
Exhaustive Search of Correspondences between Multimodal Remote Sensing Images Using Convolutional Neural Network





Abstract
:1. Introduction
2. Learned Similarity Measure for Multimatch Case
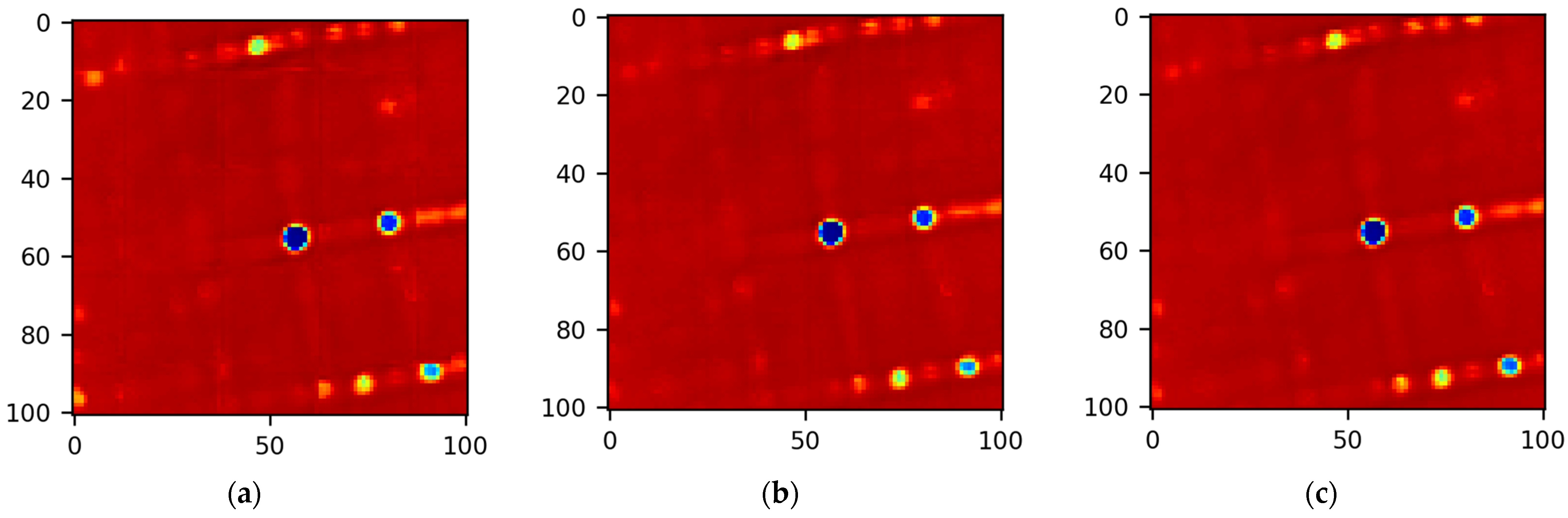
2.1. SM Map Structure and Translation Invariance Property
- Discrimination between the true and false matches;
- Subpixel accuracy of the true correspondence localization;
- Estimation of the accuracy of the match location, including anisotropic case;
- An “area” SM has additional requirements;
- Translation invariance;
- Plausible multiple match detection;
- Localization and localization accuracy characterizations for all detected matches.
2.2. DLSMarea Structure
2.3. Loss Function
2.3.1. Main Peak Term
2.3.2. Translation Invariance Term
2.3.3. Discrimination Loss Term
2.3.4. Rotation Loss Term
2.4. Multiple-Correspondence Detection
2.5. Training Details
3. Experimental Section
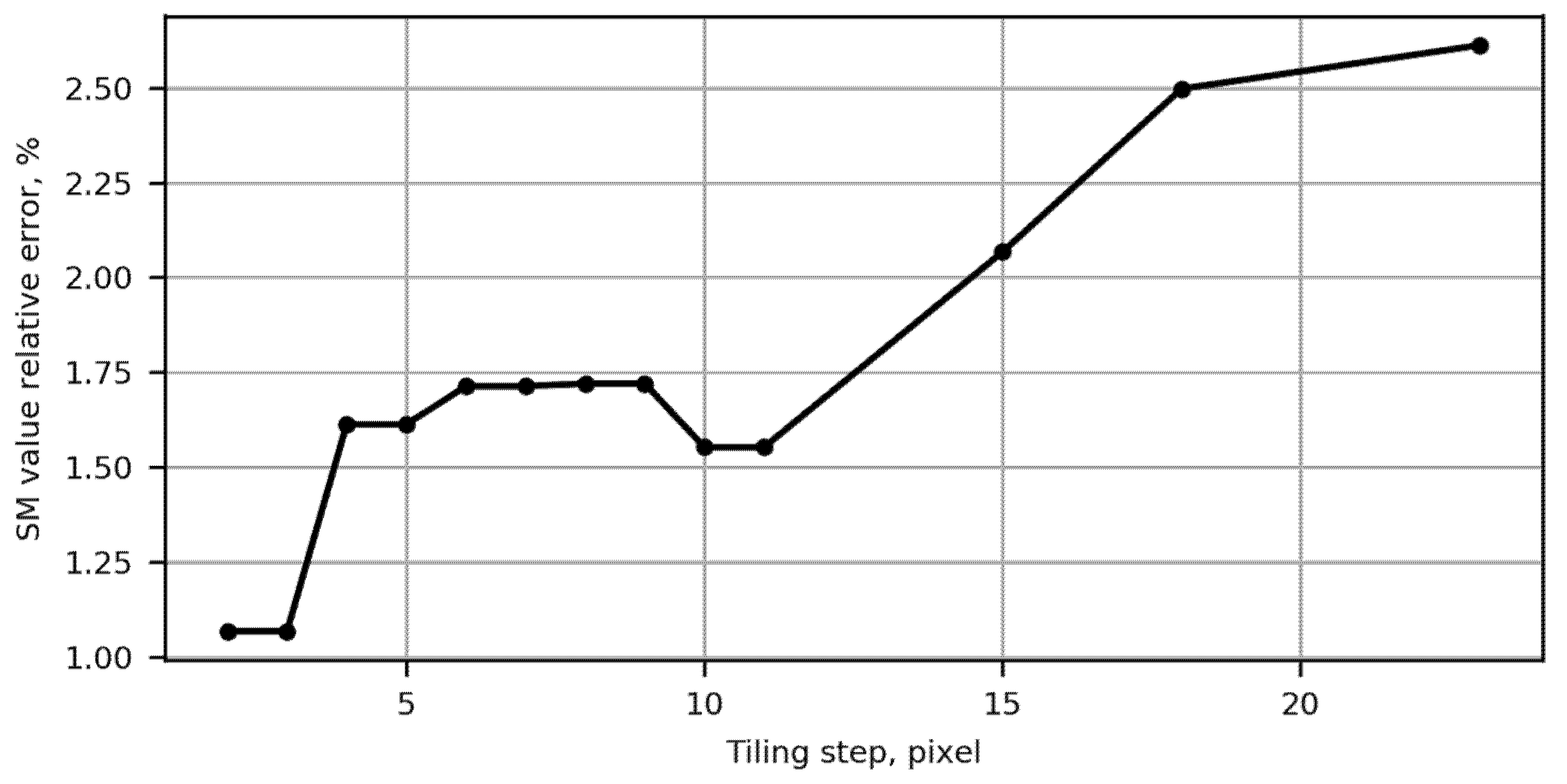
3.1. SM Spatial Properties: Tiling
3.2. Computational Efficiency
3.3. AUC Analysis
3.4. SM Map Comparative Analysis
3.5. Localization Accuracy
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goshtasby, A.; Le Moign, J. Image Registration: Principles, Tools and Methods; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Xiaolong, D.; Khorram, S. The effects of image misregistration on the accuracy of remotely sensed change detection. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1566–1577. [Google Scholar] [CrossRef] [Green Version]
- Holtkamp, D.J.; Goshtasby, A.A. Precision Registration and Mosaicking of Multicamera Images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3446–3455. [Google Scholar] [CrossRef]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.M.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.M.; Anders, K.; Gloaguen, R.; et al. Multisource and multitemporal data fusion in remote sensing a comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef] [Green Version]
- Ye, Y.; Shan, J.; Bruzzone, L.; Shen, L. Robust Registration of Multimodal Remote Sensing Images Based on Structural Similarity. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2941–2958. [Google Scholar] [CrossRef]
- Bürgmann, T.; Koppe, W.; Schmitt, M. Matching of TerraSAR-X derived ground control points to optical image patches using deep learning. ISPRS J. Photogramm. Remote Sens. 2019, 158, 241–248. [Google Scholar] [CrossRef]
- Zhang, H.; Lei, L.; Ni, W.; Tang, T.; Wu, J.; Xiang, D.; Kuang, G. Optical and SAR Image Matching Using Pixelwise Deep Dense Features. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Uss, M.L.; Vozel, B.; Lukin, V.V.; Chehdi, K. Multimodal Remote Sensing Image Registration With Accuracy Estimation at Local and Global Scales. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6587–6605. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Zhou, H.; Zhao, J.; Gao, Y.; Jiang, J.; Tian, J. Robust Feature Matching for Remote Sensing Image Registration via Locally Linear Transforming. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6469–6481. [Google Scholar] [CrossRef]
- Zitová, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef] [Green Version]
- Zbontar, J.; LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1592–1599. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient Deep Learning for Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5695–5703. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Hardmeier, H.; Sattler, T.; Pollefeys, M. Comparative Evaluation of Hand-Crafted and Learned Local Features. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1482–1491. [Google Scholar]
- Georgakis, G.; Karanam, S.; Wu, Z.; Ernst, J.; Kosecka, J. End-to-End Learning of Keypoint Detector and Descriptor for Pose Invariant 3D Matching. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1965–1973. [Google Scholar]
- Revaud, J.; Weinzaepfel, P.; Harchaoui, Z.; Schmid, C. DeepMatching: Hierarchical Deformable Dense Matching. Int. J. Comput. Vis. 2016, 120, 300–323. [Google Scholar] [CrossRef] [Green Version]
- Zhou, L.; Ye, Y.; Tang, T.; Nan, K.; Qin, Y. Robust Matching for SAR and Optical Images Using Multiscale Convolutional Gradient Features. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- YiK, M.; Trulls, E.; Ono, Y.; Lepetit, V.; Salzmann, M.; Fua, P. Learning to Find Good Correspondences. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Balakrishnan, G.; Zhao, A.; Sabuncu, M.R.; Dalca, A.V.; Guttag, J. An Unsupervised Learning Model for Deformable Medical Image Registration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9252–9260. [Google Scholar]
- Chen, Y.; Zhang, Q.; Zhang, W.; Chen, L. Bidirectional Symmetry Network with Dual-Field Cyclic Attention for Multi-Temporal Aerial Remote Sensing Image Registration. Symmetry 2021, 13, 1863. [Google Scholar] [CrossRef]
- Ye, Y.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and Robust Matching for Multimodal Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef] [Green Version]
- Gonçalves, H.; Corte-Real, L.; Gonçalves, J. Automatic Image Registration Through Image Segmentation and SIFT. IEEE Trans. Geosci. Remote Sens. 2011, 49, 2589–2600. [Google Scholar] [CrossRef] [Green Version]
- Fan, B.; Huo, C.; Pan, C.; Kong, Q. Registration of Optical and SAR Satellite Images by Exploring the Spatial Relationship of the Improved SIFT. IEEE Geosci. Remote Sens. Lett. 2013, 10, 657–661. [Google Scholar] [CrossRef] [Green Version]
- Gonçalves, H.; Gonçalves, J.A.; Corte-Real, L.; Teodoro, A.C. CHAIR: Automatic image registration based on correlation and Hough transform. Int. J. Remote Sens. 2012, 33, 7936–7968. [Google Scholar] [CrossRef]
- Laga, H.; Jospin, L.V.; Boussaid, F.; Bennamoun, M. A Survey on Deep Learning Techniques for Stereo-based Depth Estimation. arXiv 2020, arXiv:2006.02535. [Google Scholar] [CrossRef]
- Roche, A.; Malandain, G.; Pennec, X.; Ayache, N. The Correlation Ratio as a New Similarity Measure for Multimodal Image Registration: Medical Image Computing and Computer-Assisted Interventation—MICCAI’98; Springer: Berlin/Heidelberg, Germany, 1998; pp. 1115–1124. [Google Scholar]
- Heinrich, M.P.; Jenkinson, M.; Bhushan, M.; Matin, T.; Gleeson, F.V.; Brady, S.M.; Schnabel, J.A. MIND: Modality independent neighbourhood descriptor for multi-modal deformable registration. Med. Image Anal. 2012, 16, 1423–1435. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef]
- Zhang, W.; Kosecka, J. Generalized RANSAC Framework for Relaxed Correspondence Problems. In Proceedings of the Third International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT’06), Chapel Hill, NC, USA, 14–16 June 2006; pp. 854–860. [Google Scholar]
- Merkle, N.; Luo, W.; Auer, S.; Müller, R.; Urtasun, R. Exploiting Deep Matching and SAR Data for the Geo-Localization Accuracy Improvement of Optical Satellite Images. Remote Sens. 2017, 9, 586. [Google Scholar] [CrossRef] [Green Version]
- Hughes, L.H.; Marcos, D.; Lobry, S.; Tuia, D.; Schmitt, M. A deep learning framework for matching of SAR and optical imagery. ISPRS J. Photogramm. Remote Sens. 2020, 169, 166–179. [Google Scholar] [CrossRef]
- Uss, M.; Vozel, B.; Lukin, V.; Chehdi, K. Efficient Discrimination and Localization of Multimodal Remote Sensing Images Using CNN-Based Prediction of Localization Uncertainty. Remote Sens. 2020, 12, 703. [Google Scholar] [CrossRef] [Green Version]
- Suri, S.; Reinartz, P. Mutual-Information-Based Registration of TerraSAR-X and Ikonos Imagery in Urban Areas. IEEE Trans. Geosci. Remote Sens. 2010, 48, 939–949. [Google Scholar] [CrossRef]
- Suri, S.; Schwind, P.; Uhl, J.; Reinartz, P. Modifications in the SIFT operator for effective SAR image matching. Int. J. Image Data Fusion 2010, 1, 243–256. [Google Scholar] [CrossRef] [Green Version]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Uss, M.L.; Vozel, B.; Abramov, S.K.; Chehdi, K. Selection of a Similarity Measure Combination for a Wide Range of Multimodal Image Registration Cases. IEEE Trans. Geosci. Remote Sens. 2021, 59, 60–75. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yonglong, Z.; Kuizhi, M.; Xiang, J.; Peixiang, D. Parallelization and Optimization of SIFT on GPU Using CUDA. In Proceedings of the 2013 IEEE 10th International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, Zhangjiajie, China, 13–15 November 2013; pp. 1351–1358. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Requirement | ||||
|---|---|---|---|---|
| Translation invariance | - | - | + | - |
| Detection of multiple matches | - | - | + | - |
| Subpixel accuracy of the main lobe localization without the need for intensity or SM interpolation | + | - | - | - |
| Estimation of the accuracy of lobe localization, including anisotropic case | + | - | - | + |
| Discrimination between the main and false matches | - | + | - | - |
| Method | General | Optical-to-DEM | Optical-to-Optical | Optical-to-Radar | Radar-to-DEM |
|---|---|---|---|---|---|
| NCC | 61.50 | 54.54 | 59.57 | 70.18 | 62.12 |
| MI | 59.23 | 57.05 | 68.40 | 63.84 | 54.92 |
| SIFT-OCT | 65.69 | 59.13 | 65.79 | 73.60 | 67.71 |
| MIND | 72.56 | 68.88 | 85.37 | 70.98 | 64.52 |
| DLSM | 83.86 | 80.00 | 88.49 | 83.23 | 81.95 |
| DLSMarea17 | 84.39 | 82.10 | 90.14 | 80.20 | 82.90 |
| DLSMarea25 | 86.37 | 84.23 | 91.98 | 83.17 | 85.85 |
| DLSMarea33 | 86.87 | 83.98 | 92.41 | 84.58 | 87.81 |
| DLSMarea41 | 84.32 | 80.79 | 88.81 | 80.43 | 86.86 |
| DLSMarea49 | 86.05 | 83.10 | 91.89 | 83.11 | 86.42 |
| DLSMarea57 | 85.14 | 84.05 | 90.70 | 82.30 | 83.61 |
| Method | Number of Pairs Localized with Subpixel Accuracy |
|---|---|
| DLSM | 1440 |
| DLSMarea17 | 2227 |
| DLSMarea25 | 2324 |
| DLSMarea33 | 2292 |
| DLSMarea41 | 1463 |
| DLSMarea49 | 2021 |
| DLSMarea57 | 2495 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uss, M.; Vozel, B.; Lukin, V.; Chehdi, K. Exhaustive Search of Correspondences between Multimodal Remote Sensing Images Using Convolutional Neural Network. Sensors 2022, 22, 1231. https://doi.org/10.3390/s22031231
Uss M, Vozel B, Lukin V, Chehdi K. Exhaustive Search of Correspondences between Multimodal Remote Sensing Images Using Convolutional Neural Network. Sensors. 2022; 22(3):1231. https://doi.org/10.3390/s22031231
Chicago/Turabian StyleUss, Mykhail, Benoit Vozel, Vladimir Lukin, and Kacem Chehdi. 2022. "Exhaustive Search of Correspondences between Multimodal Remote Sensing Images Using Convolutional Neural Network" Sensors 22, no. 3: 1231. https://doi.org/10.3390/s22031231
APA StyleUss, M., Vozel, B., Lukin, V., & Chehdi, K. (2022). Exhaustive Search of Correspondences between Multimodal Remote Sensing Images Using Convolutional Neural Network. Sensors, 22(3), 1231. https://doi.org/10.3390/s22031231