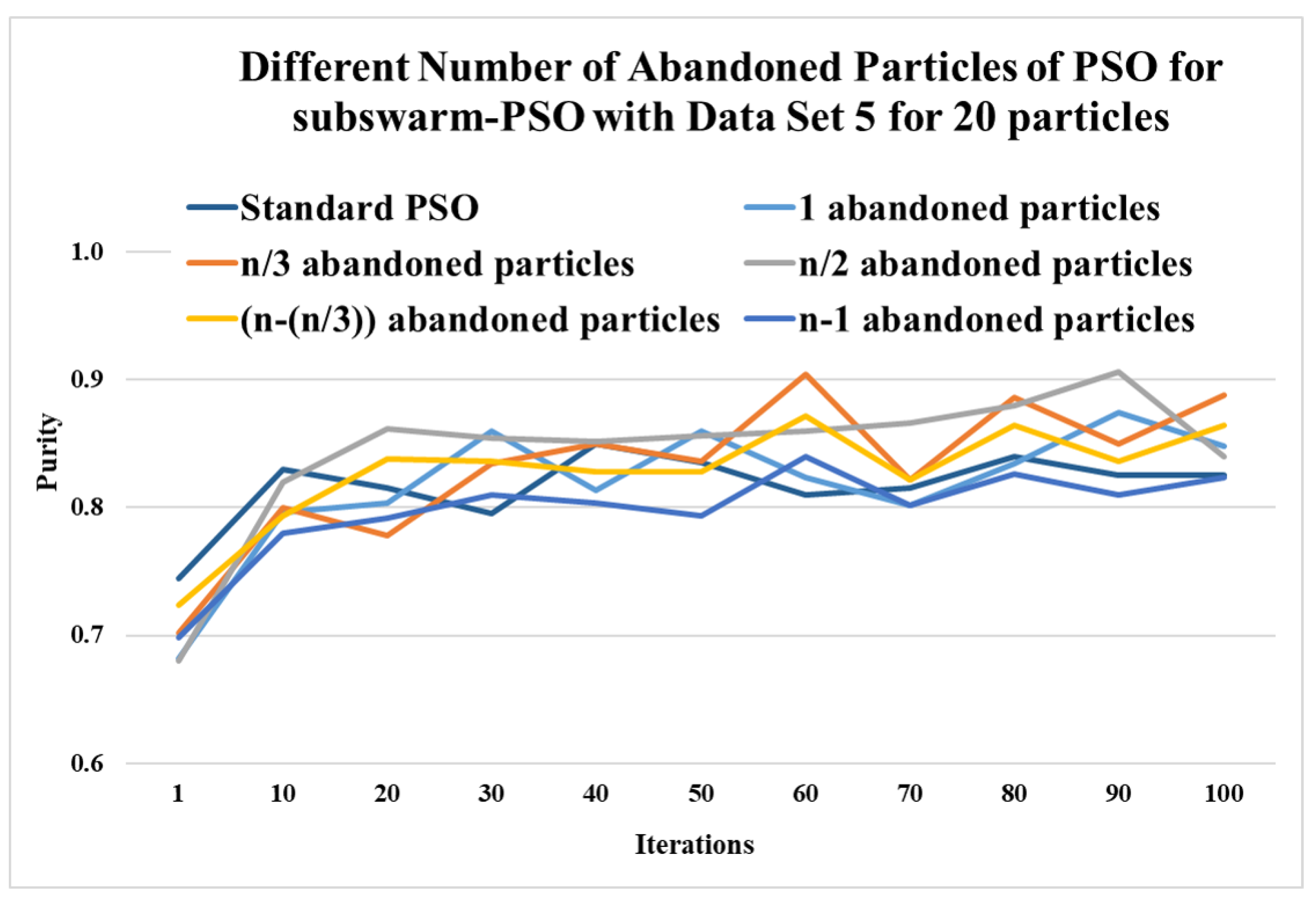
Here, Table 4 shows the comparative experimental results for a number of abandoned particles with the least solutions such as 1, , , , and are compared with the standard PSO algorithm for 20 particles. This table shows the maximum, mean, and standard deviation of purity for the iterations (1, 10, 20, 30, …, 100) and data set 5. This table also shows the average and ranks for all numbers of abandoned particles. Here, the results show that abandoned particles show the highest performance with the purity values 0.862, 0.852, 0.866, and 0.906 for iterations 20, 40, 70, and 90 respectively. The next level’s performance is shown for with an average of 0.832. Figure 4 shows the results of a different number of abandoned particles for 20 particles and this figure shows that comparing the standard PSO algorithm other compared methods show better performance and half-abandoned particles show the best performance with the highest average value of 0.843.
Table 4.
Different number of abandoned particles with least solutions of subswarm-PSO for 20 particles.
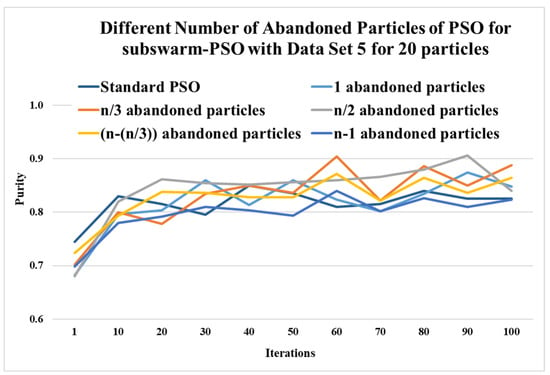
Figure 4.
Comparison of the different number of abandoned particles of subswarm-PSO for data set 5 with 20 particles.
8.2. Performance Comparison of Proposed Subswarm PSO Algorithm
This section shows the performance comparison results of the proposed subswarm-PSO algorithm with an optimal number of abandoned particles with the least solution which is determined by the experimental results of the previous subsection.
Table 5 shows the maximum, mean, and standard deviation of purity values for the text document clustering algorithms. These values are the average of all the iteration numbers. The highest purity means values among all the algorithms for each data set are highlighted in bold. Here, the subswarm-PSO algorithm has the highest purity mean values of 0.728, 0.820, 0.650, 0.807, and 0.888 for data set 1, 3, 4, 5, and 6 respectively. The algorithm K-means shows the highest purity mean value of 0.763 for data set 2. The K-means algorithm shows the lowest purity mean values of 0.527, 0.651, 0.450, and 0.595 for data sets 1, 3, 4, and 5 respectively.
Table 5.
Maximum, mean, and standard deviation results for all iteration numbers for clustering algorithms for six data sets.
Table 6 shows the ranking of the mean of purity values for text document clustering algorithms with all data sets for the data shown in Table 5. This table shows that the total performance ranks of the algorithms K-means, PSO, and subswarm-PSO are 3, 2, and 1 respectively.
Table 6.
Ranking table of purity mean values for text document clustering algorithms.
The comparative results and average running time of all algorithms for the data sets 1 to 6 are shown in the Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10, Figure 11, Figure 12, Figure 13, Figure 14, Figure 15 and Figure 16. K-means takes very little time for execution. So, we ignored K-means and compared the execution time for only PSO and subswarm-PSO.
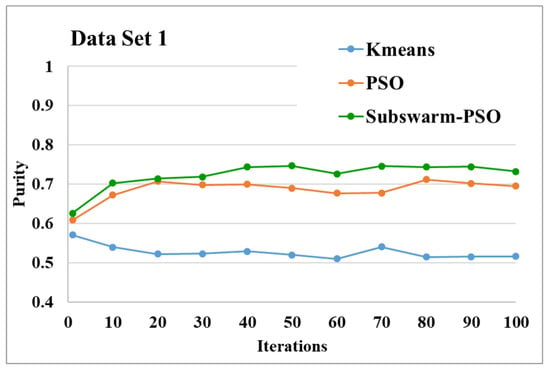
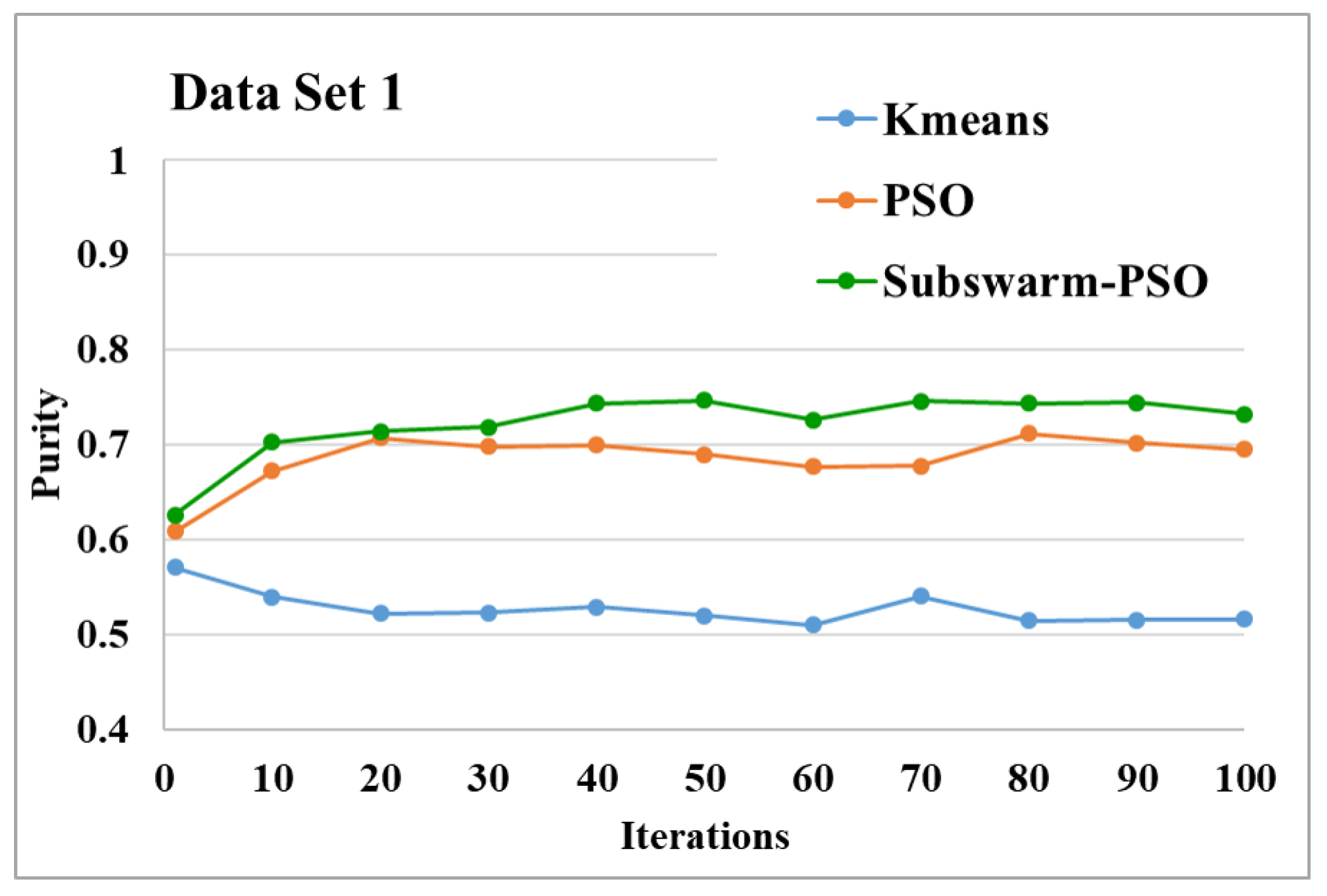
Figure 5.
Purity comparison for data set 1.
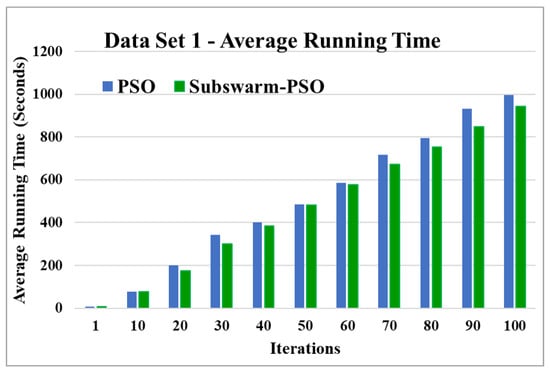
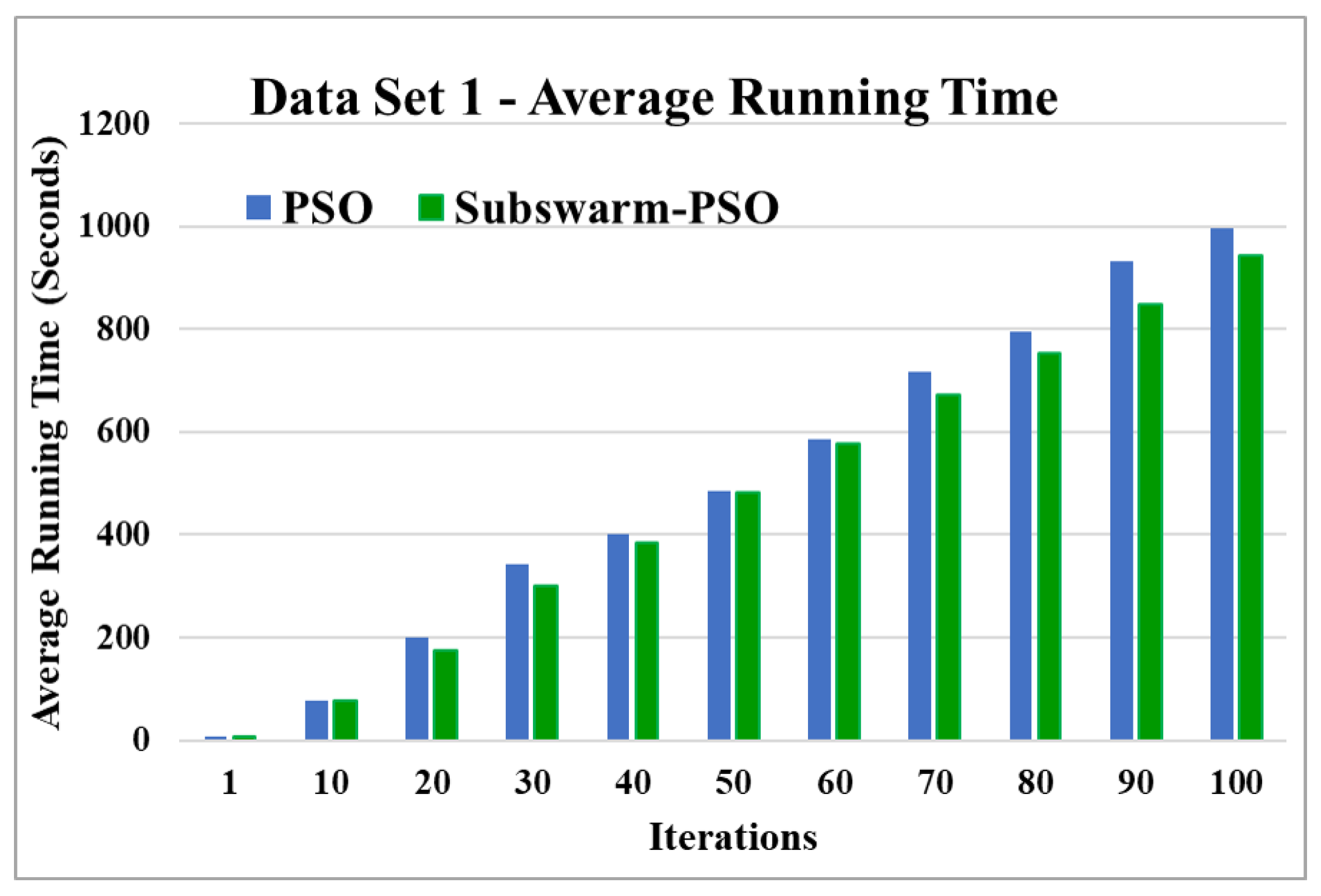
Figure 6.
Average running time for data set 1.
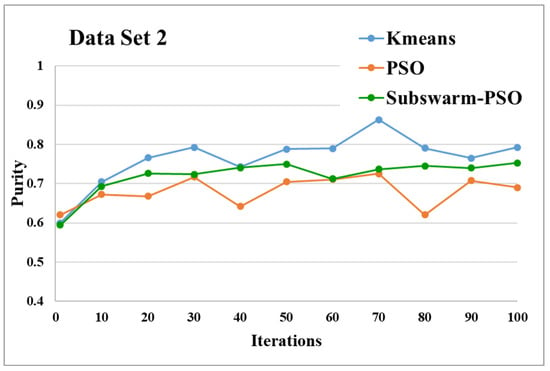
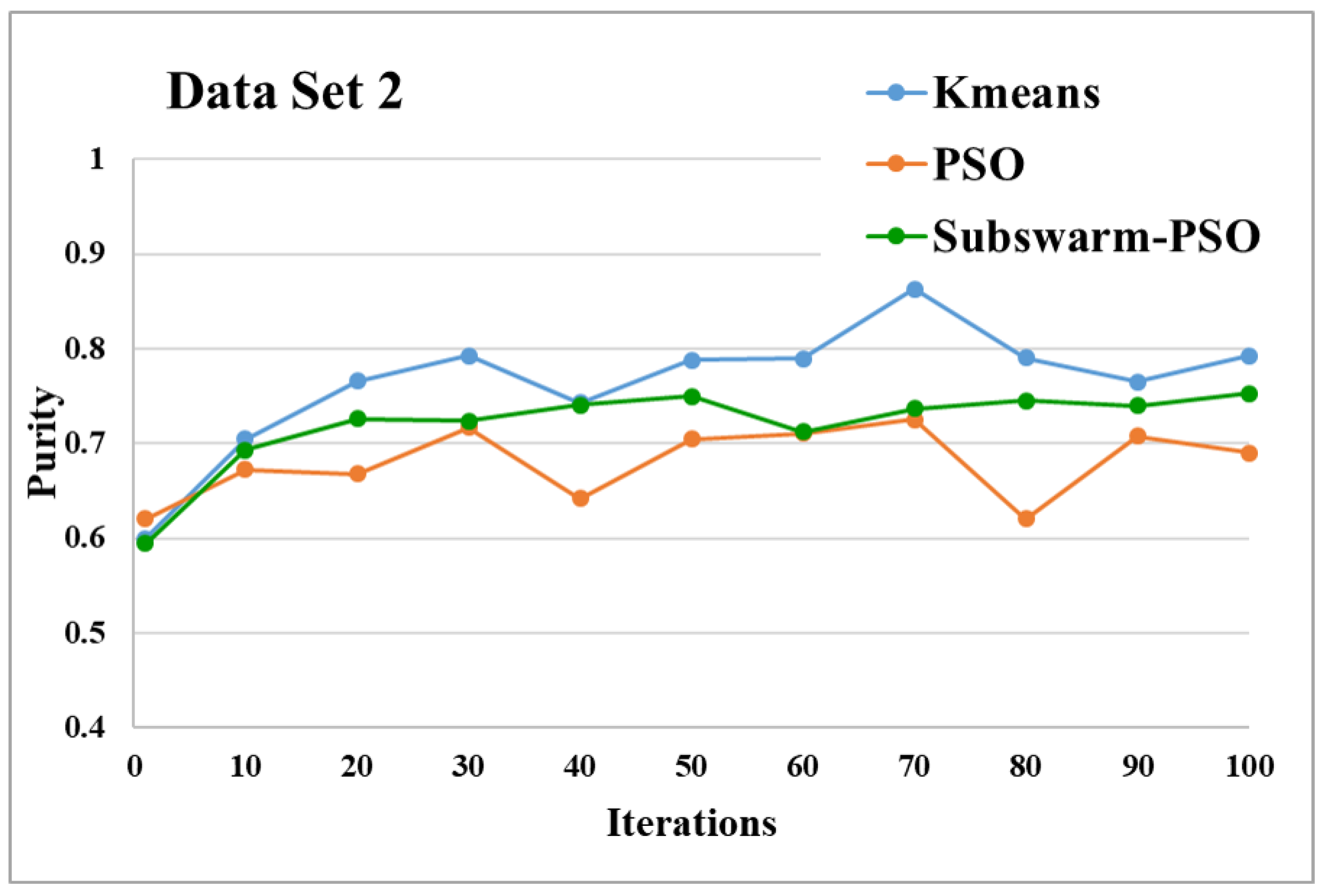
Figure 7.
Purity comparison for data set 2.
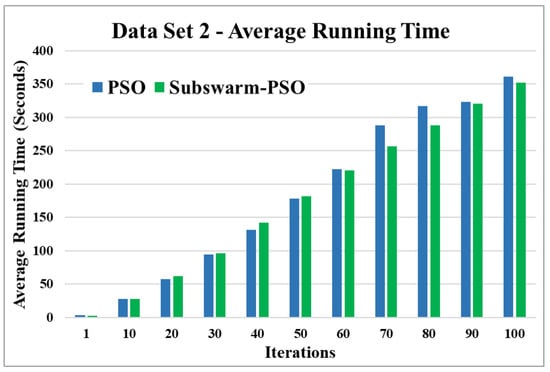
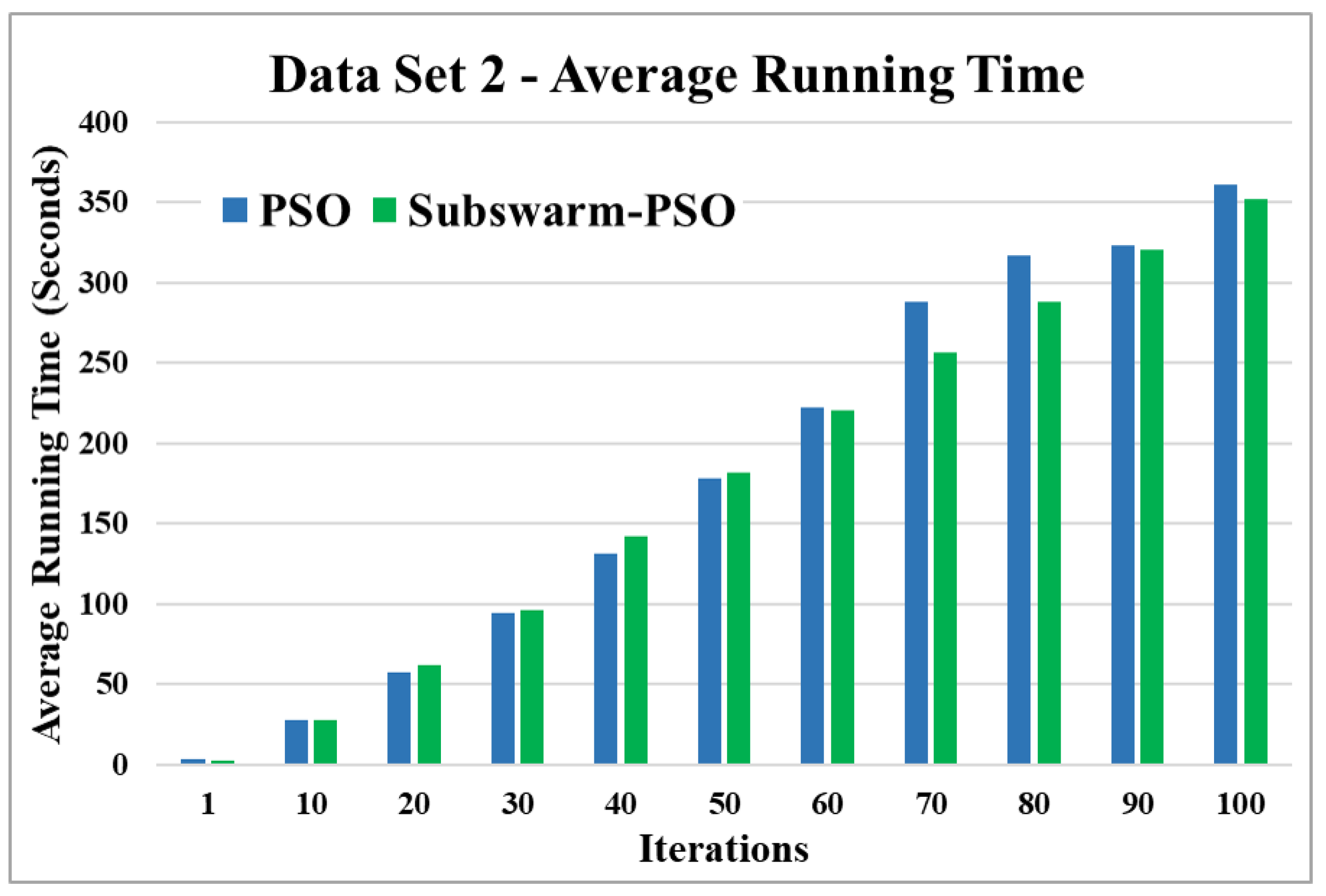
Figure 8.
Average running time for data set 2.
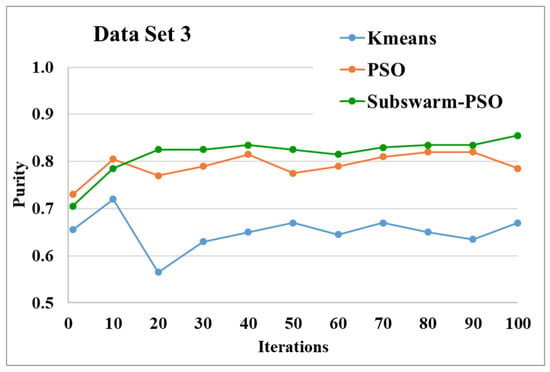
Figure 9.
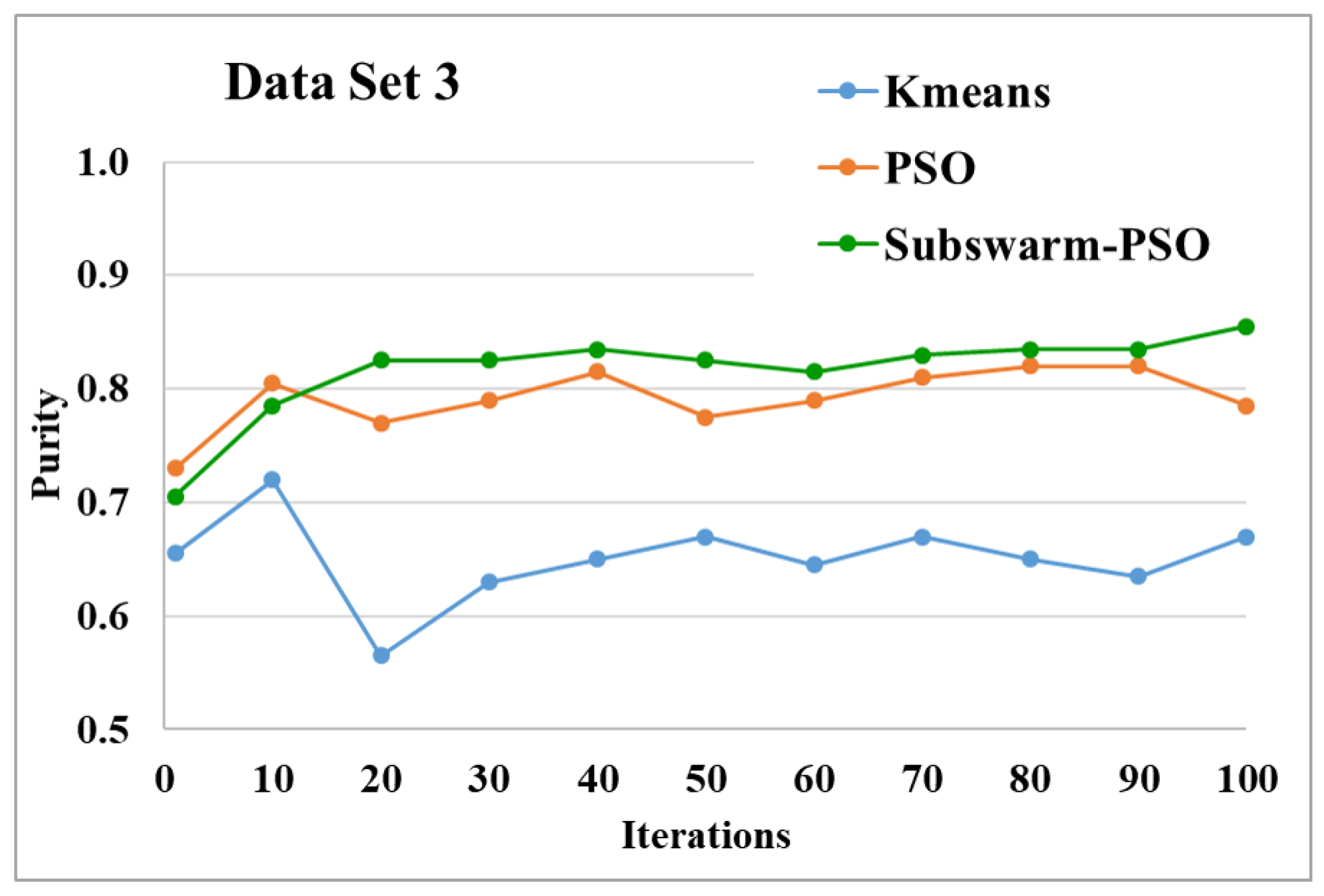
Purity comparison for data set 3.
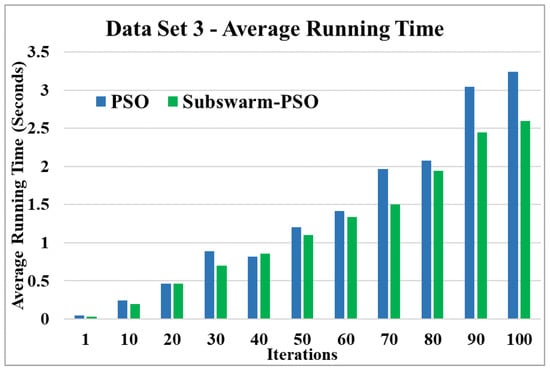
Figure 10.
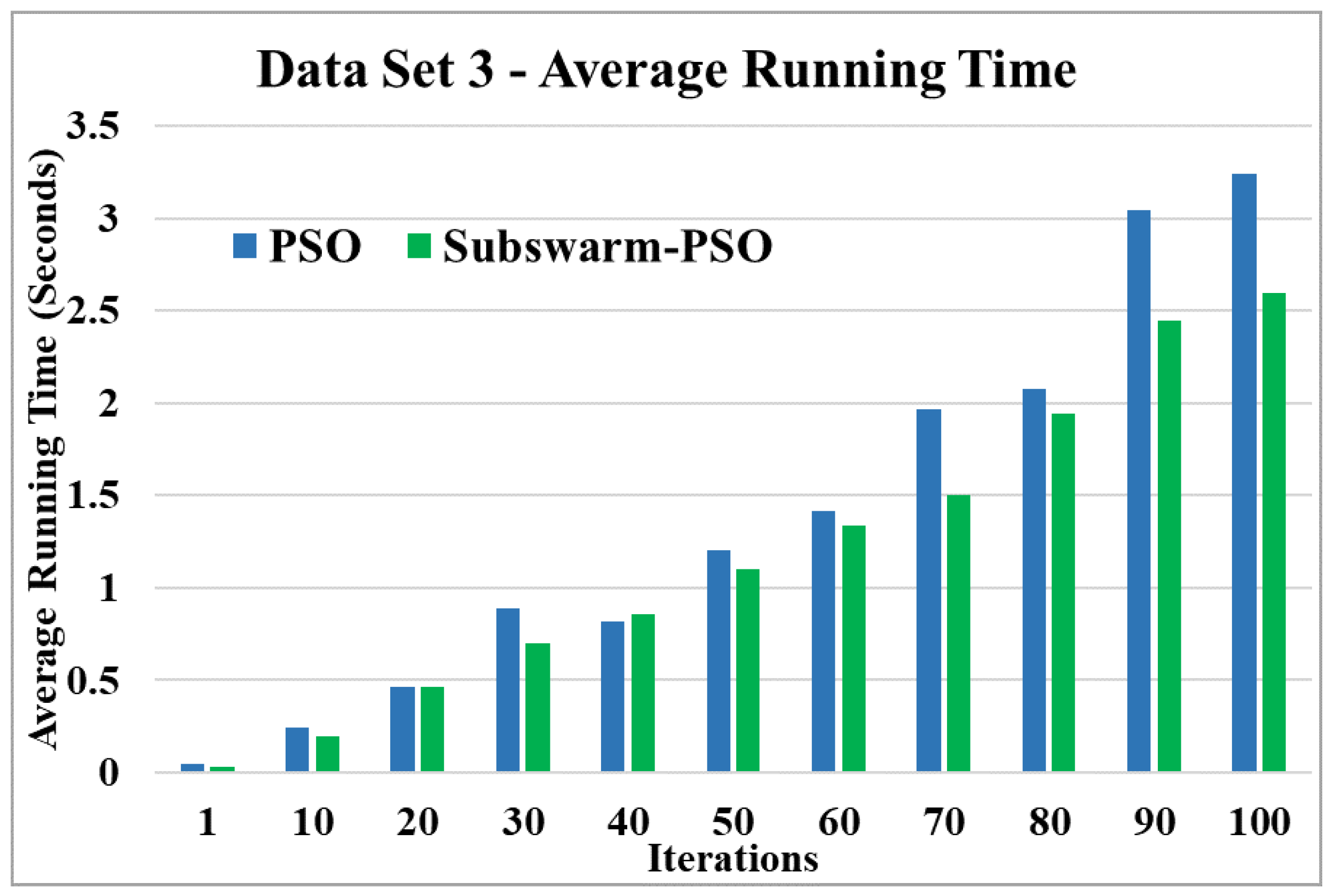
Average running time for data set 3.
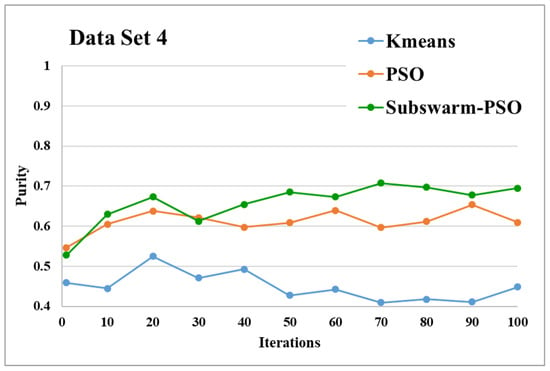
Figure 11.
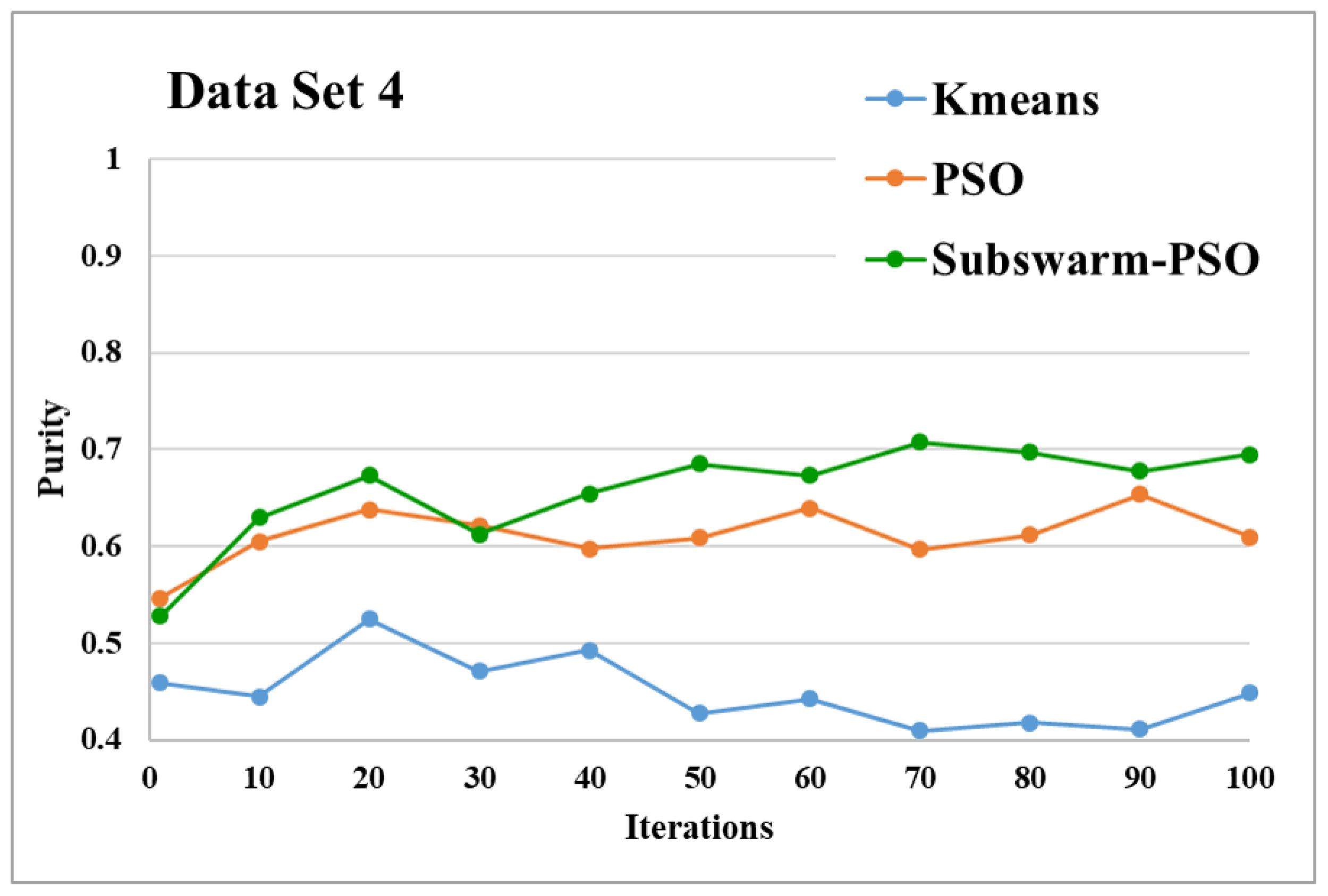
Purity comparison for data set 4.
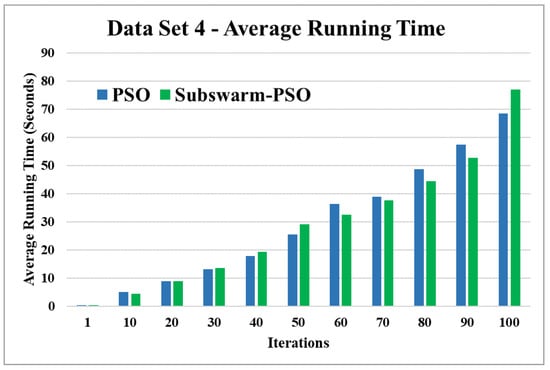
Figure 12.
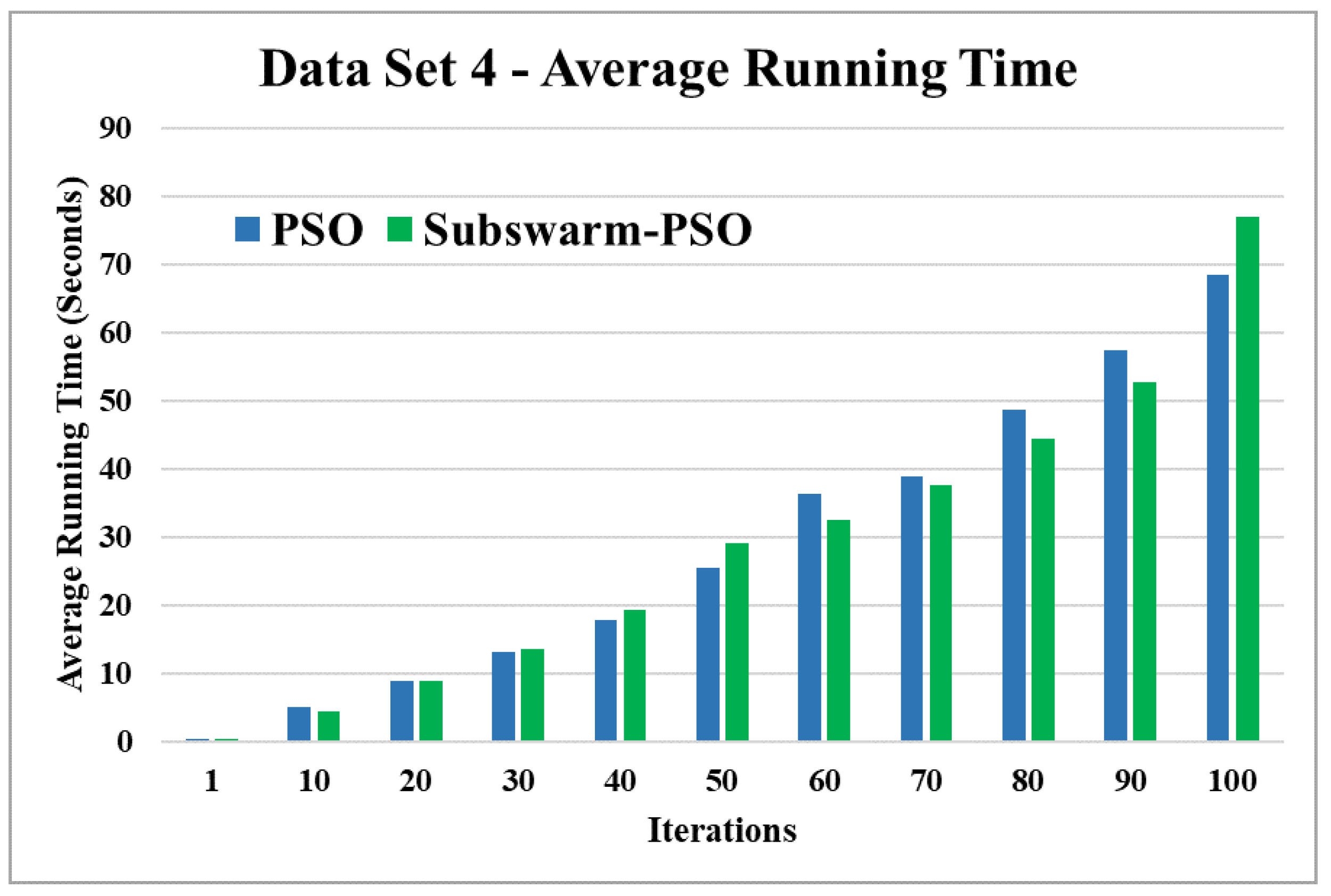
Average running time for data set 4.
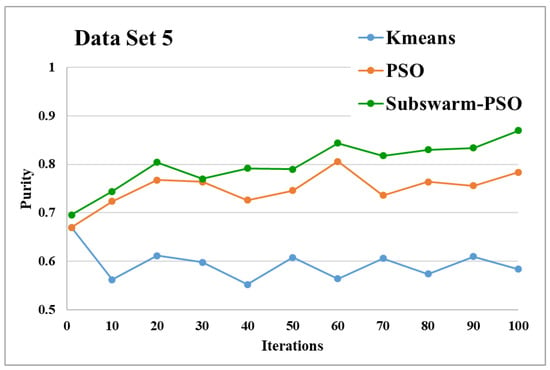
Figure 13.
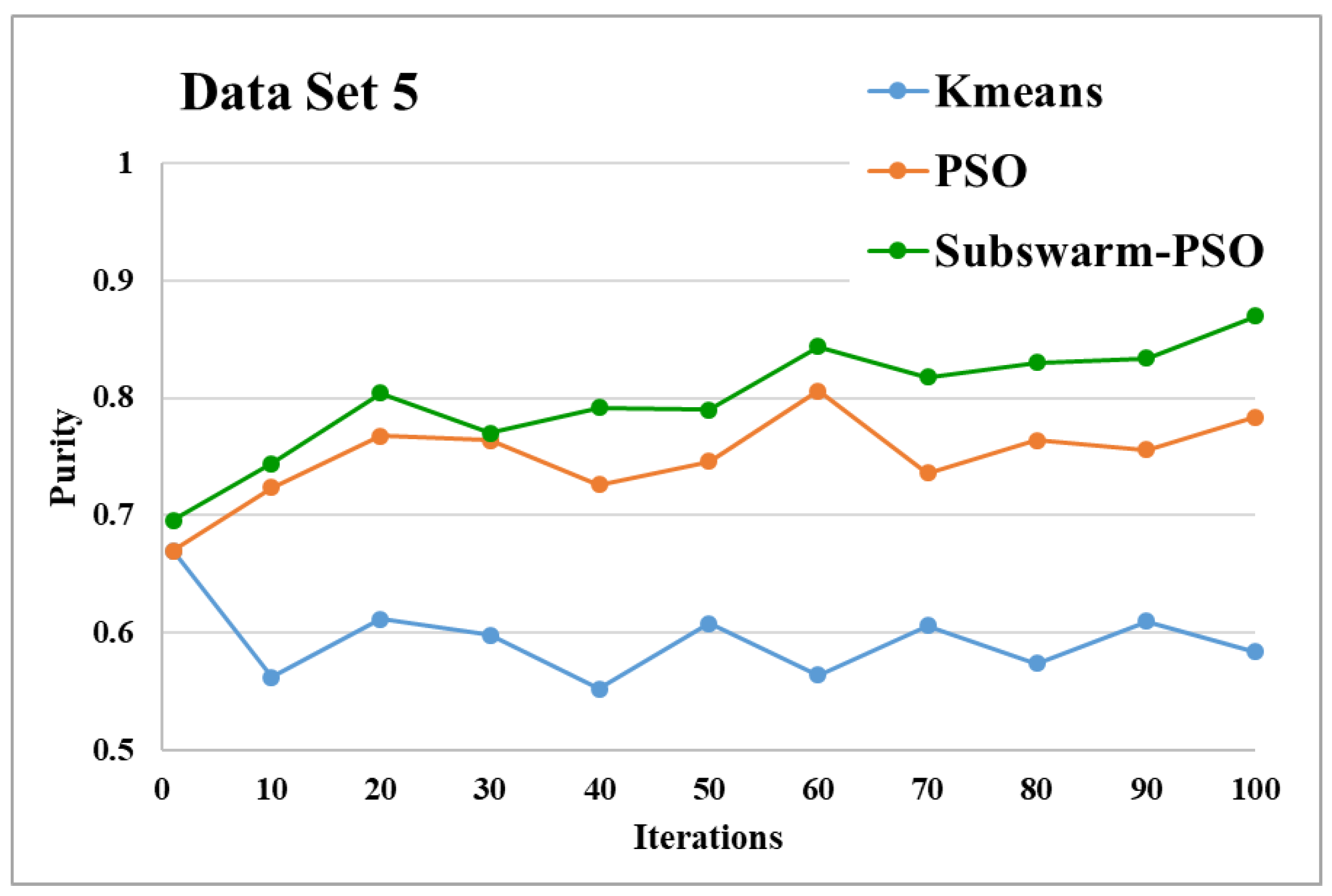
Purity comparison for data set 5.
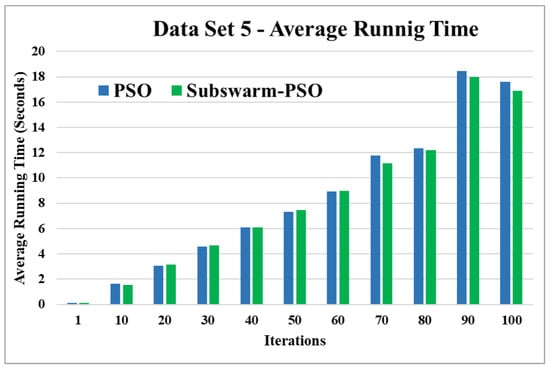
Figure 14.
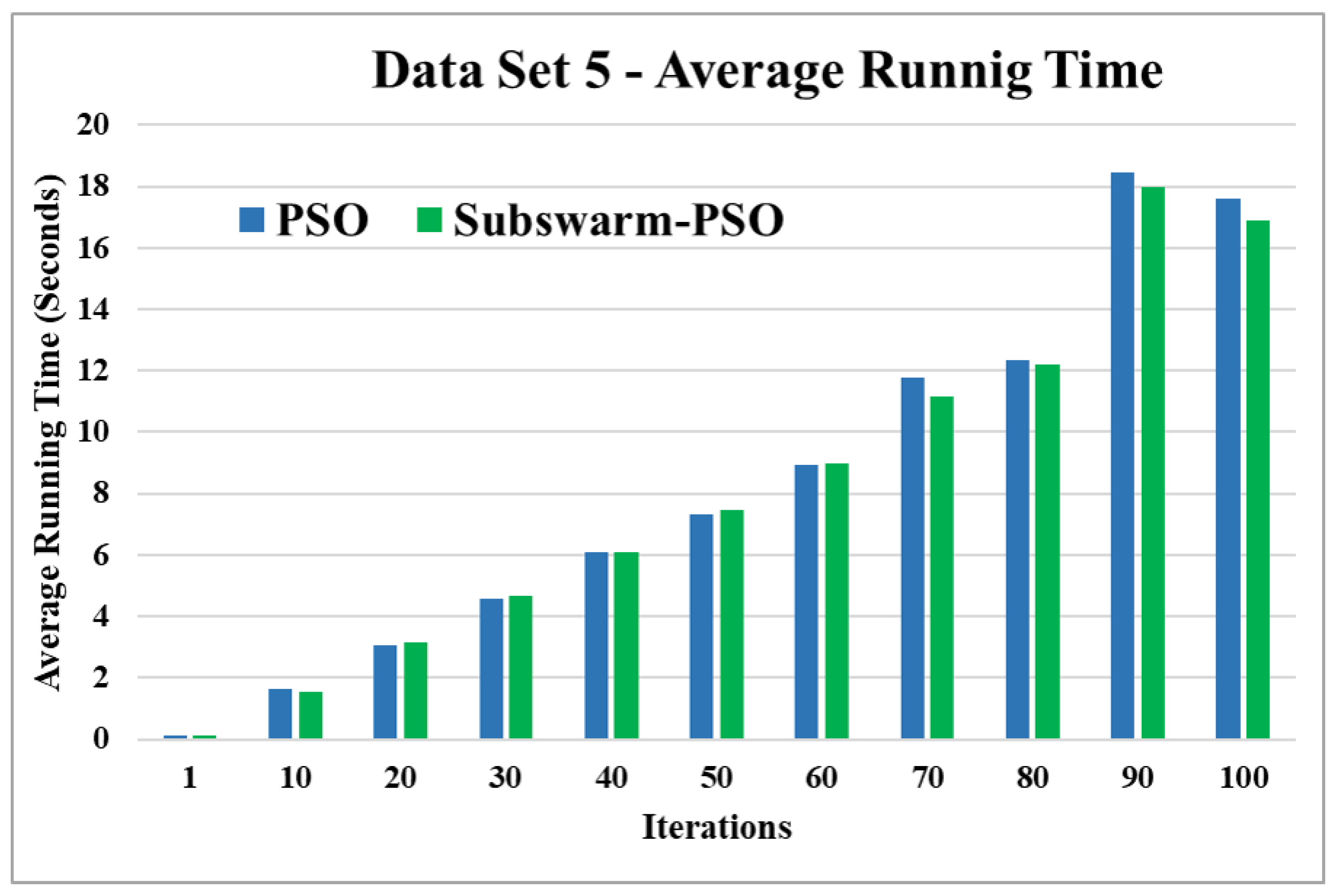
Average running time for data set 5.
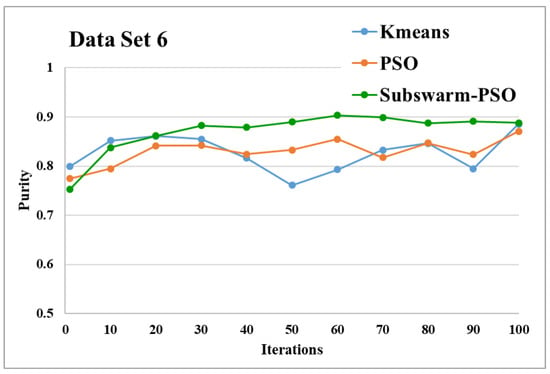
Figure 15.
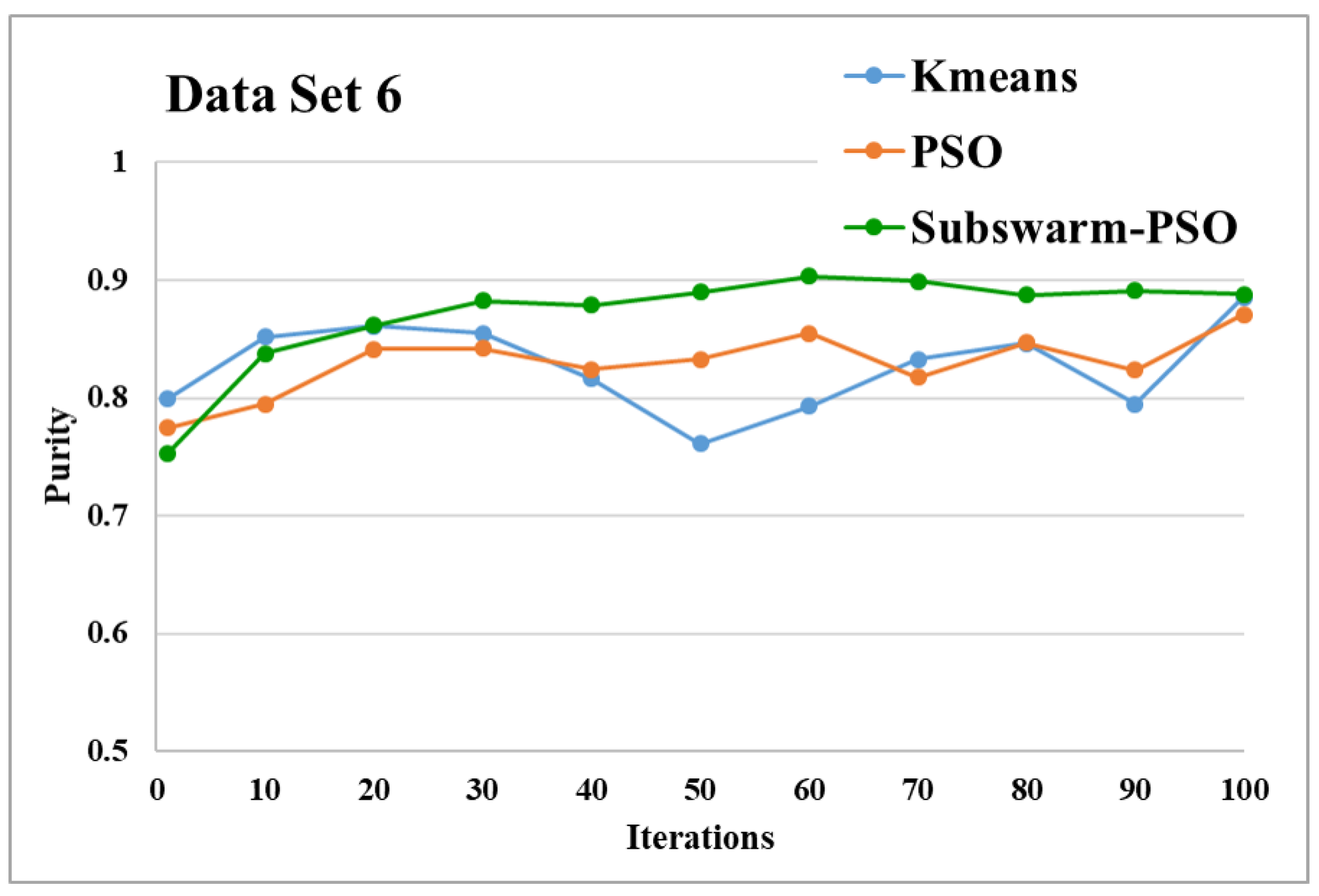
Purity comparison for data set 6.
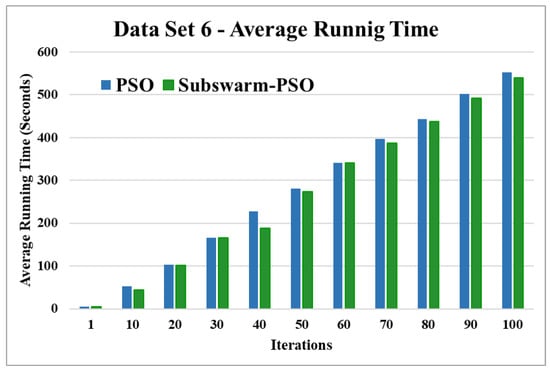
Figure 16.
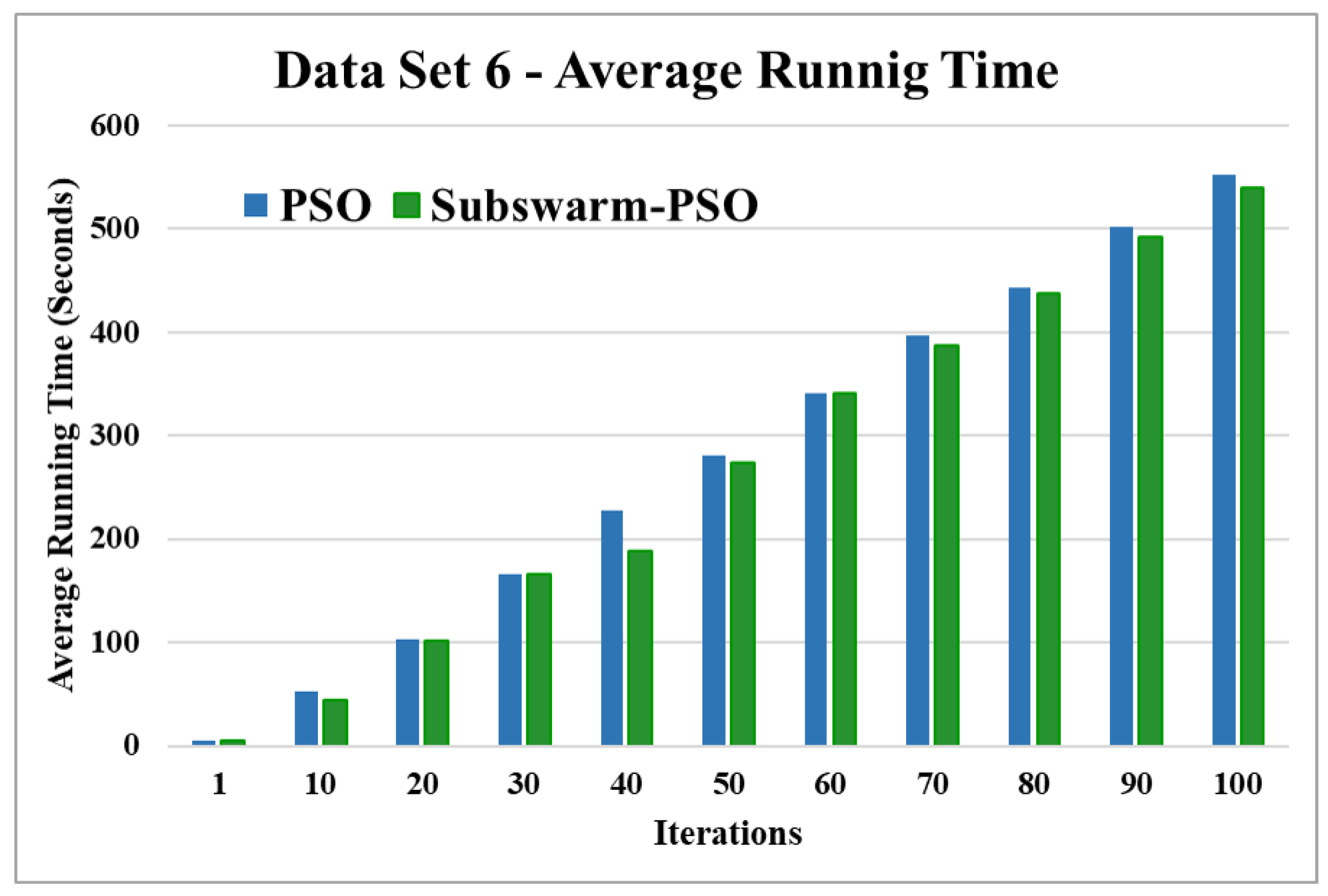
Average running time for data set 6.
Figure 5 shows the comparative results of the proposed algorithm subswarm-PSO with all other algorithms for data set 1. Here, the result shows that the proposed algorithm shows the best performance than other algorithms and the algorithm PSO is performing second. K-means is the lowest-performing algorithm. Figure 6 compares the average execution time of PSO and subswarm-PSO for the results of Figure 5 and Table 5. Here, the proposed algorithm subswarm-PSO takes less time than PSO for the execution on average.
Figure 7 shows the comparative results and Figure 8 show the average execution time of the proposed subswarm-PSO algorithm with other algorithms for the data set 2. From Figure 7 we can see that comparing other algorithms, K-means is performing well. However, our proposed algorithm subswarm-PSO shows a second better performance than PSO algorithms. On average our proposed algorithm subswarm-PSO takes less time for the execution than PSO as shown in Figure 8.
Figure 9 and Figure 10 show the comparative results and average running time respectively for all algorithms for data set 3. Figure 9 and Table 5 show that our proposed subswarm-PSO algorithm shows the highest purity. The PSO algorithm performs second. Here, the K-means algorithm shows the least performance. Figure 10 shows that subswarm-PSO takes less execution time than PSO.
Figure 11 and Figure 12 are the comparative results and average running time respectively of all algorithms for data set 4. From Figure 11 and Table 5, we can say that the proposed subswarm-PSO shows the highest performance, and the PSO algorithm performs second. K-means shows the least performance for dataset 4. Figure 12 shows similar results that subswarm-PSO take little less execution time than PSO.
Figure 13 and Figure 14 are the comparative results and average running time respectively of all algorithms for data set 5. Figure 13 shows that subswarm-PSO, PSO, and K-means algorithms perform first, second, and third respectively. Here, similarly to other data sets subswarm-PSO takes less execution time than PSO.
Figure 15 and Figure 16 are the comparative results and average running time respectively of all algorithms for data set 6. Figure 15 shows that subswarm-PSO, PSO, and K-means algorithms perform first, second, and third respectively. Here, the algorithm subswarm-PSO takes less time for execution than PSO as shown in Figure 16.
8.3. Discussion
Based on the above results, we can say that the proposed algorithm subswarm-PSO is performing best to find the optimal solution for most of the data sets by comparing standard PSO and K-means algorithms in text document clustering. The average running times of this proposed subswarm-PSO algorithm are , , , , , and lesser than the standard PSO algorithm for data sets 1, 2, 3, 4, 5, and 6 respectively. The K-means is much faster than other algorithms but it shows the very least optimum solutions for all data sets except data set 2.
The standard PSO algorithm has more ability to solve complex optimization problems such as text document clustering but is usually trapped into the local optimum. Our proposed algorithm ignores half of the least solutions and reinitializes the particles which include the least solution in each iteration. This proposed approach increases the global search capability of PSO and enhances the performance of the PSO algorithm. During each iteration, only half of the particles which include the best solutions are moved to the next solution, and others are reinitialized randomly. Random initialization takes less time compared with updating particles to the next position. This might be the reason for the reduced execution time of our proposed algorithm.
In our proposed method, we choose half of the particles with the least solution to abandon based on the results from Table 3 and Table 4. Comparing the standard PSO with other different numbers of abandoned solutions, this half and nearly half and are showing better performance. While choosing , it may be balanced well to retain the top half of good solutions to move towards the global best solution and use the remaining half of the particles to explore the new solution. Here, if we reduce the number of abandoned particles to , the global search capability may be reduced, and if increase the number of abandoned particles to more than , may be distracted from moving toward the global best solution. This might be the reason for the abandoned particles performing well.
9. Conclusions
The standard PSO algorithm is more effectively solving complex problems like text document clustering compared with other standard SI algorithms and traditional K-means algorithms. Still, PSO needs to be improved to avoid the problems such as premature convergence and local optima. In this study, we propose a subswarm-PSO algorithm to increase the global search capabilities of PSO and avoid the local optimum to improve the results for text document clustering. Our proposed algorithm is to select potential solutions and re-initialize particles dynamically. Out of a number of experimental observations, selecting half of the best solutions in each iteration has provided performance achievement. The results of this proposed approach were compared with the standard PSO algorithm and the K-means algorithm. Here, evaluation metric purity is used with six benchmark data sets. The experimental results show that our proposed algorithm subswarm-PSO performs best and uses less execution time than the standard PSO algorithm. Previous literature shows that the PSO is also performing well in a few other problems such as clustering, feature selection, and scheduling [18]. Our proposed approach also may perform well in those problems as the PSO algorithm. As a future study, we are aiming to apply and check the performance of the proposed subswarm-PSO approach in different domains.
Author Contributions
Conceptualization, S.S. and E.C.; methodology, S.S. and E.C.; software, S.S.; writing—original draft preparation, S.S.; writing—review and editing, E.C.; project administration, E.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the BK21 FOUR (Fostering Outstanding Universities for Research) 5120200213791, funded by the Ministry of Education (MOE, Korea) and the National Research Foundation of Korea (NRF).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
We thank the Global Scholarship Program for Foreign Graduate Students at Kookmin University, Korea, for its support.
Conflicts of Interest
The authors declare no conflict of interest.
Nomenclature
The below list describes the symbols that are used in this paper:
| d | Number of documents |
| t | Number of unique terms in the document collection |
| N | Number of properly assigned documents in the cluster |
| C | Set of classes |
| Element of the class C in position j | |
| W | Set of clusters |
| Element of the cluster W in position k | |
| k | Number of clusters |
| n | Population of Algorithms |
| P | Set of particles in the PSO algorithm |
| X | Set of particles’ position in the PSO algorithm |
| V | Set of particles’ velocities in the PSO algorithm |
| x | Position of a particle in the PSO algorithm |
| v | Velocity of each particle in the PSO algorithm |
| Global best solution in the PSO algorithm | |
| Personal best solutions in the PSO algorithm | |
| Random parameters within the range [0,1] | |
| Constant values in PSO algorithm | |
| Subset of particles P with least solutions in PSO | |
| Subset of particles P with best solutions in PSO | |
| Inertia weight |
References
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. A new feature selection method to improve the document clustering using particle swarm optimization algorithm. J. Comput. Sci. 2018, 25, 456–466. [Google Scholar] [CrossRef]
- Selvaraj, S.; Kim, H.; Choi, E. Offline-to-Online Service and Big Data Analysis for End-to-end Freight Management System. J. Inf. Process. Syst. 2020, 16, 377–393. [Google Scholar]
- Manning, C.D.; Raghavan, P.; Schutze, H. Introduction to Information Retrieval? Cambridge University Press: Cambridge, UK, 2008; Volume 20, pp. 405–416. [Google Scholar]
- Ramkumar, A.S.; Nethravathy, R. Text Document Clustering using K-means Algorithm. Int. Res. J. Eng. Technol. 2019, 6, 1164–1168. [Google Scholar]
- Hassanien, A.E. Swarm Intelligence: Principles, Advances, and Applications; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Selvaraj, S.; Choi, E. Survey of swarm intelligence algorithms. In Proceedings of the 3rd International Conference on Software Engineering and Information Management, Sydney, Australia, 12–15 January 2020; pp. 69–73. [Google Scholar]
- Salehizadeh, S.; Yadmellat, P.; Menhaj, M. Local Optima Avoidable Particle Swarm Optimization. In Proceedings of the 2009 IEEE Swarm Intelligence Symposium, Washington, DC, USA, 2–4 November 2009; pp. 16–21. [Google Scholar] [CrossRef]
- Mei, C.; Liu, G.; Xiao, X. Improved particle swarm optimization algorithm and its global convergence analysis. In Proceedings of the 2010 Chinese Control and Decision Conference, Xuzhou, China, 26–28 May 2010; pp. 1662–1667. [Google Scholar] [CrossRef]
- BBC News Datasets. Available online: http://mlg.ucd.ie/datasets/bbc.html (accessed on 12 November 2022).
- 20 Newsgroups. Available online: https://kdd.ics.uci.edu/databases/20newsgroups/20newsgroups.html (accessed on 12 November 2022).
- Scientific Papers. Available online: https://github.com/mayarachew/compscience_papers (accessed on 12 November 2022).
- Liang, J.J.; Suganthan, P.N. Dynamic multi-swarm particle swarm optimizer. In Proceedings of the 2005 IEEE Swarm Intelligence Symposium, Pasadena, CA, USA, 8–10 June 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 124–129. [Google Scholar]
- Xu, Y.; Chen, G.; Yu, J. Three Sub-Swarm Discrete Particle Swarm Optimization Algorithm. In Proceedings of the 2006 IEEE International Conference on Information Acquisition, Taichung, Taiwan, 5–7 June 2006; pp. 1224–1228. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, G.; Chen, H.; Dong, H.; Zhu, X.; Wang, S. An improved particle swarm optimization for feature selection. J. Bionic Eng. 2011, 8, 191–200. [Google Scholar] [CrossRef]
- Ye, W.; Feng, W.; Fan, S. A novel multi-swarm particle swarm optimization with dynamic learning strategy. Appl. Soft Comput. 2017, 61, 832–843. [Google Scholar] [CrossRef]
- Qiu, C. A novel multi-swarm particle swarm optimization for feature selection. Genet. Program. Evolvable Mach. 2019, 20, 503–529. [Google Scholar] [CrossRef]
- Xia, X.; Tang, Y.; Wei, B.; Zhang, Y.; Gui, L.; Li, X. Dynamic multi-swarm global particle swarm optimization. Computing 2020, 102, 1587–1626. [Google Scholar] [CrossRef]
- Selvaraj, S.; Choi, E. Swarm Intelligence Algorithms in Text Document Clustering with Various Benchmarks. Sensors 2021, 21, 3196. [Google Scholar] [CrossRef] [PubMed]
- Karol, S.; Mangat, V. Evaluation of text document clustering approach based on particle swarm optimization. Open Comput. Sci. 2013, 3, 69–90. [Google Scholar] [CrossRef]
- Purity Metric. Available online: http://www.cse.chalmers.se/~richajo/dit862/L13/Text%20clustering.html (accessed on 12 November 2022).
- Cui, X.; Potok, T.E.; Palathingal, P. Document clustering using particle swarm optimization. In Proceedings of the 2005 IEEE Swarm Intelligence Symposium, Pasadena, CA, USA, 8–10 June 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 185–191. [Google Scholar]
- PSO Code. Available online: https://github.com/dandynaufaldi/particle-swarm-optimized-clustering (accessed on 12 November 2022).
- Afzali, M.; Kumar, S. Text Document Clustering: Issues and Challenges. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 263–268. [Google Scholar] [CrossRef]
- Paulovich, F.V.; Nonato, L.G.; Minghim, R.; Levkowitz, H. Least Square Projection: A Fast High-Precision Multidimensional Projection Technique and Its Application to Document Mapping. IEEE Trans. Vis. Comput. Graph. 2008, 14, 564–575. [Google Scholar] [CrossRef] [PubMed]
- PySwarms. Available online: https://pyswarms.readthedocs.io/en/latest/api/pyswarms.single.html (accessed on 12 November 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).