1. Introduction
The control and monitoring of industrial processes require special attention because of their complexity, which is the result of the sub-processes and the multiple variables involved that need to be considered to know the current state of the general process. Regarding systems that make use of structures, the use of structural health monitoring (SHM) systems allows the proper monitoring of variables in the decision-making process, allowing better knowledge of the behavior of the structure and providing tools for maintaining tasks [
1]. In an SHM system, some elements are required, such as the use of sensors permanently installed in the structure, a data acquisition system for sensing/actuating over the structure, a signal conditioning step, the development of statistical models and the possibility of a decision-making process [
2]. This last element can be developed by computational tools in an autonomous way or by the analysis obtained from the statistical models. The literature includes multiple examples of developed monitoring systems and applications in different kinds of structures, such as those used in aircraft [
3,
4,
5], buildings [
6,
7], bridges [
8,
9] and furnaces [
10,
11], among others.
Concerning furnace monitoring as used in smelting processes, the number of variables and the influence on the process is highly significant. As an example, in the case of the ferronickel production industry, this process can be performed in an electric arc furnace (EAF) [
12] and the structural health monitoring (SHM) of the system requires the monitoring of several parts. The refractory hearth lining of an EAF is a crucial part to improve the campaign life of the furnace [
13]. The lining monitoring variables comprise temperature, heat fluxes, water quality, remaining thickness refractory, sidewall erosion and protective layer formation, among others [
14]. However, the development of temperature lining prediction models in an EAF is still an open research field because of the reduced number of works in this area [
15,
16].
Recently, the use of deep learning models has spread due to the data availability and their success rates in classification and regression tasks in minerals processing [
17]. In addition, the success of deep learning models is based on their capacity for extracting features, improving the data-driven models in terms of accuracy and efficiency; moreover, the big data coming from a sensor network allow large-scale training based on deep learning models [
18].
Cerro Matoso S.A. (CMSA) is one of the world’s major producers of ferronickel and it is operated by South32. This is an open-cut mine operation in Northern Colombia, /textcolorbluewith nearly 40 years of operation in the region. More details about the process developed by CMSA can be found directly on its web page
https://www.cerromatoso.com.co/ (accessed on 10 January 2022 ). The complex process of produce ferronickel in the EAF of (CMSA) involves a number of variables. In this work, the lining temperature in an EAF is predicted using a multivariate time series deep learning model. The developed model is able to handle the multiple input variables as well as predict multiple thermocouple output variables. The time series approach was selected in order to process variable-length sequences of inputs. This kind of model can use recurrent neural networks (RNN) to handle the temporal dynamic behavior of the data. The long-term dependency of the temperature predictions in the EAF was compared using, first, a Long Short-Term Memory (LSTM) unit and, second, a Gated Recurrent Unit (GRU) approach [
19]. These kinds of cells are used in contrast with traditional RNN due to the capacity to handle the vanishing and exploding long-term gradient problems [
20]. The temporal information has been incorporated into deep learning models using different encoder architectures, such as convolutional neural networks (CNN), RNN and attention-based models [
21]. Attention models allow us to identify relevant parts in the input sequence data to improve the prediction behavior of the deep learning model in the target time series [
22,
23,
24].
The time series forecasting deep learning model is developed with data from a 75 MW shielded arc smelting furnace of CMSA [
25]. This furnace is instrumented with a large set of thermocouples radially distributed in the lining furnace. The cooling system in the furnace uses plate and waffle coolers [
26]. There are four levels of plate coolers radially distributed in 72 panels in the furnace.
The novelty of this work lies in the development of a time series forecasting deep learning model using an attention-based mechanism. This model takes into account as input variables different operation variables in the furnace, such as power, current, voltage, electrode position, amount of input material and chemistry composition. As output variables, 68 thermocouples radially distributed in the furnace lining were satisfactorily predicted at different forecast times in a range from 1 h to 6 h in the future.
The remainder of the paper is structured as follows.
Section 2 includes the theoretical background, where all methods are described, followed by the dataset for validation in
Section 3; then, the multivariate time series temperature forecasting model is described in
Section 4. Then, the results and discussion are shown in
Section 5, and, finally, the conclusions are included in the last section.
3. Dataset for Validation
Data used to train and validate the attention-based deep RNN model were obtained from a thermocouple sensor network located at the side-wall of an EAF in CMSA. Photography of the EAF side-wall is shown in
Figure 3. The EAF side-wall is composed of 72 radially distributed panels.
Figure 3 details a portion of the side-wall of 1 panel. The illustrated hoses carry water, which is used to cool the refractory walls of the EAF through the plate coolers (4 for each panel) and the waffle cooler (1 for each panel).
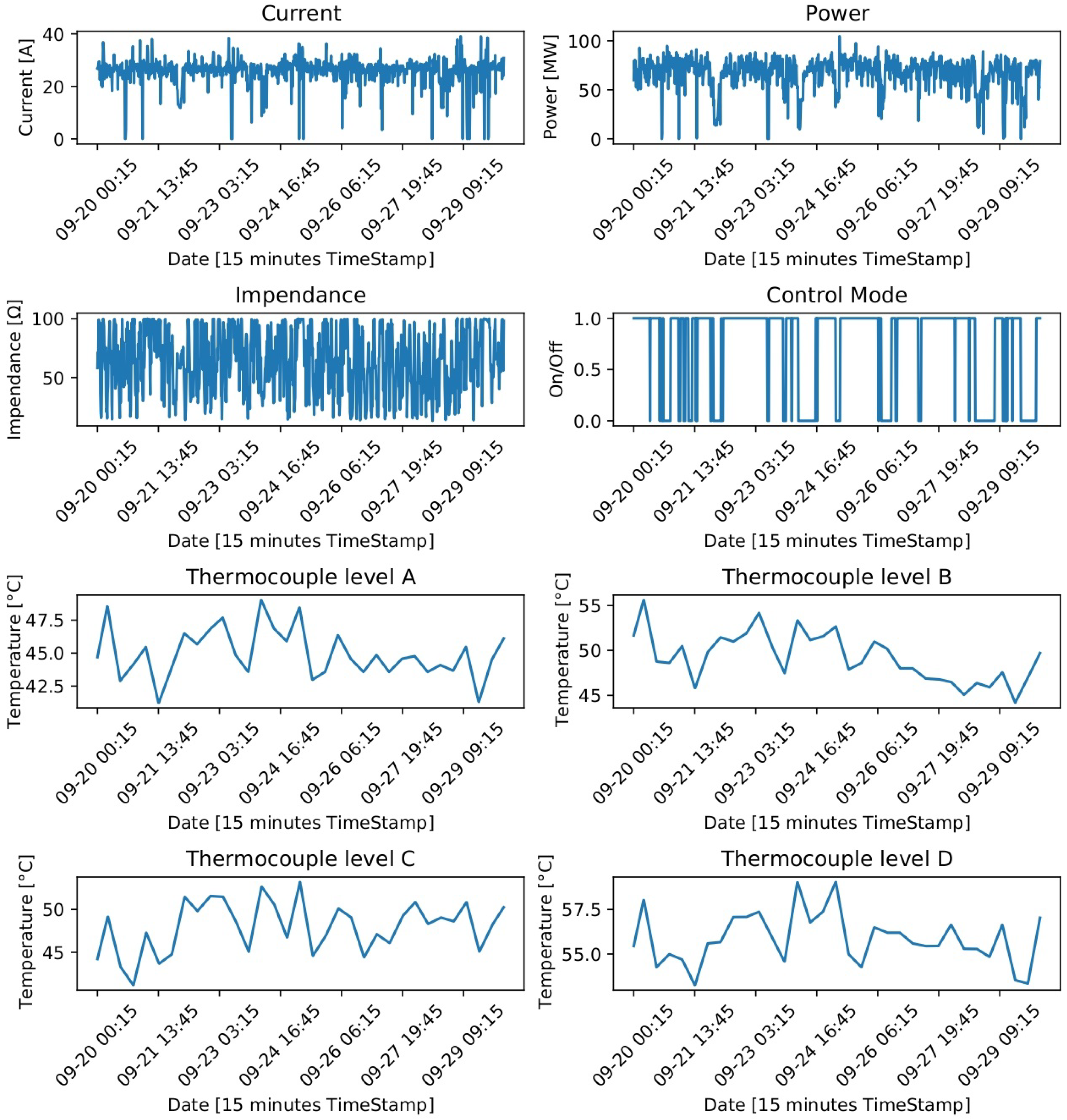
The dataset used for model training and validation is composed of data recorded during 5 years, with 177,312 instances and 49 attributes, from an EAF located in Cerro Matoso, South 32 company. Data were collected every 15 min during a period of 1847 days, from September 9th of 2016 to September 30th of 2021. The input variables in the model were related to electrode current, voltage, arc, power, calcine feed, the chemical composition of the calcine, relative electrode position and 16 thermocouples. These 16 thermocouples were also taken as output variables to predict. In particular, 4 panels radially distributed 90 degrees in each quadrant of the furnace were selected to study the behavior of their plate cooler thermocouples. Each of the selected 4 panels had 4 plate coolers; thus, a total of 16 plate coolers were analyzed. The behavior of the time series of some of these variables in a time window that allows the trend to be seen can be observed in
Figure 4.
Several data preprocessing steps were performed to detect abnormal behavior in the used variables. These data preprocessing steps are listed below [
32]:
Remove duplicates;
Treat empty and null values;
Treat unique values;
Encode strings;
Remove negative temperatures;
Eliminate variables with high variance;
Remove variables with zero variance.
After verifying the data preprocessing, it was concluded that the 49 variables used to train and test the models did not present abnormal behaviors.
5. Results and Discussion
Four deep neural network configurations corresponding to a GRU model and an LSTM model, with and without attention mechanisms, were designed, trained and tested, using 49 input variables to predict the 16 output variables corresponding to the thermocouple temperature. The Average Root Mean Square Error (RMSE) of these 16 output variables was used as a performance metric for each of the models.
5.1. Influence of Changing the Prediction Time
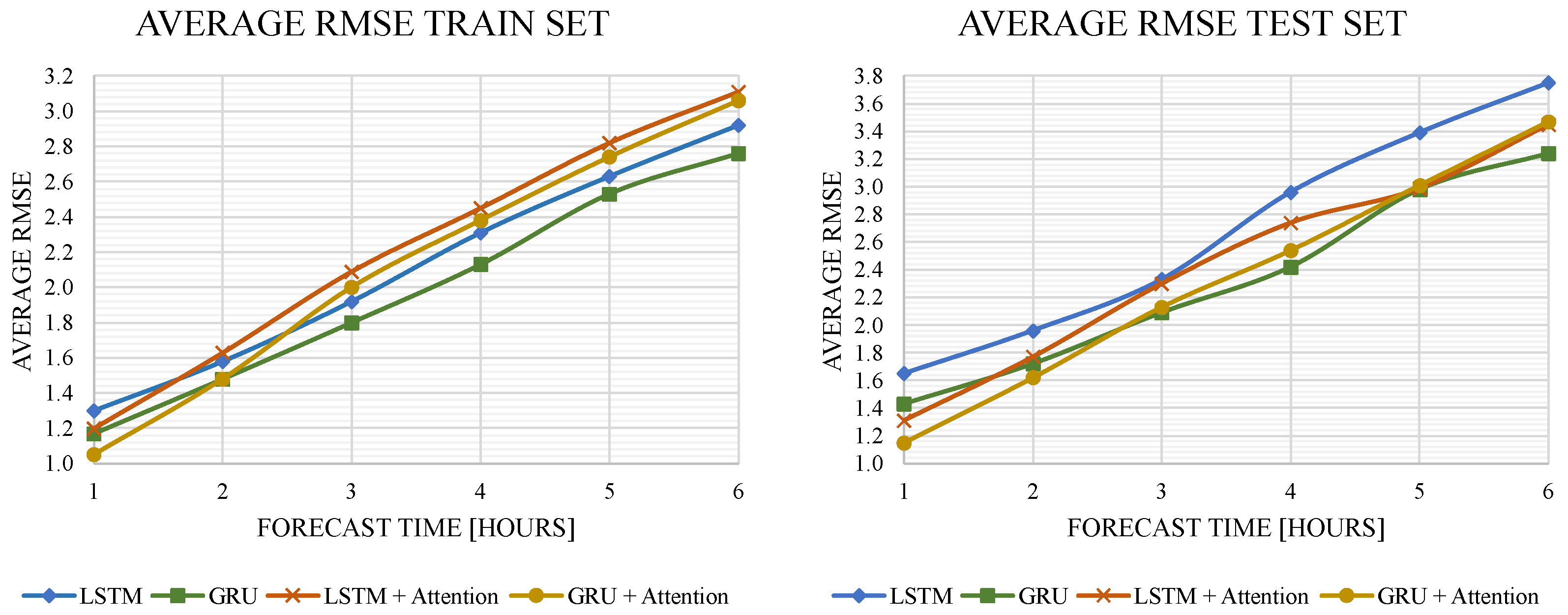
To determine the models’ behavior relating to the time interval under which they performed the prediction, the test was performed in a time window of 1 to 6 h predicting in the future for each model, increased by 1 h, as shown in
Table 1 and
Figure 7. From
Table 1, it is evident that the Average RMSE values in the test set are larger than the train values. This is caused by the large amount of data belonging to the train set (90%) compared to the data from the test set (10%).
Figure 7 shows that the models with attention mechanisms had higher performance during a shorter prediction time. As the prediction time increased from 1 to 6 h, the models without attention mechanisms outperformed the other models. The GRU model obtained the best results with attention mechanisms for short times and without attention mechanisms for long times; for the short times, the longer input sequence in the GRU and LSTM networks resulted in worse prediction accuracy of the output sequence because it focused on all input variables equally. An attention mechanism can be used to alleviate this problem by focusing on more relevant input variables, since, as already described above, attention mechanisms can adaptively assign a different weight to each input sequence to automatically choose the most relevant features of the time series. Therefore, the model can effectively capture the long-term dependence on the time series.
As a result of the models evaluated in a 1 h forecast with and without attention, the predicted and true behaviors for a single thermocouple were compared, as shown in
Figure 8. It is evident that the GRU model including attention (orange line) obtained a better representation of the true (green line) behavior. In contrast, the only GRU model (blue line) presented a more curly and distant behavior from the true data.
Additionally, in
Table 2, the individual comparison of the RMSE error of each one of the thermocouples for each model used is presented. Here, it can be observed how some thermocouples have small prediction errors and others very large, which is averaged and leads to obtaining the Average RMSE of the total forecast.
5.2. Parameter Exploration
To evaluate the influence of some parameters in the Average RMSE results, an exploration procedure was executed. The changing of three different parameters was evaluated. These parameters were the optimizer, the number of cells in the GRU and LSTM models and finally the number of training epochs in the GRU model.
5.2.1. Changing of Optimizer
Four different optimizers were evaluated in order to compare their influence on the Average RMSE obtained by the GRU model. The four compared optimizers were RMSprop, Adam, Adamax and Nadam. As shown in
Table 3, the best optimizer was Adam, obtaining an RMSE value in the train set of 3.01.
5.2.2. Change of GRU Cell Number
The variation in the number of GRU cells was studied by changing this number from 50 to 175, as shown in
Table 4. The results indicate that, as the number of cells increases, the RMSE in the training set decreases, which does not mean that it is a good result because, in this way, the model is over-fitting with the training data, which means that, as the number of cells increases, the RMSE of the test set becomes worse because the model is so adjusted to the training data that when new and unknown data arrive in the model input, it is more difficult to make an adequate prediction.
5.2.3. Change of LSTM Cell Number
Three different cell numbers were compared in the LSTM model. In this case, they were 32, 64 and 96, as shown in
Table 5. The results show favorable behavior for the variation of 64 cells; as in the GRU model, more units does not lead to better results, due again to phenomena such as over-fitting.
5.2.4. Changing of the Loss Behavior of the GRU Model through the Epochs
Figure 9 shows the loss behavior as the number of training epochs increases. From the results, it is evident that the first seven epochs are crucial in the decrease in loss, while, from epoch 7 onwards, the decrease in loss is scarce.
5.3. Time Series Cross-Validation
Different cross-validation procedures have been developed to evaluate the behavior of a time series forecasting model [
33]. In this study, three different approaches to perform time series cross-validation were used. These three approaches were (a) 7-fold moving origin, (b) Blocking Time Series Split and (c) Blocking Time Series Split with a static test set. Below, these three approaches are described and discussed.
5.3.1. Seven-Fold Moving Origin Time Series Split Cross-Validation
The first approach for the time series cross-validation was the 7-fold moving origin. This procedure involves cumulative training data from 1 October of 2020 to 1 September of 2021.
Figure 10 illustrates the results at the top and details the data division in the bottom section. Seven different folds were evaluated; the first is the least in the training set, and as the folds increase, the size of the training data also increases. The size of the test set remains constant in each fold. The size of this test set is 4000 data instances.
Table 6 shows the RMSE results for the train and test sets in each fold. As can be seen, the train RMSE increases as the number of folds increases. The opposite happens with the behavior of the RMSE test set; this indicates that it is better to train with numerous data because, with more data, the model can learn different scenarios that are presented in the furnace.
5.3.2. Blocking Time Series Split
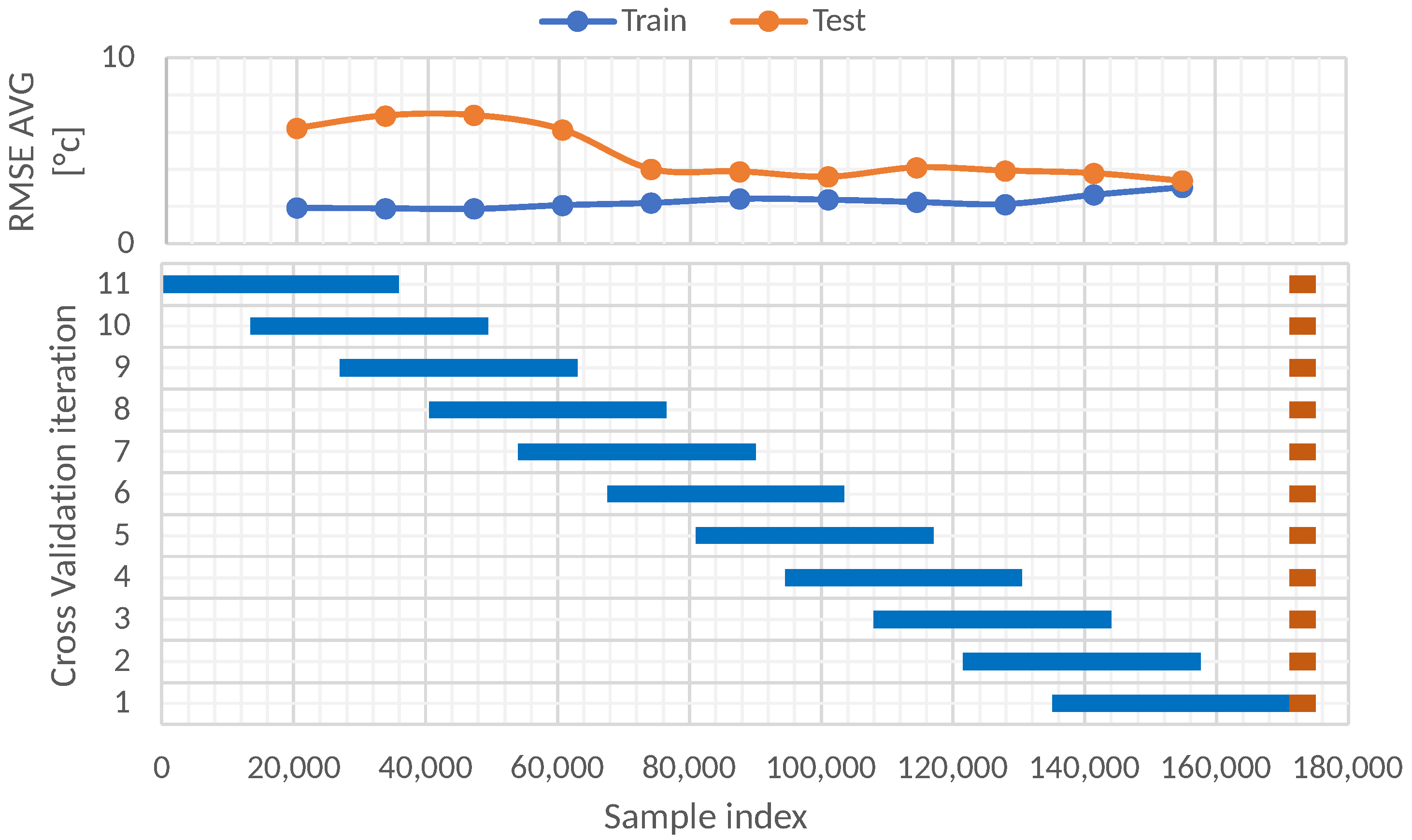
A second study using a blocking time series split cross-validation was performed. This validation approach consists of setting a fixed size of the train and test sets and moving across the entire dataset in several folds. In this case, 11 folds were used, and the train test had a size of 36,000 instances, whereas the test size had a size of 4000 instances. The shift between each fold was 140 days.
Figure 11 illustrates the 11 folds and every train set in blue and test set in orange. In total, 177,312 instances of the dataset were used; these data began on 9th September of 2016 and ended on 30th September of 2021.
The results after performing the 11-fold blocking time series split cross-validation are shown in
Table 7. From these results, it is evident that the best results of RMSE in the train set (1.89) and test set (1.96) were reached by the oldest fold—in this case, the 11th fold. Furthermore, a decreasing behavior of the RMSE through the folds is evident for the train set. In contrast, the behavior of the test set is oscillatory decreasing. Considering the 11 folds, the average RMSE was 2.24 for the train set and 2.89 for the test set.
5.3.3. Blocking Time Series Split with Static Test Set
The last study for the time series cross-validation model was the blocking time series split with the static test set. In this case, 11 folds were also evaluated, but the test set remained the same for every fold. This test set was created with the most recent 4000 instances. Different training sets were tested. The shift between each training fold was 140 days. The size of each training set was 36,000 instances.
Figure 12 illustrates the blocking time series split with static test set approach.
The RMSE results of the blocking time series split with static test set approach are shown in
Table 8. The results indicate that it is preferable to perform training with recent data since the RMSE increases as the training data move away from the test data. The RMSE in the test set changes from 3.37 for the first fold to 6.21 in the 11th fold, which represents an increase of 84.27%. Therefore, it is advisable to train the model every certain period to avoid obvious increases in the RMSE.
5.4. Variable Importance Study
A study of the selected variables used to train and test the GRU model was performed to evaluate their influence on the RMSE values. This study was performed with the data of the 7th fold in the time series split cross-validation data partitions shown in
Figure 10. Therefore, 36,000 instances composed the training set, whereas 4000 instances constituted the test set. Seven different scenarios were selected to train and test, removing the original number of variables as follows: (a) only with the 16 thermocouples to predict, (b) without furnace and electrode electric power, (c) without an electric arc, (d) without electrode position, (e) without electrode voltage, (f) without electrode current, (g) without the automatic control of electric power in the furnace (SAEE) mode, (h) without calcine chemistry and (i) using all 49 variables. The results of the RMSE comparison are shown in the bar chart of
Figure 13. From the results in the bar chart, one can observe the difference between the RMSE results in the train and test sets, the latter being the one with the largest RMSE values. In particular, the worst results in the test set were obtained by the (i) all variables’ configuration, causing the error to reach the highest value of 3.45 in the test set. Consequently, when removing different groups of variables, the RMSE value improved. The lowest RMSE value of the test set of 3.22 was reached when the group (c) without electric arc was removed. Thus, it is better to remove the group of variables (c) related to the electric arc to develop the GRU model.
5.5. Study of Increasing the Number of Predicted Thermocouples to 76
Based on a request made by the CMSA engineering team in which they preferred to concentrate on the monitoring of the plate coolers in the lower row, the number of thermocouples to be monitored and predicted was increased. A study of the increase in the number of thermocouples was carried out, progressively evaluating their impact on the Average RMSE of the predictions.
The number of thermocouples was progressively increased from 16 until reaching 76 thermocouples. The RMSE values of the training set and the test set were measured for each increase; these values are shown in
Table 9. It can be seen that the relationship between the increase in thermocouples and the Average RMSE of the predictions is directly proportional since, in
Figure 14, the increasing trend of this evaluation metric can be observed due to the increase in the number of variables to be predicted.
The increase that occurs in the Average RMSE is small compared with the increase in the number of thermocouples. There was an increase of 4.75 times in the number of thermocouples, while the RMSE in the training set remained approximately constant because there was more information that the model could use to obtain better relationships between the variables. On the other hand, for the test set, the RMSE increased only 1.1 times; this is because the number of variables and data that the model must predict is greater, but it is still a good prediction result.
From the results depicted in
Figure 14, it can be seen that the attention GRU model improved the RMSE value when 24 thermocouples were predicted. Therefore, for a few thermocouples, the attention GRU model is better, whereas, for numerous thermocouples, it is recommended to use the GRU model without the attention mechanism.
5.6. Root Mean Squared Error Distribution by Each Thermocouple in the Test Set
Figure 15 illustrates the boxplot of the RMSE obtained by each thermocouple in the test set. In particular, the four quadrants of the furnace are separated. These quadrants are named as follows: northwest (section 18), southwest (section 19), southeast (section 20) and northeast (section 21). From the results, the southeast quadrant presents the lower error, while the southwest quadrant presents the highest. In general, the mean value of RMSE for each thermocouple is near to 0.4, reaching a maximum value of 1.75.
6. Conclusions
This work has shown the development of a multivariate time series deep learning model to predict the temperature behavior of a lining furnace. The developed model is based on an attention mechanism in the encoder–decoder approach of a recurrent neural network. The validation of the model was performed using data acquired in an industrial ferronickel furnace over a period of 5 years. The model considered the historical behavior of 49 variables involved in ferronickel production. Among these variables were the electrode current, voltage, power and position, besides the electric arc, the chemical composition and the temperature measured by the thermocouples themselves. These results were validated by a study carried out in terms of the Average RMSE calculated in 76 different thermocouples located in the furnace lining side-wall at four different heights.
The principal conclusions of this work are as follows:
The temperature of the lining furnace at different heights of the wall and in different sectors was satisfactorily predicted using the developed deep learning model.
The results showed that the prediction time influenced the obtained Average RMSE, which was better when predicted in a time window of 1 h in the future when the attention mechanism was used. RMSE values increased as the time window increased.
A comparison between four different approaches using GRU, LSTM, and their attention-based variants was performed. The best RMSE results were obtained using the GRU attention-based model.
Three different time series cross-validation procedures were used: the 7-fold moving origin time series split, the Blocking Time Series Split and the Blocking Time Series Split with static test set. The results showed that, over time, the model lost its ability to correctly predict temperatures. Therefore, it is recommended to retrain the model every year to maintain an RMSE value of around 4 °C.
A study increasing the number of thermocouples to predict from 16 to 76 was carried out. The results showed that the Average RMSE was maintained at a value near to 4 °C, which is allowed in the furnace operation due to the normal operation conditions.
As general conclusions, we can highlight that this work aimed to provide and validate a forecast temperature methodology that is applied to an electric arc furnace. The validation was performed by using real data from a furnace of the Cerro Matoso S.A. and results were validated by staff from the same company. Although the methodology was implemented in this furnace, the paper presents the steps to apply it to any multivariable process to predict the behavior of a variable.
As future works, the following ideas will be explored:
An online learning-based stream data approach will be developed to evaluate damages in the refractory walls using the developed model. Moreover, the concept of drift detection and treatment in these variables will be studied.
The methodology will be adapted to forecast other important variables in this furnace, such as the thickness of the refractory wall by predicting, among others, the flow heat in these walls. Since thickness can be measured directly by the operational conditions, it can be obtained by a model that uses forecasted variables.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}