1. Introduction
Sea surface temperature (SST) has an important impact on the health of regional marine ecosystems [
1], and its changing trend may lead to the growth, reproduction, and distribution of marine species. Long-term SST forecasts on large-scale waters are of great significance to oceanic physical phenomena and help climate monitoring and early warning systems for flood and drought risks. Subsea changes are likely to leave traces on the sea surface through changes in sea-surface height (SSH) [
2], so research on SST is important in order to investigate the subsurface parameters. According to Khedouri (1983) [
3] and Ali (2004) [
4], sea surface parameters are correlated with subsea ones. Yan et al. (1992) [
5] estimated subsea parameters based on the ocean surface information. X. Wu et al. (2012) [
2] showed that in a subpolar basin, the estimation accuracy of the subsurface temperature anomaly (STA) was improved by 40% through monthly SST and SSH data. M. Han et al. (2019) [
6] estimated the subsurface temperature through parameters such as SST. M. Han et al. used the Copernicus Marine Environment Monitoring Service data sets (sea surface temperature anomaly (SSTA)), sea surface height anomaly (SSHA), and sea-surface salinity anomaly as input parameters of a convolutional neural network (CNN) model to predict the subsurface temperatures of the subsurface layers (a total of 57 layers) of the Pacific Ocean. The mean square errors (MSEs) of the subsurface temperature in all of those subsurface layers in the Pacific Ocean in January, April, July, and October were 0.2659, 0.3129, 0.5318, and 0.5160, respectively. So, research on SST is very important in many ways.
So far, investigators have focused on the short-term forecast of a small- or medium-sized area of the ocean. For example, research usually selects data sets covering thousands of meters to 2000 km and forecasts them one week or one month in advance. The following research involved the prediction of sea surface temperature in a small range in the medium and short term. Based on the sea temperature data of the past 7 days, 20 days, and 50 days, J. Dong et al. (2018) [
7] made SST predictions at 1 day, 7 days, and 30 days in advance, respectively, on a small area of water in the Bohai Sea using a combined fully convolutional long short-term memory (LSTM) and CNN (CFCC-LSTM) model, with average MSEs of 0.1466 °C, 0.2722 °C, and 0.7260 °C, respectively. Xiao et al. (2019) [
8] established an LSTM model in the East China Sea using 36 years of spaceborne sea surface temperature data; the model is accurate for the daily prediction of the short-term and medium-term sea surface temperature field. L. Guan et al. (2020) [
9] divided the entire China Sea and its adjacent area into 130 small regions using the self-organizing map algorithm, constructed an LSTM model for each region to predict its SST, and found that the root-mean-square error (RMSE) of the forecasts at 1 month in advance was 0.5 °C. In summary, previous studies have mostly used data sets to make short-term predictions of regional SST, in which the selected feature is rather simple. The prediction of sea temperature over large areas of water and a long period has been rarely investigated. Moreover, as the forecast period is extended, the accuracy of the existing methods decreases [
9]. Compared with the above, this paper used a TCN model to accurately predict long-term SSTs of a large area in the Indian Ocean. “Long term” means five years prediction, and “large area” means predicting on large-scale sea waters (40–110° E, 25° N–25° S) almost covering the Indian Ocean. Also, in this study, the influences of various factors on SST were fully considered when choosing features.
Also, from the above-mentioned studies it is evident that with artificial intelligence widely used, [
10,
11,
12,
13,
14], deep learning models are gaining importance in the prediction of marine environmental elements. The prediction of sea surface temperature is usually solved as a time series problem, usually using LSTM. But LSTM has two disadvantages: it cannot extract spatial features and is prone to gradient problems when there is too much data [
15,
16]. By contrast, the TCN model can extract features in both time and space and is not prone to gradient problems because of its structure.
This study focused on the Indian Ocean to make an extended long-term SST forecast. By using multisource, multimodal air–sea data, a temporal convolutional network (TCN)-based model was constructed to perform a 5-year SST forecast on large-scale sea waters (40–110° E, 25° N–25° S, with a spatial resolution of 1° × 1°), thus realizing the ultra-long-term SST prediction on a large sea area. At the same time, theories of ocean physics and DL were combined in this study. The ocean surface is affected by ocean circulation and turbulence [
5]. The large-scale SST annual cycle in the eastern equatorial Pacific is largely controlled by the changing depth of the mixed layer every year, while the depth of the mixed layer is mainly determined by solar radiation and the competitive effects of wind forces [
17,
18]. Therefore, this study selected multifactor, multilevel data of the ocean surface, the subsea, and the atmosphere as the input features to give the TCN model prior knowledge of physical oceanography in the training process, thereby achieving the goal of improving SST prediction accuracy through the powerful data-mining capability of a DL model.
The study of physical oceanographic phenomena in large-scale sea waters requires processing massive amounts of detailed data. The method proposed in this study only used data sets with low spatial resolution and time granularity to make ultra-long-term predictions about a large area of sea water. The aim is to predict trends in large-scale long-period SSTs and to improve the prediction accuracy as much as possible. Therefore, this method can have many applications, such as sea surface detection [
19,
20] and eddy current recognition, and it can be applied in practice and can play a key role in the study of some large-scale physical oceanographic phenomena, such as El Niño and Indian Ocean Dipole phenomena.
2. Materials and Methods
This study focused on the Indian Ocean (30–135° E, 30° N–66.5° S), which is the third largest ocean in the world. It influences climate anomalies in its surrounding areas, including Central and South America, the southern tip of Africa, southeastern Australia, northeast Asia, and other regions [
21,
22,
23,
24]. This study used the reanalysis data sets provided by the National Centers for Environmental Prediction, with a spatial resolution of 1° × 1°, to perform quality control and normalization on the observation data of various sources (ground, ship, radiosonde, wind balloon, aircraft, satellite, etc.). These data sets are characterized by many elements, a wide range, and long time range.
This study used the monthly ocean–atmosphere data of the sea area (40–110° E, −25–25° N) in the Indian Ocean obtained at
https://psl.noaa.gov/data/gridded/ (accessed on 29 December 2021). The sea temperature forecast problem can be viewed as a time-series regression problem. Using monthly data is easier to study some ultra long-term marine phenomena, such as IOD and ENSO. The cycle of ENSO is long, usually 6–8 years, and using daily data is unrealistic.
The monthly data from 10 consecutive years were selected to predict the SST in the next 5 years.
Table 1 shows the factors (a total of 81) that likely affect the SST of a given data point, and their monthly data were collected and divided into three categories: atmospheric parameters, sea-surface parameters, and subsea parameters. A total of 24 atmospheric parameters at different heights (1000, 850, 500, and 300 hPa), i.e., the data of atmospheric temperature (T), geopotential height (GPH), vertical velocity (W), relative humidity (RH), east–west wind speed (U), and north–south wind speed (V), were chosen. A total of 17 sea-surface parameters were included, i.e., the SSH of the centre point, the SST of the centre point, and the SSTs of 15 surrounding points (i.e., sub1_SST, sub2_SST, …, sub15_SST in the
Table 1). A total of 40 subsea parameters were included, i.e., temperature, east–west ocean current (u), north–south ocean current (v), and sea-surface salinity (SSS) at each sea depth of the centre point (5, 15, 25, 35, 45, 55, 65, 75, 85, 95 m). The 1980–2008 data were used for a training dataset. The time span of features was 10 years. The training set was constructed by the sliding-window method, i.e., the sliding window slid backward 1 year at a time. The test set included the monthly atmospheric data of the ocean from 2004 to 2013 and their corresponding monthly SSTs from 2014 to 2018, making a total of 2533 pieces of data.
The TCN was adopted to perform deep learning (DL) and modelling with big data of ocean parameters. The TCN architecture adopted in this study was proposed by S. Bai (2018) [
25]. TCNs use various ideas, including residual connection, dilated convolution, and causal convolution, to make them more effective in processing long-time-series/space problems. Of them, the residual connection (residual block) can to a certain extent eliminate the effects of vanishing gradients and gradient explosion that mar some DL networks [
26]. By restricting the sliding direction of the convolution window, the causal convolution allows the prediction at time t (Yt) to be judged only through the input of x1 to xt − 1 before time t. Dilated convolution was originally adopted in the field of image segmentation, in which it decreases the loss of information and increases the receptive field while maintaining the same dimension numbers for both inputs and outputs. The formula for calculating the number of convolution kernels after dilated convolution is shown in Equation (1), in which K is the number of convolution kernels after dilation, k is the number of original convolution kernels, and d is the dilation rate of the neural network layer:
This study transformed the two-dimensional training set into a three-dimensional matrix (m, 120, 81) to input into the model. Each sample was a matrix (120, 81), one time step was 120, and each time step had 81 features. The layer number of the three-dimensional matrix was m, which equaled the number of samples. The numbers of convolution kernels were 8 and 24, dilations = (1, 2, 4, 8, 16, 32, 64, 128, 256), and stack = 1. A preliminary experiment showed that when the number of convolution kernels was set to 8, the model showed optimal efficiency, indicating that when training the model, at least the information of the past 8 months needed to be considered, and as the dilation factor increased, the historical time to be considered should also increase. The number of convolution kernels determines the number of feature maps generated in the convolution. The feature map contains information extracted from the output of the previous layer, and the information extracted through different convolution kernels differs. When the number of convolution kernels is too large, some occasional small data disturbances in the training set could be learned by the model, which could affect the accuracy of the model. When the number of convolution kernels is too small, the model’s ability to learn features becomes weak. In this study, we added more historical data to the output information by setting the dilation list, and the model was trained using the ordinary convolution method under the dilation rate of 1. The seasonal and interannual variation characteristics of SST in large sea areas required that more historical data be considered when predicting future sea temperatures. A comparison of the performance of ordinary and dilated convolutions on the data set of this study found that dilated convolution was more suitable for our purposes.
Figure 1 shows the operation of a sample in the TCN structure. A one-dimensional convolution (Conv1d) is performed on the samples of the input layer to obtain a matrix of size (120, 1, 24), which enters the first residual block for the operation (dashed box). The blue is the tensor of the calculation process of the TCN model. The red is the prediction results of TCN, which represents the sea surface temperature in the next 60 months. The input matrix of the residual block is convolved once in one dimension, and the same input matrix is convolved twice in one dimension, and the results are summed and passed to the second residual block, and the results obtained from both convolutions of the residual block are kept until the end for summing. Finally, the prediction result (60, 1) is mapped by the fully connected layer. The TCN model in this study was set up with nine residual blocks.
4. Discussion
This study made a long-term SST prediction on large-scale sea waters, in which the oceanic and atmospheric observation data of the past 10 years were used to forecast the SST in the next 5 years, and the prediction model was evaluated through the correlations of the predicted SST time series, RMSE, and ACC. The predicted SSTs in the period from 2014 to 2018 showed an average monthly error of 0.506 °C. The most important fact in this paper is that the 5-year correlation reached 88.23%
An advantage of this paper is the use of low spatial resolution and relatively small data sets, which yielded a high accuracy rate on the SST forecast on large sea areas over a long time scale. Generally, the number of deep learning samples is positively correlated with the prediction accuracy; this means that for data with higher resolution, the number of samples would also be more and the accuracy would be better. Current studies have focused on the SST forecast using a high-resolution dataset [
6,
7,
8,
9]. For example, Lei G. (2020) [
9] et al. used a 0.05° × 0.05° resolution dataset forecasting 12 months in advance and RMSE was 0.66 °C. This study made a 5-year SST forecast of the entire Indian Ocean basin using 1° × 1° resolution dataset. But we achieved better results on RMSE (average monthly error of 0.506 °C).
Another strength of this paper is that although the forecast was long term, the error was stable, as shown in
Figure 2. Generally speaking, the error increased with the increase of model prediction time. Lei G. [
9] found that the accuracy of prediction one month in advance was the highest, with an error of 0.5 °C; When predicting 2 months in advance, RMSE increased to 0.59 °C; When predicting 12 months in advance, RMSE reached a peak of about 0.66 °C. So, it is obvious that with the increase of lead time, RMSE increases slowly. But the TCN model has a stable error, as shown in
Figure 2a. In 2015 and 2016, the prediction error increased, while the error in other years was always small, ranging from 0.3 °C–0.5 °C. Although Indian Ocean Dipole occurred in the Indian Ocean in 2015 and 2016 [
27], and this may have affected the error of the TCN model, it performed better than others.
Another strength of this paper is that the study researches large-scale ocean physical phenomena. The study of marine physical phenomena usually involves analyzing the characteristics of seasonal and interannual changes over a medium or large area of the ocean considering multiple ocean–atmosphere factors. The fit of the SST of the entire ocean basin to the long-term prediction in this study was good, indicating that the proposed model is more suitable for the study of large-scale and long-term ocean physical phenomena.
Another advantage of this paper is that we selected many features. Large-scale ocean phenomena are affected by multiple factors, such as ocean current, sea wind, and sunlight. Model features in previous studies only included time-varying parameters of the sea surface (e.g., SST, SSS), but this study combined some theories of ocean physics with feature selection engineering to model multisource and multimodal data. These features included SST, sea subsurface temperature, flow velocity, atmospheric factors, and other factors to enable the model to learn the relationships between multiple features and SST, which is more in line with the requirements of studying physical phenomena.
The current studies on SST have focused on the forecasting of short and medium time scales in small sea areas, and the prediction accuracy decreases with increased forecasting time. Medium and short-term prediction generally refers to the time span of the next few days or months, and long-term prediction refers to the time span of more than several years. Among the models used in the past, CNNs cannot use the correlations between different feature time series (before and after), and LSTM models cannot extract the spatial dependency. TCNs can extract spatiotemporal information simultaneously and are thus superior to CNNs and LSTM models in many aspects. Since numerical values instead of images are inputted, TCNs have a faster calculation speed than CNNs while being less prone to the problem of gradient explosion. This study proposed an ultra-long-term SST prediction technology for large-scale sea waters based on multisource and multimodal observation data, which is conducive to using DL to develop deep-sea remote sensing technology. Limited by the data density and time span, the proposed model was only used to make 5-year SST predictions. We believe that by expanding the datasets, it will be possible to improve the prediction accuracy and extend the prediction period.
In addition, another strength of this paper is that TCN can extract its temporal and spatial characteristics. And when learning spatial location information, convolutional networks such as CNN are generally used, and the information is input into the model in the form of pictures, which requires a high computational workload. In the TCN model used in this study, only numerical values are input, making the calculation simpler and faster. Given the complexity of marine data systems, the model proposed in this study is apparently more suitable for marine data processing. The proposed model can output a 5-year SST time series at one time, making it more functional than the NOAA’s CFSv2 model, which can only make predictions 9 months in advance.
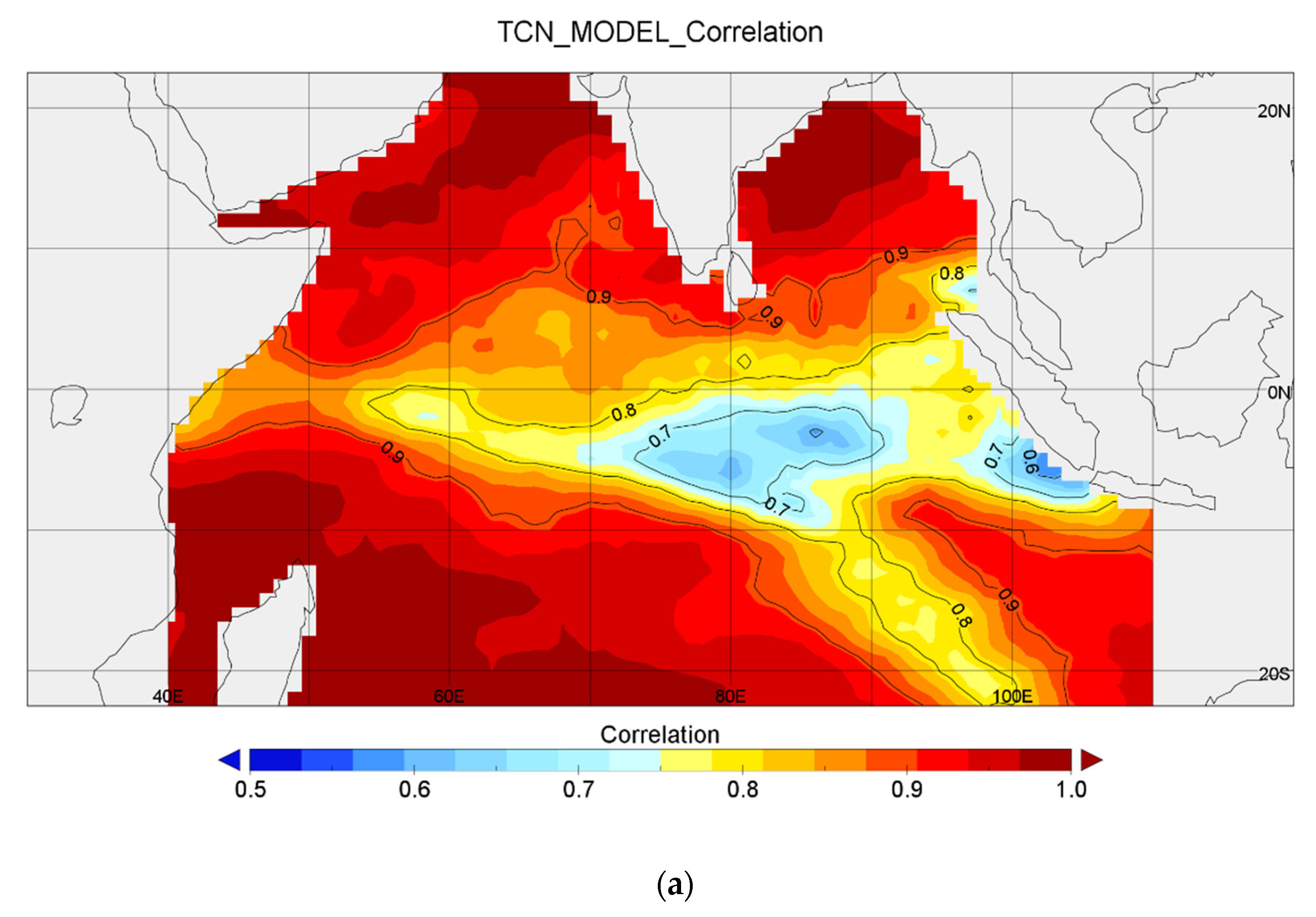
Due to the limited period of available data, this study only made a 5-year forecast. In future work, it should be possible to make SST forecasts for a longer period by increasing the data volume. As shown in
Figure 6, in certain areas of the Indian Ocean (−10° S to 10° N, 40–110° E), the correlation was rather low, and
Figure 4d,e shows clearly the research limitations. So special phenomenon (i.e., IOD) can not be observed. These areas showed a very strong nonlinear dynamic process, which needs simplification so that the prediction accuracy of DL algorithms in these areas can be improved. In future work, we will focus on improving the model’s prediction accuracy when a special phenomenon happens.
Regarding the reduced prediction accuracy of the TCN model near the equator in the inner ocean, we believe that the relationship between the convergence and divergence of ocean currents and their resulting upwelling and downwelling is nonlinear, and this nonlinear problem cannot be solved well by deep learning models. This nonlinear relationship is reflected in our model in that the variation of underwater UV and the variation of SST are nonlinear, thus causing a decrease in prediction accuracy near the equator. We also plan to conduct further research on this problem, such as designing appropriate linearization equations for specific situations and then adding them to deep learning to combine human knowledge with deep learning to achieve more accurate predictions.
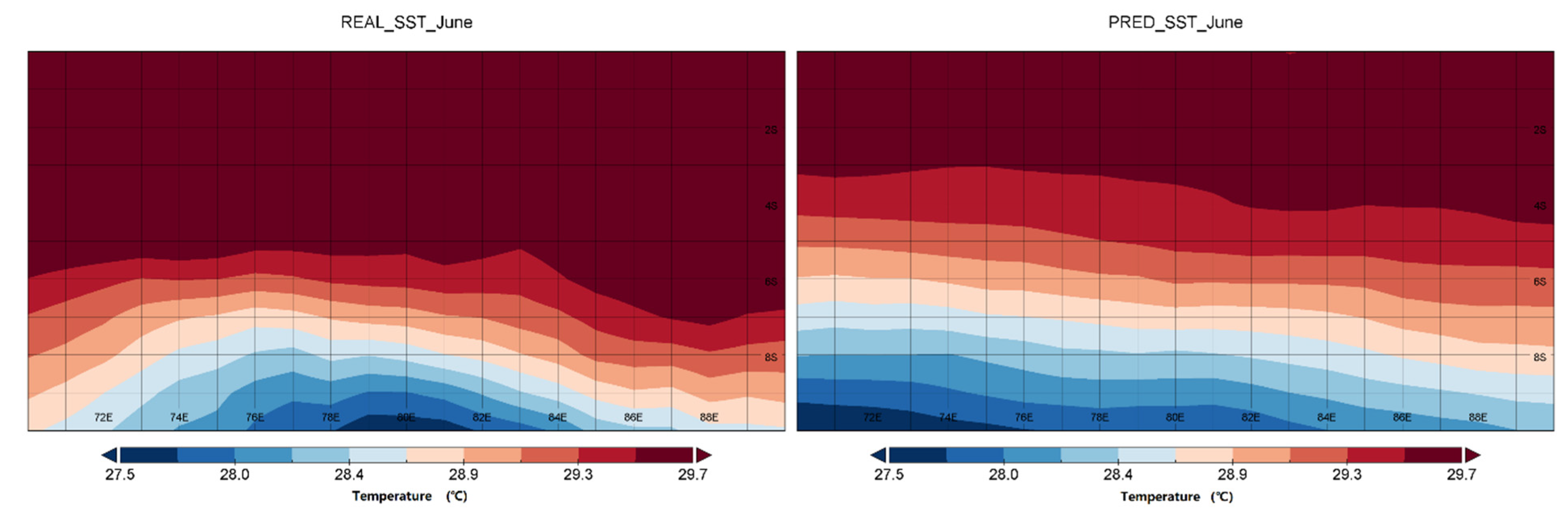
In
Figure 8 we have selected the region 70° E–90° E, equator, to 10° S to plot six plots of the real sea surface temperature. The TCN model predicted sea surface temperature for June, September, and December 2015. With the RMSE line graphs, we can see that the model prediction accuracy decreases in the second half of 2015, which affects the average correlation. So, we focus our discussion on the second half of 2015. Our prediction of the gradient of temperature is still accurate, especially in June, as can be seen in the comparison chart (south of the equator, gradually decreasing). The TCN model predicts this change in temperature. The same is true in September. This study focuses on the prediction of correlation, that is, the degree of fit between the true SST variation and the predicted SST variation. This study lays the foundation for large physical ocean phenomena, such as the IOD phenomenon, which manifests itself as the difference between the mean values of temperature in the east and west Indian seas. If we have a high level of correlation prediction of sea surface temperature, it will be of great help for such physical ocean phenomena, such as IOD, which are related to changes in SST.
5. Conclusions
In this study, the TCN model was used to predict the sea surface temperature of the Indian Ocean in the next five years using multisource and multimodal data in the past 10 years. The dataset used was from 1980 to 2008 for predicting monthly SSTs from 2014 to 2018. This study was about large ocean areas and long-term prediction. From 2014 to 2018, the RMSE of the proposed model was 0.420 °C, 0.556 °C, 0.650 °C, 0.487 °C and 0.417 °C, respectively. The 5-year SST’s average RMSE was 0.506 °C, and the correlation between the predicted SST time series and the observed SST time series was 88.23%. Through the results analysis, the TCN method was stable and reliable, with high accuracy. The model contributes to the long-term prediction of SST, thus greatly aiding the study of physical phenomena in the ocean. The model performed better in ordinary years than in years with abnormal IOD events. In the future, we will add other data to improve the model’s prediction accuracy for abnormal years.
In sum, since long-term prediction requires a lot of data, the traditional LSTM model does not work, which is a problem for long-term prediction. The TCN model is suitable for long-term forecasting and has relatively high accuracy. Secondly, we found that using multi-elements is good for improving long-term prediction, because long-term SST change is about the long-term sea–air dynamics process, and multi-element learning is more consistent with this. In the results, it was also proved that our multi-element learning can improve prediction for a long-term period. Finally, we focused on the correlation to measure the effect of the model. This is beneficial for large-scale oceanic phenomena. IOD is the temperature difference between regions, and it would be one-sided to focus only on the average error of all points of the RMSE. Both regions have errors














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}