
A 6D Pose Estimation for Robotic Bin-Picking Using Point-Pair Features with Curvature (Cur-PPF)


Abstract
:1. Introduction
2. The Proposed Method
2.1. Offline Phase
2.1.1. Preprocessing
2.1.2. Cur-PPF Feature Extraction and Hash Table
2.2. Online Phase
2.2.1. Point Cloud Segmentation and Candidate Target Selection
| Algorithm 1 Watershed Segmentation Algorithm Based on Distance Transform |
| 1: Input: , Output: 2: if end if 3: 4: 5: 6: if else end if 7: 8: 9: if else end if 10: 11: 12: |
2.2.2. Feature Matching
2.2.3. Weighted Voting System
2.2.4. Pose Clustering
2.2.5. ICP Optimization
3. Experimental Results and Discussions
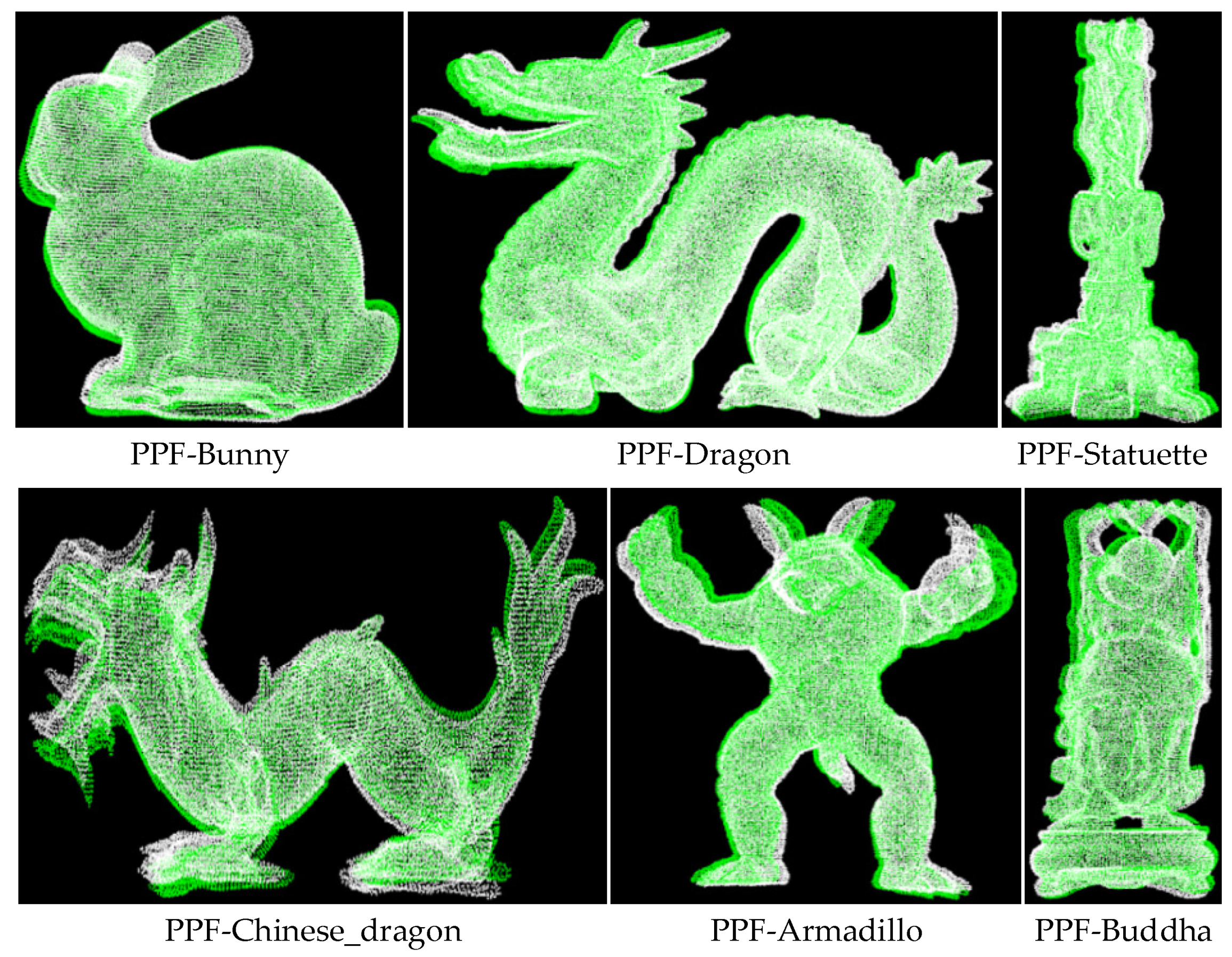
3.1. Public Data Set
3.2. Real Scene Data
3.2.1. Matching Effect of Real Scenario
3.2.2. Bin-Picking Performance of Robotic Arm
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Inagaki, Y.; Araki, R.; Yamashita, T.; Fujiyoshi, H. Detecting layered structures of partially occluded objects for bin picking. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019. [Google Scholar]
- Danielczuk, M.; Mahler, J.; Correa, C.; Goldberg, K. Linear Push Policies to Increase Grasp Access for Robot Bin Picking. In Proceedings of the IEEE International Conference on Automation Science and Engineering, Munich, Germany, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Iriondo, A.; Lazkano, E.; Ansuategi, A. Affordance-based grasping point detection using graph convolutional networks for industrial bin-picking applications. Sensors 2021, 21, 816. [Google Scholar] [CrossRef] [PubMed]
- Matsumura, R.; Harada, K.; Domae, Y.; Wan, W. Learning based industrial bin-picking trained with approximate physics simulator. In Proceedings of the Advances in Intelligent Systems and Computing, Cham, Switzerland, 23 May 2018. [Google Scholar]
- Hofer, T.; Shamsafar, F.; Benbarka, N.; Zell, A. Object Detection And Autoencoder-Based 6d Pose Estimation For Highly Cluttered Bin Picking. arXiv 2021, arXiv:2106.08045. [Google Scholar]
- Chen, J.; Zhang, L.; Liu, Y.; Xu, C. Survey on 6D Pose Estimation of Rigid Object. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020. [Google Scholar]
- Du, G.; Wang, K.; Lian, S. Vision-based robotic grasping from object localization, pose estimation, grasp detection to motion planning: A review. arXiv 2019, arXiv:1905.06658. [Google Scholar]
- Hu, Y.; Hugonot, J.; Fua, P.; Salzmann, M. Segmentation-Driven 6D Object Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast Point Feature Histograms (FPFH) for 3D Registration. In Proceedings of the IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009. [Google Scholar]
- Tombari, F.; Salti, S.; Di Stefano, L. Unique signatures of histograms for local surface description. In Proceedings of the European Conference on Computer Vision, Berlin, Germany, 5–11 September 2010. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Xue, S.; Zhang, Z.; Lv, Q.; Meng, X.; Tu, X. Point Cloud Registration Method for Pipeline Workpieces Based on PCA and Improved ICP Algorithms. IOP Conf. Ser. Mater. Sci. Eng. 2019, 612, 032188. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence, San Diego, CA, USA, 19–24 July 1992. [Google Scholar]
- Sarode, V.; Li, X.; Goforth, H.; Aoki, Y.; Srivatsan, R.A.; Lucey, S.; Choset, H. PCRNet: Point Cloud Registration Network using PointNet Encoding. arXiv 2019, arXiv:1908.07906. [Google Scholar]
- Guo, J.; Xing, X.; Quan, W.; Yan, D.M.; Gu, Q.; Liu, Y.; Zhang, X. Efficient Center Voting for Object Detection and 6D Pose Estimation in 3D Point Cloud. IEEE Trans. Image Process. 2021, 30, 5072–5084. [Google Scholar] [CrossRef] [PubMed]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. PVNET: Pixel-Wise Voting Network for 6dof Pose Estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Los Angeles, CA, USA, 15–21 June 2019. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Deng, L. Artificial Intelligence in the Rising Wave of Deep Learning: The Historical Path and Future Outlook. IEEE Signal Process. Mag. 2018, 35, 177–180. [Google Scholar] [CrossRef]
- Wang, C.; Xu, D.; Zhu, Y.; Martin-Martin, R.; Lu, C.; Fei-Fei, L.; Savarese, S. DenseFusion: 6D object pose estimation by iterative dense fusion. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Braun, M.; Rao, Q.; Wang, Y.; Flohr, F. Pose-RCNN: Joint object detection and pose estimation using 3d object proposals. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, Rio de Janeiro, Brazil, 1–4 November 2016. [Google Scholar]
- Choi, C.; Christensen, H.I. 3D pose estimation of daily objects using an RGB-D camera. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Liu, D.; Arai, S.; Miao, J.; Kinugawa, J.; Wang, Z.; Kosuge, K. Point pair feature-based pose estimation with multiple edge appearance models (PPF-MEAM) for robotic bin picking. Sensors 2018, 18, 2719. [Google Scholar] [CrossRef] [Green Version]
- Vidal, J.; Lin, C.Y.; Lladó, X.; Martí, R. A method for 6D pose estimation of free-form rigid objects using point pair features on range data. Sensors 2018, 18, 2678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ruel, S.; English, C.; Anctil, M.; Church, P. 3DLASSO: Real-time pose estimation from 3D data for autonomous satellite servicing. In Proceedings of the Proc. ISAIRAS 2005 Conference, Munich, Germany, 5–8 September 2005. [Google Scholar]
- Mérigot, Q.; Ovsjanikov, M.; Guibas, L.J. Voronoi-based curvature and feature estimation from point clouds. IEEE Trans. Vis. Comput. Graph. 2011, 17, 743–756. [Google Scholar] [CrossRef] [Green Version]
- Beucher, S.; Lantuejoul, C. Use of Watersheds in Contour Detection. In Proceedings of the International Workshop on Image Processing, Rennes, France, 17–21 September 1979. [Google Scholar]
- Braeger, S.; Foroosh, H. Curvature augmented deep learning for 3D object recognition. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Tong, L.; Ying, X. 3D Point Cloud Initial Registration Using Surface Curvature and SURF Matching. 3D Res. 2018, 9, 1–16. [Google Scholar] [CrossRef]
- Nguyen, A.; Le, B. 3D point cloud segmentation: A survey. In Proceedings of the IEEE Conference on Robotics, Automation and Mechatronics, RAM—Proceedings, Manila, Philippines, 12–15 November 2013. [Google Scholar]
- Selvarasu, N.; Nachiappan, A.; Nandhitha, N.M. Euclidean Distance Based Color Image Segmentation of Abnormality Detection from Pseudo Color Thermographs. Int. J. Comput. Theory Eng. 2010, 2, 514. [Google Scholar] [CrossRef]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Wang, Z.; Wang, E.; Zhu, Y. Image segmentation evaluation: A survey of methods. Artif. Intell. Rev. 2020, 53, 5637–5674. [Google Scholar] [CrossRef]
- Xiao, J.; Adler, B.; Zhang, H. 3D point cloud registration based on planar surfaces. In Proceedings of the IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems, Hamburg, Germany, 13–15 September 2012. [Google Scholar]
- Mian, A.; Bennamoun, M.; Owens, R. On the repeatability and quality of keypoints for local feature-based 3D object retrieval from cluttered scenes. Int. J. Comput. Vis. 2010, 89, 348–361. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Zhang, J.; Zhang, G. An automatic 3D point cloud registration method based on regional curvature maps. Image Vis. Comput. 2016, 56, 49–58. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Bunny | Dragon | Statuette | Chinese_Dragon | Armadillo | Buddha | Average |
|---|---|---|---|---|---|---|---|
| PPF [16] | 87.42% | 84.71% | 84.92% | 94.77% | 81.40% | 93.25% | 87.75% |
| Cur-PPF(Unweight) | 93.12% | 95.96% | 89.91% | 95.74% | 92.94% | 94.25% | 93.65% |
| Models | Bunny | Dragon | Statuette | Chinese_Dragon | Armadillo | Buddha | Average |
|---|---|---|---|---|---|---|---|
| PPF [16] | 145 | 745 | 1151 | 893 | 341 | 803 | 679.67 |
| Cur-PPF(Unweight) | 85 | 165 | 169 | 233 | 203 | 221 | 179.33 |
| Models | Bunny | Dragon | Statuette | Chinese_Dragon | Armadillo | Buddha | Average |
|---|---|---|---|---|---|---|---|
| Cur-PPF(Unweight) | 93.12% | 95.96% | 89.91% | 95.74% | 92.94% | 94.25% | 93.65% |
| Cur-PPF | 94.40% | 99.84% | 95.44% | 97.09% | 94.20% | 96.80% | 96.30% |
| Models | Bunny | Dragon | Statuette | Chinese_Dragon | Armadillo | Buddha | Average |
|---|---|---|---|---|---|---|---|
| Cur-PPF(Unweight) | 85 | 165 | 169 | 233 | 203 | 221 | 179.33 |
| Cur-PPF | 87 | 195 | 289 | 226 | 241 | 236 | 212..33 |
| Models | Cheff | Chicken | T-Rex | Parasaurolophus | Average |
|---|---|---|---|---|---|
| Cur-PPF | 91.41% | 87.60% | 90.68% | 86.01% | 88.93% |
| Cur-PPF+ICP | 95.15% | 94.37% | 92.86% | 90.31% | 93.17% |
| Models | Three-Way Tube | Pillar | Average |
|---|---|---|---|
| PPF | 83.15% | 87.84% | 85.50% |
| Cur-PPF | 95.60% | 94.35% | 94.98% |
| PPF+ICP | 96.10% | 95.25% | 95.68% |
| Cur-PPF+ICP | 98.90% | 97.50% | 98.20% |
| Models | Three-Way Tube | Pillar | Average |
|---|---|---|---|
| PPF | 7034 | 8560 | 7797 |
| Cur-PPF | 3256 | 4236 | 3746 |
| PPF+ICP | 8098 | 9362 | 8730 |
| Cur-PPF+ICP | 4136 | 5082 | 4609 |
| Total Number of Experiments | Success | Failure | Success Rate |
|---|---|---|---|
| 100 | 95 | 5 | 95% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, X.; Yu, M.; Wu, L.; Wu, S. A 6D Pose Estimation for Robotic Bin-Picking Using Point-Pair Features with Curvature (Cur-PPF). Sensors 2022, 22, 1805. https://doi.org/10.3390/s22051805
Cui X, Yu M, Wu L, Wu S. A 6D Pose Estimation for Robotic Bin-Picking Using Point-Pair Features with Curvature (Cur-PPF). Sensors. 2022; 22(5):1805. https://doi.org/10.3390/s22051805
Chicago/Turabian StyleCui, Xining, Menghui Yu, Linqigao Wu, and Shiqian Wu. 2022. "A 6D Pose Estimation for Robotic Bin-Picking Using Point-Pair Features with Curvature (Cur-PPF)" Sensors 22, no. 5: 1805. https://doi.org/10.3390/s22051805
APA StyleCui, X., Yu, M., Wu, L., & Wu, S. (2022). A 6D Pose Estimation for Robotic Bin-Picking Using Point-Pair Features with Curvature (Cur-PPF). Sensors, 22(5), 1805. https://doi.org/10.3390/s22051805