Abstract
We live in a period when smart devices gather a large amount of data from a variety of sensors and it is often the case that decisions are taken based on them in a more or less autonomous manner. Still, many of the inputs do not prove to be essential in the decision-making process; hence, it is of utmost importance to find the means of eliminating the noise and concentrating on the most influential attributes. In this sense, we put forward a method based on the swarm intelligence paradigm for extracting the most important features from several datasets. The thematic of this paper is a novel implementation of an algorithm from the swarm intelligence branch of the machine learning domain for improving feature selection. The combination of machine learning with the metaheuristic approaches has recently created a new branch of artificial intelligence called learnheuristics. This approach benefits both from the capability of feature selection to find the solutions that most impact on accuracy and performance, as well as the well known characteristic of swarm intelligence algorithms to efficiently comb through a large search space of solutions. The latter is used as a wrapper method in feature selection and the improvements are significant. In this paper, a modified version of the salp swarm algorithm for feature selection is proposed. This solution is verified by 21 datasets with the classification model of K-nearest neighborhoods. Furthermore, the performance of the algorithm is compared to the best algorithms with the same test setup resulting in better number of features and classification accuracy for the proposed solution. Therefore, the proposed method tackles feature selection and demonstrates its success with many benchmark datasets.
1. Introduction
The fields of big data, cryptography, and computer science in general are all influenced by the domain of optimization and to some extent even somewhat rely on it. The field of optimization is broad and employs a large variety of techniques. Although there is a large number of optimization solutions, in most of the cases there is room for further improvements and new algorithms can lead to better results. What is more, some optimization methods prove to be suitable for a certain class of problems, while others perform better for other types. Consequently, when proposing a new optimization technique, it needs to be thoroughly tested in order to identify its strengths and weaknesses with respect to the solutions’ quality when dealing with different types of problems.
Nature-inspired algorithms have been widely applied in recent years for solving various range mathematical and engineering optimization non-deterministic polynomial hard (NP-hard) problems [1] due to its high robustness and efficiency in exploiting and exploring vast search space domain. Of all nature-inspired approaches, evolutionary algorithms (EA) and swarm intelligence metaheuristics stand out the most and they have been effectively applied to different NP-hard real-world challenges [2,3,4]. The EA approaches conduct a search process by adopting reproduction, crossover and mutation operators from natural evolution, while swarm intelligence mimics collective intelligent behavior of group of organisms from nature such as flock of birds, school of fish, colonies of ants and bees, and so forth. Both families of methods belong to the group of artificial intelligence optimization techniques. Various metaheuristics were reviewed and considered to be improved upon. The most recent from the reviewed set are the grey wolf optimizer (GWO), red deer algorithm (RDA) [5], ant lion optimizer (ALO) [6], grasshopper optimization algorithm (GOA) [7], multi-verse optimizer (MVO) [8], moth-flame optimization algorithm (MFO) [9], social engineering optimizer (SEO) [10], dragonfly algorithm (DA) [11], whale optimization algorithm (WOA) [12], harris hawks optimization (HHO) [13], sine cosine algorithm (SCA) [14]. While the mentioned algorithms have all shown notable improvement performance-wise, none are without shortcomings. In the field of swarm metaheuristics, the primary solutions tend to favor either exploration or exploitation phases. There have been attempts in the domain to initially create a solution that performs equally well in both phases like the elaborate SCA. Nevertheless, even the SCA has undergone modifications and achieved better performance than its original version [15]. Hence, the true potential of the swarm metaheuristics is achieved through hybridization. This modification method relies on the principle of fusing the original algorithm with another. This is usually achieved by incorporating a principle from an algorithm that has better performance for the phase that unfavored by the solution that is improved upon. The dynamic of the field dictates constant improvement and search for new solutions and new ways to improve the existing ones. The reason for the authors to opt to improve SSA is with its robustness while maintaining simplicity. The algorithm is easy to implement and the fine-tuning modifications are even suggested by its author.
The expansion of data availability and computer processing power in recent decades has led to interaction between the fields of nature-inspired metaheuristics and machine learning, which is an artificial intelligence subdomain and as a crucial tool for data science. Machine learning models can be efficiently utilized to find patterns and make predictions from what may appear at first glance uncorrelated huge amounts of data. However, employed large datasets are usually packed with inessential and redundant data negatively influencing machine learning performance regarding computational complexity and accuracy. An attribute of “high-dimensional” is usually associated with such datasets and this phenomena is known as the curse of dimensionallity [16].
Therefore, finding relevant information (features) from large datasets is crucial for tackling the above mentioned issue and it is known as the dimensionality reduction challenge in the modern computer science literature [17]. The process of dimensionality reduction is usually employed in the data pre-processing phase of machine learning and it encompasses two approaches: feature extraction and feature selection. By using feature extraction, new variables are derived from the primary dataset [18], while feature selection chooses a subset of significant variables for further use [19].
The aim of feature selection is to find the most informative subset from high-dimensional datasets by removing redundant and irrelevant features, therefore improving classification and prediction accuracy of machine learning model. According to G. Chandrashekar et al. [20], all feature selection methods can be split into three groups: filter, wrapper and embedded. Wrapper methods utilize learning algorithms to evaluate feature subset by training a model and they are the most efficient, however the most computational demanding as well. Filter methods do not rely on a training system, but apply a measure to assign a score to feature subsets. This group is generally less computationally expensive than the wrapper family, but generates a universal set (not tuned to a particular predictive model) since it does not include model training. Finally, the embedded methods use feature selection as a part of the model construction procedure, that is, algorithms execute feature selection during the model training. The embedded methods are as fast as the filter ones, but more precise. Regarding the computational difficulty, embedded methods are in the middle of wrappers and filters.
Nature-inspired algorithms, especially swarm intelligence metaheuristics [21,22], have been successfully applied as wrapper methods for feature selection in machine learning and this is one point where machine learning and optimization metaheuristics intersect. If there are features in a dataset, the total number of subsets exist and, since for high-dimensional datasets is typically a large number, this challenge is considered NP-hard. Consequently, regarding the fact that swarm intelligence proved to be a robust and efficient optimizer for solving NP-hard challenges, its application as a wrapper feature selection method is straightforward.
Notwithstanding that many swarm intelligence applications for feature selection can be found by surveying recent literature sources, considering no free lunch (NFL) theorem [23], there is still space for improvements in this domain. The NFL, which proved to be accurate, states that no universal algorithm exists that can solve all optimization problems. Accordingly, an approach that efficiently solves feature selection issues for all datasets does not exist. The NFL theorem motivates researchers to improve and adjust current algorithms or propose new ones, to solve various problems, including feature selection challenge.
Therefore, the motivation behind the proposed study is to try to further enhance feature selection in machine learning by employing an improved salp swarm algorithm (SSA), which was also developed and evaluated for the purpose of this research. The SSA belongs to the family of swarm intelligence metaheuristics and it was proposed in 2017 by Mirjalili et al. [24]. The basic SSA is enhanced by including an additional mechanism and by hybridization with another well-known swarm intelligence metaheuristics.
Guided by established practice from the modern literature, before its application to feature selection, the proposed enhanced SSA is firstly tested and evaluated on a recognized test-bed with challenging instances of functions having 30 dimensions from the Congress on Evolutionary Computation 2013 (CEC2013) benchmark suite [25]. This also allows a direct comparison of the obtained results with the outputs of a large variety of state-of-the-art (SOTA) metaheuristics. Afterwards, it is adapted as a wrapper-based approach for feature selection and validated against 21 well-known datasets retrieved from University of California, Irvine (UCI) repository [26].
The scientific contributions of proposed study can be summed as follows:
- proposed improved SSA algorithm overcomes some observed deficiencies and establishes better performance than original SSA;
- proposed method proves to be promising and competitive with other SOTA metaheuristics according to CEC2013 testing results; and
- compared to other SOTA approaches, improvements in addressing feature selection issue in machine learning in terms of classification accuracy and number of selected features is established.
Based on that stated above, the method proposed in this study tackles the feature selection challenge and demonstrates its success with many benchmark datasets.
The organization of the manuscript is as follows. Section 2 covers some of the most notable SOTA approaches from the domain of swarm intelligence, as well as from the area of hybrid methods between swarm algorithms and machine learning. In Section 3, the original SSA is presented first, then its drawbacks are indicated and finally details of the proposed algorithm are provided. Section 4 and Section 5 present simulations with standard CEC2013 instances along with feature selection experiments including comparative analysis and discussion with other recent SOTA algorithms. Finally, a summary and future research plans are examined in Section 6.
2. Related Works
There are several recent good survey studies that present the challenges that appear within feature selection in various fields of machine learning, as well as indicate the most prolific methods to achieve the task. Some very inspiring reads are [20,27], as well as the more recent work [28]. These also thoroughly present the complexity of the feature selection task, the manner in which the dimensionality reduction can be achieved for various datasets, ideas that are also marginally discussed in the introduction section of the current article. Another work that also presents a survey for the same problem is [29]. This study especially concentrates on evolutionary computation approaches for achieving the goal, so it is better linked with the current work. A review of studies for feature selection that is further narrowed only on methodologies involving swarm intelligence algorithms is found in [30].
The two most popular evolutionary computation approaches in feature selection are genetic algorithms (GAs) and particle swarm optimization (PSO), and for both there is an increasing trend in the number of studies using them in the last couple of decades [29]. They are both applied in wrapper approaches beside various classification algorithms, like support vector machines [31,32,33], K-nearest neighbor [34,35,36], artificial neural networks [37,38], decision tree [39] and so forth.
In [31], a regression real-world task regarding combustion processes in industry is considered, where support vector regression is actually employed for getting an optimal carbon monoxide concentration in the exhaust gases based on other characteristics. Besides a GA for feature selection, two more methods from Bayesian statistics are tested, but the GA approach proves to be superior. Another case of successful combination between a GA and SVM for classification is presented in [32], where the GA is used both for feature selection and for fine tuning the parameters of the SVM. In [33], dataset with medical microscopical images is considered and features are first extracted from these and they are further reduced by feature selections and eventually an SVM is applied for achieving automated diagnosis.
In [34], a bees inspired optimization algorithm is used as the metaheuristics that takes care of optimization, several benchmark datasets are used and the results are compared to cases when a GA, a PSO or an ant colony optimization are used. The approach in [36] integrates an evolutionary algorithm with a local search technique and the authors claim very good performance for medium- to large-sized datasets.
In [37], a real-world credit dataset is collected at a Croatian bank and the GA combined with ANN is applied to it and then further tested on a UCI database. Applications to medical data are presented in [38], where various classifiers (SVM, artificial neural networks, K-nearest neighbor, linear regression) are optimized via a genetic algorithm as concerns both parameter optimization and feature selection.
Finally, in [39] an application to medical images performs, as in [33] above, feature extraction and then feature selection is performed using a GA. Various classifiers like SVM, ANN and decision tree are used for the final prediction. Another example of feature selection tackled by swarm intelligence is [40], where the PSO algorithm is validated and improved upon with a innovative mechanism of initialization and the update process of solutions with the 20 popular datasets.
SSA has also been used to address the feature selection problem. Some of the efficiently improved cases of the basic SSA include the solution of feature weighting with the minimum distance problem [41], the problem of feature selection solving through hybridization with the opposition based learning heuristics [42], and the improvement of accuracy, reliability and the convergence time for the problem of feature selection with the introduction of the inertia weight control parameter [43]. SSA has also been successfully modified and applied in other application domains recently, such as green home health care routing problem [44], health care supply chain [45], crop disease detection [46] and power systems unit commitment task [47], to name the few.
Nature is the source of inspiration in the case of swarm intelligent algorithms. The benefit for the machine learning techniques derives from the good compatibility with the main principle of swarm intelligence of employing an immense amount of units individually incapable of solving the problem. This sort of algorithms are often applied by themselves for the reason of their well known exceeding performance. Furthermore, their full potential is reached by incorporating hybridization techniques. The real world application of swarm intelligence solutions is vast from the clustering, node localization, and preserving of energy in wireless sensor networks [48,49,50,51], through to the scheduling problem with cloud tasks [2,52], the prediction of COVID-19 cases based on machine learning [53,54], MRI classification optimization [55,56], text document clustering [57], and the optimization of the artificial neural networks [58,59,60,61].
3. Proposed Method
This section first introduces basic details of the original SSA metaheuristics. Afterwards, the observed drawbacks of the basic version are elaborated and mechanisms that are able to overcome its deficiencies are proposed. Finally, solutions for improving SSA are put forward.
3.1. Basic Salp Swarm Algorithm
The SSA [24] algorithm was motivated by the group of animals called salp, which are aquatic, small, barrel-shaped and transparent. The individual units of this specimen bind together with the goal of finding the safest paths in finding food sources. These interesting creatures link up one behind another forming a chain.
The first unit in the chain is the leader and its behavior models exploration and exploitation of the optimization algorithm search process. The leader decides where the group will go in search for paths and food in its area. The leader’s position is changed towards the direction of the food source, that represents the current best solution.
The units’ positions in D-dimensional search space are mathematically described as a two-dimensional matrix labeled X, while the food source (current best solution) is labeled as F. The following function updates the leader’s position in the j-th dimension [24]:
the denotes leader, represents the position of the current best solution (food source), the upper and lower search space boundaries in the j-th dimension are, respectively, and , while , and denote pseudo-random numbers drawn from the interval .
The parameters and determine the step size and dictate whether the position of the new solution will be generated towards negative or positive infinity. However, the most important parameter is considered to be due to the reason that it directly influences the exploration and exploitation balance, which is one of the most important factors that influence search process efficiency. The is calculated as [24]:
where the current iteration is represented as l and the maximum iterations in a run are denoted as L.
The position of followers is updated with the following equation that represents Newton’s law of motion [24]:
where denote i-th follower in the j-th dimension and . Annotation t represents time and , where , and the initial speed is .
Due to the fact that time in any optimization process is modeled as iteration, the disparity between iterations is 1 and at the beginning, Equation (3) can be reformulated as:
3.2. Cons of the Original Algorithm and Proposed Improved Approach
It is a common case for the basic optimization algorithms to have certain deficiencies and that is also the case with the SSA. Noticed cons of the basic SSA can be summarized as follows: insufficient exploration, average exploitation power (conditional drawback) and intensification-diversification trade-off.
In general, any optimization algorithm can be improved by applying small modifications, for example, minor changes made to the search equation, additional mechanisms, and/or significant changes by hybridization with other algorithm. For the purpose of this study, basic SSA was improved by including novel mechanism, as well as hybridization with another well-known optimization metaheuristics.
Based on the findings from previous research [62,63], as well as on extensive simulations with challenging CEC2013 benchmark instances [25] that were conducted for the purpose of this study, it was discovered that the diversification process of basic SSA exhibits some deficiencies, which leads to the inappropriate intensification-diversification balance, that is on average dis-balanced towards exploitation.
First of all, the SSA exploration is controlled only by dynamic parameter according to Equation (2) and at the beginning of a run it is shifted towards exploration, while at later iterations it slides towards exploitation. However, this mechanism is applied only to the leader F (current best solution) and the whole search process to some extent depends on the luck. Followers are updated according to Equation (4), which is essentially exploitation between its previous and current positions. If the algorithm was lucky and manages to find a region of the search space where the optimum solution resides, then the search process will eventually converge and satisfying solutions’ quality will be obtained. Conversely, the search will stuck in sub-optimal regions and best solutions will be located far from global optimum at the end of a run.
Therefore, a solution for the above mentioned issue would be to improve exploration in early iterations. For achieving this goal, an exploration replacement mechanism is incorporated into the basic SSA in the following way: in the first iterations, the worst solutions from population are rejected and renewed with randomly generated solutions within upper and lower bounds of the search space according to expression:
where is pseudo-random number drawn from a uniform distribution.
The same expression is utilized in the initialization phase, where a starting random population is generated. This mechanism introduces two additional control parameters: replacement mechanism point (), that determines when (in terms of l) the replacement mechanism will be triggered and worst replaced solutions () that controls the number of worst solutions that will be replaced with random ones. If , then the enhanced exploration will be performed throughout the whole run, similarly if , then the SSA search will executed as in its basic version.
By further analysis of the original SSA, it was also determined that the exploitation procedure with the followers (Equation (4)) is relatively simple depending on their current and previous positions. To overcome this, hybridization with another recently proposed metaheuristics, the SCA [14] is performed. In each iteration, the followers are updated either by using basic SSA equation (Equation (4), or SCA search expression for and individual i and component j:
where , , and are four randomly generated values from the interval , represents the j-th component of random individual from population, indicates the absolute value and and are standard trigonometric functions.
Similarly, as the original SSA, the SCA employs the following formula to adjust intensification-diversification balance:
where the parameter a represents a constant.
To control whether the followers’ position will be updated using basic SSA or SCA search, pseudo-random number is used, as it is shown in Algorithm 1.
Encouraged with the introduced modifications, proposed enhanced SSA is named SSA with replacement mechanism and SCA search-SSARM-SCA. Its pseudo-code is shown in Algorithm 1. The flowchart of the algorithm is shown in Figure 1.
| Algorithm 1: Pseudocode of SSARM-SCA. |
| Initialize population X by using Equation (5) |
| repeat |
| Compute the objective function for each solution |
| Update the best salp (solution) |
| for do |
| if then |
| Update the position of salp using Equation (1) |
| end if |
| if then |
| Update followers by using SSA search and Equation (4) |
| else |
| Update followers by using SCA search and Equation (6) |
| end if |
| end for |
| Sort all individuals according to fitness |
| if then |
| Replace worst solutions by random ones using Equation (5). |
| end if |
| Update using Equation (2) |
| Update using Equation (7) |
| until |
| Return the best solution F. |
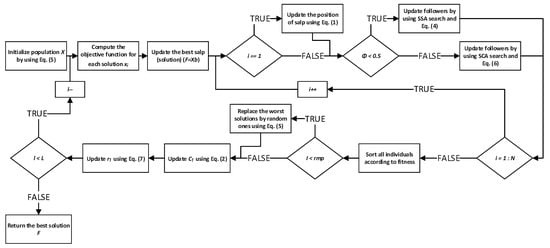
Figure 1.
Flowchart of the proposed SSARM-SCA algorithm.
3.3. Complexity and Limitations of Proposed Method
The most computationally expensive operation during metaheuristics algorithm’s execution is fitness function valuation (). Accordingly, as established in the most relevant and contemporary computer science publications, the complexity of the algorithm is measured in terms of utilized [64].
Complexity of both basic SSA and the proposed SSARM-SCA algorithms is the same: , where denotes the number of solutions in the population, while T represents the number of iterations. The proposed algorithm in each iteration performs the search either by utilizing the SSA or SCA search equations. In the first iterations the solutions are replaced by pseudo-random solutions, however this does not add additional costs in terms of , as all solutions in the population are being evaluated at the beginning of each iteration.
When the is being considered, the proposed SSARM-SCA algorithm is not more complex than the basic SSA metaheuristics. The algorithm is slightly more complex if the number of floating point operations is taken into account, however this can be disregarded in comparison to , and therefore it is not relevant for the algorithm’s complexity.
4. Validation of the Proposed Method for Standard CEC2013 Benchmarks
Following good practice from modern literature, the proposed SSARM-SCA is first tested on challenging CEC2013 benchmark instances [25] with 30 dimensions () before being adapted for the practical feature selection challenge. With the goal of making comparative analysis with other SOTA approaches, which results are published in the recent papers, the same experimental conditions in terms of control parameters as in [65] are kept.
The CEC2013 benchmark suite contains 28 functions that are split into three groups based on its characteristics. Test instances from 1 to 5 are unimodal, benchmarks from 6 to 20 are multimodal, and finally, test bed from 21 to 28 belongs to the category of composite functions. Functions’ details employed in simulations are given in Table 1.

Table 1.
CEC2013 benchmark suite details.
Besides the proposed method and original SSA, for the purpose of comparative analysis, all methods shown in [65] are also implemented and evaluated. All algorithms are tested with 50 individuals in population and the number of fitness function evaluations of is set as termination condition as in [65].
The SSARM-SCA is compared to practical genetic algorithm (RGA) [66], gravitational search algorithm (GSA) [67], disruption GSA (D-GSA) [68], black hole GSA (BH-GSA) [69], clustered GSA (C-GSA) [70] and attractive repulsive GSA (AR-GSA) [65].
Specific SSARM-SCA control parameters are set as follows: according to expression and by using formula . Values for these parameters are determined empirically. Dynamic parameter for original SSA and SSARM-SCA are adjusted according to Equation (2) and parameter of SSARM-SCA is adjusted throughout the run by expression (7). It is noted that in those expressions instead of l and L, the and are used, respectively. Other methods implemented for the purpose of comparison are tested with the control parameters suggested in [65].
All algorithms are executed in 51 independent runs and the following metrics in terms of objective function values are captured: best, median, worst, mean and standard deviation. Comparative analysis results are split into three tables based on the function types as follows: Table 2 show results for unimodal, Table 3 presents metrics for multimodal and Table 4 depicts results for composite CEC2013 instances. The best results for each metrics are marked bold in all tables.
Table 2.
Comparative analysis between SSARM-SCA and other SOTA methods for CEC2013 unimodal benchmarks.
Table 3.
Comparative analysis between SSARM-SCA and other SOTA methods for CEC2013 multimodal benchmarks.
Table 4.
Comparative analysis between SSARM-SCA and other SOTA methods for CEC2013 composite benchmarks.
First of all, obtained results for all methods for the purpose of this study are similar as in [67], therefore this research validates results reported in [67]. From the comparative analysis results superiority of proposed SSARM-SCA can be unambiguously determined. For most of the benchmarks, including all three types (unimodal, multimodal and composite) in average, the SSARM-SCA obtains the best results for all four indicators among all other SOTA metaheurisitcs. Specifically, when comparing to the original SSA, improvements in terms of convergence speed and results’ quality are substantial.
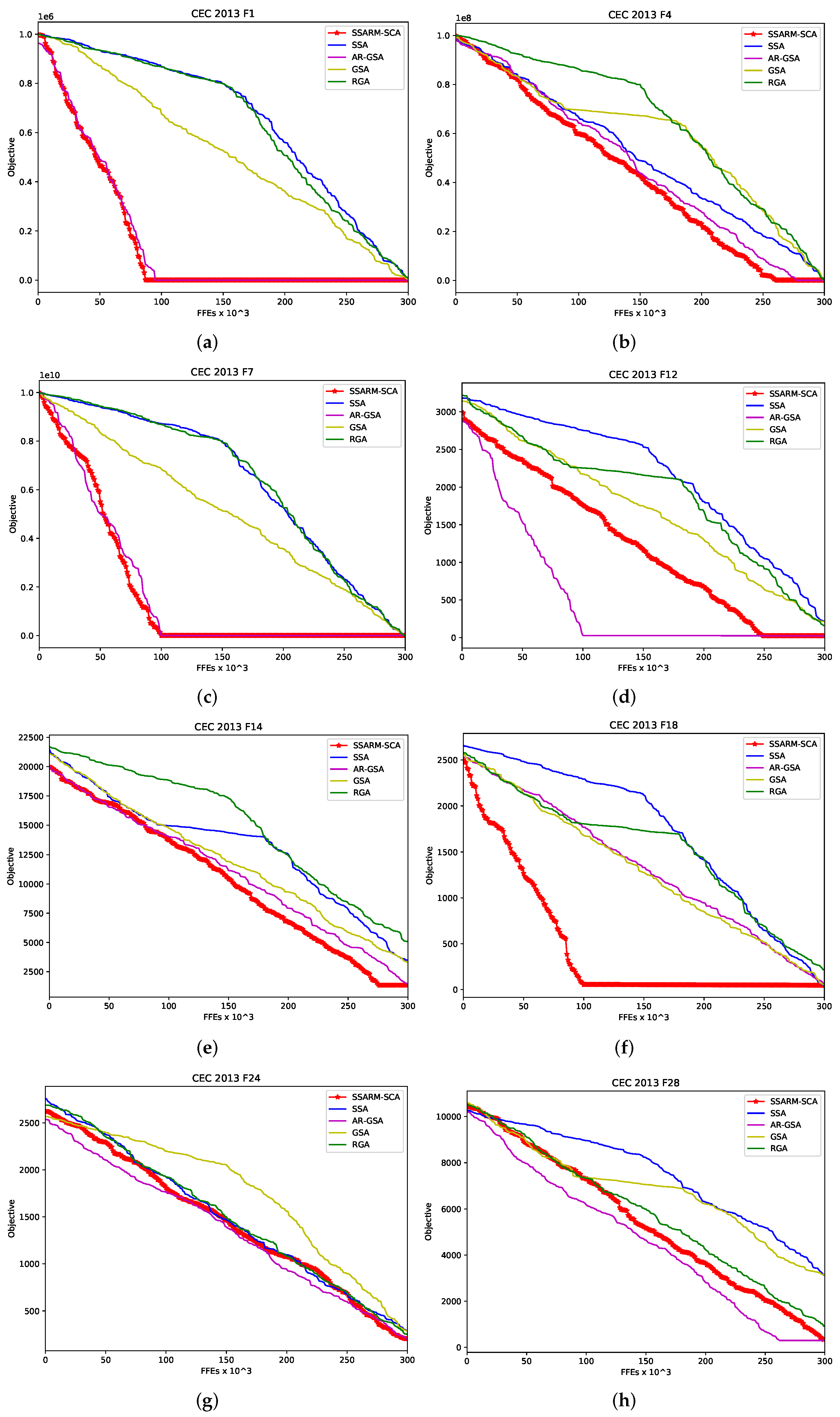
More insights regarding the convergence speed can be obtain from Figure 2. In the presented figure, convergence speed graphs for some methods included in analysis for 2 unimodal (F1 and F4), 4 multimodal (F7,F12,F14 and F18) and 2 composite (F24 and F28) benchmarks are generated. Provided graphs validate clear improvements of proposed SSARM-SCA over original SSA and other SOTA methods in terms of convergence.
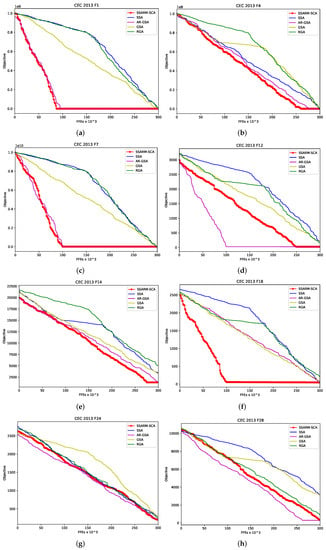
Figure 2.
Convergence speed comparison for 8 CEC2013 instances-proposed SSARM-SCA vs. other approaches. (a) SSARM-SCA vs. others-CEC2013 F1. (b) SSARM-SCA vs. others-CEC2013 F4. (c) SSARM-SCA vs. others-CEC2013 F7. (d) SSARM-SCA vs. others-CEC2013 F12. (e) SSARM-SCA vs. others-CEC2013 F14. (f) SSARM-SCA vs. others-CEC2013 F18. (g) SSARM-SCA vs. others-CEC2013 F24. (h) SSARM-SCA vs. others-CEC2013 F28.
However, to more objectively determine the robustness and efficiency of one approach over others, results should also be compared in terms of statistical tests. For that reason, the Friedman test [71,72], as the primary method for doing as alongside the ranked two-way analysis of variances of the proposed method and other implemented methods for the research, was conducted.
The results achieved by the 8 implemented algorithms over the 28 functions from the CEC2013 benchmark set, including the Friedman and the aligned Friedman test, are presented in the Table 5 and Table 6, respectively.
Table 5.
Friedman test ranks for the compared algorithms over 28 CEC2013 functions.
Table 6.
Aligned Friedman test ranks for the compared algorithms over 28 CEC2013 functions.
As observed in Table 6, the proposed SSARM-SCA outperformed all of the other candidates, as well as the basic SSA which averaged the ranking of 133.463. Proposed SSARM-SCA obtained an average ranking of 56.838.
Furthermore, the research [73] provides grounds for the possible improvement in terms of performance in comparison with the value. Hence, the Iman and Davenport’s test [74] is used as well. The results of this test are summarized in Table 7.
Table 7.
Friedman and Iman–Davenport statistical test results summary ().
The results show a value of , which demonstrates significantly better results than the F-distribution critical value (). Additionally, the null hypothesis is rejected by Iman and Davenport’s test. The Friedman statistics fared with the score of () resulting in better performance than the F-distribution critical value at the level of significance being .
The final conclusion is that the null hypothesis can be rejected and that the proposed SSARM-SCA is clearly the best of its competitors.
The rejection of the null hypothesis by both statistical tests performed is followed by the next type of test, Holm’s step-down method which is a non-parametric post-hoc method. The findings of such experiments are displayed in Table 8.
Table 8.
Results of the Holm’s step-down procedure.
The p value is the main sorting reference for all the methods and they are compared against the . The k denote the degree of freedom while the i shows the number of the algorithm, respectively.
This research utilized parameter at the levels of 0.05 and 0.1. It should be noted that the values of p parameter are displayed in scientific notation.
The summary of testing with Holm’s method by the results provided in the Table 8 stands to prove that the improvement has been achieved for the subjected solution in case of both levels of significance.
5. Feature Selection Experiments
The feature selection belongs to the group of binary problems, hence the well-known V-shaped transfer function was used for mapping continuous search space variables to discrete values 0 and 1. Therefore, if a dataset consists of feature, one solution is represented as a binary array of length . This is how the proposed SSARM-SCA was adapted for this problem and for the sake of distinguishing binary version from its respecting continuous version it is referenced as the bSSARM-SCA.
Efficiency of proposed method for feature selection challenge was compared to SOTA metaheuristics presented in [22]. For that reason similar experimental conditions as in [22] were established. However, instead of using with as in [22], the was used as termination condition and it was set to 560 (). This approach is more reasonable since different optimization algorithms consume different number of in each iteration and respecting the fact that the is the most expensive calculation in optimization process. The other SSARM-SCA control parameters were as follows: according to formula and by using expression .
The bSSARM-SCA performance was tested on the 21 UCI datasets which are often used for bench-marking (Table 9). All datasets are split into training and testing using rule in proportion 80%:20%. Each solution’s fitness is calculated on the training set by utilizing nearest neighbors (KNN) classifier and the following fitness function F as in [22]:
where the represents the error-rate of classification, the selected features number represented as R, and lastly the C shows the sum of all features. The and are parameters that establish relative influence of the and R to the fitness function and they sum to 1 ().
Table 9.
Experimental setup datasets.
From the formulated fitness function it can be seen that the classification error rate, as well as the number of selected features are taken into consideration and that the problem is formulated as minimization optimization challenge. In this study, is set to 0.9, while is adjusted to 0.1.
At the end of a run, the solution with best fitness is determined and results of its evaluation on the testing set were reported. All experiments were conducted in 20 independent runs. All methods, including SOTA metaheuristics used in comparative analysis shown in [22], along with original bSSA and bSSARM-SCA are implemented in Python using numpy, pandas, scikitlearn and matplotlib libraries. Moreover, the same performance metrics as in [22] are shown and for all implemented methods, a V-shaped transfer function is used for mapping continuous to binary search space. Algorithms proposed in [22] were tested with the control parameters as suggested in original papers.
Finally, as proposed in [40], four different initialization methods were employed in order to more objectively evaluate proposed method: small, mixed and large. In small initialization, all individuals are generated at the beginning of a run with small number of selected features (about 1/3) and in the case of a large individuals employ most of the features ([2/3,1]). In mixed initialization experiments, generated solutions take into account about 2/3 of all features in the dataset.
In all three experiments mean fitness and accuracy obtained over 20 runs are used as performance metrics and expressions used for its calculation are given in Equation (9) and Equation (10), respectively.
where average fitness is denoted as , designates the individual with the best fitness in the run, while represents the total number of runs.
where represents the average classification accuracy, N marks the number of instances in the test set, represents the classifier output for instance i, and denotes the reference class corresponding to the given instance i.
As already noted, for the purpose of comparative analysis, besides original SSA adapted for binary optimization problems (bSSA), the following algorithms, which results are shown in [22], are also used: whale optimization algorithm (WOA) [12], bWOA with sigmoidal transfer function (bWOA-S) and with hyperbolic tangent transfer function (bWOA-V) [22], three versions of binary ant lion optimizer (BALO) [22], particle swarm optimization (PSO) [75], binary gray wolf optimization (bGWO) and binary dragonfly algorithm (bDA) [11].
Mean fitness and classification accuracy for all three initialization strategies and 21 UCI datasets are shown in Table 10, Table 11, Table 12, Table 13, Table 14 and Table 15. In all provided tables, the best results are marked with bold style.
Table 10.
Mean fitness statistical metric using small initialization with the 21 utilized datasets.
Table 11.
Classification accuracy using small initialization for the 21 utilized datasets.
Table 12.
Mean fitness statistical metric using large initialization with the 21 utilized datasets.
Table 13.
Classification accuracy using large initialization for the 21 utilized datasets.
Table 14.
Mean fitness statistical metric using mixed initialization with the 21 utilized datasets.
Table 15.
Classification accuracy using mixed initialization for the 21 utilized datasets.
From the provided experimental results, a few important remarks can be deduced. First, similar results for WOA, bWOA-S, bWOA-v, BALO1, BALO2, BALO3, PSO, bGWO and bDA to those reported in [22] were obtained, therefore validity of previous study is confirmed (it is noted that due to stochastic nature of metaheuristics, exactly the same results could not be generated). Second, proposed hybrid bSSARM-SCA for most datasets and benchmark instances outscores original SSA, hence performance improvements over basic implementation are clear. Finally, when compared to all other SOTA approaches encompassed by comparative analysis, proposed bSSARM-SCA in average obtained the best results and proved to be robust method in tackling feature selection challenge in terms of employed fitness function and classification accuracy.
Formulated fitness function takes into account the number of selected features, however only with weighted coefficient of 0.1 (parameter in expression (8)). For that reason, to further validate propose method the average proportion of selected features (selection size) over 20 runs and all three initialization strategies are shown in Table 16.
Table 16.
Average selection size with various datasets for the compared algorithms with the three different initialization methods.
Similar to results with an average obtained fitness function and classification accuracy, from Table 16 it can be concluded that on average proposed bSSARM-SCA metaheuristics managed to significantly reduce the number of selected features and this in turn has implications for the classifier’s computational efficiency. Therefore, as a conclusion by performing feature selection with bSSARM-SCA classification computational time can be substantially reduced. In terms of average selection size, only the bDA for some test instances managed to outscore the method proposed in this study.
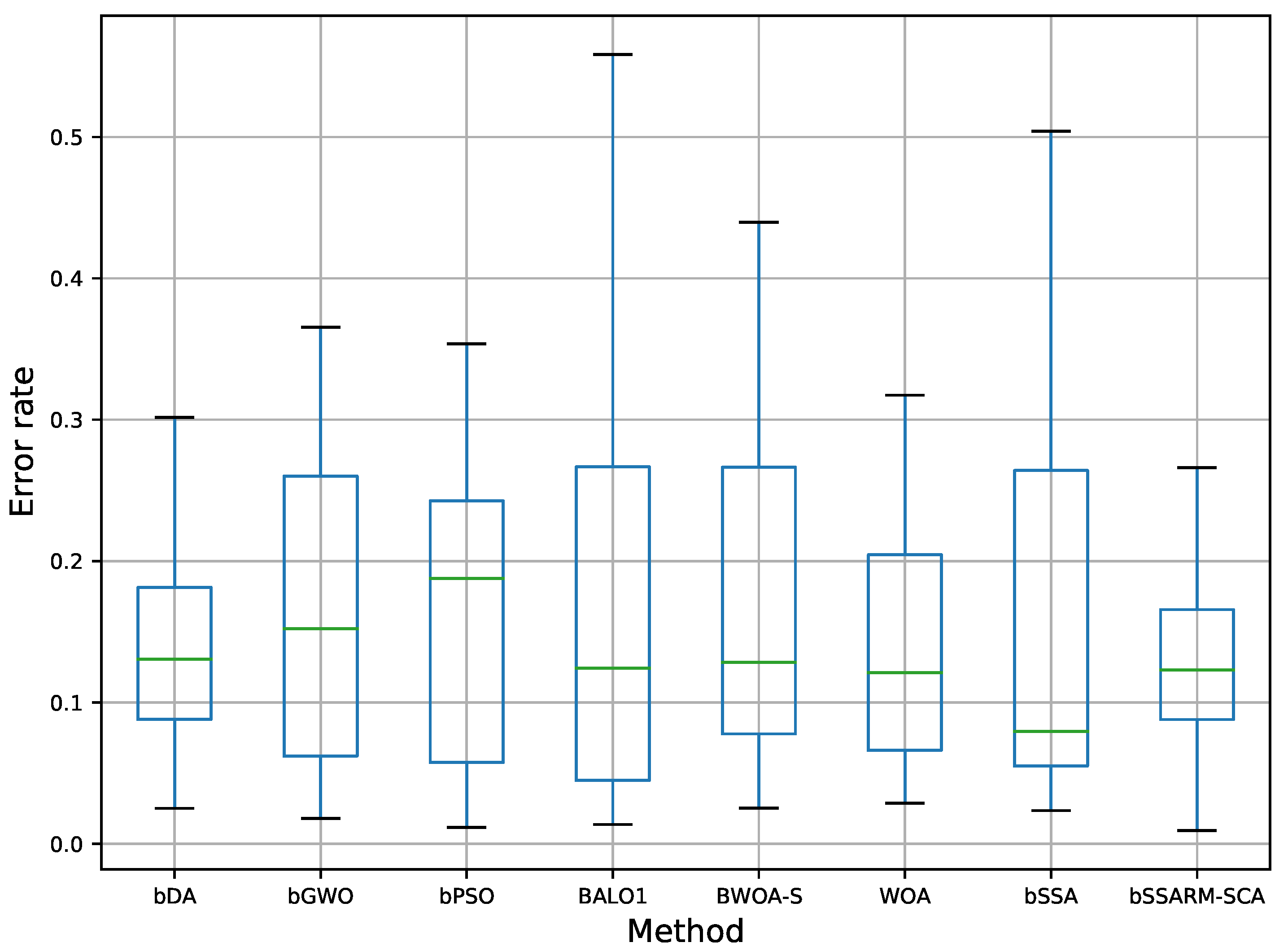
Box and whiskers diagram visualization of average classification error () for all datasets and three initialization strategy is shown in Figure 3. From presented diagram stability of propose bSSARM-SCA can be undoubtedly noticed. For example, when compared with basic SSA, that in some runs misses promising regions of the search space, the superiority of the algorithm proposed in this study is evident.
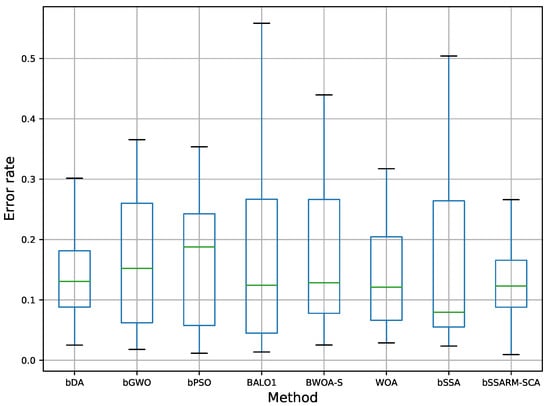
Figure 3.
Box plots and whiskers diagrams for average error rate including all datasets and three initialization strategies.
Finally, to show the performances of the proposed bSSARM-SCA algorithm and compare it to other SOTA SSA versions, the authors have implemented binary versions of three novel SSA modifications. The accuracy of the bSSARM-SCA over 21 datasets was compared to opposition based learning and inertia weight ISSA (bISSA1), proposed by [41], opposition based learning and local search ISSA (bISSA2) proposed in [42], and inertia weight ISSA (bISSA3) given in [43]. Again, it is worth noting that the authors have independently implemented all three mentioned binary ISSA variants and executed the experiments with 21 observed datasets. The obtained results are shown in Table 17, where the best result is marked bold for each category (small, large or mixed initialization). The simulation findings clearly show the superiority of the proposed bSSARM-SCA method, that obtained the best results on 15 out of 21 observed datasets. The second best method was bISSA2 [42], which obtained the best results on four datasets, while the bISSA1 method [41] achieved the best accuracy on two datasets.
Table 17.
Classification accuracy of the proposed bSSARM-SCA method and three recent ISSA variants for the 21 utilized datasets.
6. Conclusions
Research proposed in this study presents a novel SSA algorithm that addresses observed deficiencies of its original implementation. By hybridizing basic algorithm with well-known SCA metaheuristics and by incorporating guided replacement mechanism, a novel SSARM-SCA metaheurisitcs is devised.
Guided by established practice from the modern literature, before its application to feature selection, the proposed enhanced SSA is firstly tested and evaluated on a recognized test-bed with challenging instances of functions having 30 dimensions from the CEC2013 benchmark suite. Afterwards, it is adapted as a wrapper-based approach for feature selection and validated against 21 well-known datasets retrieved from UCI.
According to experimental findings and rigorous comparative analysis with other recent SOTA approaches, proposed SSARM-SCA proves to be an efficient optimizer that significantly improves convergences speed and results’ quality of the basic SSA and also other SOTA algorithms. Moreover, obtained results prove that the proposed method manage to established better classification accuracy and utilization of lesser number of features, therefore it also manages to improve the solution to the feature selection challenge.
The proposed SSARM-SCA algorithm does not increase the complexity of the basic SSA implementation in terms of , while offering significantly better performances for this particular problem. However, according to the no free lunch theorem, the limitation of the proposed solution is that there are no guarantees that it would perform well for other optimization problems.
The possible directions of the future research include testing of the devised SSARM-SCA algorithm on other practical datasets from different application domains, and also applying it to other optimization problems, such as the wireless sensor networks optimization problem and task scheduling in cloud-based systems.
Author Contributions
Conceptualization, N.B. (Nebojsa Bacanin), M.Z. and C.S.; methodology, N.B. (Nebojsa Budimirovic), A.C., A.P. and C.S.; software, N.B. (Nebojsa Budimirovic), A.C., M.Z.; validation, N.B. (Nebojsa Bacanin) and C.S.; formal analysis, M.Z. and A.P.; investigation, N.B. (Nebojsa Budimirovic) and N.B. (Nebojsa Bacanin); data curation, C.S., N.B. (Nebojsa Bacanin) and A.C.; writing—original draft preparation, A.P. and M.Z.; writing—review and editing, M.Z., C.S. and A.C.; visualization, N.B. (Nebojsa Budimirovic), M.Z. and A.C.; supervision, N.B. (Nebojsa Bacanin) and C.S. All authors have read and agreed to the published version of the manuscript.
Funding
The work of Catalin Stoean was supported by a grant of the Romanian Ministry of Education and Research, CCCDI-UEFISCDI,411PED/2020, project number PN-III-P2-2.1-PED-2019-2271, within PNCDI III.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Korani, W.; Mouhoub, M. Review on Nature-Inspired Algorithms. Oper. Res. Forum 2021, 2, 1–26. [Google Scholar] [CrossRef]
- Bezdan, T.; Zivkovic, M.; Tuba, E.; Strumberger, I.; Bacanin, N.; Tuba, M. Multi-objective Task Scheduling in Cloud Computing Environment by Hybridized Bat Algorithm. J. Intell. Fuzzy Syst. 2020, 42, 718–725. [Google Scholar]
- Strumberger, I.; Minovic, M.; Tuba, M.; Bacanin, N. Performance of elephant herding optimization and tree growth algorithm adapted for node localization in wireless sensor networks. Sensors 2019, 19, 2515. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Katyara, S.; Shaikh, M.F.; Shaikh, S.; Khand, Z.H.; Staszewski, L.; Bhan, V.; Majeed, A.; Shah, M.A.; Zbigniew, L. Leveraging a genetic algorithm for the optimal placement of distributed generation and the need for energy management strategies using a fuzzy inference system. Electronics 2021, 10, 172. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R. Red deer algorithm (RDA): A new nature-inspired meta-heuristic. Soft Comput. 2020, 24, 14637–14665. [Google Scholar] [CrossRef]
- Mirjalili, S. The Ant Lion Optimizer. Adv. Eng. Softw. 2015, 83, 80–98. [Google Scholar] [CrossRef]
- Meraihi, Y.; Gabis, A.B.; Mirjalili, S.; Ramdane-Cherif, A. Grasshopper Optimization Algorithm: Theory, Variants, and Applications. IEEE Access 2021, 9, 50001–50024. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.; Hatamlou, A. Multi-Verse Optimizer: A nature-inspired algorithm for global optimization. Neural Comput. Appl. 2015, 27, 495–513. [Google Scholar] [CrossRef]
- Okwu, M.; Tartibu, L. Moths–Flame Optimization Algorithm. In Metaheuristic Optimization: Nature-Inspired Algorithms Swarm and Computational Intelligence, Theory and Applications; Studies in Computational Intelligence; Springer: Cham, Switzerland, 2021; Volume 927, pp. 115–123. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R. The Social Engineering Optimizer (SEO). Eng. Appl. Artif. Intell. 2018, 72, 267–293. [Google Scholar] [CrossRef]
- Mirjalili, S. Dragonfly algorithm: A new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Comput. Appl. 2016, 27, 1053–1073. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Mirjalili, S. SCA: A sine cosine algorithm for solving optimization problems. Knowl.-Based Syst. 2016, 96, 120–133. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A. Advances in sine cosine algorithm: A comprehensive survey. Artif. Intell. Rev. 2021, 54, 2567–2608. [Google Scholar] [CrossRef]
- Trunk, G. A Problem of Dimensionality: A Simple Example. Pattern Anal. Mach. Intell. IEEE Trans. 1979, PAMI-1, 306–307. [Google Scholar] [CrossRef] [PubMed]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative. J. Mach. Learn. Res. 2009, 10, 13. [Google Scholar]
- Levine, M.D. Feature extraction: A survey. Proc. IEEE 1969, 57, 1391–1407. [Google Scholar] [CrossRef]
- Dhiman, G.; Oliva, D.; Kaur, A.; Singh, K.K.; Vimal, S.; Sharma, A.; Cengiz, K. BEPO: A novel binary emperor penguin optimizer for automatic feature selection. Knowl.-Based Syst. 2021, 211, 106560. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Nguyen, B.H.; Xue, B.; Zhang, M. A survey on swarm intelligence approaches to feature selection in data mining. Swarm Evol. Comput. 2020, 54, 100663. [Google Scholar] [CrossRef]
- Hussien, A.G.; Oliva, D.; Houssein, E.H.; Juan, A.A.; Yu, X. Binary Whale Optimization Algorithm for Dimensionality Reduction. Mathematics 2020, 8, 1821. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Gandomi, A.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Li, X.; Engelbrecht, A.; Epitropakis, M.G. Benchmark Functions for CEC’2013 Special Session and Competition on Niching Methods for Multimodal Function Optimization; Techtechnical Report; Evolutionary Computation and Machine Learning Group, RMIT University: Melbourne, Australia, 2013. [Google Scholar]
- Dua, D.; Graff, C. Uci machine learning repository. In The Absenteeism at Work Dataset Was Donated by Andrea Martiniano, Ricardo Pinto Ferreira, and Renato Jose Sassi; University of California: Irvine, CA, USA, 2017. [Google Scholar]
- Miao, J.; Niu, L. A Survey on Feature Selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar] [CrossRef] [Green Version]
- Dhal, P.; Azad, C. A comprehensive survey on feature selection in the various fields of machine learning. Appl. Intell. 2022, 28, 4543–4581. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A Survey on Evolutionary Computation Approaches to Feature Selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef] [Green Version]
- Brezočnik, L.; Fister, I., Jr.; Podgorelec, V. Swarm Intelligence Algorithms for Feature Selection: A Review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef] [Green Version]
- Rebolledo, M.; Stoean, R.; Eiben, A.E.; Bartz-Beielstein, T. Hybrid Variable Selection and Support Vector Regression for Gas Sensor Optimization. In Bioinspired Optimization Methods and Their Applications, Proceedings of the 9th International Conference (BIOMA 2020), Brussels, Belgium, 19–20 November 2020; Filipič, B., Minisci, E., Vasile, M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 281–293. [Google Scholar]
- Tao, Z.; Huiling, L.; Wenwen, W.; Xia, Y. GA-SVM based feature selection and parameter optimization in hospitalization expense modeling. Appl. Soft Comput. 2019, 75, 323–332. [Google Scholar] [CrossRef]
- Stoean, C. In Search of the Optimal Set of Indicators when Classifying Histopathological Images. In Proceedings of the 18th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 24–27 September 2016; pp. 449–455. [Google Scholar] [CrossRef]
- Marinaki, M.; Marinakis, Y. A bumble bees mating optimization algorithm for the feature selection problem. Int. J. Mach. Learn. Cybern. 2016, 7, 519–538. [Google Scholar] [CrossRef]
- Kashef, S.; Nezamabadi-pour, H. An advanced ACO algorithm for feature subset selection. Neurocomputing 2015, 147, 271–279. [Google Scholar] [CrossRef]
- Jeong, Y.S.; Shin, K.S.; Jeong, M.K. An evolutionary algorithm with the partial sequential forward floating search mutation for large-scale feature selection problems. J. Oper. Res. Soc. 2015, 66, 529–538. [Google Scholar] [CrossRef]
- Oreski, S.; Oreski, G. Genetic algorithm-based heuristic for feature selection in credit risk assessment. Expert Syst. Appl. 2014, 41, 2052–2064. [Google Scholar] [CrossRef]
- Winkler, S.M.; Affenzeller, M.; Jacak, W.; Stekel, H. Identification of Cancer Diagnosis Estimation Models Using Evolutionary Algorithms: A Case Study for Breast Cancer, Melanoma, and Cancer in the Respiratory System. In Proceedings of the 13th Annual Conference Companion on Genetic and Evolutionary Computation (GECCO’11), Dublin, Ireland, 12–16 July 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 503–510. [Google Scholar] [CrossRef]
- Da Silva, S.F.; Ribeiro, M.X.; Batista Neto, J.D.E.S.; Traina, C., Jr.; Traina, A.J.M. Improving the Ranking Quality of Medical Image Retrieval Using a Genetic Feature Selection Method. Decis. Support Syst. 2011, 51, 810–820. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. Particle swarm optimisation for feature selection in classification: Novel initialisation and updating mechanisms. Appl. Soft Comput. 2014, 18, 261–276. [Google Scholar] [CrossRef]
- Ben Chaabane, S.; Belazi, A.; Kharbech, S.; Bouallegue, A.; Clavier, L. Improved Salp Swarm Optimization Algorithm: Application in Feature Weighting for Blind Modulation Identification. Electronics 2021, 10, 2002. [Google Scholar] [CrossRef]
- Tubishat, M.; Idris, N.; Shuib, L.; Abushariah, M.A.; Mirjalili, S. Improved Salp Swarm Algorithm based on opposition based learning and novel local search algorithm for feature selection. Expert Syst. Appl. 2020, 145, 113122. [Google Scholar] [CrossRef]
- Hegazy, A.E.; Makhlouf, M.; El-Tawel, G.S. Improved salp swarm algorithm for feature selection. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 335–344. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.M.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R. A bi-objective green home health care routing problem. J. Clean. Prod. 2018, 200, 423–443. [Google Scholar] [CrossRef]
- Fathollahi-Fard, A.M.; Hajiaghaei-Keshteli, M.; Tavakkoli-Moghaddam, R.; Smith, N.R. Bi-level programming for home health care supply chain considering outsourcing. J. Ind. Inf. Integr. 2021, 25, 100246. [Google Scholar] [CrossRef]
- Jain, S.; Dharavath, R. Memetic salp swarm optimization algorithm based feature selection approach for crop disease detection system. J. Ambient. Intell. Humaniz. Comput. 2021, 1–19. [Google Scholar] [CrossRef]
- Venkatesh Kumar, C.; Ramesh Babu, M. An Exhaustive Solution of Power System Unit Commitment Problem Using Enhanced Binary Salp Swarm Optimization Algorithm. J. Electr. Eng. Technol. 2022, 17, 395–413. [Google Scholar] [CrossRef]
- Zivkovic, M.; Bacanin, N.; Tuba, E.; Strumberger, I.; Bezdan, T.; Tuba, M. Wireless Sensor Networks Life Time Optimization Based on the Improved Firefly Algorithm. In Proceedings of the International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1176–1181. [Google Scholar]
- Bacanin, N.; Tuba, E.; Zivkovic, M.; Strumberger, I.; Tuba, M. Whale Optimization Algorithm with Exploratory Move for Wireless Sensor Networks Localization. In Proceedings of the 19th International Conference on Hybrid Intelligent Systems (HIS 2019), Bhopal, India, 10–12 December 2019; Springer: Cham, Switzerland, 2019; pp. 328–338. [Google Scholar]
- Zivkovic, M.; Bacanin, N.; Zivkovic, T.; Strumberger, I.; Tuba, E.; Tuba, M. Enhanced Grey Wolf Algorithm for Energy Efficient Wireless Sensor Networks. In Proceedings of the Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 26–27 May 2020; pp. 87–92. [Google Scholar]
- Bacanin, N.; Arnaut, U.; Zivkovic, M.; Bezdan, T.; Rashid, T.A. Energy Efficient Clustering in Wireless Sensor Networks by Opposition-Based Initialization Bat Algorithm. In Computer Networks and Inventive Communication Technologies; Springer: Singapore, 2022; pp. 1–16. [Google Scholar]
- Bacanin, N.; Bezdan, T.; Tuba, E.; Strumberger, I.; Tuba, M.; Zivkovic, M. Task scheduling in cloud computing environment by grey wolf optimizer. In Proceedings of the 27th Telecommunications Forum (TELFOR), Belgrade, Serbia, 26–27 November 2019; pp. 1–4. [Google Scholar]
- Zivkovic, M.; Bacanin, N.; Venkatachalam, K.; Nayyar, A.; Djordjevic, A.; Strumberger, I.; Al-Turjman, F. COVID-19 cases prediction by using hybrid machine learning and beetle antennae search approach. Sustain. Cities Soc. 2021, 66, 102669. [Google Scholar] [CrossRef] [PubMed]
- Zivkovic, M.; Venkatachalam, K.; Bacanin, N.; Djordjevic, A.; Antonijevic, M.; Strumberger, I.; Rashid, T.A. Hybrid Genetic Algorithm and Machine Learning Method for COVID-19 Cases Prediction. In Proceedings of International Conference on Sustainable Expert Systems; Springer Nature: Singapore, 2021; Volume 176, p. 169. [Google Scholar]
- Bezdan, T.; Zivkovic, M.; Tuba, E.; Strumberger, I.; Bacanin, N.; Tuba, M. Glioma Brain Tumor Grade Classification from MRI Using Convolutional Neural Networks Designed by Modified FA. In International Conference on Intelligent and Fuzzy Systems, Proceedings of the INFUS 2020 Conference, Istanbul, Turkey, 21–23 July 2020; Springer: Cham, Switzerland, 2020; pp. 955–963. [Google Scholar]
- Basha, J.; Bacanin, N.; Vukobrat, N.; Zivkovic, M.; Venkatachalam, K.; Hubálovskỳ, S.; Trojovskỳ, P. Chaotic Harris Hawks Optimization with Quasi-Reflection-Based Learning: An Application to Enhance CNN Design. Sensors 2021, 21, 6654. [Google Scholar] [CrossRef] [PubMed]
- Bezdan, T.; Stoean, C.; Naamany, A.A.; Bacanin, N.; Rashid, T.A.; Zivkovic, M.; Venkatachalam, K. Hybrid Fruit-Fly Optimization Algorithm with K-Means for Text Document Clustering. Mathematics 2021, 9, 1929. [Google Scholar] [CrossRef]
- Strumberger, I.; Tuba, E.; Bacanin, N.; Zivkovic, M.; Beko, M.; Tuba, M. Designing convolutional neural network architecture by the firefly algorithm. In Proceedings of the International Young Engineers Forum (YEF-ECE), Costa da Caparica, Portugal, 10 May 2019; pp. 59–65. [Google Scholar]
- Milosevic, S.; Bezdan, T.; Zivkovic, M.; Bacanin, N.; Strumberger, I.; Tuba, M. Feed-Forward Neural Network Training by Hybrid Bat Algorithm. In Modelling and Development of Intelligent Systems, Proceedings of the 7th International Conference (MDIS 2020), Sibiu, Romania, 22–24 October 2020; Revised Selected Papers 7; Springer International Publishing: Cham, Switzerland, 2021; pp. 52–66. [Google Scholar]
- Bacanin, N.; Bezdan, T.; Venkatachalam, K.; Zivkovic, M.; Strumberger, I.; Abouhawwash, M.; Ahmed, A. Artificial Neural Networks Hidden Unit and Weight Connection Optimization by Quasi-Refection-Based Learning Artificial Bee Colony Algorithm. IEEE Access 2021, 9, 169135–169155. [Google Scholar] [CrossRef]
- Bacanin, N.; Alhazmi, K.; Zivkovic, M.; Venkatachalam, K.; Bezdan, T.; Nebhen, J. Training Multi-Layer Perceptron with Enhanced Brain Storm Optimization Metaheuristics. Comput. Mater. Contin. 2022, 70, 4199–4215. [Google Scholar] [CrossRef]
- Bezdan, T.; Petrovic, A.; Zivkovic, M.; Strumberger, I.; Devi, V.K.; Bacanin, N. Current Best Opposition-Based Learning Salp Swarm Algorithm for Global Numerical Optimization. In Proceedings of the Zooming Innovation in Consumer Technologies Conference (ZINC), Novi Sad, Serbia, 26–27 May 2021; pp. 5–10. [Google Scholar]
- Bacanin, N.; Petrovic, A.; Zivkovic, M.; Bezdan, T.; Chhabra, A. Enhanced Salp Swarm Algorithm for Feature Selection. In International Conference on Intelligent and Fuzzy Systems, Proceedings of the INFUS 2021 Conference, Virtual, 24–26 August 2021; Springer: Cham, Switzerland, 2021; pp. 483–491. [Google Scholar]
- Yang, X.S. Firefly Algorithms for Multimodal Optimization. In Stochastic Algorithms: Foundations and Applications; Watanabe, O., Zeugmann, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 169–178. [Google Scholar]
- Zandevakili, H.; Rashedi, E.; Mahani, A. Gravitational search algorithm with both attractive and repulsive forces. Soft Comput. 2019, 23, 1–43. [Google Scholar] [CrossRef]
- Haupt, R.L.; Haupt, S.E. Practical Genetic Algorithms; John Wiley and Sons: New York, NY, USA, 1998. [Google Scholar]
- Rashedi, E.; Nezamabadi-pour, H. Improving the precision of CBIR systems by feature selection using binary gravitational search algorithm. In Proceedings of the 16th CSI International Symposium on Artificial Intelligence and Signal Processing (AISP 2012), Shiraz, Iran, 2–3 May 2012. [Google Scholar] [CrossRef]
- Sarafrazi, S.; Nezamabadi-pour, H.; Saryazdi, S. Disruption: A new operator in gravitational search algorithm. Sci. Iran. 2011, 18, 539–548. [Google Scholar] [CrossRef] [Green Version]
- Doraghinejad, M.; Nezamabadi-Pour, H. Black hole: A new operator for gravitational search algorithm. Int. J. Comput. Intell. Syst. 2014, 7, 809–826. [Google Scholar] [CrossRef] [Green Version]
- Shams, M.; Rashedi, E.; Hakimi, A. Clustered-gravitational search algorithm and its application in parameter optimization of a Low Noise Amplifier. Appl. Math. Comput. 2015, 258, 436–453. [Google Scholar] [CrossRef]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar]
- Iman, R.L.; Davenport, J.M. Approximations of the critical region of the fbietkan statistic. Commun. Stat.-Theory Methods 1980, 9, 571–595. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).