
DOA Estimation Method Based on Improved Deep Convolutional Neural Network


Abstract
:1. Introduction
2. Signal Model
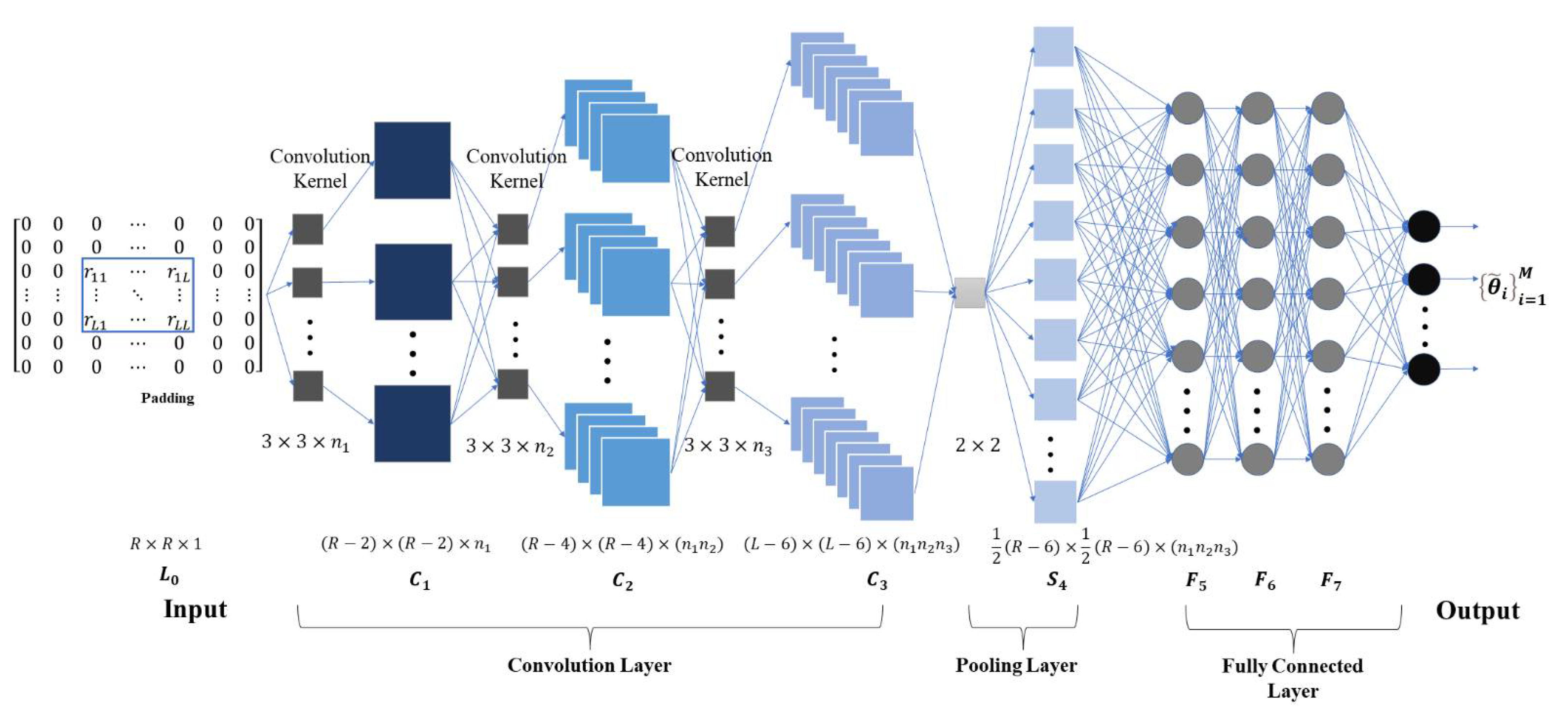
3. Deep Convolutional Neural Network Model
3.1. Forward Propagation Process
3.2. Error Backpropagation Process
4. Simulation and Result Analysis
4.1. Determination of Discrete Angle Interval
4.2. Effect of the Number of Snapshots on the Performance of DOA Estimation
4.3. Effect of SNR on DOA Estimation Performance
4.4. Effect of Upper Triangular Array as Input on the Efficiency of Operation
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wirth, W.D. Radar Techniques Using Array Antennas, 2nd ed.; IET Digital Library: Hertfordshire, UK, 2013; pp. 49–70. [Google Scholar] [CrossRef]
- Yadav, S.; Wajid, M.; Usman, M. Support Vector Machine-Based Direction of Arrival Estimation with Uniform Linear Array. In Advances in Computational Intelligence Techniques; Jain, S., Sood, M., Paul, S., Eds.; Springer: Singapore, 2020; pp. 253–264. [Google Scholar] [CrossRef]
- Youngmin, C.; Yongsung, P.; Woojae, S. Detection of Direction-Of-Arrival in Time Domain Using Compressive Time Delay Estimation with Single and Multiple Measurements. Sensors 2020, 20, 5431. [Google Scholar] [CrossRef]
- Siwen, Y. Design and Analysis Of Pattern Null Reconfigurable Antennas, University of Illinois at Urbana-Champaign, 1201 W; University Avenue: Urbana, IL, USA, 2012. [Google Scholar]
- Rossi, M.; Haimovich, A.M.; Eldar, C. Spatial Compressive Sensing for MIMO Radar. IEEE Trans. Signal Process 2013, 62, 419–430. [Google Scholar] [CrossRef] [Green Version]
- Hassanien, A.; Shahbazpanahi, S.; Gershman, A.B. A Generalized Capon Estimator for Localization of Multiple Spread Sources. IEEE Trans. Signal Process 2004, 52, 280–283. [Google Scholar] [CrossRef]
- Schmidt, R.; Schmidt, R.O. Multiple emitter location and signal parameter estimation. Trans. Antennas Propagat 1986, 34, 276–280. [Google Scholar] [CrossRef] [Green Version]
- Roy, R.; Kailath, T. ESPRIT-Estimation of Signal Parameters via Rotational Invariance Techniques. IEEE Trans. Acoust. Speech Signal Processing 1989, 37, 984–995. [Google Scholar] [CrossRef] [Green Version]
- Ziskind, M. Wax, Maximum likelihood localization of multiple sources by alternating projection. IEEE Trans. Acoust. Speech. Signal Processing 1988, 36, 1553–1560. [Google Scholar] [CrossRef]
- Heidenreich, P.; Abdelhak, M. Superfast Maximum Likelihood DOA Estimation in the Two-Target Case with Applications to Automotive Radar. Signal Process 2013, 93, 3400–3409. [Google Scholar] [CrossRef]
- Viberg, M.; Ottersten, B. Detection and estimation in sensor arrays using weighted subspace fitting. IEEE Trans. Signal Process 1991, 39, 2436–2449. [Google Scholar] [CrossRef]
- Wax, M.; Adler, A. Detection of the Number of Signals by Signal Subspace Matching. IEEE Trans. Signal Process 2021, 69, 973–985. [Google Scholar] [CrossRef]
- Zheng, C.; Chen, H.; Wang, A. Sparsity-Aware Noise Subspace Fitting for DOA Estimation. Sensors 2020, 20, 81. [Google Scholar] [CrossRef] [Green Version]
- Hu, B.; Liu, M. DOA Robust Estimation of Echo Signals Based on Deep Learning Networks with Multiple Type Illuminators of Opportunity. IEEE Access 2020, 8, 14809–14819. [Google Scholar] [CrossRef]
- Xiao, X.; Zhao, S.; Zhong, X.; Jones, D.L.; Chng, E.S.; Li, H. A Learning-Based Approach to Direction of Arrival Estimation in Noisy and Reverberant Environments. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 2814–2818. [Google Scholar] [CrossRef]
- Chakrabarty, S.; Habets, E.A.P. Broadband DOA Estimation Using Convolutional Neural Networks Trained With Noise Signals. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Roshani, M.; Sattari, M.A.; Ali, P.J.M.; Roshani, G.H.; Nazemi, B.; Corniani, E.; Nazemi, E. Application of GMDH neural network technique to improve measuring precision of a simplified photon attenuation based two-phase flowmeter. Flow Meas. Instrum. 2020, 75, 101804. [Google Scholar] [CrossRef]
- Xiang, H.; Chen, B.; Yang, T. Phase enhancement model based on supervised convolutional neural network for coherent DOA estimation. Appl. Intell. 2020, 50, 2411–2422. [Google Scholar] [CrossRef]
- Koep, N.; Behboodi, A.; Mathar, R. An Introduction to Compressed Sensing. In Compressed Sensing and Its Applications. Applied and Numerical Harmonic Analysis; Boche, H., Caire, G., Calderbank, R., Kutyniok, G., Mathar, R., Petersen, P., Eds.; Birkhäuser: Cham, IL, USA, 2019; pp. 1–65. [Google Scholar] [CrossRef]
- Ketkar, N.; Moolayil, J. Convolutional Neural Networks. In Deep Learning with Python; Apress: Berkeley, CA, USA, 2021; pp. 197–242. [Google Scholar] [CrossRef]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, Long Short-Term Memory, fully connected Deep Neural Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar] [CrossRef]
- Du, K.L.; Swamy, M.N.S. Multilayer Perceptrons: Architecture and Error Backpropagation. In Neural Networks and Statistical Learning; Springer: London, UK, 2014; pp. 83–126. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Array Elements | 6 | 8 | 10 | 12 |
|---|---|---|---|---|
| Triu matrix | 0.0873 | 0.0864 | 0.0852 | 0.0835 |
| Matrix | 0.0882 | 0.0857 | 0.0844 | 0.0837 |
| Number | C1 | C2 | C3 | P1 | SUM | |
|---|---|---|---|---|---|---|
| 6 | Triu | 432 | 3024 | 8640 | 2592 | 14,688 |
| Matrix | 768 | 5184 | 13,824 | 3456 | 23,232 | |
| 8 | Triu | 660 | 5184 | 18,144 | 5184 | 29,172 |
| Matrix | 1200 | 9216 | 31,104 | 7776 | 49,296 | |
| 10 | Triu | 936 | 7920 | 31,104 | 8640 | 48,600 |
| Matrix | 1728 | 14,400 | 55,296 | 13,824 | 85,248 | |
| 12 | Triu | 1260 | 11,232 | 47,520 | 18,144 | 78,156 |
| Matrix | 2376 | 20,736 | 86,400 | 31,104 | 140,616 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, F.; Hu, G.; Zhan, C.; Zhang, Y. DOA Estimation Method Based on Improved Deep Convolutional Neural Network. Sensors 2022, 22, 1305. https://doi.org/10.3390/s22041305
Zhao F, Hu G, Zhan C, Zhang Y. DOA Estimation Method Based on Improved Deep Convolutional Neural Network. Sensors. 2022; 22(4):1305. https://doi.org/10.3390/s22041305
Chicago/Turabian StyleZhao, Fangzheng, Guoping Hu, Chenghong Zhan, and Yule Zhang. 2022. "DOA Estimation Method Based on Improved Deep Convolutional Neural Network" Sensors 22, no. 4: 1305. https://doi.org/10.3390/s22041305